특징 기반 행렬 분해
본 논문은 기존 협업 필터링 모델들을 하나의 일반화된 형태인 “특징 기반 행렬 분해(FMF)”로 통합하고, 새로운 정보(시간, 이웃, 계층 등)를 특징(feature)만 정의하면 코드 수정 없이 적용할 수 있는 툴킷을 제안한다. 선형 회귀와 전통 MF를 결합하고, 다양한 활성·손실 함수와 정규화를 지원하며, 대규모 데이터 처리와 효율적인 SGD 학습을 위한 버퍼링·파이프라인 기법을 구현한다. KDDCup 2011 트랙 1에서 최고 성능을 기록한…
저자: Tianqi Chen, Zhao Zheng, Qiuxia Lu
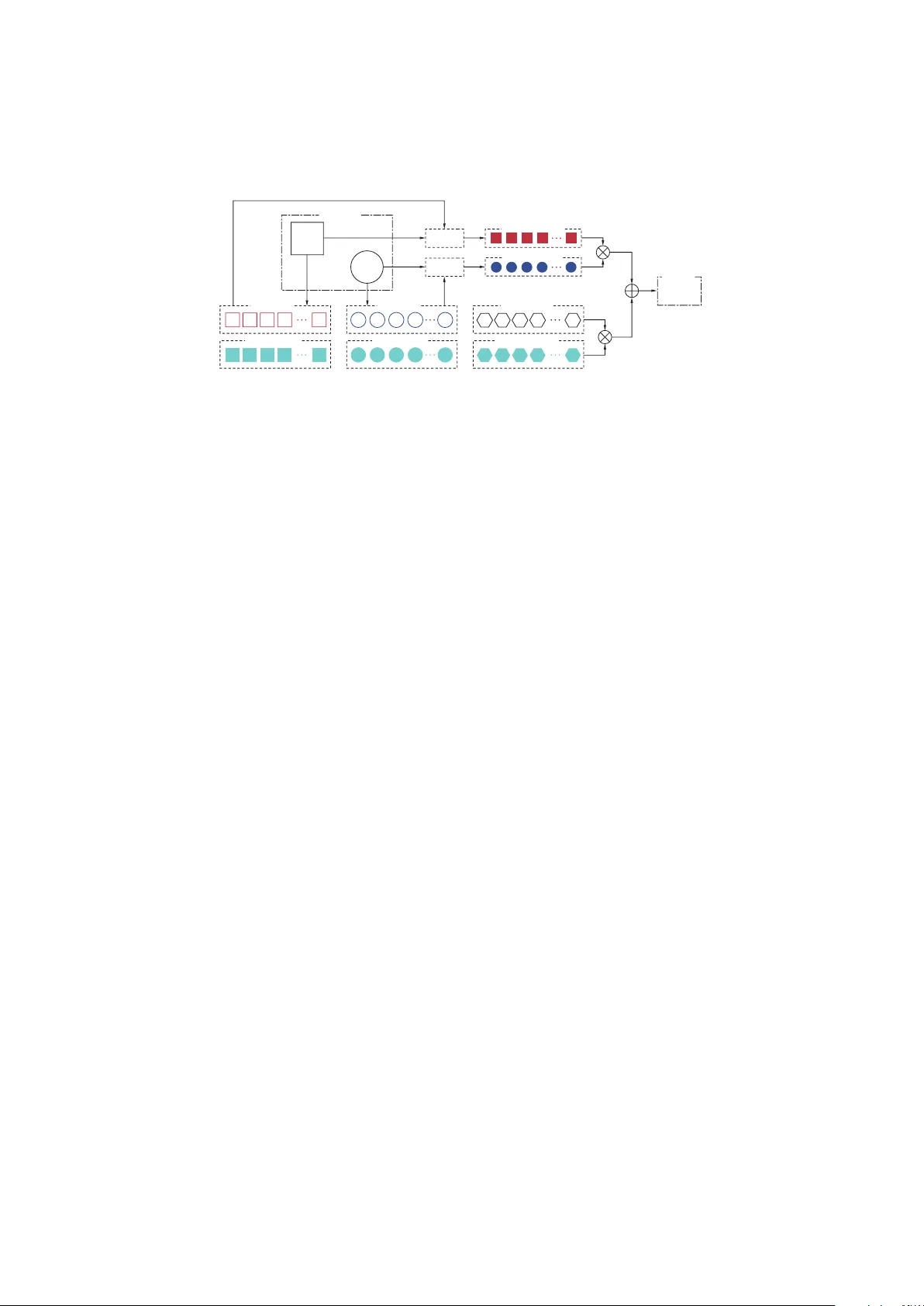
본 논문은 “Feature‑Based Matrix Factorization”(FMF)이라는 통합 모델을 제안한다. 기존 협업 필터링(CF) 방법은 사용자·아이템 평균 편향, 이웃 기반 가중치, 시간·계층적 정보 등 다양한 변형을 각각 별도의 코드로 구현해야 하는 비효율성을 가지고 있었다. 저자들은 이러한 변형들을 모두 선형 회귀의 특수 형태로 재해석하고, 공통된 파라미터 구조를 특징(feature) 벡터로 추상화함으로써 하나의 프레임워크 안에서 모두 다룰 수 있게 했다.
먼저, 기본 선형 회귀 모델을 통해 기존 베이스라인(μ + b_u, μ + b_u + b_i)과 이웃 기반 모델(μ + b_u + b_i + ∑ s_ij·(r_uj − \bar b_u))을 특징 벡터 x와 가중치 w로 표현한다. 여기서 x는 사용자·아이템·이웃 관계를 나타내는 인디케이터와 실수값으로 구성되고, w는 각각 b_u, b_i, s_ij에 대응한다.
다음으로, 전통적인 행렬 분해 모델 ˆr_ui = μ + b_u + b_i + p_u^T q_i 를 확장한다. FMF는 세 종류의 특징을 도입한다: 전역 특징 γ(편향 전용), 사용자 특징 α(편향·잠재 요인 모두에 사용), 아이템 특징 β(편향·잠재 요인 모두에 사용). 예측식은
y = μ + ∑_j γ_j b(j) + ∑_j α_j b(j) + ∑_j β_j b(j) + (∑_j α_j p_j)^T (∑_j β_j q_j)
이다. 여기서 b(j), p_j, q_j는 각각 편향·잠재 요인 파라미터이며, α, β, γ는 입력 데이터에 따라 동적으로 정의된다. 이 구조는 기본 MF를 포함할 뿐 아니라, 시간 의존 편향(b_u(t), b_i(t)), 시간 가중 잠재 요인(p_u(t), q_i(t)), 이웃 가중치, 계층적 아티스트·트랙 관계 등 복합 정보를 손쉽게 삽입할 수 있다.
활성 함수 f와 손실 함수 L은 자유롭게 선택 가능하다. 논문에서는 신원 함수와 L2 손실(전통 MF), 시그모이드와 로그우도(로그리그레션), 스무스드 힌지와 최대 마진 손실(이진 분류) 등을 예시로 들었다. 파라미터 업데이트는 SGD 기반이며, 편향·잠재 요인 각각에 대해 학습률 η와 정규화 λ를 별도 지정한다.
특히 SVD++와 같은 암묵 피드백을 포함하는 모델을 효율적으로 학습하기 위해, 사용자별 피드백 집합을 미리 집계한 p_im = ∑_j α_j d_j 로 정의하고, d_j 파라미터를 직접 업데이트한다. 이때 Δd_j와 Δp_im 사이의 관계 Δd_j = α_j · (∑_k α_k^2) · Δp_im 를 이용하면, 동일 사용자의 연속 샘플에 대해 d_j를 일일이 재계산하지 않아도 된다. 정규화 항을 포함하면 근사적으로 동일 관계가 유지된다. 이를 기반으로 제안된 Algorithm 1은 사용자 단위로 데이터를 배치 처리하여 연산량을 크게 줄인다.
대규모 데이터 처리 측면에서는 전체 학습 데이터를 메모리에 적재하지 않고, 이진 포맷으로 디스크에 버퍼링한다. 학습 전 데이터를 무작위 셔플한 뒤, 버퍼링 프로그램이 순차적으로 읽어들여 메모리 큐에 공급한다. 별도 프리페치 스레드가 I/O를 비동기적으로 수행함으로써 훈련 스레드가 I/O 대기 없이 연산에 집중할 수 있다. 이 설계는 200 M 레이팅(Yahoo! Music) 데이터를 2 GB 이하 메모리로 처리하면서도, KDDCup 2011 트랙 1에서 RMSE 22.16이라는 최고 성적을 달성했다.
관련 연구로는 Factorization Machine(FM)과 libFM 툴킷을 언급한다. FM은 모든 2차 상호작용을 특징으로 모델링하지만, FM은 전역·사용자·아이템 특징을 동일한 차원에 두어 편향과 잠재 요인을 구분하기 어렵다. 반면 FMF는 전역·사용자·아이템 특징을 명시적으로 구분하고, 편향 전용 전역 특징을 지원함으로써 시간·이웃·계층 등 특수한 편향을 효과적으로 다룰 수 있다. 또한, 기존 회귀 기반 잠재 요인 모델과 차별화된 점은 특징을 통해 컨텍스트 정보를 직접 삽입한다는 점이다.
논문의 한계는 현재 다중 독립적인 잠재 요인(예: 사용자‑시간‑아이템 3‑차 텐서) 구조를 지원하지 않으며, 특징 설계가 모델 성능에 큰 영향을 미친다. 향후 연구에서는 텐서 분해와 자동 특징 생성(예: 메타‑학습) 등을 통합하여 FMF의 표현력을 확장할 계획이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기