Fisher Information in Flow Size Distribution
The flow size distribution is a useful metric for traffic modeling and management. Its estimation based on sampled data, however, is problematic. Previous work has shown that flow sampling (FS) offers enormous statistical benefits over packet samplin…
Authors: Paul Tune, Darryl Veitch
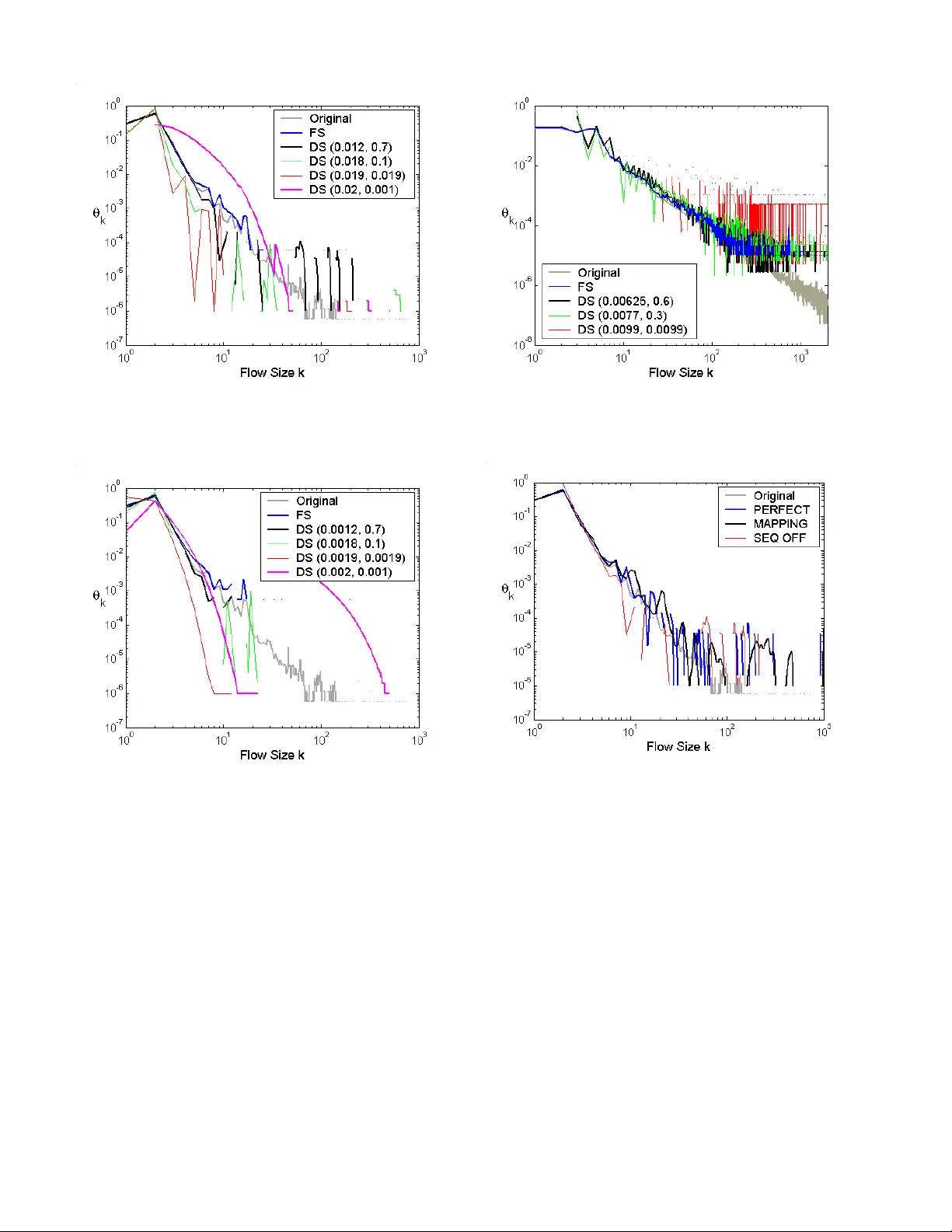
1 Fisher Information in Flo w Size Distrib ution Estimation Paul T un e, Member , IEEE, and Darryl V eitch, F e llow , IEEE Abstract —The flow size d istribution is a useful metric for traf- fic modeling and management. Its estimation based on sampled data, howev er , is problematic. Previous work has shown th at flow sampling (FS) offers enormous statistical benefits ov er packet sampling but high resour ce requirements pr ecludes its use in routers. W e present Dual Sampling (DS), a two-parameter family , which, to a large extent, p ro vide FS -like statistical performance by approaching FS continuously , with just packet-sa mpling- like computational cost. Our wo rk utilizes a Fisher information based approac h recently used to evaluate a number of sampling schemes, excludi ng FS, for TCP fl ows. W e re vise and extend the ap proach to mak e rigoro us and fair comparisons between FS, DS and others. W e show how DS signifi cantly outperf orms other packet based methods, including Sample and Hold, the closest packet samplin g-based competitor to FS . W e describe a packet sampli ng-based implementation of DS and analyze its key computational costs to show that router implementation is feasible. Ou r approach offers i nsights int o numerous issues, includin g the notion of ‘fl ow quality’ for un derstanding the relati ve perfo rmance of methods, and how and when employing sequence numbers is beneficial. Our work is theoretical with some simulation supp ort and case studies on Internet data. Index T erms —Fi sher information, flow size d istribution, Inter - net measurement, router measurement, sampling. I . I N T RO D U C T I O N The distribution of flow siz e , that is the nu mber of packets in a flo w , is a useful metric for traf fic modellin g an d manag ement, and is imp ortant for secur ity because of the ro le small flows play in attacks. As is now well known h owe ver , its estimation based o n sam pled d ata is prob lematic. Currently , sampling decisions in rou ters are made on a per- packet b asis, with only sampled p ackets bein g subsequently assembled into (sampled) flows. Duffield e t al. [1] wer e the first to po int out that simp le p ack et sampling strategies such as ‘ 1 in N ’ p eriodic or i.i.d. (indepen dent, identically dis- tributed) pac ket samp ling h av e severe limitatio ns, in particular a strong flow len gth bias which a llows the ta il of the flow size distribution to be recovered, but d ramatically obscures the details of small flows. Th ey explored the use o f TCP SYN packets to imp rove the resolution a t the small flow end of the spectru m. Hohn et al. [2], [3] explored these d ifficulties further and p ointed out that flo w sampling , wher e the samplin g decision is made directly on flows, resulting in all pac kets belongin g to any sam pled flows being co llected, has enorm ous statistical advantages. Howe ver , flow sampling has not been pursued further nor fou nd its way into router s, pa rtly because it implies that look ups be per formed on every packet, which is very resource inten si ve. The authors are with the Department of E& E Engineerin g, T he Uni versi ty of Melbourne, Australia (Email: { lsptune@ee.,dv eitch@ } unimelb .edu.au). More recently , Ribeiro et al. [4] explor ed the use of TCP sequence numbers to im prove estimation for TCP flows. The idea is that th e presence of p ackets which are no t physically sampled can be inferred b y n oting th e incr easing by te coun t giv en by the sequence number fields of sampled packets. By using the Fisher in formation as a metric o f the effecti veness of sampling in retaining information about the original flo w sizes, they showed th at th is help s greatly to ‘fill in the holes’ left by packet sampling. Howe ver , they did no t ad dress wheth er th ese technique s out-perf orm flo w sampling (FS). In this paper we revisit FS in the context of TCP flows. Our first contribution is to explain h ow the appr oach of [4] can be reform ulated and extended to includ e FS. This provides a fram ew ork for our second contribution, proof s that FS ou tperform s existing m ethods b y a large margin, thou gh they themselves greatly improve u pon simple p acket sampling. Our results ar e rigo rous, based on explicit calculation and compariso n of th e Fisher Info rmation matrice s of competing schemes. W ith the statistical reputation of FS thu s reinforced, the ch allenge is to find m ethods which can som ehow approach or app roximate flow sampling in order to benefit f rom its informa tion theoretic efficiency , but with lower r esources requirem ents. W e show how this can be done. The comp utational p roblem for FS c an be descr ibed as follows. T o captu re the variety present in tra ffic flows and to provide th e ra w mater ial f or a variety of current (an d future) metrics, many flows must b e sampled. This implies large flo w tables which in turn implies the use of slower but cheaper DRAM rather th an the faster but expe nsiv e SRAM [5]. Howe ver , DRAM is n ot fast eno ugh to perf orm lookup s for ev ery packet, as required b y a straightfo rward imp lementation of FS, for to day’ s h igh c apacity links. The q uestion then becomes, how can flow sampling be implemen ted using per- packet decisions, in o ther words using som e form of packet sampling? The main contr ibution o f this pa per is the introduction of Dua l Sam pling (DS), a h ybrid approa ch combining the advantages of bo th packet an d flow samplin g. It is a two parameter sampling family which inclu des FS a s a spec ial case and allo ws FS to be ap proach ed continuo usly , enab ling a tradeoff of sampling efficiency against com putational cost. Computation ally , it can be implemented via a modified form of two-speed or ‘dua l’ packet sampling wh ich circumvents the p roblem of slow DRAM. Th ere is a cost in terms of wasted samples, but we show that this can be born e in high speed rou ters. Following [4], DS b enefits fr om the u se of TCP sequence numb ers although it can also be used witho ut them, and we provide insig ht into how an d when they have an 2 impact. W e sho w r igorou sly that DS outperfor ms the methods propo sed in [ 4]. W e also comp are and co ntrast DS with the well k nown ‘Sam ple and Hold’ sch eme [6]. W e show that Sample and Hold per forms quite well, though not as well as DS. Finally , we intr oduce S YN+SEQ+FIN , an other sampling method which enables flow sampling to be p erfectly achie ved (aside from errors in the mapping o f byte to packet co unts) at very low computation al co st, well below th at even of packet sampling. Its disadvantage is that it e xploits the TCP FIN field, when n ot all TCP flows term inate corre ctly with a FIN packet. W ith its explicit use of TCP p rotocol info rmation in most cases, ou r work a pplies to T CP flows o nly . Howe ver , the ideas and results could apply to o ther k inds of flows provided that suitable substitutes could be foun d for con nection startup (SYN), ‘progress’ (sequ ence n umbers) and ter mination (FIN) . TCP flows still co nstitute th e overwhe lming majority of traffic in the Intern et. The rest of the paper is organized as follows. Section II describes our samplin g framew ork and derives th e Fisher informa tion matrix and its inverse explicitly . Section I II de- fines the sampling methods and derives their m ain properties. Section IV com pares the methods the oretically and derives further p roperties explaining their p erforman ce, and Sec tion V explores in m ore detail h ow seque nce num bers reduce esti- mation variance. Section VI introduces a simp le mode l f or computatio nal cost an d u ses it to define and solve an o pti- mization p roblem for sam pling pe rforman ce under constra ints. Section VII applies the methods to real Interne t data and sho ws that DS performs f av orably with flow sampling in p ractice, and has better perform ance than Sample and Hold. A closed-form unbiased estimator was p roposed fo r DS and Sam ple and Ho ld which achieves th e Cram ´ er-Rao lo wer bound asymptotically , eliminating the need for iter ati ve optimization alg orithms. W e conclud e and discuss futu re work in Section VIII. This p aper is an extended and enhanced version o f the con- ference paper [7]. The ma in addition s relate to the inclusion of the Sample and Hold me thod th rough out the paper, several new theo rems and coun ter-examples on m ethod compar ison, and the inclusion of a new major d ata set. I I . T H E S A M P L I N G F R A M E W O R K In th is section we establish a framework to define and analyze samp ling techniques a pplied to an idealized view of TCP flows on a link. Nominally , we imagine that such flows are d efined b y th e usu al 5-tuple of o rigin an d destination IP addresses, por t numb ers, an d TCP p rotocol field together with a timeo ut. For the analy sis we make a number of simplifying assumptions: (i) flows b egins with a SYN packet and ha ve no others, (ii) flows ar e not split (this can occur throu gh timeo uts or flow table clearing), (iii) all n ecessary protocol information (5-tuple, SYN/FIN bits and sequen ce numb ers) can be ob served, and (iv) per-flo w seque nce num bers coun t packets, no t bytes. Assumptions (iii) and (iv) will b e discussed/r elaxed when we deal with r eal data in Section VI I. Note that we do respect TCP’ s pe r-flo w rand om initialization of sequen ce n umber s. Hence their absolute value holds no informatio n o n the numb er of packets in a flow , on ly differences of sequence n umbers matter . This is crucial fo r the analysis. A. The Flow Model W e consider a measuremen t inter val con taining N f flows. Let m i denote the size of flow i (the n umber of packets it contains). It satisfies 1 ≤ m i ≤ W , wh ere 1 ≤ W < ∞ is the maximum flow size. The total number of packets is n = P N f i =1 m i . Let M j be th e nu mber of flows of size j , 1 ≤ j ≤ W , that is M j = P i : m i = j 1 , and N f = P W j =1 M j . The flow size ‘d istribution’ is the set θ = { θ 1 , θ 2 , . . . , θ W } of r elativ e frequen cies, that is θ j = M j N f (1) where 0 ≤ θ j ≤ 1 and P W j =1 θ j = 1 . Note that { M j } a nd { θ , N f } are eq uiv alent a nd complete descr iptions of the flows in the measu rement interval. They are sets of deterministic parameters , not ra ndom v ariables, effectively a determin istic flow size model. Most of the literatur e on traffic sampling follows the above vie wpoint, where the data is de terministic, the only random ness being in troduced thr ough the sampling itself. An exception is th e work of Ho hn and V eitch ( [2], [3]) where random ness arises both thr ough th e traffi c model and the sampling process, which makes the analysis considera bly m ore difficult, but less generic. B. General Ran dom Sampling The ef fect on flow size of random sampling can be described as fo llows: from an origin al flow of size k , only j pac kets, 0 ≤ j ≤ k , are sa mpled (retained ), with probability b j k = Pr( sampled flow has j pkts | o riginal flow h as k pkts ) . The op eration of th e samp ling scheme is entirely d efined by the b j k , which ca n b e assembled into a ( W + 1) × W sampling matrix B , who se ( j + 1 , k ) -th element is b j k . Note that b j k = 0 for j > k . By definitio n B is a (column) stochastic matrix , that is each element obeys b j k ≥ 0 , and each colu mn sums to unity . The experimental outcom e can be described by a set of random variables { M ′ j | 0 ≤ j ≤ W } wh ere M ′ j counts the number of sampled flo w s o f size j . Thus, M ′ j = X i : m ′ i = j 1 = N f X i =1 1 ( m ′ i = j ) . Equiv alently , let θ ′ = { θ ′ j | 0 ≤ j ≤ W } ( note that the index j includ es 0) d enote the em pirical distribution of sampled flow sizes, wh ere θ ′ j = M ′ j N f , (2) where 0 ≤ θ ′ j ≤ 1 and P W j =0 θ ′ j = 1 . Note that θ ′ 0 ≥ 0 as some flows may n ot survi ve th e thinning process. Out of the 3 original N f flows, only N ′ f = N f (1 − θ ′ 0 ) = N f − M ′ 0 flows survive sampling. Define a normalized set of fractio ns o f th e sampled flow sizes γ = { γ j | 1 ≤ j ≤ W } by γ j = θ ′ j P W k =1 θ ′ k = θ ′ j 1 − θ ′ 0 , (3) where 0 ≤ γ j ≤ 1 and P W j =1 γ j = 1 . The set γ constitutes the n a¨ ıve or directly measurable samp led flow size d istribution and is equiv alen t to the distribution o f flo ws conditional on at least a single packet from th at flow being sampled. For j ≥ 1 , θ ′ j is r elated to γ j by (1 − θ ′ 0 ) γ j = ( N ′ f / N f ) γ j = θ ′ j . C. The Un condition al F ormulation The samp led flow above includes the case, j = 0 , where the flow ‘ev aporates’. It seems natural to con clude h owe ver that such cases cann ot b e observed. Th is lo gically leads to an analysis based o n th e observation of the γ j defined above where j ≥ 1 , which is effecti vely condition al : samp le flow distributions given that at least o ne packet is samp led. This is the app roach adopted in [1], [4], [8] an d in the liter ature generally . On e of the key differences in o ur work is that we show that it is possible to o bserve the j = 0 case, leading to an u nconditio nal formulation which enjoys many advantages. T o see how this is possible we return to general context of N f flows, each one of which will be sampled in this g eneral sense. As defined above N ′ f is th e nu mber of flo ws of size at least 1 after sampling. Th e n umber o f evaporated flows is just N f − N ′ f , but typ ically N f is no t known and is regar ded as a ‘nuisance parame ter’ which must b e estimated . Ho we ver , it can ea sily be measured by directly counting the total n umber of SYN packets, which is just the nu mber of flows N f . For methods wh ich ar e already assuming an ability to access and perfor m specific actions based on whether a pa cket is a SYN or not, the add itional assump tion o f b eing able to cou nt all SYN packets is a natural one. It is also implementab le, as a single additional co unter which checks every pac ket and condition ally increments based on a small num ber of h eader bits is not difficult e ven at the highest speeds [5], as we discuss in more detail in Section VI. In summar y , b y knowing N f , ev ery flow gives rise to a samp led flow , each one of which is observable, eith er directly ( j ≥ 1 ) , o r indir ectly ( j = 0 ). In other words, we can in effect observe the θ ′ j over the full range fr om j = 0 to j = W . The chief advantage of the unc ondition al for mulation is the very simple form o f the likelihood f unction f or the experimen- tal outcome j f or a single flow . This makes the man ipulation of the Fisher inform ation far m ore tractable, leading to new analytic resu lts an d insigh ts. The other big ad vantage is that flow sampling can now be included . In the co nditional world flow sampling is perfect – by definition, if a flow is sampled at all, all its packets will be and so there is no thing to do ! The unco nditional fram ew ork allows the missing par t of the picture to be included, enablin g meanin gful com parison. D. The Sampled Flow Distrib ution Our analysis is b ased on the idea o f selectin g a ‘typ ical’ flow , and tha t flows a re m utually independ ent (a reasonable Fig. 1. The flow sampling and sele ction process. Here a flo w is selected which had k = 5 packets originall y and j = 3 after sampling. assumption if N f is very large) . Since flows ar e in fact deterministic, th is is on ly mean ingful if we introd uce a sup- plementary rand om v ariable U , a unifo rm over th e N f flows av a ilable, wh ich p erform s the r andom flow selection. This variable, which acts ‘in v isibly’ behind the scenes (and is rare ly discussed), is not p art of th e random sampling sch eme itself, but is essential as it allows the θ par ameters to be trea ted as probab ilities, even though they are n ot. An example is g iv en in Fig ure 1 which shows N f = 12 flows before and after sampling, followed by a random flow selection. In the interests of clarity a flow of size j = 3 after sampling was selected , but it c ould ha ve been one of the ev aporated flo ws ( j = 0 ). W ith this backgr ound established , the discrete distribution for a sampled flo w or iginally of size k is very simple: d j = W X k =1 b j k θ k , 0 ≤ j ≤ W . (4) This can be e xpressed in matrix notation as d = B θ (5) where d = [ d 0 , d 1 , d 2 , . . . , d W ] T is a ( W + 1) × 1 colum n vector , and θ a W × 1 co lumn vector . The p robab ility d j is related to the empirical fr action θ ′ j for j ≥ 0 by E [ θ ′ j ] = E [ P i : m ′ i = j 1] N f = P N f i =1 E [ 1 ( m ′ i = j )] N f = P N f i =1 Pr( m ′ i = j ) N f = N f d j N f = d j . The likeliho od fun ction fo r the parameters is simply f ( j ; θ ) = d j , 0 ≤ j ≤ W. (6) In the c onditiona l fram ew ork com monly used j = 0 is missing, and no rmalization is then needed to en sure pro babilities add to one. This implies a di vision o f random variables, which greatly co mplicates th e lik elihood . E. The F isher Information of a Sa mpled Flow The parame ter vector θ is the unk nown we would like to estimate fr om samp led flows. Since here we are n ot co ncerned 4 with specific estima tors of θ , but in th e effecti veness of the underly ing sampling sch eme, a powerful appr oach (introd uced in [4]) is to u se the F isher informa tion [9, Section 11.1 0] to access its efficiency in collectin g in formation ab out θ . W e first in troduce notation that will b e used thr ougho ut this paper . The expectation of a ran dom variable X is deno ted by E [ X ] , and th e variance by V ar( X ) . M atrices are written in bold-face up per case and vectors in bold-face lower case. The transpose of a matrix A is denoted by A T . The operato r also applies to vectors. T he o perator tr ( A ) deno tes the trace o f th e matrix A . The matrix I n denotes the n × n iden tity matrix. The vector 1 n = [1 , 1 , . . . , 1] T denotes an n × 1 v ector of 1s. The vector 0 n denotes the n × 1 n ull vector, and th e m × n null matrix is written as 0 m × n . Giv en an n × 1 vector x , diag ( x ) denotes an n × n matrix with diagonal entries x 1 , x 2 , . . . , x n . Definition 1 : An n × n real matrix M is positive defi nite iff for all vecto rs z ∈ R n \{ 0 n } , z T Mz > 0 , and is positive semidefinite if f z T Mz ≥ 0 . W e wr ite A > 0 or 0 < A to indicate that A is positive definite. For tw o matr ices A and B , we write A > B to mean A − B > 0 in the positiv e de finite sense. Similarly , A ≥ B an d A − B ≥ 0 each mean that A − B is positive semidefinite. The operator | · | returns the size of a vector or set. All other definitions will be d efined w hen n eeded. The Fisher inform ation is useful b ecause its in verse is the Cram ´ er-Rao lower bo und (CRLB), wh ich lower-bounds th e variance of any unb iased estimator of θ . In fact the Fisher informa tion takes a different form d ependin g on whether constraints are imposed on the θ or not [10]. Inequ ality constraints are particular ly problematic, so we av oid them by assuming th at each θ k obeys 0 < θ k < 1 (this en sures that the CRLB optimal solutio n cannot inclu de boun dary values, which would create bias and there by in validate the use of the unbiased CRLB). Assuming that flo ws e xist for all sizes, i.e. that θ k > 0 for all k , is reasonable given th e h uge n umber of simultaneou sly active flows (u p to a million) in high end routers. Ther e is one mo re constraint, th e equality constraint P W k =1 θ k = 1 , which must be includ ed. As this comp licates the Fisher inf ormation , we first dea l with the unco nstrained case. F . The Unco nstrained F isher Info rmation The Fisher info rmation is based on the likelihoo d and is defined b y J ( θ ) = E [( ∇ θ log f ( j ; θ ))( ∇ θ log f ( j ; θ )) T ] = W X j =0 ( ∇ θ log f ( j ; θ ))( ∇ θ log f ( j ; θ )) T d j . (7) Here ∇ θ log f ( j ; θ ) = (1 /d j )[ b j 1 , . . . , b j W ] T because o f the simple f orm (6) of th e likelihoo d. This leads to th e simple explicit expression ( J ( θ )) ik = P W j =0 b ji b jk d j , or equivalently J ( θ ) = B T D ( θ ) B (8) where D ( θ ) is a diagona l matrix with ( D ( θ )) j j = d − 1 j − 1 . W e will n eed to find th e in verse of J , but since B is not square, this cannot be do ne directly from (8) in terms of the in verse of B . Howe ver if we re-express B as B = b T 0 ˜ B (9) where b T 0 = [ b 01 , . . . , b 0 W ] is the top row of B an d ˜ B = b 11 b 12 · · · b 1 W 0 b 22 · · · b 2 W . . . . . . . . . . . . 0 0 · · · b W W , then we can write J ( θ ) = 1 d 0 b 0 b T 0 + ˜ J ( θ ) (10) where ˜ J ( θ ) = ˜ B T ˜ D ( θ ) ˜ B , ˜ D ( θ ) = diag ( d − 1 1 , . . . , d − 1 W ) , and d 0 = b T 0 θ . Since ˜ B and ˜ D ( θ ) a re sq uare, th e in verse o f ˜ J ( θ ) is ju st ˜ J − 1 ( θ ) = ˜ B − 1 ˜ D − 1 ( θ )( ˜ B − 1 ) T , that is ( ˜ J − 1 ( θ )) ik = W X j =1 b ′ ij b ′ kj d j (11) where b ′ j k = ( ˜ B − 1 ) j k . By Lemma 2 8(ii) in Ap pendix B, ˜ J ( θ ) is p ositi ve definite. W e can n ow giv e the in verse o f ˜ J . Pr op osition 2: The in verse of J ( θ ) is given by J − 1 ( θ ) = ˜ J − 1 ( θ ) − 1 d 0 + b T 0 ˜ J − 1 ( θ ) b 0 ˜ J − 1 ( θ ) b 0 b T 0 ˜ J − 1 ( θ ) . Pr oo f: The matrix inversion lemma applies (see Lemma 30 in Ap pendix A) with R = ˜ J and T = 1 /d 0 nonsingu lar . Since d 0 + b T 0 ˜ J − 1 ( θ ) b 0 > b T 0 ˜ J − 1 ( θ ) b 0 > 0 as ˜ J − 1 is p ositi ve definite, the r esult imm ediately follows. The d iagonal elements of the matrix J − 1 ( θ ) will be impo rtant in later sections, and the explicit form ula is gi ven below: ( J − 1 ( θ )) j j = W X k =1 b ′ 2 j k d k − P W k = j d k b ′ j k P k ℓ =1 b 0 ℓ b ′ ℓk 2 d 0 + P W k =1 d k P k ℓ =1 b 0 ℓ b ′ ℓk 2 . (12) Again, this explicit inverse, valid for any general samplin g matrix B , is made possible by the very s imple form of the like- lihood f unction in equation ( 6). W e now specialize the above result fo r sampling matrices that satisfy particular cond itions. Although some of th ese matrices e xhibit a dependence on θ , we drop this depe ndence fo r n otational simplicity when the context is clear . Cor ollary 3: If for so me constant q the sampling matrix B satisfies b 0 = q 1 W then (setting p = 1 − q ) J − 1 = ˜ J − 1 − q p θ θ T . Pr oo f: The given conditio n implies that d 0 = b T 0 θ = q 1 T W θ = q , an d 1 T W ˜ B − 1 = (1 /p ) 1 T W since B is column 5 stochastic. Next, b T 0 ˜ J − 1 b 0 = q 2 1 T W ˜ J − 1 1 W = q 2 1 T W ˜ B − 1 ˜ D − 1 ( ˜ B − 1 ) T 1 W = ( q 2 /p 2 ) 1 T W ˜ D − 1 1 W = ( q 2 /p 2 ) W X j =1 d j = ( q 2 /p 2 )(1 − d 0 ) = q 2 /p. Let ˜ d = ˜ B θ = [ d 1 , d 2 , . . . d W ] T . Then fro m Propo sition 2, J − 1 = ˜ J − 1 − 1 d 0 + q 2 /p ˜ J − 1 b 0 b T 0 ˜ J − 1 = ˜ J − 1 − q 2 /p 2 q + q 2 /p ˜ B − 1 ˜ D − 1 1 W 1 T W ˜ D − 1 ( ˜ B T ) − 1 = ˜ J − 1 − q 2 /p 2 q + q 2 /p ˜ B − 1 ˜ d ˜ d T ( ˜ B T ) − 1 = ˜ J − 1 − q p θ θ T . The matrix ˜ J correspon ds to the inform ation car ried by the outcomes 1 ≤ j ≤ W o nly . W e expect J to car ry mor e informa tion through the kn owledge of N f which gives access to j = 0 , and th erefore J − 1 to have re duced uncertainty , correspo nding (thr ough th e CRLB) to a red uced variance. The following result confirm s this intuition (pr oof in Ap pendix A) . Theor em 4: An upper bo und f or J − 1 ( θ ) is J − 1 ( θ ) ≤ ˜ J − 1 ( θ ) . Equality h olds if and only if b 0 = 0 W × 1 . The reduc tion in uncer tainty is given by the second term in the expression for J − 1 ( θ ) in Propo sition 2. G. The Constr ained F isher I nformation and CRLB Intuitively , c onstraints on the par ameters should increase the Fisher in formation since they tell us someth ing mor e abou t them, ‘for free’. In fact, [ 11] shows that th is is on ly true for equality constraints. Since we a re assuming that 0 < θ k < 1 , the only active constraint is P W k =1 θ k = 1 . I ts g radient is G ( θ ) = ∇ θ g ( θ ) (13) where g ( θ ) = P W j =1 θ j − 1 . The inverse constrained Fisher infor mation [11] is I + = J − 1 − J − 1 G G T J − 1 G − 1 G T J − 1 (14) where I + denotes the Moore-Pen rose p seudo-inverse [12, Chapter 20, pp. 493-51 4] o f the constrained Fisher information matrix I . Th e m atrix I + is rank W − 1 due to th e single equality constraint and is thus singu lar (see [11, Remark 2]). This somewhat fo rmidable expr ession ca n be simplified in our case, as we now show . Lemma 5 : J diag ( θ 1 , . . . , θ W ) 1 W = 1 W . Pr oo f: Th e row sum of ro w i of J diag ( θ 1 , . . . , θ W ) is W X k =1 W X j =0 b j i b j k d j θ k = W X j =0 b j i d j W X k =1 b j k θ k = W X j =0 b j i d j d j = 1 since B is column stochastic. It is easy to see that G = 1 W . Hence J − 1 G = J − 1 1 W = diag ( θ 1 , . . . , θ W ) 1 W = θ from Lemma 5. It is then straigh t- forward to verify that G T J − 1 G is simply the n umber 1 , and further that (14) can be red uced to I + = J − 1 − θ θ T . (15) The rem arkable thin g here is that the constrain t term θθ T depend s on θ only , and so is constant for all samp ling matrices B , a great adv antage when comparin g different methods. Since we are assumin g flows are sampled indep endently , the Fisher inf ormation f or N flows is just N J , an d th e inv erse becomes I + / N . For any unbiased estimator ˆ θ of θ , th e CRLB then states that E [( ˆ θ − θ )( ˆ θ − θ ) T ] ≥ I + ( θ ) N . (16) Because of ind ependen ce we study N = 1 . In p ractice all flows are sam pled a nd so N = N f . Remark 6 : There is an inte rpretation to th e simple struc- ture of the matrix P = J − 1 G ( G T J − 1 G ) − 1 G T J − 1 . The scalar value 1 T W I + 1 W is eq uiv alent to V ar( P W i =1 ˆ θ i ) . By the equ ality con straint, we expect the best estimator o f P W i =1 ˆ θ i to have a variance of 0, since the estimator already knows that P W i =1 θ i = 1 . T his co rrespon ds to a CRLB o f zero, nam ely 1 T W I + 1 W = 1 T W J − 1 1 W − 1 T W θ θ T 1 W = 1 T W diag ( θ 1 , . . . , θ W ) 1 W − 1 = 0 . Thus, P = θ θ T is the form of the cor rection term to the unco nstrained covariance matrix J − 1 needed to satisfy the con straint. I I I . T H E S A M P L I N G M E T H O D S In this section we define the sam pling metho ds we consider and deriv e their main properties. W e begin with metho ds which have been d escribed elsewhere, in cluding simple packet and flow sampling, as well as others exploitin g protoc ol informa tion, in particular th ose proposed in [4], [1]. Apart from th eir in herent inte rest, we revisit these because in the uncon ditional framework these methods are no w all different to befo re. More imp ortantly , we also d erive inverses an alyti- cally which has not been p ossible before, and thereby o btain a n umber of impor tant insights. W e also in clude the widely cited ‘Sample and Hold’ [ 6] whose Fisher inf ormation h as not previously b een studied. W e then introdu ce ou r ne w method, Dual Sam pling. T o better see the connec tion b etween the usual fra mew ork and ou rs, r ecall tha t b j k is always a c ondition al pr obability with respect to the s ize k of the original flow . T ypically howe ver , it is also made conditiona l with respect to j , b ut we do not so here. Hen ce, if B c is the usu al j -co nditional m atrix, then B c C = ˜ B where C = I W − diag ( b 01 , . . . , b 0 W ) , i.e. the matrix C − 1 does th e con ditioning . W e use the decomposition o f (9) to describ e e ach sampling matrix B . In each case we define B an d ˜ B , give the inverse ˜ B − 1 of ˜ B , and g iv e explicit e xpressions for the d iagonal terms ( J − 1 ) j j , or in some c ase for the e ntire inverse J − 1 . The importan ce of the diag onal terms will become very clear in Section I V. 6 A. P acket Sa mpling (P S) By this we mean th e simplest for m of sampling , i.i.d. packet sampling , wher e each packet is retained ind ependen tly with probab ility p p and otherwise dro pped with q p = 1 − p p . For the purpo se of simplicity , we treat both ‘1 in N ’ periodic sampling and i. i.d. rand om samp ling und er the same fr amew ork, as both methods were shown to be statistically indistinguishable in practice [1]. The chief ben efit of PS is its simplicity , and the fact that it can be implemented at high speed becau se a sampling decision can b e m ade withou t ev en inspectin g the packet. The c hief disadvantage is the fact that it has a stron g length bias, small flows are very likely to e vaporate. It is easy to see that b j k = k j p j p q k − j p , or B = q p q 2 p q 3 p q 4 p · · · q W p p p 2 p p q p 3 p p q 2 p 4 p p q 3 p · · · W 1 p p q W − 1 p 0 p 2 p 3 p 2 p q p 6 p 2 p q 2 p · · · W 2 p 2 p q W − 2 p . . . . . . . . . . . . . . . . . . 0 0 0 · · · 0 p W p . Before finding the inverse of ˜ B , it is first instructive to n ote the following gen eral results by Strum [ 13]. Let B ( x, y ) be an ( W + 1) × ( W + 1) matrix with the following structure B ( x, y ) = 1 x x 2 · · · x W 0 y 2 xy · · · W 1 x W − 1 y 0 0 y 2 · · · W 2 x W − 2 y 2 . . . . . . . . . . . . . . . 0 0 0 · · · y W which is kn own as the binomia l matrix . Note that B (0 , 1) reduces to the identity ma trix. From [13] we have Lemma 7 : If y 6 = 0 , then B ( x, y ) is invertible and [ B ( x, y )] − 1 = B ( − xy − 1 , y − 1 ) . Using th ese results we ca n find the inverse of ˜ B (r ecall that b ′ j k = ( ˜ B − 1 ) j k .) Theor em 8: Th e inverse of ˜ B is given by ˜ B − 1 = p − 1 p − 2 p − 2 p q p 3 p − 3 p q 2 p · · · W p − W p ( − q p ) W − 1 0 p − 2 p − 3 p − 3 p q p · · · . . . . . . . . . . . . . . . . . . 0 0 · · · · · · p − W p that is b ′ j k = ( − 1) k − j k j q k − j p p − k p . Pr oo f: Here b T 0 = [ q p , q 2 p , . . . q W p ] . W e have B ( q p , p p ) = 1 b T 0 0 W ˜ B . Since B ( q p , p p )[ B ( q p , p p )] − 1 = I W +1 , for some k we have 1 b T 0 0 W ˜ B 1 k 0 W ˜ B − 1 = 1 0 T W 0 W I W . Furthermo re, from Lemma 7 we ha ve [ B ( q p , p p )] − 1 = B ( − q p p − 1 p , p − 1 p ) . Thus ˜ B − 1 is essentially a prin cipal W × W submatrix o f B ( − q p p − 1 p , p − 1 p ) . For PS J − 1 is difficult to write in a compact form and will be o mitted. It is howe ver feasible to gi ve using eq uation (1 2) ( J − 1 ) j j = W X k = j k j 2 q 2( k − j ) p p − 2 k p d k − P W k = j ( − 1) 2 k − j − 1 d k k j q 2 k − j p p − 2 k p 2 P W k =0 q 2 k p p − 2 k p d k . (17) The a bove form is derived in Appen dix C. B. P acket Sa mpling with Sequence Numb ers (PS+SE Q) First PS with p arameter p p is p erforme d as ab ove. Se- quence number s ar e then used as follows. Let s l be the lowest sequ ence number among the sampled packets, and s h the highest. All packets in -between these ca n n ow reliably inferred , h ence j = s h − s l + 1 is the nu mber of sam pled packets retur ned. This is called “ ALL -seq-sflag” in [4]. The chief bene fit of PS+SEQ is the fact that a potentially large number of packets can b e ‘virtu ally’ ob served with out having to p hysically samp le them. The d isadvantage is the additional processing inv o lved to pe rform the inferen ce. Also, the techniq ue is of limited v alue if flows are too short (as we discuss later). If j = 0 , 1 th en sequen ce num bers cannot h elp and b j k is as f or PS. Otherwise, note that the j p ackets must occur in a contiguo us block bor dered by s l and s h . Th ere are k − j + 1 possible positions fo r such a bloc k, each characterized by k − j unsampled packets outside it an d the bord ers s l and s h . It follows that b j k = ( k − j + 1 ) p 2 p q k − j p for 2 < j ≤ k . Hence B = q p q 2 p q 3 p q 4 p · · · q W p p p 2 p p q p 3 p p q 2 p 4 p p q 3 p · · · W p p q W − 1 p 0 p 2 p 2 p 2 p q p 3 p 2 p q 2 p · · · ( W − 1) p 2 p q W − 2 p 0 0 p 2 p 2 p 2 p q p · · · ( W − 2) p 2 p q W − 3 p . . . . . . . . . . . . . . . . . . 0 0 0 · · · 0 p 2 p . Theor em 9: Th e inverse of ˜ B is ˜ B − 1 = p − 1 p − 2 q p p − 2 p q 2 p p − 2 p 0 · · · 0 0 p − 2 p − 2 q p p − 2 p q 2 p p − 2 p · · · 0 0 0 p − 2 p − 2 q p p − 2 p · · · 0 . . . . . . . . . . . . . . . . . . 0 0 0 · · · 0 p − 2 p . Pr oo f: Obser ve that ˜ B = ST where S = diag ( p p , p 2 p , p 2 p , . . . , p 2 p ) 7 is a W × W matrix and T = 1 2 q p 3 q 2 p 4 q 3 p · · · W q W − 1 p 0 1 2 q p 3 q 2 p · · · ( W − 1) q W − 2 p 0 0 1 2 q p · · · ( W − 2) q W − 3 p . . . . . . . . . . . . . . . . . . 0 0 0 · · · 0 1 . A straightforward computatio n yields T − 1 = 1 − 2 q p q 2 p 0 · · · 0 0 1 − 2 q p q 2 p · · · 0 0 0 1 − 2 q p · · · 0 . . . . . . . . . . . . . . . . . . 0 0 0 · · · 0 1 , and S − 1 = diag ( p − 1 p , p − 2 p , p − 2 p , . . . , p − 2 p ) . Thus, ˜ B − 1 = T − 1 S − 1 , which proves our r esult. The d iagonal ele ments o f J − 1 are gi ven by ( J − 1 ) 11 = p − 2 p d 1 + 4 q 2 p p − 4 p d 2 + q 4 p p − 4 p d 3 − ( q 2 p p − 4 p d 1 + 2 q 3 p p − 4 p d 2 ) 2 r ( J − 1 ) 22 = p − 4 p d 2 + 4 q 2 p p − 4 p d 3 + q 4 p p − 4 p d 4 − q 4 p p − 8 p d 2 2 r ( J − 1 ) j j = p − 4 p d j + 4 q 2 p p − 4 p d j +1 + q 4 p p − 4 p d j +2 , 3 ≤ j ≤ W where r = d 0 + q 2 p p − 2 p d 1 + q 4 p p − 4 p d 2 , and for conv enience we set d j = 0 for j > W . C. P a ck et Samp ling with SYN Sa mpling (P S+SYN) First PS with pa rameter p p is performed as above. A post-pro cessing pha se th en discar ds all packets belongin g to sampled flows which lack a SYN packet (or more acc urately , maps them to sampled flo ws with j = 0 ). Th is was intr oduced in [1] and called “SYN-p ktct” in [4]. The ch ief benefit of PS+SYN is that the flow len gth bias of PS is a verted by k eeping flows based on the p resence of the SYN, wh ich is flow length indepe ndent. The ch ief disadvantage is the fact that it is wasteful: if p p = 0 . 01 then 99% of packets which were initially sampled belo ng to ‘failed’ flows and are subsequen tly discarde d! A flow ev aporates iff its SYN is not sampled, h ence b 0 k = q p . For j ≥ 1 the SYN must first be sampled, which occurs with prob ability p p , an d co nditional on this j − 1 more packets must be sampled fr om the remaining k − 1 usin g i.i.d. sampling. Hen ce b j k = p p · k − 1 j − 1 p j − 1 p q k − j p for j ≥ 1 , giving B = q p q p q p · · · q p p p p p q p p p q 2 p · · · p p q W − 1 p 0 p 2 p 2 p 2 p q p · · · ( W − 1) p 2 p q W − 2 p . . . . . . . . . . . . . . . 0 0 0 · · · p W p . Theor em 10 : T he inverse of ˜ B is given by ˜ B − 1 = 1 p p 1 − q p p − 1 p q 2 p p − 2 p · · · ( − q p ) W − 1 p − W +1 p 0 p − 1 p − 2 q p p − 2 p · · · ( − q p ) W − 2 p − W +1 p . . . . . . . . . . . . . . . 0 0 · · · · · · p − W +1 p that is b ′ j k = ( − 1) k − j k − 1 j − 1 q k − j p p − k p . Pr oo f: Note t hat we can express ˜ B in terms of a W × W binom ial matrix B ( x, y ) such that ˜ B = p p B ( q p , p p ) . T hen b y Lem ma 7, the in verse is given by ˜ B = (1 /p p ) B ( − q p p − 1 p , p − 1 p ) . It is easy to see that th e cond ition of Cor ollary 3 is satisfied with p = p p . Hen ce J − 1 = ˜ J − 1 − q p p p θ θ T , an d the diagona l entries f or 1 ≤ j ≤ W are ( J − 1 ) j j = W X k = j k − 1 j − 1 2 q 2( k − j ) p p − 2 k p d k − q p p p θ 2 j . (18) D. P acket Sam pling with SYN a nd SEQ (PS+SYN+SEQ) First sam pling is per formed acco rding to PS+SYN with parameter p p , an d then on each resulting sampled flo w the se- quence number post-pr ocessing is pe rformed as per PS+SEQ. This is called “SYN-seq” in [4]. PS+SYN+SEQ is a hy brid of PS+SYN an d PS+SEQ an d combin es the advantages and disadvantages of both. If j = 0 , 1 th en sequ ence n umber s cannot help and b j k is as for PS+SYN. Oth erwise, b y combining the arguments above, it is easy to see that b j k = p p · p p q k − j p for j > 1 , giving B = q p q p q p q p · · · q p p p p p q p p p q 2 p p p q 3 p · · · p p q W − 1 p 0 p 2 p p 2 p q p p 2 p q 2 p · · · p 2 p q W − 2 p 0 0 p 2 p p 2 p q p · · · p 2 p q W − 3 p . . . . . . . . . . . . . . . . . . 0 0 0 · · · 0 p 2 p . (1 9) Theor em 11 : T he inverse of ˜ B is given by ˜ B − 1 = 1 p p 1 − q p p p 0 0 · · · 0 0 1 p p − q p p p 0 · · · 0 0 0 1 p p − q p p p · · · 0 . . . . . . . . . . . . . . . . . . 0 0 0 · · · 0 1 p p Pr oo f: A straightforward computa tion shows that ˜ B ˜ B − 1 = I W . Since b 0 = q p 1 W , Corollary 3 applies and states that J − 1 = ˜ J − 1 − q p p p θ θ T . The diago nal elements can be explicitly written, but we defer this to Section III-H. E. Flow Sampling (FS) In i.i.d. flow sampling [3], flows are retained independen tly with pr obability p f and otherwise dro pped with q f = 1 − p f . The ch ief ben efit of FS is the fact that flo ws which are sampled retain their fu ll complemen t of packets, elimin ating completely the difficulties in in verting sampled flow sizes back to orig inal sizes. Th e chief disadvantage is that ea ch packet requires a look up in a flow table to see if it be longs to be flow which has been sampled. A flow ev aporates iff its SYN is not sampled, hence b 0 k = q f . If a flo w has been selected, which occurs with p robability 8 p f , then con ditional on this j = k with certainty , th at is b j k = 1 if j = k , else 0, for j ≥ 1 : B = q f q f q f q f · · · q f p f 0 0 0 · · · 0 0 p f 0 0 · · · 0 . . . . . . . . . . . . . . . . . . 0 0 0 0 · · · p f . (20) The inverse of ˜ B is just ˜ B − 1 = I W /p f , an d J takes the elegant form J ( θ ) = q f 1 W 1 T W + p f diag ( θ − 1 1 , . . . , θ − 1 W ) . Clearly Cor ollary 3 applies with p = p f . Since ˜ J = p f diag ( θ − 1 1 , . . . , θ − 1 W ) , the unconstrained in verse can therefore b e expressed as J − 1 ( θ ) = 1 p f diag ( θ ) + (1 − 1 p f ) θ θ T . (2 1) Remark 1 2: By using equ ations (15) and (2 1), the inverse constrained Fisher inform ation matrix for FS is g i ven by I + = 1 p f diag ( θ ) − 1 p f θ θ T , with the diag onals being ( I + ) kk = (1 / p f ) θ k (1 − θ k ) . This is just an approp riately scaled version (b y 1 /p f ) of the in verse Fisher information of a multinomial model. This m akes sense giv en that FS work s by p icking o ut who le flows fro m the o rig- inal flow set in an i.i.d fashion and that the complete likelihood function can be modeled using a mu ltinomial mo del. F . P acket Sampling with S YN, FIN, SE Q (PS+SYN+FIN+SEQ) In this schem e SYN packets are retained indepe ndently with probab ility p f and oth erwise drop ped with q f = 1 − p f , an d the FIN packets correspondin g to sampled SYNs are also sampled, but no others. Sequence nu mbers are then used to infer flow sizes. This scheme has two gr eat advantages: like FS th e flows sampled are sampled per fectly , an d m oreover th is could be achieved by ph ysically samp ling on ly two packets per flow , based on lo oking for SYN and FIN flags o n a p er packet basis, w hich is feasible at hig h spee d. The disad vantage is th at a moderate m inority of flows do no t te rminate correctly with a FIN, and/or the FIN ma y be not observable. Furthermor e, flows consisting of a single SYN ( such as in a SYN attack) would be entirely missed. For this reason we cho ose no t to study it furthe r . Inform ation th eoretically , PS+SYN+FIN+SEQ is identical to flo w sampling provided we assume θ 1 ≈ 0 . G. Sample and Hold (SH) Here packets are first samp led as for PS with probab ility p p , howev er fo r each flow if a packet is samp led, then all subsequen t packets in the flow will b e. Hence th e total numb er of packets sampled is mu ch higher than th e p arameter p p . The scheme w as in troduced in [6]. The chief benefit o f SH is that provide d just a single p acket from a flow is PS-sampled, th en typically many will be finally sampled. This co nditional be haviour is mu ch mo re effectiv e than methods using SEQ where at least tw o packets must be PS-sampled, an d even then fewer pac kets are finally recoup ed. Essentially SH skips a geo metric numb er o f the first p ackets in a flow and then captu res all the rest. It therefore ef ficiently skips small flo ws and accurately recovers the size of large flows. T his amp lified flow length bias ( ev en stronger than f or PS) makes it well suited for the hea vy hitter problem (i.e. ac- curately measur ing the very largest flows) fo r which it was originally designe d. For flow size estimation mo re generally howe ver , it is a disadvantage f or most flow sizes. T he other disadvantage is the need to che ck, for each packet , wheth er it belongs to a flow which h as already been samp led. This m akes it very co stly in a true samp ling im plementation . Inde ed Estan and V arghese implemen ted it using lossy sketching techn iques [6]. A flow evaporates if f no ne of its p ackets are sampled, h ence b 0 k = q k p . Otherwise, b j k = p p q k − j p , thu s: B = q p q 2 p q 3 p q 4 p · · · q W p p p p p q p p p q 2 p p p q 3 p · · · p p q W − 1 p 0 p p p p q p p p q 2 p · · · p p q W − 2 p . . . . . . . . . . . . . . . . . . 0 0 0 0 · · · p p . (2 2) It is intere sting to no te that the fir st row is as for PS, the second as f or PS+SYN, and sub sequent rows like PS+SYN scaled b y 1 / p p . Theor em 13 : T he inverse of ˜ B is given by ˜ B − 1 = 1 p p 1 − q p 0 0 · · · 0 0 1 − q p 0 · · · 0 0 0 1 − q p · · · 0 . . . . . . . . . . . . . . . . . . 0 0 0 · · · 1 − q p 0 0 0 · · · 0 1 Pr oo f: It is easily verified that ˜ B ˜ B − 1 = I W . It is not difficult to show that Prop osition 2 r educes to J − 1 = ˜ J − 1 − C , where the on ly no n-zero element of C is C 11 = p − 2 p q 2 p d 2 1 ( p 2 p d 0 + q 2 p d 1 ) − 1 = d 0 /p p since d 1 = p p q p d 0 . Furthermo re, using (11) one can show th at ˜ J − 1 is tridiago nal (and symmetric) with u pper off-diagonal terms ( ˜ J − 1 ) k,k +1 = − p − 2 p q p d k +1 , k < W , an d d iagonal elem ents ( J − 1 ) 11 = 1 p 2 p ( d 1 + q 2 p d 2 ) − 1 p p d 0 = θ 1 + 1 p p W X k =2 q k − 1 p θ k (23) ( J − 1 ) j j = 1 p 2 p ( d j + q 2 p d j +1 ) , 2 ≤ j ≤ W − 1 = θ j p p + 1 + q p p p W X k = j +1 q k − j p θ k (24) ( J − 1 ) W W = d W p 2 p = θ W p p , 9 where we have used the property of B that d j = p p θ j + q p d j +1 for 1 ≤ j ≤ W − 1 . H. Dual S ampling ( DS) DS can be defined simply as follows. First, at the pac ket lev el it con sists of two PS schemes running in parallel, one which operates only o n SYN packets with sampling prob abil- ity p f , and the other only on non- SYN pa ckets with sampling probab ility p p . In a second ph ase, sampled flows which lack a SYN are d iscarded, and sequence numbers are used to infer additional ‘virtu al’ packets, as in PS+SYN+SEQ. Thu s, a t o ne lev el DS is simply a gen eralization of PS+SYN+SEQ, and reduces to it when p f = p p . Howe ver , the gen eralization is significant as it also includes FS as the special c ase p p = 1 , and interpolates con tinuously between the two. This is illustrated in Fig ure 2 which depicts the ( p p , p f ) parameter spac e, and marks the special cases. Dual Sampling is ‘ dual’ in two senses. Comp utationally it ca n be viewed as the origin al PS sampling being split into two, at the ( low) cost of per-packet switching based on some b it ch ecking to d etermine wh ich PS app lies. I nform ation theoretically , th e sampling is now split into tw o parts with very different natures, each co ntrolled by a de dicated par ameter: a F S-like direct sampling of flo ws, and a PS-like in -flow sampling. Here p f controls the numb er o f sampled flows, and p p their ‘ quality’. The der i vation o f the sampling ma trix mirrors closely that of PS+SYN+SEQ. The result shows clear ly how p f and p p act in a mod ular fashion. The flow sam pling com ponen t controls the top row of B and factors ˜ B , whereas the packet sampling compon ent determines th e internal structur e of ˜ B . B = q f q f q f q f · · · q f p f p f q p p f q 2 p p f q 3 p · · · p f q W − 1 p 0 p f p p p f p p q p p f p p q 2 p · · · p f p p q W − 2 p 0 0 p f p p p f p p q p · · · p f p p q W − 3 p . . . . . . . . . . . . . . . . . . 0 0 0 · · · 0 p f p p . The separation of the FS and PS roles in ˜ B is clearly r eflected in its in verse: ˜ B − 1 = 1 p f 1 − q p p p 0 0 · · · 0 0 1 p p − q p p p 0 · · · 0 0 0 1 p p − q p p p · · · 0 . . . . . . . . . . . . . . . . . . 0 0 0 · · · 0 1 p p . The similarity be tween ˜ B − 1 for SH a nd DS is strikin g. Indeed , whereas SH uses sampling to select which flows it will focus on and th en holds to th em, DS reverses these operations and thus could b e descr ibed as a ‘Hold an d Sam ple’ scheme. Howe ver , althoug h th ey each comb ine PS an d FS features, the methods remain significantly different. In pa rticular SH is strongly flow length biased whereas DS is u nbiased. Once again Corollar y 3 for the inverse Fisher info rmation holds, sh owing that J − 1 = ˜ J − 1 − q f p f θ θ T . Similar ly to SH, Fig. 2. Parame ter space ( p p , p f ) of DS. F ixing ESR = p constrai ns the famil y to the solid (blue) curv e p f ( p p ; p ) , where it redu ces to PS+SYN+SEQ at p p = p ∗ p and FS at p p = 1 . Fixing P PR = p co nstrains the famil y to a straight (green) line emana ting from (0 , pD ) . For fix ed p , the constraint curve s depend on D . Three example s are giv en for each normalizati on. from (1 1) one can show that ˜ J − 1 is tridiag onal with u pper off diagona l terms ( ˜ J − 1 ) k,k +1 = − ( p f p p ) − 2 q p d k , k < W . The diagona l elements ( here 2 ≤ j ≤ W − 1 ) are given by ( J − 1 ) 11 = 1 p 2 f p 2 p ( p 2 p d 1 + q 2 p d 2 ) − q f p f θ 2 1 = θ 1 p f + 1 p f p p W X k =2 q k − 1 p θ k − q f p f θ 2 1 (25) ( J − 1 ) j j = 1 p 2 f p 2 p ( d j + q 2 p d j +1 ) − q f p f θ 2 j = θ j p f p p + 1 p f p p W X k = j +1 q k − j p (1 + q p ) θ k − q f p f θ 2 j ( J − 1 ) W W = d W p 2 f p 2 p − q f p f θ 2 W = θ W p f p p − q f p f θ 2 W . (2 6) By setting p f = p p we ob tain tho se for PS+SYN+SEQ. I V . C O M PA R I S O N S In this section we comp are and contrast the p erform ance of the different meth ods, using two normalizations wh ich are the key to a fair comparison. W e show tha t a positiv e semidefinite comparison holds for certain c ases, and justify why we ultimately resort to co mparison of the diagonals of the cov ariance m atrix. W e provide a par tial rankin g of th e methods. Proofs of most key results in this section are deferre d to App endix D. A. Normalization W e mu st first consider how to com pare fairly . W e do this in two ways, using the following pac ket-based measures of incoming worklo ad/infor mation. 10 • P acket Pr o cessing Rate ( PPR ) : the ra te at which p ackets are initially being sampled (a nd h ence r equire some further processing). • E ffective Sampling Rate ( ESR ): the r ate at wh ich packets are arriving to the flow table (an d hence become available as in formatio n for estimatio n). PPR is a me asure of the proc essing speed re quired by the methods, whereas ESR is a m easure of the arriv al rate of packets containing information which is actu ally used by the method. Because the methods which discard flows withou t SYN p ackets lose (the majority) of their packets, an eq ual PPR comp arison greatly d isadvantages them . An equa l ESR compariso n effecti vely inflates the parameters of such methods to compensate. Note that given a sam pling method X , both the PPR and ESR no rmalizations of X+SEQ an d X are identical, as the methods only d iffer in h ow th e packet data is used, not how many p ackets are ph ysically collected . W e now pr esent th e normalizatio ns for each m ethod. Here and below we use D = P W k =1 k θ k ≥ 1 to deno te the a verage flow size. T ab le I g iv es the re sults for PPR. Both th e average sampling rate p as a function of the method parameter( s), and its inv erse, the parameter value requir ed to set the av erage samp ling r ate at p , are sh own. The expression p ( p p , θ ) for SH was de riv ed by compu ting the a verage number of packets sampled (which is h ighly dep endent on θ ) and d i viding the result by the av erage flow size D . It is monoton ically in creasing in p p with p (1 , θ ) = 1 , and p /p p → P W j =1 j P W k = j θ k /D ≥ 1 as p p → 0 , which in the w orst case ( θ W = 1 ) bec omes p/p p = (1 + W ) / 2 . W e inv ert p ( p p , θ ) numerically as requ ired for choices o f θ , denoted by root ( p ( p p )) in the tables. DS has two parameters. W e choose to make p p the independen t one. T ab le II gives the results for ESR. Only the methods which in volve d iscarding pac kets after their initial collection ha ve changed compared to T able I. Note th at fo r PS+SYN p/p p → 1 /D ≥ 1 as p p → 0 , and p (1) = 1 . W e are particu larly interested in th e ESR case for the DS family , and so r epeat its ESR normalization here: p f ( p p ; p ) = pD p p ( D − 1 ) + 1 . (27) The deno minator p p ( D − 1) + 1 is simply the average samp led flow size, conditional on its SYN being sampled. For fixed p , this equ ation gives p f as a monoto nically decreasing, in fact conv ex, function of p p . Three e xamples (the blu e curves) are giv en in Figu re 2 for different values of D . T o maintain an ESR fixed at p , if we increase p p we must move down the curve and decr ease p f to com pensate. The PPR case is similar Method(pa rams) A verage sampling rate p = PPR ( p ) = PS ( p p ) p p p PS+SYN ( p p ) p p p FS ( p f ) p f p SH ( p p ) p p D P W j =1 j q − j p P W k = j q k p θ k root ( p ( p p )) DS ( p p , p f ) p f 1 D + p p 1 − 1 D p f = pD − p p ( D − 1) T ABLE I A V E R A G E P P R S A M P L I N G R AT E S A N D N O R M A L I Z A T I O N S . Method(pa rams) A verage sampling rate p = ESR ( p ) = PS ( p p ) p p p PS+SYN ( p p ) p p ( p p ( D − 1)+1) D − 1+ √ 1+4 pD ( D − 1) 2( D − 1) FS ( p f ) p f p SH ( p p ) p p D P W j =1 j q − j p P W k = j q k p θ k root ( p ( p p )) DS ( p p , p f ) p f ( p p ( D − 1)+1) D p f = pD p p ( D − 1)+1 T ABLE II A V E R A G E E S R S A M P L I N G R AT E S A N D N O R M A L I Z AT I O N S . but simpler as th e level curves ar e straig ht lines (gr een lines in Figu re 2). Note that depend ing on p and D , under both PPR and ESR there are values of p f and/or p p that may be disallowed. T o compar e m ethods we also req uire a performanc e metric . A natural c riterion is th e set of diagonal elements of the CR LB, the k -th b eing ( I + ) kk = ( J − 1 ) kk − θ 2 k , (28) since this is a lower bou nd on the variance of any un biased estimator of θ k . W e plo t the square root of these values, calculated usin g the expressions for the pr evious section. Fig. 3. An equal PPR comparison of the CRLB bound for θ with p = 0 . 005 . Fig. 4. Dependence of the CLRB bound on p , PPR comparison. 11 W e be gin with some instructi ve examples. Consider the results of Figure 3, where we set W = 5 with θ = { 0 . 2 2 , 0 . 21 , 0 . 20 , 0 . 19 , 0 . 08 } , for wh ich D = 2 . 90 packets. W e use the PPR nor malization with p = 0 . 005 , correspon ding to p p ≈ 0 . 00 2184 5 for SH. For DS we g iv e two examp les satisfying p : ( p f , p p ) = (0 . 001 , 0 . 0443 ) , a nd ( p f , p p ) = (0 . 1 , 0 . 0 0334 ) . As expected from ear lier work, the perfo rmance of PS is extraordinar ily poor . I n agreement with the results of [4] and as expected , th e inclusion o f SEQ im proves it enormously , by o rders of magn itude, but it is still orders of magn itude behind FS, wh ich has the lowest standard deviation bo und of all. In a highly coun terintuitive r esult, PS+SYN performs (much! ) better than PS, d espite the en ormou s n umber of wasted p ackets. W e can offer two r easons for this. First, in the unco nditional fr amew ork in formatio n in d iscarded flows is n ot e ntirely wasted, some is reco uped by the (observable) increase in th e j = 0 outcome 1 . Second, SYN sampled flo ws (much like FS) h av e no flow length b ias. T ogether th ese lead PS+SYN to pe rform better in most cases even und er PPR. Three r esults for DS are gi ven. Fro m best to worst these were with p f = 0 . 001 < p , the special case PS+SYN+SEQ with p f = p , and p f = 0 . 1 > p . Finally SH per forms well in this example as its key disadvantage, a strong bias to large flo ws, does n ot p lay a large role for suc h a small v alue of W . Using the same PPR ba sed comp arison, Figur e 4 shows th e improvement in CRLB as p increases, as we expect. W e see that very high v alues of p are n eeded bef ore the p erform ance of FS is app roached . Here the free par ameter p f for DS was chosen to guarantee meaningfu l examples to either side of PS+SYN+SEQ. Specifically , the normalization defines fo r each v alue of p a feasible range [ p l f , p u f ] for p f which in cludes p f = p . For DS1 we set p f = p − c ( p − p l f ) < p , and for DS2 p f = p + c ( p u f − p ) > p , where c ∈ [0 , 1] . In the figure we use c = 0 . 1 . The gr eat merit of the ESR normalizatio n is that it allows us to vie w the methods as being different ways in which the 1 It was pointed out in [4], under a condit ional framewor k, that PS+SYN+SEQ outperforms PS+SEQ on actual traces. Our own numeric al e v aluati on of the CRLB of these methods (under the conditiona l frame work ) also sho w this in some cases, leadi ng us to c onject ure the same coun terint uiti ve results may hold for the condition al frame work. Fig. 5. An equal ESR comparison of the CRLB bound for θ with p = 0 . 005 . same budget of sampled packets can be allocated among flo ws. The essential tradeoff is tha t we can h av e more sam pled flows of p oor quality , or fewer of higher qua lity . In a class w ith no flow leng th bias, flo w sampling is at one e xtreme: for a given ESR = p it giv es th e minimu m n umber of sampled flo ws, each of perfect quality . Among sub-classes of metho ds with roughly the same numbe r of flows, we can then distinguish between the fin er de tails of how the ‘h oles’ appea r over the flow , which will h av e an impact on the degree of improvement wh ich the sequence n umbers can bring. Results using the same scenario as Figu re 3 but ESR normalized are shown in Figure 5. As expected, all SYN-based methods im prove significantly . In particular the DS with the smaller p f = 0 . 001 no w outperform s SH, and is second only to FS. Another example with a larger W = 50 and a truncated exponential distribution for θ with D = 1 6 . 039 is g iv en in Figu re 6. Th e same general conclusion s hold, with the exception of SH, whose performan ce is n ow worse than PS+SYN+SEQ rather than con siderably better . This is to be expected at larger W , as SH expen ds its packet budget on the rare largest flo ws. At rea listic W values in network data this effect is f urther exag gerated. It is inter esting to n ote in the right plot of Figure 6 th at variance decre ases as k increases. This is consistent with the fact that the ambig uity inherent in an ob servation of j samp led packets is lo wer for larger j and disappear s at j = W , since this o bservation can only arise in one way . The dip at very small k we attribute to the influence of the co nstraint. B. P ositive Semidefin ite Comparisons The examples above co mpared metho ds u sing the CRLB of each θ k separately . Let two metho ds ha ve Fisher informa tion J 1 and J 2 . A mo re co mplete, an d in a sense id eal comparison , would be to show that J 1 ≥ J 2 , since that would imply I + 1 ≤ I + 2 , a lower CRLB. What this positive semidefinite compariso n r eally m eans is that for any line ar co mbination f ( θ ) = a T θ = P k a k θ k of the p arameters, the ( bound on the) variance o f f ( θ ) under method 1 will be less than that under method 2. A geometric interpretation is that the ellipsoid correspo nding to unit variance of vectors under J 1 lies entirely within that of J 2 . I n this section we pr ovide a number of compariso ns of this ty pe between m ethods, and explain why it is not suitable as a un iv ersal basis of comp arison. W e first confirm the intuition th at metho ds lose in formatio n monoto nically in the ir samplin g p arameter(s). Theor em 14 : For any method Z sur veyed h ere if p 1 ≥ p 2 (for DS p p, 1 ≥ p p, 2 and p f , 1 ≥ p f , 2 ) th en J Z ( p 1 ) ≥ J Z ( p 2 ) (for DS J Z ( p p, 1 , p f , 1 ) ≥ J Z ( p p, 2 , p f , 2 ) ). E quality h olds if f p 1 = p 2 (for DS ( p p, 1 , p f , 1 ) = ( p p, 2 , p f , 2 ) ). The p roof ( see Ap pendix D) , is a straig htforward co nsequen ce of c losure u nder sam pling fo r all methods e xcept SH. Next, we confirm tha t t he use of sequence num bers in creases Fisher inf ormation . Theor em 15 : J Z + SEQ ≥ J Z for each of Z = PS and Z = PS+SYN. 12 Fig. 6. Comparison of the CRLB bound wit h W = 50 . Left: PPR with p = 0 . 005 . p f = 0 . 001 , p p = 0 . 0052 for DS ( p f < p p ) and p f = 0 . 01 , p p = 0 . 0047 for DS ( p f > p p ). Middle: ESR with p = 0 . 005 . p f = 0 . 032 , p p = 0 . 1 for DS ( p f < p p ) and p f = 0 . 079 , p p = 0 . 001 for DS ( p f > p p ). Right: Zoom of middle plot, the same legen d applies. Pr oo f: W e make use of the data processing in equality (DPI) for Fisher in formatio n (see Theorem 31 in Ap pendix B), which states that if θ → Y → X is a Markov chain, wh ere X is a determin istic function of Y , the n J Y ( θ ) ≥ J X ( θ ) wh ich holds with equality if X is a sufficient statist ic of Y . W e first consider P S+SEQ and P S. Flo ws are selected r andomly and a re represented as a rando m vector of SEQ n umbers V = { A, A + 1 , . . . , A + K − 1 } with realization v = { a, a + 1 , . . . , a + k − 1 } . Here, K represents the flo w size (realizatio n k ) while the A , the initial SEQ n umber (realization a ) is u niform over [0 , N a − 1] . All operations on them are modulo N a , thus allo wing wrap- around s. A is indep endent of K . W e also assume that W ≤ N a to a v oid problems with multiple wrap-a round s. After the PS process, we hav e the SEQ vector Y = { Y i , 1 ≤ i ≤ J } , ( realization y = { y i , 1 ≤ i ≤ j } ). W e define two statistics on Y : J ( Y ) , the actual n umber of raw packets sampled, and L ( Y ) = max i ( Y i ) − min i ( Y i ) + 1 ( with a sample l ( y ) and L ( Y ) = 0 if Y is em pty), the inferred length of th e sequence. Th e statistic L ( Y ) disregards A since it takes th e d ifference of SEQ numbers. Note that both statistics are deterministic function s o f Y an d so form Markov ch ains θ → Y → L ( Y ) and θ → Y → J ( Y ) . A straightf orward application of DPI yields J Y ≥ J L ( Y ) and J Y ≥ J J ( Y ) . W e show that L ( Y ) is a sufficient statistic of Y w .r . t. θ . W e use the Fisher-Neyman factorizatio n th eorem [14, Th eorem 6.5, p . 35] which states that if th e prob ability mass fu nction of Y takes th e fo rm Pr( Y = y ) = h( y )g( l ( y ) , θ ) , (29) where h is independe nt of the parameters θ , the n L ( Y ) is a sufficient st atistic. Let m ≥ 0 den ote the number of unsamp led packets bef ore the first samp led p acket. If J = j > 0 , Pr( Y = y ) = W X k = l θ k k − l X m =0 Pr( A = y 1 − m ) q m p p p ( p j − 2 p q l − j p ) p p q k − l − m p = Pr( A = a ) W X k = l θ k k − l X m =0 q k − j p p j p = 1 N a p j p q − j p W X k = l ( k − l + 1) q k p θ k ! , since A is uniform. For the case j = 0 , Pr( Y = ∅ ) = W X k =1 q k p θ k . Clearly , each case satisfies (29), hence L ( Y ) is a sufficient statistic of θ . By the DPI, since L ( Y ) is a sufficient statistic, J Y = J L ( Y ) . Fr om the previous r elation J Y ≥ J J ( Y ) , we now have J L ( Y ) ≥ J J ( Y ) . But J ( Y ) is equiv alent to the statistic used in PS, proving the result. As for PS+SYN sampling, we define an ad ditional rando m variable S ta king value 1 if the SYN packet was sampled , 0 otherwise. V is defined a s b efore. Y = ∅ if and only if S = 0 . The same statistics L ( Y ) and J ( Y ) ar e defin ed. Then, fo r J = j > 0 , Pr( Y = y ) = W X k = l θ k Pr( A = y 1 ) p p ( p j − 2 p q l − j p ) p p q k − l p = Pr( A = a ) W X k = l θ k q k − j p p j p = 1 N a p j p q − j p W X k = l q k p θ k ! , and for j = 0 , Pr( Y = ∅ ) = W X k =1 q p θ k = q p . Once again, each case satisfies (2 9), hence L ( Y ) is a sufficient statistic. Th us, b y DPI, the same relation ship J L ( Y ) ≥ J J ( Y ) holds, with J ( Y ) now equi valent to the statistic used in PS+SYN. Intuitively this r esult seems obvious: if th e addition al in- formation af forded by the sequence nu mbers is a v ailable, we should certainly be able to do b etter by using it. Ho wev er , it is tempting to co nclude that by the same logic J PS > J PS+SYN under th e PPR normaliza tion, since deciding to discard flo ws without a SYN is also a d eterministic transfo rmation. How- ev er , the data pr ocessing inequa lity does not a pply here because some of the info rmation used b y PS+SYN (namely the SYN variable S ) , although a v ailable to PS, is not used by 13 it. Indeed we sa w in the figures above th at, counterintu iti vely , PS+SYN can actually outper form PS in terms of the individual variances un der PPR, which is a counter-example to the mor e general positive semidefinite com parison. Under ESR th is is ev en more true as we saw from th e mid dle p lot in Figure 6. W e now gi ve another, even more s urprising counter-example which teaches an important lesson. Theor em 16 : J F S 6≥ J P S Pr oo f: Proof is by co ntradiction v ia co unter-example. Let W = 2 with θ 1 = θ 2 = 1 / 2 , and let p p = p f = p . Evaluate 1 T 2 ( J F S − J P S ) 1 2 , (the sum of each element of the m atrix difference), which we expect to be no nnegative by assumption. It can be shown that this reduces to 2 − 2 q (1 + q 2 ) 1 + q − 2 1 + 3 q − 4 q 3 1 + 2 q − q 2 which can b e n egati ve, e .g. when q = 1 / 2 , a co ntradiction . Using Lemma 27(ii) one can show that J F S 6≥ J P S implies J − 1 P S 6≥ J − 1 F S which in turn implies I + F S 6≤ I + P S (see Lemma 26). Since we earlier showed that PS is enormously worse than FS for variances, this result is surprising, p articularly a s experience shows that it is not difficult to find other examples for much larger W . W e c an explain this quand ary as follows. When we focus on the v ariances in isolation we h ighlight the poor per forman ce of PS. Ho wev er , linear combinations such as P k a k θ k bring in cross terms, which for PS are negativ e because of strong ambiguity in its ob servations. Strong cor relations ar e a bad fea ture of a cov ariance matr ix of an estimator, howe ver if they are negative, they can in some cases cancel other positi ve terms resulting in a lower total variance. Hen ce, paradox ically , it is the poor behaviour of PS which pre vents J F S ≥ J P S from h olding. The last example reveals that a ranking o f methods b ased on a p ositi ve semidefin ite com parison, althou gh very d esirable when tru e, is not possible in general. W e the refore turn to a more gener ally applicable appro ach in the next section which we use for the rem ainder of the pap er . C. V ariance Compa risons: a P artial Ranking In this section we f ocus on com paring method s via the diag- onal elements of I + , correspon ding to the optimal variances of θ i estimates, just as in the figures above. As befor e, it is sufficient to co nsider the unco nstrained c ov ariance matrix J − 1 since I + = J − 1 − θ θ T by (15). T o the extent possible, we seek to establish a h ierarchy between m ethods based on diagona l co mparison s. Than ks to Theorem 15, which applies in particular to diago nal elements, we alrea dy h av e the an swer in some cases. W e begin by compar ing PS a nd PS+SYN. The exam ples giv en so far sho wed PS+SYN as enorm ously superior to PS. Howe ver , this is n ot always the case. A coun terexample u nder the PPR norma lization with p = 0 . 05 is g i ven by θ = { θ 1 , θ 1 , θ 3 ≤ k ≤ 10 = θ 1 / 100 } , θ 1 = 0 . 4808 , (30) for which D ≈ 1 . 69 . As seen in Figu re 7, PS outperf orms PS+SYN for θ 9 and θ 10 , but n ot otherw ise. Th is makes sense giv en the bias of PS to ward sampling lar ge flows. For these same parameters PS+SYN outp erforms PS for a ll θ k under ESR. This is typically the case. For example, with the above parameter set, PS+SYN outperf orms PS on a ll sampling rates. While it may be true that PS outperforms PS+SYN under ESR in some rare situations, we believe this is n ot the case, and conjectur e that PS+SYN defeats PS under ESR for a ll θ . For small p , we can prove that this is the case. Theor em 17 : U nder PPR and ESR normalization, for small enoug h p , ( J − 1 PS+SYN ) j j ≤ ( J − 1 PS ) j j for any θ , j = 1 , . . . , W . Fig. 7. PPR comparison between PS and PS+SYN with p p = 0 . 05 for a partic ular distr ibut ion highly s ke wed to small flows. W e now co nsider the above comp arison af ter b oth method s have benefitted fro m the use o f sequ ence nu mbers. Theor em 18 : U nder PPR and ESR normalization, f or every 3 ≤ j ≤ W , ( J − 1 PS+SYN+SEQ ) j j ≤ ( J − 1 PS+SEQ ) j j . For each of j = 1 and 2 co unterexamp les can be fo und for certain θ and p , under both PPR and E SR. For example PS+SEQ has lower v ariance for θ 1 for the parameter set (30) with p = 0 . 0 5 un der b oth PPR an d E SR, a nd f or θ 2 the family θ = { a, 1 − 2 a , a } with a < 0 . 1 gives examples for w ide ranges of p , includin g as p → 0 fo r a sm all enou gh. The counterexam ples occur in atypical situation s where θ 1 or θ 2 are large relative to other θ j , and can b e excluded if these are approp riately co ntrolled. For example if p < 1 / 2 it can be shown that wh en θ 2 /θ 3 < q 2 p , then PS+SEQ is worse under PPR (and hence ESR). Gi ven that PS+SYN+SEQ defeats PS+SEQ except for per haps θ 1 or θ 2 under atypical conditions, in ge neral PS+SYN+SE Q c an b e regard ed as sup erior . The pictu re emerging from the above comp arisons is that PS+SYN+SEQ is clear ly superior to PS and PS+SEQ. Since PS+SYN+SEQ is just a spec ial case of DS, we n ow consider this family in m ore d etail. W e f ocus o n th e E SR n ormalization which, apart from being far mor e important than PPR , is the key to our optimality result in Section VI. The f ollowing is one of our m ain results, a d etailed char acterization of the perfor mance of DS under ESR. I t can be sh own that an analogo us result d oes no t ho ld fo r PPR. Theor em 19 : T he diagona l elements 2 ≤ j ≤ W of J − 1 DS under the ESR normalization are monotonic ally decr easing in 14 p p . The prop erty holds for j = 1 iff the condition θ 2 ≥ D − 1 D θ 1 (1 − θ 1 ) (31) is satisfied. Also, mon otonicity h olds when D = 1 or W = 2 . The above result shows, provided (31) is satisfied, that the variance bounds fo r each θ k under DS dro p as p p increases. It follows that the optimal point p ′ p in the DS family lies at p ′ p = 1 , that is flow sampling ! The superior ity of FS clearly demonstra tes that the problem of inv erting from imperfect sampled flows is so difficult that in the tradeoff between flo w quality and qua ntity , quality wins convincingly . The exception is for θ 1 when (31) fails, in which case the optimal DS lies to the left of p p = 1 . Ho we ver , this only occurs when θ 2 /θ 1 is extremely small, and even then in most cases p ′ p ≈ 1 u nless D is also very large. Con sider the region p p → 1 . By solving for the optimal p ⋆ p using (41), we o btain (provided D > 1 ). p ⋆ p = s θ 2 ( D − 1)[ θ 1 (1 − θ 1 ) − θ 2 ] . (32) For p ⋆ p to be much smaller than 1, we require D to be large and the ratio θ 2 /θ 1 very small (effecti vely , θ 2 being negligible). Such a scenario is very unlikely to occur in networks a nd in any case only affects θ 1 , and so it is rea sonable to assume th at the optimal DS corresponds to FS in practice. Our next result compares the fin al method , SH, again st FS. Theor em 20 : U nder PPR and ESR normalization, f or every 2 ≤ j ≤ W , ( J − 1 FS ) j j ≤ ( J − 1 SH ) j j . For j = 1 the cond ition holds for any θ for p suf ficiently small. Sufficient conditions indepen dent of p are either W = 2 , or for W > 2 , θ 2 ≥ θ 1 (1 − θ 1 ) . (33) The pro of for (33) in volves b ound s which are tight as p → 1 . Hence, when th e condition is violated and p is large enough , SH can indeed ou tperfor m FS f or θ 1 . An example is given in Figu re 8 with W = 6 and p p = 0 . 435 1 , which is large and reason ably close to p = 0 . 5 . Howe ver , this e ffect is difficult to see in distributions with larger W as SH shifts most of its packet budget to larger flows, r esulting in p p being orders of magnitude smaller than p a nd the bounds leading to the sufficient co ndition b ecoming very loose. In all cases of interest therefore, FS can be regarded as superior to SH at all flow sizes. Finally , we clarify the relatio nship between DS and SH more generally . DS is a two par ameter family whose perf ormance varies in a wide range. In deed, Figure 5 already shows that it can perfor m be tter than SH at the ‘FS’ end of its rang e, and worse a t th e other end. The impor tant observation is that in all cases whe re FS ou tperfor ms SH f or a gi ven θ , it follows fro m continuity of the CRLB in ( p p , p f ( p )) that ther e are members of the DS family other than FS which do likewise. Theor em 20 shows that th is is true in almo st all cases un der E SR, allowing us to conclude that in gene ral DS outperform s SH at all flo w sizes. The natural cou nterexample to this general ru le is when (31) is satisfied so that the best DS can do is giv en by FS, and ye t θ is such that SH defea ts FS (fo r θ 1 ), im plying that SH defeats all member s of the DS family fo r θ 1 . Th is ca n occur if (33) is n ot satisfied and p is large. Fu rthermo re there are cases where bo th SH and the optimal DS defeat FS, in which case the compar ison is m ore co mplex. Since h owe ver this battle is c ontained within a very small and u nimpor tant region of ( θ , p, p f ( p )) space, we do no t characterise these counterexam ples fully but instead conc lude with the fo llowing result, which fo r the first tim e exhibits specific DS m embers (other than those in a neig hbou rhood of FS) which d efeat SH. Theor em 21 : U nder ESR normalization with rate p , if 0 ≤ p p, SH ≤ pD − 1 D − 1 , then a su fficient condition for ( J − 1 DS ) j j ≤ ( J − 1 SH ) j j for e very 1 ≤ j ≤ W is that p p, DS satisfies p p, SH ≤ p p, DS . Summary: W e have confirmed that a rank ing of meth ods based on a positive semid efinite comparison is impossible, since e ven a diagon al comp arison does n ot yield a simple hierarchy . Noneth eless, igno ring the cou nterexamples wh ich sometimes occur for the CRLB variance for θ 1 and perhap s θ 2 , a clear overall picture emerges from the co mparisons above. First, fro m Theorem 1 5, the utilization of sequence nu mbers yields consistent infor mation theoretic dividends. In particu lar , PS n eed n ot be considered fu rther since it h as extrem ely poor performance and by The orem 15 PS+SEQ is better . Theorem s 17 and 18 show tha t the use of SYN samp ling as a tech nique to eliminate bias is very powerful, which makes PS+SYN+SEQ the lead ing can didate, an d f ocussed attentio n on its gene ralization, DS. Theorem 19 then shows that DS out-per forms PS +SYN+SEQ u nder the ESR normalizatio n (the most relev a nt o ne for estimation perform ance) provided p p > p ∗ p , and furth ermore that FS is th e fa v ored member of DS. Theo rem 20 sho ws that FS is also superior to SH. In conclusion , FS is the best sampling method for all flow sizes. Fig. 8. PPR and ESR compa rison betwe en FS and SH w ith p = 0 . 5 for a partic ular distr ibut ion highly s ke wed to small flows. 15 This stro ngly mo tiv ates the adoptio n of sampling method s which approach FS as closely as p ossible, b ut which are efficiently implemen table. Th is re focuses atten tion b ack to DS as it enjoys bo th o f these prope rties. V . A N A LY S I S O F T H E S E Q D I V I D E N D The utilization of s equence numb ers pr ovides addition al ‘virtual’ packets f or free. T he extent to wh ich th is improves our information on θ clearly depends o n parameters. For example, flows with only k = 1 o r 2 packets a re not helped at all. Intuitively ( for example, under PS) it is the flows for which k ≫ 1 /p p which will receiv e the most benefit: since on ly the packets bef ore the first and after the last physically samp led packets will no t b e r ecovered using sequenc e numb ers, an d o n av erage there are 2 / p p of these since 1 /p p is the average gap between tw o p hysically sampled packets within a flo w . T o quantify the b enefit of sequ ence n umbers better we define th e ef fective pa ck et gain , which is the r atio r = E [ ˜ N k ] / E [ N k ] , where ˜ N k and N k are th e nu mber of SEQ assisted and unassisted (physical) packets samp led respecti vely from a flow of size k . By definition, R = ˜ N k / N k ≥ 1 and so r ≥ 1 , and asym ptotically the gain satura tes at r = 1 / p p . For DS it can be shown (see [15] for more details) that to obtain a ratio α of this m aximum gain , a flow must have a size o f the order of q p (1+ α ) p p (1 − α ) , sugg esting that flo ws must ha ve a size of roughly 1 / p p or mo re befo re the sequence n umber ‘inform ation dividend’ effecti vely switches on. A lthough intu- iti vely appealing, this is h owe ver quite misleading. There is a high variance associated with the rand om v ariable ˜ N k , which for large flo ws un der PS+SYN+SEQ goes as V ar( ˜ N k ) ≈ 4 p p + k ( k − 2) p p + (2 k − 3) . Therefo re the gain R is not sharply c oncentrate d around its mean and is highly d ependen t on the sampling p arameter . More generally , the sequen ce numb er dividend ‘switch’ is primarily about wh ether at least two packets are sampled. When p is small this is a very rare event, but can nonethe less be responsible for most of the av ailable informa tion abou t flo w size. For example in Figu re 3 th e probability of samp ling two packets is o f the o rder of 10 − 6 , an d yet the ratio o f variance of PS to PS+SEQ is ar ound 400 – even rare dividends ar e worth having! Thus even fo r smaller to m edium sized flows (‘mice’ and ‘r abbits’), the u se of sequence num bers provides a h uge reduction in estimator variance, as shown by numeric al and empirical e vidence thro ugho ut th is p aper . It is inter esting to compare the SEQ dividend with SH, which implements a kind of extreme SE Q e ffect in the sense that if only a single packet is sampled , th en all subsequent ones will be. This is a more powerful ‘switch’ than the SEQ mechanism which requires at least two packets. For large flows howe ver , packets inferred under DS approach this level of packet recovery since , bec ause the SYN packet is sampled , only a geo metric n umber of pa ckets will be missed at the end of the flow , compar ed to a geometric nu mber at the beginn ing under SH. O f co urse, SH ach iev es this solely from its real packet b udget whereas DS does not, which explain s why DS outperf orms SH even in the latter’ s area o f stren gth, n amely very large flows. V I . C O M P U TA T I O N A L I S S U E S A. Optimizing DS with Comp utationa l Constraints From our result o n the monoto nic behaviour of ESR no r- malized DS, what is op timal in ter ms of information is clear: simply move down the ESR constraint curve to FS. Ho wev er , there are other constraints from the resour ce side wh ich will con strain the par ts of the cur ve that will be accessible. The solutio n to the joint in formation /resource optimization problem is th erefore clear: move as far down the ESR cu rve as possible. Our task now is to determ ine those con straints and hence the region in the ( p p , p f ) p lane wh ich is feasible. The b ottlenecks in the imp lementation of any sampling method are the memo ry access time and memory size. CPU processing is included in th e memor y access, since the CPU has to read o ut v alues from m emory during looku p, perfor ming modification s and write-ba cks wh en necessary . These tasks constitute the main portion of what is req uired of the CPU for measurement, as the measurement p rocess is basically all about efficient cou nting [5]. This can b e done for example with a hy brid SRAM-DRAM counter achitectur e [16], [17], [18], where a small amou nt of (fast b ut expensi ve) SRAM is used for th e co unter an d its value p eriodically expor ted to a (cheaper but slo wer) DRAM stor e. W ith abou t 10 ns access time for SRAM, suc h a coun ter can be imp lemented e ven for OC-768 link s wh ich r un at 40 Gbps. W e n ow co nsider how to o ptimize DS based on these constraints. Re garding flo ws, let T max be the maximum flow table size measured in terms of flow reco rds an d λ F be the flow arriv al rate. As for p ackets, let C be the c apacity of the link, P th e size of the smallest packet ( ≈ 4 0 by tes), and τ the access tim e of memor y (nom inally DRAM). Our simple ana lysis o f th e ab ove bottleneck c onstraints is based o n the following. I n terms of pac ket arriv als we assume the worst case, n amely the smallest size p ackets arriving back- to-back at line rate. By b oundin g the processing in such a case we gu arantee that the fro nt line of packet p rocessing (which occurs at the highest speeds) is not unde r-dimensioned. In terms of flow arrivals we assume the ‘average case’ based o n the av erage number o f activ e flo ws. This c an easily be made more conservati ve by replacing the av erage by some q uantile to take into accou nt fluctuation s i n flo w arri v als. F or simplicity , we ignore data export constraints from t he measur ement center to a central data collection center . W e also do not consider rate adapta tion based on the traffic cond ition altho ugh such schemes ar e compatible with DS. Consider the pro cessing of a single packet. The SYN bit is first tes ted to see wh ich sampling param eter will app ly , the cost of this is negligible, and if a packet is not sampled no furth er action is need ed. Now consid er the cost of a packet which is sampled. Each SYN packet wh ich is sampled is inserted into the flow table. No prior looku p is n ecessary since it must be the first packet of its flow . E ach n on-SYN p acket which is sampled must first perfor m a lookup of its flo w-ID in the flo w table to see if th at flow is being tracked. I f not it is discard ed. 16 The cost of this wasteful per packet imp lementation o f the ‘flow discarding ’ step (inherent to any SYN based m ethod such as DS) is n ot the bo ttleneck because th e follo wing case is the most expensiv e of a ll and is the one we model: a non - SYN packet which is sam pled and whose flow is bein g tracked requires b oth a looku p followed by an upd ate. Using th e above, the constraints are p f ≤ b p f = min ( T max D λ F , P τ C ) , p p ≤ b p p = P 2 τ C . (34) The constraint T max / ( D λ F ) ensures that the a verage number D λ F of active flo ws does n ot exceed the flow table size. Constraint P / ( τ C ) provides the worst case b ound fo r per packet proce ssing, for a single operation (insert or update) . Th e factor of 2 th at app ears in th e de nominato r for b p p is to accou nt for the worst case, in which a looku p and upd ate is need ed. The a nalysis is based on th e use of a single per flo w co unter to tra ck flow size. In pr actice, there may b e mo re coun ters needed to tr ack other quantities of interest, n ecessitating tighter constraints. In the seque l, our examples consider traf fic m ixes that ha ve manageab le numbers of SYN packets, so that from (34), b p f = T max / ( D λ F ) . This is done mainly to illustrate the relationship betwe en the CRLB and parameter p f . Inde ed, at lower link speed s (OC-48 f or example) , p f is determ ined by the number of flo ws arriving at the measurem ent poin t, rather than packet proce ssing time. Secondly , to in crease accuracy , from the pr evious discussions, w e would like p f < p p , i.e. fe wer , but better quality sampled flo ws. The constraints form a simple region on the ( p p , p f ) plane that is conve x, since it is rectangu lar with a corner at the origin. W e want to minimize th e variance fo r each θ k subject to the se constraints. Since the ESR curve is con vex with respect to p f and p p , the optimal value must lie on the vertex of the conv ex co nstraint set [19, Corollary 32. 3.1, p. 3 44]. For this to hold, we require th at the optimum f or θ k on the ESR curve (Section IV - C) is o utside th e con strained region . This will be the case fo r all k fo r any reasonab le traf fic mix. Under such condition s, the solu tion is therefor e p f = b p f and p p = b p p . W e then h av e a relation ship b etween th e flow ta ble size and link capac ity and th e diagon al elem ents of J − 1 DS . Since it is apparen t from (26) that the diagonals are domin ated by 1 /p f , by substituting the op timal solution, we hav e for 1 ≤ j ≤ W , ( J − 1 DS ) j j = O ( 1 b p f ) = O ( 1 T max ) . Thus, with a larger table size (i.e. more m emory available), variance of th e estimator can be red uced. As for the relation to capacity , we assum e that C is large and use th e approximation b q p ≈ 1 . This can be ju stified con- sidering that sam pling is r equired beyond OC-3 link speeds. The d iagonals b ecome ( J − 1 DS ) 11 = θ 1 (1 − θ 1 ) b p f + 1 b p f b p p W X k =2 θ k + θ 2 1 ( J − 1 DS ) j j = θ j (1 − b p p θ j ) b p f b p p + 1 b p f b p p W X k = j +1 2 θ k + θ 2 j ( J − 1 DS ) W W = θ W b p f b p p − 1 b p f θ 2 W + θ 2 W which are appr oximately in versely prop ortional to b p p , and hence ar e O ( C ) . W e conclud e that th e variance o f DS is in versely prop ortional to memor y usage and propo rtional to the link capacity . As an example, consider an OC-19 2 link with Dλ F = 1 × 10 6 flows/s ec, T max = 100 , 000 and an access time of 100 ns for DRAM. L et us assume a further 100 ns is required for further processes (e.g. sequence numb er info rmation). Thu s, b p f = 0 . 1 and b p p = 0 . 08 . W ith o ur n umerical ev aluation on the Leipzig -II trace (d iscussed in the following section), th is would imp ly that the trace contain at least 9 . 5 × 10 8 original flows in to ach iev e a standard deviation of 1 0 − 8 or better . If we comp are th is to PS w ith a sampling rate of p p = 0 . 1 , we req uire a stagge ring 5 . 6 × 10 44 flows to achieve the same perfor mance! T o o bserve the depen dence o n memory and link ca pacity , now consider an OC-768 link instead with T max = 10 , 000 . This tim e, we have b p f = 0 . 01 an d b p p = 0 . 02 . T he nu mber of flows required to achie ve the same stand ard deviation now increases to 8 . 8 × 1 0 9 which is still orders of m agnitude better than PS. If we consider the SRAM-DRAM arc hitecture discussed earlier, with state-of-th e-art SRAM having access times of about 5 -10 ns, th is can only increase the v alue of b p p . Id eally , we still keep p f low to reduce the nu mber of flow entries while increasing p p to ap proach FS perf ormance. Con tinuing o n from the previous examp le of the OC-192 link and assumin g τ = 5 ns, b p p can now app roach 1. For th e OC-768 example, b p f = 0 . 01 while b p p = 0 . 8 , gi ving hug e pe rforman ce gains. B. Other Issues Checking for the SYN bit can b e done in a simple way by testing the paylo ad type in the IP h eader and then verifyin g the presence o f the SYN b it. This takes m uch less effort than d eep packet inspectio n systems. Furthermo re, sam pling d ecisions can be implemen ted u sing pr ecalculated values, much faster than a straight random nu mber gener ator implem entation. W e ad dress th e problem of flow table overload b y u sing the metho d proposed by Estan et al. [20] by d efining discrete measuremen t time bins, where sampled flows are exported at the end of each time bin. Consequently , overload of th e flo w table can be a v oided at the cost of increased e xport r ate. V I I . C A S E S T U DY O N I N T E R N E T D A TA In this section we te st the p erform ance of DS on tw o traf fic traces u nder the ESR normalization, a nd co mpare it to FS and its closest competitor, SH. W e also further examin e the 17 benefit of sequen ce numbers both in a fully empirical setting, and an idealised one. Since we work with r eal data, we require an unbiased estimato r f or each meth od. W e propose closed-for m estimators tha t ach iev e the CRLB asymp totically . W e test their statistical performance b y examining how clo se they app roach th e empirical CRLB on the traces we used. In general, the empirical results m atch th e theoretical o nes fr om earlier sectio ns well. A. Data T r aces W e used two publicly a vailable n etwork traces, Leipzig - II [2 1] and Abilene-III [22], which are each co llections of anonymized packet head ers passing th rough a single router . Since the raw tra ffic is a t packet level, specialized software such as CoralReef [23] are required to r econstruct flo ws. W e modified th e software so that o nly TCP flo ws were analyzed. Summary statistics of these traces ap pear in T able II I. Both traces are unidirectional, presentin g problem s wh en construct- ing a sequenc e numbe r functio n, as elaborated later . There are many flows wh ose SYN packet is missing as they began before the me asurement interval. T o b e con sistent with our model assumptions, w e remove these. A similar situation was encoun tered in [1]. Fortunately , such flows are in the minority , f or example with Leipz ig-II they acco unt fo r only 18%. Furth ermore, when sam pling the trace , we assum e an infinite timeou t, th at is, flows are expired at the end of the measuremen t interval. T his is in accordance with the fact that we do not consider flo w splitting. In practice, timeouts would split a flow , resulting underestimation o f flow size. Note th at some flows may be m alformed an d have one or more SYN p ackets within the flow . Po tentially , DS may sample one of these packets a nd treat it as a new flow , instead of part of a long er one. Howe ver , such cases are rare. In Leipzig-II , there are on ly 468 o f such flows, or ≈ 0 . 0 2% , and there a re none in Abilene-I II. These flo ws wer e left in the trace. T race Link Capacity Activ e TCP Flows Duration (hh:mm:ss) D Leipzig-I I 50 Mbps 2 ,277,052 02:46: 01 19.76 Abilene -III 10 G bps 23,806,285 00:59:49 16.12 T ABLE III S U M M A RY O F T H E T R A C E S U S E D The value o f D in T able III is the actual a verage flo w size. In o ur e xperimen ts, we truncate Leip zig-II to W = 1 000 an d Abilene-II I to W = 20 00 , resulting in D being 1.94 and 7.65 packets for eac h trace re spectiv ely . Truncation is perfo rmed by discardin g all flows with size ab ove W , which ensur es that the assumption θ k > 0 , k = 1 , 2 , . . . , W is met. B. Closed-F orm Unb iased Estimators The analy sis of ear lier sections we re centered on the CRLB, which bo unds what is ac hiev able by any un biased estimator, but it is neithe r a constructio n of such an estimator no r ev en a proo f of its existence. When working with real data an actu al estima tor is required, id eally o ne that achieves the p reviously computed CRLB. The m aximum likelihood Fig. 9. Comparison of DS on Leipzig-I I, using W = 10 00 and varyi ng paramete rs under ESR normalizat ion with p = 0 . 01 . Fig. 10. C omparison of DS on Leipzi g-II, usin g W = 1000 and va rying paramete rs under ESR normalizat ion with p = 0 . 001 . estimator (MLE) is an attractive candida te as it is asympto t- ically efficient , guar anteeing that its perform ance appro aches the CRLB asym ptotically [24]. However , the MLE, althou gh unbiased asym ptotically , is in general biased, especially in the small sample regime. W e pro pose the fo llowing estimator for FS and DS (o r other SYN b ased m ethods such as PS+SYN): ˆ θ = ˜ B − 1 N f [ M ′ 1 , M ′ 2 , . . . , M ′ W ] T . (35) This estimato r h as a natural interpr etation as an emp irical histogram based on o bserved sampled flow co unts, inverted by ˜ B − 1 to th e origin al flow distribution. It is easy see that it is unb iased since E [ ˆ θ ] = ˜ B − 1 ˜ B θ = θ . Th e m atrix ˜ B − 1 can b e co mputed explicitly for th ese methods, as shown in Section I II. Our estimator is fu rther motiv a ted by its relation to the MLE, as we no w sho w (all proofs are deferr ed to Append ix E). 18 Fig. 11. Comparison of DS on Abilene- III, using W = 2000 and v arying paramete rs under ESR normalizat ion with p = 0 . 005 . Theor em 22 : I f the sampling matrix of a metho d satisfies b 0 = q 1 W , then the MLE is ˆ θ = ˜ B − 1 p P W j =1 M ′ j [ M ′ 1 , M ′ 2 , . . . , M ′ W ] T ! . (36) By rewriting P W j =1 M ′ j as N f (1 − M ′ 0 / N f ) and observ ing that M ′ 0 / N f conv erges to q with high probability (th is follows from Hoe ffding’ s inequality [25, p . 303]) , the MLE (36) tends to our estimato r (35), wh ich theref ore ap proach es the CRLB asymptotically . Our prop osed estimator only obeys the co nstraint 1 T W ˆ θ = 1 on av erage, wh ile t he e stimator in T heorem 22 always obeys the constraint. (Note that (36) remains a v iable estimator in the cond itional framew ork, see Remark 32 in Appendix E.) Fig. 12. Comparison of FS, SH ( p r = 0 . 0002 ) and DS ( p f = 0 . 0117 , p p = 0 . 7 ) on L eipzig -II, using W = 1000 and v arying parame ters under ESR normalization with p = 0 . 01 . The f ollowing applies to SH. Theor em 23 : T he ML E for SH is given by ˆ θ SH = ˜ B − 1 SH N f · [ p ( M ′ 0 + M ′ 1 ) , M ′ 2 , . . . , M ′ W ] T . (37) This tim e th e MLE is un biased (see App endix E), so we use it directly on the d ata. It closely resembles the estimator (35), with a slight difference: fo r the e stimate of θ 1 , the number of missing flo ws M ′ 0 plays a significant r ole. Th is can be interpreted as f ollows. Since SH work s by geome trically skipping the first few packets in a flow , flows of size 1 a re those most likely to ha ve b een entirely missed. Hen ce, the simplest way to incorpo rate a knowledge of M ′ 0 is to assume that it arises solely from evaporated flows o riginally of size 1 . The ad vantage of simple closed f orm estima tors such as these, which o nly req uire a matrix multiplication, is th at they eliminate the n eed for iterative estimation a lgorithms suc h as Exp ectation-Max imization (EM), often em ployed in the literature [1], [4], [8]. Fro m a computational viewpoint, this is highly ad vantageous. C. T esting with a P erfect Sequence Numbe r Functio n W e begin o ur ca se study by testing DS with a p erfect sequence numb er f unction, which retu rns the exact number of packets between tw o sampled packets. As we hav e access to the or iginal u nsampled flows, th is is easily evaluated. Apart from being a benchmar k for sequence numb er functions that may b e d esigned in the future, a per fect fun ction allows clean compariso ns between alternative m ethods emp loying sequence number s to be made. In Figure 9, for an E SR o f p = 0 . 0 1 , values o f p p from p p = 1 (equ i valent to FS) stead ily d ecreasing to p p = 0 . 001 are sho wn (DS with p f = p p = 0 . 019 correspo nds to PS+SYN+SEQ). As p p → 1 the perfo rmance vastly impr oves. Similar results were o bserved in Figure 10, wher e p = 0 . 0 01 . Fig. 13. Comparison of FS, SH ( p r = 0 . 00018 ) and DS ( p f = 0 . 0134 , p p = 0 . 7 ) on Abil ene-III, using W = 1000 and varying paramete rs und er ESR normalization with p = 0 . 01 . 19 Fig. 14. C omparison of DS on Leipzi g-II, usin g W = 1000 and va rying paramete rs under E SR normalizatio n with p = 0 . 01 . An imper fect sequence number function is used here. Fig. 15. C omparison of DS on Leipzi g-II, usin g W = 1000 and va rying paramete rs under E SR normalizati on with p = 0 . 001 . An imperfect sequence number function is used here. In all cases, a chron ic lack of samples at the tail end of the distribution causes inaccur ate estimates, with zero samples showing as disco ntinuities. FS holds to the tru e d istribution the longe st, as we expect, and the best DS performs similarly to it. W ith a mu ch larger sample set in Figur e 11, we can see better ag reement between th e estima tes and the or iginal distribution. W e also tested SH, as seen in Figures 12 and 13. T o simplify the com parison across the traces, we tr uncate each to W = 1000 , so that D becomes 1. 94 an d 6.4 5 packets f or Leipzig-II and Ab ilene-III respectively , an d use th e sam e ESR v alue p = 0 . 01 . In both cases the perform ance is much worse for SH than DS, which track s FS and the true distribution well. I n Le ipzig- II the perfor mance is very poor almost ev erywhere , while in Abilene-II I the front end of the distribution, u p to a bout flows of size 8 , is estimated qu ite well, befo re d eteriorating badly Fig. 16. Comparison of DS on Abilene- III, using W = 2000 and v arying paramete rs under E SR normalizati on with p = 0 . 005 . An imperfect seque nce number function is used here. Fig. 17. Benefit s of using sequence numbers. Three cases are shown: PERFECT uses a perfect sequence number function, MAPPING uses an imperfect function and SEQ OFF uses no sequence number information. at lar ger sizes. The good p erform ance of SH at j = 1 can be attributed to th e fact that this event is do minated by the sheer number of original flows o f size one. Both FS and DS track s the distrib ution m uch b etter since both method s have samp led flows of f ar sup erior qu ality to SH. D. T esting with an Imperfect Seq uence Numb er Fun ction W e now test DS with an impe rfect sequen ce numb er func - tion. Our functio n is similar to that ou tlined in [4]. Ho we ver , as we do not ha ve statistics of popular TCP payload sizes av a ilable, we infer the most likely pay load size as follows. If the seq uence numb er difference is divisible by a p opular payload size (for example, 1 460 bytes), we take this as the most likely payload size. Other wise, we use the average payload size. This fun ction is subject to err ors, esp ecially when a flow has v ariable pa yloads, howev er it suffices fo r 20 our purposes. In addition to T CP sequence numb ers, we exploit IPID num - bers. As mentioned in [4], the IPID field of Lin ux machines is incr emented sequentially fo r each TCP flow every time a packet in the flow is tr ansmitted. Given that the ma jority of web-servers on the Internet are Linux -based, we exploit IPI D number s to check the accuracy o f our estimate when a flow has packets with v ariable paylo ads. Furthermo re, the unid irectional nature o f the trace presents a significan t challenge. As one side in a TCP conn ection usually transmits more d ata than th e other , som e sampled flows may con sist mainly o f TCP ACK packets, which means that they will have z ero-by te TCP payloads. In this case sequence number s may not be incremented at all, and so will not provide informa tion abou t th e num ber o f bytes tran smitted. A solution is to use the T CP acknowledgement numbers instead to inf er the n umber of bytes tr ansmitted fr om the oppo site direction, which would yield an estimate of the number o f packets in the TCP A CK flow . This may n ot b e the most id eal solutio n, as this metho d would be susceptible to delayed ACKs, thus undere stimating the size of the flow . Modern web b rowsers rely on maintainin g TCP conn ections rather than initiating new co nnection s, whic h r equire mor e memory . This is the p ersistent HTTP protoc ol. The pr ev a lence of this pro tocol amo ngst web browsers presents a challen ge, since empty p ayload packets are perio dically sent to keep the connectio n ali ve. Th ese packets do n ot increm ent the sequ ence number . The best we can do in such cases is to infer using IPID number s, or possibly cou nting A CK packets coming in from the other direction , if bidirectional inf ormation is a vailable. Even with the imperfect and relatively simple sequence number functio n used here, results are consistent with theory . Figures 1 4 an d 1 5 illustrate this. I n bo th cases, the imper fec- tion of th e function affects th e accur acy of DS, b ut not to a large degree. A similar ob servation applies to the Abilene - III trace, shown in Figu re 16, where the artifacts due to the imperfect f unction (the sawtooth p attern) are clearly seen. Finally , Figure 17 illustrates the effect of using sequen ce number s in recovering the flow size d istribution. The three cases shown are for DS with parameter s p f = 0 . 00 117 and p p = 0 . 7 , with an E SR of p = 0 . 01 . The PERFECT case is wh en DS is given a perfect sequence n umber fun ction, MAPPING when using o ur sequence num ber function, and SEQ O FF when no sequence n umber s were u sed at all. It is a pparent that using seq uence numb ers, even with an imperfect function, provid es sign ificantly more info rmation to an estimato r . E. Empirical estimato r v ariance Here, we see how closely the estimator variance match es the CRLB b y computing the observed F isher information [26] of the estimato r in Figure 18. T o improve readab ility , smoothing was ap plied to th e tail end of the observed Fisher informa tion where samples are scarse using a simple moving av erage filter with a w indow size of 10 0. Even when using an imper fect sequen ce nu mber f unction, the variance of th e estimator closely m atches the CRLB, effecti vely proving the benefit of sequence numbers. Fig. 18. CRLB versus observe d ML E vari ance of DS with p f = 0 . 00625 , p p = 0 . 6 on Abil ene-III. V I I I . C O N C L U S I O N S A N D F U T U R E W O R K W e have re-examined the qu estion of sampling for flow size estimation in the context of TCP flo ws from a theo retical point of view . W e used the Fisher infor mation to examin e th e inherent p otential of a number of sampling methods. Most of these had been examined previously , b ut we showed how the usual condition al framework can be made u nconditio nal and thereby simplified, wh ich a ctually changes the sampling methods them selves and their p erforma nce. The new frame- work led to a numb er of new rigor ous r esults regard ing the perfor mance of sampling methods which we stud ied under two dif ferent normalizations. It a lso enabled flo w sampling to be comp ared to methods usin g TCP sequ ence nu mbers and Sample and Hold for the first time, and we showed that it is far superior to them, excep t in very special cases which ar e not im portant f or n etwork measure ment app lications. W e intro duced a new two parameter family of meth ods, Dual Sampling, which allows the statistical b enefits of flow sampling to be traded off ag ainst the computationa l advantages of p acket samplin g. W e discussed how , as an unb iased ‘Hold and Sample’ metho d, it differs fro m Sample and Hold , an d proved that it is super ior to it. W e argue that the schem e is implementab le and offers an efficient way of ap proachin g flow sampling in practice to the exten t possible. W e also p roposed closed-for m unbiased estimato rs for SYN-based methods and SH which asymptotically achieve the CRLB, saving compu- tational tim e in the estimation stage. W e per formed a case study of Dual Sampling and Sample and Hold on t wo I nternet da ta traces using ou r pr oposed estimators, and fou nd results entirely consistent with the theoretical p redictions, d espite th e fact th at the fu nction wh ich maps sequence num bers to p acket counts introduces a new source o f err or , and was not highly op timized. Althou gh there is high v ariation at the tail end of the distribution, our prop osed estimator closely matches the CRLB. In fu ture work, we inten d to search over th e spac e of all possible s ampling matrices to fin d an optimal s ampling method 21 for flo w size estimation, and to co mpare it to flow sampling. Our framework is ap plicable to o ther traffic m etrics such as anomaly detection and a future d irection is to extend the work to those areas. It would also be of interest to improve the sequence nu mber map ping fun ction, and also to explor e u sing our appro ach for the direct estimation of the b yte size of flows, for which sequ ence numbe rs are more natu rally suited, rather than the p acket size. Finally , we will d ev elop a more detailed case for DS and its implementability in high speed router s. A P P E N D I X A O U R M AT R I X L E M M A S A. General Lemma 2 4: The matrix ˜ J ( θ ) and its inverse ˜ J ( θ ) − 1 are symmetric and positive definite. Pr oo f: For simplicity we om it the θ depe ndencies. Recall that ˜ J = ˜ B T ˜ D ˜ B where ˜ D is a real diagon al positive d efinite matrix with ( ˜ D ) j j = d − 1 j and rank( ˜ D ) = W . Matrix ˜ B is a W × W m atrix and rank( ˜ B ) = W . It follows that an inverse exists f or both ˜ D and ˜ B . Hence, an in verse also exists for ˜ J since ˜ J − 1 = ˜ B − 1 ˜ D − 1 ( ˜ B T ) − 1 . An equiv alen t expression for ˜ J is ˜ J = ˜ B T ˜ D 1 / 2 ˜ D 1 / 2 ˜ B = ( ˜ D 1 / 2 ˜ B ) T ( ˜ D 1 / 2 ˜ B ) (38) since ˜ D 1 / 2 is symmetric. W e can no w show that ˜ J is symmetr ic. W e have ˜ J T = [( ˜ D 1 / 2 ˜ B ) T ( ˜ D 1 / 2 ˜ B )] T = ( ˜ D 1 / 2 ˜ B ) T ( ˜ D 1 / 2 ˜ B ) = ˜ J . The for m ( ˜ D 1 / 2 ˜ B ) T ( ˜ D 1 / 2 ˜ B ) is at least positi ve semid efinite (Theor em 28). Howe ver, since ˜ J − 1 = ˜ B − 1 ˜ D − 1 ( ˜ B T ) − 1 , ˜ J is in vertible, it is a lso positive definite. By definition o f symm et- ric, p ositiv e definite ma trices, its in verse is also symmetric, positive definite. Lemma 2 5: The un constrained Fisher info rmation matrix J ( θ ) and its in verse J ( θ ) − 1 are symmetric and positive definite. Pr oo f: Recall that J = B T DB where D is a real diagonal positive definite matrix with ( D ) j j = d − 1 j − 1 and rank( D ) = W + 1 . Matrix B is a ( W + 1) × W matrix a nd rank( B ) = W . An equiv alen t expression for J is J = B T D 1 / 2 D 1 / 2 B = ( D 1 / 2 B ) T ( D 1 / 2 B ) since D 1 / 2 is symmetric. Now J T = [( D 1 / 2 B ) T ( D 1 / 2 B )] T = ( D 1 / 2 B ) T ( D 1 / 2 B ) = J . From Th eorem 28, ( D 1 / 2 B ) T ( D 1 / 2 B ) is positive semid efi- nite. Moreover , J is invertible b y Proposition 2, implying it is positive d efinite. By d efinition of symmetric, positive definite matrices, its inv erse is also sy mmetric and positive definite. Lemma 2 6: J 1 ≥ J 2 if and only if I + 1 ≤ I + 2 . Pr oo f: Since by Lemma 27(ii), J 1 ≥ J 2 iff J − 1 1 ≤ J − 1 2 , then by definition of positive semidefinite m atrices, x T J − 1 1 x ≤ x T J − 1 2 x . Hen ce, this implies x T ( J − 1 1 − θ θ T ) x ≤ x T ( J − 1 2 − θ θ T ) x , implying J 1 ≥ J 2 . B. Pr oo f of Theor em 4 Let E = (1 /d 0 ) b 0 b T 0 from ( 10). I t has rank 1 an d is there- fore p ositiv e semid efinite since its eigenv a lues are tr ( E ) = P W k =1 b 2 0 k /d 0 with multiplicity 1 and 0 with multiplicity W − 1 . It fo llows fro m Lemma 29 that J ( θ ) ≥ ˜ J ( θ ) sin ce J ( θ ) = E + ˜ J ( θ ) , and fr om Le mma 27, this imp lies tha t ˜ J − 1 ( θ ) − J − 1 ( θ ) ≥ 0 W × W and therefo re J − 1 ( θ ) ≤ ˜ J − 1 ( θ ) . Equality can only hold if f E = 0 W × W since this is the only case where all eigen values of E are zero . T his implies that b 0 = 0 W × 1 is requ ired for equality , tha t is that no flo w can ‘ev aporate’. A P P E N D I X B O T H E R M A T R I X L E M M A S W e collec t some useful results required in this p aper here. This first result comes from [12]. Lemma 2 7: Let A b e a n × n symm etric positiv e definite matrix and B an n × n positive definite matrix. Then (i) If B − A is positive definite, th en so is A − 1 − B − 1 , (ii) If B − A is sy mmetric a nd po siti ve sem idefinite (imply - ing B is symmetric), then A − 1 − B − 1 ≥ 0 . The following th eorem appears in [27, Theorem 6.3, p . 161]. Lemma 2 8: The f ollowing statements ar e equ i valent: (i) A is po siti ve semidefinite; (ii) A = B ∗ B for some m atrix B , where B ∗ is the conjuga te transpose o f B . The following result gives mo re properties of positi ve semidef- inite matr ices [ 27, Th eorem 6 .5, p . 16 6]. Lemma 2 9: Let A ≥ 0 and B ≥ 0 have same size. Then (i) A + B ≥ B , (ii) A 1 / 2 BA 1 / 2 ≥ 0 , (iii) tr ( AB ) ≤ tr ( A ) tr ( B ) , (iv) the eig en values of AB are a ll n onnegative. The matrix in version lemma (also known as W ood bury’ s formu la) can be found in [12, Theorem 1 8.2.8, p. 424]. Lemma 3 0 (Ma trix I n version Lemma): Let R be a n × n matrix, S a n × m matrix, T a m × m matr ix, and U a m × n matrix. Sup pose th at R and T are nonsingular . Then, ( R + STU ) − 1 = R − 1 − R − 1 S ( T − 1 + UR − 1 S ) − 1 UR − 1 . The da ta proc essing inequality fo r Fisher informatio n f rom [28] is as follows. Theor em 31 : I f Θ → Y → X satisfies a relation of the form f ( y , x | Θ) = f Θ ( y ) f ( x | y ) (i.e. the cond itional distribu- tion of X gi ven Y is independen t of Θ ), then J X (Θ) ≤ J Y (Θ) with the deterministic version being J γ ( Y ) (Θ) ≤ J Y (Θ) . Equality holds if γ ( Y ) is a su fficient statistic relativ e to the family f Θ ( y ) , i.e. Θ → γ ( Y ) → Y fo rms a Markov chain. A P P E N D I X C S A M P L I N G M E T H O D S A. Pr oo f of equation (17) Expand ing (1 + ( − 1 )) k leads to the useful identity k X ℓ =1 ( − 1) k − ℓ k ℓ = ( − 1) k − 1 . (39) 22 Using (12) and b ′ j k = ( − 1) k − j k j q k − j p p − k p for PS, we have ( J − 1 ) j j = W X k = j k j 2 q 2( k − j ) p p − 2 k p d k − P W k = j P k ℓ =1 ( − 1) 2 k − j − ℓ k j k ℓ q 2 k − j p p − 2 k p d k 2 d 0 + P W k =1 d k q k p p − k p P k ℓ =1 ( − 1) k − ℓ k ℓ 2 . The d enomin ator can b e simplified as follo ws: d 0 + W X k =1 d k q k p p − k p k X ℓ =1 ( − 1) k − ℓ k ℓ 2 = d 0 + W X k =1 d k q 2 k p p − 2 k p k X ℓ =1 ( − 1) k − ℓ k ℓ 2 = d 0 + W X k =1 ( − 1) 2 k − 2 d k q 2 k p p − 2 k p = W X k =0 q 2 k p p − 2 k p d k , where we used identity (3 9) in the secon d line . Similarly , the nume rator can be simplified: W X k = j k X ℓ =1 ( − 1) 2 k − j − ℓ k j k ℓ q 2 k − j p p − 2 k p d k 2 = W X k = j d k k j ( − 1) k − j q 2 k − j p p − 2 k p k X ℓ =1 ( − 1) k − ℓ k ℓ 2 = W X k = j d k k j ( − 1) k − j q 2 k − j p p − 2 k p ( − 1) k − 1 2 = W X k = j ( − 1) 2 k − j − 1 d k k j q 2 k − j p p − 2 k p 2 , where (39) is used in the th ird line . This proves (17). A P P E N D I X D C O M PA R I S O N S A. Pr oo f of Theor em 14 Let Z denote any m ethod except SH, and Y the complete outcome (i.e. the vector of SEQ numb ers and the SYN variable in the richest case) of samplin g with Z usin g p arameter p 1 (for DS ( p p, 1 , p f , 1 ) ). Now samp le Y using Z with par ameter p 2 /p 1 to form X (for DS ( p p, 2 /p p, 1 , p f , 2 /p f , 1 ) ). Since X is a function o nly of Y and the new sampling, th e DPI for Fisher applies (Th eorem 3 1) (an d X ⊆ Y ). Fu rthermo re, it is easy to see that X is statistically equiv alent to the outcome of sampling the o riginal data using Z with probab ility p 1 ( p 2 /p 1 ) = p 2 (for DS ( p p, 1 ( p p, 2 /p p, 1 ) , p f , 1 ( p f , 2 /p f , 1 )) = ( p p, 2 , p f , 2 ) ). It follows that J Z ( p 1 ) ≥ J Z ( p 2 ) . Equality ho lds iff p 2 = p 1 (for DS p p, 1 = p p, 2 and p f , 1 = p f , 2 ) implyin g X = Y , since sampling inhe rently discards information. The above p roof does no t apply to SH as it do es not have a clo sure prope rty , meaning that X is no t equivalent to applying SH with some p p . W e tu rn instead to a d irect method, exploiting the tridiagonal stru cture of J − 1 SH . Denote ( J − 1 SH ) ij = a i,j , an d con sider the quadratic for m x T J − 1 SH x for any n on-zero vector x ∈ R W : x T J − 1 SH x = ( a 1 , 1 + a 1 , 2 ) x 2 1 + ( a W ,W + a W − 1 ,W ) x 2 W + W − 1 X j =2 ( a j,j + a j − 1 ,j + a j,j +1 ) x 2 j (40) + W X j =1 ( − a j,j +1 )( x j − x j +1 ) 2 . From Lemma 5 we kn ow J − 1 1 W = θ . It fo llows that ( a 1 , 1 + a 1 , 2 ) = θ 1 ( a j,j + a j − 1 ,j − a j,j +1 ) = θ j , j = 2 , . . . , W − 1 ( a W ,W + a W − 1 ,W ) = θ W which ar e eac h inde pendent o f p p . Con sider then the term in volving − a j,j +1 = p − 2 p q p d j +1 = 1 p p P W k = j +1 q k − j p θ k , 1 ≤ j < W . Differentiating with respect with p p , we obtain − 1 p 2 p W X k = j +1 q k − j p θ k − 1 p p W X k = j +1 ( k − j ) q k − j − 1 p θ k . Since this is n egati ve, it follows that x T J − 1 SH x decreases monoto nically in p p , and so J − 1 SH ( p 1 ) ≤ J − 1 SH ( p 2 ) for any p 1 ≥ p 2 . Th e result then follo ws by Lemma 2 7(ii). B. Pr oo f of Theor em 17 W e first conside r PPR norm alization, where p p = p for both methods. Recall from (17) that ( J − 1 PS ) j j = W X k = j k j 2 q 2( k − j ) p − 2 k d k, PS − P W k = j ( − 1) 2 k − j − 1 d k, PS k j q 2 k − j p − 2 k 2 P W k =0 q 2 k p − 2 k d k, PS ≥ W X k = j k j 2 q 2( k − j ) p − 2 k d k, PS | {z } T 1 − q − 2 j ( W − j + 1) W ! where the lo wer b ound follo ws b y , in the second term, drop- ping the first j terms in th e den ominato r an d upp er boundin g k j by W ! . Also, from (18), ( J − 1 PS+SYN ) j j = W X k = j k − 1 j − 1 2 q 2( k − j ) p − 2 k d k, PS+SYN | {z } T 2 − q p θ 2 j . Since k j = k − 1 j − 1 + k − 1 j ≥ k − 1 j − 1 , d j, PS ≥ W X k = j k − 1 j − 1 p j q k − j θ k = d j, PS+SYN , implying that T 1 ≥ T 2 . 23 Now under the limit p → 0 , for j ≥ 1 , the second term for PS become s − ( W − j + 1 ) W ! wh ich is finite, whereas for PS+SYN, − q p θ 2 j ≈ − 1 p θ 2 j → − ∞ . It fo llows that ( J − 1 PS+SYN ) j j ≤ ( J − 1 PS ) j j . Since p p > p for PS+SYN under ESR, the result also ho lds for ESR b y Th eorem 1 4. C. Pr oo f of Theor em 18 W e begin by examinin g th e simplest case, where j = W . W e have ( J − 1 PS+SEQ ) W W = θ W p 2 p and ( J − 1 PS+SYN+SEQ ) W W = θ W p 2 p − q p p p θ 2 W , and so ( J − 1 PS+SYN+SEQ ) W W ≤ ( J − 1 PS+SEQ ) W W under PPR. Now consider the case 3 ≤ j ≤ W − 1 . Let d Q,j and d S Q,j be the propo rtion o f sampled flows of size j after sam pling by PS+SEQ and PS+SYN+SEQ r espectively . For j ≥ 1 , a straightfor ward comparison would yield d Q,j ≥ d S Q,j . Intu- iti vely , since mor e flows are discard ed in the PS+SYN+SEQ scheme, the pro portion o f sam pled flows must be less th an the propo rtions of PS+SEQ. Th erefore, expr essing th e diagonals in terms of d Q,j and d S Q,j , we have for 3 ≤ j ≤ W − 1 , ( J − 1 PS+SEQ ) j j = p − 4 p d Q,j + 4 q 2 p p − 4 p d Q,j +1 + q 4 p p − 4 p d Q,j +2 and ( J − 1 PS+SYN+SEQ ) j j = p − 4 p d S Q,j + q 2 p p − 4 p d S Q,j +1 − q p p − 1 p θ 2 j ≤ p − 4 p d S Q,j + q 2 p p − 4 p d S Q,j +1 , which, by a direct com parison, shows ( J − 1 PS+SYN+SEQ ) j j ≤ ( J − 1 PS+SEQ ) j j . Similarly , the ESR compa rison follows since the sampling rate fo r PS+SYN+SE Q must increase, thereby reducing its CRLB. D. Pr oof of The or em 19 First co nsider the simplest case, j = W . By substituting (27) into ( 26) and then differentiating w .r .t p p d dp p ( J − 1 DS ) W W = − θ W p 2 p pD − ( D − 1 ) θ 2 W pD < 0 , implying ( J − 1 DS ) W W is m onoton ically decreasing with p p . For 2 ≤ j ≤ W − 1 the de riv ati ve d dp p ( J − 1 DS ) j j is g i ven by − θ j p 2 p pD − ( D − 1) θ 2 j pD − 1 p 2 p pD W X k = j +1 q k − j p (1 + q p ) θ k − 1 p f p p W X k = j +1 q k − j − 1 p (( k − j ) + ( k − j + 1) q p ) θ k , which is n egati ve since e ach term is negative for 0 < p p ≤ 1 . Finally , for j = 1 we ha ve d dp p ( J − 1 DS ) 11 = D − 1 pD θ 1 (1 − θ 1 ) − 1 p 2 p pD W X k =2 q k − 1 p θ k ! − p p ( D − 1) + 1 p p pD W X k =2 ( k − 1) q k − 2 p θ k ! . ( 41) For small values of p p the expression is domina ted by ter ms in 1 /p p and is theref ore again n egati ve, b ut as the first term is positive, fo r large p p it may chang e sign. It is no t hard to show that d dp 2 p ( J − 1 DS ) 11 > 0 , so at mo st o ne sig n change is possible. Setting p p = 1 in (4 1) yields (3 1) as the necessary and sufficient condition f or this n ot to o ccur in the feasible region p p ≤ 1 . T he spe cial c ases f ollow simply f rom (3 1). E. Pr oo f of Theor em 20 First co nsider the case 2 ≤ j ≤ W . Fro m ( 21) and (24) ( J − 1 SH ) j j ≥ θ j p p ≥ θ j p ≥ θ j p − q p θ 2 j = ( J − 1 FS ) j j since p f = p an d p p = p p ( p ) ≤ p under both PPR and ESR. Now conside r j = 1 . It is co n venient to recall (23) and (21): ( J − 1 SH ) 11 = θ 1 + 1 p p P W k =2 q k − 1 p θ k , an d ( J − 1 FS ) 11 = 1 p f θ 1 − q f p f θ 2 1 . It follo ws that ( J − 1 FS ) 11 ≤ ( J − 1 SH ) 11 when p p ≤ p P W k =2 q k − 1 p θ k θ 1 (1 − θ 1 )(1 − p ) . (42) A suf ficient co ndition implying (4 2) is ob tained b y using the lower bound q p θ 2 ≤ P W k =2 q k − 1 p θ k and rearranging, yielding p p ≤ pθ 2 θ 1 (1 − θ 1 )(1 − p ) + pθ 2 . (43) Furthermo re, since p p ≤ p , a mo re restricti ve sufficient condition is g iv en by r eplacing the l.h.s. with p , wh ich redu ces to p (1 − p ) θ 1 (1 − θ 1 ) − θ 2 ≤ 0 , wh ich sho ws tha t fo r any 0 ≤ p ≤ 1 , if θ 2 ≥ θ 1 (1 − θ 1 ) , then (42) holds and ( J − 1 FS ) 11 ≤ ( J − 1 SH ) 11 . The cond ition is satisfied if W = 2 . Now let θ b e a rbitrary and consider the small p (and h ence small p p ) limit. Then (42) be comes p p ≤ p/ θ 1 , whic h is always satisfied since p p ≤ p . A P P E N D I X E M A X I M U M L I K E L I H O O D E S T I M A T O R S A. Pr oo f of Theor em 22 The likeliho od fun ction fo r N f flows is f ( θ , N f ) = Y i f ( j i ; θ ) = Y j ≥ 0 d M ′ j j . The M LE is the θ which maximizes the log-likelihood l ( θ , N f ) = X j ≥ 0 M ′ j log d j subject to the constraint P k ≥ 1 θ k = 1 , θ k > 0 , ∀ k . T he opti- mization pro blem admits a feasible solu tion by th e Bolzano- W eierstrass theorem [29, p. 517], since the log-likelihood f unc- tion is co ncave and continu ous, an d optimization is per formed over a com pact, conv ex set. Fu rthermor e, the solu tion obtained will be unique under our assumptio ns, since th e Hessian of the log-likeliho od is the Fisher inform ation, which is po siti ve definite g iv en 0 < θ k < 1 f or all k . Giv en the assumption s, th e method o f Lagrange m ultipliers would y ield the o ptimal solution since strong duality hold s 24 as the prob lem satisfies Slater’ s co nstraint qu alification [30, Section 5 .2.3, p. 226]. The Lagran gian is L ( θ , λ, ν ) = X j ≥ 0 M ′ j log d j − λ X k ≥ 1 θ k − 1 − ν T θ , where th e vector ν has elemen ts ν k ≥ 0 and λ ∈ R . By differentiating with respect to θ k , ∀ k and th e multipliers, ∂ ∂ θ k L ( θ , λ, ν ) = X k ≥ j M ′ j d j b j k − λ − ν k = 0 , ∂ ∂ λ L ( θ , λ, ν ) = 1 − X k ≥ 1 θ k = 0 , ∂ ∂ ν k L ( θ , λ, ν ) = θ k = 0 . The secon d equatio n is just the eq uality con straint while th e third yie lds a solu tion θ = 0 W , which lies on th e boun dary , yielding an u nbou nded solution (observed by substituting th e solution in to the likelihood func tion). That leaves the first equation, an d by the Karush-Kuhn -T u cker cond ition, ν T θ = 0 [30, Section 5. 5.3, p. 243], implying that ν = 0 W (our assumptions r equire that the origin al parameters 0 < θ k < 1 for all k , hence the optimal must lie within the region where the constraints are inacti ve). Thus, we have, in matrix for m, ˜ B T ˜ D diag ( M ′ 1 , . . . , M ′ W ) 1 W = λ 1 W − M ′ 0 d 0 b 0 , (44 ) recalling that ˜ D = di ag ( d − 1 1 , . . . , d − 1 W ) . W e proceed to solve for λ using the equality constrain t P k ≥ 1 θ k = 1 an d ˜ d = ˜ B θ , as fo llows, by multiply ing bo th sides o f ( 44) by θ T to ob tain θ T ˜ B T ˜ D diag ( M ′ 1 , . . . , M ′ W ) 1 W = λ − M ′ 0 ˜ d T ˜ D diag ( M ′ 1 , . . . , M ′ W ) 1 W = λ − M ′ 0 1 T W diag ( M ′ 1 , . . . , M ′ W ) 1 W = λ − M ′ 0 , implying λ = N f . For methods that pick flows in an un biased manner, b 0 = q 1 W , and thus ˜ B T 1 W = p 1 W , implying ( ˜ B − 1 ) T 1 W = p − 1 1 W , therefore (44) reduces to ˜ B T ˜ Ddiag ( M ′ 1 , . . . , M ′ W ) 1 W = ( N f − M ′ 0 ) 1 W . (45 ) which can be re written as ˜ D − 1 ( ˜ B − 1 ) T 1 W = 1 N f − M ′ 0 diag ( M ′ 1 , . . . , M ′ W ) 1 W ˜ B θ = p P W j =1 M ′ j [ M ′ 1 , . . . , M ′ W ] T . The r esult follo ws. Remark 3 2: In the cond itional fram ew ork, expr essing the log-likelihood fun ction is d ifficult, due the fact that norma liza- tion of the likelihood inv olves division by r andom variables. Howe ver , the estimator above would, with high p robab ility , be close to the actua l MLE. The flow selection p rocess is a Bernoulli p rocess. The denom inator, P W j =1 M ′ j encapsulates informa tion abo ut N f , because a symptotically , the deviation between pN f and P W j =1 M ′ j is extremely small, a con sequence of the conce ntration o f Bernoulli samples aroun d its m ean. This prop erty is no t found am ongst other methods, such as PS, w here sam ples are biased to wards large flows. B. Pr oo f of Theor em 23 W e begin with the op timization eq uation (4 4), ˜ B T ˜ D diag ( M ′ 1 , . . . , M ′ W ) 1 W + M ′ 0 d 0 b 0 = N f 1 W . Using p roperties o f the sampling m atrix f or SH, we ha ve ˜ D diag ( M ′ 1 , . . . , M ′ W ) 1 W + M ′ 0 d 0 · q p e 1 = N f ( ˜ B − 1 ) T 1 W (46) ˜ D diag ( M ′ 0 + M ′ 1 , . . . , M ′ W ) 1 W = N f ( ˜ B − 1 ) T 1 W (47) ˜ D diag ( p ( M ′ 0 + M ′ 1 ) , . . . , M ′ W ) 1 W = N f 1 W . (48) where in (46) we use the prop erty b T 0 = q p ˜ B T e 1 , where e i is the ca nonical b asis vecto r , in ( 47) we use d 0 = q p d 1 , and in (48) we u se ( ˜ B − 1 ) T 1 W = diag ( p − 1 , 1 . . . , 1) 1 W . All th ese proper ties can b e o btained b y a straig htforward ev aluation using the sampling matrix. The final line reduces to ˜ B θ = 1 N f · [ p ( M ′ 0 + M ′ 1 ) , . . . , M ′ W ] T , proving the result. The estimator is unbiased, as b y taking the e xpectation , we obtain E [ p ( M ′ 0 + M ′ 1 )] = N f ( pd 0 + pd 1 ) = N f ( p + q ) d 1 = d 1 , by u sing the identity d 1 = p p q p d 0 while clearly E [ M ′ j ] = d j for all j ≥ 2 . Thus E [ ˆ θ SH ] = ˜ B − 1 SH ˜ B SH θ = θ . R E F E R E N C E S [1] N. Duf field, C. Lund, and M. Thorup, “Estimat ing Flow Distri buti ons from Sampled Flow Statisti cs, ” IEEE/AC M T rans. Networking , vol. 13, no. 5, pp. 933–9 46, Oct 2005. [2] N. Hohn and D. V eitch, “In ver ting Sample d Traf fic, ” in P r oc. 2003 ACM SIGCOMM Internet Measure ment Confere nce , Miami, Octobe r 2003, pp. 222–233. [3] ——, “In verting Sampled Traf fic, ” IEE E/ACM T ransactions on Network- ing , vol. 14, no. 1, pp. 68–80, 2006. [4] B. Ribe iro, D. T o wsle y , T . Y e, and J. Bolot , “Fisher information on sampled packet s: an appli catio n to flow size estimation, ” in Pr oc. ACM /SIGCOMM Internet Measuremen t Conf. , Rio de J aneiro , Oct 2006, pp. 15–26. [5] G. V arghese , Network A lgorithmi cs . Sa n Francicso: Elsevi er/Mor gan Kaufmann, 2005. [6] C. Estan and G. V arghe se, “New directi ons in traf fic measurement and accoun ting, ” ACM T ransaction s on Computer Systems , vol . 21, no. 3, pp. 270–313, August 2003. [7] P . Tun e and D. V eitc h, “T oward s Optimal Sampling for Flow Size Estimation, ” in Proc . ACM SIGCOMM Internet Measur ement Conf. , V ouliagmeni, Greece, Oct.20-22 2008 , pp. 243–256. [8] L. Y ang and G. Michaili dis, “Estimat ion of flo w leng ths from sampled traf fic, ” in Proc . GLOBECOM , San Francisco, CA, Nov 2006. [9] T . M. Cover and J. A. Thomas, Eleme nts of Informat ion Theory , 2nd ed. John W ile y and Sons, Inc., 2006. [10] A. Hero, J. Fessler , and M. Usm an, “Exploring est imator bias-va riance tradeof fs using the Uniform CR bound, ” IE EE T rans. Sig. Proc. , vo l. 44, no. 8, pp. 2026– 2041, Aug 1996. [11] J. D. Gorman and A. O. Hero, “Lower bounds for parametric estimat ion with constraint s, ” IEEE T rans. Info. Th. , vol. 26, no. 6, pp. 1285–1301, Nov 1990. [12] D. Harville, Matrix A lge bra fr om a Statistici an’ s P erspe ctive . Springer- V erlag, 1997. [13] J. E. Strum, “Binomial matrice s, ” The T wo Y ear Coll e g e Mathemat ics J ournal , vol. 8, no. 5, pp. 260–266, Novembe r 1977. 25 [14] E. L. Lehmann and G. Casella, Theory of P oint Estimation , 2nd ed., ser . Springer T exts in Statistics. Spri nger , 1998. [15] P . T une and D. V eitch, “Fisher information in flow size distributio n es- timatio n: T echn ical report, ” Dept. E&EE, The Univ ersity of Melbourn e, T ech. Rep., 2008, copy av ailable upon request. [16] D. Shah, S. Iyer , B. Prabhakar , and N. McKeo wn, “Mai ntainin g statist ics counter s in line ca rds, ” IEE E Micr o , vol. 22, no. 1, pp. 76–81, 2002. [17] S. Ramab hadran and G. V arghe se, “Ef ficient imple mentati on of a statis- tics counter architecture , ” A CM SIGMETRICS P erformanc e Evalu ation Revie w , vol. 31, no. 1, pp. 261–271, June 2003. [18] Q. Zhao, J. Xu, and Z. Liu, “Design of a nov el statistics counte r archit ecture with optimal space and time ef ficienc y , ” Proc. of ACM SIGMETRICS 2006 , vol. 34, no. 1, pp. 323–334, June 2006. [19] R. T . Rockafella r , Con vex Analysis , ser . Princeton L andmarks in Math- ematics and Physics. Pri nceton Univ ersity Press, 1970. [20] C. Estan, K. Ke yes, D. Moore, and G. V arghese, “Building a better netflo w , ” in Proc. ACM SIGCOMM 2004 , Portland, OR, Aug 2004. [21] NLANR, Leipzig-I I Trace Data, ht tp://pma .nlanr .net/Special/leip2.html. [22] ——, Abilene-III Trace Data, http://pma.nla nr .net/Special/ipls3.html. [23] CoralR eef, ht tp://www .caida.or g/too ls/measurement/coralreef/. [24] S. Kay , Fundamentals of Stat istical Signal P r ocessin g, V olume I, Esti- mation Theory . Prentice Hall, 1993. [25] M. Mitz enmacher and E. Upfal, Pr obability and Computi ng . Cambridge Uni versi ty Press, 2005. [26] G. J. McLachlan and T . Krishna n, The EM Algorithm and Extensions , 2nd ed. Wile y Intersci ence, 2008. [27] F . Zhang, Matrix Theory: Basic Results and T ec hniques . Springer - V erlag, 1999. [28] R. Zamir, “ A proof of the Fisher information inequality via a data pro- cessing argument, ” IEE E T ransactions on Information Theory , v ol. 44, no. 3, pp. 1246– 1250, May 1998. [29] A. E. T aylor and W . R. Mann, Advance d Calculus , 3rd ed. John W iley and Sons, 1983. [30] S. Boyd and L. V andenber ghe, Con ve x Optimization . Cambridge Uni versi ty Press, 2004. Paul T une (M’09) rec ei ved the B.E. (Hon.) and B.Sc. degree s in Electri cal and Electr onics Engi- neering and Computer Science respecti ve ly , both in 2005, from the Univer sity of Melbour ne, A us- tralia. He has r ecentl y completed a Ph.D. degr ee at the ARC Speci al Center for Ultra-Broadband Info rmation Networks (CUBIN) at the Uni ver sity of Melbourne , Australi a. His rese arc h intere sts are in communicatio n networ ks, particularl y in traffic inv ersion and sampling, infor mation the- ory , statistics and signal proce ssing, specifica lly sparse signal rec ov ery . Darryl V eitch (F’10) complete d a BSc. Hons. at Monash Uni ver sity , A ustralia (1985) and a math- ematic s Ph.D. from Cambr idge, England (1990). He worked at TRL (T elstra, Melbour ne), CNET (France T elecom, Pari s), KTH (Stockholm), IN- RIA (Sophia Antipolis, France), Bellcor e (New Jer sey), RMI T (Melbour ne) and EMUlab and CUBIN at The Unive rsity of Melbour ne, where he is a P rofe ssorial Research Fello w . His resear ch inter ests include traffic modelling, parameter es- timation, activ e measurement, traffic sampling, and clock synchr onizati on.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment