Scalable Probabilistic Entity-Topic Modeling
We present an LDA approach to entity disambiguation. Each topic is associated with a Wikipedia article and topics generate either content words or entity mentions. Training such models is challenging because of the topic and vocabulary size, both in …
Authors: Neil Houlsby, Massimiliano Ciaramita
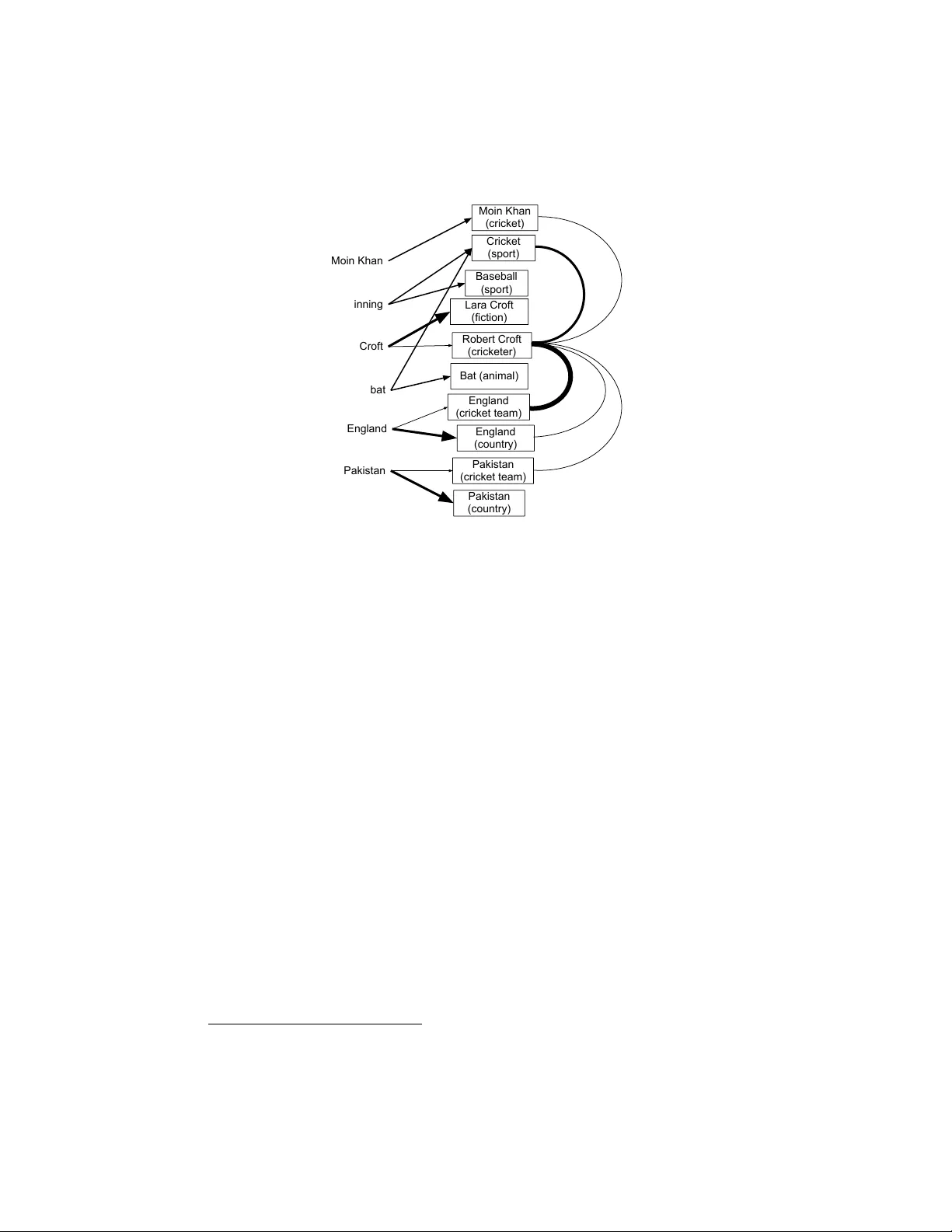
Scalable Probabilistic Entity-T opic Modeling Neil Houlsby ∗ Department of Engineering Uni versity of Cambridge, UK nmth2@cam.ac.uk Massimiliano Ciaramita Google Research Z ¨ urich, Switzerland massi@google.com September 3, 2013 Abstract W e present an LD A approach to entity disambiguation. Each topic is asso- ciated with a W ikipedia article and topics generate either content words or entity mentions. T raining such models is challenging because of the topic and v ocabulary size, both in the millions. W e tackle these problems using a nov el distributed infer- ence and representation frame work based on a parallel Gibbs sampler guided by the W ikipedia link graph, and pipelines of MapReduce allo wing f ast and memory- frugal processing of large datasets. W e report state-of-the-art performance on a public dataset. 1 Intr oduction Popular data-driv en unsupervised learning techniques such as topic modeling can re- veal useful structures in document collections. Howe ver , they yield no inherent in- terpr etability in the structures revealed. The interpretation is often left to a post-hoc inspection of the output or parameters of the learned model. In recent years an in- creasing amount of work has focused on the task of annotating phrases, also known as mentions , with unambiguous identifiers, referring to topics , concepts or entities , drawn from large repositories such as Wikipedia. Mapping text to unambiguous ref- erences provides a first scalable handle on long-standing problems such as language polysemy and synonymy , and more generally on the task of semantic gr ounding for language understanding. Resources such as W ikipedia, Freebase and Y A GO provide enough coverage to support the in vestig ation of W eb-scale applications such search results clustering [29]. By using such a notion of topic one gains the advantage ov er pure data-driven clustering, in that the topics ha ve an identifiable transparent semantics, be it a person or location, an event such as earthquakes or the “financial crisis of 2007-2008”, or more abstract concepts such as friendship, e xpressionism etc. Hence, one not only gets human-interpretable insights into the documents directly from the model, but also ∗ W ork carried out during an internship at Google. 1 from a ‘grounded interpretation’ which allows the system’ s output to be interfaced with downstream systems or structured knowledge bases for further inference. The discov ery of such topics in documents is known as entity annotation. The task of annotating entities in documents typically in volv es two phases. First, in a se gmentation step , entity mentions are identified. Secondly , in the disambiguation or linking step, the mention phrases are assigned one Wikipedia identifier (alternati vely from Freebase, Y AGO etc.). In this paper we focus upon the latter task which is chal- lenging due to the enormous space of possible entities that mentions could refer to. Thus, we assume that the segmentation step has already been performed, for example via pre-processing the text with a named entity tagger . W e then take a probabilistic topic modeling approach to the mention disambiguation/linking task. Probabilistic topic models, such as Latent Dirichlet Allocation (LDA) [2], although they do not normally address the interpretability issue, provide a principled, flexible and extensible frame work for modeling latent structure in high-dimensional data. W e propose an approach, based upon LD A, to model W ikipedia topics in documents. Each topic is associated with a W ikipedia article and can generate either content words or explicit entity mentions. Inference in such a model is challenging because of the topic and vocabulary size, both in the millions; furthermore, training and applications require the ability to process very lar ge datasets. T o perform inference at this scale we propose a solution based on stochastic vari- ational inference (SVI) and distributed learning. W e build upon the hybrid infer - ence scheme of [23] which combines document-lev el Gibbs sampling with variational Bayesian learning of the global topics, resulting in an online algorithm that yields parameter-sparsity and a manageable resource overhead. W e propose a ne w learn- ing framework that combines online inference with parallelization, whilst a v oiding the complexity of asynchronous training architectures. The framew ork uses a nov el, conceptually simple, MapReduce pipeline for learning; all data necessary for infer- ence (documents, model, metadata) is serialized via join operations so that each doc- ument defines a self-contained packet for inference purposes. Additionally , to better identify document-lev el consistent topic assignments, local inference is guided by the W ikipedia link graph. The original contributions of this w ork include: 1. A large scale topic modeling approach to the entity disambiguation task that can handle millions of topics as necessary . 2. A hybrid inference scheme that exploits the advantages of both stochastic in- ference and distributed processing to achiev e computational and statistical effi- ciency . 3. A fast Gibbs sampler that exploits model sparsity and incorporates knowledge from the W ikipedia graph directly . 4. A novel, simple, processing pipeline that yields resource efficienc y and f ast pro- cessing that can be applied to other problems in v olving very lar ge models. 5. W e report state-of-the-art results in terms of scalability of LD A models and in disambiguation accuracy on the Aida-CoNLL dataset [12]. 2 Moin Khan (cricket) Robert Croft (cricketer) Lara Croft (fiction) Bat (animal) Baseball (sport) Cricket (sport) England (country) England (cricket team) Pakistan (country) Pakistan (cricket team) Moin Khan inning Croft bat England Pakistan Figure 1: Example of document-W ikipedia graph. The paper is or ganized as follo ws: Background on the problem and related work is discussed in the following section. Section 3 introduces our model. Section 4 describes the inference scheme, and Section 5 the distributed framework. Experimental setup and findings, are presented in Section 6. Follo w conclusions. 2 Related W ork Much recent work has focused on associating textual mentions with Wikipedia top- ics [20, 22, 16, 9, 12, 27, 11]. The task is kno wn as topic annotation , entity linking or entity disambiguation . Most of the proposed solutions exploit two sources of in- formation compiled from W ikipedia: the link graph, used to infer similarity measures between topics, and anchor text, to estimate how likely a string is to refer to a giv en topic. Figure 1 illustrates the main intuitions behind most annotators’ designs. The figure depicts a fe w words and names from a ne ws article about cricket. Connections between strings and W ikipedia topics are represented by arrows whose line weight represents the likelihood of that string being used to mention the topic. In this example, a priori, it is more likely that “Croft” refers to the fictional character rather than the cricket player . Ho wev er , a similarity graph induced from W ikipedia 1 would reveal that the cricket player topic is actually densely connected to sev eral of the candidate topics on the page, those related to cricket (line weight represents again the connection strength). V irtually all topic annotators propose different ways of e xploiting these ingredients. A few topic model-inspired approaches have been proposed for modeling entities 1 The similarity measure is typically symmetric. 3 [24, 15, 11]. Early work [24] presents extensions to LD A to model both words and entities; ho we ver , they treat entities as strings , not linked to a kno wledge base. [15, 11] model a document as a collection of topic mentions, materializing as words or phrases, with topics being identified with Wikipedia articles. Kataria et al. in particular in v es- tigate the use of the W ikipedia category graph as the topology of a hierarchical topic model. The main dra wback of this proposal is its scalability both in terms of ef ficiency and topic co verage; the y prune W ikipedia to a subset of approximately 60k entities, re- porting training times of 2.6 days. Han & Sun carried out the largest e xperiment of this kind, training on 3M Wikipedia documents (and no graph), reporting training times of one week with a memory footprint of 20GB on one machine. Our goal is to provide full W ikipedia cov erage and high annotation accuracy with reasonable training/processing efficienc y . Scalable inference for topic models is the focus of much recent work. Broadly , the main approaches divide into two classes: those that parallelize inference e.g., via dis- tributed sampling methods [35, 31], and stochastic optimization methods [13]. Com- puting infrastructures like MapReduce [7] allow processing of huge amounts of data across thousands of machines. Unlike in previous work, we deal with an enormous topic space as well as large datasets and vocab ularies. V ery high dimensional mod- els, that can also grow as ne w data is presented, impose additional constraints such as a large memory footprint, limiting the resources available for distributed process- ing. One solution is to store a model in scalable distributed storage systems such as Bigtables [4], and allow individual processes to read the parameters needed to process subsets of the data from the global model. This approach allows individual work ers to send back model updates thus supporting asynchronous training. The do wnside is the cost of the w orker -model communication which can become prohibiti v e and difficult to optimize. Sophisticated asynchronous training strategies and/or dedicated control ar- chitectures are necessary to address these issues [31, 10, 19, 18]. Recent work on SVI provides an online alternativ e to parallelization [13], this approach can yield memory efficient inference and good empirical con vergence. In this paper we combine a sparse SVI approach with a distrib uted processing framework that gi v es us massi ve scalability with our models. 3 W ikipedia-T opic Modeling 3.1 Problem statement W e follow the task formulation, and ev aluation framework, of [12]. Given an input text where entity mentions ha ve been identified by a pre-processor , e.g., a named entity tagger , the goal of a system is to disambiguate (link) the entity mentions with respect to a W ikipedia page. Thus, gi ven a snippet of te xt such as “[Moin Khan] returns to lead [Pakistan]” where the NER tagger has identified the entity mentions “Moin Kahn” and “Pakistan”, the goal is to assign the cricketer id to the former, and the national cricket team id to the latter . 2 W e refer to the words outside entity mentions, e.g., “returns” and 2 Respectiv ely , en.wikipedia.org/wiki/Moin_Khan and http://en.wikipedia.org/ wiki/Pakistan_national_cricket_team . 4 “lead”, as content wor ds . 3.2 Notation Throughout the paper we use the following notation con ventions. 3.2.1 Data The training data consists of a collection of D documents, D = { w d } D d =1 . Note that this data can be any corpus of documents, e.g., news, web pages or W ikipedia itself. Each document is represented by a set of L c d content words w c d = { w c 1 , . . . , w c L c d } and L m d entity mentions w m d = { w m 1 , . . . , w m L m d } . Each word is either a ‘content word’ or an ‘entity mention’, these two types are dis- tinguished with a superscript w c , w m respectiv ely; when unambiguous, this superscript is dropped for readability . Content words consist of all words occurring in the English W ikipedia articles. Mentions are phrases (i.e., possibly consisting of sev eral words) that can be used to refer directly to particular entities e.g. “JFK Airport”, “Boeing 747”. Mention phrases are collected from W ikipedia titles, redirect pages and anchor text of links to other Wikipedia pages. The v ocabularies of words and mentions hav e size V c , V m respectiv ely . More details on the data pre-processing step are provided in Section 6.1. 3.2.2 Parameters Associated with each document are two sets of latent variables, referred to as ‘local’ parameters because they model only the particular document in question. The first is the topic assignments for each content word in the document z c d = { z 1 , . . . , z L c d } , and the topic assignments for each entity mention z m d = { z 1 , . . . , z L m d } . Thus, content words and entity mentions are generated from the same topic space, each z i indicates which topic the word w i (content or mention) is assigned to, where the topic represents a single W ikipedia entity . For e xample, if w m i = “Bush”, then z i could label this word with the topic “George Bush Sn. ”, or “Geor ge Bush Jn. ”, or “bush (the shrub)” etc. The model must decide on the assignment based upon the context in which w m i is observed. The second type of local parameter is the document-topic distribution θ d . There is one such distribution per document, and it represents the topic mixture ov er the K possible topics that characterize the document. Formally , θ d is a parameter v ector for a K -dimensional multinomial distribution over the topics in document d . For example, in an article about The Ashes 3 , θ d would put lar ge mass upon topics such as “ Australian cricket team”, “bat (cricket)” and “Lords Cricket Ground”. Note that, although mention and content word’ s topic assignments are generated independently , conditioned on the the topic mixture θ d , the y become dependent when we marginalize out θ d , as explained in Section 4 in more detail. There are two vectors of ‘global’ parameters per topic, the ‘topic-word’ and ‘topic- mention’ distributions φ c k , φ m k respectiv ely . These distributions represent a probabilis- 3 http://en.wikipedia.org/wiki/The_Ashes . 5 d = 1. .. D α z dj θ d di w dj β ϕ k k =1. .. K β ϕ k c m c m z di j = 1. .. L d m i =1. .. L d c w c m Figure 2: LD A with content words (superscript c ) and mentions (superscript m ). tic ‘dictionary’ of content words/ mentions associated with the W ikipedia entity repre- sented by the topic. The content and mention distributions are essentially treated iden- tically , the only difference being that they are distributions ov er different dictionaries of words. Therefore, for clarity we omit the superscript and the follo wing discussion applies to both types. For , each topic k , φ k is the parameter vector of a multinomial distribution ov er the words, and will put high mass on words associated with the en- tity represented by topic k . Because each topic corresponds to a W ikipedia entity , the number of topic-word distributions, K , is large ( ≈ 4 · 10 6 ); this provides additional computational challenges not normally encountered by LD A models. 3.2.3 V ariational Parameters When training the probabilistic model, we learn the topic distributions φ k from the training data D ; again, note that training is unsupervised and D is any collection of documents. Rather than learn a fixed set of topic distributions, we represent statistical uncertainty by learning a probability distribution over these global parameters. Using variational Bayesian inference (detailed in Section 4.2) we learn a Dirichlet distribution ov er each topic distrib ution, φ k ∼ Dir ( λ k ) , and learn the parameters of the Dirichlet, λ k ∈ R V , called the ‘variational parameters’. The set of all vectors λ k represents our model. Intuitively , each element λ kv gov erns the pre v alence of vocab ulary word v in topic k ; for example, for the topic “ Apple Inc. ” λ kv will be large for words such as “phone” and “tablet”. Most topics will only hav e a small subset of words from the large vocab ulary associated with them i.e. the topic distributions are sparse . Ho w- ev er , the model would not be robust if we ruled out all possibility of a ne w word being associated with a particular topic - this would correspond to having λ kv = 0 . There- fore, each variational parameter takes at least a small minimum v alue β (defined by a prior , details to follow). Due to the sparsity , most λ kv will take this minimum value β . Therefore, in practice, to save memory we represent the model using ‘centered’ variational parameters, ˆ λ kv = λ kv − β , most of which will take value zero, and need not be explicitly stored. 6 3.3 Latent Dirichlet Allocation The underlying framework for our model is based upon LDA, a Bayesian generativ e probabilistic model, commonly used to model text collections [2]. W e revie w the gen- erativ e process of our model below . The only difference to vanilla LD A is that both mentions and content words are generated (in the same manner), whereas LDA just considers words. 1. For each topic k (corresponding to a W ikipedia article), sample a distribution ov er the vocab ulary of words from a Dirichlet prior φ k ∼ Dir ( β ) . 2. For each document d sample a distribution o ver the topics from a Dirichlet prior θ d ∼ Dir ( α ) . 3. For each content word i in the document: (a) Sample a topic assignment from the multinomial: z i ∼ Multi ( θ d ) . (b) Sample the word from the corresponding topic’ s word distribution w c i ∼ Multi ( φ c z i ) . 4. For each mention phrase j in the document: (a) Sample a topic assignment from the multinomial: z j ∼ Multi ( θ d ) . (b) Sample the word from the corresponding topic’ s mention distrib ution w m j ∼ Multi ( φ m z j ) . Since topics are identified with W ikipedia articles, we can use the topic assignments to annotate entity mentions. α, β are scalar hyperparameters for the symmetric Dirichlet priors; the y may be interpreted as topic and word ‘pseudo-counts’ respectiv ely . By setting them greater than zero, we allow some residual probability that any word can be assigned to any topic during training. Documents can be seen as referring to topics either with content words, e.g., the topic “Barack Obama” is likely to be rele vant in a document mentioning words like “election” “2012”, “debate” and “U.S. ”, but also via explicit mentions of the entity names such as “President Obama” or “the 44th President of the United States”. It is im- portant to notice that mentions, although to a less degree than words, can be highly am- biguous; e.g., there at least se v en dif ferent “Michael Jordan”s in the English W ikipedia – including two basketball players. Mentions in text can be detected by running a named entity tagger on the te xt, or by heuristic means [11]. Here we adopt the former approach which is consistent with the ev aluation data used in our e xperiments. 4 Thus, a mention is a portion of te xt identified as an entity by a named entity tagger . 5 Howe ver , it is not known to which entity a particular mention refers and the resolu- tion of this ambiguity is the disambiguation/ linking task. Assuming the segmentation of the document is known, the simplest possible extension to LD A to include topic 4 Off-the-shelf taggers run typically in linear time with respect to the document length, thus do not add complexity . 5 W e disregard the label predicted by the tagger . 7 mentions, deriv ed from Link-LDA [8], is depicted in Figure 2, and the generative pro- cess corresponding to this graph is outlined abov e. Importantly , note that although the topics for each word type are sampled inde- pendently , their occurrence is coupled across words and mentions via the document’ s topic distribution θ d . During inference, topics appearing in a document that corre- spond to content w ords and those corresponding to mentions will influence each other . Therefore, during training, the parameters of the topics φ c k , φ m k can learn to capture word-mention co-occurrence. This enables our model to use the content words for disambiguating annotations of the mentions. This sets our approach apart from many current approaches to entity-disambiguation, which often ignore the content words. Because the locations of the mentions in a document are observed, the inference process is virtually identical to LD A. For ease of exposition, throughout the paper we present our framework using vanilla LD A, but extension to the model in Figure 2 is straightforward. 4 Infer ence and Learning The model is trained in an unsupervised manner on a corpus of unlabeled te xt, e.g. news articles, web-pages, or the W ikipedia articles themselves. Only during initialization of the model do we use supervised information from W ikipedia articles, which by construction of our model, are each labeled with a single topic. The English Wikipedia contains around 4M articles (topics). The vocab ulary size for content words and mention strings is, respectiv ely , around 2M and 10M. Given the vast potential size of the parameter space (topic-word, and topic-mention matrix), learning a sparse set of parameters is essential, and large corpora are required, necessi- tating a highly scalable framew ork. 4.1 Hybrid inference W e b uild upon a hybrid v ariational inference and Gibbs sampling framew ork [23]. The key adv antages of this method are statistical efficienc y from the online variational inference (the parameters are updated online, before waiting for all the data to be pro- cessed), and parameter sparsity from taking finite samples. Here we present the key equations, together with reformulations that yield a fast implementation of the sam- pler . For notational brevity we present the equations in this section for content word modeling only (i.e. omitting w m di , φ m k , β m nodes and the superscript c . from Figure 2); giv en the conditional independence assumptions the equations are easily extensible to the model in Figure 2. 4.2 V ariational Bayes The goal of learning in LD A is to infer the posterior distribution of topics φ k . When performing inference on documents we seek the ‘local’ topic assignments z d . W e in- tegrate/collapse out θ d , which is found to improve conv ergence [32]. Bayes rule is employed to compute the joint posterior 8 p ( z 1 , . . . , z D , φ 1 , . . . , φ K |D , α, β ) . This computation is not tractable, and hence ap- proximate variational Bayesian inference is used. V ariational inference in volv es ap- proximating a complex posterior distribution with a simpler one, q ( z 1 , . . . , z D , φ 1 , . . . , φ K ) . The latter is fitted to the true posterior so as to maximize the ‘Evidence Lower Bound’ (ELBO), a lower bound on the log marginal probability of the data p ( D | model ) [1]. W e use the following approximation to the posterior: p ( z 1 , . . . , z D , φ 1 , . . . , φ K |D , α, β ) ≈ q ( z 1 , . . . , z D ) q ( φ 1 , . . . , φ K ) = Y d q ( z d ) Y k q ( φ k ; λ k ) . (1) In (1) we assume statistical independence in the K topics and D topic-assignment vectors. Importantly , howe ver , independence is not assumed between the elements of each document’ s assignment vector , z d . The correlations between the topics are k ey to modeling topic consistency in the document, and the sparse computations that follo w . The ELBO is optimized with respect to the v ariational distrib utions q ( z 1 , . . . , z D ) , q ( φ 1 , . . . φ K ) in an alternating manner; one distribution is held fixed, while the other is optimized. The variational distribution over topics q ( φ k ; λ k ) is a Dirichlet distri- bution, with V − dimensional parameter vector λ k , one for each topic. The elements of the topic’ s v ariational parameter vector λ kv giv e the importance of word v in topic k . This can be observed from the mean of the Dirichlet, which is the multinomial: E φ k [ q ( φ k | λ k )] = p ( v | k ) = Multi ( λ kv / P k λ kv ) . The variational parameters λ k are optimized during learning, with { q ( z d ) } D d =1 fixed. The optimal variational parameters are giv en by: λ kv = β + D X d =1 L d X i =1 E q ( z d ) [ I z di = k I w di = v ] . (2) For bre vity we shall henceforth refer to these v ariational parameters simply as the ‘pa- rameters’ of the model. The optimal q ( z d ) gi v en { q ( φ k ; λ k ) } K k =1 is giv en by q ( z d ) ∝ exp { E q ( { z 1: D \ z d ) [log p ( z d | α ) p ( w d | z d , β )]) } , where q ( z 1: D \ z d ) is the variational distribution over all assignment vectors for all documents excluding d . Howe ver , in stead of parameterizing q ( z ) and performing variational inference we Gibbs sample from q ( z ) . This in volv es sequentially visiting each topic and sampling that topic conditioned on all other assignments and the other parameters of the (variational) posterior and w ord w i : z i ∼ p ( z i | z \ i , λ 1 , . . . , λ K , w i ) . The key adv antage of sampling the assignments is that one can retain sparsity . Most improbable word-topic assignments will not be sampled, the result being that many of the elements λ k remain constant. 4.3 Stochastic variational infer ence The key insight behind SVI is that one can update the model parameters λ k from just a subset of the data, B [14]. This enables one to discard the local variables (sampled 9 topic assignments) after each update is performed. Having performed inference on only a subset of the data, one achiev es only a noisy estimate of the full batch update step; b ut, provided that the noisy estimates are unbiased (averaging over the data sub-sampling process), one can guarantee conv er gence to an optima of the full batch solution. The correct update scheme is achieved by interpolating the noisy updated parameters from the subset with the old ones: λ kv = (1 − ρ ) λ old kv + ρ |D | |B | λ new kv (3) The scaling of the update by |D | / |B | ensures that the expected value of the update is equal to the batch update that uses all of the data, as required. The stochastic approach has two key advantages. Firstly , one does not have to wait until the entire dataset is observed before performing even a single update to the parameters (as in the batch approach, Eq. (2)), which yields improved con ver gence. Secondly , by discarding the local samples after each mini-batch B one can save vast amounts of memory . The requirement to store and communicate all of the local samples can be prohibitive in approaches based purely upon Gibbs sampling [35]. Section 5 details how the h ybrid scheme is incorporated into a distributed frame work. 4.4 Implementation of sparse sampling Beyond sparsity , when w orking with a very lar ge topic space it is important to perform efficient Gibbs sampling. For each word in each document (and for each sweep) we must sample z i from a K dimensional multinomial. Naive sampling would require O ( K ) operations. Howe ver , if one judiciously visits the high probability topics first, the number of computations can be vastly reduced, and any O ( K ) operations can be pre-computed. The sampling distribution for z i is giv en by (for brevity we omit the parameters): q ( z i = k | z \ i , w i = v ) ∝ ( α + N \ i k · ) exp { E q [log φ kv ] } , (4) exp { E q [log φ kv ] } = exp { Ψ( β + ˆ λ kv ) − Ψ( V β + ˆ λ k · ) } . ˆ λ kv = λ kv − β denotes ‘centered’ parameters, these are initialized to zero for most k , v . N \ i kv = P j 6 = i I [ z j = k, w j = v ] counts the number of assignments of topic k to word v in the document, and the subscript dots in N k · , ˆ λ k · are shorthand for the summation ov er inde x v , e.g. N \ i k · counts total occurrences of topic k in the document. Ψ() , denotes the Digamma function. T o av oid O ( K ) operations we decompose the sampling distribution as follo ws: q ( z i = k | z \ i , w i = v ) ∝ α exp { Ψ( β ) } κ 0 k | {z } µ ( d ) k + ακ kv κ 0 k | {z } µ ( v ) k + N \ i k exp { Ψ( β ) } κ 0 k | {z } µ ( c ) k + N \ i k κ kv κ 0 k | {z } µ ( c,v ) k (5) where κ kv = exp { Ψ( β + ˆ λ kv ) } − exp { Ψ( β ) } and κ 0 k = exp { Ψ( V β + ˆ λ · k ) } are transformed versions of the variational parameters. µ ( d ) k is dense, b ut it can be 10 precomputed. For each word µ ( v ) k has mass only for the topics for which ˆ κ kv 6 = 0 ; for each word in the document this can be precomputed. µ ( c ) k has mass only for currently observed topics in the document, i.e. those for which N \ i k 6 = 0 ; this term must be updated every time we sample, but it can be done incrementally . µ ( c,v ) k is non-zero only for topics which hav e non zero parameters and counts, but must be recomputed for e very update and ne w word. If most of the topic-mass is in the smaller components (which can be achieved via appropriate choices of α, β ), visiting these topics first when performing sampling will require much fewer than O ( K ) operations. T o compute the normalizing constant of (4) the rearrangement (5) is exploited with O ( K ) sums in the initialization, followed by sparse online updates. Algorithm 1 summarizes the processing of a single document. Algorithm 1 recei ves as input the document w d , initial topic assignment vector z (0) d , and transformed parameters κ 0 k , κ kv . Firstly , the components of the sampling distribu- tion in (5) that are independent of the topic counts µ ( d ) , µ ( v ) and their corresponding normalizing constants Z ( d ) , Z ( v ) are pre-computed (lines 2-3). This is the only stage at which the full dense K –dimensional vector µ ( d ) needs to be computed. Note that one only computes µ ( v ) k for the words in the current document, not for the entire v ocab- ulary . Next, at the beginning of each Gibbs sweep, s , the counts for each word-topic pair N kv and overall topic-counts N k · are computed from the initial vector of samples z (0) (lines 5-6). During each iteration of sampling the first operation is to subtract the current topic from the counts in line 8. No w that the topic count has changed, the two count-dependent components of the sampling distribution are computed (note that µ ( c ) k can be updated from the previous sample, but µ ( c,v ) k must be recomputed for the new word). The four components of the sampling distribution and their normalizing con- stants are summed in lines 13-14 and a single topic is drawn for the word at location i (line 15). The topic-word counter for the current sweep is updated in line 16, and if the topic has changed since the pre vious sweep the total topic count is updated accordingly (line 18). The ke y to ef ficient sampling from the multinomial in line 15 is to visit µ k in order { k ∈ µ ( c,v ) k , k ∈ µ ( c ) k , k ∈ µ ( v ) k , k ∈ µ ( d ) k } . A random schedule would require on av erage K/ 2 ev aluations of µ k . Ho wev er , if the distribution is skewed, with most of the mass in the sparse components, then much fe wer ev aluations are required if these topics are visited first. The degree of skewness in the distribution is gov erned by the initialization of the parameters, and the priors α, β . Because the latter act as pseudo- counts, setting them to small values f av ors sparsity . After completion of all of the Gibbs sweeps the topic-word counts from each sweep N ( s ) kv are averaged (discarding an initial burn in period of length B ) to yield updated parameter values ˆ λ d kv After completion of Algorithm 1, the parameter updates from the processing of each document ˆ λ d kv are interpolated with the current values on the shard using (3) to complete the local SVI procedure. In practice, we found a baseline local minibatch size |B | of one, and a small local update weight ρ loc already worked well. 11 Algorithm 1 Inner Gibbs Sampling Loop 1: input : ( w d , z (0) d , { κ kv } , { κ 0 k } ) 2: µ ( d ) k ← αe Ψ( β ) /κ 0 k , Z ( d ) ← P k µ ( d ) k 3: µ ( v ) k ← ακ kv /κ 0 k , Z ( v ) ← P k µ ( v ) k ∀ v ∈ D 4: for s ∈ 1 . . . S do Perform S Gibbs sweeps. 5: N ( s ) kv ← P L d i =1 I z ( s − 1) i = k ∧ I w ( s − 1) i = v Initial counts 6: N k · ← P v | N kv > 0 N ( s ) kv 7: for i ∈ 1 . . . L d do Loop o ver words. 8: N \ i k ← N k · − I z i = k Remo ve topic z i from counts. 9: µ ( c ) k ← N \ i k e Ψ( β ) /κ 0 k 10: Z ( c ) ← P k µ ( c ) k 11: µ ( c,v ) k ← N \ i k κ kw i /κ 0 k 12: Z ( c,v ) ← P k µ ( c,v ) k 13: µ k ← µ ( d ) k + µ ( v ) k + µ ( c ) k + µ ( c,v ) k 14: Z ← Z ( d ) + Z ( v ) + Z ( c ) + Z ( c,v ) 15: z ( s ) i ∼ Multi( { µ k / Z } K k =1 ) Sample topic. 16: N ( s ) w i z ( s ) i ← N s z ( s ) i w i + 1 Update counts. 17: if z ( s ) i 6 = z ( s − 1) i then 18: update N k · 19: end if 20: end for 21: end for 22: ˆ λ d kv ← 1 S − B P s>B N ( s ) kv Compute updated parameters. 23: return : ˆ λ d kv 12 4.5 Incorporating the graph Most non-probabilistic approaches to entity disambiguation achie ve good performance by using the Wikipedia in-link graph. W e exploit the W ikipedia-interpretability of the topics to readily include the graph into our sampler . Intuitiv ely , we would like to weight the probability of a topic, not only by the presence of other topics in the document, but by a measure of its consistency with these topics. This is in line with the Gibbs sampling approach where, by construction, all topics assignments, except the one being considered, are known. F or this purpose we introduce the following coherence score: coh( z k | w i ) = 1 |{ z d }| − 1 X k 0 ∈{ z d } \ i sim( z k , z k 0 ) . (6) where { z d } is the set of topics induced by assignment z d for document d , and sim( z k , z k 0 ) is the ‘Google similarity’ [5, 21] between the corresponding W ikipedia pages. W e include the coherence score by augmenting N \ i k in Eqn. 5 as N \ i k = ( N k · − I z i = k )coh( z k | w i ) . Thus, the coherence contributions is appropriately incorporated into the computation of the normalizing constant. Adding coherence will change the con- ver gence of the model, howe ver , we perform a relati vely small numbers of Gibbs sweeps; full con ver gence is not desired anyw ay because it would yield an impractical dense solution. In practice, the addition of coherence to the sampler proves ef fecti ve. Previous work has e xtended LD A to learn topic correlations, for e xample, by using a more sophisticated prior [17]. Learning the correlations in such a manner , using the W ikipedia graph for guidance, could provide a ef fecti ve alternativ e solution. Howe ver , extending the model in this direction and maintaining scalability is a challenging prob- lem, and an opportunity for future research. Alternativ ely , our simple approach, that incorporates the graph directly into the sampler , pro vides an effecti v e solution that does not increase the complexity of inference. 5 Distrib uted Processing W e use MapReduce [7] for distributed processing of the input data. A dataset is parti- tioned in shar ds which are processed independently by multiple workers. Documents, model parameters and all other data used for inference are stored in SST ables [4], im- mutable key-v alue maps where both keys and values are arbitrary strings. K eys are sorted by lexicographic order , allowing efficient joins over multiple tables with the same key types. V alues hold serialized structured data encoded as pr otocol buf fers 6 . W e denote such tables as , where K is a ke y type and V a value type, when the value is a collection of objects we use the notation > . 5.1 Pipelines of MapReduce Each worker needs the current model to perform inference. The model is typically lar ge to start with and can grow larger as new explicit parameters can be added after each 6 https://code.google.com/p/protobuf 13 iteration. Storing huge models in memory on many machines is impractical. One solu- tion is to store the model in a distrib uted data structure, e.g., a Bigtable. A shortcoming of using a centralized model is the latency introduced due to concurrent work er-model communication [31, 10, 19, 18]. W e propose a novel, conceptually simple, and practical alternati ve. Documents are stored in tables where the key is a document identifier and the value holds the document content. The current model is stored in a table > keyed by a symbol (a mention or content word) while the value is a collection of the symbol’ s topic parameters. Before inference we process the data and generate tables re-keyed by symbols, whose values are the document identifiers of the documents where the symbol occurred. Then a join 7 is performed of the new table with the model table, which outputs a table > keyed by document id, whose values are all model parameters appearing in the corresponding document. A document and its parameters can no w be streamed in the inference step, by-passing the issue of representing the full model anywhere, either in local memory or in distrib uted storage. Additional meta-data, e.g. the W ikipedia graph, can be passed to the document- lev el sampler in a similar fashion by generating a table > keyed by document identifiers, whose val ues are the edges of the W ikipedia graph connecting the topics in that document. Thus, document-model-metadata tuples which define self-contained blocks with all information needed to perform inference on one document are streamed together . After inference, the topic assignments are outputted. While training, updates are computed, streamed out and aggregated over the full dataset by reducers. Updates are stored in a table > keyed by a symbol which can finally be joined with the original model table for interpolation with old v alues (as defined by the SVI procedure (3)), to generate a new model. Figure 3 illustrates the flow graph for the process corresponding to one iteration. Rounded boxes with continuous lines denote input or output tables, dashed-line boxes denote intermediate outputs. Although apparently complex, this procedure is efficient since the join and data re-keying operations are faster than the inference step which dominates computation time. The procedure can produce large intermediate outputs, howe ver , these are only temporary and are deleted immediately after being consumed. W e implement the pipeline using Flume [3] which greatly simplifies coding and exe- cution, and takes care of the clean-up of intermediate outputs and optimization of the flow of operations. The proposed architecture is significantly simpler to replicate us- ing public software than complex asynchronous solutions e.g. [31, 6]. Open source implementations of Flume and other MapReduce pipelines (e.g., Pig [25]) are becom- ing increasingly popular and are publicly av ailable, opening up new opportunities for machine learning at web scale. 8 5.2 Combined procedur e The overall procedure for parameter re-estimation takes the following pathway which is summarized in Algorithm 2. Globally we store (on disk, not in memory) just the 7 W ith the term join we always mean an outer join. 8 E.g., see http://flume.apache.org/. 14 Join > > > > > Join > Join > Join > Data Model Graph Updates Predictions Inference New model > Figure 3: Pipeline of MapReduce flow graph. sparse set of parameters, and their sum over words for each topic (lines 1-2). W e perform T global iterations of Stochastic V ariational Inference. Using the pipeline described in Section 5.1, parameters (and meta-data) corresponding to the words in each shard of data (i.e. only those λ kv for which word v appears at least once in D m ) are copied to an individual worker , along with relev ant pre-computed quantities, λ · k . In lines 6,7 the transformed parameters κ kv , κ 0 k are computed using Eqn. (5) once at the initialization stage of each worker . The initial topic assignments are set in line 8. In each worker we loop sequentially ov er the documents, performing Gibbs sampling (algorithm 1). W e run an ‘inner loop’ of SVI on each shard; after sampling a single document, the local copy of the model parameters ˆ λ kv is updated using weighted interpolation in line 10. In line 11, the dense vector λ k · is updated incrementally , i.e. its values corresponding to topics that hav e not been observed in the current document do not change. After processing all of the documents in the shard, the updates from each document are a veraged (line 13), and the global parameter updates are aggre gated and interpolated with the previous model (line 15). This completes the ‘outer loop’ of SVI. The minibatch size for the outer loop SVI is equal to the number of documents per shard. W e use a minibatch size of one in the inner loop SVI, as presented in Algorithm 2, extension to arbitrary minibatches is straightforward. For simplicity we set the interpolation ρ loc , ρ global to be constant. It is straightfor- ward to extend the algorithm to use a Robbins-Monroe schedule [28]. Recent work has dev eloped methods for automatic setting of this parameter [30, 26], in vestigating an optimal update schedule within our framew ork is a subject for future work. 15 Algorithm 2 Distributed inference for LD A 1: initialize ˆ λ kv ← W ikipedia initialization (Section 6.1). 2: ˆ λ k · = P v ˆ λ kv Dense K -dim vector . 3: for t = 1 . . . T do Global SVI iterations. 4: parfor m = 1 , . . . , M ; D m ⊂ D do MapReduce. 5: for d ∈ D m do 6: κ kv ← exp { Ψ( β + ˆ λ kv ) } − exp { Ψ( β ) } Sparse. 7: κ 0 k ← exp { Ψ( V β + ˆ λ k · ) } Dense K − dim vector . 8: z (0) d ← T agMe initialization (Section 6.2) 9: ˆ λ d kv ← Algorithm 1, input : ( w d , z 0 d , { κ kv } , { κ 0 k } ) 10: ˆ λ kv ← (1 − ρ loc ) ˆ λ kv + ρ loc |D m | ˆ λ d kv Update locally . 11: ˆ λ k · = P v ˆ λ kv Update incrementally (sparse). 12: end for 13: ˆ λ m kv ← P d ∈D m ˆ λ d kv 14: end parfor 15: ˆ λ ( t ) kv ← (1 − ρ global ) ˆ λ ( t − 1) kv + ρ global M P m ˆ λ m kv 16: end for 6 Experiments For statistical models with a very large parameter space, and many local optima, such as the proposed Wikipedia-LD A model, the initialization of the parameters has a sig- nificant impact upon performance (deep neural netw orks are another classical example where this is the case). Empirically , we found that in this vast topic space, random initializations results in models with poor performance. W e describe firstly how we initialize the global parameters of the model λ kv , and secondly , the initialization of topic assignments z (0) d when performing Gibbs sampling on a document. W e test the performance of our model on the CoNLL 2003 NER dataset [12], a large public dataset for ev aluation of entity annotation systems, and compare to the current best performing annotation algorithm. 6.1 Model initialization and training An English W ikipedia article is an admissible topic if it is not a disambiguation, redi- rect, category or list page, and its main content section is longer than 50 characters. Out of the initial 4.1M pages this step selects 3.8M articles, each one defining a topic in the model. Initial candidate mention strings for a topic are generated from its title, the titles of all W ikipedia pages that redirect to it, and the anchor text of all its incoming links (within W ikipedia). All mention strings are lo wer-cased, single-character mentions are ignored. This amounts to roughly 11M mention types and 13M mention-topic param- eters. Note, that although this initialization is highly sparse - for most mention-topic pairs, the initial v ariational parameter ˆ λ kv is initialized to zero, this does not mean that topics cannot be associated with new mentions during training, due to the inclusion of the prior pseudo-count β . 16 Iteration Log likelihood Test Train Figure 4: Log likelihood on train and held-out data (rescaled to fit on same axes). W e carry out a minimal filtering of infrequent and stop words. W e compile a list of 600 stop words: all lo wer -cased single tokens that occur in more than 5% of W ikipedia. W e discard all w ords that occur in less than 3 articles. This procedure defines a v ocab u- lary of 1.8M dif ferent (lo wercased) w ords. The total number of topic-w ord parameters is approximately 70M. Let v be a symbol denoting a word or a mention. W e initialize the corresponding parameter ˆ λ kv for topic k as ˆ λ kv = P ( k | v ) = count( v,k ) count( v ) . For the content words, counts are collected from W ikipedia articles and for mentions, from titles (including redirects) and anchors. For each word we retain in the initial model the top 500 scoring topics, according to P ( k | v ) . W e don’t limit the number of topics associated with mentions. Notice that parameters not explicitly represented in the initial model are still eligible for sampling via the pseudocount β , thus the full model is giv en by the cross-product of the vocab ularies and the topics. W e train model on the English Gigaw ord Corpus 9 , a collection of news-wire text consisting of 4.8M documents, containing a total of 2 billion tokens. W e annotate the text with an off-the-shelf CoNLL-style named entity recognizer which identifies mentions of organizations, people and location names. W e ignore the label and simply use the entity boundaries to identify mention spans. Before ev aluating in terms of entity disambiguation, as an objectiv e measure of model quality , we compute the log likelihood on a held-out set with a ‘left-to-right’ approximation [34]. Figure 4 shows that the model behaves as expected and appears not to overfit: both train and held-out likelihood increase with each iteration, le velling out o ver time. 6.2 Sampler initialization A naive initialization of the Gibbs sampler could use the topic with the greatest pa- rameter value for a word z (0) i = arg max k λ kv , or e ven random assignments. W e find that these are not good solutions. Poor performance arises because the distribution of 9 LDC Catalogue: 2003T05 17 topics for a mention is typically long-tailed. If the true topic for a mention is not the most likely one, its parameter value could be several orders of magnitude smaller than the primary topic. The problem is that topics have e xtremely fine granularity and even with sparse priors it is unlikely that the right patterns of topic mixtures will emerge by brute-force sampling in a reasonable amount of time. T o improve the initialization we use a simpler , and faster , heuristic disambiguation algorithm derived from T agMe’ s annotator [9]. The score for topic z k being assigned to mention w i is defined as the edge-weighted contribution from all other mentions in the document: rel( z k | w i ) = X j 6 = i v otes j ( z k ) , where the edge-weighted votes are defined as: v otes j ( z k ) = P k 0 ∈ z ( w j ) sim( z k , z k 0 ) λ k 0 w j | z ( w j ) | , (7) and z ( v ) index es the set of topics k with ˆ λ kv > 0 . The similarity measure is that used in Equation (6). Gi ven hyperparameters and τ T agMe excludes from the set of candidates for mention w i topics with score lower than max k rel ( z w i k ) × , and P ( k | w i ) < τ . W ithin this set the candidate arg max k λ kw i is selected. Intuitiv ely , this method first selects a set of topics that are closely related according to the graph, then picks the one with the highest prior . 6.3 Evaluation data and metrics A well-studied dataset for named entity recognition is the English CoNLL 2003 NER dataset [33], a corpus of Reuters news annotated with person, location, organization and miscellaneous tags. It is divided in three partitions: train (946 documents), test- a (216 documents, used for dev elopment) and test-b (231 documents, used for blind ev aluation). The dataset was augmented with identifiers from Y A GO, W ikipedia and Freebase to e valuate entity disambiguation systems [12]. W e refer to this dataset as CoNLL-Aida. In our experiments on this data we report micr o-accur acy : the frac- tion of mentions whose predicted topic is the same as the gold-standard annotation. There are 4,788 mentions in test-a and 4,483 mentions in test-b . W e also report macr o- accuracy , where document-lev el accuracy is av eraged by the total number of docu- ments. 6.4 Hyper -parameters Since we don’t train on the CoNLL-Aida data, we set the hyper-parameters of the model by carrying out a greedy search that optimizes the sum of the micro and macro scores on both the train and test-a partitions. Our model has a fe w hyperparameters, α , β c , β m , the number of Gibbs sweeps and the number of iterations. W e find that comparable performance can be achiev ed using a wide range of values. The priors control the degree of exploration of the sampler . α acts as a pseudo-count for each topic in a document. If this parameter is set to zero 18 test-a Base T agMe* Aida W iki-LD A Micro 70.76 76.89 79.29 80.97 ± 0.49 Macro 69.58 74.57 77.00 78.61 test-b Micro 69.82 78.64 82.54 83.71 ± 0.50 Macro 72.74 78.21 81.66 82.88 T able 1: Accuracy on the CoNLL-Aida corpus. the sampler can visit only topics that have already been observed in the document; although this ensures a high degree of consistency in the topics, prev enting any explo- ration in this manner is detrimental to performance. W e find that any α ∈ [10 − 5 , 10 − 1 ] works well. β provides a residual probability that any word/mention can be associated with a topic, thus controlling exploration in sampling and vocabulary growth. β also regularizes the sampling distrib ution; the denominator κ 0 z i in Equation (5) is a function of β . If V β is too small, the topics with very small parameters λ can be sampled with high probability . For our model the vocab ulary is in the order of 10 6 , thus in practice we find β ∈ [10 − 7 , 10 − 3 ) w orks well for both words and mentions. The robustness of the model’ s performance to these wide range of hyperparame- ter settings advocates the use of our probabilistic approach. Conv ersely , we find that approaches built upon heuristic scoring metrics, such as our T agMe-like algorithm for sampler initialization require much more careful tuning. W e found that and τ , values around 0.25 and 0.02, respectiv ely , worked well. W e obtain the best results after one training iteration, this is probably because W ikipedia essentially provides a (noisy) labeled dataset to fix the initial parameters, which yields a strong initialization. Indeed, a number of approaches just use a Wikipedia initialization like ours alone, along with the graph. Note, ho we ver , that without running inference in model, the initial model alone, even with the guidance of the Wikipedia in-link graph, e.g., as in the T agMe tagging algorithm, does not yield optimal perfor- mance (see T able 1, column ‘T agMe’). It is the fast Gibbs sampler used in combination with the W ikipedia in-link graph which greatly improv es the annotation accuracy . In terms of Gibbs sweeps the best results are achieved with 800 sweeps but the improv ement ov er 50 (which we use for training) is marginal. 6.5 Results T able 1 summarizes the disambiguation ev aluation results. The Baseline predicts for mention m the topic k maximizing P ( k | m ) . The baseline is quite high, this is due to the skewed distrib ution of topics – which makes the problem challenging. The second column reports the accuracy of our implementation of T agMe (T agMe*), used to initial- ize the sampler . Finally , we compare against the best of the Aida systems, extensiv ely benchmarked in [12] where the y prov ed superior to all the best currently published sys- tems. W e report figures for the latest best model (“r-prior sim-k r-coh”), periodically 19 updated by the Aida group. 10 The proposed method, Wiki-LD A, has the best results on both dev elopment (test-a) and blind e valuation (test-b). For completeness, we re- port micro and macro figures for the train partition: 83.04% and 82.84% respecti vely . W e report standard deviations on the micro accuracy scores of our model obtained via bootstrap re-sampling of the system’ s predictions. Inspection of errors on the dev elopment partitions re vealed at least one clear issue. In some documents, a mention can appear multiple times with different gold annota- tions. E.g. in one article, ‘W ashington’ appears multiple times, sometimes annotated as the city , and sometimes as USA (country); in another, ‘W igan’ is annotated both as the UK to wn, and its rugby club . Due to the ‘bag-of-words’ assumption, the Wiki-LD A model is not able to discriminate such cases and naturally tends to commit to one as- signment per string per document. Local context could help disambiguate these cases. It would be relati vely straightforward to up-weight this context in our sampler; e.g. by weighting the influence of assignments by a distance function. This extension is left for future work. 6.6 Efficiency remarks The goal of this work is not simply provide a new scalable inference frame work for LD A, but to produce a system sufficiently scalable to address the entity-disambiguation task ef fectiv ely , hence achieving state-of-the-art performance in this domain. Indeed, direct comparison to other scalable LD A algorithms is impossible due to the different regimes in which the models operate – typical LDA models seek to ‘compress’ the documents, representing them with a small set of topics, but our model addresses an- notation with a very large number of topics. Ho wev er , we attempt to roughly compare approximate computation times and memory requirements with the current state-of- the-art scalable LD A frame works. The time needed to train on 5M documents with 50 Gibbs sweeps per document on 1,000 machines is approximately one hour . The memory footprint is negligible (a few hundred Mb). As noted, one cannot compare directly to the current distributed LD A systems which use far fewer topics and run dif ferent inference algorithms (usually pure Gibbs sampling), ho we ver , some of the fastest systems to date are reported in [31]. This work reports a maximum throughput of around 16k-30k documents/machine per hour on dif ferent corpora, using 100 machines, beyond this number they run out of memory . They use a complex architecture and vanilla LDA, with our simple architecture and a much (5000 times) larger topic space our training rates are certainly comparable. In addition, in our architecture based on pipelines of MapReduce speed should, in principle at least, correlate linearly with the number of machines as the processes run independently of each other . W e plan to in v estigate these issues further in the future. The LD A model proposed in [11] is somewhat comparable, the y report a training time of ov er a week with 20G memory , on a single machine. 10 http://www.mpi- inf.mpg.de/yago- naga/aida/ as of May 2013. W e thank Johannes Hof- fart for providing us with the latest best results on the test-a partition in personal communications. 20 7 Conclusion and Futur e W ork T opic models provide a principled, flexible framew ork for analyzing latent structure in text. These are desirable properties for a whole new area of work that is begin- ning to systematically explore semantic grounding with respect to web-scale knowl- edge bases such as W ikipedia and Freebase. W e hav e proposed a conceptually simple, highly scalable, and reproducible, distrib uted inference frame work built upon pipelines of MapReduces for scaling topic models for the entity disambiguation task, and be- yond. W e extended the hybrid SVI/Gibbs sampling frame work to a distributed setting and incorporated crucial metadata such as the Wikipedia link graph into the sampler . The model produced, to the authors’ best knowledge, the best results to date on the CoNLL-Aida ev aluation dataset. Although we address a different task to the usual ap- plications of LDA (exploratory analysis and structure discovery in text) and work in a very dif ferent parameter domain, this system is comparable to, or e ven faster than state of the art learning systems for v anilla LD A. The topic space and parallelization degree are the largest to date. Further lines of inv estigation include implementing more ad- vanced local/global update schedules, in vestigating their interaction with sharding and batching schemes, and the ef fect on computational ef ficiency and performance. On the modeling side our first priority is the inclusion of the segmentation task directly into the model, and e xploring hierarchical v ariants, which could provide an alternativ e w ay to incorporate information from the W ikipedia graph. The graphical structure could ev en be further refined from data. Acknowledgments W e would like to thank Michelangelo Diligenti, Y asemin Altun, Amr Ahmed, Alex Smola, Johannes Hof fart, Thomas Hofmann, Marc’Aurelio Ranzato and Kuzman Ganchev for valuable feedback and discussions. Refer ences [1] C. M. Bishop. P attern Recognition and Machine Learning (Information Science and Statistics) . Springer-V erlag New Y ork, Inc., 2006. [2] D. M. Blei, A. Y . Ng, and M. I. Jordan. Latent Dirichlet Allocation. Journal of Machine Learning Resear ch , 3:993–1022, 2003. [3] C. Chambers, A. Raniwala, F . Perry , S. Adams, R. R. Henry , R. Bradshaw , and N. W eizenbaum. FlumeJava: Easy , efficient data-parallel pipelines. In Pr oceed- ings of the 2010 ACM SIGPLAN conference on Pr o gramming language design and implementation , pages 363–375. A CM, 2010. [4] F . Chang, J. Dean, S. Ghema wat, W . C. Hsieh, D. A. W allach, M. Burro ws, T . Chandra, A. Fikes, and R. E. Gruber . Bigtable: A distributed storage system for structured data. A CM T rans. Comput. Syst. , 26(2):4:1–4:26, 2008. 21 [5] R. L. Cilibrasi and P . M. B. V itanyi. The Google Similarity Distance. IEEE T rans. on Knowl. and Data Eng. , 19(3):370–383, 2007. [6] A. Coates, A. Karpathy , and A. Ng. Emer gence of object-selectiv e features in unsupervised feature learning. In Advances in Neural Information Processing Systems 25 , pages 2690–2698, 2012. [7] J. Dean and S. Ghemawat. MapReduce: Simplified data processing on lar ge clusters. Commun. A CM , 51(1):107–113, 2008. [8] E. A. Eroshe va, E. Fienberg, and J. Lafferty . Mix ed-membership models of scientific publications. Pr oceedings of the National Academy of Sciences , 97(22):11885–11892, 2004. [9] P . Ferragina and U. Scaiella. T agMe: On-the-fly annotation of short text frag- ments (by wikipedia entities). In Pr oceedings of the 19th A CM international con- fer ence on Information and knowledge management , pages 1625–1628. A CM, 2010. [10] K. Hall, S. Gilpin, and G. Mann. MapReduce/Bigtable for distributed opti- mization. In Advances in Neur al Information Pr ocessing Systems: W orkshop on Learning on Cor es, Clusters and Clouds . MIT Press, 2010. [11] X. Han and L. Sun. An entity-topic model for entity linking. In Pr oceedings of the 2012 Joint Confer ence on Empirical Methods in Natural Language Processing and Computational Natur al Languag e Learning , pages 105–115. Association for Computational Linguistics, 2012. [12] J. Hoffart, M. A. Y osef, I. Bordino, H. F ¨ urstenau, M. Pinkal, M. Spaniol, B. T ane va, S. Thater, and G. W eikum. Robust disambiguation of named enti- ties in text. In Pr oceedings of the Confer ence on Empirical Methods in Natural Language Pr ocessing , pages 782–792. Association for Computational Linguis- tics, 2011. [13] M. Hoffman, D. Blei, and F . Bach. Online learning for Latent Dirichlet Alloca- tion. Advances in Neural Information Pr ocessing Systems , 23:856–864, 2010. [14] M. Hof fman, D. M. Blei, C. W ang, and J. Paisley . Stochastic variational inference. arXiv pr eprint arXiv:1206.7051 , 2012. [15] S. S. Kataria, K. S. Kumar , R. R. Rastogi, P . Sen, and S. H. Sengamedu. En- tity disambiguation with hierarchical topic models. In Pr oceedings of the 17th A CM SIGKDD international confer ence on Knowledge discovery and data min- ing , pages 1037–1045. A CM, 2011. [16] S. Kulkarni, A. Singh, G. Ramakrishnan, and S. Chakrabarti. Collective annota- tion of wikipedia entities in web text. In Pr oceedings of the 15th ACM SIGKDD international conference on Knowledge discovery and data mining , pages 457– 466. A CM, 2009. 22 [17] J. D. Lafferty and D. M. Blei. Correlated topic models. In Advances in neural information pr ocessing systems , pages 147–154, 2005. [18] Q. Le, M. Ranzato, R. Monga, M. De vin, K. Chen, G. Corrado, J. Dean, and A. Ng. Building high-lev el features using large scale unsupervised learning. In Pr oceedings of the 29th Annual International Confer ence on Machine Learning . A CM, 2012. [19] R. McDonald, K. Hall, and G. Mann. Distributed training strategies for the struc- tured perceptron. In Human Language T echnologies: The 2010 Annual Confer- ence of the North American Chapter of the Association for Computational Lin- guistics , pages 456–464, Los Angeles, California, June 2010. Association for Computational Linguistics. [20] R. Mihalcea and A. Csomai. Wikify!: Linking documents to encyclopedic kno wl- edge. In Pr oceedings of the sixteenth ACM conference on Confer ence on infor- mation and knowledge manag ement , pages 233–242. A CM, 2007. [21] D. Milne and I. W itten. An effecti ve, low-cost measure of semantic relatedness obtained from Wikipedia links. In Pr oceedings of the first AAAI W orkshop on W ikipedia and Artificial Intelligence (WIKIAI’08) , 2008. [22] D. Milne and I. H. W itten. Learning to link with Wikipedia. In Proceedings of the 17th ACM conference on Information and knowledge management , pages 509–518. A CM, 2008. [23] D. Mimno, M. Hof fman, and D. Blei. Sparse stochastic inference for Latent Dirichlet allocation. arXiv pr eprint arXiv:1206.6425 , 2012. [24] D. Newman, C. Chemudugunta, and P . Smyth. Statistical entity-topic models. In Pr oceedings of the 12th A CM SIGKDD international confer ence on Knowledge discovery and data mining , pages 680–686. A CM, 2006. [25] C. Olston, B. Reed, U. Sriv astav a, R. Kumar , and A. T omkins. Pig latin: A not-so- foreign language for data processing. In Pr oceedings of the 2008 A CM SIGMOD international confer ence on Manag ement of data , pages 1099–1110. A CM, 2008. [26] R. Ranganath, C. W ang, D. M. Blei, and E. P . Xing. An adapti ve learning rate for stochastic variational inference. In International Conference on Machine Learn- ing , 2013. [27] L.-A. Ratinov , D. Roth, D. Downe y , and M. Anderson. Local and global algo- rithms for disambiguation to wikipedia. In ACL , volume 11, pages 1375–1384, 2011. [28] H. Robbins and S. Monro. A stochastic approximation method. The Annals of Mathematical Statistics , pages 400–407, 1951. [29] U. Scaiella, P . Ferragina, A. Marino, and M. Ciaramita. T opical clustering of search results. In Proceedings of the fifth ACM international confer ence on W eb sear ch and data mining , pages 223–232. A CM, 2012. 23 [30] T . Schaul, S. Zhang, and Y . LeCun. No more pesk y learning rates. arXiv pr eprint arXiv:1206.1106 , 2012. [31] A. Smola and S. Narayanamurthy . An architecture for parallel topic models. Pr oceedings of the VLDB Endowment , 3(1-2):703–710, 2010. [32] Y . W . T eh, D. Newman, and M. W elling. A collapsed v ariational bayesian in- ference algorithm for latent dirichlet allocation. Advances in Neural Information Pr ocessing Systems , 19:1353, 2007. [33] E. F . Tjong Kim Sang and F . De Meulder . Introduction to the conll-2003 shared task: Language-independent named entity recognition. In Pr oceedings of the seventh confer ence on Natural language learning at HLT -N AA CL 2003 - V olume 4 , pages 142–147. Association for Computational Linguistics, 2003. [34] H. W allach, I. Murray , R. Salakhutdinov , and D. Mimno. Evaluation methods for topic models. In Pr oceedings of the 26th Annual International Confer ence on Machine Learning , pages 1105–1112. A CM, 2009. [35] Y . W ang, H. Bai, M. Stanton, W .-Y . Chen, and E. Y . Chang. Plda: Parallel la- tent dirichlet allocation for large-scale applications. In Algorithmic Aspects in Information and Management , pages 301–314. Springer , 2009. 24
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment