이중 샘플링으로 흐름 크기 분포 추정 효율 극대화
본 논문은 흐름 크기 분포를 정확히 추정하기 위해 기존의 흐름 샘플링(FS)의 통계적 장점을 유지하면서도 패킷 기반 연산 비용만으로 구현 가능한 이중 샘플링(DS) 기법을 제안한다. Fisher 정보량을 정량적 기준으로 삼아 FS, DS, Sample‑and‑Hold 등 여러 방법을 공정하게 비교하고, TCP SYN/FIN 및 시퀀스 번호 활용이 추정 정확도에 미치는 영향을 분석한다. 실험 결과 DS가 다른 패킷 기반 방법보다 현저히 우수함을 …
저자: Paul Tune, Darryl Veitch
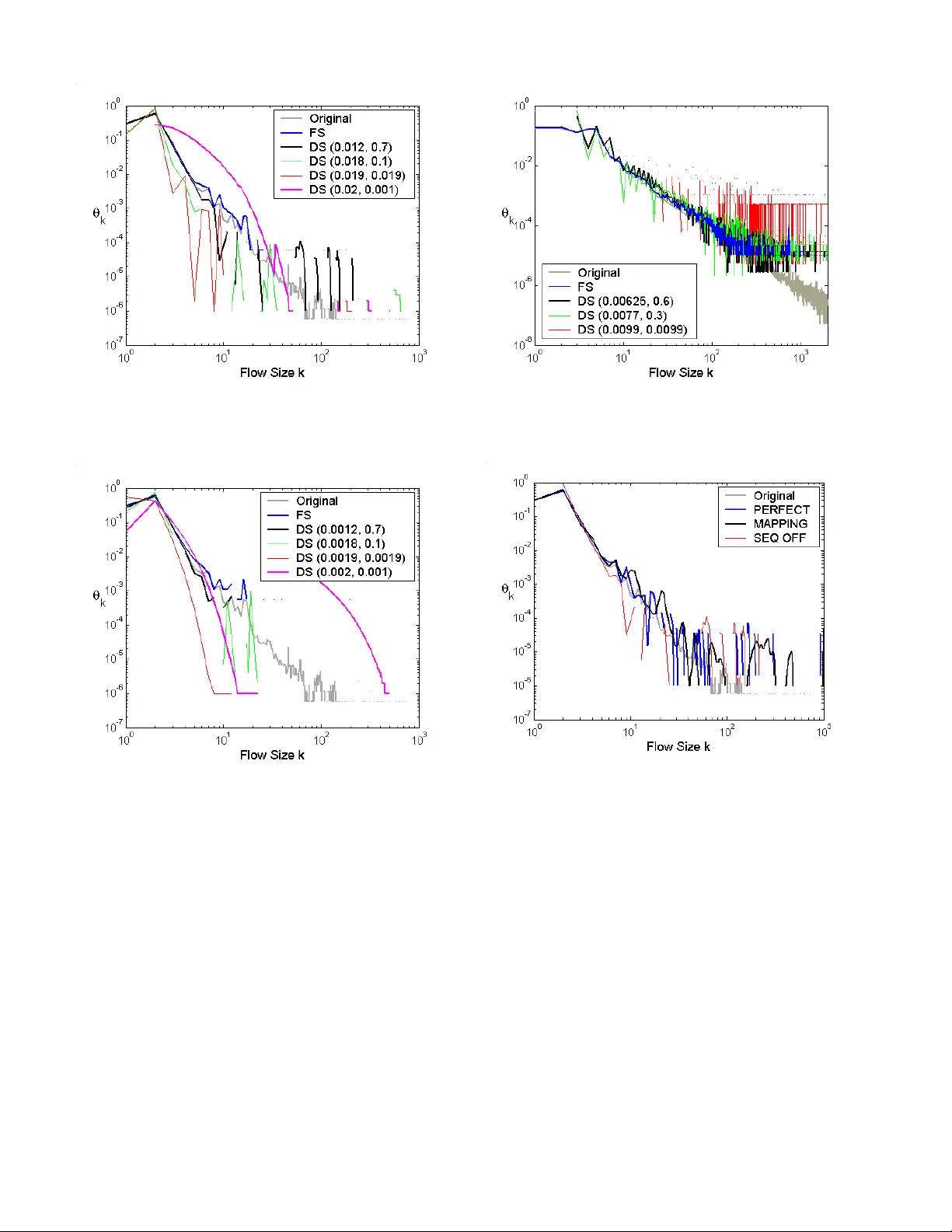
본 논문은 인터넷 트래픽 분석에서 핵심적인 지표인 흐름 크기 분포(Flow Size Distribution)를 정확히 추정하기 위한 새로운 샘플링 기법을 제시하고, 이를 기존 방법들과 Fisher 정보량이라는 통계적 기준으로 비교·평가한다.
1. **배경 및 문제 정의**
- 흐름 크기 분포는 트래픽 모델링·보안·QoS 등에 필수적이지만, 실제 라우터에서는 패킷 단위 샘플링만이 실현 가능하다. 기존의 ‘1 in N’ 패킷 샘플링은 큰 흐름은 복원하지만 작은 흐름을 크게 왜곡한다.
- 흐름 샘플링(FS)은 흐름 자체를 선택하면 해당 흐름의 모든 패킷을 수집하므로 통계적으로 최적이지만, 매 패킷마다 흐름 테이블을 조회해야 하는 높은 연산·메모리 비용 때문에 라우터에 적용하기 어렵다.
2. **샘플링 프레임워크와 비조건부 모델**
- 저자들은 흐름 시작을 나타내는 SYN 패킷을 카운트함으로써 전체 흐름 수 N_f를 직접 측정할 수 있다고 가정한다. 이를 통해 흐름이 전혀 샘플링되지 않은 경우(j=0)까지 포함하는 비조건부 확률 모델을 구축한다.
- 흐름 크기 k에 대해 j개의 패킷이 샘플링될 확률을 b_{jk}라 정의하고, 이를 (W+1)×W 샘플링 행렬 B에 배치한다. 실제 관측된 샘플링 분포 d는 d = Bθ 로 표현된다.
3. **Fisher 정보량 도출**
- 로그우도 함수는 f(j;θ)=d_j 로 단순하며, 이에 대한 파라미터 θ에 대한 기울기는 (1/d_j)
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기