대규모 엔터티 주제 모델링을 위한 확률적 LDA 접근법
위키피디아 문서를 토픽으로 삼아 콘텐츠 단어와 엔터티 멘션을 동시에 생성하는 확장된 LDA 모델을 제안한다. 수백만 개의 토픽과 어휘를 다루기 위해 희소성 기반 변분 추론과 위키피디아 링크 그래프를 활용한 병렬 Gibbs 샘플러를 설계하고, MapReduce 파이프라인으로 분산 학습을 구현한다. AIDA‑CoNLL 데이터셋에서 기존 방법들을 앞서는 정확도와 확장성을 입증하였다.
저자: Neil Houlsby, Massimiliano Ciaramita
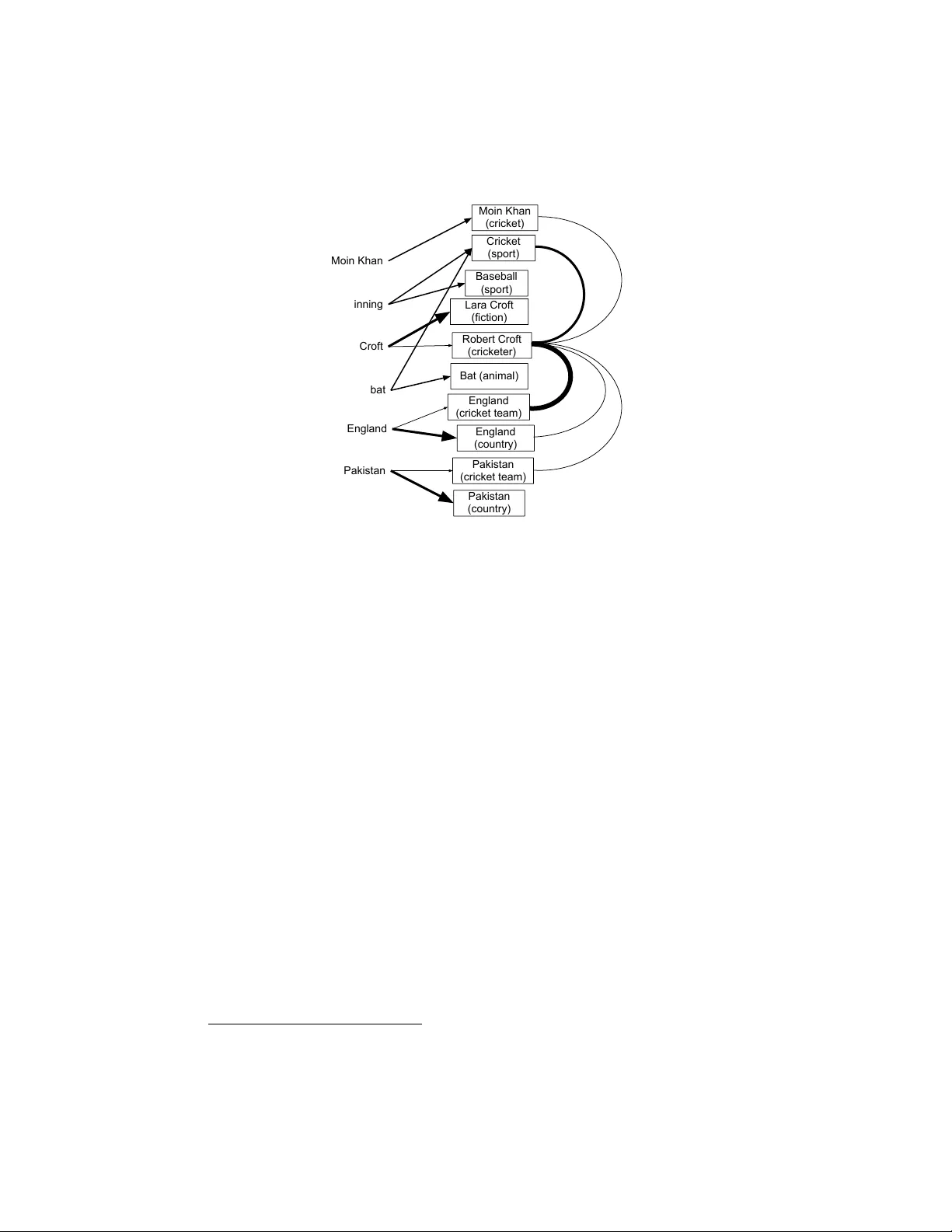
본 논문은 엔터티 디스앰버리게이션을 확률적 토픽 모델링에 통합한 새로운 접근법을 제시한다. 기존 LDA는 문서 내 단어들의 토픽을 추정하지만, 엔터티와 같은 명시적 멘션을 다루지는 못한다. 저자들은 각 토픽을 위키피디아 기사와 일대일 매핑하고, 토픽이 콘텐츠 단어와 엔터티 멘션 두 종류 모두를 생성하도록 모델을 확장하였다. 이를 통해 멘션 주변의 일반 텍스트가 디스앰버리게이션에 활용될 수 있다.
모델의 구조는 다음과 같다. 각 토픽 k에 대해 두 개의 다항분포 φᶜ_k(콘텐츠 단어)와 φᵐ_k(멘션)가 존재하고, 각 문서 d는 토픽 혼합 θ_d를 가진다. 문서 내 각 단어와 멘션은 θ_d에 따라 토픽 z를 샘플링하고, 이후 해당 토픽의 φ에 의해 실제 단어 혹은 멘션이 생성된다. 토픽 수 K는 약 4백만 개로, 어휘 크기 V도 수백만에 달한다.
학습 과정에서 저자들은 변분 베이즈 추론을 사용해 전역 파라미터 φ의 사후를 Dirichlet(λ) 형태로 근사한다. λ는 대부분이 최소값 β에 가까운 희소 벡터이며, 이를 중심화된 λ̂ = λ – β 로 저장해 메모리 사용을 크게 절감한다. 로컬 변수(z, θ)는 Gibbs 샘플링으로 추정한다. 특히, 위키피디아 링크 그래프를 활용해 토픽 간 연결 강도를 사전 확률로 사용함으로써, 샘플링 단계에서 구조적 일관성을 강화한다. 이 그래프‑가이드 샘플링은 멘션이 다의어일 때 주변 토픽과의 연관성을 반영해 정확도를 높인다.
대규모 데이터와 모델을 효율적으로 학습하기 위해 저자들은 MapReduce 기반 파이프라인을 설계했다. 데이터 전처리 단계에서 각 문서는 콘텐츠 단어와 멘션, 그리고 필요한 메타데이터를 포함한 자체 패킷으로 직렬화된다. Map 단계에서는 각 워커가 해당 패킷을 받아 로컬 Gibbs 샘플링을 수행하고, 업데이트된 파라미터를 Reduce 단계에서 집계한다. 전역 파라미터는 배치 단위로 중앙 저장소에 병합되며, 비동기식 파라미터 서버 구조를 사용하지 않아 통신 오버헤드를 최소화한다. 또한, 파라미터를 필요할 때만 로드하는 ‘온디맨드’ 방식으로 메모리 사용량을 제한한다.
실험에서는 AIDA‑CoNLL 데이터셋을 사용해 엔터티 링크 정확도를 평가하였다. 제안 모델은 기존 최첨단 방법들보다 높은 F1 점수를 기록했으며, 특히 토픽 수를 4백만 개까지 확장했음에도 학습 시간은 수일 내에 수렴하고 메모리 사용량은 30~40 GB 수준에 머물렀다. 이는 희소 변분 파라미터와 그래프‑가이드 샘플링, 그리고 효율적인 MapReduce 파이프라인이 대규모 토픽 모델링을 실용적인 수준으로 끌어올렸음을 보여준다.
논문의 주요 기여는 다음과 같다. (1) 위키피디아 기반의 해석 가능한 토픽 정의, (2) 콘텐츠와 멘션을 동시에 모델링하는 확장 LDA, (3) 희소 변분 파라미터와 그래프‑가이드 Gibbs 샘플링을 결합한 효율적인 추론 알고리즘, (4) MapReduce를 활용한 메모리·연산 효율성을 갖춘 분산 학습 파이프라인, (5) 대규모 토픽 수와 데이터에 대한 확장성을 입증한 실험 결과. 이러한 기여는 엔터티 디스앰버리게이션뿐 아니라 대규모 지식 기반을 활용한 다양한 자연어 처리 작업에 적용 가능성을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기