Online Learning in a Contract Selection Problem
In an online contract selection problem there is a seller which offers a set of contracts to sequentially arriving buyers whose types are drawn from an unknown distribution. If there exists a profitable contract for the buyer in the offered set, i.e.…
Authors: Cem Tekin, Mingyan Liu
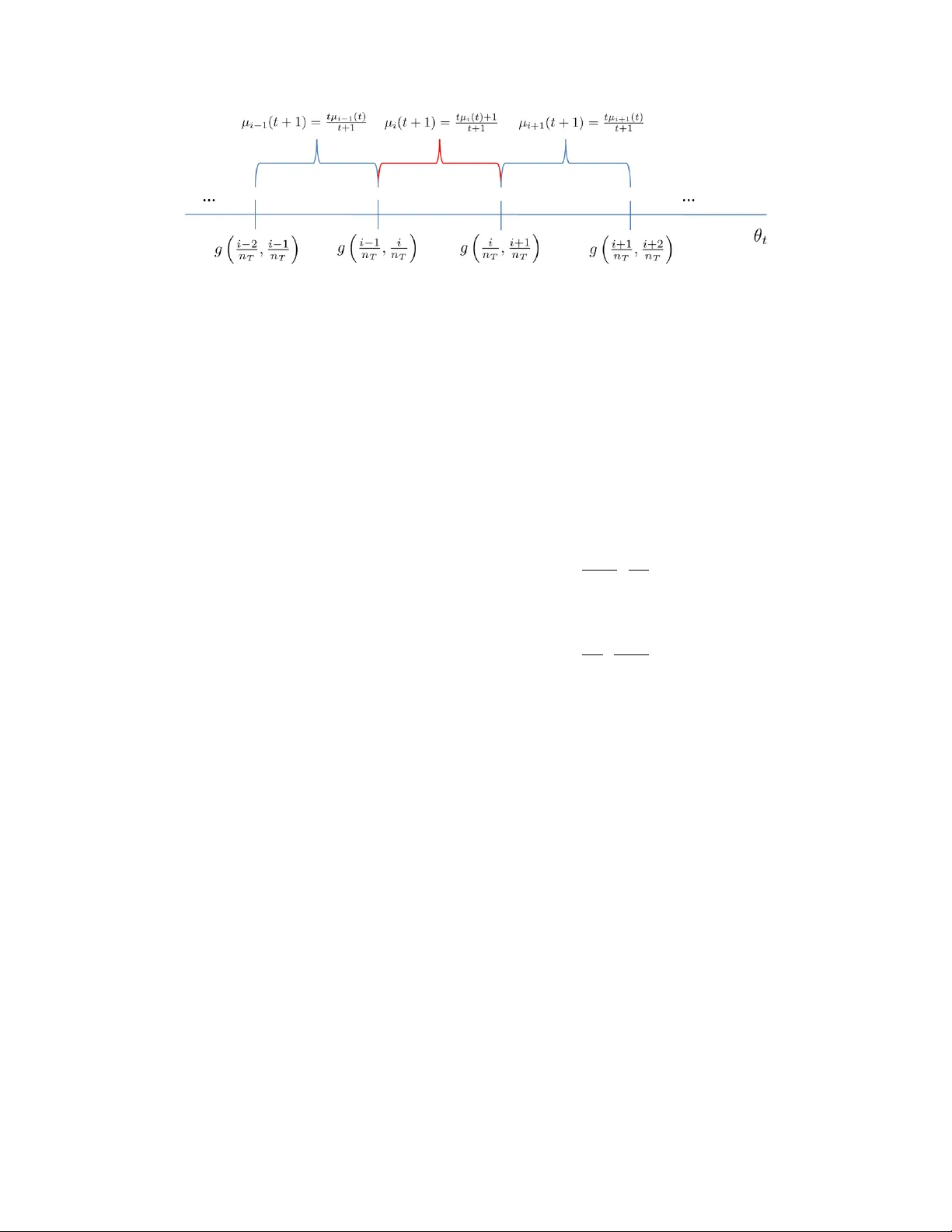
1 Online Learning in a Contract Selection Problem Cem T ekin, Mingyan Liu Abstract In an online contract selection problem there is a seller which offers a set of contracts to sequentially arriving b uyers whose types are drawn from an unknown distrib ution. If there exists a profitable contract for the buyer in the offered set, i.e., a contract with payoff higher than the payoff of not accepting any contracts, the buyer chooses the contract that maximizes its payoff. In this paper we consider the online contract selection problem to maximize the sellers profit. Assuming that a structural property called or der ed prefer ences holds for the b uyer’ s payoff function, we propose online learning algorithms that hav e sub-linear regret with respect to the best set of contracts gi ven the distribution over the buyer’ s type. This problem has many applications including spectrum contracts, wireless service provider data plans and recommendation systems. I . I N T RO D U C T I O N In an online contract selection problem there is a seller who of fers a bundle of contracts to b uyers arri ving sequentially over time. The goal of the seller is to maximize its total expected profit up to the final time T , by learning the best bundle of contracts to offer . Ho wever , the seller does not kno w the best bundle of contracts beforehand because initially it does not know the preferences of the buyers. Assuming that the buyers’ preferences change stochastically over time, our goal in this paper is to design learning algorithms for the seller to maximize its e xpected profit. Specifically , we assume that the preferences of a buyer depends on its type , and is giv en by a payoff function depending on the type of the buyer . The type of the buyer at time step t is drawn from a distribution not known by the seller , C. T ekin is with the Dept. of Electrical Engineering, Univ ersity of California, Los Angeles, CA, 90095, M. Liu is with the Dept. of Electrical Engineering and Computer Science, University of Michigan, Ann Arbor , MI 48105, cmtkn@ucla.edu, mingyan@eecs.umich.edu. This work is supported by NSF grant CIF-0910765 and AR O grant W911NF-11-1-0532. 2 independently from the other time steps. Obviously , the best bundle of contracts (which maximizes the sellers expected profit) depends on the distribution of the buyers’ type and the preferences of the buyers. W e assume that the seller can choose what to of fer from a continuum of contracts, b ut it should choose a finite number of contracts to of fer simultaneously . W e show that if the buyers’ payoff function has a special property which we call the ordered preferences property , then there exists learning algorithms for the seller by which the seller can estimate the type distribution of the b uyers by offering contracts and observing the contracts that are accepted by the b uyers. Then, the seller can compute the expected payoff of different bundles of contracts using the estimated type distrib ution. The online contract selection problem can be viewed as a combinatorial multi-armed bandit problem, where each arm is a vector (b undle) of contracts, and each component of the vector can be chosen from an interv al of the real line. T wo aspects that make this problem harder than the classical multi-armed bandit problem are: (i) uncountable number of contracts; (ii) exponential number of arms in the number of contracts. W e can o vercome (i) by of fering bundles of suf ficiently closely spaced contracts to form an estimate of the distrib ution of buyer’ s type, and (ii) by writing the expected payoff of an arm as a function of the expected payoffs of the contracts in that arm. Exploiting the structure of the problem, we prov e sublinear regret bounds which scale linearly in the dimension m . The online learning problem we consider in this paper in v olves large strategy sets, combinatorial and contextual elements. Problems with a continuum of arms are considered in [1], [2], [3], [4], where sub-linear regret results are deriv ed. Sev eral combinatorial bandit problems are studied in [5], [6], and problems in volving stochastic linear optimization are considered in [7], [8]. Another line of work [9] generalized the continuum armed bandits to bandits on metric spaces. In this setting, the dif ference between the expected payoffs of a pair of arms is related to the distance between the arms via a similarity metric. Contextual bandits, in which context information is provided to the algorithm at each round is studied in [10], [11]. The goal there is to learn the best arm, gi ven the context. Many applications can be modeled using our online contract selection frame work. For instance, the bundles of contracts can be vie wed as wireless service pro vider data plans from which the users make selections based on their needs, or they can be viewed as recommendations in a recommender system such as airline tickets, hotels, rental cars, etc., where each recommendation has a rating that encodes its price and quality . The organization of the rest of the paper is as follo ws. In Section II, we define the contract selection problems, the ordered preferences property , and provide three applications of the problem. W e propose a contract learning algorithm with v ariable number of simultaneous offers at each time step in Section 3 III, and analyze its performance in Section IV. Then, we consider a variant of this algorithm with fixed number of offers in Section V. Finally , we discuss the similarities and the differences between our work and the related work in Section VI. I I . P RO B L E M F O R M U L AT I O N A N D P R E L I M I N A R I E S In an online contract selection problem there is a seller who offers a bundle of m ∈ { 1 , 2 , . . . } contracts x ∈ X m , where X m := { ( x 1 , x 2 , . . . , x m ) , such that x i ∈ (0 , 1] , ∀ i ∈ { 1 , 2 , . . . , m } , x i ≤ x i +1 } , to buyers arri ving sequentially at time steps t = 1 , 2 , . . . , T , where T is the time horizon. Let x ( t ) be the bundle of fered by the seller at time t . The buyer can accept a single contract y ∈ x ( t ) and pay y to the seller , or it can reject all of the offered contracts and pay 0 to the seller . Profit of the seller by time T is T X t =1 ( u ( t ) − c ( t )) , where u ( t ) represents the rev enue/payoff of the seller at time t and c ( t ) is any cost associated with of fering the contracts at time t . W e hav e u ( t ) = x if contract x is accepted by the buyer at time t , u ( t ) = 0 if none of the offered contracts at time t is accepted by the b uyer at time t . The buyer who arri ves at time t has type θ t which encodes its preferences into a payoff function. At each time step, the type of the buyer present at that time step is dra wn according to the probability density function f ( θ ) on [0 , 1] independently from the other time steps. W e assume that buyer’ s type density is bounded, i.e. f max := sup θ ∈ [0 , 1] f ( θ ) < ∞ . Neither θ t nor f ( θ ) is known by the seller at any time. Therefore, in order maximize its profit, the seller should learn the best set of contracts over time. The expected profit of the seller ov er time horizon T is gi ven by E " T X t =1 u ( t ) − c ( t ) # , where the expectation is taken with respect to buyer’ s type distribution f ( θ ) and the seller’ s contract of fering strategy . Our goal in this paper is to de velop online learning algorithms for the seller to maximize its expected profit over time horizon T . 4 Let U b ( x, θ ) : [0 , 1] × [0 , 1] → R represent the payoff function of type θ buyer , which is a function of the contract accepted by the buyer . W e assume that the seller kno ws U b . For example, when the contracts represent data plans of wireless service providers, the service provider can kno w the worth of a 2 GB contract to a b uyer who only needs 1 GB each month. For instance, the amount of payment for the 2 GB contract that exceeds the payment for a 1 GB can represent the loss of the b uyer . Similarly , a 500 MB contract to a buyer who needs 1 GB a month can ha ve a cost equal to the 500 MB shortage in data. Of course there should be a way to relate the monetary loss with the data loss, which can be captured by coefficients multiplying these two. These coefficients can also be known by the seller by analyzing pre vious buyer data. Based on its payoff function, the buyer either selects a contract from the of fered bundle or it may reject all of the contracts in the bundle. If x = ( x 1 , x 2 , . . . , x m ) is offered to a type θ buyer , it will accept a contract randomly from the set arg max x ∈{ 0 ,x 1 ,...,x m } U b ( x, θ ) , where x = 0 implies that the buyer does not accept any of the offered contracts. Since the seller kno ws the buyer’ s payof f function U b ( x, θ ) , for a gi ven bundle of contracts x = ( x 1 , x 2 , . . . , x m ) , it can compute which contracts will be accepted as a function of the buyer’ s type. For y ∈ x , let I y ( x ) be the acceptance region of contract y , which is the v alues of θ for which contact y will be accepted from the b undle x (usually an interval of the real line). For two intervals of the real line I 1 and I 2 , I 1 < I 2 means that the rightmost point of I 1 is less than or equal to the leftmost point of I 2 . W e assume that the buyers payof f function induces or der ed prefer ences , which means that for a bundle of contracts ( x 1 , . . . , x m ) , the values of θ for which x i is accepted only depends on x i − 1 , x i and x i +1 , and I x i − 1 ( x ) < I x i ( x ) < I x i +1 ( x ) , for all i ∈ { 1 , 2 , . . . , m − 1 } , which means that the acceptance re gions are ordered. Assumption 1: Ordered Preferences. U b ( x, θ ) induces ordered preferences which means that for any x ∈ X , I x i ( x ) = ( g ( x i − 1 , x i ) , g ( x i , x i +1 )] . The function g is such that g ( x, y ) < g ( y , z ) for x < y < z , and g is H ¨ older continuous with constant L and exponent α , i.e., | g ( x 1 , x 2 ) − g ( y 1 , y 2 ) | ≤ L p ( | x 1 − y 1 | 2 + | x 2 − y 2 | 2 ) α . Although the assumption on U b ( x, θ ) is implicit, it is satisfied by many common payoff functions. Below we provide se veral e xamples. For notational con venience for any bundle of contracts ( x 1 , x 2 , . . . , x m ) , let x 0 = 0 , x m +1 = 1 and g ( x m , 1) = 1 . 5 Fig. 1. acceptance region of bundle ( x 1 , . . . , x m ) for U b ( x, θ ) = h ( a ( x − θ ) + + b ( θ − x ) + ) Example 1: Wir eless Data Plan Contract. A wireless user’ s goal is to have a certain video/audio quality and download/upload quota. For a wireless user with type θ , it is intuitive to assume that ( x − θ ) + corresponds to loss in accepting a contract which of fers data less than the demand, while ( θ − x ) + corresponds to loss in accepting a contract x which of fers data more than the demand but hav e a higher price than the price of the demanded data service. T radeoff between these two is captured by coef ficients that relate the buyers weighting of these losses. Therefore we assume that the buyer’ s payoff function is gi ven by U b ( x, θ ) := h ( a ( x − θ ) + + b ( θ − x ) + ) , where ( x − y ) + = max { 0 , x − y } , and h : R + → R is a decreasing function. For data plan contracts, For this payoff function, the accepted contract from any bundle ( x 1 , x 2 , . . . , x m ) of contracts is gi ven as a function of the buyer’ s type in Figure 1. It is easy to check that the boundaries of the acceptance regions are g ( x i − 1 , x i ) = bx i − 1 + ax i a + b , ∀ i = 1 , 2 , . . . , m. Since | g ( x 1 , x 2 ) − g ( y 1 , y 2 ) | = b ( x 1 − y 1 ) a + b + a ( x 2 − y 2 ) a + b ≤ max {| x 1 − y 1 | , | x 2 − y 2 |} ≤ p | x 1 − y 1 | 2 + | x 2 − y 2 | 2 , Assumption 1 holds for this buyer payof f function with L = 1 and α = 1 . Example 2: Secondary Spectrum Contract. Consider a secondary spectrum market, where the service provider leases excess spectrum to secondary users. F or simplicity , assume that the service provider al ways hav e a unit bandwidth av ailable. In general, due to the primary user activity the bandwidth av ailable for 6 leasing at time t is B t ∈ [0 , 1] , howe ver , all our results in this paper will hold for dynamically changing av ailable bandwidth, provided that the seller pays a penalty to the buyers for any bandwidth it offers but cannot guarantee to a b uyer . By this way , the seller can still learn the b uyer’ s type distribution by of fering a bundle of contracts x for which there is some x i > B t . The buyer’ s payoff function in this case is U b ( x, θ ) := − a ( θ − x ) + − x, where x is the amount of money that the buyer pays to the seller by accepting contract x and a > 1 is a coef ficient that relates the tradeof f between the loss in data and monetary loss. For this payof f function it can be shown that the acceptance re gion boundaries are g ( x i − 1 , x i ) = ( a − 1) x i − 1 + x i a , ∀ i = 1 , 2 , . . . , m, and Assumption 1 holds with L = 1 , α = 1 . Example 3: Recommendation System. Consider a recommendation system where the recommender makes m recommendations to each arriving user . For instance these recommendations can be flights, hotels, etc. Each recommendation has a rating x ∈ [0 , 1] which reflects some weighted av erage of quality and price. Based on its (unkno wn) type θ (budget, preferences, etc.) a user either chooses one of the recommendations or it does not accept any . For e xample, type of the user may represent its preferred rating, and the user may only accept a recommendation if its rating is within ( θ − , θ + ) for some small > 0 . Note that this user preference satisfies the ordered preferences property giv en in Assumption 1 where I x i ( x ) = I ( x i ∈ ( θ − , θ + ) and x i closest in x to θ ) 1 Note that although we do not require the H ¨ older condition to hold here, our analysis throughout the paper hold for this type of user preference as well. Whene ver a user chooses a recommendation, the recommender obtains rew ard 1 . The goal of the recommender is to maximize the number of sales. Abov e examples sho w that our contract selection framew ork has a large set of applications. By Assumption 1, the expected payof f of a bundle of contracts x ∈ X m to the seller is U ( x ) = x 1 P ( g (0 , x 1 ) < θ ≤ g ( x 1 , x 2 )) + x 2 P ( g ( x 1 , x 2 ) < θ ≤ g ( x 2 , x 3 )) + . . . + x m P ( g ( x m − 1 , x m ) < θ ) . 7 Fig. 2. acceptance region of bundle ( x 1 , . . . , x m ) for U b ( x, θ ) = − a ( θ − x ) + − x Note that the seller’ s problem would be solved if it knew f ( θ ) , since it could compute the best bundle of m contracts, i.e., arg max x ∈X m U ( x ) . (1) Remark 1: W e do not require that the maximizer of (1) is a bundle of m distinct contracts. Note that by definition of the set X m , the maximizer of (1) may be a bundle ( x 1 , . . . , x m ) for which x i = x i +1 for some i ∈ { 1 , 2 , . . . , m − 1 } . This is equiv alent to offering m − 1 contracts ( x 1 , . . . , x i − 1 , x i , x i +2 , . . . , x m ) . Indeed, our results hold when the seller’ s goal is to learn the best bundle of contracts that hav e at most m contracts in it. The key idea behind the learning algorithms we design for the seller in the subsequent sections is to form estimates of the b uyer’ s type distribution by offering different sets of contracts. Each algorithm consists of exploration and exploitation phases. Although we stated that the seller of fers m contracts at each time step, in our first algorithm m will vary ov er time (two dif ferent values for m ; one for exploration, one for exploitation), so we denote it by m ( t ) . In our second algorithm m will be fixed throughout the time horizon T . W e also assume that the cost of offering m contracts at the same time is given by c ( m ) , which increases with m . For e xample, in a recommendation system, the buyer can get confused when there is a huge list of recommendations, for wireless service providers the regulatory costs increase with the number of different plans of fered, etc. The seller’ s objecti ve of maximizing the profit ov er time horizon T is equi v alent to minimizing the regret which is giv en by R alg ( T ) = T ( U ( x ∗ ) − c ( m )) − E alg " T X t =1 r ( x ( t )) − c ( m ( t )) # , (2) where x ∗ ∈ arg max x ∈X m U ( x ) , (3) 8 is the optimal set of m contracts, r ( x ( t )) is the payoff of the seller from the bundle offered at time t , and “alg” is the learning algorithm used by the seller . W e will drop the superscript “alg” when the algorithm used by the seller is clear from the context. Note that for any algorithm with sublinear regret, the time av eraged expected profit will conv erge to U ( x ∗ ) − c ( m ) . I I I . A L E A R N I N G A L G O R I T H M W I T H V A R I A B L E N U M B E R O F O FF E R S In this section we present a learning algorithm which sequences time steps into exploration and exploitation steps, and uses the exploration steps to learn about the buyer’ s type distribution while using the exploitation steps to offer best bundle of contracts. The algorithm is called type learning with variable number of offers (TL V O), whose pseudocode is given in Figure 3. Instead of searching for the best bundle of contracts in X m which is uncountable, the algorithm searches for the best bundle of contracts in the finite set L m,T := { x = ( x 1 , . . . x m ) : x i ≤ x i +1 and x i ∈ K T , ∀ i ∈ { 1 , . . . , m }} , where K T := 1 n T , 2 n T , . . . , n T − 1 n T . Here n T is a non-decreasing function of the time horizon T . Since the best bundle in L m,T might hav e an expected rew ard smaller than the expected rew ard of the best bundle in X m , in order to bound the regret due to this difference sublinearly over time, n T should be adjusted according to the time horizon. Exploration and exploitation steps are sequenced in a deterministic way . This sequencing is provided by a contr ol function z ( t ) which is a parameter of the learning algorithm. Let N ( t ) be the number of explorations up to time t . If N ( t ) < z ( t ) , time t will be an e xploration step. Otherwise time t will be an e xploitation step. While z ( t ) can be any sublinearly increasing function, we will optimize o ver z ( t ) in our analysis. In an exploration step, TL V O estimates the distribution of buyer’ s type by simultaneously offering the set of n T − 1 uniformly spaced contracts in K T . Based on the accepted contract at time t , the seller learns the part of the type space that the buyers type at t lies in, and uses this to form sample mean estimates of the distribution of the b uyer’ s type. An example is sho wn in Figure 4. W e simply call the contract i/n T ∈ K T as the i th contract. Let θ be the unknown type of the buyer at some e xploration step. If i th contract is accepted by the buyer , then the seller kno ws that g i − 1 n T , i n T < θ ≤ g i n T , i + 1 n T . 9 T ype Learning with V ariable Number of Offers (TL V O) 1: Parameters: m , T , z ( t ) , 1 ≤ t ≤ T , n T , K T , L m,T . 2: Initialize: set t = 1 , N = 0 , µ i = 0 , N i = 0 , ∀ i ∈ K T . 3: while t ≥ 1 do 4: if N < z ( t ) then 5: EXPLORE 6: Of fer all contracts in K T simultaneously . 7: if Any contract x ∈ K T is accepted by the buyer then 8: Get rew ard x . Find k ∈ { 1 , 2 , . . . , n T − 1 } such that k /n T = x . 9: + + N k . 10: end if 11: + + N . 12: else 13: EXPLOIT 14: µ i = N i / N , ∀ i ∈ { 1 , 2 , . . . , n T − 1 } . 15: Of fer bundle x = ( x 1 , . . . , x m ) , which is a solution to (4) based on µ i ’ s. 16: If some x ∈ x is accepted, get reward x . 17: end if 18: + + t . 19: end while Fig. 3. pseudocode of TL VO Let N i ( t ) be the number of times contract i is accepted in an exploration step up to t . Then the sample mean estimate of P g i − 1 n T , i n T < θ ≤ g i n T , i + 1 n T , is giv en by µ i ( t ) := N i ( t ) N ( t ) . In an exploitation step, TL V O offers a b undle of m contracts chosen from L m,T , which maximizes the seller’ s estimated expected payof f. For constants θ l and θ u , let ˆ P t ( θ l < θ ≤ θ u ) be the estimate of 10 Fig. 4. an illustration of the sample mean update of buyer’ s type distribution when contract i is accepted at time t P ( θ l < θ ≤ θ u ) at time t . TL V O computes this estimate based on the estimates µ i ( t ) in the follo wing way: ˆ P t ( θ l < θ ≤ θ u ) = j + ( θ u ) X i = j − ( θ l ) µ i ( t ) , where j − ( θ l ) = min i ∈ { 1 , . . . , n T − 1 } such that g i − 1 n T , i n T ≥ θ l , and j + ( θ u ) = min i ∈ { 1 , . . . , n T − 1 } such that g i n T , i + 1 n T ≥ θ u . W e can write x i ∈ L m,T as k i /n T for some k i ∈ { 1 , 2 , . . . , n T − 1 } . If time t is an exploitation step, TL V O computes the estimated best bundle of contracts x ( t ) by solving the following optimization problem. x ( t ) = arg max x ∈L m,T ˆ U t ( x ) , (4) where ˆ U t ( x ) := x 1 ˆ P t ( g (0 , x 1 ) < θ ≤ g ( x 1 , x 2 )) + x 2 ˆ P t ( g ( x 1 , x 2 ) < θ ≤ g ( x 2 , x 3 )) + . . . + x m ˆ P t ( g ( x m − 1 , x m ) < θ ) . Note that there might be more than one maximizer to (4). In such a case, TL VO arbitrarily chooses one of the maximizer bundles. Maximization in (4) is a combinatorial optimization problem. In general solution to such a problem is NP-hard. W e assume that the solution is provided to the algorithm by an oracle. This is a common assumption in online learning literature, for example used in [8]. Therefore, we do not consider the computational complexity of this operation. Although we do not provide a computationally 11 ef ficient solution for (4), there exists computationally efficient methods for some special cases. W e discuss more on this in Section VI. W e analyze the regret of TL V O in the next section. I V . A N A LY S I S O F T H E R E G R E T O F T L VO In this section we upper bound the re gret of TL V O. Let S = { x ∈ L m,T : | U ( x ∗ ) − U ( x ) | < β n − α T } , be the set of near -optimal bundles of contracts where α is the H ¨ older exponent in Assumption 1, and β = 5 mf max L 2 α/ 2 is a constant where L is the H ¨ older constant in Assumption 1. Denote the complement of S on L m,T , i.e., L m,T − S , by S c . Let T x ( t ) be the number of times x ∈ L m,T is offered at exploitation steps by time t . For TL V O, re gret giv en in (2) is upper bounded by R ( T ) ≤ X x ∈ S ( U ( x ∗ ) − U ( x )) E [ T x ( T )] + X x ∈ S c ( U ( x ∗ ) − U ( x )) E [ T x ( T )] + N ( T )( U ( x ∗ ) + c ( n T ) − c ( m )) , (5) by assuming zero worst-case payoff in exploration steps. First term in (5) is the contribution of selecting a nearly optimal bundle of contracts in exploitation steps, second term is the contribution of selecting a suboptimal bundle of contracts in the exploitation steps, and the third term is the worst-case contribution during the exploration steps to the regret. The following theorem giv es an upper bound on the regret of TL V O. Theor em 1: The re gret of the seller using TL V O with time horizon T is upper bounded by R ( T ) ≤ 5 mf max L 2 α/ 2 n − α T ( T − N ( T )) + N ( T )( U ( x ∗ ) + c ( n T ) − c ( m )) + 2 n T T X t =1 e − f 2 max L 2 2 α N ( t ) n 2+2 α T . Remark 2: In this form, the regret is linear in n T and T . The first term in the regret decreases with n T while the second and third terms increase with n T . Since T is kno wn by the seller , n T can be optimized as a function of T . Pr oof: Let δ ∗ x = U ( x ∗ ) − U ( x ) . By definition of the set S , we hav e X x ∈ S δ ∗ x E [ T x ( T )] ≤ max x ∈ S δ ∗ x X x ∈ S E [ T x ( T )] ≤ β n − α T ( T − N ( T )) . (6) 12 Next, we consider the term X x ∈ S c ( U ( x ∗ ) − U ( x )) E [ T x ( T )] . Note that ev en if we bound E [ T x ( T )] for all x ∈ S c , in the worst case | S c | = cn m T , for some c > 0 . Therefore a bound that depends on n m T will scale badly for large m . T o overcome this dif ficulty , we will sho w that if the distribution function has sufficiently accurate sample mean estimates µ i ( t ) for all p i := P g i − 1 n T , i n T < θ ≤ g i n T , i + 1 n T , i ∈ { 1 , 2 , . . . , n T − 1 } , then the probability that some bundle in S c is of fered will be small. Let T S c ( t ) be the number of times a bundle from S c is offered in exploitation steps by time t . Since for any x ∈ X m , U ( x ) ≤ 1 , we hav e X x ∈ S c ( U ( x ∗ ) − U ( x )) E [ T x ( T )] ≤ E [ T S c ( T )] , (7) where E [ T S c ( T )] = E " T X t =1 I ( x ( t ) ∈ S c ) # = T X t =1 P ( x ( t ) ∈ S c ) . (8) For con venience let x 0 = 0 , x m +1 = 1 and g ( x m , x m + 1) = 1 . For any x i ∈ x ∈ L m,T , we can write P ( g ( x i − 1 , x i ) < θ ≤ g ( x i , x i +1 )) = P ( g ( x i − 1 , x i ) < θ ≤ j − ( g ( x i − 1 , x i ))) + j + ( g ( x i ,x i +1 )) X i = j − ( g ( x i − 1 ,x i )) p i − P ( g ( x i , x i +1 ) < θ ≤ j + ( g ( x i , x i +1 ))) . Let er r x ( x i ) = | P ( g ( x i − 1 , x i ) < θ ≤ j − ( g ( x i − 1 , x i ))) − P ( g ( x i , x i +1 ) < θ ≤ j + ( g ( x i , x i +1 ))) | . Figure 5 shows the decomposition of P ( g ( x i − 1 , x i ) < θ ≤ g ( x i , x i +1 )) in terms of the acceptance regions defined by contracts in L m,T and the error terms. It is easy to see from Figure 5 that g ( x i − 1 , x i ) , j − ( g ( x i − 1 , x i )) n T ⊂ j − ( g ( x i − 1 , x i )) − 1 n T , j − ( g ( x i − 1 , x i )) n T , and g ( x i , x i +1 ) , j + ( g ( x i , x i +1 )) n T ⊂ j + ( g ( x i , x i +1 )) − 1 n T , j + ( g ( x i , x i +1 )) n T . 13 Fig. 5. decomposition of P ( g ( x i − 1 , x i ) < θ ≤ g ( x i , x i +1 )) Then, by Assumption 1, we have for any x i ∈ x ∈ L m,T er r x ( x i ) ≤ max { P ( g ( x i − 1 , x i ) < θ ≤ j − ( g ( x i − 1 , x i ))) , P ( g ( x i , x i +1 ) < θ ≤ j + ( g ( x i , x i +1 ))) } ≤ f max L 2 α/ 2 n − α T . (9) Consider the ev ent ξ t = n T − 1 \ i =1 ( | µ i ( t ) − p i | ≤ ( β − mf max L 2 α/ 2 ) n − α T 4 n T m ) . If ξ t happens, then for any 1 ≤ a < b ≤ n T − 1 b X i = a µ i ( t ) − b X i = a p i ( t ) ≤ ( b − a ) ( β − mf max L 2 α/ 2 ) n − α T 4 n T m ≤ ( β − mf max L 2 α/ 2 ) n − α T 4 m , which implies that for any x ∈ L m,T | ˆ U t ( x ) − U ( x ) | ≤ x 1 j + ( g ( x 1 ,x 2 )) X i = j − ( g (0 ,x 1 )) | µ i ( t ) − p i | + er r x ( x i ) + . . . + x m j + ( g ( x m ,x m +1 )) X i = j − ( g ( x m − 1 ,x m )) | µ i ( t ) − p i | + er r x ( x m ) ≤ j + ( g ( x 1 ,x 2 )) X i = j − ( g (0 ,x 1 )) | µ i ( t ) − p i | + er r x ( x i ) + . . . + j + ( g ( x m ,x m +1 )) X i = j − ( g ( x m − 1 ,x m )) | µ i ( t ) − p i | + er r x ( x m ) ≤ 2 mf max L 2 α/ 2 n − α T . (10) 14 Let y ∗ = arg max x ∈L m,T U ( x ) . By Assumption (1) we have U ( x ∗ ) − U ( y ∗ ) ≤ mf max L 2 α/ 2 n − α T . Then, using the definition of the set S c , which denotes the set of suboptimal b undles of contracts, for any x ∈ S c , we hav e U ( y ∗ ) − U ( x ) > ( β − mf max L 2 α/ 2 ) Ln − α T = 4 mf max L 2 α/ 2 n − α T . Since by (10) the estimated payoff of any bundle x ∈ L m,T is within 2 mf max L 2 α/ 2 n − α T of its true v alue, the ev ent ξ t implies that for any x ∈ S c ˆ U t ( x ) ≤ ˆ U t ( y ∗ ) , which means ξ t ⊂ { ˆ U t ( x ) ≤ ˆ U t ( y ∗ ) , ∀ x ∈ S c } , and { ˆ U t ( x ) > ˆ U t ( y ∗ ) for some x ∈ S c } ⊂ ξ c t . Therefore P ( x ( t ) ∈ S c ) ≤ P n T − 1 [ i =1 {| µ i ( t ) − p i | > ( β − mf max L 2 α/ 2 ) n − α T 4 n T m } ! ≤ n T − 1 X i =1 P | µ i ( t ) − p i | > ( β − mf max L 2 α/ 2 ) n − α T 4 n T m ! ≤ 2 n T e − f 2 max L 2 2 α N ( t ) n 2+2 α T , by using a Chernoff-Hoef fding bound. Using the last result in (7), we get X x ∈ S c ( U ( x ∗ ) − U ( x )) E [ T x ( T )] ≤ 2 n T T X t =1 e − f 2 max L 2 2 α N ( t ) n 2+2 α T . (11) W e get the main result by substituting (6) and (11) into (5). The following corollary giv es a sublinear regret result for a special case of parameters. Cor ollary 1: When the cost of offering n contracts simultaneously , i.e., c ( n ) ≤ n γ , for all 0 < n < T , for some γ > 0 , the regret of the seller that runs TL VO with n T = $ ( f max L 2 α/ 2 ) 2 4+2 α T log T 1 4+2 α % , z ( t ) = 1 f max L 2 α/ 2 2+6 α 2+ α T log T 2+2 α 4+2 α log t, 15 where b y c is the largest integer smaller than equal to y , is upper bounded by R ( T ) ≤ 5 m ( f max L 2 α/ 2 ) 2 2+ α (log T ) α 4+2 α T 4+ α 4+2 α + 1 f max L 2 α/ 2 2+6 α 2+ α (log T ) 2+ γ 4+2 α T 2+2 α + γ 4+2 α + 2( f max L 2 α/ 2 ) 1 2+ α (log T + 1)(log T ) 1 4+2 α T 1 4+2 α . Hence R ( T ) = O ( mT (2+2 α + γ ) / (4+2 α ) (log T ) 2 / (4+2 α ) ) , which is sublinear in T for γ < 2 . Pr oof: W e want e − f 2 max L 2 2 α N ( t ) n 2+2 α T ≤ 1 t . For this,we should have − f 2 max L 2 2 α N ( t ) n 2+2 α T ≤ − log t, which implies N ( t ) ≥ ( n T ) 2+2 α f 2 max L 2 2 α log t. (12) Note that at each time t either N ( t ) ≥ z ( t ) or z ( t ) − 1 ≤ N ( t ) < z ( t ) so we chose z ( t ) = ( n T ) 2+2 α f 2 max L 2 2 α log t + 1 . Note that z ( t ) in this form depends on n T which we hav e not fixed yet. T o hav e minimum regret, we need to balance the first and second terms of the re gret giv en in Theorem 1. Thus T /n T ≈ N ( T ) n T . Since n T must be an integer , substituting (12) into N ( T ) , we have n T = $ ( f max L 2 α/ 2 ) 2 4+2 α T log T 1 4+2 α % . Proof is completed by substituting these into the result of Theorem 1. V . A L E A R N I N G A L G O R I T H M W I T H F I X E D N U M B E R O F O FF E R S One drawback of TL VO is that in exploration steps it simultaneously of fers n T − 1 contracts, and this number increases sublinearly with T . Usually , the seller will offer dif ferent bundles of contracts but it will include same number of contracts in each bundle. For example, a wireless service pro vider usually adds new data plans by removing one of the current data plans, thus the total number of data plans 16 Fig. 6. bundles of m contracts offered in exploration steps l = 1 , 2 , . . . , l 0 in an exploration phase of fered does not change significantly over time. In this section, we are interested in the case when the seller is limited to offering m contracts at ev ery time step. In this case, the e xploration step of TL V O will not work. Because of this, we propose the algorithm type learning with fixed number of of fers (TLFO) that alw ays of fers m contracts simultaneously . TLFO dif fers from TL V O only in its exploration phase. Each exploration phase of TLFO lasts multiple time steps. Instead of simultaneously offering n T − 1 uniformly spaced contracts at an exploration step, TLFO has an exploration phase of d ( n T − 1) / ( m − 2) e steps indexed by l = 1 , 2 , . . . , d ( n T − 1) / ( m − 2) e . The idea behind TLFO is to estimate the buyer’ s type distribution from the estimates of the segments of the buyer’ s type distribution ov er dif ferent time steps of the same exploration phase. Let time t be the start of an exploration phase for TLFO. Let l 0 = d ( n T − 1) / ( m − 2) e denote the last step of the exploration phase. Next, we define the following bundles of m contracts. The ov erlapping portions of these bundles are shown in Figure 6 for l = 1 , 2 , . . . , l 0 . B 1 = 1 n T , 2 n T , . . . , m n T , ˜ B 1 = 1 n T , 2 n T , . . . , m − 1 n T , B l 0 = n T − m n T , n T − m + 1 n T , . . . , n T − 1 n T , ˜ B l 0 = ( l 0 − 1) m − 2( l 0 − 1) + 2 n T , ( l 0 − 1) m − 2( l 0 − 1) + 3 n T , . . . , n T − 1 n T , and for l ∈ { 2 , . . . , l 0 − 1 } B l = ( l − 1) m − 2( l − 1) + 1 n T , ( l − 1) m − 2( l − 1) + 2 n T , . . . , lm − 2( l − 1) n T , ˜ B l = ( l − 1) m − 2( l − 1) + 2 n T , ( l − 1) m − 2( l − 1) + 3 n T , . . . , lm − 2( l − 1) − 1 n T . 17 Similar to TL V O let N and N k , k ∈ { 1 , 2 , . . . , n T − 1 } be the counters that are used to form type distribution estimates which are set to zero initially . Basically , at an exploitation phase the estimates µ k = N k / N are formed based on the current v alues of N k and N . Different from the analysis of TL V O, N ( t ) which is the v alue of counter N at time t represents the number of completed exploration phases by time t , not the number of exploration steps by time t . The condition N ( t ) < z ( t ) is checked at the end of each exploration phase or exploitation phase, and if the condition is true, a new exploration phase starts. In the first e xploration step of the exploration phase, TLFO of fers the bundle B 1 . If a contract k /n T ∈ ˜ B 1 is accepted, N k is incremented by one. In the l th exploration step, l ∈ { 2 , . . . , l 0 − 1 } , it of fers the bundle B l . If a contract k /n T ∈ ˜ B l is accepted, N k is incremented by one. In the last exploration step l 0 , it offers B l 0 . If a contract k /n T ∈ ˜ B l 0 is accepted, N k is incremented by one. At the time t 0 when all the exploration steps in the exploration phase are completed, N is incremented by one. Pseudocode of the exploration phase for TLFO is given in Figure 7. Exploration phase of TLFO. 1: f or l = 1 , 2 , . . . , d ( n T − 1) / ( m − 2) e do 2: Of fer bundle B l . 3: Let k /n T ∈ B l be the accepted contract. Get reward k /n T . 4: if k /n T ∈ ˜ B l then 5: + + N k 6: end if 7: + + t 8: end for 9: + + N Fig. 7. pseudocode of the exploration phase of TLFO Note that regret of the seller in this case is upper bounded by R ( T ) ≤ X x ∈ S ( U s ( x ∗ ) − U s ( x )) E [ T x ( T )] + X x ∈ S c ( U s ( x ∗ ) − U s ( x )) E [ T x ( T )] + N ( T ) d ( n T − 1) / ( m − 2) e ( U ( x ∗ )) . (13) By the exploration phase of TLFO, the accurac y of the estimates µ i ( t ) at the be ginning of each exploitation 18 phase is the same as TL VO. Moreo ver , the the regret due to near-optimal exploitations can be upper bounded by the same term as in TL VO. Only the regret due to explorations changes. The number of exploration steps of TLFO is about ( n T − 1) / ( m − 2) times the number of exploration steps of TL VO, but there is no cost of offering more than m (possibly a large number of) contracts in TLFO. The following theorem and corollary giv es an upper bound on the regret of TLFO, by using an approach similar to the proofs of Theorem 1 and Corollary 1. Theor em 2: The re gret of seller using TLFO with time horizon T is upper bounded by R ( T ) ≤ 5 mf max L 2 α/ 2 n − α T ( T − N ( T )) + N ( T ) n T − 1 m − 2 + 1 U ( x ∗ ) + 2 n T T X t =1 e − f 2 max L 2 2 α N ( t ) n 2+2 α T . Since TLFO simultaneously offers m contracts both in explorations and exploitations, its regret does not depend on the cost function c ( . ) of offering multiple contracts simultaneously . Therefore our sublinear regret bound always holds independent of c ( . ) . Cor ollary 2: When the seller runs TLFO with time horizon T and n T = $ ( f max L 2 α/ 2 ) 2 4+2 α T log T 1 4+2 α % , z ( t ) = 1 f max L 2 α/ 2 2+6 α 2+ α T log T 2+2 α 4+2 α log t, we hav e R ( T ) = C m + mT (3+2 α ) / (4+2 α ) (log T ) 2 / (4+2 α ) , uniformly ov er T for some constant C m > 0 . Hence, R ( T ) = O ( mT (3+2 α ) / (4+2 α ) (log T ) 2 / (4+2 α ) ) . V I . D I S C U S S I O N A contract design problem for a secondary spectrum market is studied in [12]. In this work the authors assume that the type distribution f ( θ ) is kno wn by the seller , and the y characterize the optimal set of contracts. They show that when the channel condition is common to all types, i.e., probability that the channel is idle is the same for all types of users, a computationally ef ficient procedure exists for choosing the best b undle of m contracts out of L m,T . This procedure can be used by the seller to ef ficiently solve (4). 19 In the fixed number of of fers case, we assume that at each time step the seller of fers a bundle ( x 1 , x 2 , . . . , x m ) ⊂ X m ⊂ [0 , 1] m . Therefore, the strategy set is a subset of the m -dimensional unit cube. Because of this relation, we can compare the performance of our contract learning algorithms with bandit algorithms for high dimensional strategy sets. For example, if the re ward from any bundle x were of linear form, i.e., U ( x ) = C · x for some C ∈ R m , then the online stochastic linear optimization algorithm in [8] would giv e regret O (( m log T ) 3 / 2 √ T ) . Ho wev er , in our problem U ( x ) is not a linear function, thus this approach will not work. One can also show that in general U ( x ) is neither con ve x or nor concav e, therefore any bandit algorithm exploiting these properties will not work in our setting. Another work, [13], considers online linear optimization in a general topological space. For an m - dimensional strategy space, they prove a lower bound of ˜ O ( T ( m +1) / ( m +2) ) . Therefore, our bound is better than their lower bound for m > 2 + 2 α . This is not a contradiction since in our problem it is the type θ that is drawn independently at each time step, not the rew ards of the indi vidual contracts, and we focus on estimating the expected rewards of arms (b undles of contracts) from the type distrib ution. In the same paper, a ˜ O ( √ T ) regret upper bound is also prov ed, under the assumption that the mean reward function is locally equiv alent to a bi-H ¨ older function near any maxima, i.e., ∃ c 1 , c 2 , 0 > 0 such that for || x − x 0 || ≤ 0 c 1 || x − x 0 || α ≤ | U ( x ) − U ( x 0 ) | ≤ c 2 || x − x 0 || α . Ho we ver , in this paper , we only require a H ¨ older condition for the boundaries of the acceptance regions (see Assumption 1), which implies that | U ( x ) − U ( x 0 ) | ≤ c 3 || x − x 0 || α , for some c 3 > 0 and ∀ x , x 0 ∈ X m . R E F E R E N C E S [1] R. Agraw al, “The continuum-armed bandit problem, ” SIAM journal on control and optimization , vol. 33, p. 1926, 1995. [2] R. Kleinberg, “Nearly tight bounds for the continuum-armed bandit problem, ” Advances in Neural Information Pr ocessing Systems , vol. 17, pp. 697–704, 2004. [3] E. Cope, “Regret and conv ergence bounds for a class of continuum-armed bandit problems, ” Automatic Control, IEEE T ransactions on , vol. 54, no. 6, pp. 1243–1253, 2009. [4] P . Auer , R. Ortner , and C. Szepesv ´ ari, “Improved rates for the stochastic continuum-armed bandit problem, ” Learning Theory , pp. 454–468, 2007. [5] Y . Gai, B. Krishnamachari, and R. Jain, “Combinatorial network optimization with unknown variables: Multi-armed bandits with linear rewards and individual observations, ” to appear in IEEE/ACM T rans. Netw . , 2012. 20 [6] Y . Gai, B. Krishnamachari, and M. Liu, “Online learning for combinatorial network optimization with restless Markovian rew ards, ” to appear in the 9th Annual IEEE Communications Society Conference on Sensor , Mesh and Ad Hoc Communications and Networks (SECON) , June 2012. [7] P . Bartlett, V . Dani, T . Hayes, S. Kakade, A. Rakhlin, and A. T ewari, “High-probability regret bounds for bandit online linear optimization, ” 2008. [8] V . Dani, T . Hayes, and S. Kakade, “Stochastic linear optimization under bandit feedback, ” in Pr oceedings of the 21st Annual Confer ence on Learning Theory (COLT) , 2008. [9] R. Kleinberg, A. Slivkins, and E. Upfal, “Multi-armed bandits in metric spaces, ” in Pr oceedings of the 40th annual ACM symposium on Theory of computing . A CM, 2008, pp. 681–690. [10] J. Langford and T . Zhang, “The epoch-greedy algorithm for contextual multi-armed bandits, ” Advances in Neural Information Pr ocessing Systems , vol. 20, 2007. [11] A. Sli vkins, “Contextual bandits with similarity information, ” Arxiv pr eprint arXiv:0907.3986 , 2009. [12] S. P . Sheng and M. Liu, “Optimal contract design for an efficient secondary spectrum market, ” in 3r d International Confer ence on Game Theory for Networks (GAMENETS) , 2012. [13] S. Bubeck, R. Munos, G. Stoltz, and C. Szepesvari, “Online Optimization in X-Armed Bandits, ” in T wenty-Second Annual Confer ence on Neural Information Pr ocessing Systems , V ancouver , Canada, 2008. [Online]. A vailable: http://hal.inria.fr/inria- 00329797
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment