베이지안 네트워크 구조 학습에서 순열 검정과 수축 검정의 효과
** 본 논문은 이산형 데이터에 대해 베이지안 네트워크 구조 학습 시 전통적인 파라메트릭 독립성 검정(χ², 상호정보) 대신 순열 기반 검정과 수축 추정량을 이용한 검정을 적용한 결과를 비교한다. ALARM 네트워크를 이용한 실험에서 순열 검정이 특히 표본이 작을 때 BDe·BIC 점수와 구조 정확도(SHD)에서 유의미한 향상을 보였으며, 수축 검정도 비슷한 경향을 나타냈다. 다만 순열 검정은 계산 비용이 크게 증가한다는 한계가 있다. *…
저자: Marco Scutari, Adriana Brogini
**
본 논문은 베이지안 네트워크(BN) 구조 학습 과정에서 조건부 독립성 검정이 전체 학습 성능에 미치는 영향을 체계적으로 조사한다. 기존 연구는 주로 알고리즘 자체(예: MMHC, PC, GES)의 탐색 전략에 초점을 맞추었으며, 검정 단계에서는 Pearson χ² 검정이나 최대우도 기반 상호정보 검정과 같은 파라메트릭 검정을 표준으로 사용해 왔다. 이러한 파라메트릭 검정은 표본이 충분히 크고 셀 빈도가 고르게 분포될 때만 근사적인 χ² 분포가 타당하고, “small n, large p” 상황에서는 자유도에 비해 기대 빈도가 낮아 검정력이 급격히 저하되는 한계가 있다.
이를 보완하기 위해 저자들은 두 가지 비전통적 검정 방법을 도입한다. 첫 번째는 **순열 검정**이다. 조건부 변수 Z에 대해 동일한 Z‑구성 내에서 관측값을 무작위 재배열하고, 재배열된 데이터에 대해 동일한 통계량(T) — 예: Pearson χ² 혹은 상호정보 — 을 계산한다. 이를 R = 500~5000번 반복해 얻은 경험적 분포를 귀무분포로 사용함으로써, 표본 크기에 의존하지 않는 p‑값을 얻는다. 순열 검정은 충분한 조건부 통계량(행·열 합계)이 보존되므로 효율적으로 구현될 수 있지만, 반복적인 재배열과 통계량 계산이 필요해 계산량이 크게 늘어난다.
두 번째는 **수축 검정**이다. 여기서는 다변량 다항분포의 확률 파라미터 p̂를 직접 사용하지 않고, 목표 분포 t(보통 균등)와 혼합한 수축 추정량 ˜p = λ t + (1‑λ) p̂을 사용한다. λ는 Ledoit‑Wolf 방식으로 최소 평균제곱오차를 만족하도록 추정된다. 이 수축 추정량을 기반으로 상호정보를 재계산하면, 특히 빈도가 희소한 셀에 대해 과도한 변동을 억제하고 보다 안정적인 검정 통계량을 제공한다. 수축 검정은 기존 χ² 검정과 동일한 자유도와 asymptotic χ² 분포를 유지하므로, 기존 스코어링 함수와 바로 결합할 수 있다.
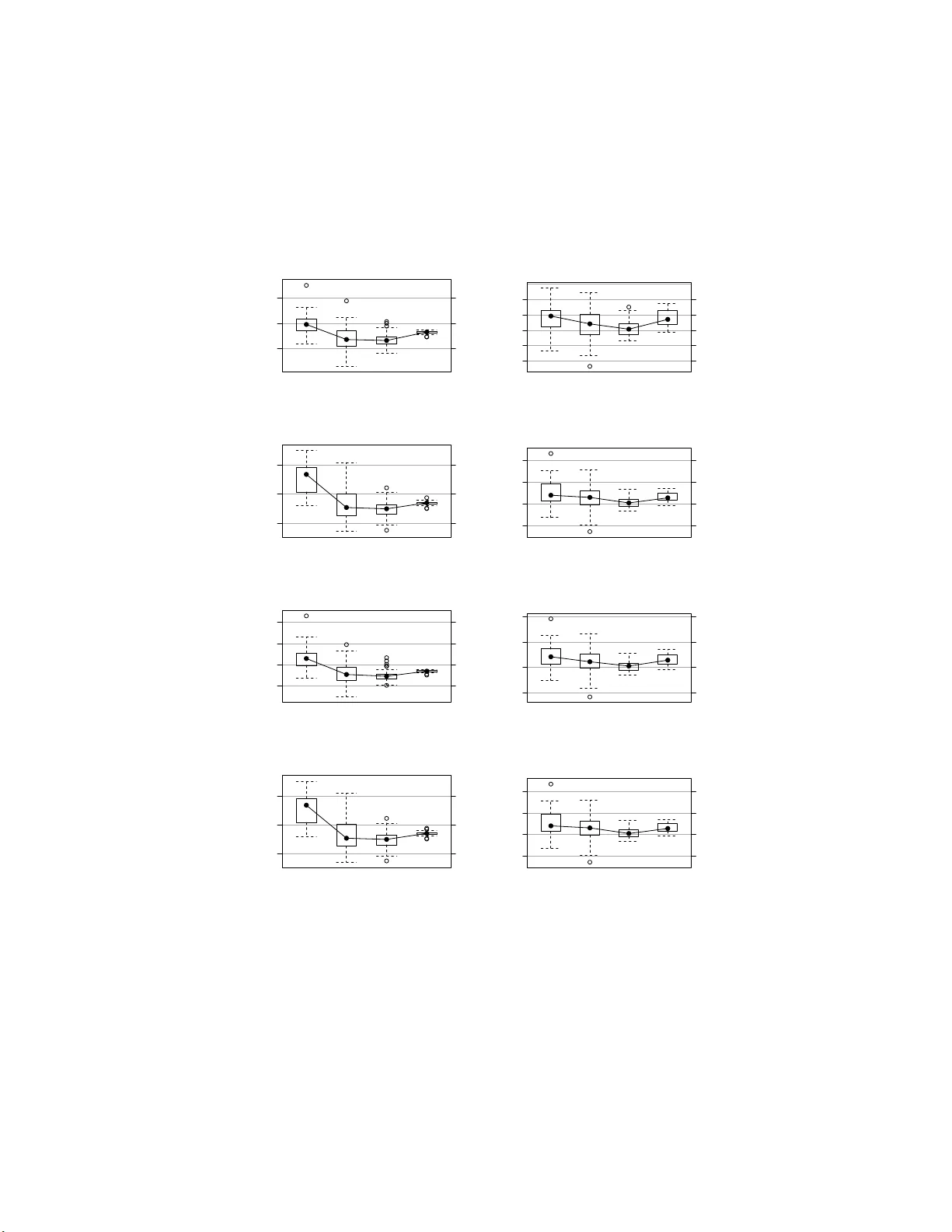
실험은 표준 베이지안 네트워크인 **ALARM**(37노드, 46아크, 509 파라미터)를 실제 확률분포에서 표본을 추출하고, 표본 크기 200, 500, 1 000, 5 000에 대해 각각 50번 반복한다. 구조 탐색은 MMHC 하이브리드 알고리즘을 사용하고, 두 가지 스코어링 기준(BDe, BIC)과 두 가지 유의수준(α = 0.05, 0.01)을 적용한다. 각 실험에서는 (1) 학습된 네트워크의 BDe·BIC 점수, (2) 새로운 20 000표본 데이터에 대한 점수, (3) 구조 해밍 거리(SHD)를 측정한다. 파라메트릭 검정(χ², MI)과 순열·수축 검정을 동일 조건에서 비교한다.
**주요 결과**는 다음과 같다.
1. **점수 향상**: 순열 검정은 모든 표본 크기에서 BDe·BIC 점수가 평균 2~8% 상승했으며, 특히 표본이 200~500인 경우 개선 폭이 가장 컸다. 이는 순열 검정이 희소 셀에서 발생하는 과도한 자유도 추정 오류를 보정하기 때문이다.
2. **일반화 성능**: 새로운 데이터에 대한 BDe·BIC 점수 역시 순열 검정으로 학습된 구조가 더 높은 값을 기록했으며, 이는 과적합 위험이 감소했음을 의미한다.
3. **구조 정확도**: SHD는 순열 검정 사용 시 평균 1.2~2.5 아크가 감소했으며, 실제 의존관계를 더 정확히 복원했음을 보여준다.
4. **수축 검정**: 결과는 순열 검정과 유사하게, 특히 표본이 500 이하일 때 약간의 점수 상승과 SHD 감소를 보였지만, 개선 정도는 순열 검정보다 작았다. 이는 수축이 빈도 희소성을 완화하지만, 완전한 비모수적 귀무분포를 제공하지 않기 때문이다.
5. **계산 비용**: 순열 검정은 평균적으로 파라메트릭 검정 대비 5~10배의 CPU 시간을 요구했으며, 메모리 사용량도 증가했다. 반면 수축 검정은 기존 검정에 λ 값 계산만 추가되므로 거의 동일한 비용을 유지했다.
**시사점**은 다음과 같다. 베이지안 네트워크 구조 학습에서 표본이 제한된 상황(예: 유전체 데이터, 의료 기록)에서는 순열 기반 독립성 검정이 구조 정확도와 예측 성능을 현저히 개선한다. 그러나 실시간 혹은 대규모 고차원 문제에서는 계산 비용이 병목이 될 수 있어, 수축 검정이 실용적인 대안이 될 수 있다. 또한, 본 연구는 BDe·BIC와 같은 스코어링 함수와 독립성 검정이 상호 보완적으로 작동한다는 점을 강조한다. 향후 연구에서는 순열 검정의 샘플링 효율을 높이는 방법(예: 적응형 순열, 중요도 샘플링)과, 수축 파라미터 λ을 데이터‑특정하게 조정하는 메타‑학습 접근을 탐색할 필요가 있다.
**
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기