Accelerating Lossless Data Compression with GPUs
Huffman compression is a statistical, lossless, data compression algorithm that compresses data by assigning variable length codes to symbols, with the more frequently appearing symbols given shorter codes than the less. This work is a modification o…
Authors: ** - R.L. Cloud (University of Alabama at Birmingham) - M.L. Curry (University of Alabama at Birmingham) - H.L. Ward (S, ia National Laboratories) - A. Skjellum (University of Alabama at Birmingham) - P. Bangalore (University of Alabama at Birmingham) **
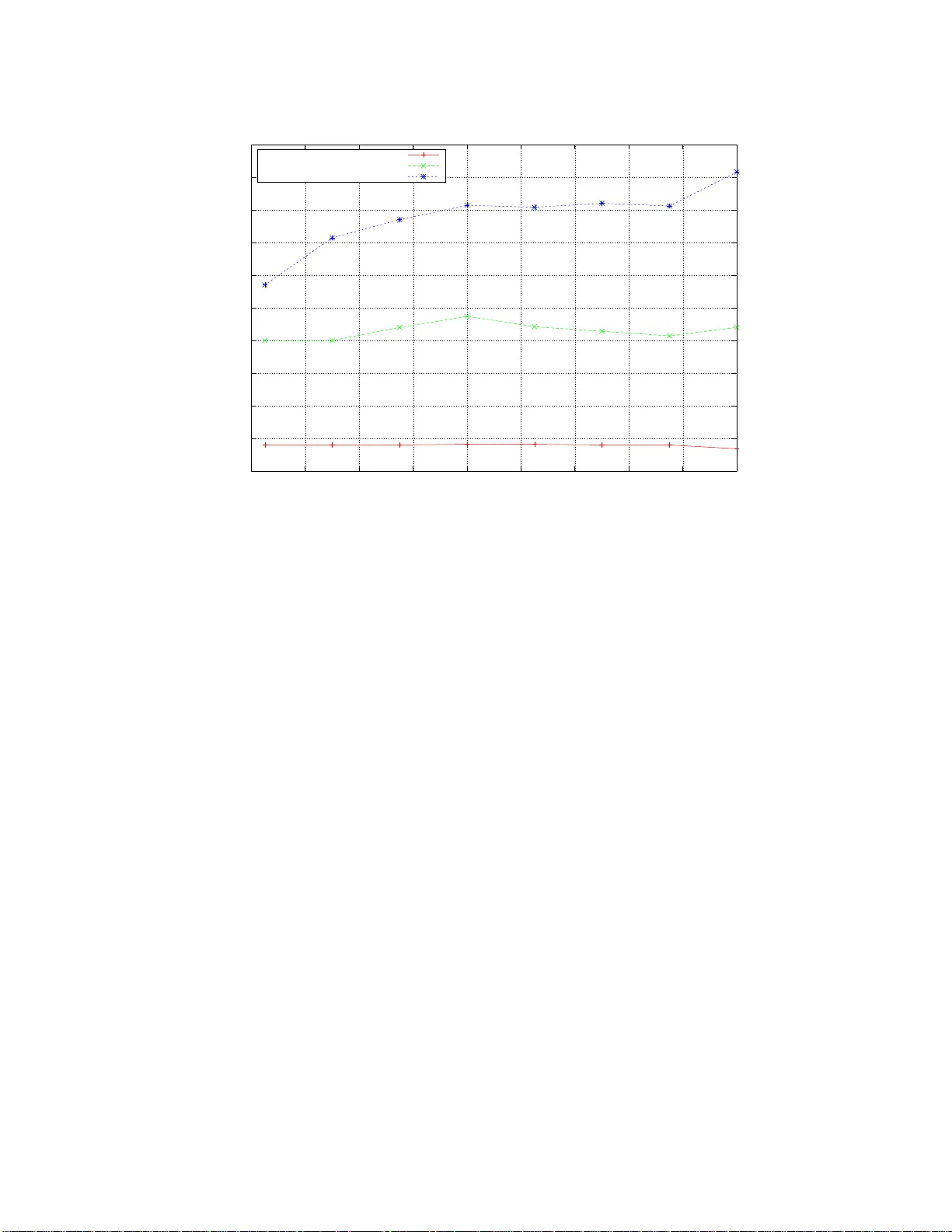
Accelerating Lossless Data Compression with GPUs R.L. Cloud ∗ M.L. Curry † H.L. W ard ‡ A. Skjellum § P . Bangal ore ¶ Octob er 22, 2018 Abstract Huffman compression is a statistical, lossless, d ata compression algorithm that com- presses data by a ssigning v aria ble length co des to symbols, with the more frequently app earing symbols giv en s h orter cod es than the less. This work is a mo difi cation of the Huffman algorithm whic h p er m its un compressed d ata to b e decomp osed int o indep en- den tly compressible and d ecompressible blocks, allo wing for concurren t compr ession and d ecompression on multiple pro cessors. W e create im p lemen tatio ns of this m o di- fied algorithm on a cur r en t NVIDIA GPU using the CUDA API as well as on a current In tel c hip and the p erformance results are compared, showing fa v orable GPU p erfor- mance for nearly all tests. Lastly , w e discuss the necessit y for high p erformance data compression in to d a y’s sup ercomputing ecosystem. 1 In tro ductio n Lossless data compression is imp ortant in application domains a nd usage en vironments where bandwidth or storage limitations may negatively impact application or system perfo r mance. Generally classifiable into statistical or dictiona r y metho ds, lossless data compression algo- rithms can range widely in compression sp eed and efficiency (compression fa ctor). Certain algorithms, especially the more efficien t, can be quite compu t a tionally expensiv e, and as the data pro cessing needs of curren t scien tific endea v o r con tinue to scale with more rapidit y than stora ge or bandwidth, compression b ecomes increasingly necessary , but questions re- main as to ho w to accelerate it and how to do so without consuming the resources dev oted to computation. The use of graphics pro cessing units (G PUs) for general purpose computation, i.e. p r ob- lems outside the graphical domain, is a relativ ely recen t dev elopmen t. First this w as a chiev ed though third part y to olkits, e.g. Stanford’s Bro okG PU, but ev en more recen tly hav e G PU man ufacturers themselv es begun to offer general purp ose to ols whic h give the programmer ∗ The Universit y of Alabama at Birmingha m, rcloud@ cis.uab.edu † The Universit y of Alabama at Bir mingham, curr yml@cis.uab.edu ‡ Sandia National Lab or atories, lee@ sandia.gov § The Univer sity of Alabama at Birmingha m, tony@cis.uab.edu ¶ The Universit y of Alabama at Birmingha m, puri@cis.ua b.edu 1 a lo wer lev el communion with the c hip than earlier GPGPU programming in terfaces whic h are built up on Op enGL and DirectX. O ne o f these, and curren tly the most prominen t, is the Compute Unified Device Arc hitecture(CUD A) from the NVIDIA corp oration. The pot ential b enefits of GPUs in g eneral purp ose computation are g reat, but p oten tial must b e embold- ened, more so ev en than for parallel programming on the x86. T o ac hiev e an ywhere near the theoretical maxim ums in p erformance on the GPU, the computation patterns underlying a solution’s alg orithm m ust b e v ery near to the traditional usage of the GPU. A prosp ectiv e algorithm’s implemen tation on the G PU should b e, in order of imp ortance to p erformance, highly data parallelizable, logically simple, and hav e relativ ely man y computations to mem- ory accesses . In essenc e, to use the GPU t o maxim um effect, the abstractable computation patterns underlying a solution should b e co-linear to the GPUs original task, graphics ren- dering. O ur problem domain, I/O, while it do es not p erfectly fit these criteria, has already b enefited from G PUs to enhance storage redundanc y [5]; w e at tempt no w their utilizat io n in lo ssless data compression. One ma jo r difficult y here in a c hieving g o o d sp eedup with slim negat ive side effects is that lossless data compression algorithms can generally not b e, in their unaltered form, tho ug h t of as highly parallelizable. Indeed, if one wishe s to express these algorithms in parallel, one of ten needs to consider tr a deoffs b etw een compression effic iency and p erformance. Nev ertheless, w e hop e t o effectiv ely demonstrate that it is p ossible to come to a reasonable middle ground with resp ect to co ding acceleration and efficiency loss. 2 Huffman C ompressio n Statistical metho ds of data compression p erform analysis on the nature of the data to mak e in telligen t decisions ab out ho w it can b e represen ted mo r e efficien tly in compressed fo rm. The Huffman enco ding algorithm fa lls within this genus and op erates b y counting the app earance of ev ery distinct sym b ol in the uncompressed data, then represen ting the more frequen t with shorter co des than the less. Ev ery sym b ol in the data is replaced with its co de, and if the dat a is non-ra ndom, i.e. a few sym b ols app ear with g reater frequency than others, compression can b e ac hiev ed. The Huffman compression alg orithm is old by the standards of our science [6 ], but is still used, and has the attractiv e quality of b eing a primitiv e of sev eral more mo dern and common algor it hms, e.g. Deflate [1] and potentially the algorithm described by Burrows and Wheeler [4]. 2.1 P arallel Huffman Compression There is literat ure o n parallel Huffman co ding and of v ariet y , ranging from the actual con- struction of Huffman co des in pa r a llel [3], [2] to [7] whic h a ddresses details of decomp o sition for para llel Huffman deco ding and demonstrates some mo derate deco ding sp eedups while main taining optimally enco ded data by making use of the observ ation t hat Huffman co des can frequen tly sync hronize. Because of limitations in our arc hitecture, w e m ust try to create the simplest enco ding routine p ossible. In doing t his we mak e a minor mo dification to the output of the Huffman alg o rithm. An alt era t io n is necessary b ecause of the nature of Huffman co des, i.e. they are of a 2 Figure 1: The original string and its ASCI I represen tation. As ASCI I enco des eac h c haracter with a single b yte, the nine c haracter string is 72 bits. Figure 2: The binary tree created by the Huffman alg o rithm and the enco ded represen tatio n of the original string. The enco ded represen tat io n of a c hara cter is found by trav ersing the tree, assigning a binary 0 or 1 for a left or right trav ersal resp ectiv ely . v ariable length; an enco ded data string is comp osed of these co des pac ked together in a nature where bit co des can cross b yte b oundar ies. Simple decomposition of the enco ded data stream in to blo ck s of static size w ould res ult in the practical certain t y that deco ding w ould t a k e an erroneous path, whic h is discussed in some detail in [7]. One counte r to this is to pac k the blo c ks to b yte b oundaries, in tro ducing some size ov erhead. One more c hange is necessary . Because the co des are o f v ariable lengths, ev en if w e encode a constan t n umber of sym b ols in eac h blo c k, the resulting length of the enco ded blo ck will v ary , sometimes dramatically . F or this reason, we m ust encode a n indication of where the blo ck starts and ends. Our approac h is ag ain simple; a t the start of the enco ded blo ck we give the length of the blo c k whic h is know n b y making an additional pass ov er the unenco ded blo c k and summing the lengths of the co de represen tation of the sym b ols. Our implemen tation stores this length as an unenco ded fo ur b yte inte g er for simplicit y , and b ecause of this and the requiremen ts of our architec t ure, w e pac k the blo c ks to four by te b oundaries. The ov erhead of our mo dificatio ns range therefore, from b etw een 32 bits and 63 bits p er blo c k, with the v ariation b eing b ecause if the size of the enco ded blo c k is ev enly divisible b y four b ytes, it is unnecessary to add pack ing bit s to its t ail. This ov erhead naturally b ecomes less significan t as the length of the blo ck is increased, whic h is indicated in the figure measuring blo ck size against ov erhead. T he time required fo r summing the blo c k lengths is measurable but undramat ic and most noticeable when comparing the run times of a sequen tial blo c k enco der to a sequen tial traditiona l( non-blo ck ) enco der. 3 Figure 3 : Decompo sing the string in to thr ee sym b ol blo c ks and then pac king the enco ded bits to the next by te b oundary . Figure 4: The a ddition of a (underlined)length delimiter at the start of the blo ck . Single b ytes are used for the o ve rhead in the diagrams fo r simplicit y . In our implemen tation, w e pac k the blo c k to four b ytes and use a four byte in t eger to represen t the blo ck length 4 0 2 4 6 8 10 12 14 16 18 20 22 0 100 200 300 400 500 600 700 800 900 1000 Percent Overhead Block Size in Bytes Encoding Efficiency of Sequential vs. Parallel Algorithms Percent Overhead of Parallel Algorithm Figure 5: The size o v erhead of using the para llel Huffman algorithm graphed against the blo c k size. The n um b er of b ytes o ve rhead p er blo c k remains a constant, so as the blo c k size increases the ov erhead b ecomes less significan t. At large blo c k sizes, the ov erhead p er blo ck can b e less than one p ercen t. T o par a llelize deco ding, it is suffic ient to build a ta ble of offsets into the enc o ded data from these block length delimite r s. The computation t hr eads on the GPU can then index in to the enco ded data and deco de in parallel, storing deco ded data in a seque ntial arr a y indexable by thread and blo c k n umbers. 3 P erformance Co mparis ons 3.1 Enco ding Acceleration o v er our seque ntial implemen tation w as achie ved for b oth enco ding and deco d- ing. This comparison is most meaningful in terms of throughputs, the amount of data whic h can be enco ded or decoded p er second. F o llo wing is the comparison of our seque ntial en- co der to our parallel GPU enco der and a parallel CPU encoder prog rammed with OpenMP . The GPU used in these exp erimen ts is the NVIDIA GeF orce GTX 285 with 240 cores at 1.5 GHz, and the CPU used is the In t el Core i7 Extreme Edition 96 5 with f our cores at 3.2 GHz. Despite the GPU having 60 times the n um b er of cores as our CPU, the difference s in thro ughput b et w een the GPU enco der and the Op enMP encoder are not dramatic. This parado x can b e largely resolv ed b y recalling t hat the arc hitecture o f the GPU was dev elop ed for the SIMD, single instruction m ultiple data, pro g ramming mo del while our CPU w as dev elop ed with MIMD, multiple instruction mu lt iple data, in mind. The pro cessors in the GPU are o r g anized into 30 groups o f 8 cores. Eac h group of 5 100 150 200 250 300 350 400 450 500 550 600 100 200 300 400 500 600 700 800 900 1000 Throughput in MB/sec. Unencoded File Size in MB Encoding Throughput CPU vs. GPU with Block Size 100 CPU Throughput OpenMP CPU Throughput GPU Throughput Figure 6: W e sa w sup erior p erformance with the GPU based enco der compared to our m ulti-core CPU enco der and our single threaded CPU implemen tation cores is kno wn as a multiprocessor and con tains a single con trol unit and a small amoun t of high sp eed memory shared b etw een the cores in the m ult ipro cessor. The con trol unit broadcasts an instruction to all the cores, a nd optimal p erfor mance can only b e achie ved when ev ery core can execute it. If, for example, the instruction is a bra nc hing statemen t, then there is a lik eliho o d that some cores will not follo w the jump, a nd in this case, some cores mus t remain inactiv e until they either themselv es satisfy the bra nc hing instruction or con t r ol passes beyond the branching sections of the co de. Therefore, in the w orst case, when only one core can satisfy the jump and the other sev en are left idle, o ur GPU b eha ve s more lik e a crippled 30 core shared memory MIMD mac hine with a slow clo ck speed and no automatic memory cac hing. Our enco der consists of complicated branc hing statemen ts for the bit manipulation whic h make s worst case b eha vior relat ively lik ely . This also illustrates that in heterogeneous programming en vironmen ts, one m ust b e v ery aw are of the strengths and w eaknesses of the v arious a rc hitectures so that programming effort can b e directed where b enefits are most lik ely to b e found. 3.2 Deco ding Our deco ding routine consists of reading bits and t r av ersing a binary tree rep eatedly fo r each co de string. This con tains branc hing instructions, but mark edly few er than the enco ding routine, and the facto r of a cceleration on the GPU is greater than that o f the enco ding routine. Also intere stingly , the measured increases in throughput from using O p enMP on t he CPU, compared to the seque ntial implemen tation, are ev en b etter than linear b y num ber of cores on the CPU. By launch ing increasing num b ers of threads, we can hide latency b y issuing 6 0 50 100 150 200 250 300 350 100 200 300 400 500 600 700 800 900 1000 Throughput in MB/sec. Encoded File Size in MB Decoding Throughput CPU vs. GPU with Block Size 100 CPU Throughput OpenMP CPU Throughput GPU Throughput Figure 7: Aga in, our G PU based deco der ga v e b etter p erformance than b oth CPU deco ders. more memory requests. In this w ay , w e sa w con tin ued p erf o rmance improv emen ts t hr o ugh increasing thread coun ts up to 8. Intel’s Hyper-Threading tec hnology assists significan tly in this. 4 Conclus ions The data presen ted here suggests that the strengths of the G PU arch itecture are ro bust enough to giv e p erformance b enefits to applications whic h, while data parallel, still hav e a not insignifican t leve l of logical complexit y . Optimal use of the GPU’s SIMD cores requires the complete elimination of div ergence within w ar ps, whic h, in practicalit y , requires the complete absence of if statemen ts from the G PU sub-routine; how ev er, sub-optimal p erformance, through the em ulation of MIMD, can still b e acceptable. Despite the large num ber of div ergen t threads in a w a r p; our enco der k ernel is capable of throughputs, sans memory transfer times to and from the GPU, in exces s of 4 GB/sec. T otal enco ding thro ughputs using the GPU are w eighed down by the need to transfer data to and from the card; how ev er, in an online system, or when enco ding v ery large amoun ts of data, this could b e somewhat ameliorated by using async hronous da t a transfers with the GPU to f ully exploit bus resources while enco ding. Realistically , curren t p erformance lev els f or our GPU enco der and deco der do not w arrant the use of the program as a standalone encoding system. The Huffman algorithm itself is not the best c hoice fo r suc h purp oses and even the strengths of the GPU do not mak e up for the algorithm’s deficie ncies. Ho wev er, our encoding system could b e used as an auxiliary pro cess to a GPU application. Muc h greater co ding p erformance than that sho wn in the 7 ab ov e figures could b e seen w ere the data to b e enco ded already on the GPU. References [1] M. Adler. Deflate algorithm. http://www.gzip.org /algorithm.txt . [2] M. J. Atallah, S. R. Ko sara ju, L. L. Larmo r e, G . L. Miller, and S.-H. T eng. Constructing trees in parallel. In SP AA ’89: Pr o c e e dings of the first annual A C M symp osium on Par al lel algorithms and ar chite ctu r es , pages 421–431, New Y ork, NY, USA, 1989. ACM . [3] P . Berman, M. Karpinski, and Y. Nekric h. Approximating huffman co des in parallel. Journal of D iscr ete A lgori thm s , 5(3):479– 490, 2007. [4] M. Burrows and D. J. Wheeler. A blo ck-sorting lo ssless data compression algorithm. T ec hnical rep ort, Digital SR C Researc h Rep ort, 1994. [5] M. Curry , A. Skjellum, H. W ard, and R. Bright w ell. Accelerating reed-solomon co ding in raid systems with g pus. IEEE I nternational Symp osium on Par al lel and Di s tribute d Pr o c e s sing , pages 1 –6, 200 8. [6] D . Huffman. A metho d for the construction of minim um-redundancy co des. Pr o c e e dings of the I RE , 40:10 98–1101, 1952. [7] S. T. Klein and Y. Wiseman. Parallel h uffman deco ding with a pplications to jp eg files. The Computer Journal , 46:487 –497, 2003 . 8
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment