Feature-Based Matrix Factorization
Recommender system has been more and more popular and widely used in many applications recently. The increasing information available, not only in quantities but also in types, leads to a big challenge for recommender system that how to leverage thes…
Authors: Tianqi Chen, Zhao Zheng, Qiuxia Lu
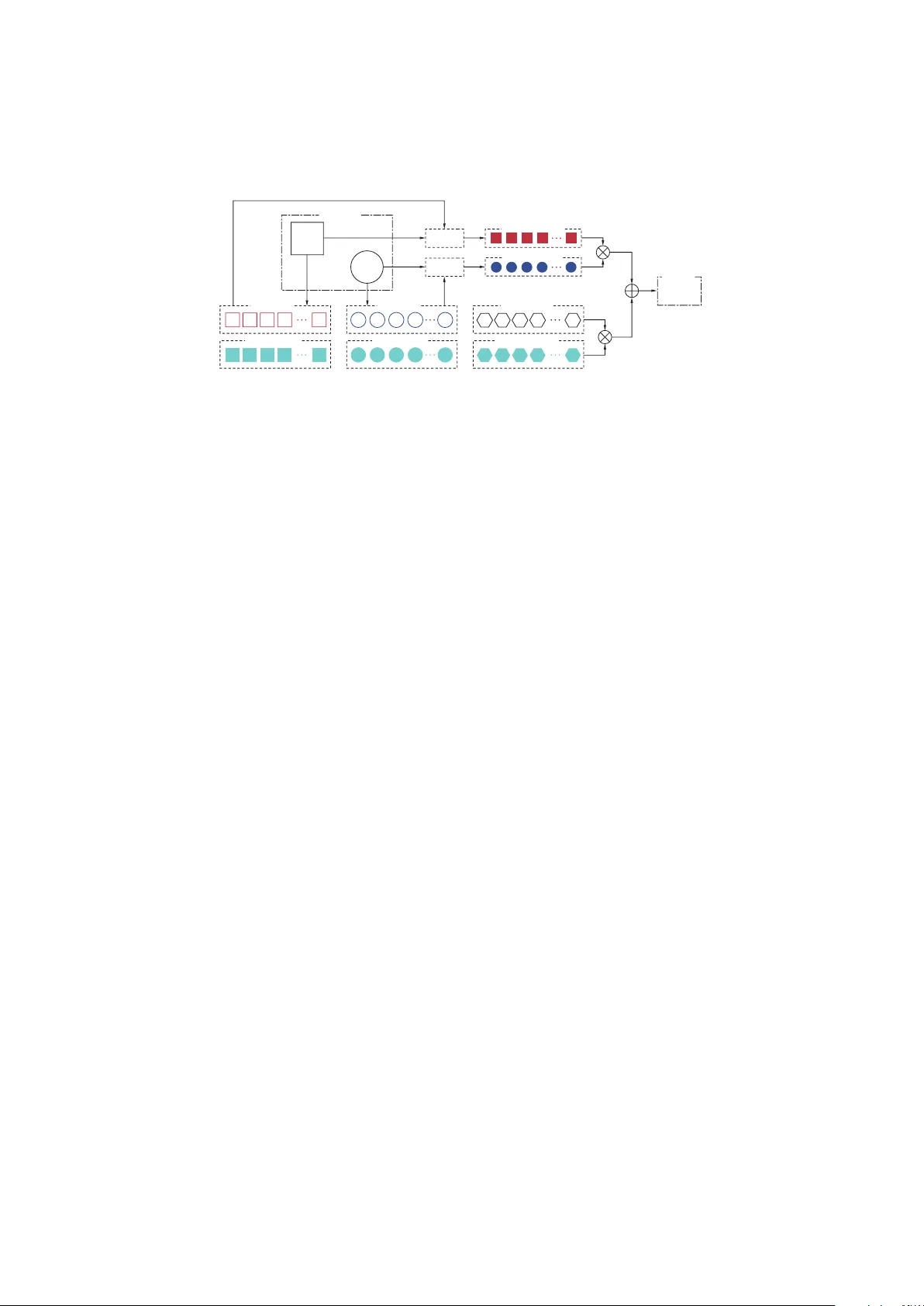
F eature-Based Matrix F actorization Tianqi Chen, Zhao Zheng, Qiuxia Lu, W einan Zhang, Y ong Y u { tqc hen,zhengzhao,luqiuxia,wnzhang,yyu } @ap ex.sjtu.edu.cn Ap ex Data & Kno wledge Managemen t Lab Shanghai Jiao T ong Universit y 800 Dongc h uan Road, Shanghai 200240 China Pro ject page: http://apex.sjtu.edu.cn/ap ex wiki/svdfeature 2011-07-11 (v ersion 1.1) Abstract Recommender system has been more and more popular and widely used in man y applications recen tly . The increasing information av ail- able, not only in quantities but also in types, leads to a big challenge for recommender system that how to lev erage these ric h information to get a b etter p erformance. Most traditional approaches try to de- sign a sp ecific mo del for each scenario, whic h demands great efforts in developing and modifying models. In this tec hnical rep ort, w e de- scrib e our implementation of feature-based matrix factorization. This mo del is an abstract of man y v arian ts of matrix factorization mo dels, and new t yp es of information can be utilized by simply defining new features, without mo difying any lines of co de. Using the to olkit, we built the b est single mo del rep orted on trac k 1 of KDDCup’11. 1 In tro duction Recommender systems that recommends items based on users in terest has b ecome more and more p opular among many web sites. Collab o- rativ e Filtering(CF) tech niques that b ehind the recommender system ha v e b een dev elop ed for man y y ears and keep to b e a hot area in b oth academic and industry asp ects. Currently CF problems face t w o kinds of ma jor challenges: ho w to handle large-scale dataset and how to lev erage the ric h information of data collected. T raditional approaches to solve these problems is to design sp e- cific mo dels for each problem, i.e writing code for each mo del, whic h 1 demands great efforts in engineering. Matrix factorization(MF) tec h- nique is one of the most p opular method of CF mo del, and exten- siv e study has b een made in different v arian ts of matrix factorization mo del, suc h as [3][4] and [5]. Ho w ev er, w e find that the ma jorit y of matrix factorization mo dels share common patterns, which motiv ates us to put them together into one. W e call this mo del feature-based matrix factorization. Moreov er, w e write a to olkit for solving the gen- eral feature-based matrix factorization problem, saving the efforts of engineering for detailed kinds of mo del. Using the to olkit, we get the b est single mo del on trac k 1 of KDDCup’11[2]. This article serv es as a tec hnical rep ort for our to olkit of feature- based matrix factorization 1 . W e try to elab orate three problems in this rep ort, i.e, what the mo del is, how can w e use suc h kind of mo del, and additional discussion of issues in engineering and efficien t compu- tation. 2 What is feature based MF In this section, we will describ e the mo del of feature based matrix factorization, starting from the example of linear regression, and then going to the full definition of our mo del. 2.1 Start from linear regression Let’s start from the basic collab orative filtering mo dels. The v ery baseline of collab orative filtering mo del may b e the baseline mo dels just considering the mean effect of user and item. See the following t w o mo dels. ˆ r ui = µ + b u (1) ˆ r ui = µ + b u + b i (2) Here µ is a constan t indicating the global mean v alue of rating. Equa- tion 1 describ e a mo del considering users’ mean effect while Equation 2 denotes items’ mean effect. A more complex mo del considering the neigh b orho o d information[3] is as follo ws ˆ r ui = µ + b i + b u + | R ( u ) | − 1 2 X j ∈ R ( u ) s ij ( r uj − ¯ b u ) (3) Here R ( u ) is the set of items user u rate, ¯ b u is a user a v erage rating pre-calculated. s ij means the similarity parameter from i to j . s ij is a parameter that w e train from data instead of direct calculation using 1 h ttp://ap ex.sjtu.edu.cn/ap ex wiki/svdfeature 2 memory based metho ds. Note ¯ b u is different from b u since it’s pre- calculated. This is a neighborho o d model that tak es the neigh borho o d effect of items in to consideration. Assuming w e w an t to implement all three mo dels, it seems to b e w asting to write co de for each of the mo del. If we compare those mo dels, it is ob vious that all the three mo dels are special cases of linear regression problem describ ed b y Equation 4 y = X i w i x i (4) Supp ose we ha v e n users, m items, and h total n um b er of p ossible s ij in equation 3. W e can define the feature vector x = [ x 0 , x 1 , · · · , x n + m + h ] for user item pair < u, i > as follo ws x k = I ndicator ( u == k ) k < n I ndicator ( i == k − n ) n ≤ k < n + m 0 k ≥ m + n, j / ∈ R ( u ) , s ij means w k | R ( u ) | − 1 2 ( r uj − ¯ b u ) k ≥ m + n, j ∈ R ( u ) , s ij means w k (5) The corresp onding la y out for weigh t w shown in equation 6. Note that choice of pairs s ij can b e flexible. W e can choose only p ossible neigh b ors instead of en umerating all the pairs. w = [ b u (0) , b u (1) , · · · , b u ( n ) , b i (1) , · · · b i ( m ) · · · s ij · · · ] (6) In other w ords, equation 3 can b e reformed as the follo wing form ˆ r ui = µ + b i 1 + b u 1 + X j ∈ R ( u ) s ij h | R ( u ) | − 1 2 ( r uj − ¯ b u ) i (7) where b i , b u , s ij corresp onds to w eigh t of linear regression, and the co efficien ts on the right of the w eigh t are the input features. In sum- mary , under this framew ork, the only thing that w e need to do is to la y out the parameters in to a feature v ector. In our case, we arrange first n features to b u then b i and s ij , then transform the input data in to the format of linear regres sion input. Finally we use a linear regression solv er to w ork the problem out. 2.2 F eature based matrix factorization The previous section shows that some baseline CF algorithms are lin- ear regression problem. In this section, w e will discuss feature-based generalization for matrix factorization. A basic matrix factorization mo del is stated in Equation 8: ˆ r ui = µ + b u + b i + p T u q i (8) 3 Question Answer r U,I U User Features User Feature Bias Item Features Item Feature Bias Global Feature Bias Merged User Factor User Factor Merging Merged Item Factor Global Features I Item Factor Merging Figure 1: F eature-based matrix factorization The bias terms ha v e the same meaning as previous section. W e also get tw o factor term p u and q i . p u mo dels the latent p eference of user u . q i mo dels the laten t prop ert y of item i . Inspired b y the idea of previous section, we can get a direct gen- eralization for matrix factorization v ersion. ˆ r ui = µ + X j w j x j + b u + b i + p T u q i (9) Equation 9 adds a linear regression term to the traditional matrix factorization mo del. This allo ws us to add more bias information, suc h as neighborho o d information and time bias information, etc. How ev er, w e may also need a more flexible factor part. F or example, w e may w an t a time dep endent user factor p u ( t ) or hierarc hical dep endent item factor q i ( h ). As w e can find from previous section, a direct w a y to include such flexibility is to use features in factor as w ell. So we adjust our feature based matrix factorization as follo ws y = µ + X j b ( g ) j γ j + X j b ( u ) j α j + X j b ( i ) j β j + X j p j α j T X j q j β j (10) The input consists of three kinds of features < α , β , γ > , w e call α user feature, β item feature and γ global feature. The first part of Equation 10. The name of these features explains their meanings. α describ es the user asp ects, β describes the item asp ects, while γ describes some global bias effect. Figure 1 shows the idea of the pro cedure. W e can find basic matrix factorization is a special case of Equation 10. F or predicting user item pair < u, i > , define γ = ∅ , α k = 1 k = u 0 k 6 = u , β k = 1 k = i 0 k 6 = i (11) W e are not limited to the simple matrix factorization. It enables us to incorp orate the neigh borho o d information to γ , and time de- 4 p enden t user factor b y mo difying α . Section 3 will present a detailed description of this. 2.3 Activ e function and loss function There, y ou need to c ho ose an active function f ( · ) to the output of the feature based matrix factorization. Similarly , you can also try v ariou s of loss functions for loss estimation. The final version of the mo del is ˆ r = f ( y ) (12) Loss = L ( ˆ r , r ) + r eg ular iz ation (13) Common c hoice of activ e functions and loss are listed as follo ws: • identit y function, L2 loss, original matrix factorization. ˆ r = f ( y ) = y (14) Loss = ( r − ˆ r ) 2 + r eg ul ar iz ation (15) • sigmoid function, log lik eliho o d, logistic regression v ersion of ma- trix factorization. ˆ r = f ( y ) = 1 1 + e − y (16) Loss = r ln ˆ r + (1 − r ) ln(1 − ˆ r ) + r eg ul ar iz ation (17) • identit y function, smo othed hinge loss[7], maximum margin ma- trix factorization[8][7]. Binary classification problem, r ∈ { 0 , 1 } Loss = h ((2 r − 1) y ) + r eg ul ar iz ation (18) h ( z ) = 1 2 − z z ≤ 0 1 2 (1 − z ) 2 0 < z < 1 0 z ≥ 1 (19) 5 2.4 Mo del Learning T o up date the mo del, we use the follo wing up date rule p i = p i + η ˆ eα i X j q j β j − λ 1 p i (20) q i = q i + η ˆ eβ i X j p j α j − λ 2 q i (21) b ( g ) i = b ( g ) i + η ˆ eγ i − λ 3 b ( g ) i (22) b ( u ) i = b ( u ) i + η ˆ eα i − λ 4 b ( u ) i (23) b ( i ) i = b ( i ) i + η ˆ eβ i − λ 5 b ( i ) i (24) Here ˆ e = r − ˆ r the difference b etw een true rate and predicted rate. This rule is v alid for both logistic lik elihoo d loss and L2 loss. F or other loss, we shall mo dify ˆ e to b e corresp onding gradient. η is the learning rate and the λ s are regularization parameters that defines the strength of regularization. 3 What information can b e included In this section, we will presen t some examples to illustrate the usage of our feature-based matrix factorization mo del. 3.1 Basic matrix factorization Basic matrix factorization mo del is defined b y follo wing equation y = µ + b u + b i + p T u q i (25) And the corresp onding feature represen tation is γ = ∅ , α k = 1 k = u 0 k 6 = u , β k = 1 k = i 0 k 6 = i (26) 3.2 P airwise rank mo del F or the ranking m odel, w e are in terested in the order of t w o items i, j giv en a user u . A pairwise ranking mo del is describ ed as follows P ( r ui > r uj ) = sig moid µ + b i − b j + p T u ( q i − q j ) (27) 6 The corresp onding features represen tation are lik e this γ = ∅ , α k = 1 k = u 0 k 6 = u , β k = 1 k = i − 1 k = j 0 k 6 = i, k 6 = j (28) b y using sigmoid and log-lik eliho o d as loss function. Note that the feature representation giv es one extra b u whic h is not desirable. W e can remov ed it by give high regularization to b u that p enalize it to 0. 3.3 T emp oral Information A mo del that include temp oral information[4] can b e describ ed as follo ws y = µ + b u ( t ) + b i ( t ) + b u + b i + ( p u + p u ( t )) T q i (29) W e can include b i ( t ) using global feature, and b u ( t ), p u ( t ) using user feature. F or example, we can define a time in terp olation mo del as follo ws y = µ + b i + b s u e − t e − s + b e u t − s e − s + p s u e − t e − s + p e u t − s e − s T q i (30) Here e and s mean start and end of the time of all the ratings. A rating that’s rated later will b e affected more by p e and b e and earlier ratings will b e more affected b y p s and b s . F or this mo del, w e can define γ = ∅ , α k = e − t e − s k = u t − s e − s k = u + n 0 otherwise , β k = 1 k = i 0 k 6 = i (31) Note w e first arrange the p s in the first n features then p e in next n features. 3.4 Neigh b orho o d information A mo del that include neigh b orho o d information[3] can b e describ ed as b elo w: y = µ + X j ∈ R ( u ) s ij h | R ( u ) | − 1 2 ( r uj − ¯ b u ) i + b u + b i + p T u q i (32) W e only need to implement neigh borho o d information to global fea- tures as describ ed b y Section 2.1. 7 3.5 Hierarc hical information In Y aho o! Music Dataset[2], some trac ks b elongs to same artist. W e can include suc h hierarc hical information by adding it to item feature. The mo del is describ ed as follo ws y = µ + b u + b t + b a + p T u ( q t + q a ) (33) Here t means track and a denotes corresp onding artist. This mo del can b e formalized as feature-based matrix factorization by redefining item feature. 4 Efficien t training for SVD++ F eature-based matrix factorization can naturally incorp orate implicit and explicit information. W e can simply add these information to user feature α . The mo del configuration is shown as follows: y = bias + X j ξ j p j + X j α j d j T X j β j q j (34) Here we omit the detail of bias term. The implicit and explicit feed- bac k information is given b y P j α j d j , where α is the feature vec- tor of feedback information, α j = 1 √ | R ( u ) | for implicit feedback, and α j = r u,j − b u √ | R ( u ) | for explicit feedbac k. d j is the parameter of implicit and explicit feedbac k factor. W e explicitly state out the implicit and explicit information in Equation 34. Although Equation 34 shows that we can easily incorp orate im- plicit and explicit information in to the mo del, it’s actually v ery costly to run the sto chastic gradient training, since the up date cost is linear to the size of nonzero en tries of α , and α can be very large if a user has rated many items. This will greatly slow do wn the training sp eed. W e need to use an optimized metho d to do training. T o show the idea of the optimized metho d, le t’s first define a derived user implicit and explicit factor p im as follo ws: p im = X j α j d j (35) The up date of d j after one step is giv en b y the follo wing equation ∆ d j = η ˆ eα j X j β j q j (36) 8 The resulted difference in p im is giv en b y ∆ p im = η ˆ e X j α 2 j X j β j q j (37) Giv en a group of samples with the same user , w e need to do gradien t descen t on each of the training sample. The simplest w a y is to do the follo wing steps for each sample: (1) calculate p im to get prediction (2) up date all d j asso ciates with implicit and explicit feedback. Every time p im has to be recalculated using up dated d j in this w a y . Ho w ev er, w e can find that to get new p im , we don’t need to up date each d j . Instead, we only need to update p im using Equation 37. What’s more, w e can find there is a relation b et w een ∆ p im and ∆ d j as follo ws: ∆ d j = α j P k α 2 k ∆ p im (38) W e shall emphasize that Equation 38 is true ev en for multiple up dates , giv en the condition that the user is same in all the samples. W e shall men tion that the ab ov e analysis doesn’t consider the regularization term. If L2 regularization of d j is used during the up date as follo ws: ∆ d j = η ˆ eα j X j β j q j − λd j (39) The corresp onding c hanges in p im also lo oks v ery similar ∆ p im = η ˆ e X j α 2 j X j β j q j − λp im (40) Ho w ev er, the relation in Equation 38 no longer holds strictly . But we can still use the relation since it approximately holds when regular- ization term is small. Using the results w e obtained, we can develop a fast algorithm for feature-based matrix factorization with implicit and explicit feedback information. The algorithm is sho wn in Algorithm 1. W e find that the basic idea is to group the data of the same user together, for the same user shares the same implicit and explicit feed- bac k information. Algorithm 1 allo ws us to calculate implicit feedbac k factor only once for a user, greatly sa ving the computation time. 5 Ho w large-scale data is handled Recommender system confron ts the problem of large-scale data in practice. This is a must when dealing with real problems. F or ex- 9 Algorithm 1 Efficien t T raining for Implicit and Explicit F eedback for all user u do p im ← P j α j d j { calculating implicit feedbac k } p old ← p im for all training samples of user u do up date other parameters, using p im to replace P j α j d j up date p im directly , do not up date d j . end for for all i, α i 6 = 0 do d i ← d i + α i P k α 2 k ( p im − p old ) { add all the changes bac k to d } end for end for ample Y aho o! Music Dataset[2] consists of more than 200M ratings. A to olkit that’s robust to input data size is desirable for real applica- tions. 5.1 Input data buffering The input training data is extremely large in real application, w e don’t try to load all the training data into memory . Instead, we buffer all the training data through binary format in to the hard-disk. W e use sto c hastic gradien t descend to train our model, that is we only need to linearly iterate o v er the data if we sh uffle our data b efore buffering. Therefore, our solution requires the input feature to b e previously sh uffled, then a buffering program will create a binary buffer from the input feature. The training pro cedure reads the data from hard-disk and uses sto chastic gradient desc end to train the mo del. This buffering approac h mak es the memory cost inv arian t to the input data size, and allo ws us to train mo dels ov er large-scale of input data so long as the parameters fit in to memory . 5.2 Execution pip eline Although input data buffering can solve the problem of large-scale data, it still suffers from the cost of reading the data from hard-disk. T o minimize the cost of I/O, w e use a pre-fetc hing strategy . W e create a indep endent thread to fetc h the buffer data into a memory queue, then the training program reads the data from memory queue and do training. The pro cedure is shown in Figure 2 This pip eline st yle of execution remov es the burden of I/O from the training thread. So long as I/O sp eed is similar or faster to train- 10 Matrix Factorization Buffer Stochastic Gradient Descent in Memory INPUT Data in Disk FETCH Thread 1 Thread 2 Figure 2: Execution pip eline ing sp eed, the cost of I/O is negligible, and our our exp erience on KDDCup’11 prov es the success of this strategy . With input buffering and pip eline execution, w e can train a model with test RMSE=22.16 for trac k1 in KDDCup’11 2 using less than 2G of memory , without significan tly increasing of training time. 6 Related w ork and discussion The most related w ork of feature based matrix factorization is F ac- torization Machine [6]. The reader can refer to libFM 3 for a to olkit for factorization mac hine. Strictly speaking, our to olkit implemen t a r estricte d case of factorization mac hine and is more useful in some as- p ects. W e can supp ort global feature that do esn’t need to b e tak e into factorization part, which is imp ortan t for bias features suc h as user da y bias, neighborho o d based features, etc. The divide of features also giv es hints for mo del design. F or global features, we shall con- sider what asp ect may influence the ov erall rating. F or user and item features, w e shall consider how to describ e the user preference and item prop ert y b etter. Our mo del is also related to [1] and [9], the difference is that in feature-based matrix factorization, the user/item feature can asso ciate with temp oral information and other context informa- tion to b etter describ e the preference or prop erty in current context. Our current model also has shortcomings. The mo del do esn’t supp ort m ultiple distinct factorizations at present. F or example, sometimes w e ma y wan t to introduce user vs time tensor factorization together with user vs item factorization. W e will try our best to ov ercome these dra wbac ks in the future w orks. References [1] Deepak Agarwal and Bee-Ch ung Chen. Regression-based latent factor mo dels. In Pr o c e e dings of the 15th ACM SIGKDD interna- 2 kddcup.y aho o.com 3 h ttp://www.libfm.org 11 tional c onfer enc e on Know le dge disc overy and data mining , KDD ’09, pages 19–28, New Y ork, NY, USA, 2009. ACM. [2] Gideon Dror, Noam Koenigstein, Y eh uda Koren, and Markus W eimer. The Y aho o! Music dataset and KDD-Cup’11. In KDD- Cup Workshop , 2011. [3] Y ehuda Koren. F actorization meets the neighborho o d: a multi- faceted collab orative filtering mo del. In Pr o c e e ding of the 14th A CM SIGKDD international c onfer enc e on Know le dge disc overy and data mining , KDD ’08, pages 426–434, New Y ork, NY, USA, 2008. A CM. [4] Y ehuda Koren. Collab orative filtering with temp oral dynamics. In Pr o c e e dings of the 15th ACM SIGKDD international c onfer enc e on Know le dge disc overy and data mining , KDD ’09, pages 447–456, New Y ork, NY, USA, 2009. ACM. [5] A. Paterek. Improving regularized singular v alue decomp osition for collab orative filtering. In Pr o c e e dings of KDD Cup and Work- shop , v olume 2007, 2007. [6] Steffen Rendle. F actorization machines. In Pr o c e e dings of the 10th IEEE International Confer enc e on Data Mining . IEEE Computer So ciet y , 2010. [7] Jasson D. M. Rennie and Nathan Srebro. F ast maxim um margin matrix factorization for collab orative prediction. In Pr o c e e dings of the 22nd international c onfer enc e on Machine le arning , ICML ’05, pages 713–719, New Y ork, NY, USA, 2005. ACM. [8] Nathan Srebro, Jason D. M. Rennie, and T ommi S. Jaak ola. Maxim um-Margin Matrix F actorization. In A dvanc es in Neur al Information Pr o c essing Systems 17 , v olume 17, pages 1329–1336, 2005. [9] David H. Stern, Ralf Herbric h, and Thore Graep el. Match b ox: large scale online bay esian recommendations. In Pr o c e e dings of the 18th international c onfer enc e on World wide web , WWW ’09, pages 111–120, New Y ork, NY, USA, 2009. ACM. 12
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment