Audio Texture Synthesis with Scattering Moments
We introduce an audio texture synthesis algorithm based on scattering moments. A scattering transform is computed by iteratively decomposing a signal with complex wavelet filter banks and computing their amplitude envelop. Scattering moments provide …
Authors: Joan Bruna, Stephane Mallat
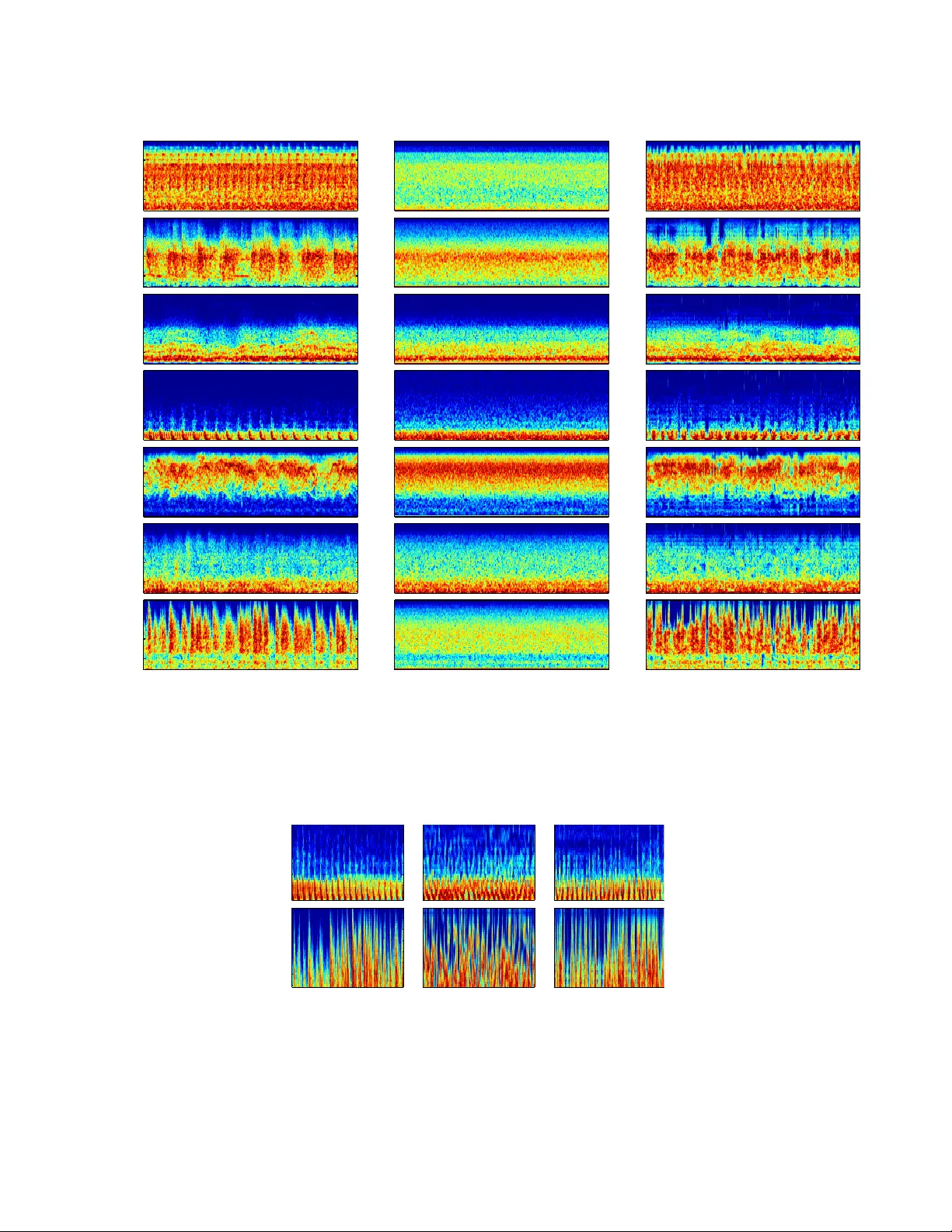
A UDIO TEXTURE SYNTHESIS WITH SCA TTERING MOMENTS J oan Bruna Ne w Y ork Unive rsity Courant Institute Ne w Y ork, NY St ´ ephane Mallat Ecole Noramle Sup ´ erieure Computer Science Department Paris, France ABSTRA CT W e introdu ce an audio texture synth esis algo rithm based on scattering m oments. A scatter ing transform is computed b y iterativ ely decomposing a s ignal with comp lex wavelet filter banks and computin g their amplitude env elop. Scatterin g mo - ments provide general representations of stationar y pro cesses computed as expected values of scatterin g c oefficients. They are estimated with low variance estimators fro m single real- izations. Audio signals ha v ing prescribed scattering moments are synthesized with a gradient descent algorith ms. Audio synthesis examp les show that scattering repr esentation p ro- vide good synthe sis of audio textures w ith mu ch f ewer coef - ficients than the state of the art. Index T erms — Audio synthesis, scatterin g moments, wa velets, te xture. 1. INTR ODUCTION The representation of a non-Gaussian stationary p rocess re- mains a fu ndamen tal issue o f prob ability and statistics. Sig- nal pro cessing faces many such issues, in p articular for a udi- tory and image textures, which can b e modele d as r ealiza- tions o f high ly n on-Gaussian processes. A ran dom vector X ∈ R N can be r epresented by a vector o f g eneralized m o- ments Φ X = { E ( φ n ( X ) } n which project the distribution of X over multiple functio ns φ n ( x ) with x ∈ R N . Rand om signal synthesis can then be perform ed by sampling the max- imum entropy distribution, which is a Boltzmann distribu- tion whose generalized moments are specified by Φ X . For most sign al proce ssing ap plications, one needs to estimate E ( φ n ( X ) from a si ngle realization of X , by replacing the ex- pected value with a sp atial or tim e av erage. W e concentr ate on on audio t exture s ynthesis, which is an impor tant application. The inform ation loss of the representatio n can be checked by ev alu ating the perceptual quality of s ynthesized signals. Second ord er moments lose essential percep tual informa- tion in audio and image sign als be cause they provid e no in- formation o n non-Gau ssian behavior . High o rder moments This work is supporte d by the ANR 10-B LAN-0126 and ERC In vari ant- Class 320959 grants. are ra rely used because the ir estimation from a single re al- ization has a variance which is too large. Representations based on g eneralized mom ents have been propo sed to repr e- sent an d synthesize a udio and im age textures, o ften based on histograms of non- linear tran sformation s of the sign al [1, 2]. Simoncelli and McDermo tt have obtain ed par ticularly effi- cient results from c ovariance measu rements at the ou tput of multistage filter ban ks [3]. In the following w e pro pose an audio texture r epresentation and a synth esis algorith m based on scattering moments. Scattering transfor ms ha ve recently been introduce d [4, 5, 6, 7] to rep resent audio sign als an d images, while providing state of the art results fo r textur e discrimination, and genre recognition in aud io [6]. A scattering transform iterates o n co mplex wa velet transfor ms and modulu s oper- ators which compute their envelop. It has close re lations with psycho physical and phy siological mo dels [ 8, 9, 10]. For stationary processes, it estimates a vector of e xpected values called scattering m oments. This pap er shows that scattering mom ents pr ovide a co mpact rep resentation of sta- tionary proc esses, which encodes impor tant non-Gaussian proper ties arising f rom multiscale amplitude an d frequ ency modulatio ns. This is demonstra ted thro ugh audio synthesis. Section 2 reviews th e prop erties of scatter ing mo ments for auditory signals. An efficient au dio synthesis algorithm is described in Section 3. Section 4 gi ves synthesis results on natural audio textures. Computa tions can be reprodu ced with a software a vailable at www .di.ens.fr/data/softwar e/scatnet . Notations: b x ( ω ) = R x ( t ) exp( − iω t ) dt is the Fourier transform of x ( t ) . W e denote E ( X ) the expected value of a stationa ry pro cess X ( t ) at any t , and σ 2 ( X ) = E ( | X | 2 ) − E ( X ) 2 . 2. SCA TTERING MOMENTS A scattering tran sform character izes transient structures throug h hig h order coefficients which capture m odulatio n proper ties. They are compu ted by iterating on filter ban ks of complex w a velet filters. 2.1. W avelet Filter Bank A wav elet ψ ( t ) is a b and-pass filter . W e consider a comp lex wa velet with a qu adratur e phase, whose Fourier transfo rm sat- isfies b ψ ( ω ) ≈ 0 for ω < 0 . W e assume th at the center fre- quency of b ψ is 1 and tha t its band width is of the ord er o f Q − 1 . W avelet filters centered at the frequen cies λ = 2 j /Q are com - puted by dilating ψ : ψ λ ( t ) = λ ψ ( λ t ) and hence b ψ λ ( ω ) = b ψ ( λ − 1 ω ) . (1) W e d enote by Λ the index set o f λ = 2 j /Q over the sign al frequen cy s uppor t, and we impo se that these filters fully cover the positiv e frequencies ∀ ω > 0 , 1 − ǫ ≤ 1 2 X λ ∈ Λ | b ψ λ ( ω ) | 2 ≤ 1 . (2) for some ǫ < 1 . The wa velet tran sform of a rando m proc ess X ( t ) is W X = { X ⋆ ψ λ ( t ) } λ ∈ Λ . One can derive from (2) that the variance s atisfies σ 2 ( X )(1 − ǫ ) ≤ X λ ∈ Λ E ( | X ⋆ ψ λ | 2 ) ≤ σ 2 ( X ) . (3) 2.2. Scattering Moments Scattering mom ents pr ovide a repr esentation of stationary processes, with exp ected values of a non- linear operator, cal- culated by iterating over wavelet tran sforms and a m odulu s. First or der scatter ing coefficients are first order mo ments of wa velet coef ficient amplitudes: ∀ l a 1 ∈ Λ , S X ( λ ) = E ( | X ⋆ ψ λ | ) . The Q-factor Q 1 adjusts the frequen cy resolution of th ese wa velets. First order scatter ing moments provide no info r- mation on the time-variation of the scalogram | X ⋆ ψ λ 1 ( t ) | . I t av erages all audio mod ulations and transien t e vents, and thus lose perceptually important informatio n. Second order scattering momen ts recover infor mation on audio-m odulation s a nd transients by comp uting the wa velet coefficients of each | X ⋆ ψ λ 1 | , and their first ord er mo ment: ∀ λ 2 , S X ( λ 1 , λ 2 ) = E ( || X ⋆ ψ λ 1 | ⋆ ψ λ 2 | ) . These multiscale variations of each en velop | X ⋆ ψ j 1 | , specify the amplitude modulations of X ( t ) [6]. The second family of wa velets ψ j 2 typically have a Q -factor Q 2 = 1 to accurately measure the sharp transitions of amp litude mod ulations. Scat- tering c oefficients have a negligible am plitude for λ 2 > λ 1 because | X ⋆ ψ λ 1 | is then a regular env elop whose frequency support is be low λ 2 . Scattering coefficients ar e thus c omputed only for λ 2 < λ 1 . Applying m ore wavelet tra nsform envelops defin es scat- tering moments at any order m ≥ 1 : S X ( λ 1 , ..., λ m ) = E ( | | X ⋆ ψ λ 1 | ⋆ ... | ⋆ ψ λ m | ) . (4) By iterating on the inequality (3), one can verif y [4] tha t the Euclidean norm of scattering moments k S X k 2 = ∞ X m =1 X ( λ 1 ,...,λ m ) ∈ Λ m | S X ( λ 1 , ..., λ m ) | 2 . (5) satisfies k S X k 2 ≤ σ 2 ( X ) . Expected scattering coefficients are first moments of non- linear func tions X and thus depend u pon high or der mom ents of X [4]. But as opposed to high order mo ments, the scatter- ing representation is compu ted with wa velet transforms and modulu s operator s, which do no t amp lify th e variability of X . It results into low-v ar iance esti mators. Scattering moments are estimated by replacing the e x pec- tation with a time a verag ing ov er the s ignal support. Suppose that X ( t ) is defin ed for 0 ≤ t < N . W ith periodic borde r extensions, we compute empirical a verage s b S X ( λ 1 , ..., λ m ) = N − 1 N X t =1 | | X ⋆ ψ λ 1 | ⋆ ... | ⋆ ψ λ m ( t ) | . (6) For most audio textures, the energy of the scatter ing vec- tor k S X k 2 is co ncentrated over first a nd seco nd or der mo- ments [6]. W e thus only co mpute b S X ( λ 1 ) an d b S X ( λ 1 , λ 2 ) for 1 ≤ λ 1 = 2 j 1 /Q 1 ≤ N and 1 ≤ λ 2 = 2 j 2 /Q 2 < λ 1 . Scattering moments estimators have large variance at the low- est frequ encies because the w a velet co efficient amplitudes are highly correlated in time. These higher variance estimato rs are removed by k eeping only the frequ encies λ 1 and λ 2 above a fixed frequency N 0 . W e thus co mpute Q 1 log 2 ( N / N 0 ) first order scattering m oments and Q 1 Q 2 (log 2 N / N 0 ) 2 / 2 second order scattering moments. Scattering transfor ms have b een extended alon g the f re- quency v ar iables to capture frequency variability and provide transposition in variant representations [6]. T ransp ositions re- fer to translation s along a log fr equency variable. For au- dio synth esis, this frequ ency transformation will only be pe r- formed on first order co efficients. W e deno te γ = log 2 λ 1 , and define wavelets ¯ ψ ¯ λ ( γ ) having an octave band width of Q = 1 . Th e correspond ing wa velet tra nsform is thus co m- puted with con volutions along the log- frequen cy variable γ . The scalogram is no w considered a s a function o f γ for each fixed time t : F t ( γ ) = | X ⋆ ψ 2 γ ( t ) | . Second or der f requen cy scattering momen ts a re the first o rder moments of the wav elet coefficients o f F t ( γ ) comp uted along γ : S X ( λ 1 , ¯ λ 2 ) = E ( | F t ⋆ ¯ ψ ¯ λ 2 (log 2 λ 1 ) | ) , This expected value is estimated with a time a veraging b S X ( λ 1 , ¯ λ 2 ) = N − 1 N X t =1 | F t ⋆ ¯ ψ ¯ λ 2 (log 2 λ 1 ) | . (7) If K = Q 1 log 2 ( N / N 0 ) is the to tal num ber o f first order scat- tering mo ments, the numbe r o f second o rder frequ ency scat- tering coefficients is αK , where α is an oversampling con - stant which is set to 2 in our experiments. 3. SCA TTERING SYNTHESIS W e present a gradient descent algorithm on the scattering do- main to adjust scatter ing moments estimated from available observations. A maximum entro py distribution satisfying a set of mo- ment condition s is a Gib bs distribution defined by th e Boltz- mann theor em. Sampling this distribution is po ssible with the Metrop olis-Hastings a lgorithms but it is co mputation ally very expansive in hig h dimension . This algorithm is often ap- proxim ated with a gradient descent algo rithm. It is initialized with a Gau ssian white no ise realization , whose mo ments are progr essi vely ad justed by the gradien t descent [11, 1, 3]. Let Y ( t ) b e the realization o f an audito ry texture of N samples. A vector of first order and second order scattering moment estimators b S X is compu ted with (6 ). This vecto r may also include second order frequ ency scattering mo ments (7). T o synthesize a new audio si gnal X such that b S X = b S Y , we start with a realizatio n of white Gaussian noise X 0 . At each iteration n , we want to minimize E ( X ) = 1 2 k b S X n − b S Y k 2 . (8) A gradient descent computes X n +1 = X n − γ ∇ E ( X n ) = X n − γ ∂ b S X T n ( b S X n − b S Y ) , (9) where ∂ b S X n is the Jacobia n o f b S X with respect to X , ev al- uated at X n , an d γ is a gra dient step, wh ich is kept fixed at a sufficiently small value for the sake of simplicity . The m inimization o f (8) is a non-linear least squares prob- lem. The Le venberg-Marqu ardt Algorithm ( LMA) [ 12] sig- nificantly accelerates the co n vergence. It rep laces ∂ b S X T n in (9) by the pseudoinverse ∂ b S X † n = ( ∂ b S X T n ∂ b S X n ) − 1 ∂ b S X T n , which requires comp uting a pseudo in verse on e ach iteration. The LMA typically requir es 2 0 iteratio ns to r each a relati ve approx imation error o f 10 − 2 and 40 to re ach 10 − 4 , tested o n the collection of auditory textures described in next section. 4. NUMERICAL EXPERIMENTS The audio scattering synthesis algorithm is tested on a dataset of natur al sound textures of Mc Dermott and Simon celli, avail- able at [1 3]. It is a collectio n o f 15 sound textures, o f 7 sec- onds each, sampled at 20 KHz, thus including N ∼ 10 5 sam- ples. Our synthesis results are av a ilable at [14]. McDermott and Simoncelli [3] have constru cted an au- dio representation based on physiolo gical m odels of au dition. Similarly to a scattering transf orm, it uses two constant-Q filter ban ks. Th e first set of c ochlea filter s co nsists in 30 complex b andpass filter s. Their en velop is first compressed with a contractive nonlin earity and then redeco mposed with a new filter ban k. They extract a co llection of 1 500 coef - ficients, co mprising marginal m oments of each cochlea en - velop and their correspo nding mod ulation ban ds, as well as pairwise cross-correlations across different cochlea and mod- ulation bands. In [15], the autho rs used a similar m odel to produ ce a texture representatio n wit h about 800 coefficients. Scattering audio synthesis is perfor med with much fewer coefficients. W ith Q 1 = 4 and N 0 = 2 2 there are Q 1 log 2 N / N 0 = 46 first order moments, Q 1 Q 2 (log 2 N / N 0 ) 2 / 2 = 266 sec- ond order momen ts and 2 · 46 = 92 fr equency scattering moments The total rep resentation thus has 402 coefficients. Figure 1 shows the scalogram o f signals recovered from first o rder mo ments o nly o r first and second ord er mom ents. Reconstruction s from first o rder mom ents are essentially re - alizations of Gaussian processes. Th ey d o n ot captu re the transient and imp ulsiv e structures o f the textures, such as the hammer o r the applau se. When second order scattering mo- ments are included, the reconstructed textur es co ntain these highly non -Gaussian pheno mena, wh ich p roduce hig hly re- alistic syn thesized soun ds. Scattering moments have the ability to cap ture pro cesses with irregular spectra, such as the jackhammer, as well as wideband phenome na s uch as fire cracking or applause. Figure 2 shows th at frequ ency scatterin g moments cor- relate and thus synchroniz e the amplitude variations acro ss frequen cy b ands. This is necessary to accurately reprodu ce transient structures in textures. Th e synthesis of wide-band textures can be further improved by comb ining scattering mo- ments compu ted with dyad ic wa velets having Q 1 = 1 . It adds 120 coefficients which fu rther co nstraint the fr equency inter- ferences created by time varying mod ulations. 5. CONCLUSIONS A texture au dio synthesis is perfo rmed with a gradient descent algorithm which p rogressively ad justs the scattering mom ents of a signal. Good p erceptual recon structions are ob tained with fewer coef ficien ts than state of the art algorithms. First and second order scattering momen ts are thus effi- cient texture d escriptors; on the on e han d, they are sufficiently informa ti ve s o tha t realizations with similar co efficients ha ve good p erceptual similar ity . On th e other han d, they are con - sistent: r ealizations of the same process ( hence perceptu ally similar) ha ve similar scatterin g representations, as opposed to high order moments. 20 40 60 20 40 60 20 40 60 20 40 60 20 40 60 20 40 60 20 40 60 Fig. 1 . Each image the scalog ram of an audio recor ding: time along the ho rizontal axis and log-f requen cy u p to 10 KHz along the vertical axis. Left column: origin al audio te xtures from [13]. Mid dle colu mn: Reconstru ction f rom 1st order time scatter ing moments Right co lumn: r econstructio n from 1st and 2nd ord er time scatterin g mome nts. The sounds are produ ced (from to to bottom) by jackhammer, applause, wind, helicopter, spa rrows, train, rusting p aper . 4 0 4 5 5 0 5 5 6 0 6 5 7 0 5 1 0 1 5 2 0 2 5 3 0 3 5 Fig. 2 . Impact of frequency scatterin g moments. Left column: origin al signals. Mid dle column: synthesis from first and second or der tim e scattering moments. Right c olumn: synthe sis ob tained by ad ding fr equency scattering momen ts. Observe how without frequen cy scattering, the subb ands tend to d ecorrelate , which p revents syn thesizing impulsive phe nomena . The sounds are produced by a helicopter and rusting paper . More examples a vailable at cims.nyu. edu/ ∼ bru na . 6. REFERENCES [1] J. Portilla an d E . Simoncelli, “ A Parametric T exture Model based on Joint Statistics of Complex W avelet Co- efficients, ” IJCV , 2000. [2] P . Hu ber and B. Kleiner , “Statistical Method s for in ves- tigating pha se relations in stochastic processes, ” IE EE T rans on Audio and Electr oa coustics , 1976. [3] J. Mc Dermott and E. Sim oncelli, “Soun d T extur e Per- ception via statistics of the auditor y peripher y: Eviden ce from Soun d Synth esis, ” Neur on , 2011. [4] S. Mallat, “ Group In variant Scattering, ” Comm unica- tions in Pur e and Applied Mathematics , 2012. [5] J. Bruna and S. Mallat, “I n variant scatterin g co n volution networks, ” IEEE tr ansactions of P AMI , 2012. [6] J. Anden and S. Mallat, “De ep scattering spectrum , ” IEEE transactions of Signal Pr o cessing , 2013 . [7] L. Sifre and S. Mallat, “Combin ed Scattering fo r Rota - tion In variant T exture Analysis, ” CVPR , 2013 . [8] T . Chi, P . Ru, and S. Shamma, “Multiresolutio n spec- trotempo ral analysis of co mplex sounds, ” J . Acoust. Soc. Am. , vol. 118, no. 2, pp. 887–906, 2005. [9] T . Dau, B. Kollmeier , an d A. K o hlrausch, “Mode ling auditory processing of amplitud e m odulation . i. detec- tion and masking with narrow-band carriers, ” J . Acoust. Soc. Am. , vol. 102, no. 5, pp. 2892–29 05, 1997. [10] M. Slaney and R. L yon, V isual repr esentatio ns of spee ch signals , chapter On the impor tance of time–a tem poral representatio n of sound, pp. 95–116, M. Coo ke, S. Beet and M. Crawford (Eds.) John W iley and Sons, 1993. [11] S. Zhu , Y . W u , an d D. Mumfor d, “Minimax En- tropy Principle and Its Application to T extur e Mo del- ing, ” Neural Computation , 1997. [12] D. Mar quard t, “ An algor ithm f or least-sq uares estima- tion of n onlinear param eters, ” SIAM Journal on Applied Mathematics , 1963 . [13] J. McDerm ott, “http://www .cns.nyu.e du/ ∼ jhm /, ” . [14] J. Bruna, “http://cims.nyu.edu / ∼ bruna/, ” . [15] R. McW alter and T . Dau, “ Analysis of the auditory sys- tem via Soun d T exture Sy nthesis, ” Interna tional Con- fer en ce on Acoustics , 2013 .
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment