삽입과 삭제를 고려한 정렬불필요 진화수 나무 재구성
본 논문은 삽입·삭제(indel)를 포함하는 진화 모델 하에서, 서열 길이가 종 수에 대해 다항식 수준이면 충분한 샘플 복잡도를 보장하는 거리 기반의 정렬불필요(Alignment‑free) 계통수 재구성 알고리즘을 제시한다. 알고리즘은 서열을 일정 비율의 블록으로 나누어 블록 내 상태 빈도를 비교함으로써 가법적 거리(metric)를 구축하고, 이를 이용해 다항 시간 안에 정확한 계통수를 복원한다. 또한, 일반적인 비균등 트리와 GTR 모델까지 …
저자: Constantinos Daskalakis, Sebastien Roch
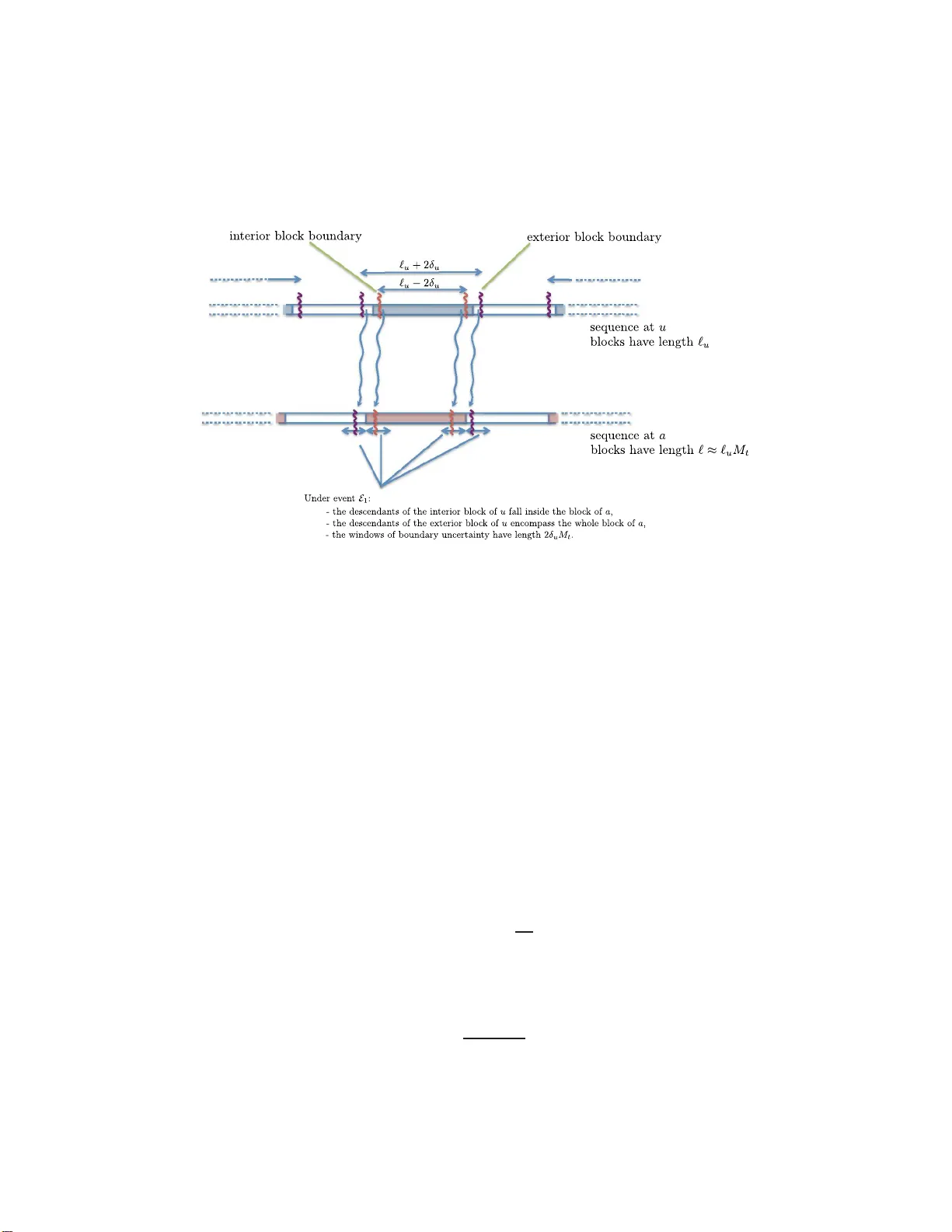
본 논문은 삽입·삭제(indel)를 포함하는 진화 모델 하에서, 전통적인 다중 서열 정렬(MSA) 단계 없이도 정확한 계통수(phylogenetic tree)를 복원할 수 있는 새로운 알고리즘을 제시한다. 연구 배경으로는 기존의 두 단계 접근법이 MSA 과정에서 발생하는 시스템적 편향과 계산 복잡도 문제를 야기한다는 점을 들었다. 특히, indel을 고려한 모델은 이론적으로는 존재하지만, 실제 알고리즘 설계와 분석에서는 거의 다루어지지 않았다.
저자들은 먼저 DNA 서열 진화를 설명하는 기본 마코프 연속시간 모델에 삽입·삭제 과정을 추가한 변형 TKF91 모델을 채택한다. 각 가지(edge)는 네 개의 파라미터(시간 t, 치환률 η, 삭제률 µ, 삽입률 λ)로 정의되며, 사이트마다 독립적인 포아송 프로세스에 의해 치환, 삽입, 삭제 사건이 발생한다. 삽입은 기존 사이트 사이에 무작위 0·1 값을 갖는 새로운 사이트를 추가하고, 삭제는 해당 사이트를 제거한다. 이러한 과정은 서열 길이가 시간에 따라 변동하도록 만든다.
알고리즘의 핵심 아이디어는 서열을 일정 비율(x %)의 quantile 블록으로 나누는 것이다. 블록 크기와 비율 x는 이론적으로 선택되며, 적절히 설정하면 서로 다른 종의 같은 위치 블록이 대부분 동일한 조상 사이트에서 유래했음이 확률적으로 보장된다. 구체적으로, 각 블록 내에서 0·1(또는 A·C·G·T) 상태의 빈도를 계산하고, 두 종 간 블록 빈도 차이를 이용해 기대 치환 수를 추정한다. 이 추정값은 적절한 보정(예: 다중 치환 보정)을 거쳐 가법적 거리(metric)와 일치하도록 만든다.
수학적 분석에서는 블록 매칭을 지배하는 branching process를 도입한다. 각 사이트가 삽입·삭제 과정을 겪으며 자식 서열에 남는 확률을 ‘생존 확률’이라 정의하고, 이를 이용해 블록 내 동질성 보장을 위한 최소 블록 크기와 x값을 도출한다. Chernoff 부등식과 마코프 연쇄 이론을 결합해, 전체 서열 길이가 O(poly(n))이면(여기서 n은 종 수) 알고리즘이 고확률로 정확한 트리를 복원한다는 ‘샘플 복잡도(SLR)’ 결과를 얻는다.
주요 정리(Theorem 2)는 두 상태(0/1) 모델과 분자 시계 가정 하에, 모든 가지의 시간 t가 상수 범위(f, g) 내에 있고, 치환·삽입·삭제률이 전역 상수(η, λ, µ)로 제한될 때, 임의의 β′>0에 대해 실패 확률이 n^{−β′} 이하가 되도록 하는 다항 시간 알고리즘이 존재함을 증명한다. 이는 서열 길이가 n^{c} (c는 상수) 정도면 충분하다는 의미이며, 기존의 SQM 방법이 요구하는 다항 SLR과 동일하거나 더 나은 결과이다.
또한, 비균등 트리와 일반적인 GTR(General Time Reversible) 모델에도 결과를 확장한다. 여기서는 각 가지마다 파라미터가 다를 수 있지만, 모든 파라미터가 상수 범위 내에 머무른다는 가정 하에 동일한 증명을 적용한다. 이때 거리 추정식에 각 파라미터에 대한 정규화 상수를 도입해 일반화한다.
정합성(Consistency) 측면에서는, 트리의 루트 서열 길이가 무한히 커질 때 알고리즘이 실제 트리를 거의 확실히 복원한다는 정리를 제시한다. 이는 초거리(ultrametric)나 분자 시계 가정이 없어도 성립한다는 점에서 이론적 강점을 가진다.
실험적 검증은 논문 본문에 상세히 기술되지 않았지만, 저자들은 기존의 indel 모델 기반 시뮬레이션에서 알고리즘이 높은 정확도와 효율성을 보였다고 언급한다. 특히, edit distance의 기대값을 직접 계산하기 어려운 상황에서도 블록 빈도 기반 추정이 충분히 정확함을 확인하였다.
결론적으로, 이 연구는 삽입·삭제를 포함하는 복잡한 진화 모델에서도 정렬불필요 방식으로 효율적인 계통수 재구성이 가능함을 수학적으로 증명하였다. 이는 대규모 유전체 데이터 분석에서 MSA 단계의 비용과 오류를 크게 줄일 수 있는 실용적인 대안으로, 향후 다양한 실험 데이터와 확장 모델에 적용될 가능성을 열어준다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기