부스팅 자유도와 규제: 이론·시뮬레이션·역사적 고찰
부스팅 알고리즘의 자유도 추정식이 실제 자유도를 과소평가한다는 점을 시뮬레이션으로 확인하고, LARS와의 연계, 다양한 베이스 학습기(선형 최소제곱, 스플라인)에서의 자유도 해석, 그리고 부스팅의 역사·규제·과적합 방지 전략을 종합적으로 논의한다.
저자: Peter B"uhlmann, Torsten Hothorn
본 논문은 부스팅(Boosting) 알고리즘에 대한 “재응답”(Rejoinder) 형태로, 원 논문에서 제시한 자유도(degrees of freedom, df) 추정식과 그 한계, 그리고 부스팅의 다양한 변형·역사·규제 전략을 심도 있게 분석한다.
1. **자유도 추정과 실제 자유도**
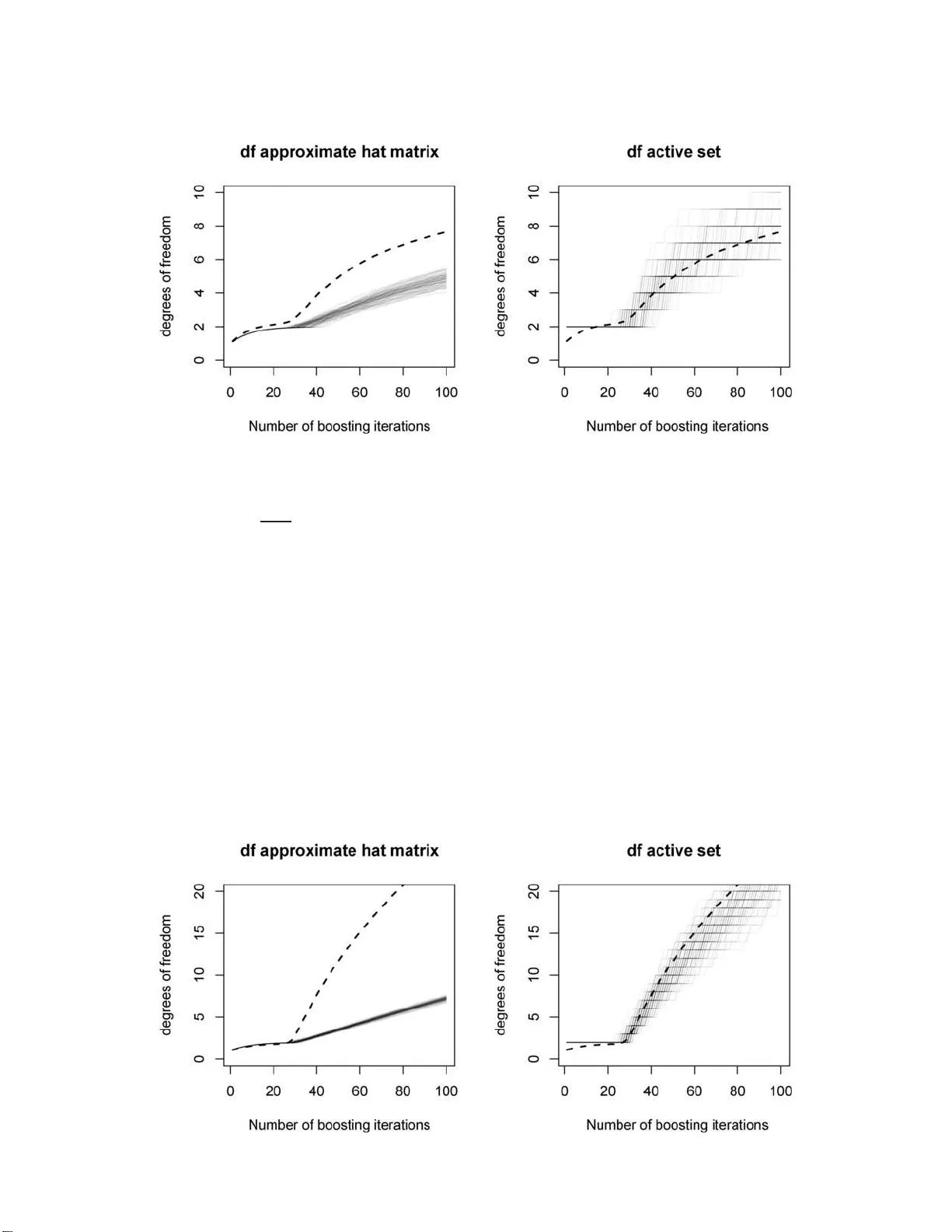
- 원 논문에서 제시한 근사식 df(m)=trace(B_m) 은 베이스 학습기(특히 컴포넌트별 선형 최소제곱)에서 “검색 비용(searching cost)”을 무시하기 때문에 실제 자유도(df_true) 를 과소평가한다.
- 실제 자유도는 회귀(L2 손실) 상황에서 df_true(m)=n·Cov(Ŷ_i,Y_i)/σ_ε² 로 정의되며, 이는 Efron 등(LARS)에서 제시한 정의와 일치한다.
- Hastie가 제시한 LARS와 iFSLR(무한소 전진 단계별 회귀)와의 연계는 df_LARS(k)=k 라는 정확한 자유도 계산을 가능하게 하지만, 부스팅에서는 “활성 집합(active set)” 기반 df_actset(m) 가 보다 현실적인 근사치가 된다.
2. **시뮬레이션 연구**
- 세 가지 모델을 사용: (1) 고희소 선형 모델(p=200, p_eff=1), (2) 저희소 선형 모델(p=200, p_eff=10), (3) 스플라인 기반 additive 모델.
- 각 모델에 대해 100번 반복 시뮬레이션을 수행, df_true, df(m), df_actset(m) 를 비교하였다.
- 결과 요약:
* 고희소 모델에서는 df(m) 이 df_true에 근접하지만, 초기 단계에서 df_actset(m) 가 과대평가한다.
* 저희소 모델에서는 df(m) 이 크게 과소추정되고, df_actset(m) 은 초기 단계에서 실제 자유도보다 크게 높다.
* 스플라인 기반 부스팅에서는 df(m) 이 전반적으로 df_true와 비슷한 경향을 보였으며, df_actset(m) 은 적용이 어려워 새로운 추정식이 필요함을 시사한다.
3. **자유도와 규제**
- df(m) 이 과소추정되면 AIC와 같은 정보 기준에서 패널티가 충분히 작아져 과적합 위험이 커진다.
- df_actset(m) 은 변동성이 적고, 특히 컴포넌트별 선형 최소제곱에서는 실제 자유도와 거의 일치한다(선택된 변수 수와 동일).
- 그러나 df_actset(m) 도 무작위적이며, 고정된 자유도 개념과는 차이가 있다.
4. **부스팅의 역사와 베이스 학습기 선택**
- Friedman, Hastie, Tibshirani가 제안한 Gradient Boosting, LogitBoost, BinomialBoost 등 다양한 변형을 소개하고, “shrinkage”(ν) 와 “early stopping” 이 규제 메커니즘으로 작동함을 강조한다.
- ν=0.1 같은 작은 단계 크기가 과적합을 방지하는 데 효과적이며, 선형 근사(gradient)와 2차 근사(Quadratic) 사이의 수치적 차이를 논한다. 특히, 로그우도 2차 근사는 p(x) 가 0 또는 1에 가까워질 때 수치 불안정이 발생함을 지적하고, 선형 근사가 이러한 문제를 완화한다는 실용적 조언을 제공한다.
5. **부스팅과 Bagging의 결합**
- Random Forest와 같은 방법은 부트스트랩 샘플링과 변수 무작위 선택을 결합해 강건성을 높인다. 저자는 본 논문에서 다루는 “기본 부스팅”은 이러한 무작위 요소를 포함하지 않으며, 순수한 부스팅 메커니즘에 초점을 맞춘다고 명시한다.
6. **통계적 관점의 한계와 보완책**
- **조건부 클래스 확률 추정**: AdaBoost·LogitBoost 가 0-1 손실에 최적화돼 과적합 위험이 낮지만, 확률 추정에는 더 많은 규제가 필요하다. 로그우도 손실을 사용하고 조기 종료를 적용하면 확률 추정 정확도가 크게 향상된다.
- **강건성(Robustness)**: 로짓 회귀의 MLE는 영향력이 제한적이지만, 부스팅에서는 지수 손실이 더 큰 영향력을 가질 수 있어 수치적 안정성을 위해 선형 근사를 선호한다.
- **베이스 학습기의 가법성**: 로그스케일에서 가법적인 경우 스텁(stump) 기반 부스팅이 효율적이며, 비가법적인 경우 큰 트리가 더 나은 성능을 보인다. 이는 Mease·Wyner(2010)에서 제시된 “반대 증거”를 가법성 여부로 설명한다.
- **조기 종료와 샤링크**: 조기 종료는 과적합 방지에 핵심적이며, ν=0.1 같은 기본값은 대부분의 상황에서 좋은 시작점이다. 그러나 모든 경우에 최적은 아니므로 교차 검증을 통한 튜닝이 권장된다.
7. **결론**
- 부스팅 자유도 추정은 베이스 학습기의 특성에 크게 의존한다. 컴포넌트별 선형 최소제곱에서는 df_actset(m) 가 실용적인 근사치가 될 수 있지만, 스플라인이나 비선형 베이스에서는 새로운 추정식이 필요하다.
- 규제 전략(샤링크, 조기 종료, 손실 함수 선택)은 부스팅의 과적합 방지와 확률 추정 정확도에 결정적 영향을 미친다.
- 부스팅의 역사적 발전과 다른 앙상블 기법(예: Random Forest)과의 차이를 명확히 이해함으로써, 연구자와 실무자는 문제 특성에 맞는 부스팅 변형을 선택하고 적절히 튜닝할 수 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기