고성능 네트워크 서버를 위한 멀티스레딩 모델 비교 분석
본 논문은 메모리 기반 캐시 데이터베이스 서버(mdcached)를 실험 플랫폼으로 삼아, SPED, SEDA, SEDA‑S, AMPED, SYMPED 등 다섯 가지 멀티스레딩 모델을 구현·평가한다. 8코어 Intel Xeon 기반 FreeBSD 시스템에서 클라이언트 연결 수를 변화시키며 초당 트랜잭션 수(TPS)를 측정한 결과, 단일 스레드 이벤트 기반(SPED) 모델이 가장 높은 효율을 보였고, SEDA와 AMPED는 커널·컨텍스트 스위칭 오…
저자: ** Ivan Voras, Mario Žagar **
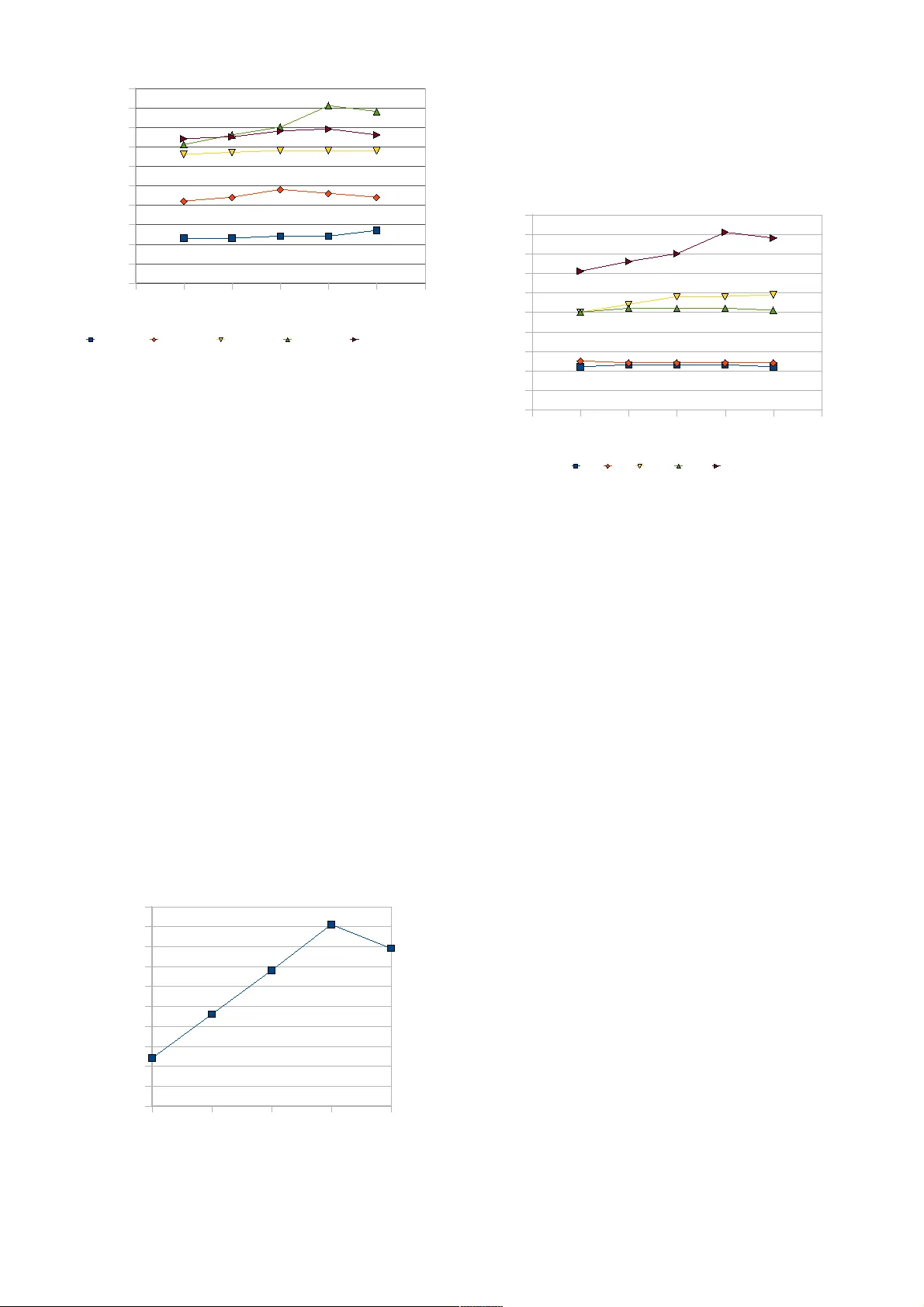
본 논문은 현대 서버 하드웨어가 다코어·다CPU 구조로 급격히 전환되는 상황에서, 고성능 네트워크 애플리케이션을 설계할 때 적절한 멀티스레딩 모델을 선택하는 것이 얼마나 중요한지를 실증적으로 보여준다. 연구자는 먼저 네트워크 서버에서 수행되는 작업을 “연결 수락·종료”, “네트워크 통신”, “페이로드 처리”라는 세 가지 클래스로 추상화하고, 이들 클래스를 어떤 스레드에 할당할지에 따라 다섯 가지 대표적인 멀티스레딩 모델을 정의한다.
1. **SPED (Single‑Process Event‑Driven)**: 모든 작업을 하나의 스레드가 순차적으로 처리한다. 커널이 제공하는 비동기 이벤트 메커니즘(epoll/kqueue 등)을 활용해 다수의 클라이언트를 동시에 관리한다.
2. **SEDA (Staged Event‑Driven Architecture)**: 각 작업 클래스를 별도의 스레드 풀에 매핑한다. 네트워크 스레드가 요청을 받아 큐에 넣고, 페이로드 워커 스레드가 이를 처리한다.
3. **SEDA‑S**: SEDA의 변형으로, 네트워크 스레드와 페이로드 스레드의 1:1 매핑을 강제해 큐 잠금과 컨텍스트 전환을 최소화한다는 목표를 가진다.
4. **AMPED (Asymmetric Multi‑Process Event‑Driven)**: 네트워크와 연결 관리는 단일 스레드에서 수행하고, 페이로드만 다수의 워커 스레드에 위임한다.
5. **SYMPED (Symmetric Multi‑Process Event‑Driven)**: 다수의 네트워크 스레드가 직접 페이로드 로직을 호출한다. 전통적인 “스레드‑퍼‑코넥션” 모델과 유사하지만, 각 스레드가 여러 연결을 동시에 처리한다.
실험 플랫폼은 8코어 Intel Xeon 5405(2 GHz) 기반 FreeBSD 8‑CURRENT이며, 메모리 전용 키‑밸류 데이터베이스인 **mdcached**를 서버 구현체로 사용한다. mdcached는 해시 테이블과 바이너리 트리를 결합한 인덱스를 가지고 있으며, 모든 I/O는 비동기 kqueue 기반으로 구현돼 있다. 서버와 클라이언트는 동일 물리 머신에서 Unix 소켓으로 통신해 네트워크 지연을 최소화했다. 테스트 데이터는 30 000개의 레코드(크기 10 B~103 B)이며, 각 클라이언트는 간단한 요청‑응답 루프를 수행한다.
각 모델에 대해 스레드 수를 다양하게 조정하고, 동시 클라이언트 수를 20~140 사이에서 변화시켜 초당 트랜잭션 수(TPS)를 측정했다. 결과는 다음과 같다.
- **SPED**는 단일 스레드임에도 불구하고, 커널 수준의 비동기 이벤트 처리와 lock‑coalescing 최적화 덕분에 400 k‑500 k TPS 범위의 최고 성능을 기록했다. 이는 멀티스레드 모델을 도입하지 않아도 충분히 높은 처리량을 달성할 수 있음을 보여준다.
- **SEDA**는 네트워크·페이로드 스레드 간 큐 잠금과 컨텍스트 전환이 병목이 되어, SPED와 거의 동일하거나 약간 낮은 성능을 보였다. 특히 워커 스레드 수를 늘려도 커널 I/O 대기 시간이 전체 지연을 지배했다.
- **SEDA‑S**는 이론적으로 1:1 매핑을 통해 잠금 경쟁을 감소시킬 것으로 기대했지만, 실제 구현에서는 네트워크 스레드가 페이로드 스레드와 직접 통신하면서 오히려 동기화 비용이 증가했다. 결과적으로 SPED와 비슷하거나 약간 낮은 TPS를 기록했다.
- **AMPED**는 네트워크 스레드가 포화 상태에 이르면 워커 스레드 수를 늘려도 처리량이 크게 향상되지 않았다. 네트워크 스레드가 하나일 때와 두 개일 때의 차이는 미미했으며, 워커 스레드가 4개까지 증가해도 최대 350 k TPS 수준에 머물렀다.
- **SYMPED**는 다수의 네트워크 스레드가 직접 페이로드 로직을 호출해 큐를 제거했지만, 여전히 커널 I/O와 컨텍스트 스위칭 비용이 전체 성능을 제한했다. 최적 구성에서는 약 380 k TPS를 달성했으며, 이는 SPED에 근접하지만 명확히 우수하지는 않았다.
전체적으로, 논문은 “멀티코어 환경에서도 I/O‑바운드 서버는 커널·스케줄러 오버헤드가 병목이 된다”는 결론을 도출한다. 스레드 수를 늘리는 것만으로는 성능 향상이 보장되지 않으며, 스레드 간 통신 메커니즘(큐, 락, 컨텍스트 전환)과 커널 이벤트 처리 방식이 전체 파이프라인에 미치는 영향을 정밀히 분석해야 함을 강조한다. 또한, 메모리 전용 서버라는 제한된 환경에서 수행된 실험이므로, 디스크 I/O가 포함된 실제 서비스에서는 결과가 달라질 가능성이 있다. 논문은 이러한 제한을 인정하면서도, 다양한 멀티스레딩 모델을 동일 조건에서 비교함으로써 서버 설계자들에게 실용적인 로드맵을 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기