Rejoinder: Boosting Algorithms: Regularization, Prediction and Model Fitting
Rejoinder to ``Boosting Algorithms: Regularization, Prediction and Model Fitting'' [arXiv:0804.2752]
Authors: Peter B"uhlmann, Torsten Hothorn
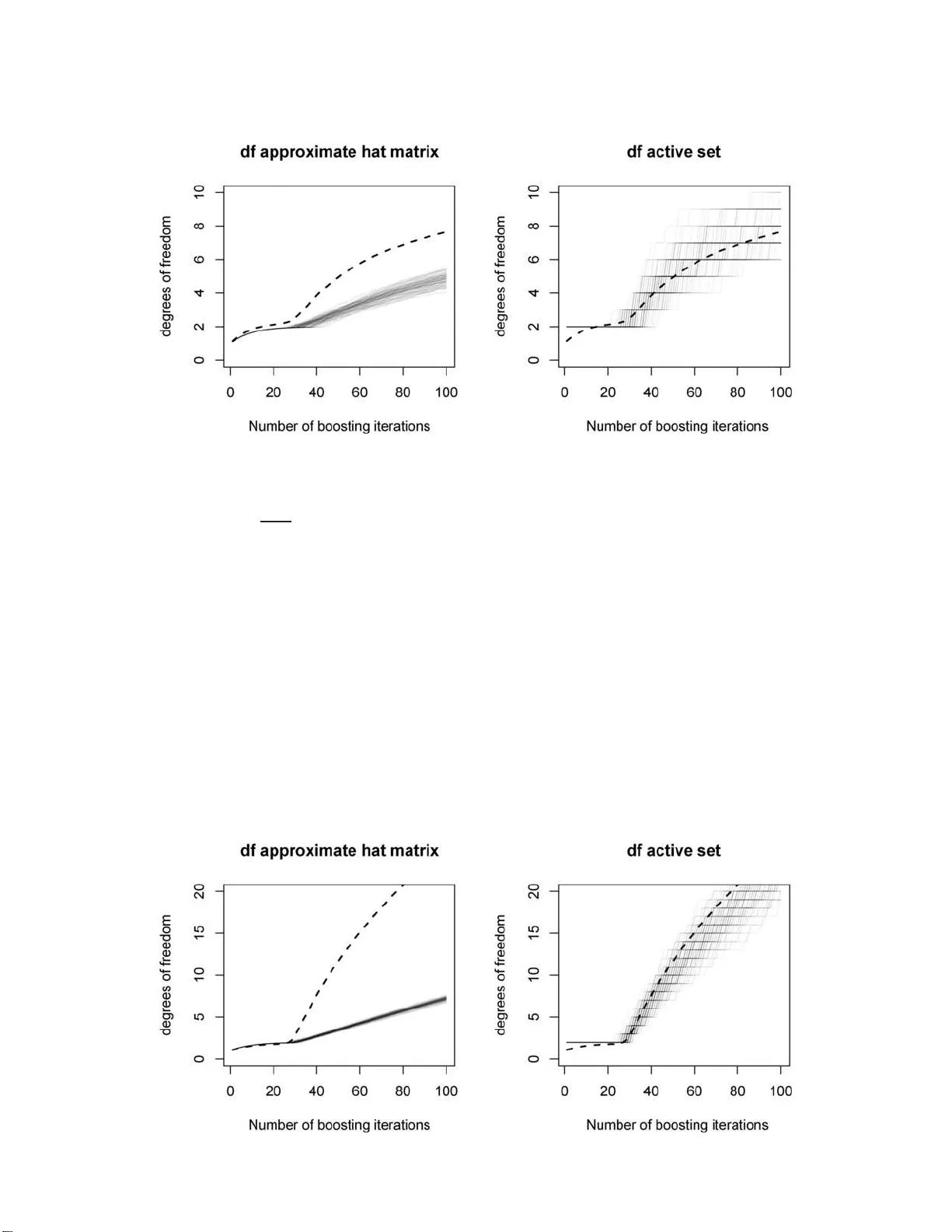
Statistic al Scienc e 2007, V ol. 22, No. 4, 516– 522 DOI: 10.1214 /07-STS242REJ Main article DO I: 10.1214/07-STS242 c Institute of Mathematical Statistics , 2007 Rejoinder: Bo osting Algo rithms: Regula rization, Prediction and Mo del Fitting P eter B¨ uhlmann and T o rsten Hotho rn 1. DEGREES OF FREEDOM F OR BOOSTING W e are grateful that Hastie p oin ts out the connec- tion to degrees of freedom for LARS whic h leads to another—and often b etter—definition of degrees of freedom for b oosting in generalized linear mo dels. As Hastie writes and as w e said in the pap er, our form ula for d egrees of freedom is only an appro xima- tion: the cost of se arc hing, for example, fo r the b est v ariable in comp onent wise linear least squares or comp onent wise smo othing sp lines, is ignored. Hence, our approximati on form ula df ( m ) = trace( B m ) for the degrees of freedom of b oosting in the m th iteration is underestimating the true degrees of free- dom. The latte r is defined (for regression with L 2 - loss) as df true ( m ) = n X i =1 Co v ( ˆ Y i , Y i ) /σ 2 ε , ˆ Y = B m Y , cf. Efron et al. [ 5 ]. F or fitting lin ear m o dels, Hastie illustrates nicely that for infin itesimal forw ard stagewise (iFSLR) and the Lasso, the cost of searc hing can b e easily ac- coun ted for in the framew ork of the LARS algo - rithm. With k steps in the algorithm, its deg rees Peter B¨ uhlmann is Pr ofessor, Seminar f¨ ur St atistik, ETH Z¨ urich, CH-8092 Z ¨ urich, Switzerland e-mail: buhlmann@stat.math.ethz.ch . T orsten Hothorn is Pr ofessor, In stitut f¨ ur Statistik, Ludwig-Maximilia ns- Universit¨ at M¨ unchen, Ludwigstr aße 33, D-80539 M¨ unchen, Germany e-mail: T orsten.Hothorn@R-pr oje ct.or g . T orsten Hothorn wr ote this p ap er while he was a le ctur er at the Universit¨ at Erlangen-N¨ urnb er g. This is an electronic repr int of the orig inal ar ticle published b y the Ins titute of Mathematical Statistics in Statistic al Scienc e , 2007, V ol. 22, No. 4, 516 –522 . This reprint differs from the original in pagina tio n and t yp ogr aphic detail. of freedom are given by df LARS ( k ) = k. F or quite a few examples, this coincides with the n umb er of activ e v ariables (v ariables w hic h ha ve b ee n selected) when us in g k steps in LARS, that is, df LARS ( k ) ≈ df actset ( k ) = cardinalit y of activ e set . Note th at th e num b er of steps in df LARS is not meaningful for b o osting with comp onen t wise linear least s quares w h ile d f actset ( m ) for b oosting with m iterations can b e used (and often seems reasonable; see b elo w). W e point out that df ( m ) and df actset ( m ) are random (and h ence they cannot b e degrees of freedom in the classical sense). W e will discuss in the follo wing whether they are go o d estimato rs for the true (n onrandom) df true ( m ). When u sing another base pro cedu r e than comp o- nen t wise linear least squares, for example, comp o- nen t wise smo o thing sp lines, the notion of df actset ( m ) is inappr opriate (the num b er of selected co v ariates times the d egrees of freedom of the base pr o cedure is not appropriate for assigning degrees of freedom). W e no w presen t some simulat ed examples where w e can ev aluate the tru e df true for L 2 Bo osting. T h e first t w o are with comp onent wise linear least squares for fitting a linear mo del and the thir d is with com- p onent wise smo ot hing splines for fitting an additive mo del. The mo dels are Y i = p X j =1 β j x ( j ) i + ε i , ε i ∼ N (0 , 1) i.i.d. , i = 1 , . . . , n, with fixed d esign from N p (0 , Σ) , Σ i,j = 0 . 5 | i − j | , p eff nonzero regression co efficien ts β j and with parame- ters p = 10 , p eff = 1 , (1) 1 2 P . B ¨ UHLMANN A ND T. HOTHORN Fig. 1. Mo del ( 1 ) and b o osting wi th c omp onentwise line ar l e ast squar es ( ν = 0 . 1 ). T rue de gr e es of fr e e dom df true ( m ) (dashe d black line) and df ( m ) (shade d gr ay li nes, l ef t p anel) and d f actset ( m ) (shade d gr ay lines, right p anel) fr om 100 simulations. n = 100 , β 5 = √ 34 . 5 , β j ≡ 0 ( j 6 = 5) , p = 200 , p eff = 1 , (2) n = 100 , β as in ( 1 ) , p = 200 , p eff = 10 , n = 100 , (3) β = (1 , 1 , 1 , 1 , 1 , 0 . 5 , 0 . 5 , 0 . 5 , 0 . 5 , 0 . 5 , 0 , 0 , . . . ) . All mo dels ( 1 )–( 3 ) h av e the same signal-to-noise ra- tio. In addition, we consid er the F riedman #1 addi- tiv e m o del with p = 20 and p eff = 5 : Y i = 10 sin( π x (1) i x (2) i ) + 20( x (3) i − 0 . 5 ) 2 + 10 x (4) i + 5 x (5) i + ε i , i = 1 , . . . , n, with fixed d esign from U [0 , 1] 20 and i.i.d. err ors ε i ∼ N (0 , σ 2 ε ) , i = 1 , . . . , n w here σ 2 ε = 1 , (4) σ 2 ε = 10 . (5) Figures 1 – 4 disp la y the results. As already men- tioned, our appr oximati on d f ( m ) und erestimates the true d egrees of fr eedom. Hence, our p enal t y term in AIC or similar inform ation criteria tends to b e to o small. F ur thermore, our df ( m ) is less v ariable than df actset ( m ). When lo oking in detail to the s p arse cases f r om mo del ( 1 ) and ( 2 ) in Figures 1 an d 2 , re- sp ectiv ely: (i) our df ( m ) is accurate for the range of Fig. 2. Mo del ( 2 ) and b o osting with c om p onentwise l ine ar l e ast squar es ( ν = 0 . 1 ). Other sp e cific ations as in Figur e 1 . REJOINDER 3 Fig. 3. Mo del ( 3 ) and b o osting with c om p onentwise l ine ar l e ast squar es ( ν = 0 . 1 ). Other sp e cific ations as in Figur e 1 . iterations whic h are reasonable (n ote that we should not sp end m ore degrees of freedom than, sa y , 2–3 if p eff = 1; OLS on the s in gle effectiv e v ariable, in- cluding an intercept, would ha ve df true = 2); (ii) the activ e set degrees of fr eedom are to o large for the first few v alues of m , that is, df actset ( m ) = 2 (one v ariable and the in tercept) although df true ( m ) < 1 . 5 for m ≤ 5. Suc h a b eha vior disapp ears in th e less sparse case in mo del ( 3 ), which is an example w here df ( m ) und erestimates very hea vily; s ee Figure 3 . Despite some (obvi ous) drawbac ks of df actset ( m ), it w orks reasonably well. Hastie has ask ed us to giv e a correction form ula for our d f ( m ). His discussion summarizing the nice relation b etw een LARS , iF- SLR and L 2 Bo osting, together w ith our sim ulated examples, su ggests that df actset ( m ) is a b etter ap- pro ximation for degrees of fr eedom for b o osting with the comp onent wise linear base pro cedure. W e h av e implemen ted df actset ( m ) in ve rsion 1.0-0 of the m b o ost pac k age [ 9 ] for assigning degrees of freedom of b o ost- ing with component wise linear least squares for gen- eralized linear mo d els. Unfortu nately , in con trast to LARS, df actset ( m ) will neve r b e exact. It seems that assigning correct degrees of freedom for b oosting is more difficult than for LARS. F or other learners, for example, the comp on ent wise smo o thing spline, w e do not ev en ha ve a b etter appro ximation for de- grees of fr eedom. Our form ula df ( m ) wo rked r eason- ably w ell for the mo dels in ( 4 ) and ( 5 ); c hanging the Fig. 4. L eft: mo del ( 4 ) . R ight: mo del ( 5 ) . Bo osting wi th c omp onentwise smo othing splines wi th four de gr e es of fr e e dom ( ν = 0 . 1 ). T rue de gr e es of f r e e dom df true ( m ) (dashe d black line) and df ( m ) (shade d gr ay l ines, for b oth p anels). 4 P . B ¨ UHLMANN A ND T. HOTHORN signal-to-noise ratio b y a fac tor 10 ga ve almost iden- tical results (which is unclear a p riori b ecause d f ( m ) dep end s on the d ata). But this is no guaran tee for generalizing to other settings. In absence of a b etter appro ximation formula in general, w e still think that our df ( m ) form ula is usefu l as a r ough app r o xima- tion for degrees of freedom of b o osting with com- p onent wise sm o othing splines. And we agree with Hastie th at cross-v alidation is a v aluable al terna- tiv e for the task of estimating the stoppin g p oin t of b o osting iterations. 2. HISTORICA L REMAR KS AND NUMERICAL OPTIMIZA T ION Buja, Mease and Wyner (BMW hereafter) mak e a very nice and detailed con tribution regarding the history and d ev elopmen t of b o o sting. BMW also ask why w e advocate F riedm an’s gra- dien t descen t as the b oosting standard. First, w e w ould like to p oint out that compu tational efficiency in b oosting do es not necessarily yield b ett er statisti- cal p erformance. F or example, a small step-size ma y b e b eneficial in comparison to step-size ν = 1 , sa y . Related to this fact, the qu adratic appr o x im ation of the loss function as describ ed by BMW may not b e b etter than th e linear approximat ion. T o exemplify , tak e the negat iv e log-lik eliho o d loss function in (3 .1) for bin ary classification. When using the linear ap- pro ximation, the wo rking r esp onse (i.e., the negativ e gradien t) is z i, linapp = 2( y i − p ( x i )) , y i ∈ { 0 , 1 } . In con trast, when usin g the quadratic appr o xima- tion, w e end up with LogitBo ost as prop osed by F riedman, Hastie and Tibsh irani [ 7 ]. The working resp onse is then z i, quadapp = 1 2 y i − p ( x i ) p ( x i )(1 − p ( x i )) . The factor 1 / 2 app ears in [ 7 ] when doing the lin- ear up d ate but not for the w orking resp onse. W e see th at z i, quadapp is numerically pr oblematic wh en - ev er p ( x i ) is close to 0 or 1, and [ 7 ], on pages 352– 353, address th is issue by thresholding the v alue of z i, quadapp to an “ad ho c” u pp er limit. On the other hand, with the linear approximat ion and z i, linapp , suc h numerical p roblems do not arise. T his is a rea- son w h y we generally prefer to work with the linear appro ximation and F riedman’s gradient descen t al- gorithm [ 6 ]. BMW also p oint out that th ere is n o “random el- emen t” in b o ost ing. I n our exp erience, aggregatio n in the st yle of bagging is often ve ry useful. A com bi- nation of b oosting with bagging h as b een p rop osed in B¨ uhlmann and Y u [ 2 ] and sim ilar ideas app ear in F riedman [ 8 ] and Dettling [ 4 ] . In fact, random forests [ 1 ] also inv olv e some b o otstrap sampling in addition to the random sampling of co v ariates in the no des of th e trees; without the b ootstrap sampling, it w ou ld not wo rk as w ell. W e agree with BMW that quite a few method s actually b enefit from additional b o otstrap aggregation. Ou r pap er, ho w ev er, fo cu s es solely on b o osti ng as a “basic mo du le” withou t (or b efore) rand om sampling and aggregation. 3. LIMIT A TIONS OF THE “S T A TIST ICAL VIEW” OF BOOSTING BMW p oint out some limitations of the “statisti- cal view” (i.e., the grad ient descen t form ulation) of b o osting. W e agree only in part with some of their argumen ts. 3.1 Conditional Class Proba bilit y Estimat ion BMW p oint out that cond itional class probabili- ties cannot b e estimate d wel l by either AdaBo ost or LogitBoost, and later in their discussion th ey men- tion that o v erfitting is a sev ere problem. In deed, the amount of regularization for conditional cla ss probabilit y estimation should b e (markedly) d iffer- en t than for classification. F or p robabilit y estima- tion w e typica lly u se (many) fewer iterations, that is, a less complex fit, than for classification. This fits in to the picture of the rejoinder in [ 7 ] and [ 2 ], sa ying that th e 0-1 misclassificatio n loss in (3.2 ) is m uc h more insensitiv e to ov erfitting . F or accurate conditional class probabilit y estimation, we should use the su r rogate loss, for exa mple, the negativ e log- lik eliho o d loss in (3.1) , for estimating (e.g., via cross- v alidation) a go o d stoppin g iteration. Then , condi- tional class pr obabilit y estimates are often quite rea- sonable (o r ev en v ery accurate), dep en ding of course on the base pro c edur e, the s tr ucture of the underly- ing problem and the signal-to-noise ratio. W e agree with BMW that AdaBo ost or LogitBo ost o ve rfit for conditional class p robabilit y estimation w hen using the wrong strate gy—namely , tuning the b o osting al- gorithm according to optimal classification. Thus, unfortun ately , the goals of accurate cond itional class probabilit y estimation and go o d classificatio n are in conflict with eac h other. Th is is a general fact (see REJOINDER 5 rejoinder b y F r iedm an, Hastie and Tibshirani [ 7 ]) but it seems to b e esp ecially pronounced with b o o st- ing complex data. Having said that, we agree with BMW that AIC/BIC regularizatio n with th e neg- ativ e log-lik eliho o d loss in (3.1) for bin ary classifi- cation will b e geared to w ard estimating conditional probabilities, and for classification, w e sh ould u se more iterations (less regularization). 3.2 Robustness F or classification, BMW argue th at robustn ess in the resp ons e space is not an issue s ince, “binary re- sp onses ha v e no pr oblem of v ertically outlying v al- ues.” W e disagree with the relev ance of their argu- men t. F or logistic regression, robu stification of the MLE h as b ee n studied in detail. Ev en th ough the MLE has b oun ded infl uence, the b ound ma y b e to o large and for p ractical problems this m a y m atter a lot. K ¨ unsc h, Stefanski and Carroll [ 10 ] is a go o d ref- erence whic h also cites earlier pap ers in this area. Note that with the exp o nentia l loss, the issue of to o large influ ence is even more pronounced than w ith the log-lik eliho o d loss corr esp onding to the MLE. 4. EXEMPLIFIED LIMIT A TIONS OF THE “ST A TISTICAL VIEW” The p ap er by Mease and Wyner [ 11 ] presen ts s ome “con trary evidence” to the “statistical view” of b oost- ing. W e r ep eat some of the p oin ts made by B ¨ uhlmann and Y u [ 3 ] in the d iscussion of Mease and Wyner’s pap er. 4.1 Stumps S hould b e Used for A dditive Bay es Decision Rules The sentence in the s ubtitle whic h is p ut forward, discussed and criticized by BMW n ever ap p ears in our p ap er. The main source of confusion seems to b e the concept of “additivit y” of a function. It sh ould b e considered on the logit-sca le (for AdaBoost, Log- itBoost or BinomialBoosting), since the p opu lation minimizer of AdaBo ost, LogitBoost or BinomialBoost- ing is half of the log-od ds ratio. Mease and Wyner [ 11 ] created a simulation mo del whic h is additiv e as a d ecision fun ction but n onadditiv e on the logit- scale for the conditional class pr ob ab ilities; and they sho w ed that larger trees are th en b etter than stumps (whic h is actually consistent with what w e wr ite in our pap er). W e think that this is the main reason wh y Mease and Wyner [ 11 ] found “con trary evi- dence.” W e illustrate in Figure 5 that our h euristics to prefer stu mps o v er larger trees is useful if the u n- derlying mo del is add itiv e for the logit of the condi- tional cla ss probabilities. The sim ulation mo del here is the same as in [ 3 ] whic h w e used to address the “con trary evidence” find in gs in [ 11 ]; our mo d el is in- spired b y Mease and Wyner [ 11 ] but w e make th e conditional class probabilities additive on the logit- scale: logit( p ( X )) = 8 5 X j =1 ( X ( j ) − 0 . 5) , (6) Y ∼ Bernoulli ( p ( X )) , and X ∼ U [0 , 1] 20 (i.e., i.i.d. U [0 , 1]). This mo del has Ba yes error rate appro ximately equal to 0 . 1 (as in Fig. 5. Bi nomialBo osting ( ν = 0 . 1) with stumps ( soli d line ) and l ar ger tr e es (dashe d l ine) for mo del ( 6 ). L eft p anel: test-set misclassific ation err or; midd le p anel: test -set surr o gate loss; right p anel: test- set absolute err or for pr ob abilities. Aver age d over 50 simulations. 6 P . B ¨ UHLMANN A ND T. HOTHORN [ 11 ]). W e use n = 100, p = 20 (i.e., 15 ineffectiv e pr e- dictors), and w e generate test sets of size 2000. W e consider Binomia lBo osting with stumps and with larger trees whose v arying size is ab out 6–8 ter- minal no d es. W e consider the misclassificatio n test error, the test-set surr ogate loss with the n egativ e log-lik eliho o d and the absolute error for pr obabili- ties 1 2000 2000 X i =1 | ˆ p ( X i ) − p ( X i ) | , where a verag ing is ov er th e test set. Figure 5 dis- pla ys the results (the d ifferences b et wee n stumps and larger tree s are significant ) whic h are in line with the explanations and heuristics in our pap er but very differen t from wh at BMW describ e. T o re- iterate, w e think th at the reason for the “con trary evidence” in Mease and Wyner [ 11 ] comes from th e fact that their mo del is not additive on the logit- scale. W e also see from Figure 5 that early stopping is imp ortant for probability estimatio n, in particular when measur in g in terms of test-set surrogate loss; a bit surprisingly , BinomialBo osting w ith stumps do es not ov erfit within the firs t 1000 iterations in terms of absolute err ors f or conditional class probabilities (this is p r obably d ue to the lo w Ba yes error rate of the mo del; ev entuall y , we will see o verfitting h ere as w ell). Finally , B ¨ uhlmann and Y u [ 3 ] also argue that the fi ndings h ere also app ear when using “discrete AdaBo ost.” In our opinion, it is exactly the “statistical view” whic h h elps to explain the phen omenon in Figure 5 . The “parameteriza tion” with stumps is only “effi- cien t” if the m o del for the logit of the conditional class probabilities is additiv e; if it is nonadditiv e on the logit-scale , it can easily happ en that larger trees are b etter base pro cedures, as found ind eed b y Mease and Wyner [ 11 ]. 4.2 Early S topping Should b e Used to Prevent Overfitting BMW indicat e that early stopping is often not necessary—or ev en degrades p erformance. One should b e aw are th at they consider the s p ecial case of bin ary classification with “discrete AdaBo ost” and use trees as the base procedu re. Arguably , this is the original prop osa l and application of b oosting. In our exposition, though, w e n ot only focus on b i- nary classification but on many other things, suc h as estimating class conditional probabilities, regression functions and surviv al fu nctions. As BM W write, when us ing the surrogate loss for ev aluating the p er- formance of b o osting, o v erfitting kic ks in quite early and early stopping is often absolutely cru cial. It is dangerous to p r esen t a message th at early stopping migh t degrade p erformance: the examples in Mease and Wyner [ 11 ] pro vide marginal impro v ement s of ab out 1–2% withou t early stopping (of cour s e, they also stop somewhere) wh ile the loss of not stopping early can b e huge in applications other than classi- fication. 4.3 Shrinkage Should b e Used to Pr event Overfitting W e agree with BMW that shrink age d o es not al- w a ys impro v e p er f ormance. W e never stated that shrink age would p r ev en t o verfitting. In fact, in lin- ear mo dels, infinitesimal shrink age corresp on d s to the Lasso (see S ection 5.2.1) and clearly , the Lasso is not free of o verfitting. In our view, shr ink age adds another dimension of r egularization. If we do not w an t to tune the amount of shrink age, the v alue ν = 0 . 1 is often a surpr isin gly goo d default v alue. Of cour se, there are examples where suc h a default v alue is n ot optimal. 4.4 The Role of the Sur rogate Loss Function and Conclusions From BMW BMW’s comments on the role of the sur rogate loss function when using a particular algorithm are in- triguing. Th eir algorithm can b e viewed as an en- sem ble method ; whether we should call it a b oosting algorithm is debatable. And for sure, th eir metho d is not within the framew ork of functional gradien t descen t algorithms. BMW point out that there are still some m ys- teries ab out AdaBo ost. In our view, the o v erfitting b ehavio r is not w ell understo o d while the issu e of using stumps ve rsu s larger tree b ase pr o ce du res has a coherent explanation as p ointe d out ab o ve . T here are certainly examp les wh ere o v erfitting o ccur s with AdaBo ost. The (theoretica l) question is whether there is a relev an t class of examples where AdaBoost is not o v erfitting when runn ing infi nitely man y itera- tions. W e cannot answer the question with n umer- ical examples since “infinitely many” can nev er b e observ ed on a computer. The qu estion has to b e answ ered b y rigorous mathematical arguments. F or practical pu rp oses, we adv o cate early stopping as a go o d and imp ortant recip e. REJOINDER 7 A CKNO WLEDGMENTS W e are m uc h obliged that the discussan ts pro- vided man y though tful, detailed and imp ortan t com- men ts. W e also would lik e to thank Ed George for organizing the d iscussion. REFERENCES [1] Breiman, L. (2001). Rand om forests. Machine L e arning 45 5–32. [2] B ¨ uhlmann, P. and Yu, B. (2000). Discussion of “Ad- ditive logistic regres sion: A statistical view,” b y J. F riedman, T. Hastie and R. Tibshirani. Ann. Statist. 28 377–386. [3] B ¨ uhlmann, P. and Yu , B. (2008). Discussion of “Evi- dence contrary to the statistical view of b oosting,” by D. Mease and A. Wy ner. J. Machine L e arning R ese ar ch 9 187–194. [4] Dettling, M. (2004). Bag Bo osting for tumor classifica- tion with gene exp ression data. Bioinf ormatics 20 3583–35 93. [5] Efr on, B. , Hastie, T. , Johnstone, I. and Ti bshirani, R. (2004). Least angle regr ession (with discussion). Ann . Statist. 32 407–499. MR2060166 [6] Friedman, J. (2001). Greedy fun ct ion app ro ximation: A gradient bo osting machine. Ann. Statist. 29 1189– 1232. MR1873328 [7] Friedman, J. , Hastie, T. and T ibshirani, R. (2000). Additive logistic regression: A statistical view of b oosting (with discussion). Ann. Statist. 28 337– 407. MR1790002 [8] Friedman, J. H. (2002). Stochastic gradien t b o ost- ing. Comput. Statist. Data Anal. 38 367–3 78. MR1884869 [9] Hothorn, T. , B ¨ uhlmann, P. , Kneib, T. and Schmid, M. (2007). Mb o ost : Mo del-based b o ost- ing. R pack age version 1.0-0. Ava ilable at http://CRA N.R- project.org . [10] K ¨ unsch, H.-R. , S tef anski, L. A. and Carro ll, R. J. (1989). Conditionally u nbiased b ound ed-influen ce estimation in general regression mod els, with ap- plications t o generalized linear mo dels. J. Amer. Statist. Asso c. 84 460–466 . MR1010334 [11] Mease, D. and Wyner, A. (2008). Evidence con trary to the statistical view of b oosting. J. Machine L e arn- ing Re se ar ch 9 131–156.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment