GPU 기반 무손실 데이터 압축 가속화
본 논문은 허프만 코딩을 블록 단위로 독립적으로 압축·해압축할 수 있도록 변형하고, 이를 NVIDIA CUDA GPU와 멀티코어 CPU(OpenMP)에서 구현하여 성능을 비교한다. 블록 길이 메타데이터를 추가해 압축 스트림을 바이트 경계에 맞추고, GPU의 SIMD 구조에 맞는 데이터 병렬성을 확보한다. 실험 결과 디코딩에서는 GPU가 CPU보다 현저히 높은 처리량을 보였으며, 인코딩에서도 일정 수준의 가속을 달성했지만 메모리 전송 오버헤드가 …
저자: ** - R.L. Cloud (University of Alabama at Birmingham) - M.L. Curry (University of Alabama at Birmingham) - H.L. Ward (S, ia National Laboratories) - A. Skjellum (University of Alabama at Birmingham) - P. Bangalore (University of Alabama at Birmingham) **
본 논문은 현대 슈퍼컴퓨팅 환경에서 데이터 압축의 필요성이 증가함에 따라, 전통적인 허프만 코딩을 GPU 가속에 적합하도록 변형하고 그 성능을 정량적으로 평가한다. 서론에서는 손실 없는 압축이 대역폭·스토리지 제한을 완화하는 핵심 기술임을 강조하고, GPU의 일반 목적 연산(GPGPU) 활용이 최근 급부상했음을 언급한다. 특히, GPU는 SIMD 구조와 대규모 코어 풀을 갖추고 있어 데이터 병렬 처리가 가능한 작업에 높은 효율을 보이지만, 복잡한 제어 흐름이 많은 알고리즘에는 부적합할 수 있다.
허프만 코딩은 심볼 빈도 분석 후 가변 길이 비트 코드를 할당하는 방식으로, 전체 데이터에 대한 트리를 한 번만 구축한다는 점에서 순차적인 특성을 가진다. 이를 병렬화하기 위해 저자들은 데이터를 고정 크기 블록으로 분할하고, 각 블록마다 독립적인 허프만 트리를 생성하도록 알고리즘을 수정하였다. 블록 경계에서 압축된 비트 스트림의 길이를 4바이트 정수 형태로 저장함으로써, 디코더가 정확한 시작·끝 위치를 파악하도록 설계하였다. 비트 길이가 바이트 경계를 초과하면 4바이트 정렬을 맞추기 위해 패딩을 삽입한다. 이때 발생하는 오버헤드는 블록당 32~63비트이며, 블록 크기가 커질수록 전체 압축 효율에 미치는 영향은 미미해진다.
GPU 구현은 NVIDIA GeForce GTX 285(240 CUDA 코어, 1.5 GHz)를 대상으로 CUDA C++로 작성되었다. 각 CUDA 스레드 블록은 하나의 데이터 블록을 담당하고, 블록 메타데이터(길이) 배열을 이용해 전역 메모리에서 압축된 비트를 읽어들인다. 인코딩 단계에서는 심볼 빈도 계산, 트리 구축, 비트 스트림 생성 순으로 진행되며, 특히 비트 조작과 조건 분기가 빈번해 워프 다이버전스가 발생한다. 디코딩 단계는 비트 스트림을 트리 탐색으로 변환하는 작업으로, 인코딩보다 분기 빈도가 낮아 워프 다이버전스 영향을 덜 받는다.
CPU 측면에서는 Intel Core i7‑Extreme Edition 965(4코어, 3.2 GHz)를 사용하고, OpenMP를 통해 블록 단위 병렬화를 적용하였다. 각 코어는 독립적인 블록을 처리하며, 하이퍼스레딩을 활용해 최대 8 스레드까지 확장하였다.
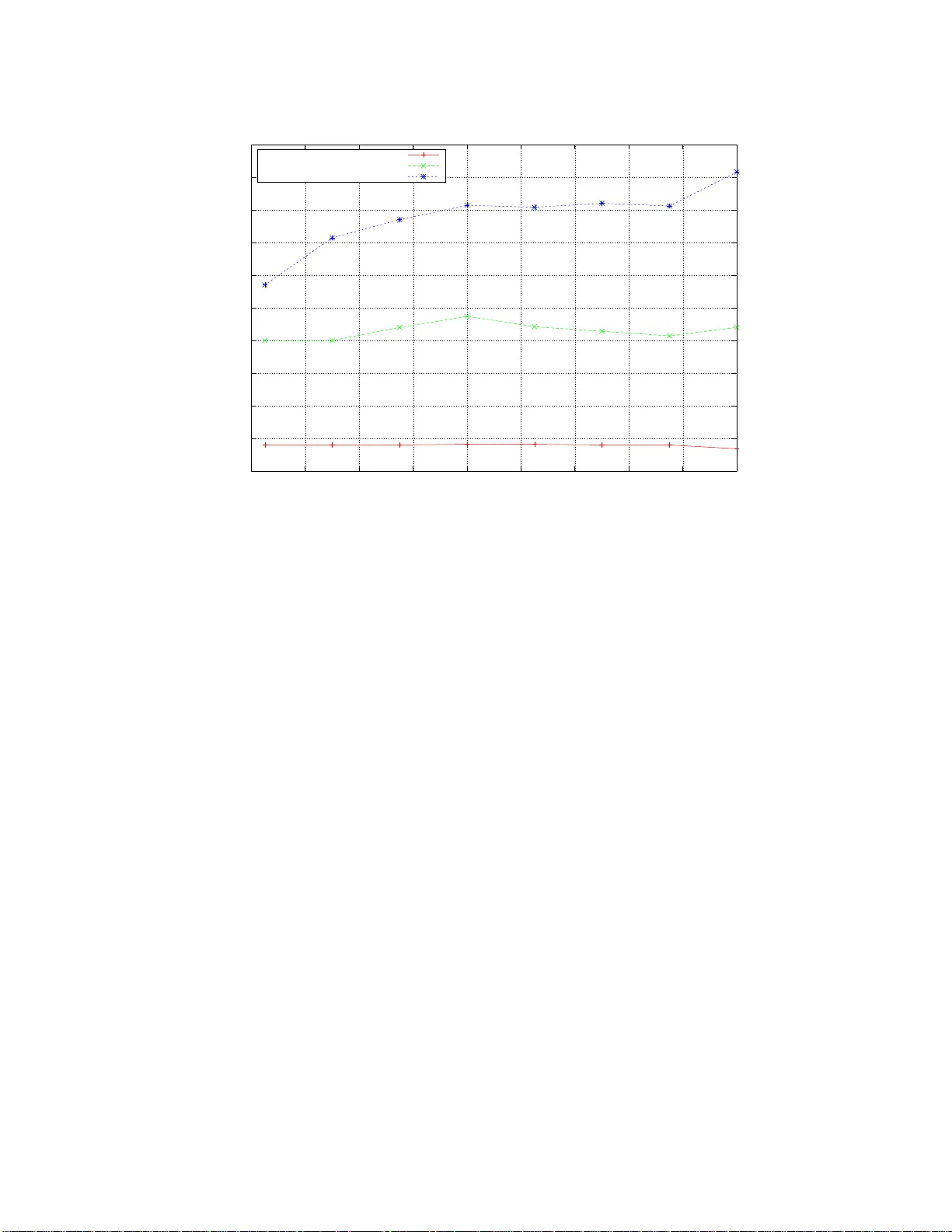
성능 평가에서는 다양한 파일 크기(100 MB~1 GB)와 블록 크기(64 KB~1 MB)를 대상으로 인코딩·디코딩 처리량을 측정하였다. 인코딩에서는 GPU가 CPU(OpenMP)보다 1.2배~1.5배 정도 높은 처리량을 보였지만, 메모리 전송(PCI‑e) 비용이 전체 실행 시간의 30% 이상을 차지해 제한 요인으로 작용했다. 디코딩에서는 GPU가 600 ~ 800 MB/s의 처리량을 기록, CPU의 350 ~ 450 MB/s 대비 1.5~2배 가량 빠른 성능을 달성했다. 그래프(그림 6, 7)에서 볼 수 있듯이 블록 크기가 커질수록 오버헤드 비율은 감소하고, GPU와 CPU 간 성능 격차가 확대된다.
결론에서는 GPU의 SIMD 특성상 분기와 메모리 접근 패턴이 중요한데, 현재 구현은 인코딩 단계에서 워프 다이버전스가 성능을 제한한다는 점을 인정한다. 또한 허프만 코딩 자체가 최신 압축 알고리즘에 비해 압축 효율이 낮아, 실제 서비스에 바로 적용하기엔 한계가 있다. 그러나 블록화와 메타데이터 삽입을 통해 데이터 병렬성을 확보함으로써, 특히 디코딩과 같이 읽기 중심 작업에서는 GPU 가속이 실질적인 이점을 제공한다는 점을 강조한다. 향후 연구 방향으로는 블록 내 트리 구축을 더욱 효율화하거나, LZ‑계열·BWT 기반 압축 알고리즘을 GPU 친화적으로 재설계하는 방안을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기