A Semi-Automatic Framework to Discover Epistemic Modalities in Scientific Articles
Documents in scientific newspapers are often marked by attitudes and opinions of the author and/or other persons, who contribute with objective and subjective statements and arguments as well. In this respect, the attitude is often accomplished by a …
Authors: Sviatlana Danilava, Christoph Schommer
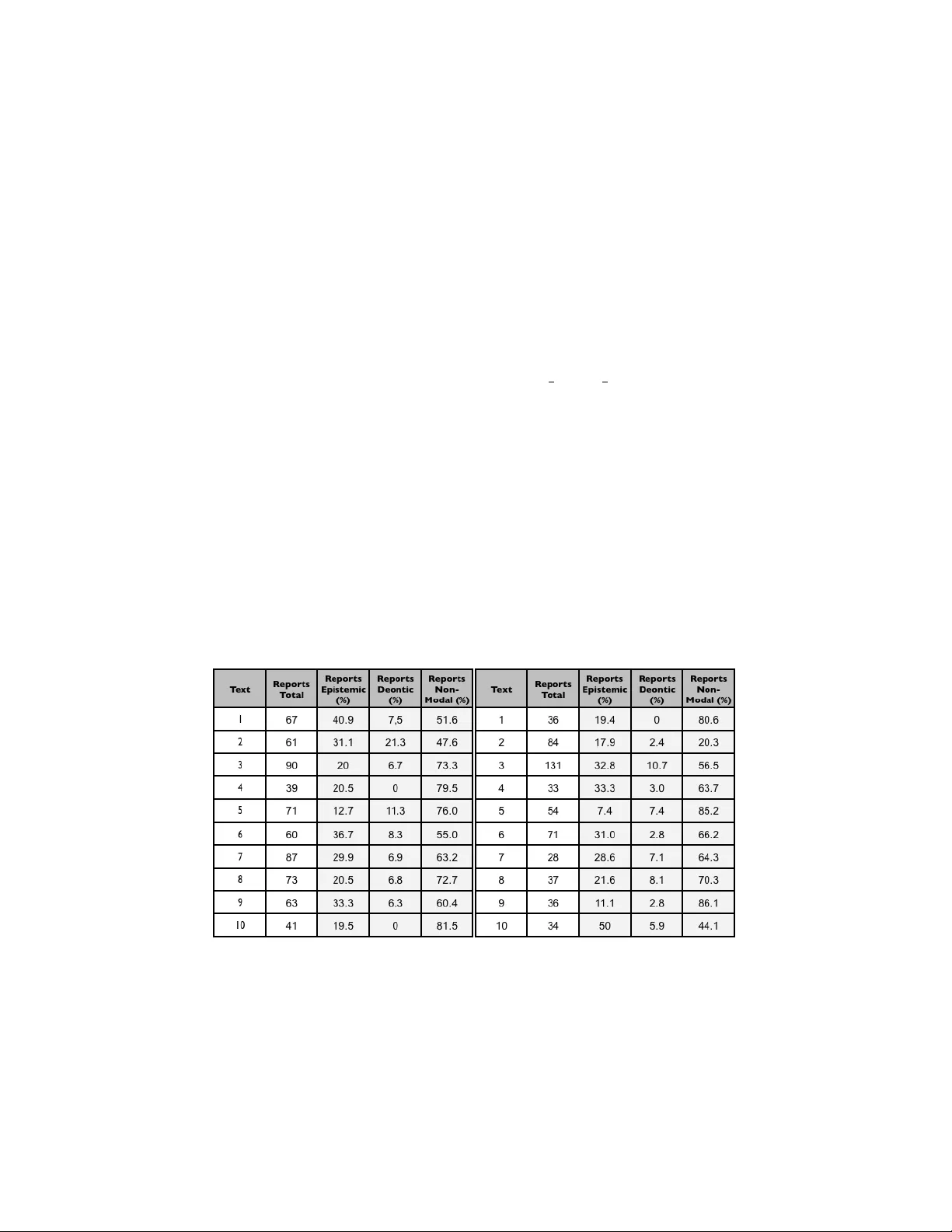
A Semi-Automatic F ramew ork to Disco v er Epistemic Mo dalities in Scien tific Articles Sviatlana Danila v a JW Go ethe-Univ ersit y F rankfurt am Main Dept. of Computer Science and Mathematics Rob ert-Ma y er-Str. 11-15, D-60486 F rankfurt am Main, German y . Email: danila v a@cs.uni-frankfurt.de Christoph Sc hommer Univ ersit y of Luxem b ourg Dept. of Computer Science - ILIAS Lab oratory , MINE Researc h Group 6, Rue Ric hard Coudenho v e-Kalergi, 1359 Luxem b ourg, Luxembourg Email: c hristoph.sc hommer @uni.lu Home: mine.uni.lu June 29, 2018 Abstract Do cumen ts in scien tific newspapers are often mark ed by attitudes and opinions of the author and/or other p ersons, who contribute with ob jectiv e and sub jective statements and arguments as w ell. In this re- sp ect, the attitude is often accomplished b y a linguistic mo dality . As in languages like english, frenc h and german, the mo dality is expressed b y special verbs lik e can, must, ma y , etc. and the sub junctive moo d, an o ccurrence of mo dalities often induces that these v erbs take ov er the role of mo dality . This is not correct as it is prov en that mo dality is the instrumen t of the whole sentence where b oth the adverbs, mo dal par- ticles, punctuation marks, and the intonation of a sentence contribute. Often, a combination of all these instruments are necessary to express a mo dality . In this work, we concern with the finding of mo dal verbs in scientific texts as a pre-step to w ards the discov ery of the attitude of an author. Whereas the input will b e an arbitrary text, the output consists of zones represen ting mo dalities. 1 1 In tro duction Searc h engines that base on the W orld-wide W eb find large amoun ts of hits and information b y an y request. Ho wev er, in telligent searc h queries lik e Which scientists supp o rt hyp othesis A or Do es the autho r b elieve in my opinion are not y et supp orted. In order to answ er, a search engine must first search for appropriate do cuments and then analyse them fast. F or this, in telligent algorithms are required that take into account linguistic insights for a analytical consideration of syntax and style but also for a treatmen t with meta-asp ects like opinion and attitude of the author himself. This is esp ecially true for scientific texts: they are very ob jectiv e in concern of the description of a hypothesis or in discussing diverse problems. The discov ery of the sub jective opinion or attitude of the author is a ma jor topic and is the research ob jective of A ttitude Mining . It concerns with the disco very of meta-information out of do cuments, esp ecially the attitude of an author in resp ect to ev ents, references to other’s work, etc. The attitude can be p ositiv e or negative, but in most cases, it is hidden and to b e prov ed b y indications. A ttitude Mining concerns with the explorativ e disco very of these indications ([21]), but demands for profound knowledge in areas like computer science, linguistics, cognitive sciences and psychology . F ollowing [8], there exist more than 350 lexical style attributes for the attitude, for example to express doubts or b eliefs. T o further motiv ate, the follo wing sen tences should demonstrate the existence of sub jectivity in scien tific texts: → When paleontologists seek the ro ots of life, they head to ro cks of the Archaean Eon, which range from 3.8 billion to 2.5 billion yea rs old. → Australian and Canadian researchers a rgue this w eek in Nature that stro- matolites w ere so diverse and complex that they must have b een alive. → Ma rtin Brasier of Oxfo rd Universit y is less sanguine, a rguing that the structures are more likely chemical precipitates. He also objects to the reasoning in the Nature pap er. “Y ou cant use