과학 논문에서 인식적 양상 자동 탐지 프레임워크
본 논문은 과학 기사에서 저자의 인식적(에피스테믹) 모달리티를 식별하기 위한 반자동 시스템을 제안한다. 입력 텍스트를 형태소 분석·명사·대명사 인식 후, 모달 동사를 추출하고, 규칙 기반 자동화와 어휘 사전(WordNet) 활용을 통해 ‘디온틱’·‘에피스테믹’·‘비모달’으로 구분한다. 최종 출력은 모달리티가 표시된 텍스트 구역(zone)이다.
저자: Sviatlana Danilava, Christoph Schommer
본 논문은 과학 기사에서 저자의 인식적(에피스테믹) 모달리티를 자동으로 탐지하고 구역화하는 반자동 프레임워크를 제안한다. 연구 배경으로는 과학 텍스트가 객관적인 서술과 동시에 저자의 주관적 의견을 내포하고 있으며, 이러한 의견은 모달 동사, 부사, 모달 파티클, 구두점, 억양 등 다양한 언어적 수단에 의해 표현된다는 점을 들었다. 기존 연구는 주로 의견 마이닝이나 감성 분석에 초점을 맞추었지만, 모달리티 자체를 구분하고 이를 기반으로 저자의 태도를 파악하는 작업은 상대적으로 적었다.
논문은 먼저 모달리티의 이론적 배경을 정리한다. 모달리티는 형식 논리에서 파생된 개념으로, ‘디온틱(현실·규범에 대한)’, ‘에피스테믹(지식·확신에 대한)’ 두 종류가 있다. 예시로 “must be alive”는 에피스테믹(가설)이며, “must submit the report”는 디온틱(의무)이다. 모달 동사는 가능성, 필요성, 의무, 추측 등을 전달하며, 같은 동사가 문맥에 따라 두 의미를 모두 가질 수 있다. 따라서 동사의 의미를 정확히 구분하는 것이 핵심 과제이다.
시스템 아키텍처는 크게 전처리와 모달리티 구분·구역화 두 부분으로 나뉜다. 전처리 단계에서는 POS 태거를 적용해 각 단어에 품사 태그를 부여하고, 명사 인식 엔진과 대명사 인식 엔진을 통해 인물·기관명을 식별한다. 여기서는 Brown Corpus와 Names Corpus를 활용했으며, 대명사는 ‘he’, ‘she’, ‘who’만을 대상으로 하여 잡음을 최소화한다.
다음으로 모달 동사 사전을 구축한다. WordNet의 동의어 관계를 재귀적으로 탐색해 ‘must’, ‘can’, ‘may’, ‘could’, ‘should’ 등 전형적인 모달 동사를 수집하고, 인지 동사(‘believe’, ‘doubt’ 등)와 부사(‘perhaps’, ‘likely’)도 포함한다. 사전 기반 매칭을 통해 텍스트에서 후보 모달 동사를 추출한다.
핵심인 모달리티 구분은 규칙 기반 자동화 엔진(Disambiguation Engine)으로 수행한다. 엔진은 동사와 주변 어휘(‘have been’, ‘be’, ‘not’, ‘been’, ‘must’, ‘could’ 등)의 결합 패턴을 분석한다. 예를 들어, ‘must + be + V‑ing’ 형태는 에피스테믹으로, ‘can + not’은 디온틱으로 분류한다. 또한, 콜로케이션 빈도에 기반한 사전 확률을 적용해 초기 분류를 수행한다. 규칙은 다음과 같이 정리된다.
- ‘can’은 디온틱, ‘could’는 에피스테믹
- ‘may’, ‘might’, ‘might’는 에피스테믹(가능성)
- ‘will’은 미래 가설이므로 에피스테믹
- ‘shall’, ‘should’는 상황에 따라 디온틱/에피스테믹을 구분
- ‘must’는 문맥에 따라 두 의미 모두 가능, 주변 어휘가 판단 근거가 된다.
구분된 결과는 세 가지 클래스로 라벨링된다: 디온틱, 에피스테믹, 비모달. 추가적으로 에피스테믹을 긍정·부정으로 세분화할 수 있는데, 이는 모달 동사와 명제 부분을 함께 고려해 ‘Author believes X(positive)’ 혹은 ‘Author rejects X(negative)’ 형태로 표현한다.
마지막 단계는 모달리티 구역화이다. 각 문장은 해당 라벨이 부착된 구역(zone)으로 변환되며, 이는 텍스트 내에서 저자의 의견이 어디에 나타나는지를 시각적으로 표시한다. 예시로 “Australian and Canadian researchers argue … that they must have been alive.”은 에피스테믹(가능성) 구역으로 표시된다.
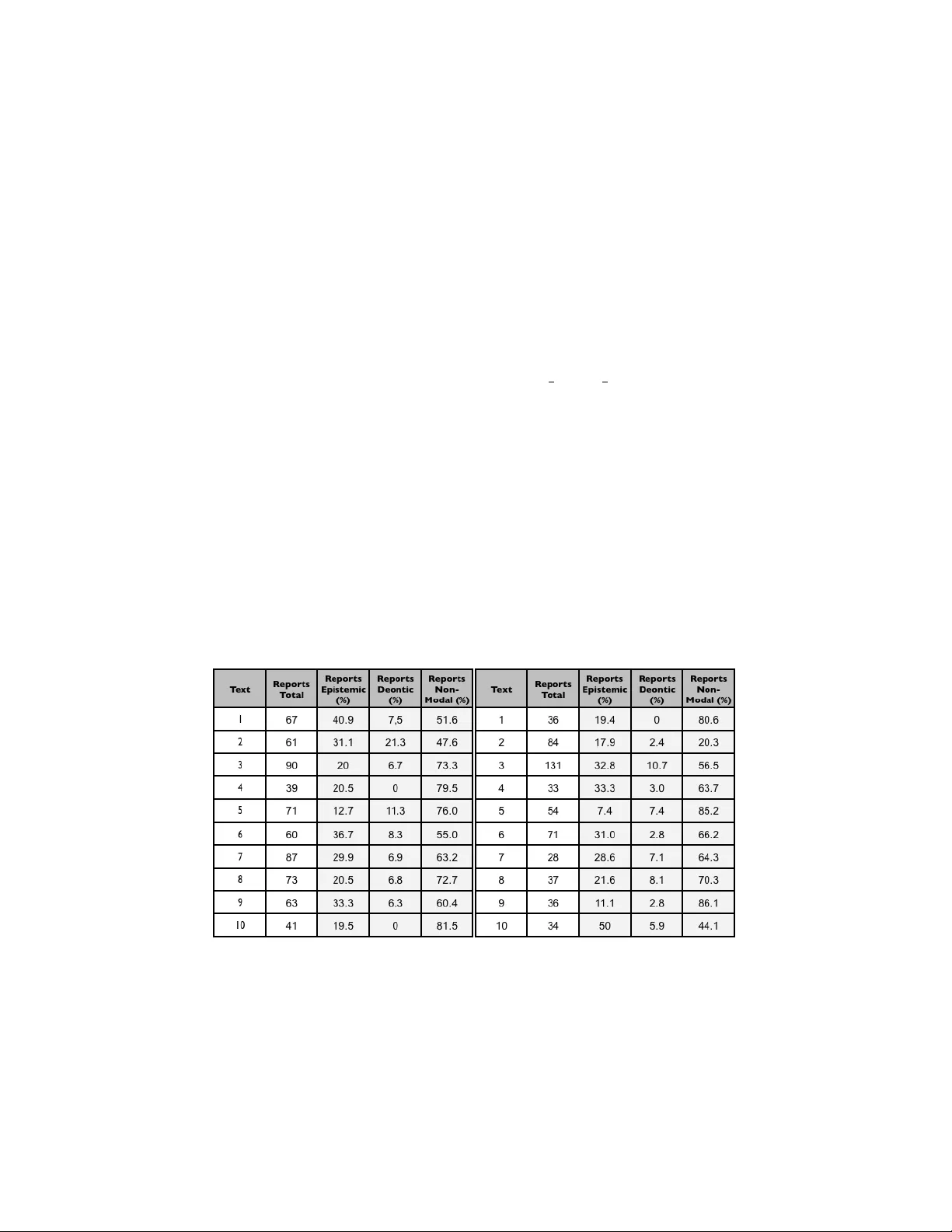
실험에서는 영어 과학 기사들을 대상으로 시스템을 적용했으며, Brown Corpus를 POS 태깅에, Names Corpus를 인명 인식에 활용했다. 결과는 규칙 기반 접근이 비교적 높은 정확도를 보였지만, 복합 문장이나 인용구가 포함된 경우 오분류가 발생했다는 한계가 보고되었다. 또한, 현재 사전은 영어에만 국한되어 있어 다국어 확장은 추가 연구 과제로 남는다.
결론적으로, 이 프레임워크는 모달 동사와 주변 어휘를 결합한 규칙 기반 방법으로 과학 텍스트에서 에피스테믹 모달리티를 효과적으로 탐지하고 구역화한다. 향후 연구에서는 딥러닝 기반 의미 구분 모델을 도입해 규칙의 확장성을 높이고, 부사·형용사까지 포함한 포괄적인 모달리티 사전을 구축함으로써 정확도와 적용 범위를 확대할 수 있을 것으로 기대된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기