허프만 코드를 활용한 순차 적응형 압축 샘플링
본 논문은 허프만 코딩 이론을 기반으로, 이전 측정값에 따라 샘플링 벡터를 동적으로 선택하는 적응형 압축 센싱 방법을 제안한다. s‑희소 n‑차원 신호에 대해 평균 측정 횟수와 복구 비용을 합친 총 비용이 s·log n + 2s 이하임을 증명하고, 1‑희소 경우에는 최적임을 보인다.
저자: Akram Aldroubi, Haichao Wang, Kourosh Zarringhalam
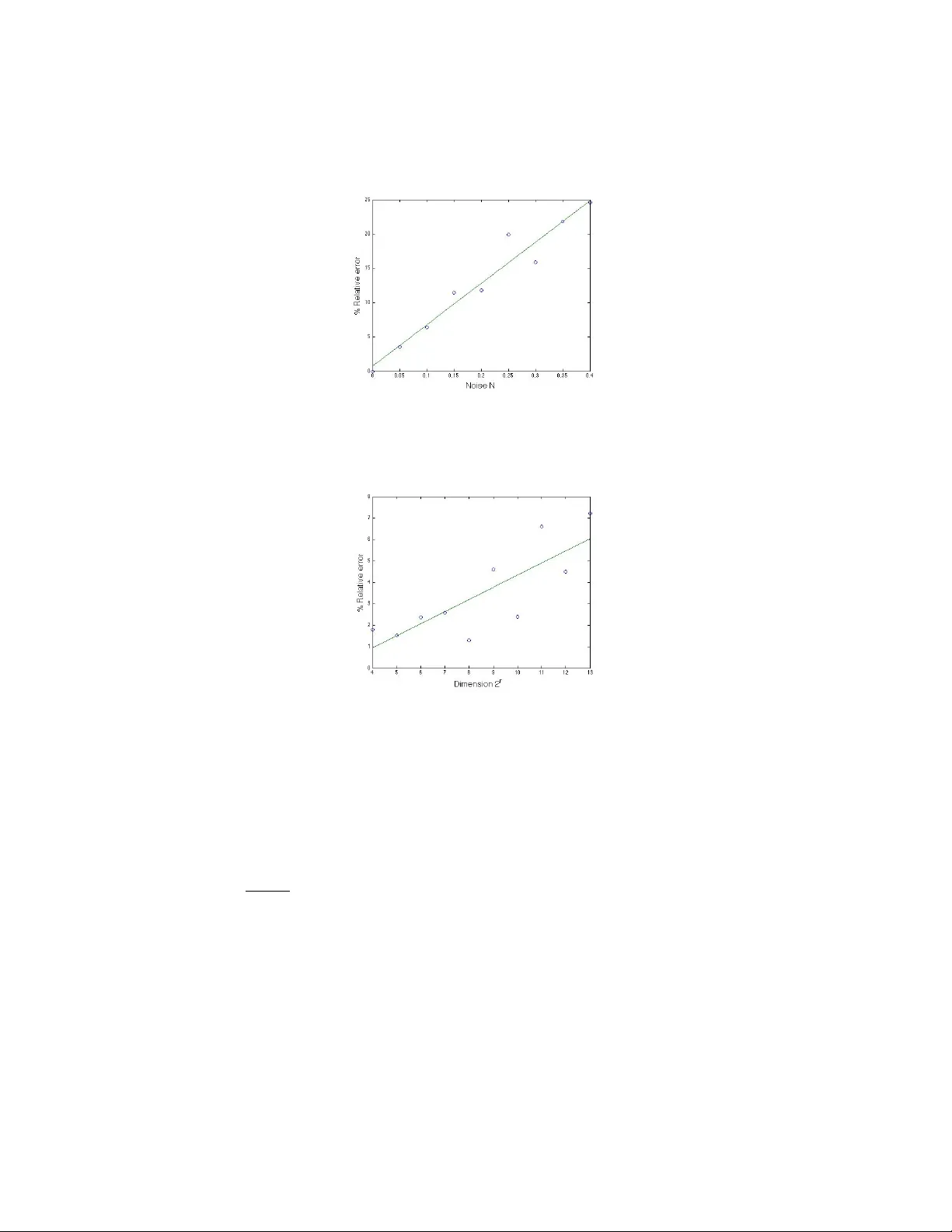
본 논문은 압축 센싱(Compressed Sensing) 분야에서 두 가지 전통적 접근법—기하학적 방법(ℓ₁ 최소화, RIP 기반)과 조합론적 방법(이분 그래프, 바이너리 탐색)—의 한계를 보완하고자, 정보 이론적 관점에서 새로운 적응형 샘플링 프레임워크를 제시한다. 핵심 아이디어는 신호 x∈ℝⁿ 을 s‑희소 확률 변수 X 로 모델링하고, 각 좌표 집합 Λ⊆{1,…,n} 에 대해 “Λ 안에 최소 하나의 비제로 성분이 존재할 확률” q_Λ 를 정의함으로써, 이 확률 분포에 기반한 허프만 트리를 구축하는 것이다.
허프만 트리 구성은 전통적인 허프만 코딩과 동일하게, 현재 노드 집합 중 확률이 가장 작은 두 노드를 선택해 병합하고, 병합된 노드에 새로운 확률 q_{Λ₁∪Λ₂}=q_{Λ₁}+q_{Λ₂} 를 할당한다. 리프는 단일 좌표 {i} 이며, 루트는 전체 좌표 집합 Ω={1,…,n} 이다. 이 과정에서 트리의 깊이는 각 노드 Λ 에 대해 log |Λ| 이상의 상한을 갖는다(정리 3.3, 3.4).
각 내부 노드 Λ 에 대해 두 자식 집합 Λ₁, Λ₂ 가 정의되면, 두 후보 샘플링 벡터 a_Λ=χ_{Λ₁} 또는 χ_{Λ₂} 를 선택한다. 선택 기준은 기대 측정 횟수 ℓ_{Λᵢ}=q_{Λᵢ}(log|Λᵢ|+1)+(1−q_{Λᵢ})(log|Λⱼ|+1) ( i≠j ) 중 더 작은 값을 갖는 쪽이다. 이는 “높은 확률·작은 집합”과 “낮은 확률·큰 집합” 사이의 비용을 균형 있게 고려한다.
알고리즘 1은 위에서 정의한 허프만 샘플링 벡터를 순차적으로 적용한다. 초기 후보 집합 Λ←Ω 에서 시작해, 현재 샘플링 벡터 a_Λ 에 대한 측정값 ⟨a_Λ, x⟩ 가 0이면 Λ←Λ₁, 1이면 Λ←Λ₂ 로 업데이트한다. 이 과정을 |Λ|=1 이 될 때까지 반복하면, 비제로 성분의 정확한 위치 t₁ 와 값 x_{t₁} 을 복구한다. 1‑희소 경우, 모든 좌표가 서로 다른 프리픽스 코드를 갖게 되므로, 허프만 코딩이 최소 평균 코드 길이를 제공한다는 정리 3.2에 의해, 평균 측정 횟수 L₁(X,P) 는 어떠한 이진 샘플링 알고리즘보다 작거나 같다. 따라서 1‑희소 상황에서는 제안 방법이 최적임을 보인다.
s‑희소 일반 경우에는 위 과정을 s번 반복한다. 한 번 비제로 성분을 찾은 뒤, 해당 좌표와 값을 기록하고, 그 성분을 신호에서 제거한 뒤 남은 s‑1‑희소 신호에 대해 동일 절차를 적용한다. 각 단계마다 기대 측정 횟수가 log n 이하임을 Lemma 3.3이 보장하므로, 전체 평균 비용은
E
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기