겹침과 불균형이 SVM 성능에 미치는 복합 효과 분석
본 논문은 데이터의 클래스 불균형과 클래스 간 겹침이 SVM 분류기의 성능에 독립적으로 작용하지 않음을 실험적으로 입증한다. 두 요인의 결합이 “숨은 과적합(covert overfitting)” 현상을 야기하며, 이는 일반적인 교차검증이나 정규화 기법으로는 탐지하기 어렵다. 저자들은 2차원 체커보드형 합성 데이터를 이용해 겹침 정도(µ)와 불균형 정도(α)를 조절하면서 F1‑score와 서포트 벡터 비율을 측정하고, 독립성 가설을 수학적으로 검…
저자: Misha Denil, Thomas Trappenberg
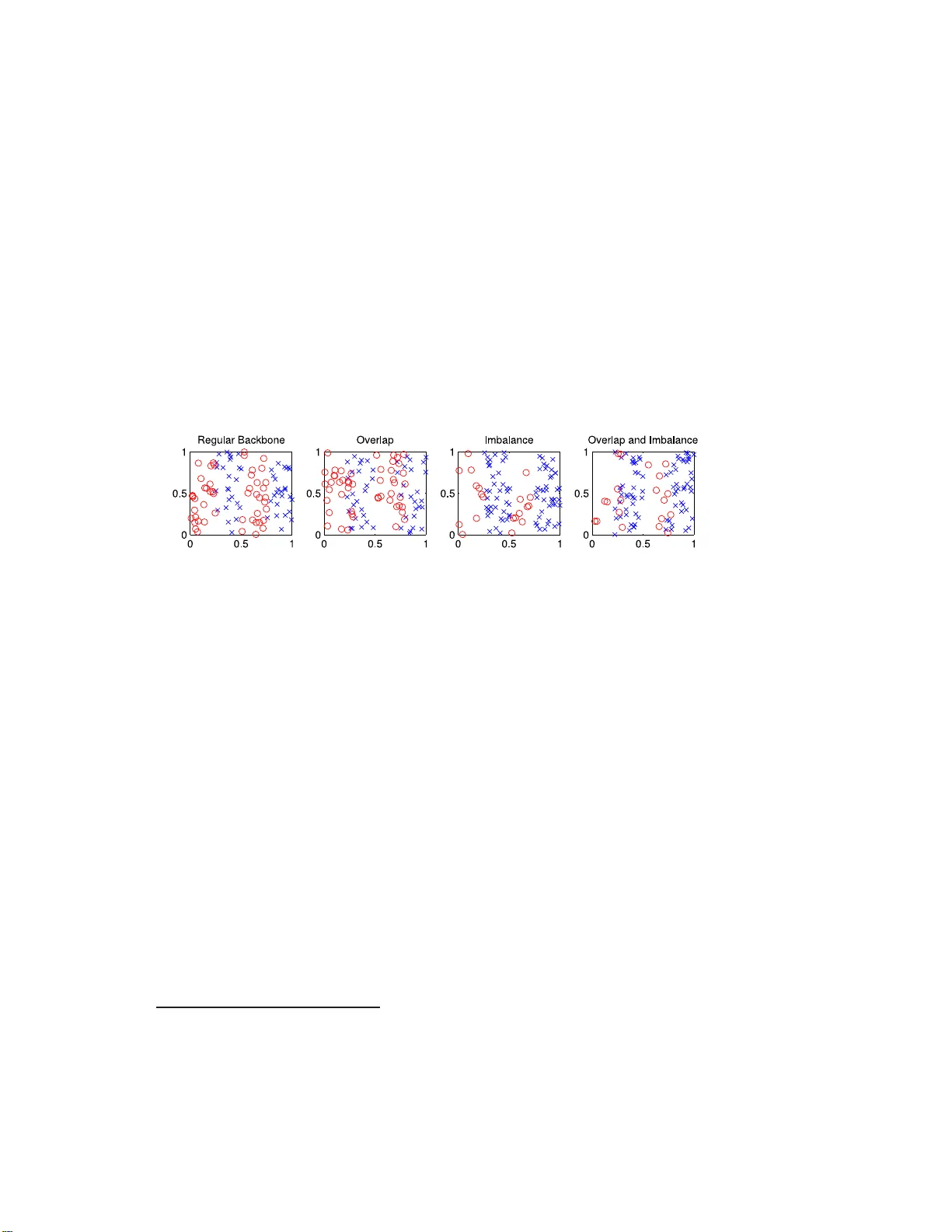
본 논문은 머신러닝에서 빈번히 발생하는 두 가지 데이터 문제, 즉 클래스 불균형(class imbalance)과 클래스 간 겹침(class overlap)이 서포트 벡터 머신(SVM) 분류기의 성능에 미치는 영향을 동시에 조사한다. 기존 연구는 이 두 문제를 별도로 다루어 왔으며, 그 상호작용에 대한 체계적인 분석은 부족했다. 저자들은 이러한 겹침과 불균형이 독립적으로 작용하지 않으며, 결합될 경우 새로운 형태의 “숨은 과적합(covert overfitting)” 현상이 발생한다는 가설을 제시하고 이를 실험적으로 검증한다.
1. **문제 정의 및 관련 연구**
- 불균형은 한 클래스가 전체 데이터의 대부분을 차지하는 상황을 말하며, 특히 소수 클래스가 중요한 경우(예: 의료 진단) 큰 문제를 야기한다.
- 겹침은 두 클래스의 생성 분포가 일부 영역에서 거의 동일한 확률을 보이는 현상으로, 이 영역에서는 어떤 결정 경계도 본질적으로 높은 오류율을 갖는다.
- 기존 연구(Bosch et al., 6; Japkowicz & Stephen, 10 등)는 각각의 문제를 독립적으로 분석했지만, 두 요인이 동시에 존재할 때의 효과는 거의 다루지 않았다.
2. **데이터 생성 및 실험 설계**
- 2차원 체커보드(Checkerboard) 모델을 사용해 합성 데이터를 만든다. 한 축을 네 구역으로 나누어 교차로 클래스를 배치하고, 다른 축에서는 두 클래스가 구별되지 않게 함으로써 비선형 경계가 필요하도록 설계하였다.
- 겹침 정도는 µ∈
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기