Anti-sparse coding for approximate nearest neighbor search
This paper proposes a binarization scheme for vectors of high dimension based on the recent concept of anti-sparse coding, and shows its excellent performance for approximate nearest neighbor search. Unlike other binarization schemes, this framework …
Authors: Herve Jegou (INRIA - IRISA), Teddy Furon (INRIA - IRISA), Jean-Jacques Fuchs (INRIA - IRISA)
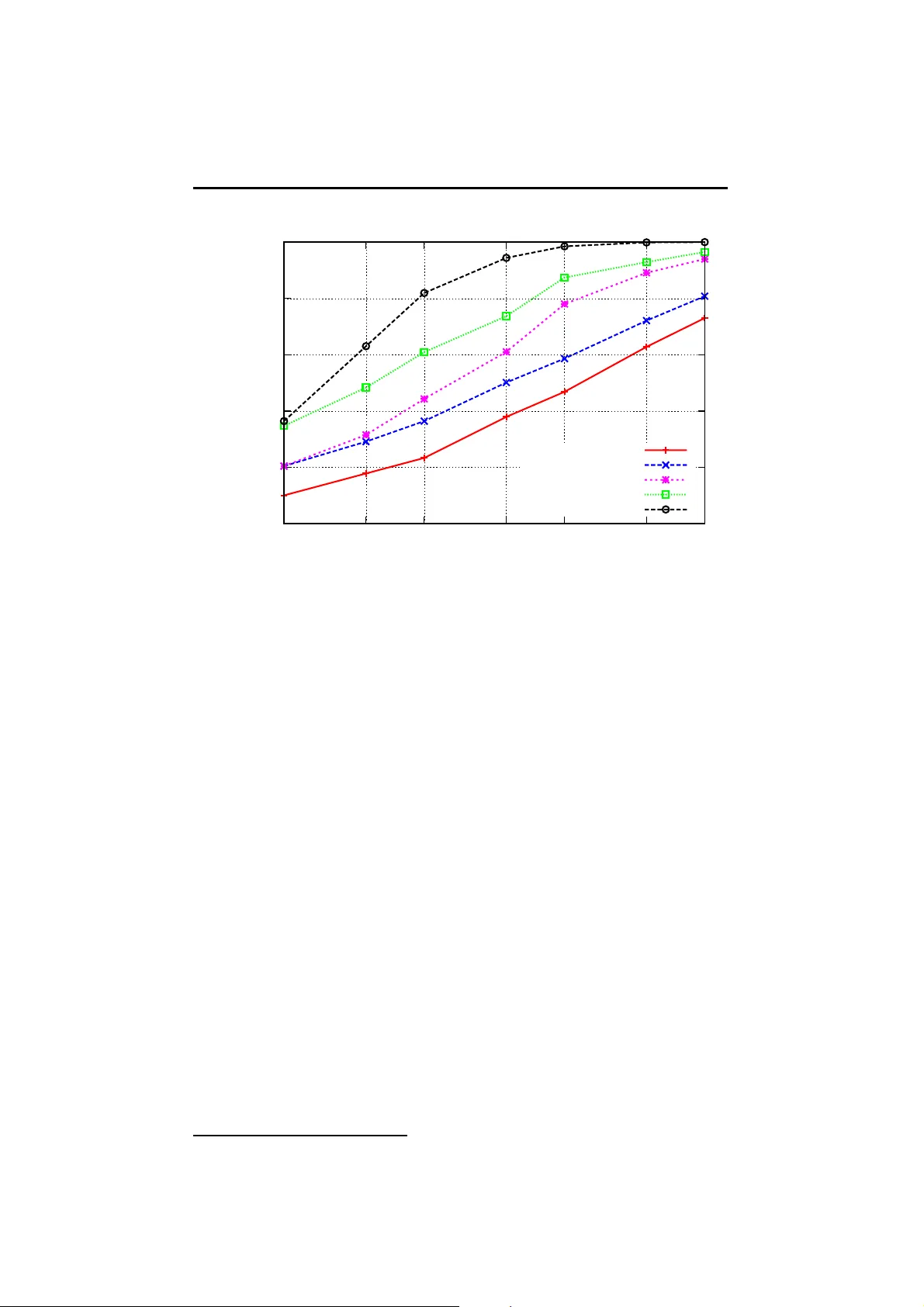
apport de recherche ISSN 0249-6399 ISRN INRIA/RR--7771--FR+ENG P erception, Cognition, Interaction INSTITUT N A TION AL DE RECHERCHE EN INFORMA TIQUE ET EN A UTOMA TIQUE Anti-sparse coding f or appro xim ate nearest neighbor searc h Hervé Jégou — T e ddy Furon — Jean-Jacques Fuchs N° 7771 October 2011 Centre de recherche INRIA Rennes – Bretagne Atlantique IRISA, Campus universitaire de Beaulieu, 35042 Rennes Cedex Téléphone : +33 2 99 84 71 00 — T éléco pie : +33 2 99 84 71 71 An ti-sparse co ding for appro xima te nearest neigh b or searc h Herv é Jégou , T eddy F uron , Jean-Jacques F uc hs Domain : Perception, Cognition, In teraction Équipe-Pro jet T exmex Rapp ort de re cherche n° 7771 — Octob er 201 1 — 13 pages Abstract: This pap er pr op oses a binarizatio n scheme for vectors of hig h dimen- sion based on the recent concept of ant i-sp arse co ding, and shows its exc e llent per formance for approximate neare s t neighbor sea r ch. Unlike other binar ization schemes, this framework allows, up to a scaling factor , the explicit rec o nstruction from the binary repres ent ation o f the orig inal vector. The pap er a lso s hows that random pro jections which are used in Lo cality Sensitive Ha s hing algorithms, ar e significantly outp erformed by re g ular frames for b oth synthetic a nd r eal data if the num b er of bits exceeds the vector dimensio nality , i.e., when high precisio n is requir ed. Key-w ords: sparse co ding, spread representations, approximate neigh b o rs search, Hamming embedding This work was realized as part of the Quaero Pro ject, funded b y OSEO, F renc h State agency for inno v ation. Co dage an ti -parcimonieux p our la rec herc he appro ximativ e de plus pro c hes v oisins Résumé : Cet article prop oses une tec hnique de binar isation q ui s ’appuie sur le concept récent de c o dage anti-p ar cimonieux , et mon tre ses excellentes per formances da ns un contexte de recherc he a pproximativ e de plus pro ches voisins. Contrairemen t aux métho des co ncurrentes, le cadre prop osé p ermet, à un facteur d’échelle près, la reconstr uctio n explicite du vecteur enco dé à par - tir de s a représentation binaire. L’article montre également que les pro jec- tions aléa to ires qui sont co mmunémen t utilisées dans les mé tho des de hachage m ulti-dimensionnel peuvent êtr e av antageusemen t remplacées par des frames régulières lorsque le nombre de bits excède la dimension originale du descrip- teur. Mots-clés : co dage parcimonieux, repr ésentations éta lées, recherche a pprox- imative de plus pro ches voisins, bina risation Anti-sp arse c o ding for appr oximate se ar ch 3 1 I n tro duction This pa p e r addr esses the problem of appr oximate nearest neighbor (ANN) search in high dimensio nal spaces. Given a query vector, the ob jective is to find, in a co llec tio n of v e ctors, those which are the closest to the query with resp ect to a given distance function. W e focus on the Euclidean distance in this pa pe r . This problem has a very high practica l int erest, since matching the descriptors representing the media is the most consuming op er a tion of most state-of-the-ar t a udio [1], image [2] and video [3] indexing techniques. There is a large b o dy of literature o n tec hniques whose aim is the optimization of the trade-off betw e e n retriev al time a nd complexity . W e are in teres ted by the techniques that rega rd t he memory usage of the index a s a ma jor criterio n. This is compulsory when considering la rge data sets including dozen mi llions to billions of vectors [4, 5 , 2, 6], because t he indexed representation must fit in memory to avoid co stly hard-drive a ccesses. One po pular way is to use a Hamming Embedding function that maps the real vec- tors into binary vectors [4, 5, 2]: Binary vectors are compact, and sea rching the Hamming space is efficient ( XOR op eration and bit count) even if the com- parison is exhaustiv e b etw een th e binar y query and the database vectors. An extension to these techniques is the asymmetric s cheme [7, 8] which limits the approximation done on the quer y , leading to b etter r e s ults for a slightly higher complexity . W e prop ose to addre s s the ANN sea rch problem with an anti-sp arse solution based on the desig n of spr e ad r epresentations recently prop o s ed by F uchs [9]. Sparse co ding has r eceived in the last decade a huge a tten tion from b oth the- oretical and pr actical p oints of v ie w. Its ob jective is to represent a vector in a higher dimensional spa ce with a very limited num b er of non-zero s compo nents. An ti-s parse co ding has the opp osite prop erties. It o ffers a robust re presentation of a vector in a higher dimensional space with a ll the comp onents sharing evenly the infor mation. Sparse and a nti-sparse co ding admits a co mmon formulation. The a lgo- rithm prop ose d by F uchs [9] is indeed similar to path-following metho ds based on co nt in uation techniques like [1 0]. The anti-sparse problem considers a ℓ ∞ pena lization term where the sparse pro blem usually cons ide rs the ℓ 1 norm. The pena lization in k x k ∞ limits the range of the co efficients which in turn tend to ‘stick’ their v a lue to ±k x k ∞ [9]. As a result, the anti-sparse approximation offers a natura l binariza tion metho d. Most imp o rtantly and in contrast to other Hamming Embedding techniques, the binar ized vector a llows an explicit and reliable reconstruction of the original database vector. This reconstruction is very useful to re fin e the sea rch. Fir st, the compar ison of the Hamming distance s b etw een the binary r epresentations iden tifies some p otential near est neighbors. Second, this l ist is r efined by com- puting the Euclidean distances b etw een the query a nd the reconstr uctions of the da ta base vectors. W e provide a Matlab pack a ge to repro duce the analysis c o mparisons rep orted in this pa p er (for the tests on s ynthet ic data), see http: //www .irisa.fr/texmex/people/jegou/src.php . The pa pe r is orga nized as follows. Section 2 intro duces the anti-sparse co ding framework. Section 3 describ es the cor resp onding ANN search metho d which is ev a luated in Section 4 on b oth synthetic and real da ta. RR n° 7771 Anti-sp arse c o ding for appr oximate se ar ch 4 2 Spr ead represen tations This sectio n briefly descr ib es the anti-sparse co ding of [9]. W e first introduce the o b jective function and provide the g uidelines o f the algorithm giving the spread representation of a given input re a l vector. Let A = [ a 1 | . . . | a m ] b e a d × m ( d < m ) full ra nk matr ix . F or any y ∈ R d , the s y stem A x = y admits an infinite num b e r of solutions. T o single out a unique solution, one a dd a cons tr aint a s for ins ta nce se e k ing a minimal norm solution. Whereas the case of the Euclidean no rm is trivial, a nd the case of the ℓ 1 -norm stems in the v ast literature of sparse represe nt a tion, F uc hs recently studied the case of the ℓ ∞ -norm. F ormally , the pr oblem is: x ⋆ = min x : A x = y k x k ∞ , (1) with k x k ∞ = max i ∈{ 1 ,...,m } | x i | . Interestingly , he prov ed that b y minimizing the range of the compo nent s, m − d + 1 of them ar e stuc k to the limit, ie. x i = ±k x k ∞ . F uchs also exhibits an efficient wa y to solve (1 ). He prop os es to solve the ser ies of simpler problems x ⋆ h = min x ∈ R m J h ( x ) (2) with J h ( x ) = k A x − y k 2 2 / 2 + h k x k ∞ (3) for so me decrea sing v alues of h . As h → 0 , x ⋆ h → x ⋆ . 2.1 The sub-diff er ential set F o r a fixed h , J h is not differentiable due to k . k ∞ . Ther efore, we need to work with s ub-differential sets. The sub-differential set ∂ f ( x ) of function f a t x is the set o f gradients v s.t. f ( x ′ ) − f ( x ) ≥ v ⊤ ( x ′ − x ) , ∀ x ′ ∈ R m . F or f ≡ k . k ∞ , we have: ∂ f ( 0 ) = { v ∈ R m : k v k 1 ≤ 1 } , (4) ∂ f ( x ) = { v ∈ R m : k v k 1 = 1 , (5) v i x i ≥ 0 if | x i | = k x k ∞ , v i = 0 els e } , for x 6 = 0 Since J h is co nv ex, x ⋆ h is so lution iff 0 b elongs to the sub-differential set ∂ J h ( x ⋆ h ) , i.e. iff there exis t v ∈ ∂ f ( x ⋆ h ) s.t. A ⊤ ( A x ⋆ h − y ) + h v = 0 (6) 2.2 Initialization and first iteration F o r h 0 large enough, J h 0 ( x ) is dominated b y k x k ∞ , a nd the solution wr ites x ⋆ h 0 = 0 and v = h − 1 0 A ⊤ y ∈ ∂ f ( 0 ) . (4) shows that this solution no longer holds for h < h 1 with h 1 = k A ⊤ y k 1 . F o r k x k ∞ small eno ug h, J h ( x ) is do minated by k y k 2 − x ⊤ A ⊤ y + h k x k ∞ whose minimizer is x ⋆ h = k x k ∞ sign ( A ⊤ y ) . In this case, ∂ f ( x ) is the set o f RR n° 7771 Anti-sp arse c o ding for appr oximate se ar ch 5 vectors v s .t. sign ( v ) = sign ( x ) and k v k 1 = 1 . Multiplying (6) by sign ( v ) ⊤ on the left, we hav e h = h 1 − k A sign ( A ⊤ y ) k 2 k x k ∞ . (7) This shows tha t i) x ⋆ h can b e a solution for h < h 1 , and ii) k x k ∞ increases as h decreases. Y et, Equation (6) also imp oses that v = ν 1 − µ 1 k x k ∞ , with ν 1 , h − 1 A ⊤ y and µ 1 , h − 1 A ⊤ A sign ( A ⊤ y ) . (8) But, the co ndition sign ( v ) = sign ( x ) from (5) must hold. This limits k x k ∞ b y ρ i 2 where ρ i = ν i /µ i and i 2 = arg min i : ρ i > 0 ( ρ i ) , which in turn translates to a low er b ound h 2 on h via (7 ). 2.3 Index partition F o r the sake of simplicit y , we introduce I , { 1 , . . . , m } , and the index partition ¯ I , { i : | x i | = k x k ∞ } and ˘ I , I \ ¯ I . The restriction of vectors and matrices to ¯ I (resp. ˘ I ) ar e denoted alike ¯ x (resp. ˘ x ). F or instance, Equation (5) transla tes in sign ( ¯ v ) = sig n ( ¯ x ) , k ¯ v k 1 = 1 and ˘ v = 0 . The index pa rtition splits (6) into t wo parts: ˘ A ⊤ ˘ A ˘ x + ¯ A sign ( ¯ v ) k x k ∞ = ˘ A ⊤ y (9) ¯ A ⊤ ˘ A ˘ x + ¯ A sign ( ¯ v ) k x k ∞ − y = − h ¯ v (10) F o r h 2 ≤ h < h 1 , w e’ve seen that ¯ x = x , ¯ v = v , and ¯ A = A . Their ‘tilde’ versions ar e empty . F o r h < h 2 , the index partition ¯ I = I and ˘ I = ∅ ca n no longer hold. Indeed, when v i 2 is null a t h = h 2 , the i 2 -th column o f A mov es from ¯ A to ˘ A s.t. now, ˘ A = [ a i 2 ] . 2.4 General iteration The general itera tion cons ists in determining on which interv a l [ h k +1 , h k ] an index pa rtition holds, giving the expressio n of the so lution x ⋆ h and prop osing a new index partition to the next iteration. Provided ˘ A is full rank, (9) g ives ˘ x = ξ k + ζ k k x k ∞ , (11) with ξ k = ( ˘ A ⊤ ˘ A ) − 1 ˘ A ⊤ y (12) and ζ k = − ( ˘ A ⊤ ˘ A ) − 1 ¯ A sign ( ¯ v ) . (13) Equation 10 gives: ¯ v = ν k − µ k k x k ∞ , (14) with µ k = ¯ A ⊤ ( I − ¯ A ⊤ ˘ A ( ˘ A ⊤ ˘ A ) − 1 ) ¯ A sign ( ¯ v ) /h (15) and ν k = ( ˘ A ⊤ y − ξ k ) /h. (16) RR n° 7771 Anti-sp arse c o ding for appr oximate se ar ch 6 Left multiplying (10) by sign ( ¯ v ) , we get: h = η k − υ k k x k ∞ (17) with υ k = ( ¯ A sign ( ¯ v )) ⊤ I − ˘ A ( ˘ A ⊤ ˘ A ) − 1 ˘ A ⊤ ¯ A sign ( ¯ v ) , (18) and η k = − s ign ( ¯ v ) ⊤ ¯ A ⊤ ( ˘ A ˘ x − y ) . (19) Note that υ k > 0 s o that k x k ∞ increases when h decrease s . These equations extend a so lution x ⋆ h to the neighborho od o f h . How ever, we m ust check that this index pa rtition is still v a lid a s we decr ease h and k x k ∞ increases. T wo even ts can br eak the v alidity: • Like in the first iteration, a comp onent o f ¯ v given in (14) bec o mes null. This index mov es from ¯ I to ˘ I . • A comp onent of ˘ x given in (11) sees its amplitude equalling ±k x k ∞ . This index mov es from ˘ I to ¯ I , and the sign of this comp onent will b e the s ign of the new comp onent of ¯ x . The v a lue of k x k ∞ for whic h o ne of these t wo ev e nts fir s t happ e ns is tr anslated in h k +1 thanks to (17). 2.5 Stopping condition and output If the go al is to minimize J h t ( x ) for a sp ecific target h t , then the alg orithm s tops when h k +1 < h t . The rea l v alue of k x ⋆ h t k ∞ is given b y (17), and the comp onents not stuc k to ±k x ⋆ h t k ∞ b y (11). W e obtain the s pr ead representation x of the input vector y . The vector x has man y of its comp onents equal to ±k x k ∞ . An approximation of the original vector y is obtained by ˆ y = A x . (20) 3 I ndexing and searc h me c hanisms This section descr ibes ho w Hamming Embedding functions a re used for a pprox- imate sear ch, and in par ticula r how the ant i-sparse co ding framework descr ib ed in Sectio n 2 is exploited. 3.1 Problem statemen t Let Y b e a dataset of n real vectors, Y = { y 1 , . . . , y n } , wher e y i ∈ R d , and consider a query vector q ∈ R d . W e aim at finding the k vectors in Y that a r e closest to the query , with res p e c t to the Euclidean distance. F o r the sake of exp osure, we consider without loss of g e ner ality the near est neighbor problem, i.e., the cas e k = 1 . The neares t neighbor o f q in Y is defined a s NN ( q ) = arg min y ∈Y k q − y k 2 . (21) The go al of approximate search is to find this nea rest neighbo r with high probability and using as less resour ces as p oss ible. The p erfor mance criteria are the following: RR n° 7771 Anti-sp arse c o ding for appr oximate se ar ch 7 • The q uality o f the sear ch, i.e., to which extent the algorithm is able to return the true nearest neighbor ; • The sea rch efficiency , typically measured by the query time ; • The memor y usage, i.e., the num b er of bytes used to index a vector y i of the da ta base. In our pap er, we a ssess the s earch quality by the reca ll@R mea sure: ov er a set of queries, w e co mpute the pr op ortion for which the sy s tem returns the true nearest neighbor in the first R p ositions. 3.2 Appro ximate searc h with binary em b eddings A cla ss o f ANN metho ds is ba sed o n embedding [4, 5, 2]. The idea is to map the input vectors to a space wher e the repres e ntation is compact and the comparis o n is efficient. The Hamming space offers these tw o desira ble prop erties. The key problem is the design of the embedding function e : R d → B m mapping the input v ecto r y to b = e ( y ) in the m - dimensional Hamming space B m , her e defined a s { − 1 , 1 } m for the sake of exp osure. Once this function is defined, all the database vectors are mapp ed to B m , and the sea rch problem is translated in to the Hamming space bas ed on the Hamming distance, or , equiv a lently: NN b ( e ( q )) = arg ma x y ∈Y e ( q ) ⊤ e ( y ) . (22) NN b ( e ( q )) is returned as the a pproximate NN ( q ) . Binarization with anti-sparse co ding. Giv en a n input vector y , the anti- sparse co ding of Sec tio n 2 pro duces x with many comp onents equal to ±|| x || ∞ . W e co nsider a “pre-binar ized” version ˙ x ( y ) = x / k x k ∞ , and the binarized version e ( y ) = s ig n ( x ) . 3.3 Hash function design The lo calit y sensitive hashing (LSH) algor ithm is mainly ba sed on r andom pro - jection, thoug h different kinds o f hash functions hav e been pro p osed for the Euclidean space [11]. L et A = [ a 1 | . . . | a m ] b e a d × m matrix storing the m pro jection vectors. The most simple wa y is to ta ke the sign of the pro jections: b = sign ( A ⊤ y ) . Note that this corresp o nds to the firs t iteration of our algor ithm (see Section 2.2). W e a lso try A a s an uniform fra me. A p oss ible constructio n of such a fra me consists in p erfor ming a QR decomp ositio n on a m × m ma trix. The matrix A is then co mpo sed o f the d first rows of the Q matrix, ensuring that A × A ⊤ = I d . Section 4 shows that such frames significantly impr ov e the res ults compared with random pro jections, for bo th LSH a nd anti-sparse co ding em b edding metho ds. 3.4 Asymmetric sc hemes As recently suggested in the literature, a b etter search quality is obtained by av oiding the binariza tion of the query vector. Sev eral v aria nt s are po ssible. RR n° 7771 Anti-sp arse c o ding for appr oximate se ar ch 8 W e c onsider the simplest o ne der ived from (22), where the quer y is not bina - rized in the inner pro duct. F o r our anti-sparse co ding scheme, this amo unt s to per forming the sea rch ba sed on the following max imization: NN a ( e ( q )) = arg ma x y ∈Y ˙ x ( q ) ⊤ e ( y ) . (23) The estimate NN a is b etter than NN b . The memory usa ge is the same be c a use the vect ors in the database { e ( y i ) } are all binarized. Ho wever, this asymmetric scheme is a bit slow er than the pure bit-based co mparison. F or better efficiency , the search (23 ) is done using lo ok- up tables computed for the query and prior to the compa risons [8]. This is slightly slower than computing the Hamming distances in (22). This a symmetric scheme is interesting for any binar ization scheme (LSH or anti-sparse coding) and any definition of A (either random pro jections or a frame). 3.5 Explicit reconstruction The anti-sparse binarization scheme explicitly minimizes the reco nstruction er- ror, which is traded in (1) with the ℓ ∞ regulariza tion term. Equation (20) gives a n explicit approximation of the da ta base vector y up to a scaling factor : ˆ y ∝ A b || A b || 2 . The appr oximate near e s t neigh b or s NN e are obtained b y com- puting the exact Euclidean distances || q − ˆ y i || 2 . T his is slow c o mpared to the Hamming distance computation. That is wh y , it is us e d to op erate, lik e in [6], a re-ranking of the first hypotheses returned based o n the Hamming distance (on the asymmetric scheme descr ib e d in Section 3.4). The ma in difference with [6] is that no extra- co de has to b e re tr ieved: the r econstruction ˆ y solely re lies o n b . 4 Sim ul ations and exp erim en ts This section ev a luates the sea r ch qualit y on synthetic and rea l data. In par tic- ular, we measure the impact of: • The Hamming embedding technique: LSH and bina rization bas ed on anti- sparse co ding. W e also compa r e to the s p ec tr al ha shing metho d of [5], using the co de av ailable online. • The choice of matrix A : r andom pro jections or fra me for LSH. F o r the anti-sparse co ding, we alwa ys as sume a frame. • The sear ch metho d: 1) NN b of (22) 2) NN a of (2 3) and 3) NN e as descr ib ed in Section 3.5. Our compar ison foc us es on the case m ≥ d . In the anti-sparse co ding method, the reg ularization term h co nt rols the tra de-off b etw een the robustness of the Hamming e mbedding and the quality of the reconstructio n. Small v alues of h fav ors the quality of the reco nstruction (without any binar ization). Big ger v a lues of h gives mo re co mp o nents stuc k to k x k ∞ , which improves the approx- imation search with bina ry embedding. Optimally , this parameter should b e adjusted to give a r easonable tra de-off b etw een the efficiency of the first stage (methods NN b or NN a ) a nd the re- ranking stage (NN e ). Note how ever that, RR n° 7771 Anti-sp arse c o ding for appr oximate se ar ch 9 0 0.2 0.4 0.6 0.8 1 16 24 32 48 64 96 128 Recall@10 m: number of bits LSH LSH+frame antisparse:NN b antisparse:NN a antisparse:NN e Figure 1: An ti-spar se co ding vs LSH on synthetic da ta . Sear ch quality (r e- call@10 in a vector set of 10 ,000 v ectors) as a function of the num b er of bits o f the r epresentation. thanks to the alg orithm describ ed in Section 2 , the pa r ameter is stable, i.e., a slight mo dification o f this para meter o nly a ffects a few co mp onents. W e set h = 1 in all our exp eriments. T wo datasets are co nsidered fo r the ev aluation: • A databa se o f 10,0 00 16-dimensiona l vectors uniformly drawn on the Eu- clidean unit s phere (normalized Gaussian vectors) and a set o f 1,00 0 query vectors. • A databa se of SIFT [12] descr iptors av aila ble online 1 , c o mprising 1 million database and 10 ,000 query vectors of dimensionality 128. Similar to [5], we firs t reduce the vector dimensiona lit y to 48 comp onents using pr incipal comp onent analysis (PCA). The vectors are not normalized a fter PCA. The comparison o f LSH and an ti-sparse. Figures 1 and 2 s how the p er- formance of Ha mming embeddings for sy nthetic da ta. On Fig. 1, the quality measure is the reca ll@ 10 (pro p o rtion of true NN r anked in firs t 10 p ositions) plotted as a function of the num b er of bits m . F or LSH, observe the muc h b et- ter p erfo rmance obtained b y the pro p o sed frame co nstruction co mpared with random pro jections. The same conclusion holds for anti-sparse binarization. The anti-sparse co ding offers similar search q uality as LSH for m = d when the compa rison is p erformed using NN b of (22). The impr ovemen t gets signif- icant as m increases . The sp ectral ha shing tech nique [5] exhibits p o o r p erfor- mance on this syntheti c dataset. The asymm etric comparison N N a leads a significant improv ement, as al- ready obse r ved in [7, 8]. T he in ter est of a nt i-sparse co ding becomes ob vious 1 h ttp://cor pus- texmex.irisa.fr RR n° 7771 Anti-sp arse c o ding for appr oximate se ar ch 10 0 0.2 0.4 0.6 0.8 1 0 100 200 300 400 500 600 700 800 900 1000 Recall@R R LSH Spectral Hashing antisparse:NN b antisparse:NN a antisparse:NN e Figure 2: Ant i-sparse co ding vs LSH on synthet ic da ta ( m = 4 8 , 10,00 0 vectors in da taset). b y co nsidering the pe r formance o f the comparison NN e based o n the explicit reconstruction of the data base vectors from their binary-c o ded representations. F o r a fixed num b er of bits, the improv ement is h uge co mpared to LSH. It is worth using this technique to re-r ank the first hypo theses obtained by NN b or NN a . Exp eriments on SIFT descriptors. As shown b y Figure 3, LSH is slightly better than anti-sparse on re al data when using the binary repr esentation only (here m = 128 ), which might so lved by tuning h , since the first iteration of antisparse leads the binar ization as LSH. How e ver, the int erest of the ex plicit reconstruction offered b y NN e is a gain o bvious. The final s e a rch quality is significantly b etter than that obtained by spec tr al hashing [5]. Since we do not sp e cifically handle the fac t that our descr iptor are no t nor m a lized after PCA, our r esults co uld probably b e improved b y taking care of the ℓ 2 norm. 5 Conclusion and op en issues In this pap er, we hav e prop o sed anti-sparse co ding as an effectiv e Hamming embedding, which, unlike concurrent techniques, offers an explicit r e construc- tion of the da ta base vectors. T o our knowledge, it outpe r forms all other search tech niques bas ed on binarization. There ar e still tw o o pe n issues to take the bes t of the metho d. First, the computationa l cost is still a bit high for high dimensional vectors. Second, if the prop osed c o deb o ok co nstruction is b etter than r andom pro jections, it is not yet sp ecifically adapted to re a l data. RR n° 7771 Anti-sp arse c o ding for appr oximate se ar ch 11 0 0.2 0.4 0.6 0.8 1 0 100 200 300 400 500 600 700 800 900 1000 Recall@R R LSH Spectral Hashing antisparse:NN b antisparse:NN a antisparse:NN e Figure 3: Approximate sea rch in a SIFT vector set of 1 million vectors. References [1] M. A. Casey , R. V eltk amp, M. Goto, M. Leman, C. Rho des, a nd M. Slaney , “Conten t-based music infor ma tion retr iev a l: Curren t dir e ctions a nd future challenges,” Pr o c. of the IEEE , April 2 008. [2] H. J égou, M. Douze, a nd C. Schm id, “Impr oving bag- of-features for large scale image search,” IJCV , F ebruary 2010 . [3] J. Law-T o, L. C hen, A. Joly , I. La ptev, O. Buisson, V. Gouet-Brunet, N. Bo ujemaa, a nd F. Stent iford, “Video cop y detection: a comparative study ,” in CIVR , July 20 0 7. [4] A. T orr a lba, R. F erg us, and Y. W eis s , “Sma ll co des a nd large da tabases for recognition,” in CVPR , June 2008 . [5] Y. W eiss , A. T orralba, a nd R. F ergus, “Spectra l hashing,” in NIPS , 2 0 08. [6] H. Jégo u, R. T avenard, M. Douze, and L. Amsale g , “ Sear ching in one billion vectors: r e - rank with s ource co ding,” in ICASS P , May 201 1 . [7] W. Dong , M. Charik ar, and K. Li, “ Asymmetric distance estimation with sketc hes for similarity sea rch in high-dimensio na l spaces ,” in S IGIR , July 2008. [8] H. Jég ou, M. Douze, and C. Sc hmid, “Pro duct quantization for nearest neighbor sea r ch,” IEEE T ra n s. P AMI , January 2011. [9] J-J. F uchs, “Spread r epresentations,” in A SILOMAR Confer en c e on Sig- nals, Systems, and Computers , Nov ember 2011 . RR n° 7771 Anti-sp arse c o ding for appr oximate se ar ch 12 [10] B. Efron, T. Hastie, I. Johnstone, a nd R. Tibshir ani, “Least a ngle r e gres- sion,” Ann. Statist. , vol. 32, no. 2, pp. 40 7–49 9, 20 04. [11] A. Andoni and P . Indyk, “Near -optimal hashing algorithms fo r near neigh- bo r problem in high dimensions,” in Pr o c. of the Symp osium on the F oun - dations of Computer Scienc e , 20 06. [12] D. L owe, “Distinctive image features from scale-inv ar iant keypoints,” IJCV , vol. 60 , no. 2, 2004 . RR n° 7771 Anti-sp arse c o ding for appr oximate se ar ch 13 Con ten ts 1 Intr o duction 3 2 Spread representa tions 4 2.1 T he sub- differ e ntial set . . . . . . . . . . . . . . . . . . . . . . . . 4 2.2 I nitializa tion and firs t iteration . . . . . . . . . . . . . . . . . . . 4 2.3 I ndex pa rtition . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5 2.4 Gener al iter ation . . . . . . . . . . . . . . . . . . . . . . . . . . . 5 2.5 Sto pping condition and output . . . . . . . . . . . . . . . . . . . 6 3 Indexing and searc h m ec hanism s 6 3.1 Pro blem statement . . . . . . . . . . . . . . . . . . . . . . . . . . 6 3.2 Appr oximate s e a rch with binary embeddings . . . . . . . . . . . 7 3.3 Ha sh function desig n . . . . . . . . . . . . . . . . . . . . . . . . . 7 3.4 As y mmetric schemes . . . . . . . . . . . . . . . . . . . . . . . . . 7 3.5 Explicit r econstruction . . . . . . . . . . . . . . . . . . . . . . . . 8 4 Simulations and experime n ts 8 5 Conclusi on and ope n issues 10 RR n° 7771 Centre de recherche INRIA Rennes – Bretagne Atlantique IRISA, Campus universitaire de Beaulieu - 35 042 Rennes Cedex (France) Centre de recherc he INRIA Bordeaux – Sud Ouest : Domaine Uni versitaire - 351, cours de la Libération - 33405 T alence Cede x Centre de recherc he INRIA Grenoble – Rhône-Al pes : 655, avenue de l’Europe - 38334 Montbon not Saint-Ismier Centre de recherc he INRIA Lille – Nord Europe : Parc Scientifique de la Haute Borne - 40, ave nue Halley - 59650 V illeneuv e d’Ascq Centre de recherc he INRIA Nancy – Grand Est : LORIA, T echnopôle de Nancy-Brab ois - Campus scienti fique 615, rue du Jardin Botani que - BP 101 - 54602 V illers-lè s -Nanc y Cede x Centre de recherc he INRIA Paris – Rocq uencourt : Domaine de V oluceau - Rocque ncourt - BP 105 - 78153 Le Chesnay Cedex Centre de recherc he INRIA Saclay – Île-de- France : Parc Orsay Uni versit é - ZAC des V ignes : 4, rue Jacques Monod - 91893 Orsay Cedex Centre de recherc he INRIA Sophia Antipolis – Méditerranée : 2004, route des Luciole s - BP 93 - 06902 Sophia Antipol is Cede x Éditeur INRIA - Domaine de V olucea u - Rocquencour t, BP 105 - 78153 Le Chesnay Cedex (France ) http://www.i nria.fr ISSN 0249 -6399
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment