동적 평판 시스템을 위한 강화학습·퍼지 기반 프레임워크
본 논문은 에이전트 기반 전자시장(e‑market)에서 거래 가치와 에이전트 경험을 실시간으로 반영하는 동적 평판 모델을 제안한다. 강화학습(RL)과 퍼지 집합 이론을 결합해 개별 평판과 공유 평판을 가중합하고, 거래 규모에 비례한 보상·벌점을 적용한다. 이를 통해 가치 불균형(Value Imbalance), 투표 조작(Ballot Stuffing), 공동 사기(Collusion) 등 기존 평판 시스템이 취약한 공격을 완화하고, 시장이 균형 상…
저자: Vibha Gaur, Neeraj Kumar Sharma
본 논문은 전자상거래 환경에서 에이전트가 중개자로 작동하는 e‑market의 핵심 문제인 ‘신뢰 구축’을 해결하기 위해 동적 평판 시스템을 설계한다. 서론에서는 전자시장이 개방형이며, 거래 당사자 간에 직접적인 신뢰 관계가 형성되기 어렵다는 점을 강조하고, 기존 평판 모델이 거래 가치와 에이전트 경험을 충분히 반영하지 못해 다양한 공격에 취약함을 지적한다.
관련 연구 섹션에서는 Dempster‑Shafer 기반 증거 모델, Bayesian 기반 TRAVOS, 퍼지 규칙을 활용한 REGRET, 인공신경망 기반 Broker‑Assisting TRS 등 다양한 평판 시스템을 리뷰한다. 이들 모델은 각각 장점이 있지만, ‘동적 가중치 조정’이나 ‘거래 규모 기반 보상’ 같은 요소가 결여돼 재입장 공격, 다중 정체성 공격, 가치 불균형 공격 등에 노출된다는 공통적인 한계를 제시한다.
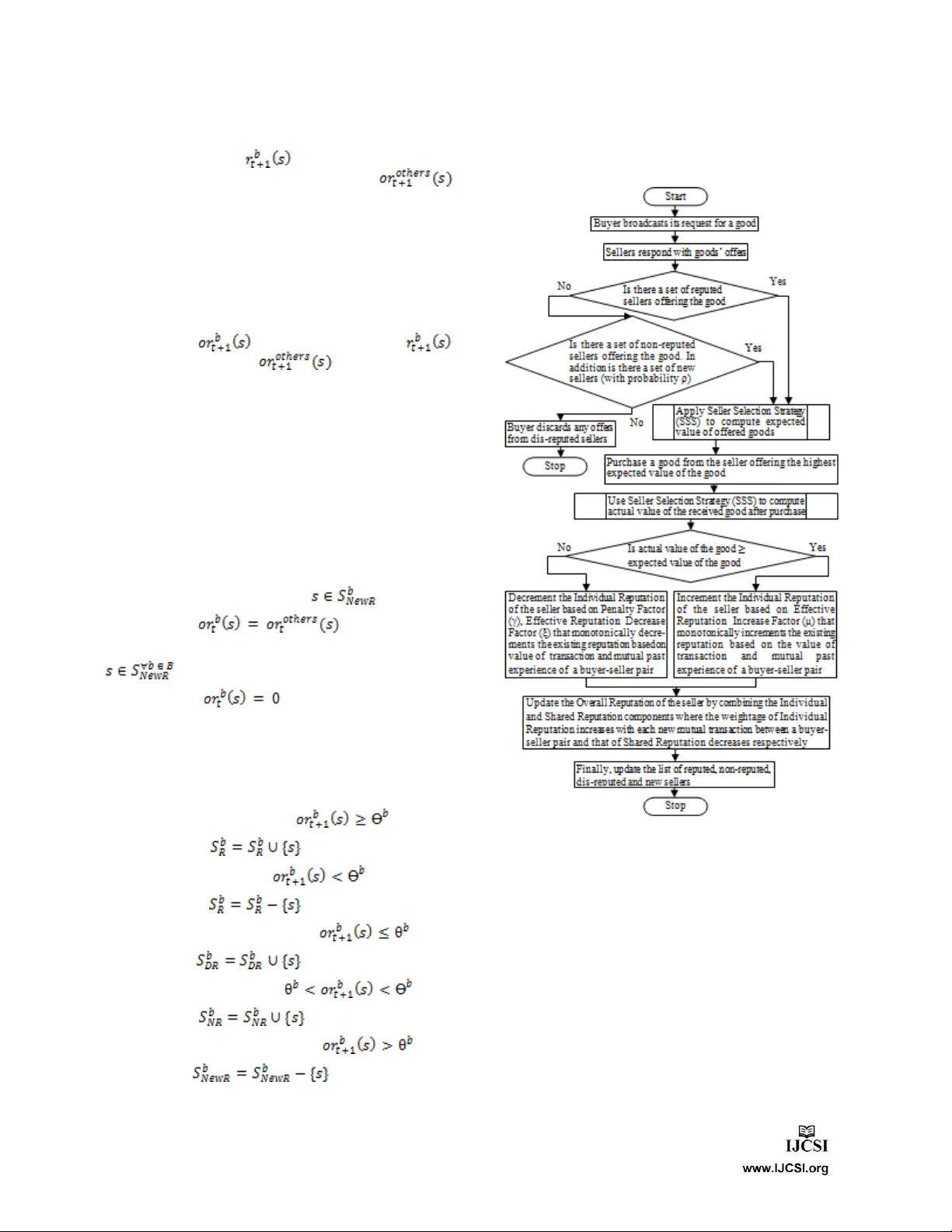
핵심 제안은 3단계 프로세스로 구성된 동적 평판 프레임워크이다.
1. **Phase I – 판매자 선택**: 구매자는 자신이 필요로 하는 상품을 브로드캐스트하고, 응답한 판매자들의 제안을 퍼지 산술을 통해 평가한다. 각 제안은 가격, 품질, 배송 시간 등 속성을 퍼지 트라페조이드 수로 변환하고, 역연산·덧셈·곱셈을 적용해 ‘예상 가치’를 산출한다. 이 값이 가장 높은 판매자를 선택한다.
2. **Phase II – 평판 업데이트**: 거래가 완료되면 구매자는 실제 거래 결과(성공/실패, 만족도)와 거래 금액을 기반으로 보상 함수를 계산한다. 보상은 강화학습의 Q‑value 업데이트 식에 적용되며, 거래 가치가 클수록 보상·벌점이 비례적으로 커진다. 동시에 구매자는 다른 구매자들의 의견(공유 평판)을 수집하고, 이를 퍼지 가중합으로 통합한다. 최종 평판은 IR과 SR의 가중 평균으로 산출되며, 가중치는 구매자와 판매자 간 누적 거래 횟수에 따라 동적으로 변한다.
3. **Phase III – 판매자 리스트 관리**: 업데이트된 평판을 바탕으로 판매자는 ‘평판 리스트(신뢰, 비신뢰, 불신, 신규)’ 중 하나에 배치된다. 평판이 불신 임계값 이하로 떨어지면 해당 판매자는 시장에서 제외된다. 반대로 평판이 상승하면 신뢰 리스트로 승격된다.
수식적으로는 IR∈
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기