확률적 헤시안 프리 최적화로 딥러닝 학습 효율 높이기
본 논문은 기존의 헤시안 프리(Hessian‑free, HF) 방법을 확률적(mini‑batch) 환경에 적용한 Stochastic Hessian‑free(SHF) 알고리즘을 제안한다. 그래디언트와 곡률(헤시안‑벡터) 연산을 각각 작은 미니배치로 수행하고, 짧은 CG 반복, δ‑모멘텀, 부드러운 Levenberg‑Marquardt 감쇠, 그리고 드롭아웃을 결합해 일반화 성능을 유지하면서도 SGD와 HF 사이의 중간 단계 성능을 달성한다. 실험 …
저자: Ryan Kiros
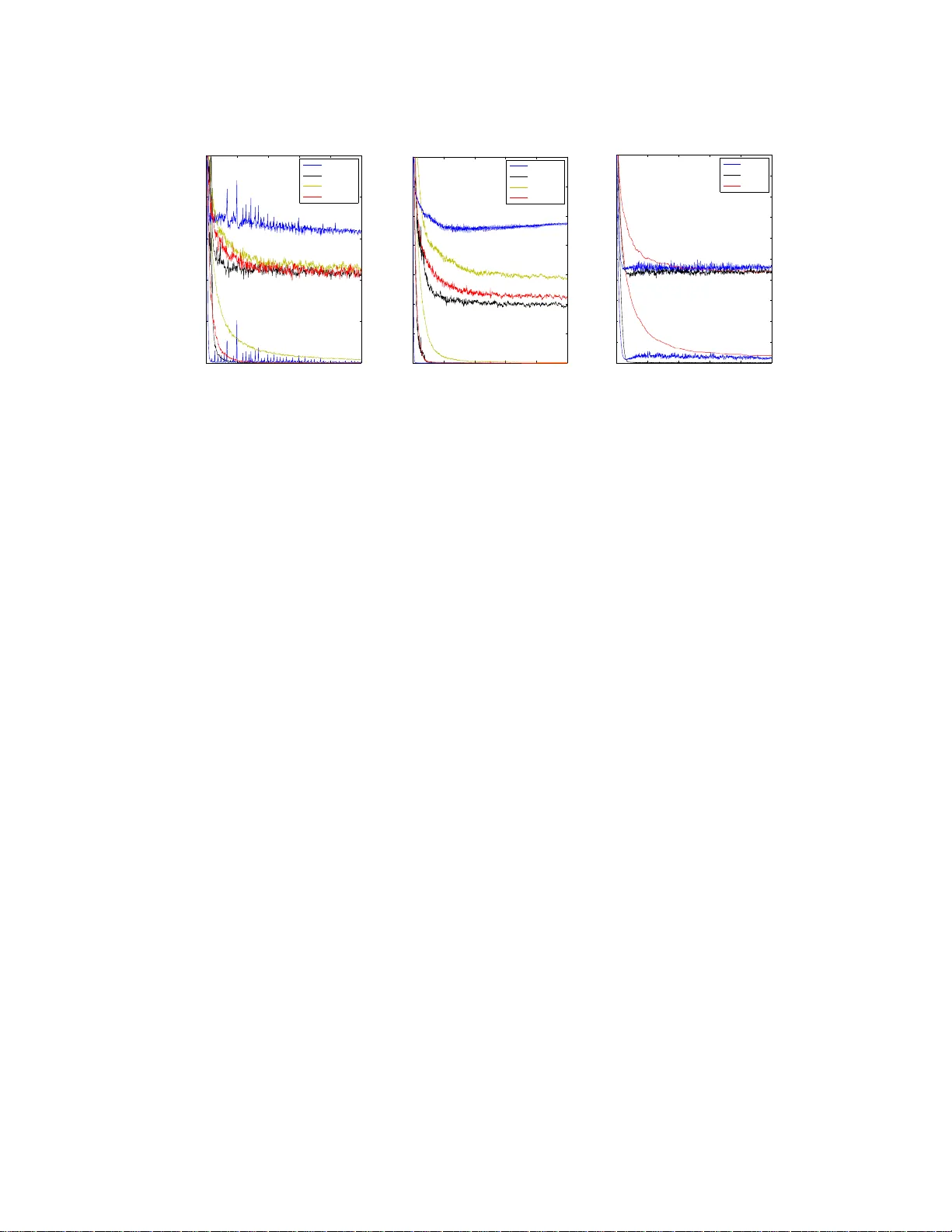
본 논문은 Hessian‑free(HF) 최적화가 딥 오토인코더와 순환 신경망 학습에 성공적으로 적용된 사례를 바탕으로, 이를 확률적(mini‑batch) 환경에 맞게 변형한 Stochastic Hessian‑free(SHF) 알고리즘을 제안한다. HF는 곡률‑벡터 곱셈을 이용해 업데이트 방향을 구하고, 이 연산은 순전파와 역전파와 동일한 복잡도로 수행될 수 있다는 장점이 있다. 그러나 기존 HF는 전체 데이터셋을 사용해 목적 함수와 그래디언트를 계산하고, 곡률 연산만 미니배치로 수행하기 때문에 대규모 데이터에 직접 적용하기엔 비효율적이다.
### 1. SHF 설계 원칙
- **그래디언트와 곡률 미니배치 독립**: 전체 데이터에 의존하지 않고, 각각 별도의 미니배치를 사용해 그래디언트와 곡률‑벡터를 추정한다.
- **짧은 CG 반복**: 학습 전반에 걸쳐 CG 반복 횟수를 고정(분류 3~5회, 오토인코더 25~50회)하여 연산 비용을 일정하게 유지한다. 이는 기존 HF에서 λ가 작아질수록 CG가 많이 필요해지는 문제를 완화한다.
- **δ‑모멘텀(δ‑momentum)**: 이전 단계의 CG 해를 초기값으로 사용하고, 매 epoch마다 감소율 γₑ를 조정한다(γₑ = min(1.01·γₑ₋₁, 0.99)). 초기에는 작은 모멘텀, 후기에는 거의 1에 가까운 모멘텀을 적용해 정보 공유를 강화한다.
- **부드러운 Levenberg‑Marquardt 감쇠**: 기존 HF의 λ 업데이트(ρ>3/4 → λ←2/3λ, ρ<1/4 → λ←3/2λ)를 완화하여 ρ>3/4 → λ←99/100λ, ρ<1/4 → λ←100/99λ 로 바꾼다. 이는 미니배치 기반 곡률 추정의 노이즈에 대한 민감도를 낮춘다.
- **그래디언트와 곡률 배치 크기 차별화**: 분류 과제에서는 곡률 배치를 작게(예: 32), 그래디언트 배치를 5~10배 크게 설정해 CG 연산량을 보완하고 λ가 0에 수렴하는 것을 방지한다. 오토인코더와 같이 CG 반복이 많을 경우 두 배치를 동일하게 잡는다.
### 2. 드롭아웃 통합
드롭아웃은 학습 시 은닉 유닛을 0.5 확률로 비활성화하고, 테스트 시 가중치를 절반으로 스케일링한다. SHF에 드롭아웃을 적용하면 그래디언트와 곡률 연산 모두에서 무작위 유닛 제거가 이루어져, 특성 검출기 간 공동 적응을 방지하고 모델 평균화 효과를 얻는다. 실험에서는 드롭아웃 사용 시 λ가 0으로 수렴하지 않고 일정 수준을 유지하면서도 일반화 성능이 크게 향상되는 것을 확인하였다.
### 3. 알고리즘 흐름
1. 현재 파라미터 θ에 대해 **그래디언트 미니배치**를 사용해 ∇f(θ)와 목적 함수 값을 계산한다.
2. **곡률 미니배치**를 이용해 Gauss‑Newton 근사 B = JᵀL″J 를 구성하고, R‑operator와 역전파를 통해 B·v 연산을 구현한다.
3. 고정된 CG 반복 수 ζ만큼 수행한다. 초기값은 이전 CG 해에 δ‑모멘텀 γₑ·δ_{k‑1}을 곱한 값이다.
4. CG 결과 δ̂를 사용해 **백트래킹 라인서치**와 **λ 업데이트**(부드러운 LM 규칙)로 최종 업데이트 방향을 결정한다.
5. 필요 시 **드롭아웃 마스크**를 재생성하고, 위 과정을 다음 미니배치에 대해 반복한다.
### 4. 실험 설정 및 결과
- **분류**: MNIST, CIFAR‑10 등에서 SHF(드롭아웃 포함)와 전통적인 SGD(드롭아웃 포함)를 비교. 정확도 차이는 미미했으며, SHF는 3~5번의 CG 반복만으로도 SGD와 동등한 수렴 속도를 보였다.
- **깊은 오토인코더**: 5~7개의 은닉층을 가진 모델에 대해 SHF, 기존 HF, 모멘텀 기반 2차 최적화(예: L‑BFGS, KSD)를 비교. SHF는 재구성 오류가 가장 낮았으며, 학습률 튜닝이 거의 필요 없었다. 특히 λ가 0에 수렴하지 않아 CG가 과도하게 반복되지 않았다.
- **연산 효율**: 전체 연산량은 SGD와 비슷하거나 약간 높았지만, 2차 정보를 활용함으로써 에포크당 진행 정도가 크게 향상되어 전체 학습 시간은 비슷하거나 더 짧았다.
### 5. 의의 및 한계
SHF는 HF의 2차 정보 활용과 SGD의 확률적 일반화 장점을 결합한 중간 지점 알고리즘으로, 대규모 데이터와 깊은 네트워크에 적용 가능하다. 짧은 CG 반복, 동적 λ 감쇠, δ‑모멘텀, 그리고 드롭아웃 통합이라는 설계는 각각의 단점을 보완하고 전체적인 안정성을 높인다. 다만, 현재 구현은 미니배치 크기와 CG 반복 수에 대한 경험적 설정에 의존하며, 복잡한 모델(예: 대규모 Transformer)에서는 추가적인 메모리/연산 최적화가 필요할 수 있다. 향후 연구에서는 자동화된 하이퍼파라미터 스케줄링과 분산 환경에서의 효율적인 곡률‑벡터 연산을 탐색할 여지가 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기