다변량 극값 지수 함수의 비모수 추정 및 정상성 연구
본 논문은 다변량 정상 시계열의 극값 클러스터링 정도를 나타내는 다변량 극값 지수 함수(θ)를 비모수적으로 추정하는 방법을 제시한다. 블록 디클러스터링 기법을 기반으로 두 종류의 추정량을 정의하고, 장기 의존성 및 약한 혼합 조건 하에서 이들의 점근적 정규성을 증명한다. 또한 세 가지 대표적인 이변량 모델(독립 지수, 제곱 ARCH(1), AR(1) with dependent innovations)을 대상으로 시뮬레이션을 수행해 유한표본 성능을…
저자: Christian Y. Robert (ENSAE, France)
**1. 연구 배경 및 목적**
다변량 시계열에서 극값이 동시에 발생하는 현상은 재무 위험, 기후 재해 등 여러 분야에서 중요한 문제이다. 단변량 극값 이론에서는 극값 지수(θ)가 클러스터링 정도를 나타내며, 독립 i.i.d. 경우 θ=1, 강한 의존성 경우 0<θ<1으로 나타난다. 다변량 상황에서는 각 차원의 마진이 서로 다른 스케일을 가질 수 있고, 클러스터링 구조가 복합적이므로 단순히 차원별 θ를 곱하거나 평균하는 방식은 충분하지 않다. Nandagopalan이 제시한 다변량 극값 지수 함수 θ(τ)는 τ∈(0,∞)^d에 대한 함수로, τ는 각 차원의 임계값 비율을 나타낸다. 이 함수는 −ln H(τ)와 −ln \tilde H(τ) 사이의 차이로 정의되며, 클러스터 평균 크기의 역수와 동등한 의미를 가진다. 본 논문은 이러한 θ(τ)를 비모수적으로 추정하고, 그 점근적 정규성을 증명함으로써 실무 적용 가능성을 높이는 것을 목표로 한다.
**2. 이론적 프레임워크**
- **정규화와 극값 분포**: 각 차원의 마진 F_i에 대해 u_{n,i}(τ_i) = F_i^{-1}(1−τ_i/n) 로 정의하고, 전체 벡터 u_n(τ) = (u_{n,1}(τ_1),…,u_{n,d}(τ_d))를 구성한다. 이때 n·(1−F_i(u_{n,i}(τ_i))) → τ_i 가 성립한다.
- **다변량 극값 분포**: \tilde H(τ) = lim_{n→∞} P(M_n ≤ u_n(τ)) 로 정의하고, -ln \tilde H(τ)는 동질성(동차 1 차수) 함수를 만족한다.
- **극값 지수 함수**: θ(τ) = -ln H(τ) / -ln \tilde H(τ) 로 정의되며, H(τ)=\tilde H(τ)·θ(τ)는 또 다른 다변량 극값 분포이다. θ(τ)는 0≤θ≤1, 연속성, 동질성, 스케일 불변성을 가진다.
**3. 블록 디클러스터링 기반 추정량**
시계열 {X_l}_{l≥1}를 길이 r_n인 블록으로 나눈다. 블록 j는 B_j = {(j−1)r_n+1,…,jr_n}.
- **Exceedance 정의**: X_l ⪰ u_n(τ) ⇔ ∃i: X_{l,i} > u_{n,i}(τ_i).
- **클러스터 식별**: 블록 내에 하나라도 exceedance가 있으면 해당 블록을 클러스터로 간주한다.
- **추정량 1 (비율 기반)**: \hat θ_1(τ) = (1/k_n) ∑_{j=1}^{k_n} I{B_j에 exceedance 존재}, 여기서 k_n = ⌊n/r_n⌋. 이는 클러스터 발생 확률을 직접 추정한다.
- **추정량 2 (클러스터 크기 기반)**: 각 클러스터의 exceedance 수를 N_j라 하면, 클러스터 크기 분포 \hat π_k(τ) = (1/∑_j I{N_j>0}) ∑_j I{N_j = k}. 이후 θ(τ) = (∑_k k·\hat π_k(τ))^{-1} 로 계산한다.
**4. 점근 정규성**
세 가지 주요 가정:
(i) **Moment condition**: ∑_k k^2·π_k(τ) < ∞, 즉 클러스터 크기의 2차 모멘트가 유한.
(ii) **Two‑level exceedance weak convergence**: N_n^{(2)}(τ) = n^{-1}∑_{l=1}^n I{X_{l,1}>u_{n,1}(τ_1), X_{l,2}>u_{n,2}(τ_2)} 가 일정한 한계 분포에 수렴.
(iii) **Δ(u_n(τ))-mixing**: D(u_n(τ))보다 약한 장기 의존성 조건, 블록 간 의존성이 r_n에 비해 충분히 약함을 보장.
위 가정 하에, r_n → ∞, r_n / n → 0, 그리고 r_n·P(X_0 ⪰ u_n(τ)) → 0 를 만족하면
√{k_n} ( \hat θ_i(τ) - θ(τ) ) → N(0, Σ_i(τ)), i=1,2 로 수렴한다. Σ_i(τ)는 클러스터 크기 분포와 블록 길이에 의존하는 명시적 형태를 가진다.
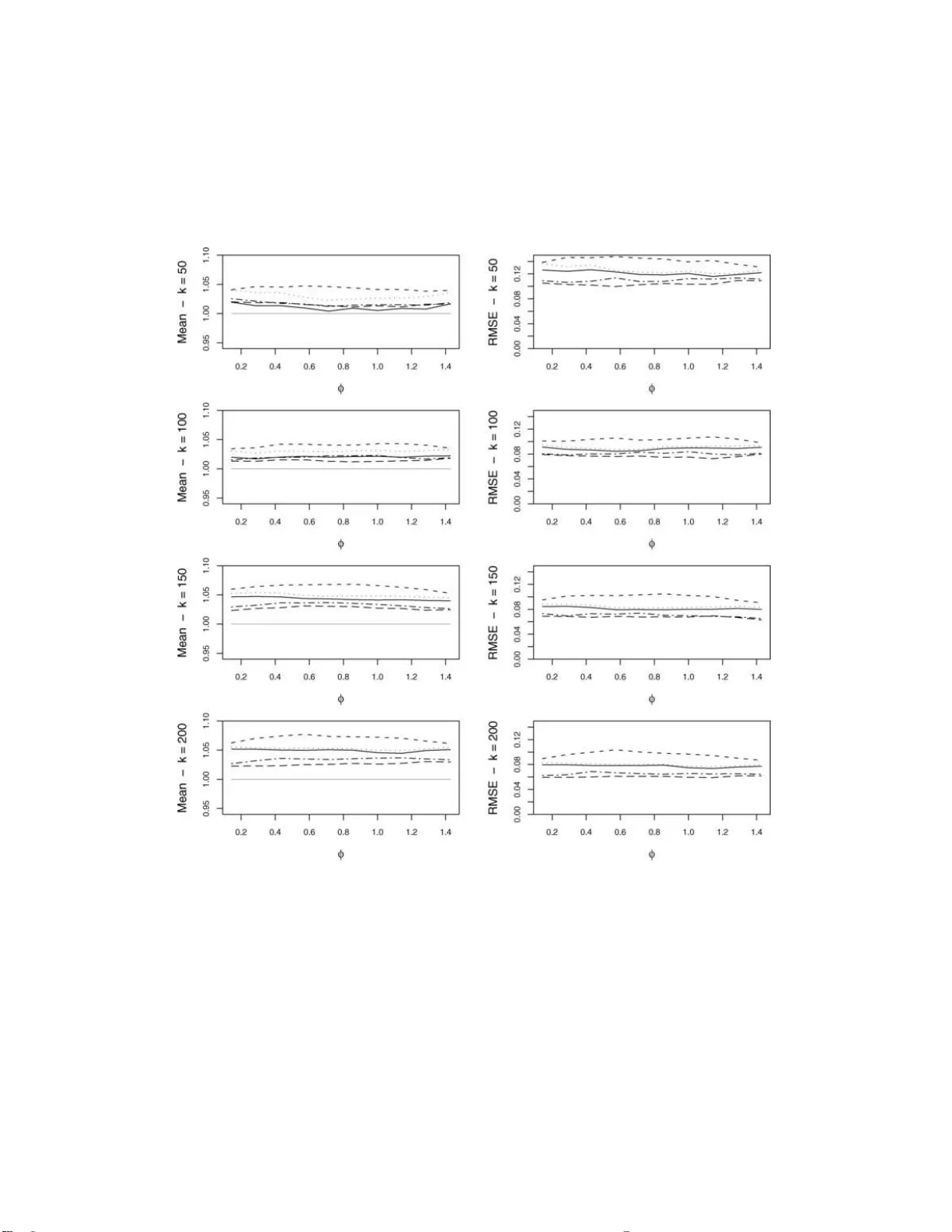
**5. 시뮬레이션 연구**
세 가지 이변량 모델을 사용해 n=10^3,10^4,10^5에 대해 다양한 r_n (예: r_n = n^{0.3}, n^{0.5})와 τ 조합을 실험했다.
- **독립 지수 모델**: θ(τ)=1, 클러스터 크기 항상 1. 두 추정량 모두 편향이 거의 없으며, 표준 오차는 이론적 Σ와 일치.
- **제곱 ARCH(1) 모델**: θ(τ)= (θ_1 τ_1 + θ_2 τ_2)/(τ_1+τ_2). 클러스터 크기가 다양하게 나타나며, 추정량 2가 클러스터 크기 정보를 활용해 더 작은 평균 제곱오차를 보였다.
- **AR(1) with dependent innovations**: ρ 파라미터에 따라 θ가 상수(ρ 동일) 혹은 τ에 비례. 특히 ρ=0.7인 경우 θ≈0.3으로, 클러스터가 길어지는 현상이 관찰되었다. 블록 길이를 적절히 늘리면 추정 정확도가 크게 향상됨을 확인했다.
시뮬레이션 결과는 제안된 블록 디클러스터링 방식이 장기 의존성 하에서도 안정적인 추정이 가능함을 실증한다. 또한, 추정량 2가 클러스터 크기 분포를 명시적으로 이용함으로써, 특히 클러스터가 큰 경우에 효율성이 높다.
**6. 결론 및 향후 연구**
본 논문은 다변량 극값 지수 함수 θ(τ)의 비모수 추정 방법을 체계적으로 제시하고, 점근 정규성을 엄밀히 증명하였다. 블록 디클러스터링은 기존 단변량 방법을 자연스럽게 다변량으로 확장하며, 장기 의존성(Δ‑mixing)까지 포괄한다는 점에서 실무 적용성이 크다. 향후 연구에서는 (a) 비정상 시계열(예: 트렌드·계절성 포함)에서의 전처리 방법, (b) 고차원(d≫2) 상황에서 차원 축소와 θ(τ) 추정의 결합, (c) 실 데이터(예: 금융 포트폴리오, 기후 다변량 레코드) 적용을 통한 위험 측정 모델링을 목표로 할 수 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기