Long Short-Term Memory Based Recurrent Neural Network Architectures for Large Vocabulary Speech Recognition
Long Short-Term Memory (LSTM) is a recurrent neural network (RNN) architecture that has been designed to address the vanishing and exploding gradient problems of conventional RNNs. Unlike feedforward neural networks, RNNs have cyclic connections maki…
Authors: Hac{s}im Sak, Andrew Senior, Franc{c}oise Beaufays
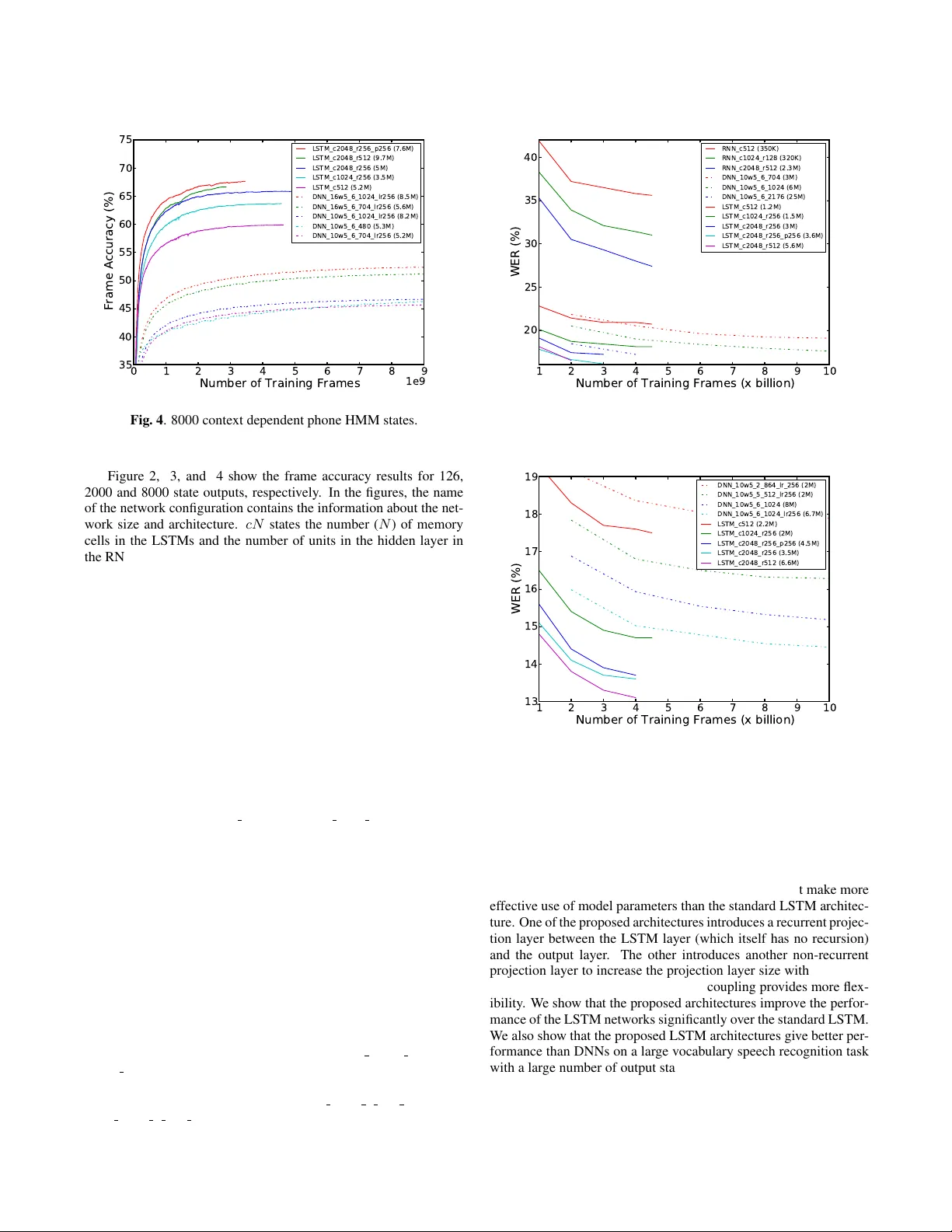
LONG SHOR T -TERM MEMOR Y B ASED RECURRENT NEURAL NETWORK ARCHITECTURES FOR LARGE V OCABULAR Y SPEECH RECOGNITION Has ¸ im Sak, Andr ew Senior , F r anc ¸ oise Beaufays Google { hasim,andrewsenior,fsb@google.com } ABSTRA CT Long Short-T erm Memory (LSTM) is a recurrent neural network (RNN) architecture that has been designed to address the vanish- ing and exploding gradient problems of con ventional RNNs. Unlik e feedforward neural networks, RNNs hav e cyclic connections mak- ing them powerful for modeling sequences. They have been suc- cessfully used for sequence labeling and sequence prediction tasks, such as handwriting recognition, language modeling, phonetic la- beling of acoustic frames. Howe ver , in contrast to the deep neural networks, the use of RNNs in speech recognition has been limited to phone recognition in small scale tasks. In this paper , we present nov el LSTM based RNN architectures which make more effecti ve use of model parameters to train acoustic models for large vocab- ulary speech recognition. W e train and compare LSTM, RNN and DNN models at v arious numbers of parameters and configurations. W e show that LSTM models con verge quickly and gi ve state of the art speech recognition performance for relatively small sized mod- els. 1 Index T erms — Long Short-T erm Memory , LSTM, recurrent neural network, RNN, speech recognition. 1. INTR ODUCTION Unlike feedforward neural networks (FFNN) such as deep neural networks (DNNs), the architecture of recurrent neural networks (RNNs) ha ve cycles feeding the acti vations from pre vious time steps as input to the network to make a decision for the current input. The acti vations from the previous time step are stored in the internal state of the network and they provide indefinite temporal contextual information in contrast to the fixed contextual windows used as inputs in FFNNs. Therefore, RNNs use a dynamically changing contextual windo w of all sequence history rather than a static fixed size window over the sequence. This capability makes RNNs better suited for sequence modeling tasks such as sequence prediction and sequence labeling tasks. Howe ver , training conv entional RNNs with the gradient-based back-propagation through time (BPTT) technique is dif ficult due to the v anishing gradient and e xploding gradient problems [1]. In addi- tion, these problems limit the capability of RNNs to model the long range context dependencies to 5-10 discrete time steps between rel- ev ant input signals and output. T o address these problems, an ele gant RNN architecture – Long Short-T erm Memory (LSTM) – has been designed [2]. The original 1 The original manuscript has been submitted to ICASSP 2014 conference on November 4, 2013 and it has been rejected due to having content on the reference only 5th page. This version has been slightly edited to reflect the latest experimental results. architecture of LSTMs contained special units called memory blocks in the recurrent hidden layer . The memory blocks contain memory cells with self-connections storing (remembering) the temporal state of the network in addition to special multiplicati ve units called gates to control the flow of information. Each memory block contains an input gate which controls the flo w of input activ ations into the mem- ory cell and an output gate which controls the output flow of cell activ ations into the rest of the network. Later, to address a weakness of LSTM models preventing them from processing continuous input streams that are not segmented into subsequences – which would al- low resetting the cell states at the begining of subsequences – a for get gate was added to the memory block [3]. A forget gate scales the in- ternal state of the cell before adding it as input to the cell through self recurrent connection of the cell, therefore adaptively forgetting or resetting cell’ s memory . Besides, the modern LSTM architecture contains peephole connections from its internal cells to the gates in the same cell to learn precise timing of the outputs [4]. LSTMs and conv entional RNNs have been successfully applied to sequence prediction and sequence labeling tasks. LSTM models hav e been shown to perform better than RNNs on learning context- free and context-sensiti ve languages [5]. Bidirectional LSTM net- works similar to bidirectional RNNs [6] operating on the input se- quence in both direction to make a decision for the current input has been proposed for phonetic labeling of acoustic frames on the TIMIT speech database [7]. For online and offline handwriting recognition, bidirectional LSTM networks with a connectionist temporal classi- fication (CTC) output layer using a forward backward type of al- gorithm which allows the network to be trained on unsegmented sequence data, hav e been shown to outperform a state of the art HMM-based system [8]. Recently , follo wing the success of DNNs for acoustic modeling [9, 10, 11], a deep LSTM RNN – a stack of multiple LSTM layers – combined with a CTC output layer and an RNN transducer predicting phone sequences – has been shown to get the state of the art results in phone recognition on the TIMIT database [12]. In language modeling, a conv entional RNN has ob- tained very significant reduction of perplexity o ver standard n -gram models [13]. While DNNs have sho wn state of the art performance in both phone recognition and large vocab ulary speech recognition [9, 10, 11], the application of LSTM networks has been limited to phone recognition on the TIMIT database, and it has required using addi- tional techniques and models such as CTC and RNN transducer to obtain better results than DNNs. In this paper, we show that LSTM based RNN architectures can obtain state of the art performance in a large vocab ulary speech recognition system with thousands of context dependent (CD) states. The proposed architectures modify the standard architecture of the LSTM networks to make better use of the model parameters while addressing the computational efficienc y problems of large netw orks. 2. LSTM ARCHITECTURES In the standard architecture of LSTM networks, there are an input layer , a recurrent LSTM layer and an output layer . The input layer is connected to the LSTM layer . The recurrent connections in the LSTM layer are directly from the cell output units to the cell input units, input gates, output gates and forget gates. The cell output units are connected to the output layer of the network. The total number of parameters W in a standard LSTM network with one cell in each memory block, ignoring the biases, can be calculated as follows: W = n c × n c × 4 + n i × n c × 4 + n c × n o + n c × 3 where n c is the number of memory cells (and number of memory blocks in this case), n i is the number of input units, and n o is the number of output units. The computational complexity of learning LSTM models per weight and time step with the stochastic gradient descent (SGD) optimization technique is O (1) . Therefore, the learn- ing computational complexity per time step is O ( W ) . The learn- ing time for a network with a relativ ely small number of inputs is dominated by the n c × ( n c + n o ) factor . For the tasks requiring a large number of output units and a large number of memory cells to store temporal contextual information, learning LSTM models be- come computationally expensi ve. As an alternative to the standard architecture, we propose two nov el architectures to address the computational complexity of learning LSTM models. The two architectures are shown in the same Figure 1. In one of them, we connect the cell output units to a recurrent projection layer which connects to the cell input units and gates for recurrency in addition to network output units for the prediction of the outputs. Hence, the number of parameters in this model is n c × n r × 4 + n i × n c × 4 + n r × n o + n c × n r + n c × 3 , where n r is the number of units in the recurrent projection layer . In the other one, in addition to the recurrent projection layer , we add another non-recurrent projection layer which is directly connected to the output layer . This model has n c × n r × 4 + n i × n c × 4 + ( n r + n p ) × n o + n c × ( n r + n p ) + n c × 3 parameters, where n p is the number of units in the non-recurrent projection layer and it allows us to increase the number of units in the projection layers without increasing the number of parameters in the recurrent connections ( n c × n r × 4 ). Note that having two projection layers with regard to output units is effecti vely equiv alent to having a single projection layer with n r + n p units. An LSTM network computes a mapping from an input sequence x = ( x 1 , ..., x T ) to an output sequence y = ( y 1 , ..., y T ) by cal- culating the network unit activ ations using the following equations iterativ ely from t = 1 to T : i t = σ ( W ix x t + W im m t − 1 + W ic c t − 1 + b i ) (1) f t = σ ( W f x x t + W mf m t − 1 + W cf c t − 1 + b f ) (2) c t = f t c t − 1 + i t g ( W cx x t + W cm m t − 1 + b c ) (3) o t = σ ( W ox x t + W om m t − 1 + W oc c t + b o ) (4) m t = o t h ( c t ) (5) y t = W ym m t + b y (6) where the W terms denote weight matrices (e.g. W ix is the matrix of weights from the input gate to the input), the b terms denote bias vectors ( b i is the input gate bias vector), σ is the logistic sigmoid function, and i , f , o and c are respecti vely the input gate, for get gate, output gate and cell activ ation vectors, all of which are the same size as the cell output acti vation vector m , is the element-wise product input g × c t − 1 h × × i t f t c t o t recurrent projection output x t m t p t r t r t − 1 y t memory blocks Fig. 1 . LSTM based RNN architectures with a recurrent projection layer and an optional non-recurrent projection layer . A single mem- ory block is shown for clarity . of the v ectors and g and h are the cell input and cell output acti vation functions, generally tanh . W ith the proposed LSTM architecture with both recurrent and non-recurrent projection layer , the equations are as follows: i t = σ ( W ix x t + W ir r t − 1 + W ic c t − 1 + b i ) (7) f t = σ ( W f x x t + W rf r t − 1 + W cf c t − 1 + b f ) (8) c t = f t c t − 1 + i t g ( W cx x t + W cr r t − 1 + b c ) (9) o t = σ ( W ox x t + W or r t − 1 + W oc c t + b o ) (10) m t = o t h ( c t ) (11) r t = W rm m t (12) p t = W pm m t (13) y t = W yr r t + W yp p t + b y (14) (15) where the r and p denote the recurrent and optional non-recurrent unit activ ations. 2.1. Implementation W e choose to implement the proposed LSTM architectures on multi- core CPU on a single machine rather than on GPU. The decision was based on CPU’ s relatively simpler implementation complexity and ease of debugging. CPU implementation also allows easier dis- tributed implementation on a large cluster of machines if the learn- ing time of large networks becomes a major bottleneck on a single machine [14]. For matrix operations, we use the Eigen matrix li- brary [15]. This templated C++ library provides ef ficient implemen- tations for matrix operations on CPU using vectorized instructions (SIMD – single instruction multiple data). W e implemented acti- vation functions and gradient calculations on matrices using SIMD instructions to benefit from parallelization. W e use the asynchronous stochastic gradient descent (ASGD) optimization technique. The update of the parameters with the gra- dients is done asynchronously from multiple threads on a multi-core machine. Each thread operates on a batch of sequences in parallel for computational efficiency – for instance, we can do matrix-matrix multiplications rather than vector -matrix multiplications – and for more stochasticity since model parameters can be updated from mul- tiple input sequence at the same time. In addition to batching of se- quences in a single thread, training with multiple threads effecti vely results in much larger batch of sequences (number of threads times batch size) to be processed in parallel. W e use the truncated backpropagation through time (BPTT) learning algorithm to update the model parameters [16]. W e use a fixed time step T bptt (e.g. 20) to forward-propagate the acti vations and backward-propagate the gradients. In the learning process, we split an input sequence into a vector of subsequences of size T bptt . The subsequences of an utterance are processed in their original order . First, we calculate and forward-propagate the activ ations iter- ativ ely using the network input and the activ ations from the pre vious time step for T bptt time steps starting from the first frame and calcu- late the network errors using netw ork cost function at each time step. Then, we calculate and back-propagate the gradients from a cross- entropy criterion, using the errors at each time step and the gradients from the next time step starting from the time T bptt . Finally , the gradients for the network parameters (weights) are accumulated for T bptt time steps and the weights are updated. The state of memory cells after processing each subsequence is saved for the next sub- sequence. Note that when processing multiple subsequences from different input sequences, some subsequences can be shorter than T bptt since we could reach the end of those sequences. In the next batch of subsequences, we replace them with subsequences from a new input sequence, and reset the state of the cells for them. 3. EXPERIMENTS W e ev aluate and compare the performance of DNN, RNN and LSTM neural network architectures on a large vocab ulary speech recogni- tion task – Google English V oice Search task. 3.1. Systems & Evaluation All the networks are trained on a 3 million utterance (about 1900 hours) dataset consisting of anonymized and hand-transcribed Google voice search and dictation traffic. The dataset is repre- sented with 25ms frames of 40-dimensional log-filterbank energy features computed e very 10ms. The utterances are aligned with a 90 million parameter FFNN with 14247 CD states. W e train networks for three different output states inv entories: 126, 2000 and 8000. These are obtained by mapping 14247 states down to these smaller state in ventories through equi valence classes. The 126 state set are the context independent (CI) states (3 x 42). The weights in all the networks before training are randomly initialized. W e try to set the learning rate specific to a network architecture and its configuration to the lar gest v alue that results in a stable con vergence. The learning rates are exponentially decayed during training. During training, we e valuate frame accuracies (i.e. phone state labeling accuracy of acoustic frames) on a held out development set of 200,000 frames. The trained models are ev aluated in a speech recognition system on a test set of 23,000 hand-transcribed utter- ances and the word error rates (WERs) are reported. The vocab ulary size of the language model used in the decoding is 2.6 million. The DNNs are trained with SGD with a minibatch size of 200 frames on a Graphics Processing Unit (GPU). Each network is fully connected with logistic sigmoid hidden layers and with a softmax output layer representing phone HMM states. For consistency with the LSTM architectures, some of the networks have a lo w-rank pro- jection layer [17]. The DNNs inputs consist of stacked frames from an asymmetrical window , with 5 frames on the right and either 10 or 15 frames on the left (denoted 10w5 and 15w5 respectiv ely) The LSTM and con ventional RNN architectures of various configurations are trained with ASGD with 24 threads, each asyn- chronously processing one partition of data, with each thread com- puting a gradient step on 4 or 8 subsequences from different ut- terances. A time step of 20 ( T bptt ) is used to forward-propagate and the activ ations and backward-propagate the gradients using the truncated BPTT learning algorithm. The units in the hidden layer of RNNs use the logistic sigmoid acti vation function. The RNNs with the recurrent projection layer architecture use linear activ ation units in the projection layer . The LSTMs use hyperbolic tangent activ ation (tanh) for the cell input units and cell output units, and logistic sigmoid for the input, output and forget gate units. The recurrent projection and optional non-recurrent projection layers in the LSTMs use linear activ ation units. The input to the LSTMs and RNNs is 25ms frame of 40-dimensional log-filterbank energy features (no window of frames). Since the information from the future frames helps making better decisions for the current frame, consistent with the DNNs, we delay the output state label by 5 frames. 3.2. Results 0 1 2 3 4 5 6 7 8 9 Number of Training Frames 1e9 35 40 45 50 55 60 65 70 75 Frame Accuracy (%) LSTM_c2048_r512 (5.6M) LSTM_c2048_r256_p256 (3.6M) LSTM_c2048_r256 (3M) LSTM_c1024_r256 (1.5M) LSTM_c512 (1.2M) DNN_10w5_6_2176 (25M) DNN_10w5_6_1024 (6M) DNN_10w5_6_704 (3M) RNN_c2048_r512 (2.3M) RNN_c1024_r128 (320K) RNN_c512 (350K) Fig. 2 . 126 context independent phone HMM states. 0 1 2 3 4 5 6 7 8 9 Number of Training Frames 1e9 35 40 45 50 55 60 65 70 75 Frame Accuracy (%) LSTM_c2048_r512 (6.6M) LSTM_c2048_r256 (3.5M) LSTM_c2048_r256_p256 (4.5M) LSTM_c1024_r256 (2M) LSTM_c512 (2.2M) DNN_10w5_6_1024_lr256 (6.7M) DNN_10w5_6_1024 (8M) DNN_10w5_5_512_lr256 (2M) DNN_10w5_2_864_lr_256 (2M) Fig. 3 . 2000 context dependent phone HMM states. 0 1 2 3 4 5 6 7 8 9 Number of Training Frames 1e9 35 40 45 50 55 60 65 70 75 Frame Accuracy (%) LSTM_c2048_r256_p256 (7.6M) LSTM_c2048_r512 (9.7M) LSTM_c2048_r256 (5M) LSTM_c1024_r256 (3.5M) LSTM_c512 (5.2M) DNN_16w5_6_1024_lr256 (8.5M) DNN_16w5_6_704_lr256 (5.6M) DNN_10w5_6_1024_lr256 (8.2M) DNN_10w5_6_480 (5.3M) DNN_10w5_6_704_lr256 (5.2M) Fig. 4 . 8000 context dependent phone HMM states. Figure 2, 3, and 4 show the frame accuracy results for 126, 2000 and 8000 state outputs, respecti vely . In the figures, the name of the network configuration contains the information about the net- work size and architecture. cN states the number ( N ) of memory cells in the LSTMs and the number of units in the hidden layer in the RNNs. rN states the number of recurrent projection units in the LSTMs and RNNs. pN states the number of non-recurrent projec- tion units in the LSTMs. The DNN configuration names state the left context and right context size (e.g. 10w5), the number of hid- den layers (e.g. 6), the number of units in each of the hidden layers (e.g. 1024) and optional low-rank projection layer size (e.g. 256). The number of parameters in each model is giv en in parenthesis. W e ev aluated the RNNs only for 126 state output configuration, since they performed significantly worse than the DNNs and LSTMs. As can be seen from Figure 2, the RNNs were also very unstable at the beginning of the training and, to achiev e con vergence, we had to limit the activ ations and the gradients due to the exploding gradient problem. The LSTM netw orks gi ve much better frame accuracy than the RNNs and DNNs while con verging faster . The proposed LSTM projected RNN architectures give significantly better accuracy than the standard LSTM RNN architecture with the same number of pa- rameters – compare LSTM 512 with LSTM 1024 256 in Figure 3. The LSTM network with both recurrent and non-recurrent projec- tion layers generally performs better than the LSTM network with only recurrent projection layer except for the 2000 state experiment where we hav e set the learning rate too small. Figure 5, 6, and 7 show the WERs for the same models for 126, 2000 and 8000 state outputs, respectively . Note that some of the LSTM networks have not con ver ged yet, we will update the re- sults when the models conv erge in the final re vision of the paper . The speech recognition experiments show that the LSTM networks give improv ed speech recognition accuracy for the context independent 126 output state model, conte xt dependent 2000 output state embed- ded size model (constrained to run on a mobile phone processor) and relativ ely large 8000 output state model. As can be seen from Fig- ure 6, the proposed architectures (compare LSTM c1024 r256 with LSTM c512 ) are essential for obtaining better recognition accura- cies than DNNs. W e also did an experiment to show that depth is very important for DNNs – compare DNN 10w5 2 864 lr256 with DNN 10w5 5 512 lr256 in Figure 6. 1 2 3 4 5 6 7 8 9 10 Number of Training Frames (x billion) 20 25 30 35 40 WER (%) RNN_c512 (350K) RNN_c1024_r128 (320K) RNN_c2048_r512 (2.3M) DNN_10w5_6_704 (3M) DNN_10w5_6_1024 (6M) DNN_10w5_6_2176 (25M) LSTM_c512 (1.2M) LSTM_c1024_r256 (1.5M) LSTM_c2048_r256 (3M) LSTM_c2048_r256_p256 (3.6M) LSTM_c2048_r512 (5.6M) Fig. 5 . 126 context independent phone HMM states. 1 2 3 4 5 6 7 8 9 10 Number of Training Frames (x billion) 13 14 15 16 17 18 19 WER (%) DNN_10w5_2_864_lr_256 (2M) DNN_10w5_5_512_lr256 (2M) DNN_10w5_6_1024 (8M) DNN_10w5_6_1024_lr256 (6.7M) LSTM_c512 (2.2M) LSTM_c1024_r256 (2M) LSTM_c2048_r256_p256 (4.5M) LSTM_c2048_r256 (3.5M) LSTM_c2048_r512 (6.6M) Fig. 6 . 2000 context dependent phone HMM states. 4. CONCLUSION As far as we kno w , this paper presents the first application of LSTM networks in a large vocabulary speech recognition task. T o address the scalability issue of the LSTMs to lar ge networks with lar ge num- ber of output units, we introduce two architecutures that make more effecti ve use of model parameters than the standard LSTM architec- ture. One of the proposed architectures introduces a recurrent projec- tion layer between the LSTM layer (which itself has no recursion) and the output layer . The other introduces another non-recurrent projection layer to increase the projection layer size without adding more recurrent connections and this decoupling provides more flex- ibility . W e show that the proposed architectures improve the perfor- mance of the LSTM networks significantly o ver the standard LSTM. W e also show that the proposed LSTM architectures gi ve better per- formance than DNNs on a large vocabulary speech recognition task with a large number of output states. Training LSTM networks on a single multi-core machine does not scale well to larger networks. W e will inv estigate GPU- and distributed CPU-implementations similar to [14] to address that. 1 2 3 4 5 6 7 8 9 10 Number of Training Frames (x billion) 11.5 12.0 12.5 13.0 13.5 14.0 14.5 15.0 15.5 WER (%) DNN_10w5_6_704_lr256 (5.2M) DNN_16w5_6_704_lr256 (5.6M) DNN_10w5_6_480 (5.3M) DNN_10w5_6_1024_lr256 (8.2M) DNN_16w5_6_1024_lr256 (8.5M) LSTM_c512 (5.2M) LSTM_c1024_r256 (3.5M) LSTM_c2048_r256 (5M) LSTM_c2048_r512 (9.7M) LSTM_c2048_r256_p256 (7.6M) Fig. 7 . 8000 context dependent phone HMM states. 5. REFERENCES [1] Y oshua Bengio, Patrice Simard, and Paolo Frasconi, “Learn- ing long-term dependencies with gradient descent is difficult, ” Neural Networks, IEEE T ransactions on , vol. 5, no. 2, pp. 157– 166, 1994. [2] Sepp Hochreiter and J ¨ urgen Schmidhuber, “Long short-term memory , ” Neural Computation , vol. 9, no. 8, pp. 1735–1780, Nov . 1997. [3] Felix A. Gers, J ¨ urgen Schmidhuber, and Fred Cummins, “Learning to for get: Continual prediction with LSTM, ” Neural Computation , vol. 12, no. 10, pp. 2451–2471, 2000. [4] Felix A. Gers, Nicol N. Schraudolph, and J ¨ urgen Schmidhu- ber , “Learning precise timing with LSTM recurrent networks, ” Journal of Machine Learning Resear ch , vol. 3, pp. 115–143, Mar . 2003. [5] Felix A. Gers and J ¨ urgen Schmidhuber, “LSTM recurrent networks learn simple context free and context sensitive lan- guages, ” IEEE T ransactions on Neural Networks , vol. 12, no. 6, pp. 1333–1340, 2001. [6] Mike Schuster and Kuldip K. Paliwal, “Bidirectional recurrent neural networks, ” Signal Pr ocessing, IEEE T ransactions on , vol. 45, no. 11, pp. 2673–2681, 1997. [7] Alex Graves and J ¨ urgen Schmidhuber , “Frame wise phoneme classification with bidirectional LSTM and other neural net- work architectures, ” Neural Networks , vol. 12, pp. 5–6, 2005. [8] Alex Grav es, Marcus Liwicki, Santiago Fernandez, Roman Bertolami, Horst Bunke, and J ¨ urgen Schmidhuber , “ A nov el connectionist system for unconstrained handwriting recogni- tion, ” P attern Analysis and Machine Intelligence, IEEE T rans- actions on , v ol. 31, no. 5, pp. 855–868, 2009. [9] Abdel Rahman Mohamed, Geor ge E. Dahl, and Geoffre y E. Hinton, “ Acoustic modeling using deep belief networks, ” IEEE T ransactions on Audio, Speech & Language Pr ocessing , vol. 20, no. 1, pp. 14–22, 2012. [10] George E. Dahl, Dong Y u, Li Deng, and Alex Acero, “Context-dependent pre-trained deep neural networks for large-v ocabulary speech recognition, ” IEEE T ransactions on Audio, Speech & Language Processing , v ol. 20, no. 1, pp. 30– 42, Jan. 2012. [11] Navdeep Jaitly , Patrick Nguyen, Andrew Senior, and V incent V anhoucke, “ Application of pretrained deep neural networks to large vocab ulary speech recognition, ” in Pr oceedings of IN- TERSPEECH , 2012. [12] Alex Graves, Abdel-rahman Mohamed, and Geoffrey Hinton, “Speech recognition with deep recurrent neural networks, ” in Pr oceedings of ICASSP , 2013. [13] T om ´ a ˇ s Mikolo v , Martin Karafi ´ at, Luk ´ a ˇ s Bur get, Jan ˇ Cernock ´ y, and Sanjee v Khudanpur , “Recurrent neural netw ork based lan- guage model, ” in Pr oceedings of INTERSPEECH . 2010, vol. 2010, pp. 1045–1048, International Speech Communication Association. [14] Jeffre y Dean, Greg Corrado, Rajat Monga, Kai Chen, Matthieu Devin, Quoc V . Le, Mark Z. Mao, Marc’Aurelio Ranzato, An- drew W . Senior, Paul A. Tuck er, Ke Y ang, and Andrew Y . Ng, “Large scale distributed deep networks., ” in NIPS , 2012, pp. 1232–1240. [15] Ga ¨ el Guennebaud, Beno ˆ ıt Jacob, et al., “Eigen v3, ” http://eigen.tuxfamily .org, 2010. [16] Ronald J. W illiams and Jing Peng, “ An ef ficient gradient-based algorithm for online training of recurrent netw ork trajectories, ” Neural Computation , vol. 2, pp. 490–501, 1990. [17] T .N. Sainath, B. Kingsb ury , V . Sindhwani, E. Arisoy , and B. Ramabhadran, “Lo w-rank matrix factorization for deep neu- ral network training with high-dimensional output targets, ” in Pr oc. ICASSP , 2013.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment