Characteristics of multithreading models for high-performance IO driven network applications
In a technological landscape that is quickly moving toward dense multi-CPU and multi-core computer systems, where using multithreading is an increasingly popular application design decision, it is important to choose a proper model for distributing t…
Authors: ** Ivan Voras, Mario Žagar **
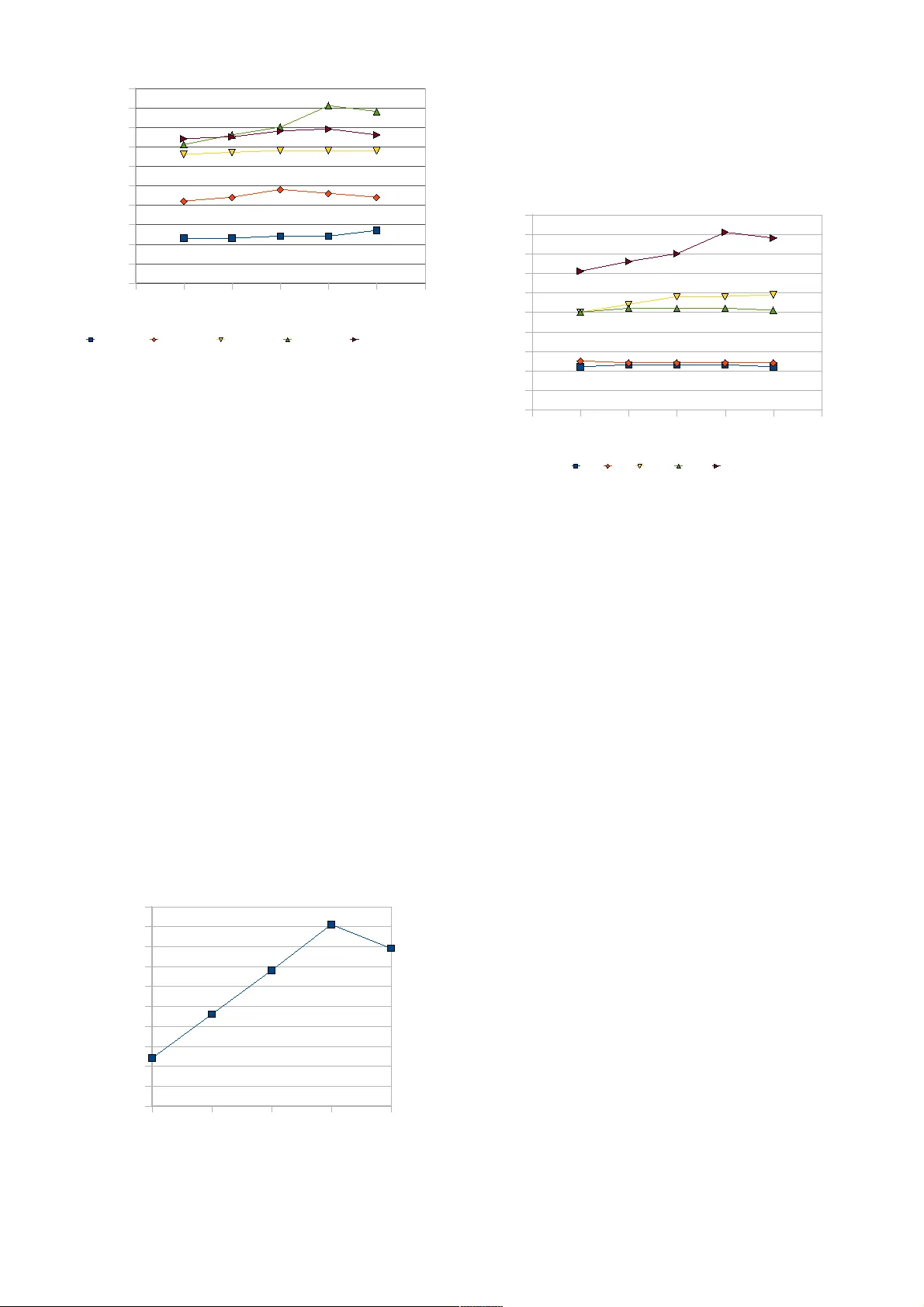
Abstract — In a t echnological landscape that is quickl y mo ving toward dense m ulti-CPU a nd m ulti-core com puter systems, where using m ultithreadin g is an increa singl y pop ular application design decision, it is important to choose a p roper model for distr ibuting tasks across m ultiple threads that will result in the b est effici en cy for the a pplic ation and the system as a whole. The work des cribed in this paper cr eates, implements and evaluates vari ous models of distr ibuting tasks to CPU thr eads and investigates thei r characte risti cs for use in mo dern h igh-performance network se rvers. The results pr esented here comprise a roadm ap of models for building multithreaded server appli cations for moder n server hardware and Unix-lik e operating systems. Index Term s — Mul tit asking, multit hre adin g, multipro cess ing, SMP, threading m odels, concurrency control, proces sor s chedu ling , dat a stru cture s I. I N TR ODUCTION odern server applicat ions can not avoid t akin g note of recent developm ents in computer arc hit ecture tha t resulted in wide-spread use of mult i- core CPUs e ven on low- end equipme nt [1]. Differ ent equipme nt ma nufactu rers use different approach es [2-4] w ith th e same end result of havi ng multip le ha rdwar e p roces sin g uni ts available to the soft ware. This is not a r ecent de velopment [ 5,17] but it h as recently rec eived a sp otlight t reat ment be cause o f the proliferat ion of multi -core CPUs in all environme nts. Thi s has resul ted i n cha nged requ irem ent s for high- perf orma nce server software. M The prevaili ng and recommend ed model f or building high - performa nce network servers for a l ong time was based on asynchrono us IO and event-driven arc hit ectures in various forms [6-8]. S hortcomin gs of thi s model grew as the nu mber of C PU cores available in recent ser vers incr eased. Despite t he complexities impl icit in creat ing mult ith rea ded program s, it was inevitably accepted as i t allows fuller use of hardwar e pos sibilities [9], though recently the pure mul tit hre aded model is combined with th e mult iprocessing model for incr eased perform ance or convenience [10] . Thi s work st udies the di ffere nt way s t asks in a dat abase- like network server can be assigned to CPU threa ds. To investigat e th e various models that can be used in th is mappi ng, we have us ed a f lexible memory database server This work is suppo rted in part by the Croatian Minis try of Scie nce , Education and Sport s, under the res earch proje ct “Soft ware Engi nee ring in Ubiquit ous Com puting ”. I. Vora s an d M. Žagar are wit h F aculty of Elect rical En ginee rin g and Computin g, Univ ersi ty of Zagreb, 100 00 Zagreb, Croatia. (e -mail : ivan.v oras@f er.h r, m ario.zagar @fer.h r). (described in [11]) which i s i nten tio nal ly created to be capable of various models of distributio n of workload tas ks to CPU threa ds. It al lows us to experiment an d measure performan ce char acter ist ics of these models in di rectly comparable circumst ances , using benchm ark in g clients made as a p art of t he referenced p roject. Our conclusions are t hat the re are sign ifican t differences betw een the mul tit hre ad in g models, which ar e visible bo th in the perform ance curve a nd the be st perf orm ance each model can achieve. Thi s paper describes major mul tit hre adi ng m odels applied in practi ce and described in li tera tur e i n the second section. I t continues with t he descri ption of the spec ific imp lement atio n o f a memory cache database project which can employ any of sev eral mu ltit hr eadi n g models and the protocol of the evaluation in s ection th ree. The mai n pa rt of the paper is c omprised o f evaluation r esults i n section four, after which follow s the conclusion in section five . II. M UL TITHR EADING M ODELS In thi s work th e term “mult ith rea din g model” refers to a disti nct way tasks in IO (i nput- output) d riven ne twork servers are distribu ted to CP U t hrea ds. It concerns itself with gener al not ion of thr eads dedica ted for certai n class of tasks, ra the r t ha n t he qu ant ity of t hrea ds or the tasks present at any one point (except for some spe cial or degenerate cases like 0 or 1). We o bserv e that i n a typical network ser ver ther e are thr ee classe s of tasks that al low t hemselves to be para lle lize d or delegated to different CPU t hrea ds: 1. Acce ptin g new clie nt connect ions an d closing or garbage collecting ex isting connections. 2. Networ k co mmun icat ion with accepted client connections. 3. Pay load w ork t hat the server does on behalf of t he client, which includes generat in g a response. Int o thi s tas k class we abstract all operatio ns t he ser ver needs to perform in response to a c omman d or input received from the network. Using these t h ree classes o f tasks, there are several m odels recognized in p racti ce an d liter atu re [12]. At one p art of t he spectrum is the singl e process even t dri ven (SPED) model, where al l three classes of tasks a re alway s p erformed by a singl e t hre ad (or p rocess), usi ng ke rnel- provided event notificati on mechan is ms to manage mult iple client s at the same t ime, but perform ing each ind ividual task sequential ly. On the opposite side o f SPED is stag ed even t- driven archit ect ure (SEDA), where every task class is imp lemente d as a t hre ad or a t hrea d p ool an d a response to a request made t o the c lient might involve mul tipl e Ivan Voras, Ma rio Žagar Characteristics of multithreading models for high-p erforman ce I O d riven network applications different th reads . In our implemen tat ion SEDA is imp lemente d as the connection accepting th read with also run s t he t asks o f t he network IO t hre ads (or simply “network thre ads”) and payloa d t h reads (or “w orker thr eads ”). Betwe en the extremes are the asymmet ric mult i- process even t- driven (AMPED) m odel where th e network operations a re processe d i n a way similar to SPED (i.e. in a singl e t hrea d) while th e payload work is delegat ed to separate t hre ads to avoid run ni n g long- term operati ons direct ly in the network loop and symmetr ic mul ti- process event driven (SYMPED) whi ch us es multi ple SPED- like thr eads , each processing several cli ent connections. A special class of AMPED is a thre ad-p er-conne ctio n model (usually cal led simply t he m ulti thr ead ed or m ulti processing – MT or MP – model) where c onnection acceptance a nd garbage collecting i s im plement ed i n a si ngle threa d which delegates both th e network communi catio n a nd p ay load work to a singl e th read for each connect ed client (th is model will not be specially investigat ed here as t here's a lar ge body o f work cov ering it). Ea ch o f the mul tit hrea ded models can also be imp lement ed as multipr ocessing models, and in fact some of them are more well known in thi s vari ant (th e process- or t hrea d- per connection model is well known and ofte n u sed in Unix enviro nmen ts). In this work we lim it ourselves only to the m ulti thr ead ed varia nts . Our e xperien ce with [11] l ead us to be part icula rly int erested in c ertai n edge cases, which w e i nvestigate he re. In part icul ar, w e a re intere sted in reducing unwa nted ef fect s of inte r- th read communi catio n and limiti n g context switching bet ween th reads . We will p resent one im porta nt variat ion of t he SEDA model where the nu mber of worker thr eads ex actly equals the nu mber of network threa ds and each network th read alway s communicat es with t he sa me worker t hre ad, avoidin g some of t he in ter -t hr ead loc king o f communicat ion queues. W e call t his model SEDA- S ( for symmetri c ). A. Multi thread ing models and the test i mplemen tat ion We h ave evaluated t he described multi th read ed models duri ng a nd after th e impleme ntat ion o f a memory d atabase int ended for cachi ng web appl icatio n a nd web service dat a, called mdcache d and origi na lly described in [11] . It uses aggressive techni ques t o achieve hi ghly para ll el operatio n and concurren t access to shared d ata. Becau se o f thi s, th e biggest i nfluence on overall pe rformanc e of th is server is obs erved to be in the mu ltit hr eadi n g model used to schedule the workload. T his b ehaviour h as ma de it a gr eat platform for experime nti ng with multi th rea din g models. The classes of tasks described ea rlie r are i mpleme nted as follo ws in th e mdc ached server: 1. New connect ion h an dli n g a nd connectio n expi rin g is alw ay s allocated to a single th read . The reasons for this i s th at connecti on acceptan ce i s in her ent ly not paral lel izab le an d tha t previous research [13] has i ndicat ed th at thi s aspect of network servers cannot be significa ntly i mproved. 2. The co de path im plement in g communicat ion betw een t he server an d the clients can be ru n in one or more th reads . Dat a asynchron ously received from the r emote client is only c hecked for vali dity in co de path and passed to the n ext code path for further processing. 3. The code p ath implemen tin g req uest parsin g, data store operation (fetch or add) , an d other pay load work can be run in one or more t hre ads. The generat ed r esponse data is immedi ately passed to the network stack for asy nc hron ous send ing. If the response i s too large to be accepted by t he network stack at onc e, the unsent data is hand led b y th e network cod e pat h. The described division into code path s allows us to imp lement th e SP ED model by executing the network and the pay load code pat hs insi de the connection ha nd lin g loop, the SEDA model by executing all thre e code pat hs in separate th reads (even several ins tan ces of the sam e code path s in mul tipl e t h reads) , the AMP ED model by executin g singl e instan ces o f the conn ection han dl in g an d network thr ead s and mul tipl e pay l oad thread s, a nd the SYMPED model by executing a singl e connection hand li ng threa d and mu ltip le network t hre ads whic h di rectly call in to the payl oad hand li ng co de pat h (no s eparat e pay load t hre ads) . Table 1 s hows the mappi ng betwe en th read s a nd code pat hs in md cached to described mul tit hre adi ng models. TABLE I M APPI NG OF C ODE P A THS AND T HRE ADS I N MDCACH ED TO M ULT ITHRE AD ING M ODEL S Connection acceptan ce Networ k comm unica tion Pa yload wor k SPED 1 thread In c onne ctio n thread In c onne ctio n thread SEDA 1 thread N 1 thread s N 2 thread s SEDA- S 1 thread N threads N threa ds AMPE D 1 thread 1 thread N threa ds SYMPED 1 thread N threads In ne twork thread Table 1 also describes t he exact models t hat are used i n thi s research . B. Operation al chara cteri sti cs of mdcached The mdca ched applic ation i s a memory database designe d for hi ghly concurre nt operation on modern Unix-like sy stems. It is prim ari ly a key -value database in which t he key s are indexed in a c ombinatio n of a hash table and binary trees [ 11]. The communicat ion betw een various thr ead s withi n md cached is imple mented usin g asy nch ronous queues in whic h jo b descripto rs a re exchanged . W ithi n a class o f th read s (conn ection, network, payl oad th reads) t here is no furthe r divisio n of prio rit y or preference. Jobs that are passed from one th read class t o th e other (e.g. a client request from a network threa d to a payl oad t hre ad) a re enqueued on th e receiving th reads ' eve nt queues i n a roun d- robin fashion . T he protocol used for co mmun icat ion betwe en the mdcache d ser ver a nd i ts clients is binary, optimi zed for per forma nce an d avoidance of sy stem (kerne l) ca lls in data receiving c ode pat h. Networ k IO operation s are alway s performed by r espondi ng to events (event-dr iven architec ture) received from t he operatin g sys tem kernel . The pr ima ry design concern for the pro toco l and th e database operatio n was to achieve as many tra nsa ctions pe r sec ond as possib le. In thi s work we aim to optimi ze the nu mber of client- server tra nsac tions per second proc essed by the mdcac hed server by va ry ing the t hre ad models us ed to distri bute work on m ulti ple CPU thre ads. Since md cached is a pu re m emory database s erver i t avoids certai n classes of behaviour present in servers that int eract with a l arger environm ent . In part icu lar, it avoids waiting for disk IO, which would h ave been a concern for a disk-based datab ase, a w eb server or a simil ar applicatio n. We obser ve th at the mdcached server operation is hi gh ly dependan t on sy stem ch arac teri stics such as m emory bandwidth an d operati n g sy stem performanc e in the are as of sy stem ca lls, i nter - process communicat ion a nd genera l context switchi ng. To ensu re m ax imum performa nce we use advanced operatin g sys tem s upport such as k queu es [14] for network IO and a lgorit hm s su ch as lock coalescing (locking int er- th rea d communicat ion queues for mult iple queue/dequeue operatio ns inste ad of a singl e operation) to avoid lock contention an d context switches. III . T HE I MPLEMENT A TION AND THE P ROTOCO L OF THE E V ALU A TION We evaluate the mul tit hre aded m odels b y appl y ing each to the operatio n of mdca ched , distributi ng its code pat hs to CPU thr eads. Each model ha s a uni que configurat ion th at is applied to t he config ura ti on of mdcached server at startup and which remai ns duri ng t he ti me t he process is active. As well as t he th read model, the nu mber of t hre ads is also varied (if it's desirabl e for th e model under evaluation) in order to present a cleare r picture of its pe rforma nce char acte risti cs. The server is acce ssed by a sp ecially created be nchm ark client t hat alway s uses th e same m ulti thr ead in g model (SYMPED) and number of t hre ads but vari es the n umber of simul taneous client conn ections it establishes. Each cli ent- server tra ns action involves t he client s endin g a request t o the server and the server sending a r esponse to th e re quest. For t esting pur poses the data set used is deliberately small, consistin g of 30,000 records wit h r ecord siz es r ang in g from 10 byt es to 103 by t es in a logari th mic dist ribution . To emphasi se the g oal of max imiz in g the nu mber of tra ns action s per second achieved and to elimi nat e e xtern al influen ces like network latency a nd ne twork ha rdwa re issues, bo th the server and the client are run on the same server, communicat in g over Uni x sockets. The test server is based on Inte l's 5000X ser ver platform with two 4-core Xeon 5405 CPUs (for a total of 8 C PU cores in t he sy stem) run ni ng a t 2 GHz. A sin gle quad-core Xeon 5405 CPU is comprised o f two sets of two cores, wit h ea ch set shari ng 6 MB of L2 cache (there i s no L3 cache). T he benchma rk client alway s st arts 4 thread s, mean in g it can use up to a t most 4 CPU cores. We h ave observe d t hat the bes t results are achieved when the number of server threa ds and the number of benchma rk client th read s together is approxi mat e to the total number of CPU c ores available in the sys tem. T he operati ng sy stem used on the server is t he deve lopment version of FreeBSD, 8- CURRE NT, r etri eved at September 15 2008. The ope rati ng syst em is fu lly mult ith rea ded and supports p aral lel operatio n of applic ations and i ts network stack [16]. Duri ng test runs of t he bench mark s we h ave obser ved tha t the result s vary betwe en 100, 000 t ra nsac tions per second and 500,000 tra nsa ctions per second, with standard deviation being usual ly less than 5,00 0 tran sact ions per second. All tests w ere perf ormed with pre vious “ warm- up” run s, and the reported resul ts are averages of 5 r uns within each configura tion of benchm ark client a nd t he server. We've deter mi ned t hat for t he pu rpose of t his work it is suffic ient to report results rou nded to the nearest 5,000 tra ns action s per second, which is e nough to show t he difference be twe en t he mu ltit hr eadi n g models. W e h ave also obs erved t hat th e most i nteres tin g cha ract eris tics of the client- server sy stem as a whole are visible when t he nu mber of clie nts is betw een 40 an d 120 clients . This is the location of peak of performa nce for most m odels. IV . E V ALU A TION R ESUL TS We have c ollected a l arge body of resul ts with different combination s o f mul tith re adi ng models a nd number of clients. Presented here are compari sons wit hin mult ith rea di ng models, in orde r of in creasi ng performance. The SPED model, presented in Fig. 1, quickly re aches its peak perf orma nce at which it doesn't sc ale furt her with the i ncre asin g nu mber of clients. The performan ce achieved with the SPED m odel can be used as a baseline result, achieved without th e use of mult ith re adi ng or mult iple C PU cores. Th is result is t he be st t hat can be achieved wit h an eve nt- driven arch itect ure 20 40 60 80 100 120 140 0 20 40 60 80 100 120 n o n e two rk t h re ad s, no p a yl oa d t h re a d s Num b e r o f c l i en ts T hou s and s o f tras n ac ti on s /s Fig. 1. P erfo rman ce of the SP ED multithreadin g mod el, de pen ding on the number of simultaneous cli ents . Semant ical ly on t he opposite side but with su rpri sin gly litt le performa nce benefit in our i mpleme nta tio n is th e SEDA model. Since s ome va riat ions of the SEDA model over lap with other models presente d h ere, Fi g. 2 s hows only the case were t here are 2 network th re ads receiving requests from t he clients a nd passi ng them t o 4 p ay load t hre ads. 20 40 60 80 100 120 140 0 20 40 60 80 100 120 2 ne t wo rk, 4 p a yl oa d thre ad s Num b e r o f c l i en ts T hou s and s o f trans ac t i on s /s Fig. 2. Perfor manc e of the SEDA m ultithreadi ng mo del with two n etwo rk threads and four payload threads , depe nding on th e numb er o f si multaneo us clie nts. Surpr isi ngly, the SEDA model in our i mplemen tat ion achieves p erforma nce comparab le to the SPED model, despite that it s hould allow the usage of much more CPU resources than the SPED model. P robing t he sys tem duri n g the benchma rk ru ns suggests th at th e m ajority of time is spent in the kernel, man agi n g int er- th read communicati on and contex t s witches, which hi nder s global perf orma nce of the client- server sys tem. F urt her investigati on is needed to reveal if a be tter distribu tion of the c ode paths to CPU thr eads wo uld y ield better per form ance, but a conclusion suggests i tself that , for t his im plement atio n, t he chosen SEDA model p resents a sort of worst-case sc enari o w ith regar ds to eff iciency , t y in g up mul tipl e CP U cores but not achievin g expected performan ce. 20 40 60 80 100 120 140 0 50 100 150 200 250 300 0 ne t wo rk, 1 p a yl oa d thre ad 1 ne two rk, 2 p a yl oa d thre ad s 1 ne two rk, 3 p a yl oa d thre ad s 1 ne t wo rk, 4 p a yl o a d thre ad s Num b e r o f c l i en ts T hou s and s o f trans ac t i on s /s Fig. 3 . Perf orman ce of th e AM PED multi threading model with 0 or one netw ork threads and betw ee n 1 and 4 payload threads , depen ding on the number of simultaneous cli ents . The performance chara cteri stics of the AMPED mult ith rea di ng model is presen ted in Fig. 3. For AMPED we presen t two basic varia tion s of the model, one without a separate network t hre ad, r unn i ng SPED-like netw ork communicat ion i n t he mai n network loop (the connection loop), and one with a single network t hrea d a nd a vary ing number of pay load threa d. Sys tem probing duri ng benchmar k ru ns on this multi th read i ng mode l reve als that the sin gle network th read is saturate d with the work it needs to process and i ncre asin g th e nu mber of worker thr ead s achieves li ttle except incre asin g the n umber of context s witches and inte r- th read c ommuni catio n. Th e b est performan ce for thi s mod el was achieved with one network thr ead and two payload th read s. In the inc reasi ng order of achi eved performanc e, the SEDA-S model whose performan ce is presented in Fig. 4 y ields results sli ght ly better tha n t he AMPED mode. Thi s model uses mu ltip le network an d p ay load t hre ads, with the number of ne twork threa ds equal lin g the nu mber of pay load thr ead s, an d where each network th read communic ates with a singl e p ay load t hr eads. The perform ance of SEDA-S is compara tively hig h, scaling up with th e nu mber of thr eads up to 3 network thr ead s an d 3 w orke r t hrea ds, afte r which it falls as the number of th reads i ncreases an d so do the a dverse effe cts of int er- th read communi cation an d context switches. 20 40 60 80 100 120 140 0 50 100 150 200 250 300 1 ne t wo rk, 1 p a yl oa d thre ad 2 ne two rk, 2 p a yl oa d thre ad s 3 ne two rk, 3 p a yl oa d thre ad s 4 ne t wo rk, 4 p a yl o a d thre ad s Num b e r o f c l i en ts T hou s and s o f trans ac t i on s /s Fig. 4. Perfo rman ce of the SEDA- S multithrea ding m odel with the number of netw ork threads equalling the number of pay load threa ds, from 1 to 4 threads each, dep endi ng on the number of si multane ous cl ient s. The hi ghest p erforma nce is achieved with the SYMPED model, whose benchma rk results a re presented i n Fig 5. The be st result achieved with the SY MPED model is 54% better better t han the nex t be st result, indic ati ng th at it is a qualit at ively better model for the pu rpose of t his work. Investigatio n of the sy stem behaviour duri ng the benchma rk run s suggests th at the pr ima ry reason for this is th at there is no i nte r- th read communi catio n overhead i n passin g jo bs betw een the network t hr ead(s) and th e p ay load th read( s). In other words, all communi catio n and data stru ctures from a singl e network req uest are hand led within a si ngle CPU thr ead . 20 40 60 80 100 120 140 0 50 100 150 200 250 300 350 400 450 500 1 ne t wo rk t h re a d 2 ne two rk t h re a ds 3 ne t wo rk t h re a ds 4 ne t wo rk t h re a d s 5 ne t wo rk t h re a ds Num b e r o f c l i en ts T hou s and s o f trans ac t i on s /s Fig. 5. Perfo rman ce of the SYM PED multithrea ding mod el with 1 t o 5 netw ork thr eads, dep end ing on the numbe r of simultaneo us cli ents . Additio nall y , th e SYMPED model exhibits very regula r scaling as the nu mber of threa ds allocated to the server incr eases, as presented by Fig. 6. The performan ce incr eases li nearl y as the numbe r of server th rea ds i ncreases , up to 4 threads . We believe t hat t his lim ita tio n is a consequence of r unn i ng both th e server a nd the client on the same c omputer sy stem and that t he performan ce w ould continu e to r ise if t he server and t he clients a re separated int o t heir own sys tems. Investigatio n into this possibility will be a par t of our future resear ch. No explici t sche duli ng was performed durin g these te sts. The benchmark clien t a nd the s erver t hrea ds were scheduled with the regular operating sy stem kern el scheduler [ 15] (e.g. they were not b ound to specific CPUs). We obser ve that the eff ects of the schedule r on overall performan ce of the sys tem described in th is paper a re mi nim al with regar ds to possible overhead involved i n rescheduli ng tasks and context switchin g. Results demonstra ted for the SYMPED model and present ed in Fig. 6 show li near in crease of perform ance with incre asin g number of server t hre ads upto 4 threa ds, which is also h alf the nu mber of available CPU cores. For th is par ticu lar benchmar k, 4 other CPU cores a re ef fe ctively t aken for t he client t hre ads. 1 ne tw or k th r ead 2 netw o r k th r eads 3 netw ork thr eads 4 ne tw or k th r ead s 5 netw ork thr eads 0 50 100 150 200 250 300 350 400 450 500 Num b er of n etw ork th read s T hou s and s o f trans ac t i on s /s Fig. 6. S calabi lity of the SYMPED model depe ndin g on the number o f ser ver threads . Final ly, we present a comparison betw een the presente d models in Fig. 7, choo sing best performanc e fr om each model ir respectively of the numbe r of thread s used in the model. 20 40 60 80 100 120 140 0 50 100 150 200 250 300 350 400 450 500 SPED S ED A SED A-S AMPED SYMP ED Num b e r o f c l i en ts T hou s and s o f trans ac t i on s /s Fig. 7. Comparis on of mult ithreading mode ls at their peek perfo rman ce, depe ndi ng on the number of sim ultaneous cli ents . Note t hat t he presented r esults involve bidi rectiona l communicat ion , so that the 450,0 00 ach ieved tran sact ions per second tra ns late to 900,0 00 i ndivid ual network operations per second. We wish to emphasi ze t hat the achieved m axi mum number of tran sact ions per second present ed in t his work come from both th e client and t he server proce sses ru nn in g on t he same computer sy stem, and that i n the ide al case, if the operat in g sy stem and the network condit ions allow, t he potential max imum could be twice as much tra nsa ctions per second, clo se to 1,000,000 t ra nsac tions /s on the s ame ha rdware. V . C ONCLUSION We have investiga ted the perform ance char act eris tics of five multi thr ea din g models f or IO driven ne twork applic ations. Th e mode ls diffe r in th e wa y s they assign classes of t asks commonly found in ne twork application s to CPU th read s. These mod els are: sing le- process event- driven (SPED), s taged ev ent- dri ven arc hitec tur e (SEDA), asymmetri c multi- process event - driven (AMPED), symmetri c mul ti- process eve nt driven (SYMPED) and a variat ion of t he S EDA model we call SEDA- S. We have evaluated t he mult ith re adi ng models as applied to a memory database called mdcached , which allows selecting the c onfigura tion of thread s and its code pat hs at progr am star t. For the pur pose of t his w ork we have config ured the server and the benchm ark client to max imiz e th e numbe r of tra ns action s per sec ond, with reduced database si ze and workload. Our investigatio n quantifi es the dif ferences bet ween the mult ith rea di ng models. Thei r r elat ive performa nce is appare nt in t hei r perform ance curves and i n t he max imum performan ce tha t can be ac hieved with each of the m. The best performin g among the evaluated multi thr eadi n g models was SYMPED, which, for the im plemen tat ion on which it was tested, offer s th e best scalability and the best overall performan ce result. We are surpr ised by t he low performan ce o f the SEDA model achi eved a nd will investigat e it a futur e work. Anot her candid ate for future research is t he li mits of scalability of the SYMPED model on more complex databases a nd server h ard ware. VI. R EFERENCES [1] Intel Corp., “Intel ® Multi-Cor e Technolog y” [Online] Available : http:/ /www .int el.c om/ multi- core/inde x.h tm [ Acc es sed : Septem ber 15 2008 ] [2] Intel Cor p., “ Teraflops Re searc h Chi p” [Onlin e] Available: http:/ /tech rese arch .int el.com /artic les/T era-Sca le/1449.htm [A cce sse d: Septe mbe r 15 2008 ] [3] Sun Microsy stems Inc. “Multithreade d Ap plica tion A cce ler ation wit h Chip Multi threading (CMT), Mu ltico re/Multi thread UltraSPARC ® Proc ess ors” , White pap er [Online ] Availa ble: http:/ /www .su n.com /pr oducts /mi croe lec troni cs/c mt_w p.pdf [Ac ces se d: Septe mbe r 15, 2008] [4] OpenSPA RC T2 C ore Micr oarchite cture Spec ifica tion, Sun Microy stems , Inc., http://o pens parc .sun source .net /sp ec s/UST 1- UASup pl- cu rrent -dr aft- P- EXT.pd f, Jan 200 7. [5] G. V. Wi lson, “The Hi story of the Dev elopm ent of Paralle l Computing ” [Online] Availa ble: http://ei .cs. vt. edu/~hist ory /Parallel.ht ml [Acces sed: Septe mbe r 15, 2008] [6] F. Dab ek, N. Zeldov ich, F. Kaashoek , D. Maziere s, R. Morris, “Event- drive n progra mming for robust softw are”, Pr oceedings of the 10th ACM SIGOPS European Wor kshop , 2002. [7] J. K. Ou sterh out, “W hy Threads are a Bad Idea ( for mos t purposes) ”, pres entat ion giv en at the 1996 Useni x Technic al Confe ren ce [Online] Ava ilable: http://ho me. pacbe ll. net/o uster/ thread s.ppt [Acc ess ed : Septe mbe r 16, 2008] [8] G. B anga, J. C. Mog ul, P. Drus chel , “A scalable and explici t delive ry mec hanis m for UNI X”, Proceedings of the 1999 Annual Conference on USEN IX Annual Technical Conference USENI X Asso ciati on, Berkeley , CA, 1999 [9] R. von Behre n, J. Condit , E. Brewer , “Why Eve nts Are A Bad Idea (for high- concurr ency serv ers )“ , Proceedings of the 9th c onference on Hot Topics in Operating Systems - Volume 9 , Hawaii 200 3 [10] P. Li, and S. Zdancewi c, "Com bini ng ev ents and threads for sc alable netw ork serv ice s im plem entat ion and ev aluation of monadic, applica tion- lev el concurre ncy primitiv es" , SIGPLA N Notice s 42 , 6 Ju n. 2007 . [11] I. Voras, D. Basch, M. Žagar, “A High Perfor manc e Memory Database for Web Applicat ion Caches”, Procee ding s of The 14th IEEE Medi terranean Elect rote chnic al Con fer enc e, 2008, p. 163-168 [12] D. Pariag , T. Brecht, A. Harji, P . Buhr, A. Shukla, and D. R. Cherito n, "Comparing the perfor mance of web serv er architecture s," SIGOPS Operating System Review 41, 3 , page s 231-243, Jun. 2007. [13] M. Cr ovella, R. F rangioso, and M. Harch ol- Balter, "Connec tion sche duli ng in web s erv ers" in Proc eed ing s o f t he 2nd U SENI X Sym posiu m on Inte rnet Tech nologi es and Syst ems , Colora do, USA , Oct 1999 . [14] J. Lem on, “Kqueue: A gene ric and scalable event noti ficat ion facili ty”, pres ente d at the BSDCon, Ottawa, CA, 200 0. [ Online ] Available : http:/ /peop le. free bsd.or g/~jle mon/ paper s/kqueue .pdf [Acce ss ed Septe mbe r 29, 2008] [15] J. Roberson , “ULE: A mode rn sch edul er for Free BSD”, Proceedi ng s of BSDCon 2003, p. 17-28, Sep 2003. [16] R. Watson, “Introducti on to Multithreadin g and Multiproce ssi ng in th e Free BSD SMPng Netw ork Stack”, Proce eding s o f the EuroBSDCon 2005 , Nov. 2005. [17] C. Schim mel , UNIX System s for Modern Archi tec tures: Sym metric Multiproc ess ing and C aching for Kern el Progra mmer s, Addis on - Wesl ey Long man Publi shing Co, 1994 VII. B IOGRAPHI ES I. Voras (M'06), was born in Slavons ki Brod, Croatia. He receiv ed Dipl.ing. in Computer Eng ine ering (20 06 ) from t he Faculty of Electr ical Engineer ing and Com puting (FER) at the U niv ersity of Zagr eb, Croatia. Sin ce 2006 he has bee n employ ed by t he Faculty as an Inter net Servi ces Ar chite ct and is a graduate stude nt (PhD) at the same F aculty, whe re he has par ticipated in rese arch projec ts at t he Departme nt of Control and Computer Engin eeri ng. His current rese arch interes ts are in the fields of distribut ed syst ems and netw ork com muni cations , with a spe cial interest in per for manc e optim izati ons. He i s an ac tive mem ber of sev era l Open sourc e pr oject s and i s a regular contri butor to the FreeBSD operating sy ste m. Contact e- mail a ddres s: ivan.v oras@f er.h r. M. Žagar (M'93-SM' 0 4), profes sor of c omput ing at the Univ er sity o f Zagreb, Croatia, receiv ed Dipl .ing., M.Sc.CS and Ph.D.CS degre es, all fro m th e Univ ers ity of Zagreb, Faculty of Elect rical En ginee rin g and Computing (FE R) in 1 97 5, 1978 , 198 5 respe ctiv ely . In 1977 M. Žagar joine d FER and since then has be en inv olve d in diffe re nt scie ntif ic pr oject s and educatio nal activit ies. He rece ive d Britis h Council f ello wsh ip (UMI ST - Manc hest er, 1983 ) and Fulbrig ht fell ows hip (UCSB - Santa Barbara, 19 83 /84). His curre nt prof ess iona l i nteres ts inc lude: c ompute r arc hitect ures, desi gn automation, real- time micr ocom puter s, di stribut ed m easurem ents /co ntro l, ubiquitous/ perv asive com puting, op en co mputi ng (JavaWorld, XML ,..). M. Žagar is a uthor/c o- author o f 5 book s and about 100 scie nti fic/ pro fe ssi onal journal and conf ere nc e paper s. He is senio r mem ber in Croatian Acade my of Engine ering . In 2 006 he r eceiv ed “B est educator” award from the IEEE/CS Cro atia Sect ion.. Cont act e- mail addres s: mario.za gar@fer .hr.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment