스캐터링 모멘트를 이용한 오디오 텍스처 합성
본 논문은 복소 웨이브렛 필터뱅크와 절댓값 모듈레이션 연산을 반복 적용해 얻는 스캐터링 변환의 기대값, 즉 스캐터링 모멘트를 이용해 오디오 텍스처를 효율적으로 합성하는 방법을 제안한다. 단일 실현으로부터 저분산 추정이 가능하며, 1차·2차 모멘트와 주파수 전이 모멘트만으로도 기존 방법보다 훨씬 적은 계수(≈400개)만으로 높은 지각 품질을 달성한다.
저자: Joan Bruna, Stephane Mallat
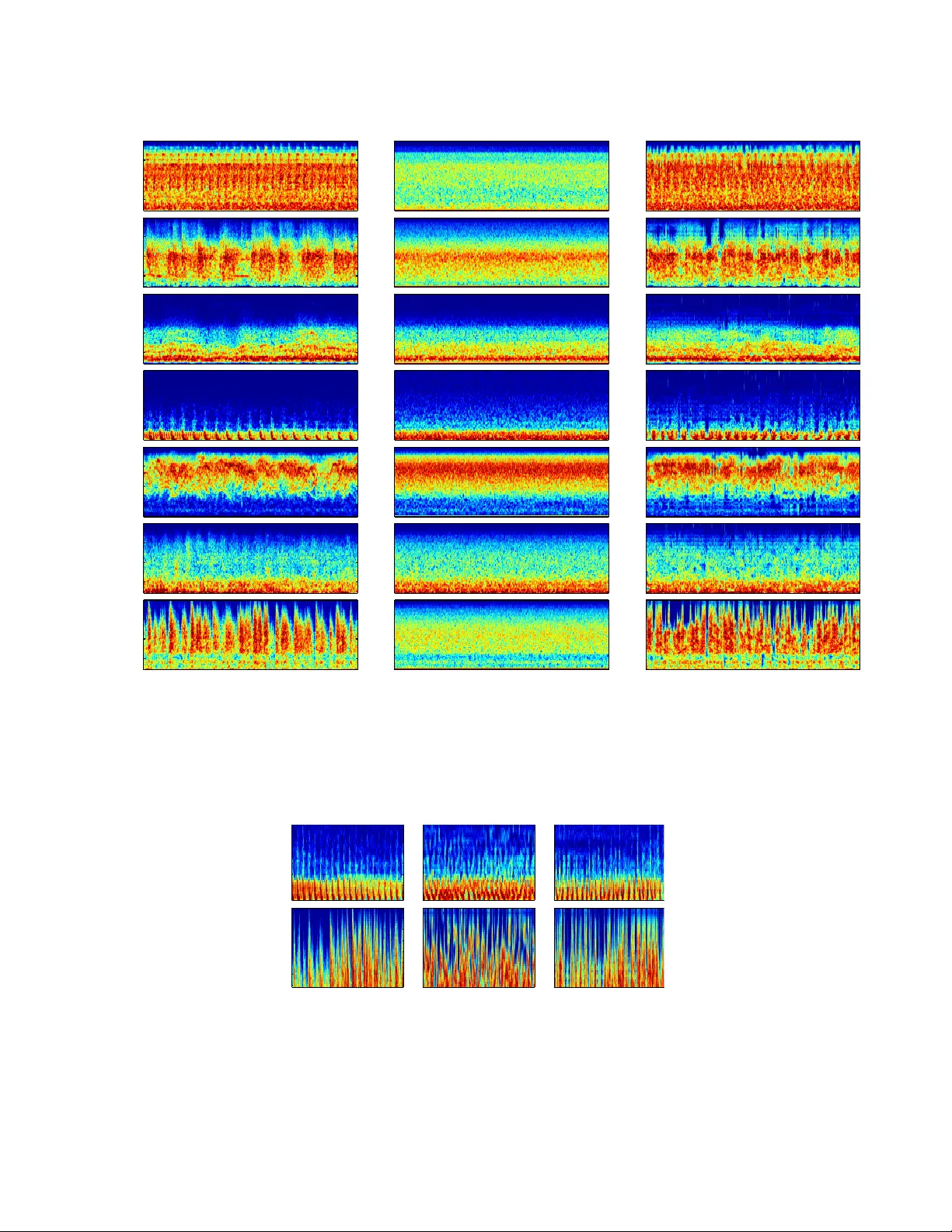
본 논문은 오디오 텍스처 합성을 위한 새로운 프레임워크를 제시한다. 핵심 아이디어는 복소 웨이브렛 필터뱅크와 절댓값 모듈레이션 연산을 반복 적용해 얻는 스캐터링 변환의 기대값, 즉 스캐터링 모멘트를 텍스처의 통계적 표현으로 사용하는 것이다. 스캐터링 변환은 신호 X(t)를 여러 스케일의 복소 웨이브렛 ψλ 로 컨볼루션한 뒤 절댓값을 취해 진폭 정보를 추출하고, 이를 다시 동일한 구조의 웨이브렛으로 처리하는 다단계 비선형 연산으로 정의된다.
1차 스캐터링 모멘트 S_X(λ)=E
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기