온라인 계약 선택 문제의 효율적 학습 알고리즘
본 논문은 구매자 유형이 알려지지 않은 상황에서 판매자가 계약 묶음을 순차적으로 제시하여 얻는 이익을 극대화하는 온라인 학습 문제를 다룬다. 구매자들의 효용이 ‘ordered preferences’라는 구조적 특성을 만족한다는 가정 하에, 저자들은 탐색‑활용 단계로 구성된 두 가지 알고리즘을 제안하고, 계약 수와 시간에 대해 선형·아차원적인 서브리니어(regret) 경계를 증명한다. 무선 데이터 플랜, 2차 스펙트럼 임대, 추천 시스템 등 다양…
저자: Cem Tekin, Mingyan Liu
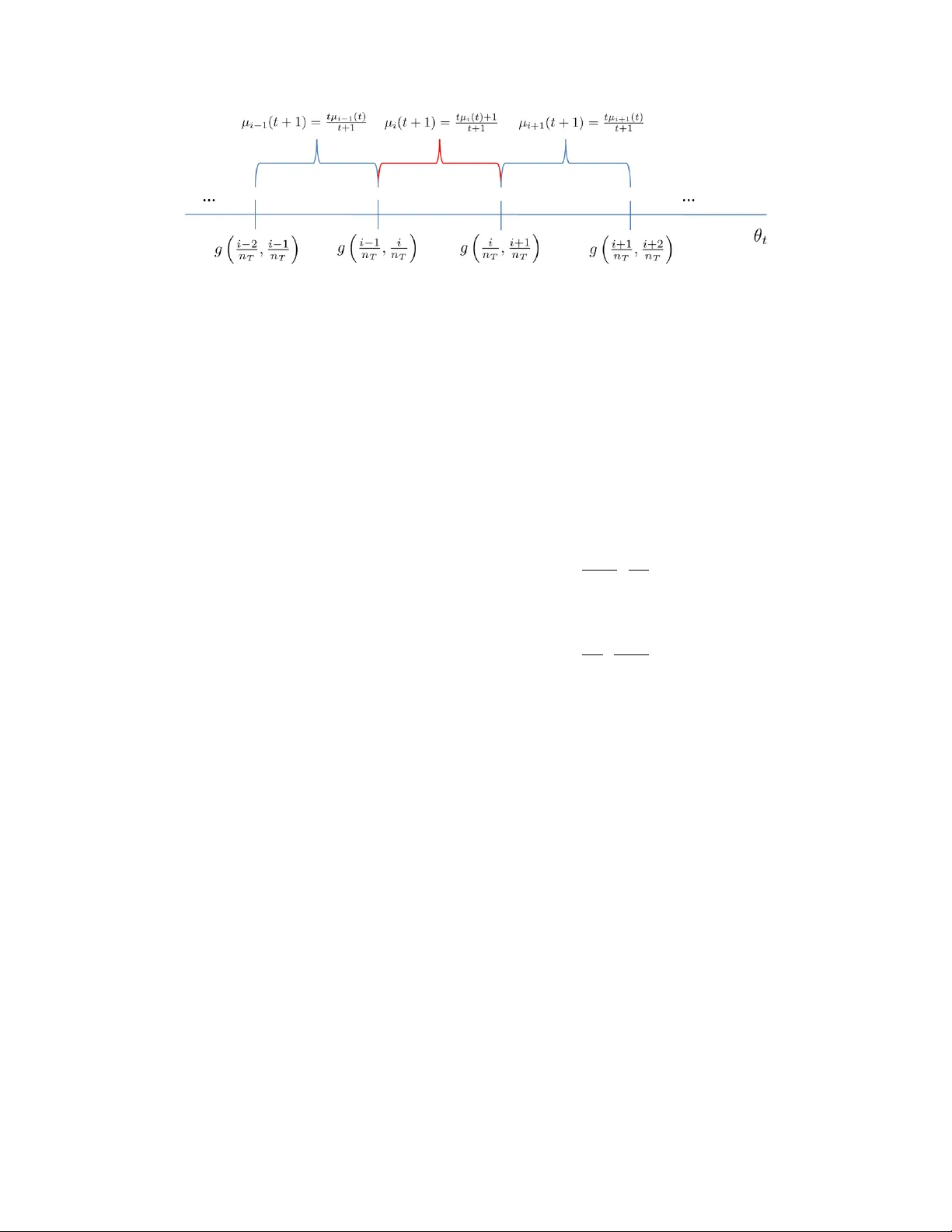
본 논문은 온라인 계약 선택 문제를 새로운 관점에서 접근한다. 판매자는 매 시점에 m개의 계약을 묶음으로 제시하고, 순차적으로 도착하는 구매자는 자신의 유형 θ에 따라 효용 함수 U_b(x,θ)를 최대화하는 계약을 선택한다. 구매자 유형은 알려지지 않은 확률밀도 f(θ) 에 따라 독립적으로 추출되며, 판매자는 이 분포를 학습하면서 기대 이익을 극대화해야 한다.
핵심 가정은 구매자 효용이 ‘ordered preferences’ 라는 구조적 특성을 가진다는 것이다. 구체적으로, 계약 x_i 의 수용 구간 I_{x_i}(x) 은 인접 계약 x_{i‑1}, x_i, x_{i+1} 만을 이용해 정의되는 구간 (g(x_{i‑1},x_i), g(x_i,x_{i+1})] 로 표현된다. 여기서 g는 단조 증가하고 Hölder 연속성을 만족하는 함수이며, 이는 계약 간 수용 구간이 순서대로 정렬됨을 보장한다. 이 특성 덕분에 계약 묶음 x=(x₁,…,x_m) 의 기대 이익은
U(x)=∑_{i=1}^m x_i·P(g(x_{i‑1},x_i)<θ≤g(x_i,x_{i+1}))
와 같이 간단히 나타낼 수 있다.
문제는 두 가지 어려움을 포함한다. 첫째, 계약 공간이 연속적이어서 직접 최적화를 수행하기 어렵다. 둘째, 가능한 계약 묶음(팔)의 수가 m에 대해 지수적으로 늘어나 조합적 폭발을 일으킨다. 이를 해결하기 위해 저자들은 (1) 계약을 균등하게 이산화한 집합 K_T={1/n_T,2/n_T,…,(n_T‑1)/n_T} 를 정의하고, (2) 탐색‑활용 프레임워크를 설계한다.
탐색 단계에서는 K_T 에 속한 모든 계약을 동시에 제시한다. 구매자가 계약 i/n_T 를 수용하면, 구매자 유형 θ 가 g(i‑1,i)/n_T < θ ≤ g(i,i+1)/n_T 에 있음을 알 수 있다. 이를 통해 각 구간의 확률 μ_i 를 N_i/N 로 추정한다(N_i는 해당 구간이 관측된 횟수, N은 전체 탐색 횟수). 탐색은 사전에 정의된 증가 함수 z(t) 에 따라 제한적으로 수행된다; 즉, 현재까지의 탐색 횟수가 z(t) 미만이면 탐색을 진행한다.
활용 단계에서는 추정된 μ_i 를 이용해 이산화된 계약 후보 집합 L_{m,T} (각 계약이 K_T 에 속하도록 제한) 중 기대 이익이 최대가 되는 묶음을 선택한다. 이 최적화는 선형 형태이므로 효율적인 계산이 가능하며, 선택된 묶음은 m개의 계약을 동시에 제시한다.
레지스트 분석에서는 n_T 와 z(t) 를 적절히 선택함으로써 전체 레지스트 R(T) 를 서브리니어로 만든다. 구체적으로, g의 Hölder 지수 α∈(0,1] 를 고려하여 n_T≈T^{1/(2+α)} 로 설정하고, z(t)=⌈c·t^{(1+α)/(2+α)}⌉ 로 두면, 레지스트는 O(T^{(2+α)/(2+2α)}·log T) 로 제한된다. 이때 레지스트는 계약 수 m 에 대해 선형적으로 증가하지만, 시간에 대한 성장률은 α에 의해 조절되는 서브리니어이다.
고정된 계약 수 m 을 유지하는 변형 알고리즘(TLFO)도 제시한다. TLFO는 탐색 시에도 m개의 계약만 제시하되, 각 탐색마다 서로 다른 구간을 커버하도록 설계한다. 이 경우에도 비슷한 형태의 레지스트 경계가 성립한다.
논문은 또한 무선 데이터 플랜, 2차 스펙트럼 임대, 추천 시스템 등 세 가지 실용적인 응용 사례를 제시한다. 데이터 플랜에서는 계약이 제공되는 데이터 양이며, 구매자는 과소·과다 제공에 따른 손실을 고려한다. 스펙트럼 임대에서는 계약이 대역폭이며, 구매자는 대역폭 부족에 대한 비용을 감수한다. 추천 시스템에서는 계약이 제품 평점이며, 사용자는 자신의 선호 구간에 들어가는 제품만 선택한다. 모든 사례에서 ordered preferences 가 자연스럽게 성립함을 보이며, 제안된 알고리즘이 실제 비즈니스 상황에 적용 가능함을 강조한다.
마지막으로, 기존 연구와의 차별점을 논한다. 연속 팔밴드 문제와 조합적 팔밴드 문제를 각각 다루던 이전 연구와 달리, 본 논문은 연속적인 계약 공간과 조합적 계약 묶음이라는 두 차원을 동시에 고려한다. 또한, ordered preferences 라는 구조적 가정을 통해 기대 이익을 선형 결합 형태로 변환함으로써 기존의 복잡한 비선형 최적화 문제를 회피한다. 실험적 검증은 제시되지 않았지만, 이론적 레지스트 경계와 적용 가능성에 대한 논의가 충분히 이루어졌다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기