the argument that com- plexit y is the signature fo r life,” he sa ys. The first sentence is neutral, as it describ es only a pro cedure what palaeon- tologists normally do when they try out to find the origin of life . The second sen tence holds a hypothesis with explanatory statemen ts, the third sentence argumen ts against the h yp othesis in the second sentence having the au- thor/originator referenced. In this resp ect, the mo dality concerns with the sp eak er’s style to mo dify the prop osition of sentences through sub jective 2 comp onen ts. And as we hav e seen ab ov e, many sentences are mo dal, for example → I b elieve she a rrives this mo rning at London Heathro w. → I can not b e in to da y . In western languages, the mo dality is expressed by sp ecial verbs like can, must, may , etc. and by the sub junctiv e mo o d. How ever, this often induces that v erbs tak e o ver the role of mo dality , which is not correct: it is pro v en that mo dalit y is the attribute of the whole sen tence where b oth the adverbs, mo dal particles, punctuation marks, and the intonation of a sentence con- tribute to it. Often, a com bination of all these instrumen ts are necessary to express a certain mo dality . F or example, the sentence → Do y ou really think that? leads to another understanding as with → Y ou do not really think of that? In the first sentence, the combination of r e al ly , think and the transfer in to a question is v ery sub jectiv e, but leav es the recipien t some space. How ev er, the second sen tence is m uc h more sub jective, influencing the recipient’s answer completely and leaving no space for another answer than ’no’. Overall, the complexit y in using mo dalities is one of the ma jor problems, both for the analysis of texts p er se and for machine translation systems. In this w ork, w e concern with finding modal verbs in scien tific texts as a pre- step tow ard discov ering the attitude of an author. Whereas the input will b e an arbitrary text, the output consists of zones representing mo dalities. 2 F undamen tals Originally , the concept of mo dality deriv es from the formal logic. Here, a mo dal expression consists of t w o parts, the mo dal part and the pr op osition part. The mo dal part contains the mo dality , the proposition the actual statemen t. Moreo v er, the mo dal part is either de ontic or epistemic ([18]). A deon tic mo dality describ es the conditions that leads the statemen t to true or false, alw a ys b eing in relation with the reality , for example: 3 → Indeed, the turnover of phytoplankton can b e so high that there can b e inverted pyramids of biomass, in which the standing crop of herbivorous zo oplankton actually exceeds that of the phytoplankton. The verb acts as mo dality , it expresses a certain idea of the ob jective realit y that might come true under certain circumstances. The epistemic mo dalit y , on the other side, concerns with p ersonal exp eriences and a knowledge level of the author, but less with reality: → Australian and Canadian researchers a rgue this w eek in Nature that stro- matolites w ere so diverse and complex that they must have b een alive. The verb must app ears in an epistemic wa y , the statemen t is not prov en yet but still an assumption. This assumption is prov en initiated b y a justifica- tion. F urthermore, the source of information is giv en, for example in → Ma rtin Brasier of Oxfo rd Universit y is less sanguine, a rguing that the structures a re mo re lik ely chemical p recipitates. This sentence contains an explicit source, namely Martin Br asier . Suc h statemen ts are referenced as eviden tial statemen ts and are mostly referenced as a sub-category of an epistemic mo dality . The mo dality is supp orted by a set of expressions: in order to develop a metho dology in resp ect to an automatic recognition, the lexical fundamen t m ust b e found first. Modal verbs form a class of v erbs that add a mo dal meaning to a prop osition. They allow the sender to mo dify the essence of a sentence by p ossibilities, necessities, doubts, b eliefs, etc. In the English language, this is for example must - have to , can - could - may , and will - w ould - shall . Ho wev er, the use of mo dal verbs often leads to am biguit y as the same modal verbs are tak en to express b oth the deontic and the epistemic relev ance. V erbs like b elieve, doubt, accept, reject, etc. describ e the mental state of the sp eaker or his attitude against prop ositional part of the statement. Moreov er, noun may describ e the men tal states or cognitiv e pro cesses as w ell, for example b y doubt, b elief, r eje ction, etc. . Adverbs and adjective are lexic al mo difiers that may assign doubts and b eliefs, for example p erhaps, pr ob ably, p ossibly, c ertain, likely , etc. English mo dal verbs are used both in epistemic and in deontic meanings. Generally , mo dal v erbs express either a p ossibility or a necessit y; eac h mo dal v erb offers sev eral meanings with seman tic and pragmatic differences, for example the word must . In the deontic version, it describ es a necessity with the consideration of an external source, where the prop ositional sub ject is 4 not source of mo dality . In contrast to this, an epistemic v ersion describ es a necessit y , taking a logical justification. The following tw o sentences are deon tic (first) and epistemic (second): → I must go, she is already w aiting fo r me. → Where is John? It is 14h00, he must b e in scho ol. The epistemic reading of mo dal verbs can b e summarised as follows: • Epistemic necessity as a conclusion out of the sp eaker’s evidence: she must b e in her offic e . • Epistemic necessity as logical conclusion out of a common v alid and kno wn fact: she wil l b e in her offic e . • Epistemic p ossibility as an uncertaint y of the sp eak er: she may b e in her offic e . The epistemic usage of mo dal v erbs, the epistemic adv erbs and cognitive v erbs distribute the sub jectivity . The provide a basis for the attitude of the author, as for example in → The individual grains in them could not have accumulated mechanically b ecause the slope of the cone is too great, says Stanley Awramik, a stromatolite exp ert at the Universit y of Califo rnia, Santa Barba ra, who w as not involved in the resea rch. Here, the prop osition is just a p ersonal attitude ( c ould ) of the referenced p erson, that is not prov en at all. Given by the mo dal verbs, there is still enough information to disco ver the author’s attitude and to differen tiate the author’s attitude against others’ attitudes. 3 Selected Researc h W ork The curren t research follo ws divergen t directions, esp ecially in the estab- lishmen t of linguistic and cognitive mo dels. These mo dels supp ort an un- derstanding of the lexical means of expression, their influence to the lexical en vironment, and the mo dification of meaning while using mo dality . In resp ect to mo dalities as a influencing comp onent to discov ering the at- titude, [19] sa ys that it is insufficien t to implemen t the attitude as to b e 5 p ositiv e or negative. Moreov er, the attitude can b e mo dified via c ontextual valenc e shifters b y not , never , none , but m ust take into account mo difiers lik e rather , deeply , and/or few . [1] says that a r ep orte d sp e e ch shares a par- ticular atten tion, since eviden tial asp ects m ust b e examined additionally . [9] argues that the lexical means of expression should not b ecome considered as conv ey or of meaning, but typical structures of attitude phrases can b e observ ed. The analysis of lexical resources that is additionally used to highlight the in tention of the authors to pro duce attitudes is currently under researc h as well. [15] follows an establishment of sp ecific emotional lexicons with p ositiv e, negative, and neutral meaning as well as an automatic extraction of emotion to extend these lexicons. The detection of do cumen t zones to structure the do cument b ecomes more and more p opular. Initially , it has b een presen ted as Ar gumentative Zoning b y T eufel and Mo ens ([24]), but has b een applied in other w orks as well ([22], [23]) or strongly influenced research work on Content Zoning ([5]). The main motiv ation is to summarise do cuments and to zone in discourse- rhetoric zones. T eufel and Mo ens argue that - dep ending on the t yp e, genre and st yle of the text - a standardised structure can often be iden tified. Using scientific articles , they hav e assigned seven argumen tativ e zones to each text, the zoning is then p erformed by a sup ervised learning system. [17] suggests an extend classification where each sen tence is assigned to a rhetoric role. There exist up to ten zones that are classified in to 3 classes. They argue that there exist no sequences of rhetoric roles; sentence ma y b elong to differen t zones, also called as combined zones. F ollowing the idea of Opinion Mining , [4] describ e a mo del to detect opinion wor ds . The idea is to discov er prop ositions, which con tain sub jective lexical expressions and the prop osition itself, for example in combination with ac- cuse , criticise , or doubt . All constituents of eac h sentence receiv e a zoning lab el lik e Opinion Pr op osition , Opinion Holder or Nul l . Another approach are disambiguation pro cesses of mo dal v erbs, where [12] has implemen ted a rule-based system to w ards the disam biguation of the epistemic and deontic meaning of the german v erbs lik e sollen , k¨ onnen , or d¨ urfen . 4 Arc hitecture The framework of this w ork consists of tw o ma jor parts which are presented in Figure 1. The first part fo cus on pre-processing the input text whereas the second part concerns with the disambiguation of the mo dal verbs and semi- 6 automatic classification of the corresp onding sen tences. The pre-pro cessing b egins with a part-of-sp eech tagger, and is follow ed by a mo dule to detect the naming en tities and the pronouns. Figure 1: The arc hitecture of the framework, using the Brown Corpus and the Names Corpus. First, a part-of-sp eech tagger[2] to a given input and sends the in termediate result to the naming and pr onoun engine . After that, mo dalities are disambiguated ( Ambiguity Engine ) while synchronised with the list of mo dality verbs and finally classified (Modality Classifier). The text output is con tains mo dality tags . W e ha v e taken an adv antage in a w ay that w e ha ve used the W ordNet thesaurus ([7]) to establish a list of mo dality v erbs. This list con tains sev eral lexical categories and are found recursively by using a synonym function of W ortNet. Curren tly , there exist several corp ora for the English language, for example the Brown Universit y Corpus ([14]), the In ternational Corpus of English (ICE), and the British National Corpus (BNC). The ICE is a set of corp ora that supp orts v arious dialects of English from around the world. The BNC is a text corpus with b oth written and sp oken English words, co vering co v ers more than 100 million words of the late tw en tieth century from a wide v ariety of genres. Ho wev er, in this w ork, we use the Bro wn Univ ersity Corpus to supp ort the part-of-sp eech tagger to assign a syntactic category to eac h w ord of the input do cument. Here, the w ord is k ept as it o ccurs, meaning that the original word is substituted by a list of syn tactic categories and the original word. W ords of the same ro ot but of another flexion are k ept as they are. In concern of dissolving naming entities , a first metho d concerns with iden ti- fication of p ersonal names on the basis of references that are probably given in the do cument. Per definitionem, this metho d is firstly applied but suffers 7 from div erse prop er names of institution names lik e Max-Planck Institute . In this case, external databases must b e consulted using an automaton (see Figure 2). F or the iden tification of p erson names, w e hav e used the Names Corpus by [13], which contains 5001 female and 3000 male first names. T o iden tify the pronouns in the text, w e restrict the list of p ossible candidates and consider only he , she , and who as they concretely reference to one sp ecific person. Common terms like r ese ar chers or c ommunity memb ers are not considered as well as the pronoun they and c ataphor a . T o identify the pronouns, w e firstly concern with who , whic h o ccurs after a referenced nominal phrase (NP) but in the same sentence as a NP . After having pre-pro cessed the data, the annotated texts are then sent to the classification mo dule. The mo dal v erbs are first disambiguated b efore they are sent to the classifier. As w e must differentiate b etw een deontic and epistemic mo dality , these t w o classes are taken as classes. W e then use the follo wing simple rule sc heme: • A sentence is deontic mo dal if it contains a mo dality word that is deon tic and if there exist mo dality words, which reference to facts. • A sentence is epistemic mo dal if it contains a mo dality w ord that is epistemic and there exist modality words, whic h reference to sub jective attitude of the author. • A sen tence is non-mo dal if there is no lexical evidence for mo dality . The sc heme ma y b ecome impro v ed when other criteria for disam biguation are included, for example the time. A more granular differen tiation b et w een epistemic p ositive and epistemic ne gative is p ossible when considering to- gether the mo dal and prop ositional part of the sentence and classifying the sen tences into A uthor X b elieves in Y (p ositiv e) and Author r eje cts Y (neg- ativ e). The disambigu ation pro cess is shown as disambiguation automaton in Figure 3. The automaton decides to which class a mo dal verb b elongs to. Depend- ing on certain collo cations, the a-priori probability for a mo dal verb to b e epistemic is generally higher than to b e deontic, so that w e take a decision quite early . F or example, if a certain collo cation prov es that a mo dal verb v i is probably epistemic for 90 p ercen t, the automaton classifies v i as to b e epistemic. The classification criteria are: • The mo dal v erb must refers to an epistemic necessity if it o ccurs with the follo wing comp onents: have been , b e and verb present participle , 8 Figure 2: Automaton used for Naming Detection where FN corresp onds to the full first name, LN to the full last name, and ABB to an y kind of abbreviations, lik e the abbreviated middle name. F or example, P . Green follo ws the path of ABB LN , whereas Peter Gr e en empties in FN LN . 9 Figure 3: Automaton used for disam biguation where MV corresp onds to mo dal verb, Vp a the v erb past participle, and Vpr the verb presen t par- ticiple. not represen ts the negation, have , b e , and b e en the corresp onding w ords. 10 have and verb past participle , have b een and verb p resent pa rticiple . In all other cases, the verb should b e deontic. • can is deon tic. • can not refers to the same v erb comp onen ts than must . • could is epistemic. • ma y is epistemic. • might is epistemic as a ten tativ e version of ma y . • will is epistemic since future asp ects are still hypothetic. • shall is deon tic. • should is epistemic as must . In Figure 3, only the paths to the class epistemic are shown; it is assumed that all other paths are either deontic or non-mo dal. A path like MV → have → b een means that the sentence con tains a sequence of verb and have and b e en . Mo dal v erbs express the attitude and opinion of a p erson. In this w ork, w e concern with t w o t yp es of p ersons: • The p erson is the author: the author of the text giv es an opinion and attitude ab out hypotheses, other authors, or other metho ds. This often occurs in scientific articles, for example references or citations. In the follo wing example, the attitude is expressed b y the author himself: → W ould a 100 mm scanning resolution b e sufficient to produce an accurate mo del for paleontological study , o r is a 50 mm scanning resolution a requirement? • The p erson is the third p erson: this happ ens if the author speaks ab out other p ersons and presen ts those attitudes. In this case, these p ersons are referenced explicitly by name or work. This is a typical w ay of discussions in scien tific articles. → Lo we p ointed out their resemblance to mo dern forms but later had doubts. 11 T o estimate the attitude of an author, we only consider epistemic sentences. W e mark the imp ortance of the mo dal part by a predicate M and ¬ M , resp ectiv ely , and the prop ositional part by a predicate H , if the prop ositional part contains arguments pro M , otherwise ¬ H . All epistemic sentences can b e describ ed with M ( H ) or M ( ¬ H ) or ¬ M ( H ) or ¬ M ( ¬ H ) Ho wev er, this step can b ecome conditionally automated as it is quite hard to decide if the mo dal part is M or ¬ M : to do so, w e certainly must find out the lexical information ab out a mo dal verb inside its lexical environmen t. Some modifiers lik e less or mo re and negations lik e not or none must b e tak en in to account as they mo dify the meaning of the mo dal v erbs. Their scop e is imp ortant; an exact analysis implies the definition of complex grammars. Secondly , we must decide if the prop ositional part is H or ¬ H , so that w e concern with prop ositional con ten t analyis. This could b e done with thesauri lik e W ordNet, as these con tain descriptions of relationships b etw een words, for example synonyms. F or example, W ordNet allo ws a multiple calculation of similarity betw een words, dep ending on the distance b et w een these w ords in the thesaurus: the shorter the distance, the similar the words. In this work, w e hav e identified t wo problems: first, the similarity b etw een t wo w ords do es not correspond to the actual situation in the text and second, the similarit y can only be computed b etw een pairs of words, but not betw een phrases or sub-phrases. W e may say at this p oin t that the arc hitecture is hybrid , meaning that the last step of estimating the attitude is done man ually - based on the result that is pro duced. W e then finally get a text result that is comp osed of text and meta information, consisting of t wo parts: the first part is mac hine readable as the data structures sta y constan tly with tags and structural information; it can therefore further b e pro cessed. The second part con tains the epistemic sentences. A third and last step concerns with the segmentation of epistemic sentences dep ending on the hypothesis of the text. F or this, w e may use a graph, where all referenced p ersons are classified into three classes: Pr o references all members P , Contr a all mem b ers C , and Neutr al all members N . Each group can be empt y , but not at the same time, as the author m ust b elong to at least one class. W e then assign • Pr o refers to sentences of M ( H ) and ¬ M ( ¬ H ) • Contr a to sen tences of M ( ¬ H ) and ¬ M ( H ) 12 • Neutr al collects undecidable sen tences, esp ecially of those persons who decline a decision. 5 Example The follo wing steps sho w an example using the follo wing scien tific text: → ”The individual grains in them could not have accumulated mechanically b ecause the slop e of the cone is to o great,” sa ys Stanley Awramik, a stromatolite exp ert at the Universit y of Califo rnia, Santa Barba ra, who w as not involved in the resea rch. Generally , figures, formulas, and c harts are manually pre-pro cessed and sub- stituted by tag-placeholders like FIG or MA TH . The part-of-sp eech tagger then marks the text by tw o subsequen t lo ops, where first all w ords are matc hed against the Br own Corpus . Often, domain-sp ecific termini arise, whic h are unknown and therefore lab eled b y a None . Therefore, a second lo op tak es in to accoun t the morphologic structure of these words, for exam- ple, assigning a suffix tion to the category noun : → [(The, ART), (individual, ADJ), (grains, NNS), (in, IN), (them, PPO), (could, MV), (not, *), (have, HA VE), (accumulated, VP A), (mechanically , RB),...] Recognizing the names, w e then c heck if the text contain s a list of references: in the p ositive case, all names are marked by a Person -tag. These w ords that b egin with an upp ercase letter are considered as well and set to candidates of p ossible first and last names, abbreviations, or other personal names. They are mark ed by a NP -tag. The first names are matched up with the men tioned Names Corpus . How ever, as am biguit y may o ccur, such words are disambiguated man ually . W e then get the follo wing automaton as it has b een describ ed in Figure 3: → . . . < Person > (Stanley , NP) (Awramik, NP) < /Person > , . . . The decision, to whic h ob jets a personal pronoun b elongs to, is taken by considering the lexical categories PPS and WPS : → . . . < Person > (Stanley , NP) (Awramik, NP) < /Person > , . . . . . . < Person Name= Awramik > (who, WPS) < /P erson Name= Awramik > 13 The final classification then leads us to → < EPISTEMIC > . . . (could, MV), (not, *), (have, HA VE), (accumulated, VP A), . . . < /EPISTEMIC > where the tag EPISTEMIC , DEONTIC , or NON-MODAL represent the mo dal state. As modelled in Figure 3, the phrase could not → have → accumulated is ambiguous and leads to ne gMV HA VE VP A . The sen tence therefore is mark ed as epistemic. 6 Classification Results W e ha v e used scientific articles from the fields of palaeontology and biology as a first test set (in the follo wing called SCA ) and con tributions to the scien tific newspap er (in the follo wing called SCI ) as a second test set. All test do cuments of SCA share a common frame like Author X talks ab out his work Y ; text do cuments of SCI share a frame lik e Author X talks ab out the opinions of M scientists in r esp e ct to hyp othesis Y . F or SCA , the texts share a similar length and style; the n umber of epistemic sentences is dominan t to deon tic and/or non-mo dal sen tences (see Figure 4). Figure 4: Percen tal distribution of epistemic, deontic, and non-mo dal sen- tences, where the left chart corresp onds to SCA , the right chart to SCI . 14 Figure 5: Percen tal classification result of selected sentences of SCA and SCI . The correct classified sentences are higher for SCI (87%) than to SCA (78.6%). In total, 312 sen tences hav e been analysed where 55.4% are of SCA and 44.6% from SCI . As presented in Figure 5, the correct classified sentences for SCI (87%) are higher than to SCA (78.6%). In resp ect to the wrong classified sen tences, the mo dal w ord will o ccurs most frequen tly . The follo wing list sho ws some epistemic sen tences that are classified correctly and wrongly: → EPISTEMIC This evidence of an ecological shift preceding phenot ypic change suggests that this pa rt of the sequence may reco rd rapid evolution driven b y shifts in trophic ecology and adaptation to b enthic niches.(co rrect) → EPISTEMIC If this hypothesis is correct how ever the low numb er of sp ecimens displaying intermediate phenot yp es is puzzling and the scenario of replacement of one lineage by another cannot b e ruled out. (correct) → EPISTEMIC Y et direct evidence that feeding controls evolution over ex- tended time scales available only from the fossil record is difficult to obtain b ecause it is rarely p ossible to directly analyze dietary change in long- dead animals. (wrong) → EPISTEMIC First p erhaps the b est-kno wn wo rk on sp ecialisation in fishes concerns stickleback in p ostglacial coastal lakes in Canada where 15 planktivo res and b enthic feeders coexist as t w o reproductively isolated and phenot ypical distinct tropic.(wrong) → EPISTEMIC Lab o rato ry feeding exp eriments and analyses of wild stickle- back p opulations sho w that micro-w ea r exhibits a p rogressive shift from planktivo res to b enthic feeders.(wrong) The main reason for a wrong classification is that - although the mo dal verb only has influenced a part of the whole sentence - the whole sentence has b een assigned as to b e epistemic. Esp ecially , comp osed sentences like → EPISTEMIC-DEONTIC This uncertaint y may relate to the fact that Bud- denb ro ckia genes have undergone rapid sequence evolution, which can either cause artifactual groupings or reduce the supp ort fo r the co rrect grouping. ha ve b een classified twice, i.e., b eing epistemic and deon tic. This is wrong as only the first part ( may ) is epistemic, the second part deontic ( can ). 7 Conclusions The calculation pro cess is c haracterised and influences by a m ultitude of external con tributions, therefore, one of the next steps will b e a step-b y- step automatisation and the access to extended sources. Although the classification result show goo d results, a more detailed consid- eration of mo dal v erbs may b ecome concerned as some of them negativ ely and p ositively influence prop ositional sentences. Last, the lexical environ- men t must b e considered if we wan t to automate the general hypothesis of b eing the mo dal part is M or ¬ M . If a modal verb is discov ered in the sen tence structure, we can assume that the meaning is either p ositive or negativ e; it can b e mo dified, if negations o ccur. W e still hav e in mind to constitute the mo dalit y as one possible metho d to characterise the author’s attitude. This ma y b e accomplished by other w orks of the group, i.e., the zoning of textual do cuments, the imaging of texts to self-organizing maps, and the fingerprin ting of texts using statistic and linguistic v ariables. 8 Ac kno wledgement This work has b een p erformed within the research pro ject TRIAS , which is funded b y the Univ ersit y of Luxem b ourg. 16 References [1] S. Bergler: Con veying attitude with rep orted sp eech. In Computing Attitude and Affect in T ext: Theories and Applications, pp. 1122, 2006. [2] S. Bird, E. Lop er, and E. Klein. The Natural Language T o olkit. V ersion 9.0. 2007. [3] A. L. Berger, S. Della Pietra, and V. J. Della Pietra: A maximum entrop y ap- proac h to natural language pro cessing. Computational Linguistics, 22(1):3971, 1996. [4] S. Bethard, H. Y u, A. Thornton, V. Haziv assiloglou, and D. Jurafsky: Extract- ing opinion propositions and opinion holders using syn tactic and lexical cues. In Computing A ttitude and Affect in T ext: Theories and Applications. pp. 125141. Springer, 2006. [5] C. Brucks, M. Hilker, C. Schommer, C. W agner, and R. W eires: Semi- automated Conten t Zoning of Spam Emails. Lecture Notes on Business In- formation Pro cessing (Springer). [6] S. Danilov a: Semi-automatische Bestimmung der Attit¨ ude ¨ ub er epistemische Mo dalit¨ at. Diplomarb eit. JW Go ethe-Universit y , F rankfurt am Main. F eburary 2008. [7] C. F ellbaum. W ordnet: An Electronic Lexical Database. Bradford Bo oks, 1998. [8] J. Holmes: Doubt and certaint y in esl textb o oks. Applied Linguistics, 9, 1. pp. 2044, 1988. [9] J. Karlgren, G. Eriksson, and K. F ranzen: Where attitudinal expressions get their attitude. In Computing Attitude and Affect in T ext: Theories and Appli- cations, pages 2331, 2006. [10] B. Kipper: Eine Disabiguierungskomponente f ¨ ur Mo dalverben. In K ONVENS, pages 258267, 1992. [11] B. Kipp er: MOD AL YS - a system for the seman tic-pragmatic analysis of mo dal v erbs. In AIMSA, pp. 171180, 1992. [12] B. Kipp er. Ambiguit¨ atsprobleme b ei der Modalverbanalyse, 1995. [13] M. Kantro witz, B. Ross. Names corpus. Carnegie Mellon, 1991. [14] H. Kucera, W. N. F rancis, Brown Universit y . 1967. [15] Y. Y. Mathieu: A computational seman tic lexicon of french v erbs of emotion. In Computing A ttitude and Affect in T ext: Theories and Applications. pp. 109124, 2006. [16] R. Mitko v: Anaphora resolution: The state of the art, 1999. 17 [17] Y. Mizuta, T. Mullen, and N. Collier. Annotation of biomedical texts for zone analysis. T echnical rep ort, National Institute of Informatics, 2-1-2 Hitotsubashi, Chiy o da, T okyo, Japan, 2004. [18] F. R. Palmer: Mo o d and Mo dality . Cambridge Universit y Press. 2001. [19] L. Polan yi, A. Zaenen: Contextual v alence shifters. In Computing Attitude and Affect in T ext: Theories and Applications. pp. 110, 2006. [20] C. Sc hommer, C. Uhde: T extual Fingerprinting with T exts from Parkin, Basse- witz, and Leander. CoRR abs/0802.2234: (2008). [21] J. G. Shanahan, Y. Qu, and J. Wieb e: Computing Attitude and Affect in T ext: Theory and Applications. Springer, 2006. [22] A. Siddharthan, S. T eufel: Whose idea w as this, and why do es it matter? A ttributing scien tific w ork to citations. In NAACL-HL T, 2007. [23] S. T eufel: Argumentativ e zoning for impro ved citation indexing. In Computing A ttitude and Affect in T ext: Theories and Applications, pp. 159169, 2006. [24] S. T eufel, M. Mo ens: Discourse level argumentation in scientific articles: hu- man and automatic annotation. T ow ards Standards and T o ols for Discourse T agging. ACL 1999 W orkshop, 1999. [25] R. Witte, J- M ¨ uller (edt.): T ext Mining: Wissensgewinnung aus nat ¨ urlichsprac higen Dokumen ten, Interner Berich t 2006-5. Universit¨ at Karl- sruhe, F akult at f ¨ ur Informatik, Institut f¨ ur Programmstrukturen und Datenor- ganisation (IPD), 2006. ISSN 1432-7864. [26] G. Zhou and J. Su. Named en tit y recognition using an hmm-based ch unk tagger, 2002. 18
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment