Training Neural Networks with Stochastic Hessian-Free Optimization
Hessian-free (HF) optimization has been successfully used for training deep autoencoders and recurrent networks. HF uses the conjugate gradient algorithm to construct update directions through curvature-vector products that can be computed on the sam…
Authors: Ryan Kiros
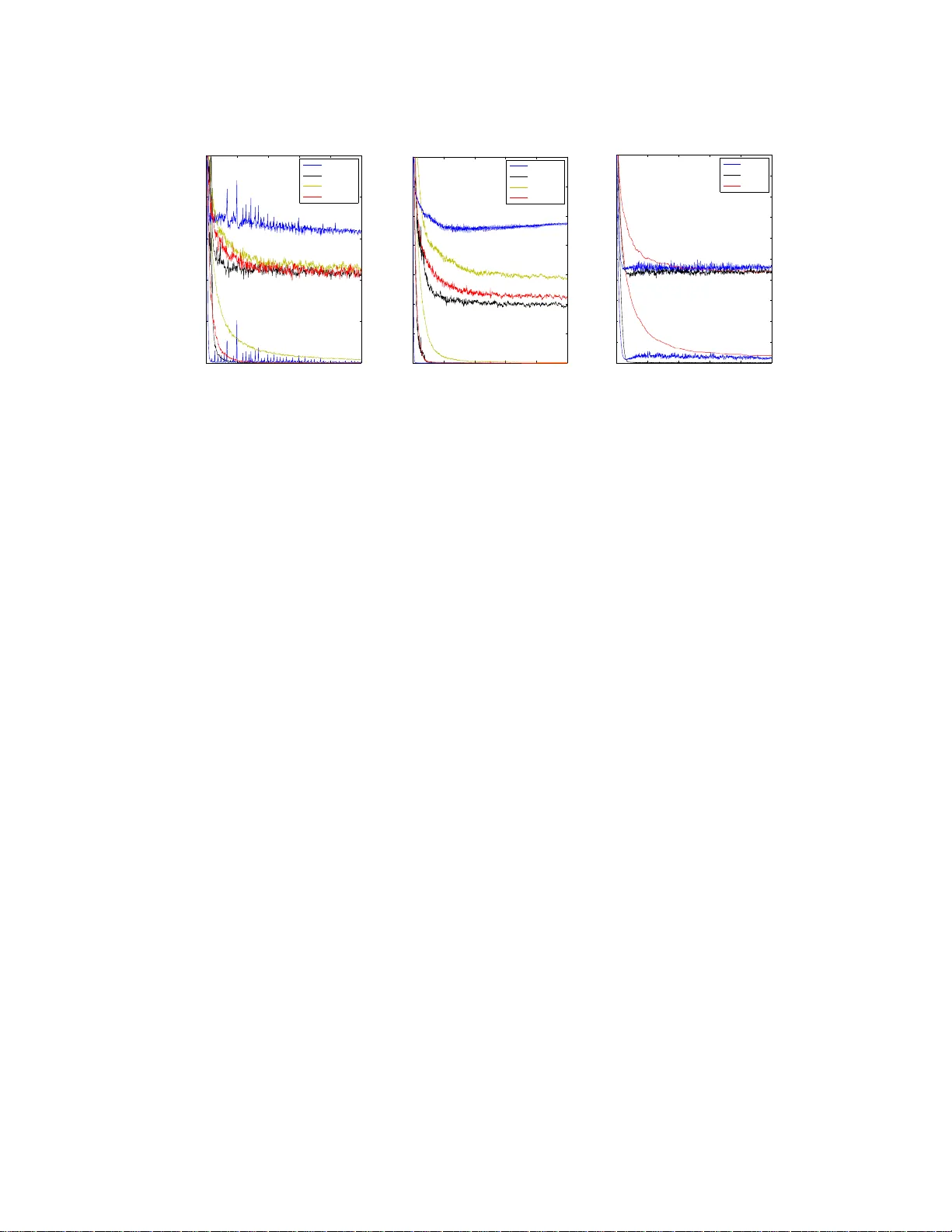
T raining Neural Network s with St ochastic Hessian-F r ee Opt imization Ryan Kiros Departmen t of C ompu ting Science University of Alberta Edmon ton, AB, Canada rkiros@ualbe rta.ca Abstract Hessian-free (HF) optimization has b een successfully used for training deep au- toencod ers and r ecurren t n etworks. H F uses the con jugate grad ient algorith m to construct update directio ns through curvature-vector prod ucts that can be com- puted on the same order of time as gradien ts. I n this paper we e xploit this prop erty and study stochastic HF with grad ient and curvature mini-batches independe nt of the dataset size. W e mo dify Martens’ HF for these settings and integrate dropout, a method fo r preventing co-adap tation of feature detectors, to gu ard against over- fitting. Stochastic He ssian-free optimizatio n giv es an intermediar y between SGD and HF that achiev es co mpetitive performance on both classifi cation and d eep autoenco der experiments. 1 Intr oduction Stochastic g radient descent (SGD) has b ecome the mo st pop ular a lgorithm for tr aining neu ral net- works. Not only is SGD sim ple to implem ent but its noisy updates o ften leads to solution s that are well-adapt to generalization on held-o ut data [1]. Furtherm ore, SGD operates on small mini-batche s potentially allowing for scalab le training on large datasets. For training deep ne tworks, SGD can be used for fine-tuning after layerwise pre-training [2] which overcom es many of the diffi culties of training dee p networks. Additionally , SGD can be aug mented with dropo ut [3] as a means of preventing overfitting. There has been recent in terest in s econd -order methods f or training deep n etworks, partially due to the successful adaptation of Hessian-free (HF) by [4], an instance of the more general family of tru ncated Newton me thods. Second-o rder method s o perate in batch settings with less but more substantial weight upd ates. Furthermo re, co mputing g radients and cu rvature in formatio n on large batches can easily be distributed acro ss several machines. Martens’ HF w as ab le to su ccessfully tr ain deep autoencod ers without the use of pre-training and was later used for solving sev eral patholo gical tasks in recurren t netw orks [5]. HF iteratively propo ses update directio ns using the conjugate gradient algorithm, requiring only curvature-vector pr oducts and not an explicit c omputatio n of t he curvature matrix. Curvature-vector produ cts can b e co mputed on the same o rder o f time as it takes to com pute gr adients with an addi- tional f orward a nd backward p ass throu gh the fu nction’ s comp utational graph [6, 7]. In this paper we exploit this pro perty and introd uce stoch astic Hessian-free optimization (SHF), a variation of HF that ope rates o n gra dient and curvature mini- batches in depend ent of th e dataset si ze. Our go al in developing SHF is to combine the generalization advantages of SGD with s econd -order infor mation from HF . SHF can adapt it s behaviour thr ough the choice of batch s ize and numb er of conjugate gradient iter ations, f or which its behaviour either be comes more c haracteristic o f SGD or HF . Ad- ditionally we integrate drop out, as a mea ns of p reventing co- adaptation of f eature detectors. W e 1 perfor m exper imental ev aluation on both classification a nd deep a utoencod er tasks. For classifica- tion, dropo ut SHF is co mpetitive with dropo ut SGD on all ta sks con sidered while f or auto encoder s SHF perfo rms comparab ly to HF and mom entum-b ased methods. Moreover , no tun ing of le arning rates needs to be done. 2 Related work Much researc h has been inv estigated into dev eloping adaptiv e learning rates or incorpo rating s econd - order inform ation into SGD. [8] prop osed aug menting SGD with a d iagonal app roximatio n o f the Hessian while Ad agrad [9] uses a glo bal learning rate wh ile dividing b y the norm of p revious gra- dients in its u pdate. SGD with Adagrad was shown to be beneficial in training de ep distrib uted networks for speech and object reco gnition [10]. T o com pletely av oid t uning lea rning rates, [ 11] considered co mputing rates as to minimize estimates of the expectation of th e loss at any o ne time. [12] p roposed SGD-QN fo r incorpo rating a quasi-Newton appr oximation to the Hessian in to SGD and used this to win one of the 2 008 P ASCAL large scale learning ch allenge track s. Recently , [ 13] provided a relationship b etween HF , Krylov subsp ace d escent and natural grad ient due to th eir u se of the Gauss-Newton curvature matrix. Furthermore, [13] argue that natural grad ient is robust to overfitting as well as the order of the training samples. Othe r methods incorporating the n atural gradient such as TONGA [14] ha ve also sho wed promise on speeding up neural network training. Analyzing the difficulty of train ing deep networks w as done by [15], prop osing a weight initial- ization th at dem onstrates faster convergence. More recently , [16] argu e that large ne ural networks waste capacity in the sen se that adding ad ditional units fail to red uce underfitting o n large datasets. The auth ors hypothe size the SGD is the cu lprit and sugg est exploration with stochastic n atural gra- dient or stoch astic second- order m ethods. Such results fu rther motivate our development of SHF . [17] show tha t with caref ul attention to th e parameter initialization and momentu m schedu le, first- order metho ds can be competitive with HF for training d eep autoen coders and recurren t network s. W e compare against these methods in our autoencod er ev aluation. Related to ou r work is that of [18], who prop oses a dyn amic ad justment of gradien t and curvature mini-batch es for HF with co n vex losses based on variance estimations. Unlike our work, the b atch sizes u sed ar e dynamic with a fixed r atio and ar e initialized a s a fun ction of the dataset size. Other work on using second -order methods for neur al networks include [19] who pr oposed using the Jacobi pre-con ditioner for HF , [2 0] using HF to gen erate text in recurrent networks and [21] who explor ed training with Krylov subspace descent (KSD). Unlike H F , KSD cou ld be used with Hessian-vector produ cts b ut req uires additional memo ry to store a basis for th e Krylov subspace. L-BFGS has also been successfully used in fine-tuning p re-trained deep au toencod ers, co n volutional networks [22] and training d eep distrib uted netw orks [10]. Oth er d ev elopme nts and detailed discussion o f gradient- based methods for neur al netw orks is describe d in [23]. 3 Hessian-free optimization In this section we review Hessian-free optimization, largely following the imp lementation o f Martens [4]. W e re fer the reader to [24] for detailed development a nd tips for using HF . W e co nsider un constrained minim ization of a function f : R n → R with respect to parameter s θ . More specifically , we assume f can be written as a compo sition f ( θ ) = L ( F ( θ )) wher e L is a conv ex lo ss function and F ( θ ) is th e o utput of a neur al network with ℓ no n-inpu t layers. W e will mostly focus o n the cas e when f is non- conv ex. T ypically L is ch osen to b e a matching loss to a corre sponding transfer fun ction p ( z ) = p ( F ( θ )) . For a single input, the ( i + 1) -th layer o f the network is expressed as y i +1 = s i ( W i y i + b i ) (1) where s i is a transfer f unction, W i is the weights connectin g layers i an d i + 1 and b i is a bias vector . Common tr ansfer fu nctions include the sigm oid s i ( x ) = (1 + exp ( − x )) − 1 , the hyp erbolic tangen t s i ( x ) = tanh ( x ) an d rectified linear un its s i ( x ) = max ( x, 0) . In the case of classification tasks, th e 2 loss function used is the generalize d cross entropy and softmax transfer L ( p ( z ) , t ) = − k X j =1 t j log ( p ( z j )) , p ( z j ) = exp ( z j ) / k X l =1 exp ( z l ) (2) where k is the n umber o f classes, t is a target vector and z j the j -th com ponent of outp ut vector z . Consider a local quadratic approx imation M θ ( δ ) of f aro und θ : f ( θ + δ ) ≈ M θ ( δ ) = f ( θ ) + ∇ f ( θ ) T δ + 1 2 δ T B δ (3) where ∇ f ( θ ) is the gradient of f and B is the Hess ian or a n appr oximation to th e Hessian. I f f was conve x, then B 0 an d equatio n 3 exhibits a minimum δ ∗ . In Newton’ s method , θ k +1 , the parameters at iteration k + 1 , are upd ated as θ k +1 = θ k + α k δ ∗ k where α k ∈ [0 , 1] is th e rate and δ ∗ k is computed as δ ∗ k = − B − 1 ∇ f ( θ k − 1 ) (4) for which calculatio n requires O ( n 3 ) time and thu s often prohibitive. Hessian-free optimization alleviates this by using the con jugate grad ient (CG) algorithm to comp ute an approximate min imizer δ k . Specifically , CG minimizes the quadr atic objecti ve q ( δ ) g i ven by q ( δ ) = 1 2 δ T B δ + ∇ f ( θ k − 1 ) T δ (5) for which the correspo nding minimizer of q ( δ ) is − B − 1 ∇ f ( θ k − 1 ) . T he motiv ation for using CG is as follows: while computin g B is expensive, comp ute th e pro duct B v fo r some vector v can b e computed on the same order of time as it takes to com pute ∇ f ( θ k − 1 ) using the R-operator [6]. Thus CG can efficiently comp ute an iterative so lution to the linear system B δ k = −∇ ( f ( θ k − 1 )) correspo nding t o a new update direction δ k . When f is non-conve x, the Hessian may not be positi ve semi-definite and thus equation 3 no long er has a well defined minimum. Following M artens, we instead use the g eneralized Gauss-newton matrix de fined as B = J T L ′′ J where J is the Jacob ian of f and L ′′ is th e Hessian o f L 1 . So long as f ( θ ) = L ( F ( θ )) for conv ex L th en B 0 . Given a vector v , the product B v = J T L ′′ J v is computed successi vely by first computin g J v , the n L ′′ ( J v ) and finally J T ( L ′′ J v ) [7 ]. T o comp ute J v , we utilize the R-operator . Th e R-operator of F ( θ ) with resp ect to v is defined as R v { F ( θ ) } = lim ǫ → 0 F ( θ + ǫv ) − F ( θ ) ǫ = J v (6) Computing R v { F ( θ ) } in a neur al network is easily do ne using a f orward pass b y com puting R v { y i } for each layer output y i . More specifically , R v { y i +1 } = R v { W i y i + b i } s ′ i = ( v ( W i ) y i + v ( b i ) + W i R{ y i } ) s ′ i (7) where v ( W i ) is the co mponen ts o f v correspond ing to p arameters between layers i and i + 1 an d R{ y 1 } = 0 (whe re y 1 is the input data). In or der to co mpute J T ( L ′′ J v ) , we simp ly apply back- propag ation b ut using the vector L ′′ J v instead of ∇ L as is usua lly done to comp ute ∇ f . Thus, B v may be compu ted thro ugh a forward and backward pass in the same sense that L and ∇ f = J T ∇ L are. As oppo sed to minimizing eq uation 3 , Martens in stead uses an addition al damping param eter λ with damped quadr atic appr oximation ˆ M θ ( δ ) = f ( θ ) + ∇ f ( θ ) T δ + 1 2 δ T ˆ B δ = f ( θ ) + ∇ f ( θ ) T δ + 1 2 δ T ( B + λI ) δ (8) Damping the quadra tic through λ gives a measure of how conservati ve th e quadratic approxim ation is. A large value o f λ is mor e conservativ e an d as λ → ∞ updates become similar to s tochastic gradient d escent. Alternatively , a small λ allows for more substantial param eter upd ates especially 1 While an abuse of definition, we still refer to “curv ature-vector products” and “curv ature batches” even when B is used. 3 along low curvature directions. Mar tens dynam ically adjusts λ at each iteration using a Levenberg- Marquar dt style up date based on computing the reduction ratio ρ = ( f ( θ + δ ) − f ( θ )) / ( M θ ( δ ) − M θ (0)) (9) If ρ is sufficiently small or n egati ve, λ is increased while if ρ is large then λ is decreased. Th e number of CG iterations used to c ompute δ h as a d ramatic effect on ρ wh ich is f urther discussed in section 4.1. T o acce lerate CG, Martens makes use of the diagonal pre-conditio ner P = diag m X j =1 ∇ f ( j ) ( θ ) ⊙ ∇ f ( j ) ( θ ) + λI ξ (10) where f ( j ) ( θ ) is the v alue of f for datapoint j and ⊙ den otes compon ent-wise m ultiplication. P ca n be easily compu ted on the s ame backward pass as computing ∇ f . Finally , two backtracking m ethods are u sed: one after optimizin g CG to select δ and the o ther a backtrack ing linesear ch to co mpute the r ate α . Bo th these methods op erate in the standar d w ay , backtrack ing through proposals until the ob jectiv e no long er decreases. 4 Stochastic Hessian-fre e optimization Martens’ imp lementation utilizes th e full dataset for co mputing objective v alues and g radients, and mini-batch es for compu ting curvature-vector products. Nai vely setting both b atch sizes to be small causes several problems. In this section we describe these pro blems and our contributions in mod i- fying Martens’ original algorith m to this setting. 4.1 Short CG runs, δ -momentum and use of mini-batches The CG termin ation criteria used b y Martens is based on a measure of relative progress in optimizing ˆ M θ . Specifically , i f x j is the solution at CG iteration j , then training is terminated when ˆ M θ ( x j ) − ˆ M θ ( x j − k ) ˆ M θ ( x j ) < ǫ (11) where k = max (10 , j / 10) and ǫ is a small positive co nstant. The effect of this stoppin g criteria has a depen dency on the streng th of th e dampin g parame ter λ , among other attributes such as the current p arameter settings. For sufficiently large λ , CG only req uires 10-2 0 itera tions when a pre - condition er is used. As λ decreases, m ore iteratio ns are req uired to acco unt for patholog ical curva- ture th at can o ccur in optimizin g f and thus lea ds to more expensive CG iterations. Such behavior would be und esirable in a stochastic setting wher e p referen ce would b e put to wards having equal length CG iterations th rough out training . T o account for this, we fix the numb er of CG iterations to be only 3-5 across trainin g for class ification and 25-50 for training deep autoen coders. Let ζ den ote this cut-off. Setting a limit on the n umber o f CG iterations is u sed by [4] and [20] and also ha s a damping ef fect, since the objective function and quadratic a pprox imation will tend to di verge as CG iterations increa se [24]. W e no te that due to the sho rter n umber of CG ru ns, the iterates fro m each solution are used during the CG backtrack ing s tep. A con tributor to the success o f Marten s’ HF is the use of informatio n sharing across iterations. At iteration k , CG is initialized to b e th e pr evious solution of CG f rom iteratio n k − 1 , with a small decay . For the rest of this work, we den ote th is a s δ -mo mentum . δ -mo mentum help s c orrect propo sed u pdate d irections when the quad ratic appro ximation varies across iterations, in the sam e sense that mom entum is used to share gra dients. This m omentum interpr etation was first suggested by [24] in th e context o f adapting HF to a setting with sh ort CG ru ns. Unfortu nately , the u se of δ - momentu m beco mes challenging when short CG runs are used. Given a non-zero CG initialization, ˆ M θ may be more likely to remain positive a fter terminating CG an d assuming f ( θ + δ ) − f ( θ ) < 0 , means th at the reduction ratio will be negative and thus λ will be incre ased to co mpensate. While this is not necessarily unwanted beh avior , having this occ ur too fre quently will pu sh SHF to be too c onservati ve and possibly re sult in the b acktrackin g linesearch to reject p roposed updates. Our 4 solution is to u tilize a sched ule on the am ount of decay u sed on the CG starting solu tion. This is motiv ated by [24] suggesting more attention on the CG decay in the setting of u sing short CG runs. Specifically , if δ 0 k is the initial solution to CG at iteration k , then δ 0 k = γ e δ ζ k − 1 , γ e = min (1 . 01 γ e − 1 , . 99) (12) where γ e is the decay at epoch e , δ 0 1 = 0 and γ 1 = 0 . 5 . While in batch training a fixed γ is suitable, in a stochastic setting it is un likely that a glob al decay p arameter is sufficient. Our sched ule has an annealing effect in the sense that γ values near 1 are feasible late in trainin g e ven wit h on ly 3-5 CG iterations, a prop erty that is otherwise h ard to achieve. T his allows us to benefit f rom sharin g more informa tion across iteration s late in training, similar to that of a typical momentum method. A remainin g question to consider is how to set the sizes o f the gradien t and curvature m ini-batche s. [24] discuss theor etical ad vantages to u tilizing the same mini-batches fo r co mputing th e gradient and curvature vector prod ucts. In o ur setting, this m ay lead to some difficulties. Using same-sized batches allows λ → 0 dur ing tr aining [2 4]. Un fortun ately , this ca n become in compatib le with ou r short hard-limit on the number of CG iterations, since CG req uires mor e work to op timize ˆ M θ when λ approach es ze ro. T o account for this, o n c lassification tasks where 3-5 CG iterations are used, we opt to use g radient mini-batches that are 5- 10 times larger than curvature m ini-batches. For deep autoenco der tasks where more CG iterations a re used, we instead set bo th g radient a nd curvature batches to b e the same size. The b ehavior of λ is depen dent on whether or n ot dropou t is used during training . Figure 1 demo nstrates th e behavior of λ dur ing classification train ing with and witho ut the use of dropout. W ith dro pout, λ n o lo nger converges to 0 but instead plummets, rises and flatten s out. In both settings, λ d oes not decr ease substantially as to negativ ely effect the propo sed CG solution an d c onsequen tly the red uction ra tio. T hus, th e amoun t of work requir ed by CG remains co nsistent late in training. The o ther benefit to using larger grad ient batches is to ac count for the addition al compu tation in co mputing cu rvature-vector products which would make training longer if both mini-batch es were small and of the same size. In [4], the grad ients and objecti ves are computed using the full training set through out the algorithm, includin g dur ing CG backtracking and the backtrack ing linesearch. W e utilize the gradient mini-batch for the current iteration in order to compute all necessary gradient and objectives throug hout the algor ithm. 4.2 Levenber g-Marquardt damping Martens makes use of the followi ng Lev enberg-M arquardt style da mping criteria for updating λ : if ρ > 3 4 , λ ← 2 3 λ else if ρ < 1 4 , λ ← 3 2 λ (13) which g iv en a su itable initial value will c on verge to zer o as training progr esses. W e observed that the above d amping criteria is too h arsh in th e sto chastic setting in the sense that λ will fre quently oscillate, wh ich is sensible g iv en the size of the curvature mini-batches. W e instead opt fo r a much softer criterion, for which lambda is updated as if ρ > 3 4 , λ ← 99 100 λ else if ρ < 1 4 , λ ← 100 99 λ (14) This choice, altho ugh somewhat ar bitrary , is con sistently effective. Thus reduction r atio v alues computed from curvature mini-batches will have less o verall influence on the damping st rength . 4.3 Integrating dropout Dropou t is a recently prop osed method for impr oving the training of neural networks. Durin g train- ing, e ach hidde n u nit is omitted with a p robability of 0.5 a long with op tionally omitting inpu t f ea- tures similar to that of a denoising autoenc oder [25]. Dro pout can b e viewed in two ways. By random ly om itting fea ture detectors, dropout p rev ents co -adaptation amon g d etectors which can im- prove gen eralization accuracy on held-ou t data. Secondly , d ropou t can be seen as a type of mod el av eraging . At test time, outgo ing weights are halved. If we consider a network with a single hidden layer and k feature detectors, using the mean network at test time corresponds to taking the geomet- ric a verage of 2 k networks with shared weights. Dropo ut is integrated in stochastic HF by randomly omitting f eature d etectors on both gradie nt and curv ature mini-batch es from the last hid den layer 5 0 100 200 300 400 500 0 0.2 0.4 0.6 0.8 1 Epoch lambda 0 200 400 600 800 1000 0 0.2 0.4 0.6 0.8 1 Epoch lambda Figure 1: V alu es o f th e dam ping strength λ durin g trainin g of MNIST (left) and USPS ( right) with and without dropo ut using λ = 1 for classification. When dropout is in cluded, the dam ping strength initially decreases followed by a steady incre ase over time. during each iteration. Sin ce we assume th at the cu rvature mini-batches ar e a sub set of the grad ient mini-batch es, the same featur e detectors are omitted in both cases. Since the curvature estimates are noisy , it is imp ortant to consider the stability of updates when different stochastic networks are used in each com putation. T he weight update s in dropout SGD are au gmented with m omentum not only fo r stab ility but also to speed up learning . Specifically , at iteration k the parameter update is given by ∆ θ k = p k ∆ θ k − 1 − (1 − p k ) α k h∇ f i , θ k = θ k − 1 + ∆ θ k (15) where p k and a k are the mo mentum an d learning rate, respecti vely . W e incor porate an additional exponential decay term β e when perfo rming p arameter upd ates. Specifically , each parameter u pdate is computed as θ k = θ k − 1 + β e α k δ k , β e = cβ e − 1 (16) where c ∈ (0 , 1] is a fixed pa rameter cho sen by the user . Incorpo rating β e into th e upd ates, along with the use of δ -momentum, leads to m ore stab le updates and fine co n vergence particularly whe n dropo ut is integrated during training. 4.4 Algorithm Pseudo-co de for one iteratio n of o ur implementa tion of stochastic Hessian- free is p resented. Gi ven a gradien t minibatch X g k and curvature minibatch X c k , we first sample dro pout units (if applicab le) for the in puts and last hidde n layer of the network. These take the form of a binary v ector, which are multiplied co mponen t-wise by the activations y i . In our pseudo-c ode, CG ( δ 0 k , ∇ f , P, ζ ) is u sed to denote ap plying CG with initial solu tion δ 0 k , gr adient ∇ f , pre- condition er P and ζ iterations. Note that, when compu ting δ -m omentum , the ζ -th solu tion in iteratio n k − 1 is used as o pposed to the solution chosen via back tracking. Given the objectives f k − 1 computed with θ and f k computed with θ + δ k , the reduction ratio ρ is calc ulated utilizing the un-damp ed q uadratic approximation M θ ( δ k ) . This allows updating λ using the Lev enberg-M arquard t style damping. Fin ally , a backtrackin g line- search with at most ω steps is perf ormed to compute the rate and serves as a last d efense against potentially poor update directions. Since curvature mini-batches are sampled from a subset of the gradient m ini-batch, it i s then sensible to utilize different curvature mini-batche s on different epochs. Along with cycling throug h grad ient mini-batch es d uring each epoch, we also cycle th rough curvature subsets e very h epochs, where h is the size of the g radient mini-b atches divided b y t he size of the curvature min i-batches. For e xample, if the gr adient batch size is 1000 and the cu rvature batch size is 100, then curvature mini-batch sampling completes a full cycle e very 1000/100 = 10 epochs. Finally , o ne simple way to speed up tr aining as indicated in [ 24], is to cache the acti vations when initially com puting the objecti ve f k . While eac h iteration of CG requ ires computin g a curvature- vector pro duct, the n etwork param eters are fixed du ring CG a nd is thu s wasteful to re-comp ute the network acti vations on each iteration . 6 Algorithm 1 Stochastic Hessian-Free Optimization X g k ← gradien t minibatch, X c k ← curvature minib atch, | X g k | = h | X c k | , h ∈ Z + Sample dropo ut un its for inputs and last hidden layer if start of new epoc h then γ e ← min (1 . 01 γ e − 1 , . 99) { δ -mo mentum} end if δ 0 k ← γ e δ ζ k − 1 f k − 1 ← f ( X g k ; θ ) , ∇ f ← ∇ f ( X g k ; θ ) , P ← Precon( X g k ; θ ) Solve ( B + λI ) δ k = −∇ f using CG ( δ 0 k , ∇ f , P, ζ ) {Using X c k to comp ute B δ k } f k ← f ( X g k ; θ + δ k ) {CG backtrack ing} for j = ζ - 1 to 1 do f ( θ + δ j k ) ← f ( X g k ; θ + δ j k ) if f ( θ + δ j k ) < f k then f k ← f ( θ + δ j k ) , δ k ← δ j k end if end for ρ ← ( f k − f k − 1 ) / ( 1 2 δ T k B δ k + ∇ f T δ k ) {Using X c k to comp ute B δ k } if ρ < . 2 5 , λ ← 1 . 01 λ elseif ρ > . 7 5 , λ ← . 99 λ end if α k ← 1 , j ← 0 {Backtracking linesearch} while j < ω do if f k > f k − 1 + . 01 α k ∇ f T δ k then α k ← . 8 α k , j ← j + 1 else break end if end while θ ← θ + β e α k δ k , k ← k + 1 {Parameter update} 5 Experiments W e perform experimen tal evaluation o n bo th classification and deep a utoencod er tasks. The goal of classification experim ents is to determine the effectiv eness of SHF on test error gen eralization. For autoenco der tasks, we in stead focu s just on measuring the effecti veness of the optimizer on the training data. The datasets and experiments are summarized as follows: • MNIST : Handwritten digits of size 28 × 28 with 6 0K trainin g samples and 1 0K testing samp les. For classification, we train networks of si ze 784-1200- 1200- 10 with rectifier activ ations. For deep autoenco ders, the enco der arch itecture of 78 4-100 0-500 -250-30 with a symmetric deco ding archi- tecture is u sed. Log istic activ ations a re u sed with a binar y cross entropy error . For classification experiments, the data is scaled to ha ve zero mean and unit v ariance. • CUR VES: A rtificial dataset of curves of size 28 × 28 with 20K training samples and 10K testing samples. W e train a d eep autoencoder using an encoding architecture of 7 84-40 0-200 -100-50-25- 6 with sy mmetric decoding. Similar to MNIST , logistic activ ations and binary c ross entropy er ror are used. • USPS: Hand written digits of size 16 × 16 with 11 K examples. W e per form classification u sing 5 rand omly sampled batche s of 8K training examples and 3K testing exam ples a s in [26] Each batch ha s an equa l numbe r of each digit. Classification networks of size 256 -500- 500-1 0 are trained with rectifier activ ations. Th e data is scaled to ha ve zero mean and unit v ariance. • Reuters: A collection o f 8293 text docum ents from 65 categories. Each docum ent is repr esented as a 18 900-d imensional bag-of-words vector . W ord counts C are transfo rmed to log( 1 + C ) as is do ne by [3]. Th e pub lically available train/test split of is used. W e tr ain networks of size 18900 -65 for classification d ue to th e high dimensionality of the in puts, wh ich reduce s to softmax - regression. For classification experiments, we pe rform comparison of SHF with and without d ropou t ag ainst dropo ut SGD [3]. All classification exper iments utilize the sp arse initialization o f Martens [ 4] with initial biases set to 0.1 . The sparse initialization in combination with ReLUs make our netw orks similar to the deep sp arse rectifier networks o f [28]. All algo rithms ar e trained for 5 00 ep ochs o n MNIST and 1000 epochs on USPS and R euters. W e use weight decay of 5 × 10 − 4 for SHF and 2 × 10 − 5 for dr opout SHF . A held-o ut validation set was used f or deter mining the amoun t of input 7 0 100 200 300 400 500 0 0.005 0.01 0.015 0.02 0.025 Epoch classification error MNIST SHF dSHF dSGD−a dSGD−l 0 200 400 600 800 1000 0 0.005 0.01 0.015 0.02 0.025 0.03 0.035 Epoch classification error USPS SHF dSHF dSGD−a dSGD−l 0 200 400 600 800 1000 0 0.02 0.04 0.06 0.08 0.1 0.12 0.14 0.16 0.18 0.2 Epoch classification error Reuters SHF dSHF dSGD Figure 2: T raining and te sting cu rves for classification. dSHF: dro pout SHF , dSGD: d ropou t SGD, dSGD-a: drop out on all layers, dSGD-l: dro pout on last hidden layer only (as well as the inputs). dropo ut for all algorithms. Both SHF and dropout SHF use initial damping of λ = 1 , gradient batch size of 1000 , curvature batch size of 100 and 3 CG iterations per batch. Dropou t SGD tr aining uses an exponential decreasing learning rate schedule initialized at 10, in combinatio n with max- norm weig ht clipping [3]. This allows SGD to u se larger learn ing r ates for greater exploration ear ly in trainin g. A linearly in creasing momen tum schedule is used w ith initial momentu m of 0.5 and final momentum of 0.99 . No weight decay is used. For ad ditional comp arison we also train dro pout SGD wh en dropo ut is only used in th e last hidde n layer, as is th e case with dropo ut SHF . For deep autoencoder e xperimen ts, we use the same experimental setup as in Chap ter 7 of [17]. In particular, we focus solely on tr aining error without any L2 penalty in order to determine the effecti veness of the optim izer on modeling th e training data. Compa rison is made ag ainst SGD, SGD w ith mo mentum, HF and Nesterov’ s accelerated gr adient (NA G ). On CUR VE S, SHF u ses a n initial damping of λ = 1 0 , gra dient and curvature batch sizes of 2000 an d 25 CG iterations p er batch. On MNIST , we use initial λ = 1 , grad ient and curvature batch sizes of 30 00 an d 5 0 CG iterations per batch. Autoe ncoder trainin g is ran un til n o su fficient progr ess is mad e, wh ich o ccurs at aroun d 250 epoch s on CUR VES and 100 epoch s on MNIST . 5.1 Classification results Figure 2 sum marizes o ur classification results. At epoch 500 , dropo ut SHF achieves 107 err ors o n MNIST . This result is similar to [3] which achieve 100-115 errors with various network sizes when training for a few tho usand epochs. W ithout drop out or input corr uption, SHF achieves 159 err ors on MNIST , on par with existing methods th at do not incorporate prio r knowledge, pre-trainin g, image distortio ns or dro pout. As with [ 4], we hypoth esize that fu rther improvements can be mad e by fine-tunin g with SHF after unsup ervised layerwise pre-training. After 1000 epochs of training on fi ve random splits of USPS , we ob tain final classifi cation er rors of 1%, 1.1%, 0.8%, 0 .9% and 0.9 7% with a mean test err or of 0.95%. Both algorithms use 50 % input corrup tion. For additional com parison, [29] obtains a mean classification erro r o f 1 .14% using a pre-train ed deep network for large-ma rgin nearest neighb or classification with the same size splits. W ithout dropo ut, SHF overfits the t raining data. On the Reuters dataset, SHF with and withou t dro pout bo th dem onstrate acceler ated train ing. W e hypoth esize that further speedu p may also be obtain ed b y starting training with a muc h smaller λ initialization, which we suspect is conservativ e given that the prob lem is con vex. 8 T ab le 1: Training errors on the dee p autoencod er tasks. All results are obtained from [1 7]. M(0 .99) refers to momentum capped at 0.9 9 a nd similarily for M (0.9). SGD-VI refers to SGD using the variance normalized initialization of [1 5]. problem N A G M(0.99 ) M(0.9) SGD SGD-VI [1 9] HF SHF CUR VES 0.07 8 0.1 10 0.220 0.250 0.160 0.110 0.089 MNIST 0.730 0.770 0.9 90 1.100 0.900 0.780 0.877 0 50 100 150 200 250 0 0.05 0.1 0.15 0.2 0.25 Epoch train_L2 CURVES SHF NAG HF SGD−VI SGD 0 20 40 60 80 100 0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 Epoch train_L2 MNIST SHF NAG HF SGD−VI SGD Figure 3: Learning cu rves for the deep au toencode r tasks. The CG d ecay paramete r γ is shut off at epoch 160 on CUR VES a nd epoch 60 on MNIST . 5.2 Deep autoencoder results Figure 3 an d tab le 1 summarize our results. Insp ired by [ 17] we make one ad ditional mo dification to our algorithms. As soon as tra ining begins to diver ge, we tu rn off the CG decay p arameter γ in a similar fashion as the the mo mentum parameter µ is decreased in [1 7]. When γ = 0 , CG is no lon ger initialized from the pr evious solution and is in stead initialized to zero . As with [17], this h as a dramatic effect on the training erro r but to a lesser extent as momentu m and Nesterov’ s accelerated gradient. [ 17] describes t he behaviour of this ef fect as follo ws: with a large momentum, the optimizer is ab le to make steady progress alo ng slo w ch anging directions o f lo w curvature. By decreasing th e momentum late in training, the optimizer is then able to quick ly reach a local minimum from finer optimization along high cur vature dir ections, which would otherwise be too difficult to obtain with an ag gressive mo mentum sch edule. This o bservation further motivates the relationship between momentu m and info rmation sharing through CG. Our e xperimen tal results demonstrate that SHF does not perform sign ificantly better or w orse on these datasets compared to e xisting app roaches. It is able to outp erform HF on CUR VES b ut no t on MNIST . An attr activ e prop erty that is shared with both HF and SHF is not requirin g the careful schedule tun ing that is nece ssary for mo mentum and NA G. W e also attempted exper iments with SHF using th e same setup for classification with smaller batches and 5 CG iteration s. Th e results were worse: o n CUR VES th e lo west training error obtained was 0.19. This sho ws that while such a setup is useful fro m the viewpoint of noisy updates and test g eneralization , they hamper the ef fectiveness of making prog ress on hard to optimiz e re gions. 6 Conclusion In this pape r we pro posed a stochastic variation o f M artens’ He ssian-free o ptimization incorp orating dropo ut for tr aining n eural network s on c lassification and de ep au toencod er tasks. By adap ting the batch sizes and number of CG iteration s, SHF c an b e con structed to perfor m well for classification 9 against d ropou t SGD o r op timizing de ep au toencod ers comparing HF , NA G and mo mentum meth- ods. While our initial results are pro mising, of interest would be adapting stochastic Hessian-free optimization to other network architectures: • Con volutional networks. The m ost com mon app roach to training c on volutional n etworks has been SGD in corpor ating a diagonal Hessian a pprox imation [8]. Dro pout SGD was r ecently used for training a deep conv olutional network on ImageNet [30]. • Recurrent Networks. It w as lar gely belie ved th at R NNs were too difficult to train with SGD due to th e explo ding/vanishing gradien t prob lem. In recent years, recurren t n etworks have becom e popular again due to se veral advancements made in their training [31]. • Recursive Networks. Recur si ve networks hav e been successfully used f or tasks such as sentiment classification and comp ositional modeling of natura l language from word embedd ings [32]. Th ese architecture s are usually train ed using L-BFGS. It is not clear yet whether this setup is ea sily generalizable to the above arch itectures or whether improvements need to be con sidered. Furth ermore, a dditional experimen tal com parison would in - volve dropout SGD with the adaptive methods of Ad agrad [9] or [ 11], as well as th e impo rtance of pre-con ditioning CG. None the less, we hope that th is work in itiates f uture research in developing stochastic Hessian-free algorithms. Acknowledgments The author would like to thank Csaba Szepesvári for helpful discussion as well as Da vid Sussillo fo r his g uidance when first lea rning about and implementing HF . The author would also like to than k the anonymou s ICLR re viewers for their comments and suggestions. Refer ences [1] L. Bottou an d O. Bou squet. The tradeoffs of large-scale learn ing. Optimization for Machine Learning , page 351, 2011. [2] Y . Bengio , P . L amblin, D. Popovici, and H. Larochelle. Greedy layer-wise tra ining o f deep networks. NIPS , 19:153, 2007. [3] G.E. Hinto n, N. Srivas tav a, A. Kr izhevsky , I. Su tske ver , a nd R.R. Salak hutdinov . Impr oving neural networks by pre venting co-adaptation of feature detectors. arXiv:1207.0 580 , 2 012. [4] J. Martens. Deep learning via hessian-free optimization. In ICML , volume 951 , 2010. [5] J. Mar tens and I . Sutskever . Learning recur rent neural networks with hessian-free optimization. In ICML , 2011 . [6] B.A. Pearlmutter . Fast exact multiplicatio n by the hessian. Neural Computa tion , 6(1 ):147–1 60, 1994. [7] N.N. Schrau dolph. Fas t c urvature matrix -vector pro ducts fo r second -orde r gradien t descent. Neural computation , 14(7):172 3–17 38, 2002. [8] Y . LeCun, L. Bottou, G. Orr , an d K. Müller . Efficient backp rop. Neural n etworks: T ricks of the trade , pages 546–546, 1998. [9] J. Du chi, E. Hazan, and Y . Singer . Adaptive subgradient metho ds for online learning and stochastic optimization. JMLR , 12:21 21–21 59, 201 0. [10] J. Dean, G. Cor rado, R. Monga, K. Chen , M. De vin, Q. Le, M. Mao, A. Senio r , P . T ucker, K. Y ang, et al. Large scale distrib uted deep networks. In NIPS , pages 1232– 1240, 2012 . [11] T . Schaul, S. Zhang, and Y . LeCun. No more pesky learning rates. arXiv:1206 .1106 , 2012. [12] A. Bordes, L. Bottou, and P . Gallinari. Sgd-qn : Careful qu asi-newton stochastic gradient descent. JMLR , 10:173 7–17 54. [13] Razvan Pascanu and Y oshu a Bengio. Natural g radient revisited. arXiv pr eprint arXiv:130 1.358 4 , 2013 . [14] N. Le Roux, P .A. Man zagol, and Y . Bengio. T opmou moute online natural grad ient algorithm. In NIPS , 2007 . 10 [15] Xavier Glorot an d Y oshu a Beng io. Understandin g the difficulty of training deep fee dforward neural networks. In AIST A TS , 201 0. [16] Y ann N Dauph in an d Y o shua Bengio. Big neur al networks w aste capacity . arXiv pr eprint arXiv:130 1.358 3 , 2013 . [17] I. Sutske ver . T raining Recurrent N eural Networks . PhD thesis, Uni versity of T oron to, 2013. [18] R.H. Byrd, G.M. Chin, J. Noced al, and Y . W u. Sample size selection in optimization method s for machine learning. Mathematical Pr ogr amming , pages 1–29, 2012. [19] O. Chapelle and D. Erhan . Improved preco nditioner for hessian free op timization. In NIP S W orkshop on Deep Learning and Unsup ervised F eatu r e Learning , 2011. [20] I. Sutskever , J. Mar tens, an d G. H inton. Generatin g text with recurrent neural networks. In ICML , 2011 . [21] O. V inyals and D. Pove y . Krylov subspace descent for deep learning. arXiv:1111.4 259 , 20 11. [22] Q.V . Le, J. Ngiam, A. Coates, A. Lahiri, B. Prochnow , and A.Y . Ng. On optimizatio n metho ds for deep learning. In ICML , 2011. [23] Y . Bengio. Practical reco mmendatio ns f or gradient-b ased trainin g of d eep architectures. arXiv:120 6.553 3 , 2012 . [24] J. Martens and I. Sutske ver . T raining deep and recurren t networks with hessian-free optimiza- tion. Neural Networks: T ric ks of the T rade , pages 479 –535, 2012. [25] P . V in cent, H. Larochelle, Y . Bengio, and P . A. Manzag ol. Extracting an d comp osing robust features with denoising autoencod ers. I n ICML , pages 1096– 1103 , 200 8. [26] R. Min, D.A. Stanley , Z . Y uan , A. Bonner, and Z. Zhang . A deep n on-linear feature mapping for large-m argin knn classification. I n Ninth IEEE In ternational Conference on Data Min ing , pages 357– 366. IEEE , 2009. [27] Deng Cai, Xuanhu i W ang, a nd Xiaofei He. Probabilistic d yadic data analysis with loc al and global consistency . In ICML , pages 105–11 2, 2009 . [28] X. Gloro t, A. Bordes, and Y . Bengio . Deep sparse rectifier neu ral networks. In AIS T ATS , 201 1. [29] R. Min, D.A. Stanley , Z . Y uan , A. Bonner, and Z. Zhang . A deep n on-linear feature mapping for large-margin knn classification. In ICDM , pages 357– 366, 2009. [30] A. Krizhevsky , I. Sutskever , and G. Hinto n. Imag enet classification with dee p conv olution al neural networks. NIPS , 25, 2012. [31] Y . Bengio, N. Boulanger-Le wandowski, and R. P ascanu. Advances in optimizing recurrent networks. arXiv:1212. 0901 , 2012. [32] R. Socher, B. Huval, C.D. Manning , and A.Y . Ng. Seman tic composition ality th rough recu rsiv e matrix-vector spaces. In EMNLP , pages 1201–12 11, 2012. 11
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment