Sequential adaptive compressed sampling via Huffman codes
There are two main approaches in compressed sensing: the geometric approach and the combinatorial approach. In this paper we introduce an information theoretic approach and use results from the theory of Huffman codes to construct a sequence of binar…
Authors: Akram Aldroubi, Haichao Wang, Kourosh Zarringhalam
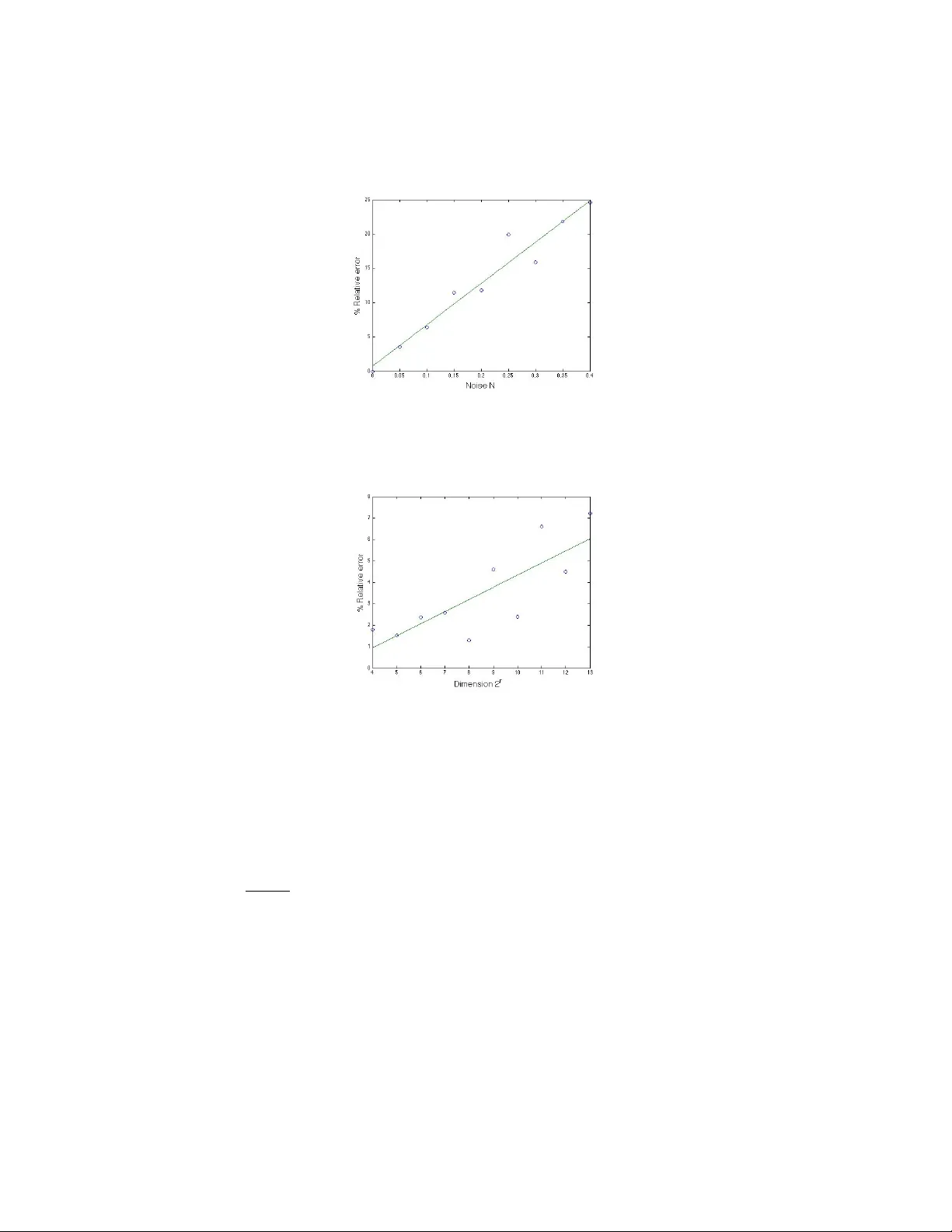
SEQUENTIAL AD APTIVE COMPRESSED SAMPLING VIA HUFFMAN CODES AKRAM ALDR OUBI, HAICHAO W ANG, AND K OUROSH ZARRINGHALAM Abstract. In this pap er w e introduce an information theoretic approac h and use tec hniques from the theory of Huffman co des to construct a sequence of binary sampling v ectors to determine a sparse signal. Unlik e the standard approaches, ours is adaptive in the sense that each sampling vector dep ends on the previous sample results. W e pro ve that the exp ected total cost (num b er of measuremen ts and reconstruction combined) we need for an s - sparse v ector in R n is no more than s log n + 2 s . 1. Introduction Let x b e a v ector in R n and assume that the vector x has at most s << n nonzero comp onents, denoted k x k 0 ≤ s . In compressed sam- pling, the goal is to determine a set of linear functionals ( the sampling functions ) and asso ciated reconstruction algorithms suc h that, if the set of functionals is applied to x , then the reconstruction algorithms will allo w us to find x from the v alues of the functionals (measuremen ts of x ) in a computationally tractable w a y whic h is stable (i.e., that should pro duce a go o d approximation ev en when x is not s -sparse) and robust to noise (i.e. that should pro duce a go o d approximation to x when the measuremen ts (sampling) are corrupted by additive noise). There is a trade off b etw een the num ber of sampling v ectors w e need to acquire x and the computational cost of the reconstruction algorithm which determines x from the samples. Some of the earlier w ork uses an ` 1 minimization for finding x from a set of samples { y i = h a i , x i , i = 1 , . . . , m } where the a i s are vectors in R n , see e.g., [CR06, CR T06, DeV07, Don06, GN03, T ro04]. Letting y = ( y 1 , . . . , y m ) t and A b e the m × n matrix whose ro ws are the v ectors a i , the ` 1 minimization approach finds the unkno wn s -sparse v ector x (i.e., k x k 0 ≤ s ) b y solving the constrained minimization problem (1.1) min k z k ` 1 , Az = y . Key wor ds and phr ases. Sampling, Sparsit y , Compressed Sensing, Huffman co des. The researc h of A. Aldroubi is supported in part b y NSF Gran t DMS-0807464. 1 2 AKRAM ALDROUBI, HAICHAO W ANG, AND KOUR OSH ZARRINGHALAM The solution to the minimization problem pro duces x as its unique solution provided A is an appropriate sampling matrix, e.g., A satis- fying the R estricte d Isometric Pr op erty (RIP). The curren t metho ds for constructing matrices satisfying the needed RIP are probabilistic and pro duce matrices with m = O ( s log( n/ 2 s )) ro ws (i.e., we need m = O ( s log ( n/ 2 s )) sampling vectors). The deterministic construc- tion of a matrix A satisfying the needed RIP prop ert y for arbitrary n ( m << n ) is still op en. Finding x via the ` 1 minimization problem in v olves linear programing with n v ariables and m constraints whic h can b e computationally exp ensive. Matc hing pursuits (OMP , ROMP , CoSaMP . etc., see [NT08, NV09] and the reference therein) form another class of sampling and recon- struction algorithms for finding an s -sparse signal x from the measure- men ts y = Ax . These algorithms are iterative in nature and view the column of A as a dictionary for the reconstruction of x . A t ev ery step of the reconstruction algorithms, a certain num ber of columns (col- umn indices) are c hosen in order to minimize an equation of the form k r n − Ax n k 2 , where r n = y − Ax n − 1 is a residual from the previous step. The most p erforman t of these t yp e of reconstruction algorithms is relatively fast, stable, and robust to noise. Ho w ev er, similar to the ` 1 minimization algorithms, it requires a sampling matrix A satisfying the needed RIP . As b efore only probabilistic metho ds are known, and they pro duce matrices with m = O ( s log ( n/ 2 s )) rows that satisfy the RIP with high probabilit y . Other approac hes for compressed sampling are com binatorial. A sampling matrix A is constructed using bipartite graphs, such as ex- pander graphs, and the reconstruction finds an unkno wn s -sparse vec- tor x using binary searc h metho ds, see e.g. [BGIKS08, GKMS03, D WB05, SBB06b, SBB06a, GSTV06, GSTV07, XH07] and the ref- erences therein. T ypically , the matrix A has binary entries. There exist fast algorithms for finding the solution x from the measurements (t ypically sublinear). How ev er, the construction of A is still difficult to pro duce. There are emerging new approaches for adaptive metho ds in com- pressed sampling. One approach uses a Ba yesian metho d com bined a gaussian mo del for the measurements and a Laplacian mo del for the sparsit y [JX C08]. The sampling vectors are c hosen b y minimizing a differen tial en tropy . Another approac h uses is a type of binary search algorithm that uses back pro jection and blo c k adaptive sampling to fo cus on the p ossible nonzero comp onen t (see [HCN09] the references therein). SEQUENTIAL ADAPTIVE COMPRESSED SAMPLING VIA HUFFMAN CODES 3 The new approach w e presen t is information theoretic and uses to ols from the theory of Huffman co des to develop a deterministic construc- tion of a sequence of binary sampling vectors a Λ , i.e., the entries of a Λ consist of 0 or 1. Moreov er, unlike standard approaches, the sampling pro cedure is adaptiv e. W e assume that the signal x ∈ R n is an instance of a v ector random v ariable X = ( X 1 , . . . , X n ) t and w e construct the i -th row a i of A using the sample y i − 1 = h a i − 1 , x i . Our goal is to mak e the av erage num b er of samples needed to determine a signal x as small as p ossible, and to make the reconstruction of x from those samples as fast as p ossible. W e take adv antage of the probability dis- tribution of the random v ector X to minimize the a v erage n um b er of samples needed to uniquely determine the unknown signal x . In our metho d, rather than constructing a fixed set of sampling vectors form- ing the rows of a single sampling matrix A for all p ossible signals, w e construct s sequences of sampling vectors. Eac h sequence fo cuses on finding exactly one nonzero comp onen t of the signal x . It is remark able that the exp ected total cost of the com bined sam- pling and reconstruction algorithms of an s -sparse vector x is no more than s log n + 2 s . If no information is a v ailable ab out the probabilit y distribution of the random vector X , w e can alw ays assume that w e ha v e a uniform distribution, in whic h case the total cost of the com- bined sampling and reconstruction algorithms of an s -sparse v ector x is equal to s log n + 2 s even if the uniform assumption is erroneous. This pap er is organized as follo ws: In Section 2 we introduce the basic notation and definitions for sparse random v ectors and trees. The new notion of Huffman tree and Huffman sampling vectors are in tro duced in Section 3.1 and 3.2. In Sections 3.3 and 3.4, we describ e an information theoretic metho d for finding s -sparse vectors in R n . In Section 3.5 w e describ e a v ariation for finding s -sparse v ectors from noisy measuremen ts. Section 4 is devoted to examples, sim ulations, and testing of the algorithms on synthetic data. 2. not a tion and preliminaries In this section we introduce the necessary notations and preliminaries needed in subsequen t sections. 2.1. Sparse random v ectors. (1) W e will use the notation X = ( X 1 , . . . , X n ) t to denote a v ector of n random v ariables. An instance x ∈ R n of X will b e called a signal . (2) W e will say that a signal x ∈ R n has sparsit y s ≤ n if x has at most k nonzero comp onents ( k x k 0 ≤ s ). 4 AKRAM ALDROUBI, HAICHAO W ANG, AND KOUR OSH ZARRINGHALAM (3) Let Ω = { 1 , . . . , n } b e the set of all indices, and Λ ⊂ Ω b e a subset of indices. Then P Λ = P (Λ) will denote the probabilit y of X having nonzero components exactly at co ordinates indexed b y Λ, i.e., P Λ = P r { X i 6 = 0 , i ∈ Λ ; X i = 0 , i ∈ Λ c } . Here Λ c denotes the complemen t of Λ. (4) The pair ( X, P ) will b e used to denote the random v ector X together with the probabilit y mass function P on the sample space 2 Ω = 2 { 1 ,...,n } . Thus ob viously P Λ P Λ = 1. (5) W e will sa y that a random v ector X is s sparse if P Λ = 0 for all Λ with cardinalit y strictly larger than s , i.e., #(Λ) > s implies P Λ = 0. (6) W e will need the probabilities q Λ = q (Λ) = P r ( E Λ ) for the ev en ts E Λ = { X i 6 = 0 , for some i ∈ Λ } , which is the probabilit y that at least one of the components of X with index in Λ is nonzero. Note that q can b e computed from P by (2.1) q Λ = X η ∩ Λ 6 = ∅ P η . 2.2. T rees. (1) W e consider finite ful l binary tr e es in whic h ev ery node has zero or t w o children. (2) The r o ot of the tree is the no de with no parent no des. (3) A le af is a no de with no c hildren. (4) A left (right) subtr e e of a no de v in a ro oted binary tree is the tree whose ro ot is the left (righ t) c hild of this no de v . (5) The set of all no des that can b e reac hed from the ro ot by a path of length L are said to b e at level L . 2.3. Other notations. (1) The notation χ Λ will denote the c haracteristic function of a set Λ, i.e., χ Λ ( i ) = 1 for i ∈ Λ and χ Λ ( i ) = 0 for i / ∈ Λ. (2) F or a set Λ, | Λ | will denote its cardinalit y . 3. Theor y In this section w e describ e our approach explicitly . 3.1. Huffman tree. Let ( X , P ) b e a s -sparse random v ector X in R n together with the probability mass function P on the sample space 2 Ω = 2 { 1 ,...,n } the set of all subsets of Ω = { 1 , . . . , n } . W e define a Huffman tree to b e a binary tree whose lea v es are the sets { 1 } , . . . , { n } . W e asso ciate probabilities q { 1 } , . . . , q { n } to these no des resp ectively . The Huffman tree is constructed from the leav es to the ro ot as follo ws: SEQUENTIAL ADAPTIVE COMPRESSED SAMPLING VIA HUFFMAN CODES 5 Figure 1. Huffman T ree for the 2-sparse random v ector X ∈ R 4 . Supp ose that the no des at the i -th step are Λ 1 , . . . , Λ s . Let i and j b e suc h that q Λ i = min 1 ≤ λ ≤ s q Λ λ , q Λ j = min 1 ≤ λ ≤ s,λ 6 = i q Λ λ . Then, the no des at the ( i + 1)-th step are obtained by replacing Λ i and Λ j with Λ i ∪ Λ j in the list of the no des at the i -th step and the probabilit y asso ciated to the no de Λ i ∪ Λ j , will b e q Λ i ∪ Λ j , i.e., at each step the tw o no des with smallest probabilities are combined. An illus- trativ e example is sho wn b elow. Example 3.1. Assume that X ∈ R 4 is a 2 -sp arse r andom ve ctor with pr ob ability mass function P define d by: P ∅ = 0 . 02 , P { 1 } = 0 . 07 , P { 2 } = 0 . 05 , P { 3 } = 0 . 03 , P { 4 } = 0 . 1 , P { 1 , 2 } = 0 . 31 , P { 1 , 3 } = 0 . 2 , P { 1 , 4 } = 0 . 03 , P { 2 , 3 } = 0 . 06 , P { 2 , 4 } = 0 . 12 , P { 3 , 4 } = 0 . 01 . The no des at the first step ar e: { 1 } , . . . , { 4 } . Using e quation 2.1, we get that: q { 1 } = P { 1 } + P { 1 , 2 } + P { 1 , 3 } + P { 1 , 4 } = 0 . 61 . Similarly, q { 2 } = 0 . 54 , q { 3 } = 0 . 3 , and q { 4 } = 0 . 26 . Ther efor e the no des at the se c ond step ar e { 1 } , { 2 } , { 3 , 4 } . Also q { 3 , 4 } = 0 . 55 and henc e the no des at the thir d step ar e { 1 } , { 2 , 3 , 4 } . The r o ot note is { 1 , 2 , 3 , 4 } with pr ob ability q { 1 , 2 , 3 , 4 } = 1 . This c ompletes the Huffman tr e e (Se e Figur e 1). 3.2. Huffman sampling vectors. In this section we in tro duce Huff- man sampling v ectors. Let ( X , P ) b e as in the previous section. Our goal is to find a signal x which is an instance of X using, on av erage, 6 AKRAM ALDROUBI, HAICHAO W ANG, AND KOUR OSH ZARRINGHALAM a minimu m num b er of samples. The a verage num ber of samples is measured b y (3.1) L ( X , P ) = X Λ P Λ ` Λ , where ` Λ is the n umber of samples for finding one nonzero comp onent of x whose comp onen ts x i 6 = 0 for i ∈ Λ and x i = 0 for i ∈ Λ c . As mentioned b efore, w e first fo cus on finding one nonzero comp o- nen t, if it exists. Other nonzero comp onen ts are then iteratively found one at a time in a similar manner until all of the nonzero comp onents are exhausted. W e first construct a Huffman tree asso ciated with the random v ector X . Each no de Λ which is not a leaf has tw o children Λ 1 and Λ 2 . Note that Λ 1 ∩ Λ 2 = ∅ and Λ 1 ∪ Λ 2 = Λ. W e denote ` Λ 1 = q Λ 1 (log | Λ 1 | + 1) + (1 − q Λ 1 )(log | Λ 2 | + 1) and ` Λ 2 = q Λ 2 (log | Λ 2 | + 1) + (1 − q Λ 2 )(log | Λ 1 | + 1). W e asso ciate a sampling vector to such no des Λ b y: (3.2) a Λ = χ Λ 1 if l Λ 1 ≤ l Λ 2 , χ Λ 2 if l Λ 1 > l Λ 2 , i.e., for l Λ 1 ≤ l Λ 2 , we hav e a Λ ( i ) = 1 for i ∈ Λ 1 and a Λ ( i ) = 0 for i ∈ Ω − Λ 1 , and for l Λ 1 > l Λ 2 w e ha v e a Λ ( i ) = 1 for i ∈ Λ 2 and a Λ ( i ) = 0 for i ∈ Ω − Λ 2 . The choice of the sampling vector in (3.2) can b e seen as follows: Since our goal is to find the nonzero comp onent as quic kly as p ossible, it seems that we would need a Λ = χ Λ i for the set Λ i with the highest probabilit y q Λ i , i = 1 , 2. Ho w ever, the set Λ i with the highest proba- bilit y q Λ i ma y also hav e a large num ber of elements. Th us the choice should b e a compromise b et w een the size of the set and its probability . This particular c hoice of a Λ will b e apparen t from the theorems and their pro ofs b elow. 3.3. Determination of a sparse v ector x using Huffman sam- pling v ectors. Let x be an s -sparse signal in R n whic h is an instance of ( X , P ) (w e will write x ∼ ( X , P )). W e mak e the additional assumption that the conditional probabilit y P r ( P i ∈ Λ X i 6 = 0 | X i 6 = 0 , i ∈ Λ) = 0 holds for any Λ ⊂ Ω (recall that Ω = { 1 . . . . , n } ). This is a natural condition if the random v ariables X i , i = 1 , . . . , n , in the random vector X do not ha ve a p ositive mass concen tration except p ossibly at zero. 3.3.1. Finding a nonzer o c omp onent. Algorithm 1 b elo w is used to find the p osition and the corresp onding v alue of one of the nonzero comp o- nen ts of x (if an y). SEQUENTIAL ADAPTIVE COMPRESSED SAMPLING VIA HUFFMAN CODES 7 Algorithm 1. (1) Initialization: Λ = Ω ; (2) R ep e at until | Λ | = 1 if h a Λ , x i 6 = 0 , Λ = Λ 1 else Λ = Λ 2 end r ep e at (3) Output the (only) element t 1 ∈ Λ (4) Output x t 1 = h χ { t 1 } , x i Remark 1. (i) If the ve ctor x = 0 , then the algorithm wil l find an output x t 1 = 0 , otherwise it wil l output the value x t 1 of one of the nonzer o c omp onents of x and its index t 1 . (ii) Note that the last inner pr o duct output in (4) is not always ne c- essary sinc e we have al l the information ne e de d to find x t 1 fr om the samples and the value of t 1 . However, this would involve solving a line ar system of e quations obtaine d fr om the sampling scheme. Thus this one extr a sample c an b e c onsider e d as r e c on- struction step. (iii) Note that the sampling ve ctors dep end on the instanc e x , i.e., the sampling ve ctors ar e adaptive. (iv) The numb er of p ossible sampling ve ctors is e qual to the numb er of no des in the Huffman tr e e, but only a subset of these ve ctors is use d to determine a nonzer o c omp onent of a given instanc e ve ctor x . (v) If P ( X = 0) > 0 , then we cho ose the first sampling ve ctor a = (1 , 1 , . . . , 1) . If h a, x i = 0 we ar e done. Otherwise we pr o c e e d with Algorithm 1. The first observ ation is that Algorithm 1 is optimal for 1-sparse v ectors. This should not b e a surprise since the algorithm was inspired b y the theory of Huffman co des. W e ha v e Theorem 3.2. Given a 1-sp arse ve ctor x ∼ ( X , P ) in R n . Then the aver age numb er of samples L 1 ( X , P ) ne e de d to find x using Algorithm 1 is less than or e qual to the aver age numb er of samples L A ( X , P ) for finding x using any algorithm A with binary sampling ve ctors. Pr o of. Let E = { e i } n i =1 b e the canonical basis for R n . W e first note that for an y sampling algorithm with binary sampling vectors, the num ber of samples required to determine any nonzero m ultiple αe i of e i ( α ∈ R ) is equal to the n um b er required to determine e i . Hence for the remainder of this pro of w e will assume that x is binary , i.e., x is one of the canonical vectors e i . Since an y sampling v ector a from an algorithm 8 AKRAM ALDROUBI, HAICHAO W ANG, AND KOUR OSH ZARRINGHALAM A is binary , the inner pro duct h a, x i is either zero or one, i.e., binary . F or each e i , i ∈ Ω = { 1 , . . . , n } , a binary algorithm uses a sequence of v ectors { a i 1 , . . . , a i ` i } where ` i is the num b er of sampling vectors needed to determine e i . W e associate to eac h e i the binary sequence c i = y i 1 y i 2 . . . y i ` i where y i j = h a i j , e i i . In this wa y eac h canonical vector e i is asso ciated to a unique sequence c i , c i 6 = c j if i 6 = j . Hence c i is a binary co de for the vectors of the canonical basis of R n . The co de is a prefix (also kno wn as instan taneous co de, i.e., no co de is a prefix of any other co de [CT91]) since a binary algorithm terminates after finding the nonzero comp onent (whic h corresp ond to the shorter code). Since x is 1 sparse, w e ha v e that q i = P i whic h is the probabilit y of comp onent i b eing nonzero and all other comp onen ts b eing zero. Hence for eac h algorithm A with binary sampling v ectors, we asso ciate a prefix code for E = { e i } n i =1 . Consequently , the a v erage num ber of samplings required in this algorithm A is the same as the av erage length of the co de: L A ( X , P ) = n P i =1 ` i P i . F rom the construction, Algorithm 1 is asso ciated with the Huffman code whose a v erage length is the shortest. Hence the a v erage num ber of samples L 1 ( X , P ) ≤ L A ( X , P ) for any A . The 1-sparse case is a sp ecial case. It is optimal b ecause the sampling sc heme can b e asso ciated exactly with the Huffman co des and we hav e that q Λ = P Λ and P i q { i } = P i P { i } = 1. In fact, the choice of a Λ in (3.2) can b e c hosen to b e either χ Λ 1 or χ Λ 2 indep enden tly of the v alues of ` Λ 1 , ` Λ 2 . Ho wev er, for the general s -sparse case, w e do not ha v e q Λ = P Λ an ymore, and the sampling v ectors cannot b e asso ciated with Huffman co des directly . Th us for the s -sparse case, the a verage n um b er of sampling vectors is not necessarily optimal and we need to estimate this n um b er to hav e confidence in the algorithm. F rom the construction of the Huffman tree in Section 3.1, it is not difficult to see that there is at most one no de Λ (called sp e cial no de ) with c hildren Λ 1 and Λ 2 suc h that ( 1 2 − q Λ 1 )( 1 2 − q Λ 2 ) < 0, i.e., except for p ossibly the sp ecial node, all other no des ha v e the prop ert y that q Λ 1 , q Λ 2 are either b oth larger than 1 / 2 or b oth smaller than 1 / 2. Thus, a Huffman tree can at most ha v e one sp ecial no de. W e ha ve the follo wing lemmas: Lemma 3.3. F or any fixe d no de Λ with childr en Λ 1 and Λ 2 , if Λ is not a sp e cial no de, then min { ` Λ 1 , ` Λ 2 } ≤ log | Λ | . Pr o of. Without loss of generalit y , w e assume that | Λ 1 | ≤ | Λ 2 | . Hence | Λ 1 | | Λ | ≤ 1 2 and | Λ 2 | | Λ | ≥ 1 2 . SEQUENTIAL ADAPTIVE COMPRESSED SAMPLING VIA HUFFMAN CODES 9 Consider the function f q ( x ) = x q (1 − x ) 1 − q for x ∈ [0 , 1] and q ∈ [0 , 1]. Easy computations sho w that (3.3) f q ( x ) ≤ 1 2 , for q ≤ 1 2 and x ≥ 1 2 , and (3.4) f q ( x ) ≤ 1 2 , for q ≥ 1 2 and x ≤ 1 2 . Since Λ is not a sp ecial no de, w e hav e that ( q Λ 1 − 1 2 )( q Λ 2 − 1 2 ) ≥ 0. If q Λ 1 ≤ 1 2 and q Λ 2 ≤ 1 2 , then using the fact that | Λ 2 | | Λ | ≥ 1 2 and (3.3), w e get f q Λ 2 ( | Λ 2 | | Λ | ) ≤ 1 2 , that is ( | Λ 2 | | Λ | ) q Λ 2 (1 − | Λ 2 | | Λ | ) 1 − q Λ 2 ≤ 1 2 , whic h implies that 2 | Λ 2 | q Λ 2 | Λ 1 | 1 − q Λ 2 ≤ | Λ | , after taking the log function on b oth sides, w e ha ve ` Λ 2 ≤ log | Λ | . A similar calculation for the case q Λ 1 ≥ 1 2 and q Λ 2 ≥ 1 2 yields ` Λ 1 ≤ log | Λ | . In either case, w e ha ve that min { ` Λ 1 , ` Λ 2 } ≤ log | Λ | . F or general no de, we hav e the following, Lemma 3.4. F or any fixe d no de Λ with childr en Λ 1 and Λ 2 , we have that min { ` Λ 1 , ` Λ 2 } ≤ log | Λ | + 1 . Pr o of. F or an y x ∈ [0 , 1] and any q ∈ [0 , 1] w e ha v e that f q ( x ) = x q (1 − x ) 1 − q ≤ 1. W e use this inequality for x = | Λ 1 | | Λ | and q = q Λ 1 or x = | Λ 2 | | Λ | and q = q Λ 2 to obtain the result. Lemma 3.5. Given a nonzer o s -sp arse ve ctor x ∼ ( X , P ) in R n . If the Huffman tr e e asso ciate d with x has no sp e cial no de, then the av- er age numb er of samples L ne e de d to find the p osition of one nonzer o c omp onent of x using Algorithm 1 is at most log n . Pr o of. W e will use induction on n to pro ve this lemma. Supp ose Λ = { 1 , . . . , n } and Λ has children Λ 1 and Λ 2 . F or n = 2, | Λ | = 2, we only need one vector χ Λ 1 or χ Λ 2 to determine the p osition of one nonzero comp onen t of x . Hence the lemma holds trivially for this case. 10 AKRAM ALDR OUBI, HAICHAO W ANG, AND KOUR OSH ZARRINGHALAM No w assume the lemma is true for n = k , k − 1 , . . . , 2, w e wan t to sho w it is also true for n = k + 1. If | Λ | = k + 1, w e m ust hav e | Λ 1 | ≤ k and | Λ 2 | ≤ k . Without loss of generality , supp ose ` Λ 1 ≤ ` Λ 2 . By Algorithm 1, a Λ = χ Λ 1 . Then with probabilit y q Λ 1 , we ha v e h a Λ , x i 6 = 0, in which case we need (on a v erage) another L Λ 1 sampling v ectors. With probability 1 − q Λ 1 , we ha v e h a Λ , x i = 0, and w e need (on a v erage) another L Λ 2 sampling v ectors. By the induction h yp othesis, we hav e L Λ 1 ≤ log | Λ 1 | and L Λ 2 ≤ log | Λ 2 | . Since by assumption the tree has no sp ecial no de,using Lemma 3.3 w e deduce that the a verage n umber of sampling v ectors we need is L = q Λ 1 (1 + L Λ 1 ) + (1 − q Λ 1 )(1 + L Λ 2 ) ≤ q Λ 1 (1 + log | Λ 1 | ) + (1 − q Λ 1 )(1 + log | Λ 2 | ) = ` Λ 1 ≤ log | Λ | = log k . W e are now ready to find an upp er b ound on the a v erage num ber of sampling v ectors needed for finding the p osition of one nonzero com- p onen t in an s -sparse signal using Algorithm 1. Denoting b y T Λ the subtree with Λ as the ro ot, w e ha ve Theorem 3.6. Given a nonzer o s -sp arse ve ctor x ∼ ( X , P ) in R n the aver age numb er of samples L ne e de d to find the p osition of one nonzer o c omp onent of x using Algorithm 1 is at most log n + 1 . Pr o of. W e will use induction. The lemma holds trivially for n = 2. No w assume the lemma is true for n = k , k − 1 , . . . , 2, w e wan t to sho w it is also true for n = k + 1. If | Λ | = k + 1, we must ha ve | Λ 1 | ≤ k and | Λ 2 | ≤ k . Without loss of generalit y , supp ose ` Λ 1 ≤ ` Λ 2 . By Algorithm 1, the av erage num ber L of sampling v ectors needed is (3.5) L = q Λ 1 (1 + L Λ 1 ) + (1 − q Λ 1 )(1 + L Λ 2 ) . Since the Huffman tree can hav e at most one sp ecial no de, w e consider three cases: Case(1): If the ro ot of the tree Λ = { 1 , . . . , n } is a sp ecial no de and Λ 1 , Λ 2 are its c hildren. Then the subtrees T Λ 1 and T Λ 2 ha v e no sp ecial no des. Th us by Lemma 3.5, we hav e that L Λ 1 ≤ log | Λ 1 | and L Λ 2 ≤ log | Λ 2 | . SEQUENTIAL ADAPTIVE COMPRESSED SAMPLING VIA HUFFMAN CODES 11 F rom Lemma 3.4, ` Λ 1 ≤ log | Λ | + 1. Th us w e hav e that L = q Λ 1 (1 + L Λ 1 ) + (1 − q Λ 1 )(1 + L Λ 2 ) ≤ q Λ 1 (1 + log | Λ 1 | ) + (1 − q Λ 1 )(1 + log | Λ 2 | ) = ` Λ 1 ≤ log | Λ | + 1 = log( k + 1) + 1 . Case(2): If Λ = { 1 , . . . , n } is not a sp ecial no de and the subtree T Λ 1 has no sp ecial no de, from Lemma 3.5, w e hav e L Λ 1 ≤ log | Λ 1 | . Since | Λ 2 | ≤ k , from the induction hypothesis, we ha ve L Λ 2 ≤ log | Λ 2 | + 1. F rom Lemma 3.3, ` Λ 1 ≤ log | Λ | . Thus we hav e that L = q Λ 1 (1 + L Λ 1 ) + (1 − q Λ 1 )(1 + L Λ 2 ) ≤ q Λ 1 (1 + log | Λ 1 | ) + (1 − q Λ 1 )(1 + log | Λ 2 | + 1) = ` Λ 1 + 1 − q Λ 1 ≤ log | Λ | + 1 = log( k + 1) + 1 . Case(3): If Λ = { 1 , . . . , n } is not a sp ecial no de and the subtree T Λ 2 has no sp ecial no de, then the same computation as in Case (2) giv es L ≤ log( k + 1) + 1. 3.3.2. Iter ative step for finding another nonzer o c omp onent. F or every subset ω ⊂ Ω with | ω | < s w e let P ω Λ = P ω (Λ) denote the conditional probabilities P r X i 6 = 0 , i ∈ Λ and X i = 0 , i ∈ Ω − { Λ ∪ ω }| X i 6 = 0 , i ∈ ω , for an y Λ ⊂ Ω − ω . Similar to Section 3.1, we let q ω Λ = q ω (Λ) = P r ( E ω Λ ) for the even ts E ω Λ = { X i 6 = 0 , for some i ∈ Λ | X i 6 = 0 , i ∈ ω } , whic h is the conditional probabilit y that at least one of the comp onen ts of X with index in Λ ⊂ Ω − ω is nonzero given that X i 6 = 0 for i ∈ ω . Using the same pro cedure as in Section 3.1, build a Huffman tree with leav es { i } , i ∈ Ω − ω with probabilities q ω Λ . Note that this tree has n − | ω | leav es. As ab ov e (see (3.2)), we assign a sampling vector a ω Λ ∈ R n to ev ery no de Λ which is not a leaf. Note that from the construction of a ω Λ w e ha v e that a ω Λ ( i ) = 0 for i ∈ ω . Let k < s b e the n um b er of nonzero comp onents of x that are found and let ω = { t 1 , . . . , t k } b e the set of corresp onding indices. The al- gorithm for finding the ( k + 1)-th nonzero comp onen t of x (if an y) is essen tially the same as in Algorithm 1. 3.4. Algorithm for finding all nonzero comp onen ts of x . The general algorithm for finding the s -sparse vector x ∼ ( X , P ) whic h is an instance of the s -sparse random v ector ( X , P ), can no w b e describ ed as follo ws: 12 AKRAM ALDR OUBI, HAICHAO W ANG, AND KOUR OSH ZARRINGHALAM Algorithm 2. Initialization: s=1; ω = ∅ ; R ep e at until k > s or x t k = 0 (1) Λ = Ω − ω ; (2) r ep e at until | Λ | = 1 if h a Ω − ω Λ , x i 6 = 0 , Λ = Λ 1 ; else Λ = Λ 2 ; end r ep e at (3) Output the (only) element t k ∈ Λ ; (4) Output x t k = h χ { t k } , x i ; (5) ω = ω ∪ { t k } ; (6) k = k + 1 ; end r ep e at Algorithm 2 rep eats Algorithm 1 at most s times and adds one extra sample to determine the v alue of eac h nonzero comp onent once its p osition is known. Th us, as a corollary of Theorem 3.6 we immediately get Corollary 3.7. Given a nonzer o s -sp arse ve ctor x ∼ ( X , P ) in R n , the aver age numb er of sampling ve ctors L ne e de d to find al l nonzer o c omp onents of x using Algorithm 2 is at most s log n + 2 s . Remark 2. (i) Cor ol lary 3.7 states that the upp er b ound on the exp e cte d to- tal c ost (numb er of me asur ements and r e c onstruction c ombine d) that we ne e d for an s -sp arse ve ctor in R n using Algorithm 2 is no mor e than s log n + 2 s . (ii) If the pr ob ability distribution P is uniform then the c ombine d c ost of the me asur ements and r e c onstruction is exactly s log n + 2 s . 3.5. Noisy measurements. In practice, the measuremen ts { y i } ma ybe corrupted b y noise. Typically the noise is mo deled as additive and uncorrelated : y Λ = h x, a Λ i + η Λ (see [CW08]). F or this case the con- dition Az = y in (1.1) for the ` 1 minimization tec hnique is mo dified to k Az − y k 2 ≤ where is of the same order as the standard de- viation σ η of the noise. With this mo dification, the ` 1 minimization tec hnique yields a minimizer x ? satisfying k x ? − x k 2 ≤ C where C is a constan t indep enden t of x . Similar mo difications are made for the other tec hniques, e.g., ` q minimization (see [FL09]). Similarly , our algorithm needs to b e mo dified accordingly to deal with noisy measuremen ts case. Algorithm 2 can b e mo dified by c hang- ing the statemen t h a Ω − ω Λ , x i 6 = 0 to the statemen t |h a Ω − ω Λ , x i| > T , SEQUENTIAL ADAPTIVE COMPRESSED SAMPLING VIA HUFFMAN CODES 13 where the threshold T is of the same order as the standard deviation of η . Consider the mo del Y = X + η where the signal X ∼ N (0 , σ X ) and the noise η ∼ N (0 , σ η ). Then Y ∼ N (0 , q σ 2 X + σ 2 η ). W e set the threshold in Algorithm 2 to b e T = E ( | η | ) = 2 σ η √ 2 π , and consider a measure of error (for one sample) given by the probability p ( e ) = P | Y | < T and | X | ≥ T | + P | Y | ≥ T and | X | < T | After easy computation, w e ha ve that p ( e ) = erf( σ η √ π σ X ) + erf( σ η √ π σ Y ) − erf( σ η √ π σ X )erf( σ η √ π σ Y ) , where erf( x ) = 2 √ π R x 0 e − t 2 dt is the error function. Using the T a ylor series, we obtain p ( e ) = 4 t π − 4 t 2 π 2 + o ( t 2 ) , where t = σ η σ X is the ratio of the standard deviations of the noise and the signal. Th us, for a relativ ely large signal to noise ratio, t will b e small and we get that the probability of at least one error in the sampling-reconstruction for an s sparse v ector is b ounded ab ov e b y the quan tit y p s ( e ) = 1 − (1 − p ( e )) s (log n +1) = s (log n +1) p ( e )+ o ( p ( e ) 2 ) ≈ s (log n +1) 4 t π . It can b e seen that p s ( e ) is essentially linear in the sparsit y s , linear in t and logarithmic in the dimension n, as can also b e seen in the sim ulations b elow. 3.6. Stabilit y and compressible signals. One of the adv an tage of the standard compressed sensing metho ds is that they pro duce almost optimal results for signal that are not s -sparse. F or example, if we let β 1 s ( x ) denote the smallest p ossible error (in the ` 1 norm) that can b e ac hiev ed by appro ximating a signal x ∈ R n b y an s -sparse v ector z : β s ( x ) := inf {k x − z k 1 , k z k 0 ≤ s } , then the vector x ? solution to the ` 1 reconstruction metho d (1.1) is quasi-optimal in the sense that k x − x ? k 1 ≤ C β s ( x ) for some constant C indep endent of x . Since for a given x ∈ R n , the quantit y β 1 s ( x ) is the ` 1 norm of the smallest n − s comp onen ts of x , the previous result means that if x is not s -sparse, then x ? is close to the s -sparse vector x s whose comp onen ts are the s -largest comp onents of x . In particular, if x is sparse, then x ? = x . 14 AKRAM ALDR OUBI, HAICHAO W ANG, AND KOUR OSH ZARRINGHALAM Clearly , our current approac h cannot pro duce similar results since, in its curren t form, our metho d do es not hav e any incentiv e for finding the largest non-zero comp onen ts. How ev er x can b e decomp osed in to x = x s + ( x − x s ), and a measuremen t y = h a Λ , x s i + η Λ where η Λ = h a Λ , , ( x − x s ) i can b e view ed as noise. Thus, a p ossible mo dification of the metho d is to replace h a Ω − ω Λ , x i 6 = 0 b y |h a Ω − ω Λ , x i| > ∆ k (Λ) in Algorithm 2 where ∆ k (Λ) depends on the c haracteristics of the random v ariables X i , and Λ. Ho w ev er, such mo dification will not b e studied in this pap er. 4. Examples and Simula tions In this section, w e pro vide some examples and test our algorithm on synthetic data. In the first exp eriment w e use an exp onen tial dis- tribution to generate the p osition of the nonzero comp onents of the s -sparse vectors, and uniform distribution for their v alues. The signal x is generated b y first generating an in teger index i ∈ [1 , n ] using the ex- p onen tial p df with a mean of 10, and then constructing the comp onent x ( i ) = A ( r and − 0 . 5), where r and is a random v ariable with uniform distribution in [0 , 1]. In all the other exp eriments, we use a uniform probabilit y distribution for b oth signal and noise. The signal x is gen- erated b y first generating an integer index i ∈ [1 , n ] with a uniform dis- tribution, and then constructing the comp onent x ( i ) = A ( r and − 0 . 5), where r and is a random v ariable with uniform distribution in [0 , 1]. This pro cess is rep eated s times for s sparse signals. Eac h additiv e noise η Λ , is generated b y η Λ = N ∗ ( r and − 0 . 5) and added to the measuremen t y Λ . All the exp erimen ts are done using Matlab 7.4 on a Macin tosh MacBo ok Pro 2.16 GHz In tel Core Duo pro cessor 1GB 667 MHz RAM. 4.1. Noiseless cases. Sim ulation 4.1. Our first exp eriment is a sp arse ve ctor x ∼ ( X, P ) in a sp ac e of dimension n = 2 15 with an exp onential p df with me an 10 for the lo c ation of the nonzer o c omp onents and a uniform distribution for the values of the c omp onents as describ e d ab ove. We have teste d our algorithm with s = 1 , 3 , 5 , 7 , 9 , 11 , 13 . The me an and varianc e of the numb er of sampling ve ctors ne e de d for the various sp arsity s (for the c ombine d sampling and r e c onstruction) is shown is T able 1. Sim ulation 4.2. Our se c ond example is a sp arse r andom ve ctor X in a sp ac e of dimension n = 1024 with a uniform pr ob ability distribution. We have teste d our algorithm on an example with n = 1024 , s = 1 , 25 , 50 , 75 , 100 , 125 , 150 . The time for finding the ve ctor x for the SEQUENTIAL ADAPTIVE COMPRESSED SAMPLING VIA HUFFMAN CODES 15 s 1 3 5 7 9 11 13 s log n 15 45 75 105 135 165 195 Me an 9.11 27.5 46.17 61.47 81.26 97.2 111.88 V ar 10.15 16.6 25.5 25.88 31.88 30.94 37.37 T able 1. Mean and v ariance of n um b er of sampling vec- tors as functions of sparsity s for n = 2 15 = 32768 . Figure 2. Relative ` 2 error of reconstruction from noisy measuremen ts. various sp arsity s is shown in T able 2. It is cle ar fr om the table that the metho ds is very p erformant. s 1 25 50 75 100 125 150 CPU time 0.0045 0.028 0.049 0.073 0.098 0.144 0.146 T able 2. CPU time as a function of sparsity s for n = 1024 . 4.2. Noisy measuremen ts. Sim ulation 4.3. In this test we fix the fol lowing values: n = 512 , A = 20 , N = 0 . 1 . F or e ach value of s , we c onstruct 100 s -sp arse signals in R n . We test the effe ct of s on the ` 2 r elative err or k ˆ x − x k 2 k x k 2 (in p er c ent) as a function of the sp arsity s . The r esults ar e displaye d in Figur e 2. The exp eriments shows that the r elative err or incr e ases line arly with s . Sim ulation 4.4. In this test we fix the fol lowing values: n = 512 , A = 20 , s = 16 . We test the effe ct of noise on the ` 2 r elative err or k ˆ x − x k 2 k x k 2 (in p er c ent) as a function of the value N of the noise. The 16 AKRAM ALDR OUBI, HAICHAO W ANG, AND KOUR OSH ZARRINGHALAM Figure 3. Relative ` 2 error of reconstruction from noisy measuremen ts. Figure 4. Relative ` 2 error of reconstruction from noisy measuremen ts. r esults ar e displaye d in Figur e 3. The exp eriments suggest that the the r elative err or incr e ases line arly with N . Sim ulation 4.5. In this test we fix the fol lowing values: A = 20 , N = 0 . 1 , s = 8 . We test the effe ct of n = 2 r on the ` 2 r elative err or k ˆ x − x k 2 k x k 2 (in p er c ent) as a function of the value r . The r esults ar e displaye d in Figur e 4. 5. Conclusion W e ha v e presented an information theoretic approac h to compressed sampling of sparse signals. Using ideas similar to those in Huffman cod- ing, we constructed an adaptive sampling scheme for sparse signals. In our scheme, the sampling vectors are binary and their construction are deterministic and can b e pro duced explicitly for each n . Without noise SEQUENTIAL ADAPTIVE COMPRESSED SAMPLING VIA HUFFMAN CODES 17 the reconstruction is exact, and the a verage cost for sampling and re- construction com bined for an s sparse vector is b ounded b y slog ( n ) + 2 s . W e ha ve also shown that the metho d is also stable in noisy measure- men ts. How ev er, the curren t metho d and algorithms are not adapted to the compressive signals and dev elopmen ts for these cases will b e in- v estigated in future research. W e hop e that the approach will stim ulate further developmen ts and interactions b et ween the area of information theory and compressed sampling. References [AEB06a] M. Aharon, M. Elad, and A.M. Bruckstein, The k-svd: A n algorithm for designing of over c omplete dictionaries for sp arse r epr esentation , IEEE T rans. On Signal Pro cessing 54 (2006), no. 11, 4311 – 4322. [AEB06b] Michal Aharon, Mic hael Elad, and Alfred M. Bruc kstein, On the unique- ness of over c omplete dictionaries, and a pr actic al way to r etrieve them , Linear Algebra Appl. 416 (2006), no. 1, 48–67. [BDD W07] R. Baraniuk, M. Da venport, Ronald A. DeV ore, and M. W akin, A simple pr o of of the r estricte d isometry pr op erty for r andom matric es , Preprin t, 2007. [BGIKS08] R. Berinde, A. C. Gilb ert, P . Indyk, H. Karloff, and M. J. Strauss, Combining ge ometry and c ombinatorics: A unifie d appr o ach to sp arse signal r e c overy , (Preprint, 2008). [CR06] E. Cand` es and J. Romberg, Quantitative r obust unc ertainty principles and optimal ly sp arse de c omp ositions , F oundations of Comput. Math. 6 (2006), 227– 254. [CR T06] E. Cand ` es, J. Romberg, and T erence T ao, R obust unc ertainty principles: Exact signal r e c onstruction fr om highly inc omplete fr e quency information , IEEE T rans. on Information Theory 52 (2006), 489–509. [CW08] E. Cand` es and M. W akin, Pe ople he aring without listening: An intr o duc- tion to c ompr essive sampling , preprint, 2008. [CT91] T. M. Cov er and J. A. Thomas, Elements of Information Theory , Wiley In terscience Publishing, New Y ork, 1991. [CT06] E. Cand` es and T erence T ao, Ne ar optimal signal r e c overy fr om r andom pr oje ctions: Universal enc o ding str ate gies , IEEE T rans. on Information Theory 52 (2006), 5406–5425. [DeV07] Ronald A. DeV ore, Deterministic c onstructions of c ompr esse d sensing ma- tric es , Preprint, 2007. [Don06] David L. Donoho, Compr esse d sensing , IEEE T rans. on Information The- ory 52 (2006), 1289–1306. [D VB07] Pier Luigi Dragotti, M. V etterli, and T. Blu, Sampling moments and r e c onstructing signals of finite r ate of innovation: Shannon me ets str ang-fix , IEEE T ransactions on Signal Pro cessing 55 (2007), 1741–1757. [D WB05] M. F. Duarte, M. B. W akin, and R. G. Baraniuk. F ast r e c onstruction of pie c ewise smo oth signals fr om r andom pr oje ctions . In Pro c. SP ARS05, Rennes, F rance, No v. 2005. 18 AKRAM ALDR OUBI, HAICHAO W ANG, AND KOUR OSH ZARRINGHALAM [FL09] S. F oucart, M.-J. Lai. Sp arsest solutions of under determine d line ar systems via ` q -minimization for 0 < q ≤ 1. Applied and Computational Harmonic Anal- ysis, 26/3, 395–407, 2009. [GKMS03] A. C. Gilb ert, Y. Kotidis, S. Muthukrishnan, and M. Strauss, One- Pass Wavelet De c omp ositions of Data Str e ams IEEE T rans. Knowl. Data Eng., 15 (3) (2003), 541–554. [GSTV06] A. C. Gilb ert, M. J. Strauss, J. A. T ropp, and R. V ersh ynin. Algorithmic linear dimension reduction in the ` 1 norm for sparse v ectors. Submitted for publication, 2006. [GSTV07] A. C. Gilb ert, M. J. Strauss, J. A. T ropp, and R. V ershynin. One sketc h for all: fast algorithms for compressed sensing. In A CM STOC 2007, pages 237246, 2007. [GN03] R. Grib onv al and M. Nielsen, Sp arse de c omp ositions in unions of b ases , IEEE T rans. Inf. Theory 49 (2003), 3320–3325. [HCN09] J. Haupt, R. Castro, and R. Now ak, A daptive sensing for sp arse signal r e c overy , Proc. IEEE Digital Signal Pro cessing W orkshop and W orkshop on Signal Pro cessing Education, Marco Island, FL, 2009, January 2009. [JX C08] S. H. Ji and Y. Xue and L. Carin, Bayesian c ompr essive sensing , IEEE T ransactions On Signal Pro cessing, v ol. 56 no. 6 (2008), ppt. 2346 – 2356 [LD07] Y. Lu and M. N. Do, A the ory for sampling signals fr om a union of sub- sp ac es , IEEE T ransactions on Signal Pro cessing, (2007). [MV05] I. Maravic and M. V etterli, Sampling and r e c onstruction of signals with finite r ate of innovation in the pr esenc e of noise , IEEE T ransactions on Signal Pro cessing 53 (2005), 2788–2805. [NT08] D. Needell and J. A. T ropp, CoSaMP: Iter ative signal r e c overy fr om inc om- plete and inac cur ate samples , Applied and Computational Harmonic Analysis, v ol. 26, no. 3(2008), pp. 301-321. [NV09] D. Needell and R. V ershynin, ”Uniform Unc ertainty Principle and signal r e c overy via R e gularize d Ortho gonal Matching Pursuit , F oundations of Compu- tational Mathematics, v ol. 9, no. 3(2009), pp. 317-334. [RSV06] Holger Rauhut, K. Schass, and P . V andergheynst, Compr esse d sensing and r e dundant dictionaries , Preprint, 2006. [SBB06a] S. Sarvotham, D. Baron, and R. G. Baraniuk. Compressed sensing re- construction via b elief propagation. T echnical Report ECE-0601, Electrical and Computer Engineering Departmen t, Rice Universit y , 2006. [SBB06b] S. Sarvotham, D. Baron, and R. G. Baraniuk. Sudo co des - fast measure- men t and reconstruction of sparse signals. IEEE In ternational Symp osium on Information Theory , 2006. [T ro04] J. A. T ropp, Gr e e d is go o d: A lgorithmic r esults for sp arse appr oximation , IEEE T rans. Inf. Theory 50 (2004), 2231–2242. [XH07] W. Xu and B. Hassibi, Efficient c ompr essive sensing with determinstic guar ante es using exp ander gr aphs IEEE Information Theory W orkshop, 2007. SEQUENTIAL ADAPTIVE COMPRESSED SAMPLING VIA HUFFMAN CODES 19 Dep ar tment of Ma thema tics, V anderbil t University, 1326 Stevenson Center, Nashville, TN 37240 E-mail addr ess , Akram Aldroubi: akram.aldroubi@vanderbilt.edu E-mail addr ess , Haichao W ang: haichao.wang@vanderbilt.edu E-mail addr ess , Kourosh Zarringhalam: Kourosh.Zarringhalam@vanderbilt.edu
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment