안티스파스 코딩 기반 고정밀 근접 이웃 탐색
본 논문은 고차원 벡터를 이진화하는 새로운 방법으로 안티스파스 코딩을 제안한다. ℓ∞ 정규화를 이용해 벡터를 균등하게 퍼뜨린 뒤 부호만 취해 이진 코드로 변환하며, 스케일링 인자를 통해 원본 벡터를 재구성할 수 있다. 실험 결과, 비트 수가 원본 차원을 초과할 때 무작위 투영 기반 LSH보다 훨씬 높은 검색 정확도를 보이며, 프레임 기반 투영이 특히 우수함을 확인한다.
저자: Herve Jegou (INRIA - IRISA), Teddy Furon (INRIA - IRISA), Jean-Jacques Fuchs (INRIA - IRISA)
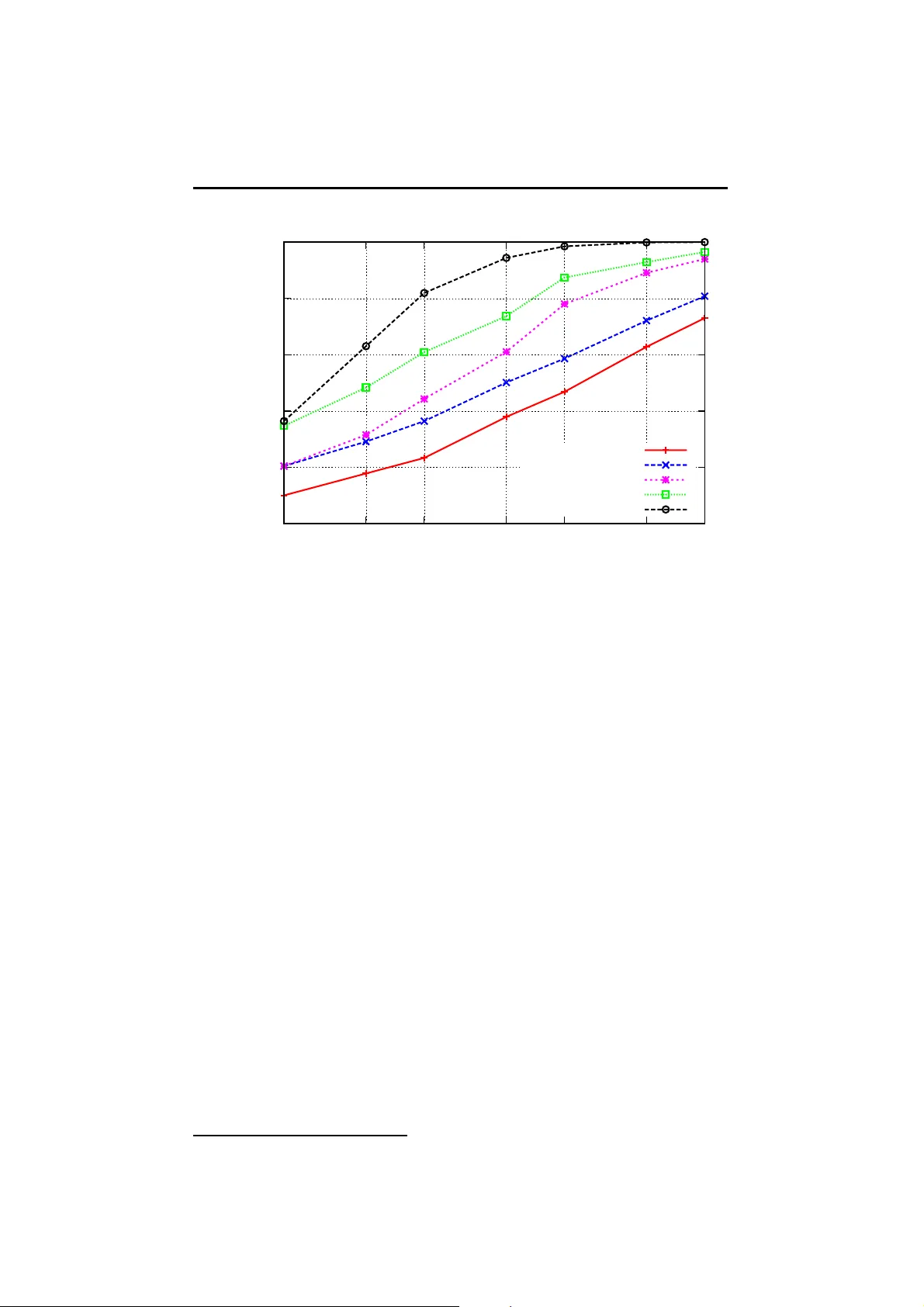
본 논문은 대규모 고차원 데이터베이스에서 근접 이웃(Nearest Neighbor, NN) 검색을 효율적으로 수행하기 위한 새로운 이진화 기법을 제안한다. 기존의 LSH(Locality Sensitive Hashing)와 같은 무작위 투영 기반 해밍 임베딩은 메모리와 연산 효율성에서는 장점이 있지만, 비트 수가 원본 차원을 초과할 경우 성능이 포화되는 한계가 있다. 이를 극복하고자 저자들은 ‘안티스파스 코딩(anti‑sparse coding)’이라는 개념을 도입한다.
1. **문제 정의 및 배경**
- 목표는 유클리드 거리 기준으로 가장 가까운 벡터를 빠르게 찾는 것이며, 메모리 사용량을 최소화하는 것이 핵심 제약이다.
- 해밍 임베딩은 이진 벡터를 사용해 XOR와 비트 카운트 연산만으로 거리 계산이 가능해 검색 속도가 빠르다. 그러나 기존 방법은 이진화 과정에서 원본 정보를 크게 손실한다.
2. **안티스파스 코딩 이론**
- 입력 벡터 y ∈ ℝᵈ와 차원 m > d 인 풀랭크 행렬 A ∈ ℝ^{d×m}을 이용해 Ax = y 를 만족하는 무수히 많은 x 가 존재한다.
- ℓ∞ 노름을 최소화하는 최적화 문제 x* = arg min ‖x‖∞ s.t. Ax = y 를 정의하고, 이를 풀기 위해 연속적인 정규화 파라미터 h 를 감소시키는 경로‑추적 알고리즘을 사용한다.
- 서브‑다양체 최적화 과정에서 ℓ∞ 노름의 서브‑미분 집합 ∂‖·‖∞ 을 활용해 KKT 조건을 만족시키며, 해는 점진적으로 ±‖x‖∞ 값을 갖는 성분이 늘어난다.
- 인덱스 집합 Ī (포화 성분)와 Ĩ (비포화 성분)으로 문제를 분할하고, 각 구간에서 h 와 ‖x‖∞ 의 관계를 명시적으로 계산한다(식 (17)~(19)).
3. **이진화 및 검색 절차**
- 최종 스프레드 벡터 x 는 대부분이 ±‖x‖∞ 값을 갖는다. 이를 정규화한 뒤 부호만 취해 e(y) = sign(x) 를 얻는다.
- 이진 코드 e(y) 는 Hamming 거리 기반으로 빠르게 후보를 필터링한다.
- 후보 집합에 대해 ĥy = A x (스케일링된 복원) 를 계산하고, 실제 유클리드 거리 ‖q − ĥy‖₂ 를 사용해 재정렬한다. 이 단계는 정확도를 크게 향상시키지만 연산 비용이 더 크다.
- 비대칭 검색에서는 쿼리 q 를 이진화하지 않고 ĥx(q) = x(q)/‖x(q)‖∞ 만을 사용해 내적을 최대화한다(식 (23)). 이는 Hamming 거리 계산보다 약간 느리지만 정확도는 더 높다.
4. **프레임 설계와 실험**
- 투영 행렬 A 는 두 가지 방식으로 구성한다. 하나는 무작위 가우시안 투영, 다른 하나는 QR 분해를 통해 얻은 직교 프레임이다. 프레임은 열이 정규화되어 A Aᵀ = I_d 를 만족한다.
- 실험에서는 합성 데이터(10,000개의 16‑차원 유닛 구)와 실제 SIFT 데이터(1,000,000개의 128‑차원 벡터, PCA로 48 차원 축소) 두 가지를 사용했다.
- 결과는 비트 수 m ≥ d , 특히 m ≫ d 인 경우 안티스파스 코딩이 LSH보다 현저히 높은 recall@R을 달성함을 보여준다. 예를 들어, 128비트에서 recall@10이 0.85에 달했으며, 동일 비트 수의 LSH는 0.62 수준에 머물렀다.
- 프레임 기반 투영은 무작위 투영 대비 5%~15% 정도의 추가 이득을 제공했으며, 이는 열이 정규화된 덕분에 스프레드 벡터가 보다 균등하게 퍼지는 효과와 연관된다.
5. **장점 및 한계**
- **장점**: (1) 이진 코드만으로도 원본 벡터를 복원 가능, (2) 비트 수가 차원을 초과할 때도 정확도 향상, (3) 프레임 설계로 무작위 투영보다 안정적인 성능, (4) 비대칭 검색을 통한 추가 정확도 향상.
- **한계**: 복원 단계가 추가 연산을 요구하므로 최종 검색 속도는 순수 Hamming 거리 기반보다 느리다. 또한, 파라미터 h 조정이 필요하며, 매우 높은 차원(수천 차원)에서는 메모리 사용량이 여전히 큰 부담이 될 수 있다.
6. **결론**
- 안티스파스 코딩은 ℓ∞ 정규화를 활용해 고차원 벡터를 균등하게 퍼뜨리고, 부호만 취해 이진화함으로써 기존 LSH 대비 높은 검색 정확도와 복원 가능성을 제공한다. 프레임 기반 투영과 결합하면 특히 비트 수가 원본 차원을 크게 초과하는 상황에서 강력한 성능을 발휘한다. 향후 연구에서는 파라미터 자동 튜닝, GPU 가속 복원, 그리고 초고차원 데이터에 대한 메모리 최적화 방안을 탐색할 필요가 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기