Estimating the multivariate extremal index function
The multivariate extremal index function relates the asymptotic distribution of the vector of pointwise maxima of a multivariate stationary sequence to that of the independent sequence from the same stationary distribution. It also measures the degre…
Authors: Christian Y. Robert (ENSAE, France)
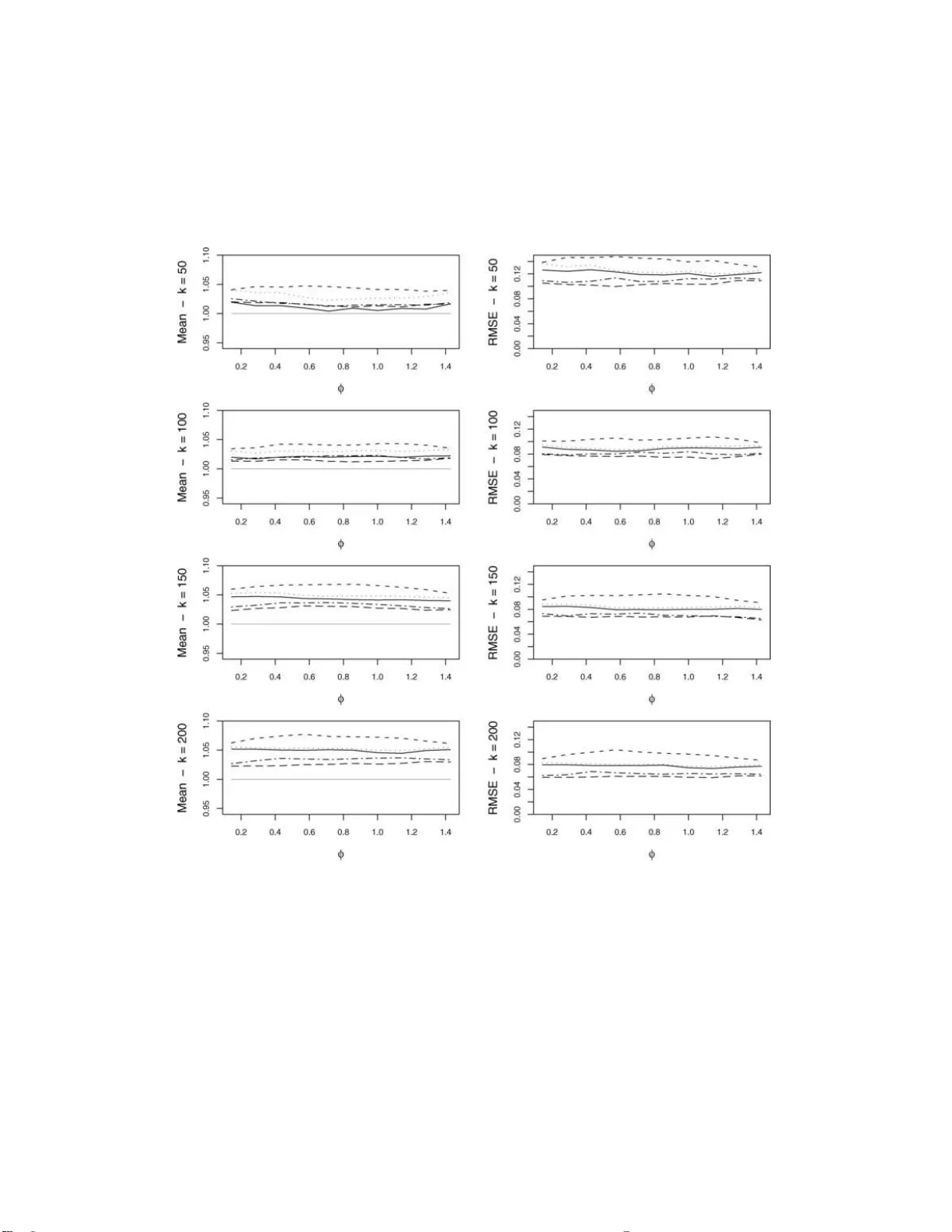
Bernoul li 14 (4), 2008, 1027–10 6 4 DOI: 10.315 0/08-BEJ 145 Estimating the m ultiv ariate extremal index function CHRISTIAN Y. R OBER T ENSAE, Timbr e J120, 3 avenue Pierr e L ar ousse, 92245 Malakoff Ce dex, F r anc e. E-mail: chr ob ert@ensae.fr The multiv ariate ex tremal index fun ction relates the asymptotic distribution of th e v ector of p oin tw ise maxima of a m ultiv ariate stationary sequence to th at of the indep endent sequ en ce from the same stationary distribution. It also measures the d egre e of clustering of extremes in the m ultiv ariate pro cess. In this paper, we construct nonparametric estimators of this function and prov e their asymptotic n ormal ity under long-range dep endence and moment conditions. The results are i llustrated by means o f a simulation study . Keywor ds: cluster-size distribu t io ns; exceedance p oin t pro cesses; extreme v alue theory; multiv ariate extremal index function 1. In tro duction The motiv a tion for this pap er comes from an empir ic a l observ a tio n that time ser ies from hydrology , meteorolo gy , environmental s c ie nces, finance, etc. are heavy-tailed and clus- tered whe n ex tremal events o ccur. In particular , it has b een reco gnized in recent decades that the mo del o f indepe nden t and identically dis tributed (i.i.d.) Ga us sian random v ari- ables is inappropria te for modeling extreme r eturns of r isky assets that are observed during a financial crisis. It is impo rtan t for risk manager s to under stand the r elativ e b e- havior of the v arious financial risks to which their institutions are ex p osed in the even t of large los ses b ecause they hav e to anticipate the diversification opp ortunities so that the risks can b e balanced b y comov ements (b et ween ris k s) or reversal mov ements in s ho rt time interv als (within risks). Although there are well-developed statistical approaches to characterize the cr oss- sectional dep endence structure of extreme r eturns o f risky assets (see, e.g., [ 14 , 20 , 23 , 34 ] a nd the references therein), problems conce rning the estimation o f their temp o ral depe ndence structure ha ve not received muc h attent ion. A notable exc e ption is [ 46 ], whic h prop oses a sp ecific cla ss of max-sta ble pro cesses to mo del simultaneous dep endencies betw een and within fina ncial time s eries. How ever, this ad ho c class o f pro cesses is no t necessarily s uita ble for a ny multiv ariate time ser ie s. The mu ltiv ariate extremal index This is an electronic reprint of th e original article pub li shed by the IS I/BS in Bernoul li , 2008, V ol. 14, No. 4, 1027–1064 . This reprint differs from the original in pagination and typographic detail. 1350-7265 c 2008 ISI/BS 1028 C.Y. R ob ert function, intro duced by Nandagopala n [ 27 , 28 ], is a q ua n tit y which allows o ne to rela te the asymptotic distribution o f the vector of point wise maxima of a s ta tionary s e quence to that of the indep enden t seq uence from the s ame statio nary distribution. It also measures the degr ee of clustering of extremes in the m ultiv a riate pro cess since it is equal to the recipro cal o f the mean num b e r of clustered extr emal even ts. Therefore , it is a sp ecific measure of the tempo ral dep endence structure of the ex treme v alues of the pro cess. It is the aim of this pap er to present a general theory for the inference of this function. W e extend the blo c k decluster ing appr oac h introduced in [ 37 ] to the ca se of multiv ariate stationary pro cesses: we construct p oint wise estimators and study their asymptotic pr op- erties. Three as sumptions are made: (i) ther e exist momen t restr ictions o n the amo un t of clustering of extremes; (ii) the num b er of tw o-level exceedances converges weakly – an ass umption which will guarantee the existence of the asymptotic v ariance– co v ariance matrix o f the estimato r s; (iii) a mixing condition weak er than stro ng mixing is supp osed to hold. Under these ass umptions, we prov e the a symptotic nor ma lit y of our es tima tors. More formally , let ( X l = ( X l, 1 , . . . , X l,d )) l ≥ 1 be a s trictly sta tionary s e quence with sta- tionary distribution function F ( x ) = P ( X l,i ≤ x i , i = 1 , . . . , d ), x = ( x 1 , . . . , x d ) ∈ R d , and univ ar iate mar ginal distributions F i ( x ) = P ( X l,i ≤ x ), i = 1 , . . . , d . W e assume that ther e exists a family of nor malizing sequences in R d , ( u n ( τ ) = ( u n, 1 ( τ 1 ) , . . . , u n,d ( τ d ))) n ≥ 1 , τ = ( τ 1 , . . . , τ d ) ∈ (0 , ∞ ) d , such that lim n →∞ n (1 − F i ( u n,i ( τ ))) = τ for τ > 0 , i = 1 , . . . , d, (1.1) and, for some function ˜ H : (0 , ∞ ) d 7→ [0 , 1] , lim n →∞ n (1 − F ( u n ( τ ))) = − ln ˜ H ( τ ) , for τ ∈ (0 , ∞ ) d . (1.2) A necessar y a nd sufficient co nditio n for the exis tence of a sequence ( u n,i ( τ )) n ≥ 1 which satisfies ( 1.1 ) is that lim x → x f,i ¯ F i ( x ) / ¯ F i ( x − ) = 1 , wher e x f ,i = s up { u : F i ( u ) < 1 } and ¯ F i = 1 − F i (see Theorem 1 .7.13 in [ 22 ]). A na tural choice for u n,i ( τ ) is then given by F ← i (1 − τ /n ), τ ∈ [0 , n ), where F ← i is the g eneralised inv erse of F i , that is, F ← i ( τ ) = inf { x ∈ R : F i ( x ) ≥ τ } . This ass umption is weaker than assuming that F i is in the domain of attra ction of an ex tr eme v alue distribution since the nor malization is linear in this case. How ever, the function ˜ G defined by ˜ G ( τ ) = ˜ H ( τ − 1 1 , . . . , τ − 1 d ) for τ ∈ (0 , ∞ ) d m ust be a multiv ariate extreme v alue distribution r egardless of whether the normalization is linear (see [ 33 ], Pr opositio n 2.1). In particular, ˜ G is a co ntin uous distribution function with unit F r´ echet margins . It is noteworth y that − ln ˜ H is a homog eneous function of degree 1, that is, − ln ˜ H ( c τ ) = − c ln ˜ H ( τ ) fo r all c > 0 and τ ∈ (0 , ∞ ) d . This function is sometimes ca lled the stable t ai l dep endenc e fun ctio n o f F . Let M n,i = max( X 1 ,i , . . . , X n,i ) b e the ma xim um o f the i th comp onent and introduce the vector of point wise max ima M n = ( M n, 1 , . . . , M n,d ). If ( X n ) n ≥ 1 is a sequence of independent and ident ically distributed (i.i.d.) vectors o f random v aria bles (r.v.s), then ( 1.2 ) is equiv alent to P ( M n ≤ u n ( τ )) = P ( M n,i ≤ u n,i ( τ i ) , i = 1 , . . . , d ) → ˜ H ( τ ) , as n → ∞ . The multivariate extr emal index function 1029 This co n vergence can be extended to stationary sequences by assuming the long- range depe ndence D ( u n ( τ ))-condition intro duced in [ 19 ], which is a natura l multiv ariate ver- sion of the well-kno wn univ ar ia te D ( u n ( τ ))-condition (see, e.g., [ 22 ], page 53 ). Let S + ≡ { τ ∈ (0 , ∞ ) d : | τ | = 1 } , where | τ | 2 = P d i =1 τ 2 i . If D ( u n ( τ )) holds fo r each τ ∈ (0 , ∞ ) d and P ( M n ≤ u n ( τ 0 )) c on verges as n → ∞ for each τ 0 in S + , then there exists a function θ : (0 , ∞ ) d 7→ [0 , 1] such that (see Pro position 2.3 in [ 33 ]) lim n →∞ P ( M n ≤ u n ( τ )) = ˜ H ( τ ) θ ( τ ) for τ ∈ (0 , ∞ ) d . (1.3) Let H ( τ ) = ˜ H ( τ ) θ ( τ ) . The function G defined by G ( τ ) = H ( τ − 1 1 , . . . , τ − 1 d ) is also a mul- tiv ar iate e x treme v alue dis tr ibution and has F r´ echet marginals . The function θ ( τ ) = − ln H ( τ ) − ln ˜ H ( τ ) (1.4) is refer r ed to as the mu ltiva riate extre mal index function of ( X n ) n ≥ 1 . The es tima tio n of the function − ln ˜ H for s e q uences of i.i.d. vectors of r.v .s has b een thoroughly inv estiga ted (see, e.g ., [ 9 , 10 , 11 , 16 , 1 8 ]) . But, ex tensions to stationary se- quences are still at a n early stag e (see an example in [ 4 2 ]). The e stimation of the mul- tiv ar iate extremal index function ha s b een little inv estiga ted. Recently , some p oin twise estimators hav e b een pr oposed, but their asy mptotic prop erties have not b een studied. In [ 41 ], Smith and W eis sman intro duce the cla ss of multiv aria te maxima o f moving max- ima ( M 4 ) pro cesses a nd es tablish that the multiv ariate extremal index function of a very wide cla ss o f pro cesses may be a ppr o ximated a rbitrarily closely by one from a M 4 pro- cess. Nevertheless, the estimation of θ via a M 4 pro cess is pra c tica lly infeasible since it necessitates the es tima tio n o f an infinite num ber of parameter s, exce pt if additional approximations are made. Smith and W eissman also give a key characteriza tion of θ ( τ ) as the univ ariate extremal index of a sequence dep e nding on the standardized F r´ echet comp onen ts (see Pro position 2 .1 in [ 41 ] and Prop osition 2.1 below). It follows tha t if one can transfo r m the data to hav e unit F r´ echet comp onen ts, then θ ( τ ) may b e estima ted by univ ariate metho ds such as those prop osed in [ 13 , 40 , 45 ], or [ 37 ]. T o ev a luate the accuracy o f this approach, a simulation study is conducted in [ 12 ] with F erro a nd Segers estimators (see [ 13 ]). In this paper , w e in tro duce t wo new nonpa r ametric estimato rs o f the multiv ariate extremal index function. Its orig inal c o n tribution is to study the as ymptotic prop erties of these es timators. The pap er is orga niz e d as fo llo ws. In Section 2 , w e discus s tw o characterizations of the m ultiv ar iate extremal index function a nd present s ome o f its prop erties. In Section 3, we explain how we construct the estimators. Note that they are based o n a blo c k decluster ing s c heme and a r e o nly determined by the blo ck length, as in [ 37 ]. In Section 4 , we pr esen t and discuss technical conditions. W e then give the asymptotic distr ibutions o f the estima to rs. In Section 5, we inv estigate their finite-s ample behaviors on simulated data. The pro of o f the asymptotic normality of the estimators is found in Section 6. Section 7 concludes. 1030 C.Y. R ob ert 2. The m ultiv ariate extremal index The multiv aria te extremal index function defined by ( 1.4 ) may a lso b e characterized by the a s ymptotic distr ibution of the following p oin t pro cess o f exceeda nces: N ( τ ) n ( B ) = n X l =1 1 { l/n ∈ B , X l u n ( τ ) } , where B is a B orel set included in (0 , 1 ] and { X l u n ( τ ) } = S d i =1 { X l,i > u n,i ( τ i ) } . Contrary to the univ a riate ca se, there a re several w ays to define a multiv ariate thres hold exceedance. Here, we define an ex ceedance as the even t that one o f the comp onen ts of X l exceeds its asso ciated threshold. Supp ose tha t ( 1.3 ) holds and ( X n ) n ≥ 1 satisfies the long- range dep endence ∆( u n ( τ ))-condition introduced in [ 28 ] (which is a little stro nger than the D ( u n ( τ ))-condition). A ne c essary and sufficient condition for the weak conv erg ence of N ( τ ) n ( · ) is then the co n vergence of N ( τ ) n ((0; q n /n ]) to a dis c rete distribution, π ( τ ) , given that ther e is a t least one exceedance , that is, lim n →∞ P ( N ( τ ) n ((0; q n /n ]) = k | N ( τ ) n ((0; q n /n ]) > 0 ) = π ( τ ) ( k ) , where ( q n ) is a ∆( u n ( τ ))-separa ting seq uence (see Sec tion 4). π ( τ ) is referre d to as the cluster-size distribution . Under these ass umptions , the p oint pro cess converges to an homogeneo us co mpound Poisson pro cess, N ( τ ) , with in tensity − θ ( τ ) ln ˜ H ( τ ) and limiting comp ound distribution π ( τ ) . It may b e stres sed that, under some mild additio na l assumptions, we have the follo wing character ization of the m ultiv ariate extremal index function (see [ 19 , 2 4 ]) : θ ( τ ) = ∞ X k =1 k π ( τ ) ( k ) ! − 1 , that is, θ is equal to the r eciproca l of the limiting mean num b er of exceeda nces in a cluster. As mentioned in the Introduction, Smith and W eissman give an a lternativ e characteri- zation of the multiv ariate extre ma l index function in [ 41 ]. They first pro pose to standard- ize the mar gins to the unit F r´ echet distribution and then to express θ ( τ ) as the univ ariate extremal index of the constructed sequence as a linea r combination of the s ta ndardized comp onen ts. In this pap er, we dec ide to standa r dize to the unit Pareto distribution, as in Sectio n 10.5.2 of [ 4 ] (see prop ert y (v)). Prop osition 2.1. L et τ ∈ (0 , ∞ ) d \{ 0 } and assume that lim n →∞ P ( M n ≤ u n ( τ )) = ˜ H ( τ ) θ ( τ ) . Define the asso ciate d univariate stationary se quenc e by The multivariate extr emal index function 1031 Z ( τ ) l = max i =1 ,...,d τ i Y l,i , l ≥ 1 , wher e Y l,i = (1 − F i, − ( X l,i )) − 1 and F i, − ( x ) = P ( X l,i < x ) . θ ( τ ) is then t he u nivari ate extr emal index of the se quenc e ( Z ( τ ) l ) l ≥ 1 , that is, it satisfies, for κ > 0 , lim n →∞ nP ( Z ( τ ) l > v ( τ ) n ( κ )) = κ and lim n →∞ P max l =1 ,...,n Z ( τ ) l ≤ v ( τ ) n ( κ ) = e − θ ( τ ) κ , wher e v ( τ ) n ( κ ) = κ − 1 ( − ln ˜ H ( τ )) n . The pr oof of Prop osition 2.1 is p ostpo ned to Appendix A . Note that it completes the arguments intro duced in Section 10.5.2 of [ 4 ], where it is assumed that the F i are contin uous. It is well known that, in the univ ar ia te case, θ is a co nstan t which does not dep end on τ . In the multiv ariate case, θ is required to b e a constant on the lines throug h the origin. In the next section, we will take into acco un t this homogeneity pro perty when constructing the estimator s . More particular ly , the multiv ariate extr emal index function has the following pr operties (see [ 28 , 3 3 ], Sectio n 10.5.2 in [ 4 ], [ 24 ] and [ 25 ]): 1. 0 ≤ θ ( τ ) ≤ 1 for all τ ∈ (0 , ∞ ) d . 2. θ ( τ ) is a contin uous function o f τ ∈ (0 , ∞ ) d and is s cale inv a rian t, that is, θ ( c τ ) = θ ( τ ) fo r a ll c > 0 a nd τ ∈ (0 , ∞ ) d . 3. θ ca n b e extended b y cont inuit y to [0 , ∞ ) d \{ 0 } . Let τ ( i ) = (0 , . . . , 0 , τ i , 0 , . . . , 0) . The univ a riate extremal index, θ i , say , for the i th comp onent sequence ( X n,i ) n ≥ 1 exists and θ i = θ ( τ ( i ) ). { 0 } is a dis con tinuit y of θ if there exist i and j suc h that θ i 6 = θ j . Note that the functions H and ˜ H can b e extended by contin uit y to [0 , ∞ ) d . In pa r ticular, we hav e ˜ H ( τ ( i ) ) = e − τ i , H ( τ ( i ) ) = e − θ i τ i and ˜ H ( 0 ) = H ( 0 ) = 1. 4. Bo unds for θ ( τ ) are given by max( θ 1 τ 1 , . . . , θ d τ d ) − ln ˜ H ( τ ) ≤ θ ( τ ) ≤ θ 1 τ 1 + · · · + θ d τ d − ln ˜ H ( τ ) . The upp er b ound co rrespo nds to the ca se wher e G ha s independent comp onents a nd the low er b o und c orresp onds to the case where G has totally dep enden t comp onent s. 5. If G and ˜ G have indep enden t comp onen ts, then θ ( τ ) = P d i =1 θ i τ i / P d i =1 τ i . In the next sec tio ns, we will illustrate our technical conditions and our limiting r esults with three examples of biv ariate pro cesses. Let us now intro duce these pro cesses and discuss their extr emal pr operties. The firs t pro cess will b e c o nsidered as the b enc hmark bec ause all the technical conditions can b e ea sily verified and the calculations of the asymptotic v aria nces of the e stimators can be car ried o ut ex plicitly . It is the biv a r iate pro cess with independent univ ariate sequences and indep endent co mp onents. The seco nd 1032 C.Y. R ob ert pro cess is a biv ariate squar ed ARCH( 1) pro cess with indep enden t co mponents. The r e is no cr oss-sectional dep endence, but each comp onen t is time dep enden t. The third pro cess is a biv ariate autoregr e ssiv e pro cess of o rder 1 with dep enden t innov a tions. By mo difying the v alues o f the pa rameters of this pro cess, we may have cross- sectional dep endence or independenc e a nd temp oral dep endence or indep endence. Reca ll that for d = 2 , we have ( X l = ( X l, 1 , X l, 2 )) l ≥ 1 , τ = ( τ 1 , τ 2 ) and u n ( τ ) = ( u n, 1 ( τ 1 ) , u n, 2 ( τ 2 )). Example 2.1. The biv ariate indep e ndent pro cess with indep endent co mponents: X l, 1 = ξ l, 1 and X l, 2 = ξ l, 2 , wher e ( ξ l, 1 ) l ≥ 1 and ( ξ l, 2 ) l ≥ 1 , are tw o indep enden t s equences of i.i.d. standard ex ponential r.v.s. It is easily seen tha t u n, 1 ( τ ) = u n, 2 ( τ ) = ln( n/τ ), − ln ˜ H ( τ ) = τ 1 + τ 2 and θ ( τ ) = 1 . The cluster of exc e edances o f N ( τ ) are of size 1, that is, the cluster-size distribution is given by π ( τ ) (1) = 1, π ( τ ) ( k ) = 0 for k > 1. The asso ciated series is g iv en b y Z ( τ ) l = ma x ( τ 1 exp( ξ l, 1 ) , τ 2 exp( ξ l, 2 )) a nd we hav e v ( τ ) n ( κ ) ∼ n κ − 1 ( τ 1 + τ 2 ) as n → ∞ . Example 2. 2. A biv ariate squared ARCH(1) pro cess with independent comp o- nent s: X l +1 ,i = ( η i + λ i X l,i ) ξ 2 l +1 ,i for l ≥ 1 and i = 1 , 2 , where ( ξ l, 1 ) l ≥ 1 and ( ξ l, 1 ) l ≥ 2 are t wo indep enden t sequences of i.i.d. standard Gaussian r.v.s, η i > 0 and 0 < λ i < 2e γ , where γ is Euler’s constant. W e as s ume that X 1 , 1 and X 1 , 2 are drawn from the univ ariate sta tio nary dis tr ibutions. Let κ i be suc h that E ( λ i ξ 2 l,i ) κ i = 1 for i = 1 , 2 . There ex ist constants c i such that ¯ F i ( x ) ∼ c i x − κ i as x → ∞ . It follows that u n,i ( τ ) ∼ ( nc i /τ ) 1 /κ i as n → ∞ (see, e .g ., [ 21 ] and [ 17 ]). Let R i ( x ) = ♯ { j ≥ 1 : ˜ X i Q j l =1 ( λ i ξ 2 l,i ) > x } where ˜ X i is independent of ( ξ l,i ) l ≥ 1 and P ( ˜ X i > x ) = x − κ i , x ≥ 1 , a nd define p k,i = P ( R i (1) = k ), k ≥ 0 . Since the comp onen ts are indep enden t, we hav e − ln ˜ H ( τ ) = τ 1 + τ 2 and θ ( τ ) = θ 1 τ 1 + θ 2 τ 2 τ 1 + τ 2 . Moreov er, θ i = p 0 ,i = R ∞ 1 P ( W ∞ j =1 Q j l =1 ( λ i ξ 2 l,i ) ≤ x ) κ i x − κ i − 1 d x , i = 1 , 2 . The clusters of exceeda nces may b e of any size. One can show that the cluster-size distribution of N ( τ ) is g iv en by π ( τ ) = θ 1 τ 1 θ 1 τ 1 + θ 2 τ 2 π 1 + θ 2 τ 2 θ 1 τ 1 + θ 2 τ 2 π 2 , where π i ( k ) = ( p k − 1 ,i − p k,i ) /p 0 ,i , k ≥ 1 and i = 1 , 2 (se e [ 17 ]). Since there is no analytic expres s ion for the stationar y univ ariate distr ibutions, a n explicit fo rm o f the asso ciated seq ue nc e cannot be g iv en. Example 2.3. A biv a riate autoreg ressive pr ocess of order 1 with dep enden t innov ations: X l +1 ,i = ρ i X l,i + ξ l +1 ,i for l ≥ 1 and i = 1 , 2, where ( ξ l, 1 , ξ l, 2 ) l ≥ 1 is a sequence o f i.i.d. vectors with a biv ar iate unit F r´ ec het extreme v alue distributio n, that is , The multivariate extr emal index function 1033 P ( ξ l, 1 ≤ x 1 , ξ l, 2 ≤ x 2 ) = exp − 1 x 1 + 1 x 2 A x 1 x 1 + x 2 := exp( − B ( x 1 , x 2 )) , where A is a conv ex and differentiable function b ounded b elow by max( x, 1 − x ) and ab o ve b y 1. W e a ssume tha t 0 < ρ i < 1 and that ( X 1 , 1 , X 1 , 2 ) is dr a wn from the statio nary distribution. W e hav e that ¯ F i ( x ) ∼ (1 − ρ i ) − 1 x − 1 as x → ∞ and it follows that u n,i ( τ ) ∼ n/ ((1 − ρ i ) τ ) as n → ∞ . B y Theore m 2.1 in [ 36 ], we deduce that − ln ˜ H ( τ ) = ∞ X k =0 B (((1 − ρ 1 ) ρ k 1 τ 1 ) − 1 , ((1 − ρ 2 ) ρ k 2 τ 2 ) − 1 ) . Similar ar gumen ts as in Section 6 of [ 33 ] show that θ ( τ ) = − ln ˜ H (( τ 1 , τ 2 )) + ln ˜ H (( ρ 1 τ 1 , ρ 2 τ 2 )) − ln ˜ H (( τ 1 , τ 2 )) . It is imp ortant to note that if ρ 1 = ρ 2 = ρ , then − ln ˜ H ( τ ) = B ( τ − 1 1 , τ − 1 2 ) and θ ( τ ) = (1 − ρ ). The multiv aria te index do es not de p end o n τ . If A = 1 , that is , if ξ l, 1 and ξ l, 2 are indep enden t, then − ln ˜ H ( τ ) = τ 1 + τ 2 and θ ( τ ) = ((1 − ρ 1 ) τ 1 + (1 − ρ 2 ) τ 2 ) / ( τ 1 + τ 2 ). The cluster s of exceedances may b e of any size. The a symptotic dis tribution of N ( τ ) n may b e obtained by using results o f Section 2 in [ 6 ]. Moreover, since there is no analy tic expression fo r the stationar y biv ar iate distribution, a n explicit for m of the asso ciated sequence ca nnot b e g iven. 3. Defining the estimators In this section, we expla in o ur a pproach to estimating the m ultiv a riate extremal index function. As in [ 37 ], we consider a blo ck declustering scheme and estimate intermediate thresholds such that we only have to take in to a ccoun t the blo ck length to study the asymptotic distr ibution of the estimators . Let us divide [1 , . . . , n ] int o k n blo c ks of length r n ( k n is the integer part of n/r n ), I j = [( j − 1) r n + 1 , . . . , j r n ] for j = 1 , . . . , k n and a last blo ck I k n +1 = [ r n k n + 1 , . . . , n ]. The num ber of exceeda nces for the j th block is defined b y N ( τ ) r n ,j = P l ∈ I j 1 { X l u r n ( τ ) } for j = 1 , . . . , k n , where u r n ,i ( τ i ) = F ← i (1 − τ i /r n ), i = 1 , . . . , d . The main iss ue when using these q uan tities to c o nstruct estimator s is that the thresholds u r n ,i ( τ i ) ar e unknown since they dep end on the univ ariate mar ginals of the statio na ry distribution. They have to b e estimated from the data. As in [ 37 ], we consider estimato r s of the thr esholds which are based on the order statistics. If 0 < τ ≤ r n , let ˆ u r n ,i ( τ ) = X ( ⌈ k n τ ⌉ ) ,i , where X ( k ) ,i is the 1034 C.Y. R ob ert k th lar gest of X 1 ,i , . . . , X k n r n ,i and ⌈ x ⌉ denotes the smallest int eger grea ter tha n or equal to x . If τ = 0, le t ˆ u r n ,i (0) = ∞ . Now, define ˆ N ( τ ) r n ,j = P l ∈ I j 1 { X l ˆ u r n ( τ ) } for τ ∈ [0 , r n ] d . In order to estimate the m ultiv a riate extrema l index function, it seems natural to exploit the characterization given by ( 1.4 ). Let N ( τ ) n ≡ N ( τ ) n ((0 , 1]) and note that, under appropria te conditions (see the following section), lim n →∞ P ( N ( τ ) n = 0) = lim n →∞ P ( M n ≤ u n ( τ )) = H ( τ ) and that, by ( 1.2 ), lim n →∞ E ( N ( τ ) n ) = lim n →∞ n (1 − F ( u n ( τ ))) = − ln ˜ H ( τ ) . Let us use the empirical distribution of the num b er o f exceedances to provide empirical counterparts o f H ( τ ) and − ln ˜ H ( τ ). W e define ˆ H n ( τ ) = 1 k n k n X j =1 1 { ˆ N ( τ ) r n ,j =0 } and − ln c ˜ H n ( τ ) = 1 k n k n X j =1 ˆ N ( τ ) r n ,j for τ ∈ [0 , r n ] d . One may consider − ln ˆ H n ( τ ) / ( − ln c ˜ H n ( τ )) in o rder to estimate θ ( τ ). But, unlike the m ultiv ariate extrema l function, this function is no t s c ale inv aria n t (see Pr operty 2 in the previous section). Hence, we intro duce a first estimator which sa tisfies the homog eneit y prop ert y: ˆ θ (1) n ( τ ) = − ln ˆ H n ( τ /L ( τ )) − ln c ˜ H n ( τ /L ( τ )) , τ /L ( τ ) ∈ [0 , r n ] d \{ 0 } , where L is a known function fro m [0 , ∞ ) d \{ 0 } to (0 , ∞ ) which is homo geneous o f order 1. F o r e x ample, co nsider the family L c,a ( τ ) = c ( P d i =1 | τ i | a ) 1 /a for a > 0 a nd c > 0 . The sec o nd estimator is derived fro m the characteriza tio n of Prop osition 2 .1 . Let us consider the num ber o f excee da nces of ( Z ( τ ) n ) n ≥ 1 ab o ve the threshold v ( τ ) n ( κ ): N ( κ , τ ) n = n X l =1 1 { Z ( τ ) l >v ( τ ) n ( κ ) } . Prop osition 2.1 implies that lim n →∞ − ln P ( N ( κ , τ ) n = 0) = θ ( τ ) κ . In or der to construct an alternative es timator of the extremal index function, w e ca n follow the approach developed in [ 37 ]. First, we r eplace the Z ( τ ) l by their e mpirical count erpa rts since the marginal distribution functions F i are unknown. Let R l,i denote the r ank of X l,i among The multivariate extr emal index function 1035 ( X 1 ,i , . . . , X k n r n ,i ). In the cas e of ties, the low est r a nk for the ties is us ed for ea c h tie. W e define ˇ Z ( τ ) l = max i =1 ,...,d τ i ˇ Y l,i , where ˇ Y l,i = k n r n k n r n + 1 − R l,i . W e then intro duce the num ber of exc e edances of ( ˇ Z ( τ ) l ) l ∈ I j for the j th blo ck: N ( κ , τ ) r n ,j = P l ∈ I j 1 { ˇ Z ( τ ) l >v ( τ ) r n ( κ ) } . As previously , v ( τ ) r n ( κ ) is unknown. How ever, it may b e esti- mated by ˆ v ( τ ) r n ( κ ) = ˇ Z ( τ ) ( ⌈ k n κ ⌉ ) , where ˇ Z ( τ ) ( ⌈ k n κ ⌉ ) is the ( ⌈ k n κ ⌉ )th-largest v a lue among ˇ Z ( τ ) 1 , . . . , ˇ Z ( τ ) k n r n . Finally , let us define ˆ N ( κ , τ ) r n ,j as the counterpart of N ( κ , τ ) r n ,j , where v ( τ ) r n ( κ ) is repla c ed by ˆ v ( τ ) r n ( κ ), and introduce the second es timator ˆ θ (2) n ( τ ) = − κ − 1 ln 1 k n k n X j =1 1 { ˆ N ( κ , τ ) r n ,j =0 } ! , τ ∈ [0 , ∞ ) d \{ 0 } , κ ∈ (0 , r n ] . Note that this estimator is scale inv ariant without tr ansformation on τ . R emark 3.1. In [ 37 ], three estimator s of the univ ariate extrema l index are intro duced. The first estimato r, deno ted b y ˆ θ ( · ) 1 ,n , is very clo se o f our estimator s ˆ θ (1) n and ˆ θ (2) n when they are ev aluated at the p oin ts τ = τ ( i ) , i = 1 , . . . , d . In fact, if L is assumed to b e a constant eq ua l to 1 and κ = τ i , we hav e ˆ θ (1) n ( τ ( i ) ) = ˆ θ ( τ i ) 1 ,n k n τ i ⌈ k n τ i ⌉ − 1 and ˆ θ (2) n ( τ ( i ) ) = ˆ θ ( τ i ) 1 ,n . It follows that in the univ a riate cas e (i.e., d = 1), b oth estimator s hav e the s a me asymp- totic b eha vior as ˆ θ ( · ) 1 ,n . 4. Main result In this section, we first pres e nt and discuss technical conditions which ar e required for the asymptotic normality of the estimators. Thes e c o nditions are q uite similar to co nditio ns int ro duced in [ 37 ] which ar e used, in particular, to establish the asymptotic pro perties of the estimator of the univ ar iate extrema l index ˆ θ ( τ ) 1 ,n (see Remark 3.1 ab o ve). They might app ear quite stringent in compariso n with those of [ 45 ], where the asy mptotic prop erties 1036 C.Y. R ob ert of the blo c ks and r uns estimators of the univ a riate extrema l index ar e studied. T his is not the c a se for tw o reaso ns. First, we estimate in termediate thresho lds and do not consider them as tuning parameters, contrary to [ 45 ]. This a llows us to es ta blish the asymptotic pr o perties of in termediate empirical pro cesses, which is mor e complica ted and necessitates more conditions. Seco nd, these conditions gua ran tee the existence of the asymptotic v aria nces of the estimator s, whereas [ 45 ] just assumes the conv erg ence of the v ar iance of a partia l sum to the asymptotic v ariance and do es not give any conditio n such that this conv erg ence ho lds. Finally , one can r efer to Section 4 o f [ 37 ] for a comparis on of similar conditions to those in [ 38 ] that are needed for conv ergence of the tail empirical pro cess o f a univ ariate stationary s e quence. Let us turn to s ome definitions which are the natura l multiv ariate versions o f definitions from [ 32 ] (see also [ 28 ] and [ 33 ]). Definition 4. 1. Fix an inte ger m ≥ 1 . L et F p,q = F p,q ( τ 1 , . . . , τ m ) b e the σ -algebr a gener ate d by the events { X l u n ( τ j ) } , p ≤ l ≤ q and 1 ≤ j ≤ m , and let α n,l ( τ 1 , . . . , τ m ) ≡ sup | P ( A ∩ B ) − P ( A ) P ( B ) : A ∈ F 1 ,t , B ∈ F t + l,n , 1 ≤ t ≤ n − l | . The ∆( { u n ( τ j ) } 1 ≤ j ≤ m ) - condition is said to hold if lim n →∞ α n,l n ( τ 1 , . . . , τ m ) = 0 for some se quenc e l n = o ( n ) . Definition 4.2. Supp ose that the ∆( { u n ( τ j ) } 1 ≤ j ≤ m ) -c ondition holds. A se quenc e of p ositive inte gers ( q n ) n ≥ 1 is said t o b e ∆( { u n ( τ j ) } 1 ≤ j ≤ m ) - separ ating if, as n → ∞ , q n = o ( n ) and t her e exists a se quenc e ( l n ) n ≥ 1 such that lim n →∞ nq − 1 n α n,l n ( τ 1 , . . . , τ m ) = 0 and l n = o ( q n ) . W e now give a deco mposition of the num b ers of exceedances when co nsidering tw o vectors of thresholds, u n ( τ 1 ) and u n ( τ 2 ) for τ 1 , τ 2 ∈ [0 , ∞ ) d . W e define N ( τ 1 , τ 2 ) n, 0 ,p = p X l =1 1 { X l u n ( τ 1 ) }∪{ X l u n ( τ 2 ) } , N ( τ 1 , τ 2 ) n, 1 ,p = p X l =1 1 { X l u n ( τ 1 ) }\{ X l u n ( τ 2 ) } , N ( τ 1 , τ 2 ) n, 2 ,p = p X l =1 1 { X l u n ( τ 2 ) }\{ X l u n ( τ 1 ) } , N ( τ 1 , τ 2 ) n, 3 ,p = p X l =1 1 { X l u n ( τ 1 ) }∩{ X l u n ( τ 2 ) } . Note that N ( τ 1 , τ 2 ) n, 0 ,p = P 3 i =1 N ( τ 1 , τ 2 ) n,i,p and N ( τ i ) n = N ( τ 1 , τ 2 ) n,i,n + N ( τ 1 , τ 2 ) n, 3 ,n , i = 1 , 2 . W e contin ue by pres en ting the first technical condition and then discus s ing the weak conv ergence of the sequence ( N ( τ 1 , τ 2 ) n, 1 ,n , N ( τ 1 , τ 2 ) n, 2 ,n , N ( τ 1 , τ 2 ) n, 3 ,n ) n ≥ 1 . The multivariate extr emal index function 1037 Condition ( C1 ). (i) The stationary se quenc e ( X n ) n ≥ 1 has a multivariate ext r emal index function θ > 0 . (ii) F or e ach τ 1 , τ 2 ∈ [0 , ∞ ) d \{ 0 } , the ∆( u n ( τ 1 ) , u n ( τ 2 )) -c ondition holds and ther e exists a pr ob ability me asur e π ( τ 1 , τ 2 ) such that for al l i 1 ≥ 0 , i 2 ≥ 0 , i 3 ≥ 0 , i 1 + i 2 + i 3 ≥ 1 , π ( τ 1 , τ 2 ) ( i 1 , i 2 , i 3 ) = lim n →∞ P ( N ( τ 1 , τ 2 ) n,h,q n = i h , h = 1 , 2 , 3 | N ( τ 1 , τ 2 ) n, 0 ,q n > 0) (C1.a) for some ∆( u n ( τ 1 ) , u n ( τ 2 )) -sep ar ating se quenc e ( q n ) n ≥ 1 . F o r τ i = ( τ 1 ,i , . . . , τ d,i ) and i = 1 , 2, let τ 1 ∨ τ 2 = ( τ 1 , 1 ∨ τ 1 , 2 , . . . , τ d, 1 ∨ τ d, 2 ). F or ea c h τ 1 , τ 2 ∈ [0 , ∞ ) d \{ 0 } , let ζ ≡ ( ζ ( τ 1 , τ 2 ) l, 1 , ζ ( τ 1 , τ 2 ) l, 2 , ζ ( τ 1 , τ 2 ) l, 3 ) l ≥ 1 be an sequence o f i.i.d. vec- tors of integer r.v.s with distribution π ( τ 1 , τ 2 ) and η ( τ 1 , τ 2 ) b e an r.v. with Poisso n distribution and par ameter − θ ( τ 1 ∨ τ 2 ) ln( ˜ H ( τ 1 ∨ τ 2 )) indepe nden t of the sequence ζ . The probability measure π ( τ 1 , τ 2 ) is a k ey parameter to characterize the distribution of the limiting tw o-level ex ceedance p oint pro cess (see Theor em 2.5 a nd its pr oof in [ 32 ] for the univ ariate c ase). The following pro p osition is concerned with the weak conv ergenc e of the related sequence o f the num ber s o f excee da nces. Prop osition 4.1. Su pp ose that ( C1 ) holds. Then, ( N ( τ 1 , τ 2 ) n, 1 ,n , N ( τ 1 , τ 2 ) n, 2 ,n , N ( τ 1 , τ 2 ) n, 3 ,n ) D → ( N ( τ 1 , τ 2 ) 1 , N ( τ 1 , τ 2 ) 2 , N ( τ 1 , τ 2 ) 3 ) (4.1) D = η ( τ 1 , τ 2 ) X l =1 ( ζ ( τ 1 , τ 2 ) l, 1 , ζ ( τ 1 , τ 2 ) l, 2 , ζ ( τ 1 , τ 2 ) l, 3 ) . Mor e over π ( τ 1 , τ 2 ) is sc ale invaria nt , that is, for e ach τ 1 , τ 2 ∈ [0 , ∞ ) d \{ 0 } and c > 0 , π ( c τ 1 ,c τ 2 ) = π ( τ 1 , τ 2 ) . The pro of of Pro position 4.1 is p ostponed to Appendix A . Let us examine the distribution of the cluster sizes of the tw o-level e x ceedances, π ( τ 1 , τ 2 ) , for the first example introduced in Section 2. The distr ibution for the seco nd example may b e derived by considering its Lapla c e tra nsform. The distribution for the third example may b e derived by using results of Section 2 in [ 6 ]. Example 2.1 (c ontinue d). The clusters of the t wo-level e x ceedances ar e of s ize 0 or 1. More precise ly , the distr ibution of the clus ter sizes is given by π ( τ 1 , τ 2 ) (1 , 0 , 0) = ( τ 2 , 1 − τ 2 , 2 ) + + ( τ 1 , 1 − τ 1 , 2 ) + τ 1 , 1 ∨ τ 1 , 2 + τ 2 , 1 ∨ τ 2 , 2 , π ( τ 1 , τ 2 ) (0 , 1 , 0) = ( τ 2 , 2 − τ 2 , 1 ) + + ( τ 1 , 2 − τ 1 , 1 ) + τ 1 , 1 ∨ τ 1 , 2 + τ 2 , 1 ∨ τ 2 , 2 , 1038 C.Y. R ob ert π ( τ 1 , τ 2 ) (0 , 0 , 1) = 1 − π ( τ 1 , τ 2 ) 2 (1 , 0 , 0) − π ( τ 1 , τ 2 ) 2 (0 , 1 , 0) . Let us turn to the s econd technical condition which is a multiv aria te version of Con- dition (C2) in [ 37 ]. Note that, s ince the estimated thresholds for our estimato rs are con- tingent o n k n τ i , i = 1 , . . . , d , a nd k n κ , and since k n may b e chosen up to a prop ortional factor, we ca n as sume, without loss o f generality , that τ and κ are b ounded. Hence, let us now assume tha t τ ∈ [0 , 1] d . Condition ( C2 ). (i) L et r > 4 d . Ther e exists a c onstant D = D ( r ) ≥ 0 such that for al l τ 1 , τ 2 ∈ [0 , 1 ] d , sup n ≥ 1 E | N ( τ 1 ) n − N ( τ 2 ) n | r ≤ D | τ 1 − τ 2 | . (C2.a) (ii) L et ω > (4 d − 1) r / ( r − 4 d ) . Ther e exists a c onstant C ≥ 0 such that for every choic e of τ 1 , . . . , τ m ∈ [0 , 1 ] d , m ≥ 1 and n ≥ l ≥ 1 , α n,l ( τ 1 , . . . , τ m ) ≤ α l := C l − ω . (C2.b) (iii) ( r n ) n ≥ 1 is a se quenc e such that r n → ∞ and r n = o ( n ) and ther e exists a se quenc e ( l n ) n ≥ 1 satisfying l n = o ( r 2 /r n ) and lim n →∞ nr − 1 n α l n = 0 . (C2.c) Let us describ e so me in tuitions reg a rding this condition. First, (C2) (i) restricts the size of c lusters by ass uming that N ( τ 1 ) n − N ( τ 2 ) n has a suitably b ounded r th mo men t. It provides an inequa lity which will very useful to prove tightn ess criteria for int er media te empirical pr ocesses in tro duced in Section 5. No te that | N ( τ 1 ) n − N ( τ 2 ) n | ≤ d X i =1 ( N ( τ ( i ) 1 ∧ τ ( i ) 2 ) n − N ( τ ( i ) 1 ∨ τ ( i ) 2 ) n ) . It follows that it is sufficient to show that for ea c h i = 1 , . . . , d , there exists a constant D i ≥ 0 such that for all τ 1 , τ 2 ∈ [0 , 1] d , sup n ≥ 1 E ( N ( τ ( i ) 1 ∧ τ ( i ) 2 ) n − N ( τ ( i ) 1 ∨ τ ( i ) 2 ) n ) r ≤ D i | τ i, 1 − τ i, 2 | . (4.2) It is easily s een that (C2) (ii) is satisfied by stro ngly mixing s ta tionary s equences where the mixing co efficien ts v a nish with at leas t a sufficient hyper bolic rate. The underlying idea of the blo c k declustering scheme is to split the blo c k I j int o a small blo c k of length l n and a lar ge blo ck o f length r n − l n . (C2) (ii) and (C2) (iii) essentially means that l n is The multivariate extr emal index function 1039 sufficiently large such that blo c ks tha t ar e not adjac en t a re asymptotically indep enden t, but do es not grow to o fast so tha t the contributions of the small blo c ks is negligible. Let us give now s ome c lue s explaining why this co nditio n holds for the examples introduced in Sectio n 2 . Example 2.1 (c ontinue d). (( X l, 1 , X l, 2 )) l ≥ 1 is a n i.i.d. sequence. The r efore, α n,l ( τ 1 , . . . , τ m ) = 0 for every choice of τ 1 , . . . , τ m ∈ [0 , 1] d , m ≥ 1, n ≥ 1 , l ≥ 1 . Mor eo ver, N ( τ ( i ) 1 ∧ τ ( i ) 2 ) n − N ( τ ( i ) 1 ∨ τ ( i ) 2 ) n has a binomial dis tr ibution with pa r ameters n and | τ i, 1 − τ i, 2 | /n . Condition ( 4.2 ) is easily verified for any integer r . Example 2.2 (c ontinu e d). The compo nen ts of (( X l, 1 , X l, 2 )) l ≥ 1 are indep enden t and each comp onen t is geometr ically strong-mixing (see Example 3.1 in [ 37 ]). Moreover, bo unds for the momen t condition ( 4.2 ) can b e obtained for any integer r by using the same ar gumen ts as fo r Le mma 6.1 in [ 37 ]. Example 2.3 (c ontinu e d). (( X l, 1 , X l, 2 )) l ≥ 1 is a biv ariate po sitiv e Ha rris recurrent Marko v chain. Moreover, it is a particular ca se of a fir st-order sto chastic equatio ns with random co efficien ts. F ollowing [ 26 ], one can sho w that (( X l, 1 , X l, 2 )) l ≥ 1 is geometr ic ally absolute regular and strong-mixing . Moreover, bo unds for the mo men t condition ( 4.2 ) can b e obtained for a n y in teger r b y using the Markov prop erty of the comp onen ts and similar a rgumen ts as for Lemma 6.1 in [ 3 7 ]. Finally , we assume that the c o n vergence rate of r n to infinity is such tha t the bias of our estimators is asymptotically negligible with resp ect to their v ariance. Mo reov er, we need a condition on the reg ularit y of H and ˜ H to guarantee that the asymptotic distribution is Gauss ia n. Condition ( C3 ). (i) The se quenc e ( r n ) n ≥ 1 satisfies lim n →∞ p k n sup τ ∈ [ 0 , 1] d | P ( N ( τ ) r n , 1 = 0) − H ( τ ) | = 0 and lim n →∞ p k n sup τ ∈ [0 , 1] d | r n (1 − F ( u r n ( τ ))) + ln ˜ H ( τ ) | = 0 . (ii) The functions H and ˜ H ar e (F r´ echet) differ entiable on (0 , 1) d and t hei r deriva - tives c an b e ex tende d by c ontinuity to [0 , 1] d . Example 2.1 (c ontinue d). Note that as n → ∞ , p k n sup τ ∈ [0 , 1] d | P ( N ( τ ) r n , 1 = 0) − H ( τ ) | ∼ e − 1 2 √ k n r n ∼ e − 1 2 n 1 / 2 r 3 / 2 n , 1040 C.Y. R ob ert p k n sup τ ∈ [ 0 , 1] d | r n (1 − F ( u r n ( τ ))) + ln ˜ H ( τ ) | = √ k n r n ∼ n 1 / 2 r 3 / 2 n . It follows that if r n = o ( n 1 / 3 ), then Co ndition (C3) do es not hold. W e end this section by giv ing the dis tr ibutional asy mptotics of the es timators. Let Θ( · ) b e a pathwise contin uous Gaussia n pro cess on [0 , 1] d \{ 0 } with cov a riance function given in Appendix B . Let Ψ L ≡ { τ : τ /L ( τ ) ∈ [0 , 1 ] d \{ 0 }} a nd Ψ κ ≡ { τ : κ τ / ( − ln ˜ H ( τ )) ∈ [0 , 1 ] d \{ 0 }} . Theorem 4.1. Supp ose t ha t ( C1 ) , ( C2 ) and ( C3 ) hold. If we let m ≥ 1 and τ 1 , . . . , τ m ∈ Ψ L , then p k n ( ˆ θ (1) n ( τ i ) − θ ( τ i )) i =1 ,...,m D → (Θ( τ i L − 1 ( τ i ))) i =1 ,...,m . If we let m ≥ 1 and τ 1 , . . . , τ m ∈ Ψ κ , then p k n ( ˆ θ (2) n ( τ i ) − θ ( τ i )) i =1 ,...,m D → (Θ( τ i κ ( − ln ˜ H ( τ i )) − 1 )) i =1 ,...,m . Although the estimators ar e very different from the p oint o f view of their cons tr uction, they shar e the same a symptotic distr ibution up to a prop ortional factor. Example 2.1 (c ontinue d). The ca lculation of the as ymptotic v a riance of ˆ θ (1) n ( τ ) and ˆ θ (2) n ( τ ) can b e car ried out explicitly . Let M ( τ ) = − ln ˜ H ( τ ) L − 1 ( τ ). W e have V ar(Θ( τ L − 1 ( τ ))) = M ( τ ) − 2 (e M ( τ ) − 1 − M ( τ )) , V ar (Θ( τ κ ( − ln ˜ H ( τ )) − 1 )) = ( κ − 2 (e κ − 1 − κ )) . It is worth ment ioning tha t the asymptotic v ariance of ˆ θ (2) n ( τ ) do es not dep end on τ . It is smaller than the asymptotic v aria nce o f ˆ θ (1) n ( τ ) if κ ≤ M ( τ ). Note that if τ = τ ( i ) , L = 1 and κ = τ i , then we obtain the s a me a symptotic v aria nc e as for ˆ θ ( τ i ) 1 ,n (see Remark 3.1 ). Example 2.2 (c ontinue d). Let us characterize the asymptotic v ariance o f the second estimator. W e hav e V ar( Θ( τ κ ( − ln ˜ H ( τ )) − 1 )) = κ − 2 exp κ θ 1 τ 1 + θ 2 τ 2 τ 1 + τ 2 − 2 κ θ 1 τ 1 + θ 2 τ 2 τ 1 + τ 2 − 1 + κ − 1 θ 3 1 τ 1 P ∞ j =1 j 2 π 1 ( j ) + θ 3 2 τ 2 P ∞ j =1 j 2 π 2 ( j ) τ 1 + τ 2 The multivariate extr emal index function 1041 + κ − 1 θ 1 θ 2 θ 1 τ 1 + θ 2 τ 2 τ 1 + τ 2 X i ≥ 0 ,j ≥ 0 ,k ≥ 0 i + j + k ≥ 1 ( i + k )( j + l )( π ( τ (1) , τ (2) ) + π ( τ (2) , τ (1) ) )( i, j, k ) . F o r the fir st estimato r, r eplace κ by M ( τ ). A c omparison between the tw o as ymptotic v ar iances is not obvious. Note that if τ = τ ( i ) , L = 1 and κ = τ i , then we obtain the s a me a symptotic v aria nc e as for ˆ θ ( τ i ) 1 ,n (see Remark 3.1 ). It is p ossible to weaken Condition (C3) (ii) by assuming that there exists an op en set O included in (0 , 1) d where the functions H and ˜ H are (F r´ echet) differentiable. O ne then has to replace Ψ L by { τ : τ /L ( τ ) ∈ O ∩ [0 , 1] d \{ 0 }} and Ψ κ by { τ : κ τ / ( − ln ˜ H ( τ )) ∈ O ∩ [0 , 1 ] d \{ 0 }} in Theorem 4.1 . 5. Sim ulation study In this section, a simulation study is conducted to inv estigate the per formance of the estimators on samples of mo derate size. Data ar e simulated from: • the biv ar ia te indep enden t pro cess with independent comp onen ts of Exa mple 2.1 – we hav e θ ( τ ) = 1 ; • the biv aria te squared AR CH(1) pro c ess with indep endent co mp onents of E xample 2.2 – we cho ose η = 2 × 1 0 − 5 , λ 1 = 0 . 7 , λ 2 = 0 . 3 so then we hav e (see [ 17 ]) θ ( τ ) = 0 . 579 τ 1 + 0 . 8 8 7 τ 2 τ 1 + τ 2 ; • the biv ariate auto r egressive pro cess of order 1 with dep enden t innov a tions of Ex am- ple 2.3 . W e choos e ρ 1 = ρ 2 = 1 / 2 and B ( x 1 , x 2 ) = ( x − 2 1 + x − 2 2 ) 1 / 2 so then we hav e θ ( τ ) = 1 / 2 . W e study the p e rformances of the fir st estimator ˆ θ (1) n asso ciated with the functions L c,a ( τ ) = c ( P 2 i =1 | τ i | a ) 1 /a for c = 2 and a = 1 , c = 1 and a = 1, c = 2 a nd a = 2, c = 1 a nd a = 2 , and we undertake compa r isons with the second estimator ˆ θ (2) n asso ciated with κ = 1. F or each pr o cess, we gener ate 50 0 sequences o f length n = 2000 and for each seq ue nc e , we compute the estimates for τ = (cos φ, sin φ ) with φ = k π / 22 and k = 1 , . . . , 10. Figures 1 , 2 a nd 3 show the means (left) a nd the ro ot mean squar ed erro rs (RMSE ) (right) o f the es timates as functions of the angle, φ , for k n = 50 , 1 00 , 150 , 20 0 and for the three pro cesses. Fir st, o bserv e that the bia s of the e s timators decreases a s the size o f the blo c ks increas e s. The estimato rs ar e nearly unbiased for k n = 50 and k n = 100 , but they show a positive bias when k n = 2 00, except in the ca s e of the biv ariate squa red ARCH pro cess and for the larg e v a lues of φ . Co n versely , the v ariances of the es tima to rs increa s e as the size of the blo c ks incr eases. This is the ordinary v aria nce-bias trade - off encount ere d 1042 C.Y. R ob ert Figure 1. The i.i.d. sequence. Left: means of the estimates of th e multiv ariate extremal index function; the gra y solid line represents the true function. Right: RMSE of the estimates of th e multiv ariate extremal ind ex function. The estima- tors w hich a re considered are ˆ θ (1) n associated with L 2 , 1 (– – –), L 1 , 1 ( · · · · ), L 2 , 2 (- – - –), L 1 , 2 (- - -) and ˆ θ (2) n associated with κ = 1 (——) . The graphs sho w the aver - age ov er 500 samples. with the blo c ks e stimators. Note that the minimum of the RMSE is ge ne r ally obse rv ed for lar ge v alues o f k n (150 o r 2 00). The multivariate extr emal index function 1043 Figure 2. The b iv ariate squared ARCH(1) p rocess. Left: means of the esti- mates of the multiv ariate extremal index function; the gra y solid line repre- sents the true function; Righ t: R MSE of the estimates of the multiv ariate ex- tremal index function; the estimators whic h are considered are ˆ θ (1) n associated with L 2 , 1 (– – –), L 1 , 1 ( · · · · ), L 2 , 2 (- – - –), L 1 , 2 (- - -) and ˆ θ (2) n associated with κ = 1 (——). The graphs show the av erage ov er 500 samples. F o r the i.i.d. sequence, the first estimator asso ciated with the function L 2 , 1 per forms uniformly better. The reasons for this ma y b e tha t the a symptotic v ariance is smaller 1044 C.Y. R ob ert Figure 3. The biv ariate autoregressiv e pro cess. Left: means of th e estimates of the multiv ariate extremal index function; the gray solid line represents th e true function. Right: RMSE of th e estimates of t h e multiv ariate extremal index function. The estimators which are considered are ˆ θ (1) n associated with L 2 , 1 (– – –), L 1 , 1 ( · · · · ), L 2 , 2 (- – - –), L 1 , 2 (- - -) and ˆ θ (2) n associated with κ = 1 (—— ). The graphs show the av erage ov er 500 samples. and that the estima ted thresholds are higher than those with the choice c = 1 a nd hence the bias is s maller. The RMSE is mimimal for k n = 200 . The multivariate extr emal index function 1045 Figure 4. The i.i.d. sequence. Ratios b et wee n the sample v ariances and th e asymptotic va ri- ances for the estimators of the multiv ariate extremal index fun ction are shown. The estimators whic h are considered are ˆ θ (1) n associated with L 2 , 1 (– – –), L 1 , 1 ( · · · · ), L 2 , 2 (- – - –), L 1 , 2 (- - -) and ˆ θ (2) n associated with κ = 1 (——). The graphs show the a verage ov er 1000 samples. F o r the biv ariate s quared ARCH( 1) pro cess, ˆ θ (1) n asso ciated with the function L 1 , 1 and ˆ θ (2) n per form better tha n the other estimator s. Note that, as for the pr evious pro cess, − ln ˜ H and L 1 , 1 are equa l, which explains why b oth estimator s hav e the s a me as ymptotic v ar iance. The RMSE is mimimal for k n = 150 , exc e pt for the large v alues o f φ . F o r the autor egressive pro cess, ther e is a r e lativ ely sma ll sensiv it y of the estimates to the choice o f the es timator when k n = 200 . The se c ond estimator a lw ays p erforms b etter. Overall, ˆ θ (2) n app ears a s a go o d candidate to estimate the m ultiv ariate extrema l index function. Its perfor mance o n samples of mo derate size is often b etter than the perfor - mance of ˆ θ (1) n and, moreov er, it do es no t necessitate the choice of a tuning function. Figure 4 shows, fo r the fir s t pro cess, the ra tios betw een the sa mple v a riances and the asymptotic v ariances for the estimators of the multiv ariate e x tremal index function. It illustrates that for s equences of length at least n = 2 000, the v ariances o f the estimator s can b e well appr o ximated by the asymptotic v ariances when they can b e calculated o r estimated. 6. In termediate results and pr o of of Theorem 4.1 The pr oof o f Theorem 4.1 and some results related to the weak conv ergence o f interme- diate empirical pro cesses ar e ga thered in this section. W e let K b e a g eneric c o nstan t whose v alue may change fr om app earance to a ppeara nc e . 1046 C.Y. R ob ert W e first introduce the Skorokho d spac e of la dcag multiparameter functions a nd g iv e the essential ingredients that will b e require d for characterizing the a symptotic behavior of the intermediate pr ocesse s . Let B d be a cub e in R d . If τ ∈ B d and if, for i = 1 , . . . , d , R i is one of the r elations ≤ and > , then let Q R 1 ,...,R d ( τ ) b e the quadra n t { σ = ( σ 1 , . . . , σ d ) ∈ B d : σ i R i τ i , i = 1 , . . . , d } . W e denote by D ( B d ) the spa ce o f functions from B d to R which a re “contin uous from below, with limits from above” in the sense defined b y [ 1 ]. More precisely , f ∈ D ( B d ) if, for each τ ∈ B d , f Q ( τ ) = lim σ → τ , σ ∈ Q f ( σ ) exists for each of the 2 d quadrants Q = Q R 1 ,...,R d ( τ ) and f ( τ ) = f Q ≤ ,..., ≤ . Let us a ssume tha t it is equipp ed with the metric d o which is e q uiv alent to the Skoroho d metric d and such that it makes D ( B d ) a co mplete separable metric space (see [ 1 ], Section 2 and [ 3 ], Section 12). A sequence ( f n ) n ≥ 1 of D ( B d )-v alued pr ocesses conv erges weakly in the Sk or ohod to p ol- ogy to a D ( B d )-v alued pro cess f ( f n ( · ) ⇒ f ( · )) if E ϕ ( f n ) → E ϕ ( f n ) for all Skoroho d- contin uous bounded functions ϕ : D ( B d ) → R . A criter io n for the weak con vergence of D ( B d )-v alued pro cesses can be g iv en in terms of the weak conv ergence of the corr espond- ing finite-dimensional distributions together with a tig h tness condition (se e Theor em 1 in [ 1 ] and the pr oof o f Theorem 6 .1 ). It is often conv enient to c o nsider the restric tions of the functions of D ( B d ) to a subset of B d . If C d is a cube included in B d and if f ∈ D ( B d ), we denote by r C d f the res triction of f to C d . W e have the following co n vergence pro perty: if f n ( · ) ⇒ f ( · ) in D ( B d ) and f is contin uous at the low er bo undary of C d , then r C d f n ( · ) ⇒ r C d f ( · ) in D ( C d ) (see, e.g., Lemma 4.1 7 in [ 35 ] for the univ a riate case). W e now turn to the definition of the intermediate pro cesses and characterize their asymptotic distr ibution. First, let us introduce, for τ ∈ [0 , 1 ] d , V n ( τ ) = p k n ( H n ( τ ) − P ( N ( τ ) r n , 1 = 0)) , W n ( τ ) = p k n (( − ln ˜ H n ( τ )) − r n P ( X l u r n ( τ ))) , where H n ( τ ) = 1 k n k n X j =1 1 { N ( τ ) r n ,j =0 } and − ln ˜ H n ( τ ) = 1 k n k n X j =1 N ( τ ) r n ,j . W e define the first intermediate D ([0 , 1] d ) × D ([0 , 1] d )-v alued pro cess b y U n ( τ ) = ( V n ( τ ) , W n ( τ )) ′ . O bserv e that U n depe nds on the unknown vector of thresholds u r n ( τ ) and cannot be used in pr actice. In the univ ariate case, W n is called the tail empiric al pr o c ess and has b een studied for dep enden t sequences in [ 7 , 8 ] and [ 38 ]. Theorem 6.1 . Supp ose that ( C1 ) and ( C2 ) hold. Ther e exists a p athwise c ontinuous c enter e d Gaussian pr o c ess U with c ovaria nc e matrix C ( · , · ) = ( C i,j ( · , · )) 1 ≤ i,j ≤ 2 given in App endix B su ch that U n ( · ) ⇒ U ( · ) ≡ ( V ( · ) , W ( · )) ′ in D ([0 , 1] d ) × D ([0 , 1] d ) . The multivariate extr emal index function 1047 The pro of o f Theo rem 6.1 is presented a s a series of tw o lemmas. Let us define the large blo cks I △ j and the sma ll blo c ks I ∗ j by , for j = 1 , . . . , k n , I △ j = [( j − 1) r n + 1 , . . . , j r n − l n ] , I ∗ j = [ j r n − l n + 1 , . . . , j r n ] . W e introduce the quantities N ( τ ) , △ r n ,j = X l ∈ I △ j 1 { X l u r n ( τ ) } , N ( τ ) , ∗ r n ,j = X l ∈ I ∗ j 1 { X l u r n ( τ ) } , j = 1 , . . . , k n , H △ n ( τ ) = 1 k n k n X j =1 1 { N ( τ ) , △ r n ,j =0 } , H ∗ n ( τ ) = − 1 k n k n X j =1 1 { N ( τ ) , △ r n ,j =0 ,N ( τ ) , ∗ r n ,j > 0 } , − ln ˜ H △ n ( τ ) = 1 k n k n X j =1 N ( τ ) , △ r n ,j , − ln ˜ H ∗ n ( τ ) = 1 k n k n X j =1 N ( τ ) , ∗ r n ,j , and consider the following pro cesses V ∆ n ( τ ) = p k n ( H △ n ( τ ) − P ( N ( τ ) , △ r n , 1 = 0)); V ∗ n ( τ ) = p k n ( H ∗ n ( τ ) + P ( N ( τ ) , △ r n ,j = 0 , N ( τ ) , ∗ r n ,j > 0)); W ∆ n ( τ ) = p k n (( − ln ˜ H △ n ( τ )) − ( r n − l n ) P ( X l u r n ( τ ))); W ∗ n ( τ ) = p k n (( − ln ˜ H ∗ n ( τ )) − l n P ( X l u r n ( τ ))); U ∆ n ( τ ) = ( V ∆ n ( τ ) , W ∆ n ( τ )) ′ , U ∗ n ( τ ) = ( V ∗ n ( τ ) , W ∗ n ( τ )) ′ . Note that H n ( τ ) = H △ n ( τ ) + H ∗ n ( τ ), − ln ˜ H n ( τ ) = − ln ˜ H △ n ( τ ) − ln ˜ H ∗ n ( τ ), V n ( τ ) = V ∆ n ( τ ) + V ∗ n ( τ ), W n ( τ ) = W ∆ n ( τ ) + W ∗ n ( τ ) and U n ( τ ) = U ∆ n ( τ ) + U ∗ n ( τ ). Lemma 6.1. Supp ose that ( C1 ) and ( C2 ) hold. L et m ≥ 1 and τ 1 , . . . , τ m ∈ [0 , 1 ] d . Then, ( U n ( τ i )) i =1 ,...,m D → ( U ( τ i )) i =1 ,...,m . Pro of. By similar arguments as in Lemma 6.6 of [ 37 ] with 4 d ∨ 2 ω ω − 1 < v < r (this ca n always b e assumed), we hav e U ∗ n ( τ ) P → 0. It is o nly needed to b e chec ked that ( U ∆ n ( τ i )) i =1 ,...,m D → ( U ( τ i )) i =1 ,...,m . 1048 C.Y. R ob ert But w e can use the arguments of Lemma 6.7 in [ 37 ] and replace (C0)(b) in [ 37 ] by (C2) (a) with τ 2 = 0 in order to esta blis h the weak co nvergence and to conclude that ( U ( τ i )) i =1 ,...,m is a Gaussian centered r a ndom vector with cov arianc e matrix Cov( U ( τ l ) , U ( τ k )) = E ( U ( τ l ) U ′ ( τ k )) = C ( τ l , τ k ) , 1 ≤ l , k ≤ m. Lemma 6.2. Supp ose t ha t ( C1 ) and ( C2 ) hold. L et u s define the mo dulus of c ontinuity of f ∈ D ([0 , 1] d ) by w f ( δ ) = sup {| f ( τ ) − f ( τ ′ ) | : τ , τ ′ ∈ [0 , 1] d , | τ − τ ′ | < δ } . L et ε > 0 . Then, lim δ → 0 lim sup n P ( w V n ( δ ) > ε ) = 0 , (6.1) lim δ → 0 lim sup n P ( w W n ( δ ) > ε ) = 0 . (6.2) Pro of. W e com bine some ar gumen ts from Section 5 of [ 29 ] and some arguments fro m the pro of of Theore m 1 in [ 5 ]. Let L (2 m n ) b e the set of all p oint s ( l 1 , . . . , l d ) / 2 m n with l i ∈ { 0 , 1 , . . . , 2 m n } , i = 1 , . . . , d . Since H n ( τ ) is a mono tonically non-incr easing function in eac h comp onen t of τ and − ln ˜ H n ( τ ) is a monoto nically non-dec r easing function in each comp onen t of τ , we hav e (see [ 31 ], pa g e 2 62) w V n ( δ ) ≤ 6 sup | V n ( τ 1 ) − V n ( τ 2 ) | + 4 d p k n 2 − m n , w W n ( δ ) ≤ 6 sup | W n ( τ 1 ) − W n ( τ 2 ) | + 4 d p k n 2 − m n , where the “ sup” is to b e taken over all τ 1 , τ 2 ∈ L (2 m n ) with | τ 1 − τ 2 | ≤ δ + 2 − m n +1 . If m n is chosen such tha t lim n →∞ √ k n 2 − m n = 0 , ( 6.1 ) and ( 6.2 ) will follow if we ca n show that lim δ → 0 lim sup n P (sup | V n ( τ 1 ) − V n ( τ 2 ) | > ε ) = 0 , lim δ → 0 lim sup n P (sup | W n ( τ 1 ) − W n ( τ 2 ) | > ε ) = 0 , where the “ sup” is to b e ta ken over all τ 1 , τ 2 ∈ L (2 m n ) with | τ 1 − τ 2 | ≤ δ . Let us define Y V ,j ( τ 1 , τ 2 ) = (1 { N ( τ 1 ) r n ,j =0 } − P ( N ( τ 1 ) r n , 1 = 0)) − (1 { N ( τ 2 ) r n ,j =0 } − P ( N ( τ 2 ) r n , 1 = 0)) , Y W ,j ( τ 1 , τ 2 ) = ( N ( τ 1 ) r n ,j − r n P ( X l u r n ( τ 1 ))) − ( N ( τ 2 ) r n ,j − r n P ( X l u r n ( τ 2 ))) , The multivariate extr emal index function 1049 S V ,n ( τ 1 , τ 2 ) = k n X j =1 Y V ,j ( τ 1 , τ 2 ) , S W ,n ( τ 1 , τ 2 ) = k n X j =1 Y W ,j ( τ 1 , τ 2 ) . W e now w ant to use e quation (4 . 3) of Theorem 4.1 in [ 39 ]. Note that α r n l ≤ α l for l ≥ 1 and r n ≥ 1 . Let 2 < v < p < r ≤ ∞ , κ > 0 , a nd assume that ω > v / ( v − 2) and ω ≥ ( p − 1) r / ( r − p ). W e choose p = 4 d and r = 2 dv with 2 < v < 4 , which lea ds to ω ≥ (4 d − 1) r/ ( r − 4 d ). W e deduce tha t E | S V ,n ( τ 1 , τ 2 ) | 4 d ≤ k 2 d n k Y V ,j ( τ 1 , τ 2 ) k 4 d v + k 1+ κ n k Y V ,j ( τ 1 , τ 2 ) k 4 d 2 dv , E | S W ,n ( τ 1 , τ 2 ) | 4 d ≤ k 2 d n k Y W ,j ( τ 1 , τ 2 ) k 4 d v + k 1+ κ n k Y W ,j ( τ 1 , τ 2 ) k 4 d 2 dv . Note that, for λ ≥ 1, | Y V ,j ( τ 1 , τ 2 ) | λ ≤ 2 λ ( | 1 { N ( τ 1 ) r n ,j =0 } − 1 { N ( τ 2 ) r n ,j =0 } | λ + | P ( N ( τ 1 ) r n ,j = 0) − P ( N ( τ 2 ) r n ,j = 0) | λ ) , | Y W ,j ( τ 1 , τ 2 ) | λ ≤ 2 λ ( | N ( τ 1 ) r n , 1 − N ( τ 2 ) r n , 1 | λ + | E N ( τ 1 ) r n , 1 − E N ( τ 2 ) r n , 1 | λ ) . Since | 1 { N ( τ 1 ) r n ,j =0 } − 1 { N ( τ 2 ) r n ,j =0 } | ≤ | N ( τ 1 ) r n ,j − N ( τ 2 ) r n ,j | , we deduce by (C2) (a) tha t for 1 ≤ λ ≤ r , E | 1 { N ( τ 1 ) r n ,j =0 } − 1 { N ( τ 2 ) r n ,j =0 } | λ ≤ E | N ( τ 1 ) r n ,j − N ( τ 2 ) r n ,j | λ ≤ D | τ 1 − τ 2 | . Moreov er, | P ( N ( τ 1 ) r n ,j = 0) − P ( N ( τ 2 ) r n ,j = 0) | ≤ E | 1 { N ( τ 1 ) r n ,j =0 } − 1 { N ( τ 2 ) r n ,j =0 } | ≤ E | N ( τ 1 ) r n , 1 − N ( τ 2 ) r n , 1 | and | E N ( τ 1 ) r n , 1 − E N ( τ 2 ) r n , 1 | ≤ E | N ( τ 1 ) r n , 1 − N ( τ 2 ) r n , 1 | ≤ E | N ( τ 1 ) r n , 1 − N ( τ 2 ) r n , 1 | r . It follows that for λ ≥ 1 a nd | τ 1 − τ 2 | < 1 , ( | E N ( τ 1 ) r n , 1 − E N ( τ 2 ) r n , 1 | ) λ ≤ ( E | N ( τ 1 ) r n , 1 − N ( τ 2 ) r n , 1 | r ) λ ≤ ( D | τ 1 − τ 2 | ) λ ≤ K | τ 1 − τ 2 | . W e deduce that for | τ 1 − τ 2 | < 1, k Y V ,j ( τ 1 , τ 2 ) k 4 d v ≤ K | τ 1 − τ 2 | 4 d/v , k Y V ,j ( τ 1 , τ 2 ) k 4 d 2 dv ≤ K | τ 1 − τ 2 | 2 /v , k Y W ,j ( τ 1 , τ 2 ) k 4 d v ≤ K | τ 1 − τ 2 | 4 d/v , k Y W ,j ( τ 1 , τ 2 ) k 4 d 2 dv ≤ K | τ 1 − τ 2 | 2 /v 1050 C.Y. R ob ert and it follows that fo r any κ > 0, E | S V ,n ( τ 1 , τ 2 ) | 4 d ≤ K ( k 2 d n | τ 1 − τ 2 | 4 d/v + k 1+ κ n | τ 1 − τ 2 | 2 /v ) , E | S W ,n ( τ 1 , τ 2 ) | 4 d ≤ K ( k 2 d n | τ 1 − τ 2 | 4 d/v + k 1+ κ n | τ 1 − τ 2 | 2 /v ) . Since right-hand sides of the previous t wo inequalities are the same, we o nly consider the case of the pro cess W n . W e then deduce that E | W n ( τ 1 ) − W n ( τ 2 ) | 4 d ≤ K ( | τ 1 − τ 2 | 4 d/v + k 1+ κ − 2 d n | τ 1 − τ 2 | 2 /v ) . If k 1+ κ − 2 d n ≤ | τ 1 − τ 2 | 4 d/v − 2 /v or, eq uiv alently , | τ 1 − τ 2 | ≥ k v (1+ κ − 2 d ) / (2( d − 1)) n , then E | W n ( τ 1 ) − W n ( τ 2 ) | 4 d ≤ K | τ 1 − τ 2 | 4 d/v . In pa r ticular, if τ 2 = τ 1 + e i 2 − γ , where e i = 1 ( i ) such that 2 − γ ≥ k v (1+ κ − 2 d ) / (2( d − 1) n , we get E | W n ( τ 1 ) − W n ( τ 2 ) | 4 d ≤ K (2 − r ) 4 d/v . Let m ( δ ) = max { γ ∈ N : δ 2 γ ≤ 1 } and 0 < a < 1. By using the sa me ar gumen ts as in Section 5 of [ 29 ], we hav e P (sup {| W n ( τ 1 ) − W n ( τ 2 ) | : τ 1 , τ 2 ∈ L (2 m n ) , | τ 1 − τ 2 | ≤ δ } > ε ) ≤ d X i =1 m n X γ = m ( δ ) 2 γ X j 1 =1 · · · 2 γ − 1 X j i =0 · · · 2 γ X j d =1 P ( | W n ( j ) − W n ( j + e i 2 − γ ) | > (1 − a ) a γ − m ( δ ) ε (4 d 2 ) − 1 ) where j = ( j 1 , . . . , j d ) ∈ L (2 γ ). If 2 − γ ≥ 2 − m n ≥ k v (1+ κ − 2 d ) / (2(2 d − 1)) n , then we get, b y Chebyshev’s inequality , P ( | W n ( j ) − W n ( j + e i 2 − γ ) | > (1 − a ) a γ − m ( δ ) ε (4 d 2 ) − 1 ) ≤ E | W n ( τ 1 ) − W n ( τ 2 ) | 4 d ((1 − a ) a γ − m ( δ ) ε (4 d 2 ) − 1 ) 4 d ≤ K (2 − γ ) 4 d/v ((1 − a ) a γ − m ( δ ) ε (4 d 2 ) − 1 ) 4 d . It follows that P (sup {| W n ( τ 1 ) − W n ( τ 2 ) | : τ 1 , τ 2 ∈ L ( i ) (2 m n ) , | τ 1 − τ 2 | ≤ δ } > ε ) ≤ dK ((1 − a ) ε (4 d 2 ) − 1 )4 d m n X γ = m ( δ ) (2 − γ ) d (4 /v − 1) 1 a γ − m ( δ ) = dK ((1 − a ) ε (4 d 2 ) − 1 )4 d (2 d (4 /v − 1) ) m ( δ ) m n X γ = m ( δ ) 1 (2 d (4 /v − 1) a ) γ − m ( δ ) . The multivariate extr emal index function 1051 Let us cho ose a such that 2 d (4 /v − 1) a > 1 , which is p ossible since v < 4 , and let us choo se m n such that lim n →∞ p k n 2 − m n = 0 a nd lim n →∞ k v (1+ κ − 2 d ) / (2(2 d − 1)) n 2 m n = 0 , that is, such that k − v (1 / 2 − κ/ (2(2 d − 1))) n = o (2 − m n ) and 2 − m n = o ( k − 1 / 2 n ) . This is cle arly p o ssible s inc e v > 2 and κ is ar bitrarily small. Now let m n tend to infinity . The infinite series co n verges s inc e 2 d (4 /v − 1) a > 1 . Finally , let δ tend to 0 o r, equiv alently , m ( δ ) tend to infinity . The upp er b ound tends to zero since 2 d (4 /v − 1) > 1 and the result follows. Pro of of Theorem 6.1 . Lets define the diameter of a recta ngle as the le ng th of its shortest s ide . Call a partitio n of [0 , 1] d formed by finitely man y hyperplanes par allel to the co ordinate axes a δ -grid if ea ch element of the partition is a “right-closed, left-op en” rectangle of diameter at lea st δ a nd define w ′ ( · ) ( δ ) : D ([0 , 1 ] d ) → R by w ′ f ( δ ) = inf ∆ max G ∈ ∆ sup σ , τ ∈ G | f ( τ ) − f ( σ ) | , where the infinim um ex tends over all δ - grids ∆ on [0 , 1] d . Le t us define Π S : D ([0 , 1] d ) → R S by Π S ( f ) = ( f ( s )) s ∈ S for each finite set S ⊂ [0 , 1] d . Let T b e the collection o f subsets of [0 , 1] d of the for m U 1 × · · · × U d where each U j contains 0 and 1 and has coun table complement. Accor ding to The o rem 2 in [ 1 ], V n ⇒ V (resp., W n ⇒ W ) if a nd only if (i) Π S ( V n ) ⇒ Π S ( V ) for all finite subsets S o f some member o f T (resp., Π S ( W n ) ⇒ Π S ( W )); (ii) lim δ → 0 lim sup n P ( w ′ V n ( δ ) > ε ) = 0 for all ε > 0 (resp., lim δ → 0 lim sup n P ( w ′ V n ( δ ) > ε ) = 0 ). By Lemma 6.1 , we der iv e the first co nditio n. Now, a ccording to equa tio n (1 . 7) in [ 29 ], we hav e w ′ V n ( δ ) ≤ w V n (2 δ ) and w ′ W n ( δ ) ≤ w W n (2 δ ) , 0 < δ < 1 / 2 . By Lemma 6.2 , we der iv e the second co ndition. Mor eo ver, b y using the s ame arg umen ts as in the pro of of Theor em 15 .5 in [ 2 ], we can show that V and W b elong to C ([0 , 1] d ), the subse t of D ([0 , 1] d ) consisting of contin uous functions. W e now substitute the unknown vector o f thresholds in the first intermediate pro cess by its estimate, ˆ u r n ( τ ), and replace P ( N ( τ ) r n , 1 = 0 ) and P ( X l u r n ( τ )) by their resp ectiv e limits. Let us int ro duce ˆ V n ( τ ) = p k n ( ˆ H n ( τ ) − H ( τ )) , ˆ W n ( τ ) = p k n (( − ln c ˜ H n ( τ )) − ( − ln ˜ H ( τ ))) 1052 C.Y. R ob ert and define the second intermediate D ([0 , 1 ] d ) × D ([0 , 1] d )-v alued pr ocess b y ˆ U n ( τ ) = ( ˆ V n ( τ ) , ˆ W n ( τ )) ′ . W e now es tablish the weak conv erg ence of this pro cess. Prop osition 6.1. Su pp ose that ( C1 ) , ( C2 ) and ( C3 ) hold. Then, ˆ U n ( · ) ⇒ ˆ U ( · ) ≡ ( ˆ V ( · ) , ˆ W ( · )) ′ in D ([0 , 1] d ) × D ([0 , 1] d ) , wher e ˆ U ( τ ) = U ( τ ) + −∇ H ( τ ) ′ Z ( τ ) ˜ H − 1 ( τ ) ∇ ˜ H ( τ ) ′ Z ( τ ) , ∇ H ( τ ) = ( ∂ H ( τ ) /∂ τ i ) i =1 ,...,d , ∇ ˜ H ( τ ) = ( ∂ ˜ H ( τ ) /∂ τ i ) i =1 ,...,d and Z ( τ ) = ( W ( π i ( τ ))) i =1 ,...,d with π i ( τ ) = τ ( i ) , i = 1 , . . . , d . Note that ˆ U is well defined on [0 , 1 ] d \{ 0 } and can be extended by co n tin uity at { 0 } by setting ˆ U ( 0 ) = U ( 0 ) = (0 , 0 ) ′ . Mo reo ver, if ˜ G has independent co mponents, then ˆ W = 0 . Pro of of Prop osition 6.1 . Let us define the functions ¯ p n,i by ¯ p n,i ( τ i ) = − ln( ˜ H n ( τ ( i ) )) = − ln( ˜ H n ((0 , . . . , 0 , τ i , 0 , . . . , 0))) , i = 1 , . . . , d. The gener a lized inverse of ¯ p n,i is given for 0 < ¯ τ ≤ r n by ¯ p ← n,i ( ¯ τ ) = inf ( τ ≥ 0 : r n k n X j =1 1 { X j,i >F ← i (1 − τ /r n ) } ≥ k n ¯ τ ) = r n ¯ F i ( X ( ⌈ k n ¯ τ ⌉ ) ,i ) since F ← i ( F i ( X ( ⌈ k n ¯ τ ⌉ ) ,i )) = X ( ⌈ k n ¯ τ ⌉ ) ,i . Without loss of g eneralit y , a ssume that ¯ p ← n,i (0) = 0 . Note that ¯ p ← n,i ( · ) is a cag lad function on [0 , 1 ]. Letting ˜ π i ( τ ) = τ i , we hav e ˆ H n ( τ ) = H n ( ¯ p ← n, 1 ( ˜ π 1 ( τ )) , . . . , ¯ p ← n,d ( ˜ π d ( τ ))) . Let us introduce the functions ¯ p n , ¯ p inv n and e d from [0 , 1] d to R d defined by ¯ p n ( τ ) = ( ¯ p n, 1 ( ˜ π 1 ( τ )) , . . . , ¯ p n,d ( ˜ π d ( τ ))) ′ , ¯ p inv n ( τ ) = ( ¯ p ← n, 1 ( ˜ π 1 ( τ )) , . . . , ¯ p ← n,d ( ˜ π d ( τ ))) ′ , e d ( τ ) = τ . By Theo rem 6.1 , we hav e ¯ p n ( · ) ⇒ e d ( · ) in D ([0 , 1] d ) × · · · × D ([0 , 1] d ). It is easily deduced that ¯ p inv n ( · ) ⇒ e d ( · ) in D ([0 , 1] d ) × · · · × D ([0 , 1] d ). Let us define the pr ocesses ˜ V n ( τ ) = p k n ( H n ( τ ) − H ( τ )) The multivariate extr emal index function 1053 = V n ( τ ) + p k n ( P ( N ( τ ) r n , 1 = 0) − P ( N ( τ ) = 0)) , ˜ W n ( τ ) = p k n (( − ln ˜ H n ( τ )) − ( − ln ˜ H ( τ ))) = W n ( τ ) + p k n ( r n (1 − F ( u r n ( τ ))) + ln ˜ H ( τ )) and let ˜ U n ( τ ) = ( ˜ V n ( τ ) , ˜ W n ( τ )) ′ . By (C3) (i), we hav e sup τ ∈ [0 , 1] d | p k n ( P ( N ( τ ) r n , 1 = 0) − P ( N ( τ ) = 0)) | → 0 as n → ∞ , sup τ ∈ [0 , 1] d | p k n ( r n (1 − F ( u r n ( τ ))) + ln ˜ H ( τ )) | → 0 as n → ∞ and it follows that ˜ U n ( · ) ⇒ U ( · ) in D ([0 , 1] d ) × D ([0 , 1] d ). By using the contin uous mapping theor em (CMT) and similar arguments as in the b eginning o f the pro of of Theo rem 4 .2 in [ 37 ], we deduce that ˜ U n ( ¯ p inv n ( · )) ⇒ U ( · ) in D ([0 , 1] d ) × D ([0 , 1] d ). Next, note that ˆ V n ( τ ) = ˜ V n ( ¯ p inv n ( τ )) + p k n ( H ( ¯ p inv n ( τ )) − H ( τ )) , ˆ W n ( τ ) = ˜ W n ( ¯ p inv n ( τ )) + p k n ( − ln ˜ H ( ¯ p inv n ( τ )) − ( − ln ˜ H ( τ ))) . Since ˜ W n ⇒ W in D ([0 , 1] d ), we hav e p k n ( ¯ p n ( · ) − e d ( · )) ⇒ Z ( · ) in D ([0 , 1] d ) × · · · × D ([0 , 1] d ). By using V erv aat’s lemma [ 44 ], we get p k n ( ¯ p inv n ( · ) − e d ( · )) ⇒ − Z ( · ) in D ([0 , 1] d ) × · · · × D ([0 , 1] d ). W e deduce fro m the differentiabilit y of H and ˜ H , a nd the finite incr e men ts formula, that p k n H ( ¯ p inv n ( · )) − H ( · ) − ln ˜ H ( ¯ p inv n ( · )) − ( − ln ˜ H ( · )) ⇒ −∇ H ( · ) ′ Z ( · ) ˜ H − 1 ( · ) ∇ ˜ H ( · ) ′ Z ( · ) in D ([0 , 1] d ) × D ([0 , 1] d ). Finally , we get ˆ U n ( · ) ⇒ U ( · ) + −∇ H ( · ) ′ Z ( · ) ˜ H − 1 ( · ) ∇ ˜ H ( · ) ′ Z ( · ) 1054 C.Y. R ob ert in D ([0 , 1] d ) × D ([0 , 1] d ). Let ¯ κ = 1 / sup { ( − ln ˜ H ( τ )) − 1 W d i =1 τ i : τ ∈ [0 , 1] d \{ 0 }} a nd in tro duce, for ( κ , τ ) ∈ [0 , ¯ κ ] × [0 , 1] d , V ˇ Z n ( κ , τ ) = p k n ( H ˇ Z n ( κ , τ ) − e − θ ( τ ) κ ) , W ˇ Z n ( κ , τ ) = p k n ( Q ˇ Z n ( κ , τ ) − κ ) , where H ˇ Z n ( κ , τ ) = 1 k n k n X j =1 1 { N ( κ , τ ) r n ,j =0 } and Q ˇ Z n ( κ , τ ) = 1 k n k n X j =1 N ( κ , τ ) r n ,j . W e define an additional intermediate D ([0 , ¯ κ ]) × D ([0 , ¯ κ ])-v alued pro cess by U ˇ Z n ( κ , τ ) = ( V ˇ Z n ( κ , τ ) , W ˇ Z n ( κ , τ )) ′ , κ ∈ [0 , ¯ κ ] . Observe that U ˇ Z n depe nds on the es tima ted series ( ˇ Z ( τ ) l ) l ≥ 1 and on the unknown threshold v ( τ ) n ( κ ). It is worth mentioning that U ˇ Z n and ˆ U n are clo sely related s ince U ˇ Z n ( κ , τ ) = ˆ U n ( κ ( − ln ˜ H ( τ )) − 1 τ ) . Corollary 6.1. S upp ose that ( C1 ) , ( C2 ) and ( C3 ) hold. Then for τ ∈ [0 , 1 ] d \{ 0 } , U ˇ Z n (( · ) , τ ) ⇒ ˆ U ( τ ( − ln ˜ H ( τ )) − 1 ( · )) in D ([0 , ¯ κ ]) × D ([0 , ¯ κ ]) . Pro of. W e hav e N ( κ , τ ) r n ,j = X l ∈ I j 1 { ˇ Z ( τ ) l >v ( τ ) r n ( κ ) } = X l ∈ I j 1 { max i =1 ,...,d τ i k n r n ( k n r n +1 − R l,i ) > ( − ln ˜ H ( τ )) r n / κ } = X l ∈ I j 1 { S i =1 ,...,d ( R l,i >k n r n +1 − τ i κ ( − ln ˜ H ( τ )) − 1 k n ) } = X l ∈ I j 1 { S i =1 ,...,d ( X l,i >X ( ⌈ τ i κ ( − l n ˜ H ( τ )) − 1 k n ⌉ ) ,i ) } = ˆ N ( κ ( − ln ˜ H ( τ )) − 1 τ ) r n ,j and it follows that U ˇ Z n ( κ , τ ) = ˆ U n ( τ ( − ln ˜ H ( τ )) − 1 κ ) . Fix τ ∈ [0 , 1 ] d \{ 0 } a nd consider the function κ 7→ U ˇ Z , κ n ( κ , τ ) fro m [0 , ¯ κ ] to R 2 as an element of D ([0 , ¯ κ ]) × D ([0 , ¯ κ ]). Since the map fro m D ([0 , 1] d ) to D ([0 , ¯ κ ]) taking f ( · ) to The multivariate extr emal index function 1055 f (( − ln ˜ H ( τ )) − 1 τ ( · )) is contin uous for any τ ∈ [0 , 1 ] d \{ 0 } , we deduce, b y the C MT, that U ˇ Z n (( · ) , τ ) ⇒ ˆ U ( τ ( − ln ˜ H ( τ )) − 1 ( · )) in D ([0 , ¯ κ ]) × D ([0 , ¯ κ ]). W e now derive, fr o m Pr o position 6.1 and C o rollary 6.1 , the distributional a symptotics of the estimators. Let us define, for τ ∈ [0 , 1 ] d \{ 0 } , ˜ θ n ( τ ) = − ln ˆ H n ( τ ) − ln c ˜ H n ( τ ) , Θ( τ ) = 1 ln ˜ H ( τ ) ( ˆ V ( τ ) H − 1 ( τ ) + ˆ W ( τ ) θ ( τ )) . Note that Θ( · ) has contin uous sample paths on [0 , 1 ] d \{ 0 } . By pr op er cub e we mean a cub e included in [0 , 1] d which do es no t contain { 0 } . Corollary 6.2. Su pp ose that ( C1 ) , ( C2 ) and ( C3 ) hold. L et C d b e a pr op er cub e. Then, p k n ( r C d ˜ θ n ( · ) − r C d θ ( · )) ⇒ r C d Θ( · ) in D ( C d ) . Pro of. W e first recall that a map Φ b et ween top ological vector spa ces B i , i = 1 , 2 , is called Hadamar d differ ent ia ble tangential ly to some subset S ⊂ B 1 at f ∈ B 1 if there exists a contin uous linea r ma p ∇ Φ( f ) from B 1 to B 2 such that Φ( f + t n g n ) − Φ( f ) t n → ∇ Φ( f ) · g for all s equences t n ↓ 0 and g n ∈ B 1 conv erging to g ∈ S . L e t D ( C d , E ) (resp., C ( C d , E )) be the space of functions from C d to the set E ⊂ R w hich are “c on tinuous from b e- low, with limits from a bov e” (resp., con tinuous). Let us consider the map Φ from D ( C d , (0 , 1)) × D ( C d , (0 , ∞ )) to D ( C d , (0 , ∞ )) defined by Φ( f 1 , f 2 ) = − ln f 1 f 2 . Note that this map is Hadamard differen tiable tang en tially to C ( C d , R ) × C ( C d , R ) at any ( f 1 , f 2 ) ∈ C ( C d , (0 , 1)) × C ( C d , (0 , ∞ )). Mor eo ver, ∇ Φ( f 1 , f 2 ) is defined and contin uous on C ( C d , R ) × C ( C d , R ) and is given by ∇ Φ( f 1 , f 2 ) · ( g 1 , g 2 ) = − 1 f 1 f 2 g 1 + ln f 1 ( f 2 ) 2 g 2 . Since r C d ˜ θ n ( · ) = Φ( r C d ˆ H n ( · ) , r C d ( − ln c ˜ H n )( · )) , 1056 C.Y. R ob ert we deduce by the δ -metho d (see Theorem 3 .9.4 in [ 43 ]) and Prop osition 6.1 that p k n ( r C d ˜ θ n ( · ) − r C d θ ( · )) ⇒ r C d Θ( · ) in D ( C d ). W e end this sec tion with the pro of of Theorem 4.1 . Pro of o f Theorem 4. 1 . Let m ≥ 1 and τ 1 , . . . , τ m ∈ Ψ L . Ther e exists C d ⊂ [0 , 1] d such that τ 1 /L ( τ 1 ) , . . . , τ m /L ( τ m ) ∈ C d . By Coro llary 6.2 , we deduce that p k n ( ˆ θ (1) n ( τ i ) − θ ( τ i )) i =1 ,...,m ⇒ Θ τ i L ( τ i ) i =1 ,...,m . Let m ≥ 1 a nd τ 1 , . . . , τ m ∈ Ψ κ . B y us ing similar a rgumen ts a s for the pr oof of Corol- lary 6.1 , we hav e ( U ˇ Z n ( · , τ i )) i =1 ,...,m ⇒ ˆ U τ i ( − ln ˜ H ( τ i )) ( · ) i =1 ,...,m in ( D ([0 , ¯ κ ])) 2 m . Let us consider the thre sholds ˆ v ( τ i ) r n ( κ ) = ˇ Z ( τ i ) ( ⌈ k n κ ⌉ ) = v ( τ i ) r n r n ( − ln ˜ H ( τ i )) ˇ Z ( τ i ) ( ⌈ k n κ ⌉ ) , i = 1 , . . . , m. Recall that p k n ( Q ˇ Z n (( · ) , τ i ) − ( · )) ⇒ ˆ W ( · ) τ i ( − ln ˜ H ( τ i )) in D ([0 , ¯ κ ]). B y using V erv aat’s lemma [ 44 ], we deduce that p k n r n ( − ln ˜ H ( τ i )) ˇ Z ( τ i ) ( ⌈ k n ( · ) ⌉ ) − ( · ) ⇒ − ˆ W ( · ) τ i ( − ln ˜ H ( τ i )) in D ([0 , ¯ κ ]). No te that p k n 1 k n k n X j =1 1 { ˆ N ( κ , τ ) r n ,j =0 } − e − θ ( τ i )( · ) ! = V ˇ Z n r n ( − ln ˜ H ( τ i )) ˇ Z ( τ i ) ( ⌈ k n ( · ) ⌉ ) , τ i + p k n (e − θ ( τ i ) r n ( − ln ˜ H ( τ i )) / ˇ Z ( τ i ) ( ⌈ k n ( · ) ⌉ ) − e − θ ( τ i )( · ) ) . The multivariate extr emal index function 1057 W e then deduce by the CMT and Co rollary 6.1 that V ˇ Z n r n ( − ln ˜ H ( τ i )) ˇ Z ( τ i ) ( ⌈ k n ( · ) ⌉ ) , τ i ⇒ ˆ V ( · ) τ i ( − ln ˜ H ( τ i )) in D ([0 , ¯ κ ]), by the finite increments formula a nd the CMT that p k n (e − θ ( τ i ) r n ( − ln ˜ H ( τ i )) / ˇ Z ( τ i ) ( ⌈ k n ( · ) ⌉ ) − e − θ ( τ i )( · ) ) ⇒ θ ( τ i )e − θ ( τ i )( · ) ˆ W ( · ) τ i ( − ln ˜ H ( τ i )) and by the δ -metho d that p k n ( ˆ θ (2) n ( τ i ) − θ ( τ i )) ⇒ e θ ( τ i )( · ) − ( · ) ˆ V ( · ) τ i ( − ln ˜ H ( τ i )) + θ ( τ i )e − θ ( τ i )( · ) ˆ W ( · ) τ i ( − ln ˜ H ( τ i )) = 1 − ( · ) e θ ( τ i )( · ) ˆ V ( · ) τ i ( − ln ˜ H ( τ i )) + θ ( τ i ) ˆ W ( · ) τ i ( − ln ˜ H ( τ i )) . Since ln ˜ H κ τ i ( − ln ˜ H ( τ i )) = − κ and H κ τ i ( − ln ˜ H ( τ i )) = e − θ ( τ i ) κ , we hav e 1 − κ e θ ( τ i ) κ ˆ V κ τ i ( − ln ˜ H ( τ i )) + θ ( τ i ) ˆ W κ τ i ( − ln ˜ H ( τ i )) = Θ κ τ i ( − ln ˜ H ( τ i )) . Finally , fix κ and deduce that p k n ( ˆ θ (2) n ( τ i ) − θ ( τ i )) i =1 ,...,m ⇒ Θ κ τ i ( − ln ˜ H ( τ i )) i =1 ,...,m . 7. Discussion In this paper, w e have develop ed new estimators for the m ultiv ariate extr emal index function. In order to co nstruct scale inv a rian t estimators , we hav e used a homogeneo us transformatio n for the first estimator , but it leads to the question of the choice of the optimal tr ansformation. W e hav e a lso consider ed a second estimator whic h is scale in- v ar ian t without transfor mation. O ne may als o ex ploit av erag ing metho ds and consider, for exa mple, the estimator defined by ˆ θ (3) n ( τ ) = 1 φ − σ Z φ σ − ln ˆ H n ( κ τ 0 ) − ln c ˜ H n ( κ τ 0 ) d κ , τ ∈ L τ 0 ≡ { κ τ 0 : κ > 0 } , 1058 C.Y. R ob ert where 0 < σ < φ < ∞ . W e hav e studied the weak conv erg ence of our e s timators as p oint - wise e s timators and given their a symptotic distributions. T o study their weak conv erge nc e as functional estimator s, one must construct a s pecific functional s pace which is differ- ent fro m the Skoroho d s pace of ca glad functions which do es no t contain the set of s c ale inv a rian t functions, then study their asy mptotic prop erties in this space. This seems to be a n imp ortan t aven ue for future rese a rc h. App endix A. Pr o ofs of Pr op ositions 2.1 and 4.1 Pro of of Prop osition 2.1 . Let λ > 0. W e have nP ( Z ( τ ) l > nλ − 1 ) = nP d [ i =1 ((1 − F i, − ( X l,i )) − 1 > n ( τ i λ ) − 1 ) ! = nP d [ i =1 ( X l,i > F ← i, − (1 − n − 1 τ i λ )) ! , where F ← i, − ( τ ) = inf { x ∈ R : F i ( x ) > τ } . Since F ← i ( τ ) ≤ F ← i, − ( τ ) for each τ ∈ (0 , 1 ), we have 0 ≤ nP d [ i =1 ( X l,i > u n,i ( τ i λ )) ! − nP d [ i =1 ( X l,i > F ← i, − (1 − n − 1 τ i λ )) ! ≤ nP d [ i =1 ( F ← i (1 − n − 1 τ i λ ) < X l,i ≤ F ← i, − (1 − n − 1 τ i λ )) ! = nP d [ i =1 ( X l,i = F ← i, − (1 − n − 1 τ i λ )) ! ≤ d X i =1 nP ( X l,i = F ← i, − (1 − n − 1 τ i λ )) . Note that lim n →∞ P ( X l,i = F ← i, − (1 − n − 1 τ i λ )) τ i λ/n = lim n →∞ P ( X l,i = F ← i, − (1 − n − 1 τ i λ )) P ( X l,i > u n,i ( τ i λ )) = lim x → x f,i ¯ F i ( x ) − ¯ F i ( x − ) ¯ F i ( x ) = 0 The multivariate extr emal index function 1059 and then lim n →∞ nP ( Z ( τ ) l > nλ − 1 ) = lim n →∞ nP d [ i =1 ( X l,i > u n,i ( τ i λ )) ! . By ( 1.2 ) and the homog e ne ity pr operty of − ln ˜ H , it follows that lim n →∞ nP ( Z ( τ ) l > nλ − 1 ) = lim n →∞ n (1 − F ( u n ( λ τ ))) = − ln ˜ H ( λ τ ) = λ ( − ln ˜ H ( τ )) . By taking λ = κ ( − ln ˜ H ( τ )) − 1 , we deduce that lim n →∞ nP ( Z ( τ ) l > v ( τ ) n ( κ )) = κ . W e now hav e P max l =1 ,...,n Z ( τ ) l ≤ v ( τ ) n ( κ ) = P max l =1 ,...,n max i =1 ,...,d τ i Y l,i ≤ n ( − ln ˜ H ( τ )) κ − 1 = P max i =1 ,...,d τ i max l =1 ,..,n Y l,i ≤ n ( − ln ˜ H ( τ )) κ − 1 = P max i =1 ,...,d τ i 1 − F i, − ( M n,i ) ≤ n ( − ln ˜ H ( τ )) κ − 1 = P ( M n,i ≤ F ← i, − (1 − n − 1 κ τ i ( − ln ˜ H ( τ )) − 1 ) , i = 1 , . . . , d ) . Note that P ( M n,i ≤ F ← i, − (1 − n − 1 κ τ i ( − ln ˜ H ( τ )) − 1 ) , i = 1 , . . . , d ) − P ( M n,i ≤ F ← i (1 − n − 1 κ τ i ( − ln ˜ H ( τ )) − 1 ) , i = 1 , . . . , d ) = P ( M n,i = F ← i, − (1 − n − 1 κ τ i ( − ln ˜ H ( τ )) − 1 ) , i = 1 , . . . , d ) ≤ d X i =1 nP ( X l,i = F ← i, − (1 − n − 1 κ τ i ( − ln ˜ H ( τ )) − 1 )) → n →∞ 0 . It follows that lim n →∞ P ( M ( Z ) n ≤ v ( τ ) n ( κ )) = lim n →∞ P ( M n,i ≤ F ← i (1 − n − 1 κ τ i ( − ln ˜ H ( τ )) − 1 ) , i = 1 , . . . , d ) = H ( κ τ ( − ln ˜ H ( τ )) − 1 ) = ˜ H ( κ τ ( − ln ˜ H ( τ )) − 1 ) θ ( κ τ ( − l n ˜ H ( τ )) − 1 ) = e − θ ( τ ) κ , 1060 C.Y. R ob ert which means that θ ( τ ) is the univ ar iate e xtremal index of the stationary seq uenc e ( Z ( τ ) n ) n ≥ 1 . Pro of of Prop osition 4.1 . The pro of follows the corresp onding lines of the pro of o f Prop osition 1 in [ 30 ]. Let τ 1 , τ 2 ∈ [0 , ∞ ) d \{ 0 } and s b e a po sitiv e co ns tan t. Define R n ( sn, τ 1 , τ 2 ) = ( N ( τ 1 , τ 2 ) n, 0 ,sn , N ( τ 1 , τ 2 ) n, 1 ,sn , N ( τ 1 , τ 2 ) n, 2 ,sn , N ( τ 1 , τ 2 ) n, 3 ,sn ) ′ . By considering a ∆( u n ( τ 1 ) , u n ( τ 2 ))-separ ating sequence, ( r n ) n ≥ 1 , and Berstein’s blo cks metho d (see Lemma 2.2 in [ 15 ] o r the pro of of Lemma 6.7 in [ 37 ]), we g et lim n →∞ | E (e i v ′ R n ( sn, τ 1 , τ 2 ) ) − ( E (e i v ′ R n ( r n , τ 1 , τ 2 ) )) m n | = 0 , where m n = ⌊ sn/r n ⌋ , ⌊ x ⌋ denotes the integer pa rt o f x and v ∈ R 4 . Now, no te that E (e i v ′ R n ( r n , τ 1 , τ 2 ) ) = P ( N ( τ 1 , τ 2 ) n, 0 ,r n = 0) + E (e i v ′ R n ( r n , τ 1 , τ 2 ) | N ( τ 1 , τ 2 ) n, 0 ,r n > 0) P ( N ( τ 1 , τ 2 ) n, 0 ,r n > 0) . Since ( r n ) n ≥ 1 is a ∆( u n ( τ 1 ) , u n ( τ 2 ))-separ ating sequence a nd lim n →∞ P ( N ( τ 1 , τ 2 ) n, 0 ,n = 0) = e − θ ( τ 1 ∨ τ 2 ) ln( ˜ H ( τ 1 ∨ τ 2 )) , we hav e lim n →∞ n r n P ( N ( τ 1 , τ 2 ) n, 0 ,r n > 0) = − θ ( τ 1 ∨ τ 2 ) ln( ˜ H ( τ 1 ∨ τ 2 )) . W e then deduce that E (e i v ′ R n ( sn, τ 1 , τ 2 ) ) = exp( m n P ( N ( τ 1 , τ 2 ) n, 0 ,r n > 0) E (e i v ′ R n ( r n , τ 1 , τ 2 ) − 1 | N ( τ 1 , τ 2 ) n, 0 ,r n > 0)) + o (1) . On one hand, we hav e lim n →∞ E (e i v ′ R n ( sn, τ 1 , τ 2 ) ) = exp( − sθ ( τ 1 ∨ τ 2 ) ln( ˜ H ( τ 1 ∨ τ 2 ))( E e i v ′ ζ ( τ 1 , τ 2 ) l − 1)) where ζ ( τ 1 , τ 2 ) l = ( ζ ( τ 1 , τ 2 ) 1 ,l + ζ ( τ 1 , τ 2 ) 2 ,l + ζ ( τ 1 , τ 2 ) 3 ,l , ζ ( τ 1 , τ 2 ) 1 ,l , ζ ( τ 1 , τ 2 ) 2 ,l , ζ ( τ 1 , τ 2 ) 3 ,l ) ′ . In par ticula r, we derive the weak conv erg ence of the seque nc e ( R n ( n, τ 1 , τ 2 )) n ≥ 1 by choo s ing s = 1 . On the other hand, it is easily seen by using the de finitio n of u n ( τ ) that lim n →∞ E (e i v ′ R n ( sn, τ 1 , τ 2 ) ) = lim n →∞ E (e i v ′ R sn ( sn,s τ 1 ,s τ 2 ) ) = lim n →∞ E (e i v ′ R n ( n,s τ 1 ,s τ 2 ) ) = exp( − sθ ( τ 1 ∨ τ 2 ) ln( ˜ H ( τ 1 ∨ τ 2 ))( E e i v ′ ζ ( s τ 1 ,s τ 2 ) − 1)) . Therefore, E e i v ′ ζ ( s τ 1 ,s τ 2 ) = E e i v ′ ζ ( τ 1 , τ 2 ) and it follows that π ( τ 1 , τ 2 ) is scale inv ariant. The multivariate extr emal index function 1061 App endix B. Co v ariance function of Θ Let us define the functions C i,j ( · , · ) for i = 1 , 2 a nd j = 1 , 2 by C 1 , 1 ( τ 1 , τ 2 ) = H ( τ 1 ∨ τ 2 ) − H ( τ 1 ) H ( τ 2 ) , C 2 , 2 ( τ 1 , τ 2 ) = − θ ( τ 1 ∨ τ 2 ) ln( ˜ H ( τ 1 ∨ τ 2 )) E (( ζ ( τ 1 , τ 2 ) 1 + ζ ( τ 1 , τ 2 ) 3 )( ζ ( τ 1 , τ 2 ) 2 + ζ ( τ 1 , τ 2 ) 3 )) , C 1 , 2 ( τ 1 , τ 2 ) = E ( N ( τ 1 , τ 2 ) 2 1 { N ( τ 1 , τ 2 ) 1 =0 ,N ( τ 1 , τ 2 ) 3 =0 } ) + H ( τ 1 ) ln ˜ H ( τ 2 ) , C 2 , 1 ( τ 1 , τ 2 ) = E ( N ( τ 1 , τ 2 ) 1 1 { N ( τ 1 , τ 2 ) 2 =0 ,N ( τ 1 , τ 2 ) 3 =0 } ) + H ( τ 2 ) ln ˜ H ( τ 1 ) . Note that C 1 , 2 ( τ 2 , τ 1 ) = C 2 , 1 ( τ 1 , τ 2 ). Let us now character iz e the cov a r iance function of the pro cess Θ . W e hav e cov(Θ( τ 1 ) , Θ( τ 2 )) = 1 H ( τ 1 ) ln ˜ H ( τ 1 ) 1 H ( τ 2 ) ln ˜ H ( τ 2 ) G 1 , 1 ( τ 1 , τ 2 ) + θ ( τ 2 ) H ( τ 1 ) ln ˜ H ( τ 1 ) G 1 , 2 ( τ 1 , τ 2 ) + θ ( τ 1 ) H ( τ 2 ) ln ˜ H ( τ 2 ) G 2 , 1 ( τ 1 , τ 2 ) + θ ( τ 1 ) θ ( τ 2 ) G 2 , 2 ( τ 1 , τ 2 ) , where G 1 , 1 ( τ 1 , τ 2 ) = C 1 , 1 ( τ 1 , τ 2 ) − H ( τ 1 ) d X i =1 ∂ ln H ( τ 1 ) ∂ τ i, 1 C 2 , 1 ( τ ( i ) 1 , τ 2 ) − H ( τ 2 ) d X i =1 ∂ ln H ( τ 2 ) ∂ τ i, 2 C 1 , 2 ( τ 1 , τ ( i ) 2 ) + H ( τ 1 ) H ( τ 2 ) d X i =1 d X j =1 ∂ ln H ( τ 1 ) ∂ τ i, 1 ∂ ln H ( τ 2 ) ∂ τ j, 2 C 2 , 2 ( τ ( i ) 1 , τ ( j ) 2 ) , G 1 , 2 ( τ 1 , τ 2 ) = C 1 , 2 ( τ 1 , τ 2 ) − H ( τ 1 ) d X i =1 ∂ ln H ( τ 1 ) ∂ τ i, 1 C 2 , 2 ( τ ( i ) 1 , τ 2 ) + d X i =1 ∂ ln ˜ H ( τ 2 ) ∂ τ i, 2 C 1 , 2 ( τ 1 , τ ( i ) 2 ) − H ( τ 1 ) d X i =1 d X j =1 ∂ ln H ( τ 1 ) ∂ τ i, 1 ∂ ln ˜ H ( τ 2 ) ∂ τ j, 2 C 2 , 2 ( τ ( i ) 1 , τ ( j ) 2 ) , 1062 C.Y. R ob ert G 2 , 1 ( τ 1 , τ 2 ) = C 2 , 1 ( τ 1 , τ 2 ) + d X i =1 ∂ ln ˜ H ( τ 1 ) ∂ τ i, 1 C 2 , 1 ( τ ( i ) 1 , τ 2 ) − H ( τ 2 ) d X i =1 ∂ ln H ( τ 2 ) ∂ τ i, 2 C 2 , 2 ( τ 1 , τ ( i ) 2 ) − H ( τ 2 ) d X i =1 d X j =1 ∂ ln ˜ H ( τ 1 ) ∂ τ i, 1 ∂ ln H ( τ 2 ) ∂ τ j, 2 C 2 , 2 ( τ ( i ) 1 , τ ( j ) 2 ) , G 2 , 2 ( τ 1 , τ 2 ) = C 2 , 2 ( τ 1 , τ 2 ) + d X i =1 ∂ ln ˜ H ( τ 1 ) ∂ τ i, 1 C 2 , 2 ( τ ( i ) 1 , τ 2 ) + d X i =1 ∂ ln ˜ H ( τ 2 ) ∂ τ i, 2 C 2 , 2 ( τ 1 , τ ( i ) 2 ) + d X i =1 d X j =1 ∂ ln ˜ H ( τ 1 ) ∂ τ i, 1 ∂ ln ˜ H ( τ 2 ) ∂ τ j, 2 C 2 , 2 ( τ ( i ) 1 , τ ( j ) 2 ) . Ac kno wledgemen ts The author gra tefully acknowledges the anonymous referees for v ar ious sug gestions lead- ing to improved results thro ughout the pap er. References [1] Bic kel, P .J. and Wich ura, M.J. (1971). Conv ergence criteria for multiparameter stochastic processes and some applications. Ann. Math. Statist. 42 1656–1670 . MR0383482 [2] Billingsley , P . (1968). Conver genc e of Pr ob ability Me asur es . New Y ork: Wiley . MR0233396 [3] Billingsley , P . (1995). Pr ob abi lity and Me asur e , 3rd ed. New Y ork: Wiley . MR1324786 [4] Beirlan t, J., Goegeb eur, Y., Segers, J. and T eugels, J. (2004). Statistics of Extr emes: The ory and Applic ations . Chichester: Wiley . MR2108013 [5] Deo, C.M. (1973). A note on empirical pro cesses of strong-mixing sequences. Ann. Pr ob ab. 5 870–875. MR0356160 [6] Davis, R.A . an d Miko sch, T. (1998). The sample autocorrelations of h ea vy-tailed pro cesses with app li cations to ARCH. Ann. Statist. 26 2049–2080. MR1673289 [7] Drees, H. (2000). W eighted approximations of tail pro cesse s for β -mixing rand om v ariables. Ann . Appl. Pr ob ab. 10 1274–1301 . MR1810875 [8] Drees, H. (2002). T ail empirical pro cesse s u nder mixing conditions. In Empi ric al Pr o c ess T e chniques for Dep endent Data (H.G. Dehling, T. Mikosc h and M. Sorensen, eds.) 325–342 . Boston: Birkh¨ auser. MR1958788 The multivariate extr emal index function 1063 [9] Einmahl, J.H.J., de Haan, L. and Huang, X. (1993). Estimating a m ultidimensional extreme v alue distribut io n. J. Multivariate Anal. 47 35–47. MR1239104 [10] Einmahl, J.H.J., de Haan, L. and Piterbarg, V.I. (2001). N on p arametri c estimation of the sp ectral measure of an extreme v alue distribution. Ann. Statist. 29 1401–142 3. MR1873336 [11] Einmahl, J.H.J., d e Haan, L. and Sinh a, A.K. (1997). Estimating the spectral measure of an ex treme val ue distribution. Sto chastic Pr o c ess. Appl. 70 143–171 . MR1475660 [12] F erro, C.A.T. (2003). Statistical metho ds for clusters of extreme va lues. Ph.D. thesis, Lan- caster Univ. [13] F erro, C.A.T. and Segers, J. (2003). In ference for clusters of extreme v alues. J. R oy. Statist. So c. Ser. B 65 545–556 . MR1983763 [14] H auksson, H.A., D aco rogna, M., Domenig, T., M ¨ uller, U . and Samoro dnitsky , G. (2001). Multiv ariate ext remes , aggregation and risk estimation. Quant. Financ e 1 79–95. [15] H sing, T., H ¨ usl er, J. and Leadb etter, M.R. (1988). On the exceedance p oin t p rocess for a stationary sequen ce. Pr ob ab. The ory R elate d Fi elds 78 97–112. MR0940870 [16] d e H aan, L. and Resnick, S. (1993). Estimating the limiting distribution of multiv ariate extremes. Comm . Statist. Sto chastic M o dels 9 275–309. MR1213072 [17] d e Haan, L., Resnick, S., Rootzen, H. and de V ries, C.G. (1989). Extremal b eha viour of solutions to a sto c hastic difference equ atio n with application to ARCH processes. Sto chastic Pr o c ess. Appl. 32 13–224. MR1014450 [18] d e Haan, L. and Sinha, A.K. (1999). Estimating the probab ility of a rare even t. Ann. Statist. 27 739–759. MR1714710 [19] H sing, T. (1989). Extreme va lue theory for multiv ariate stationary sequ en ces. J. M ul tivari- ate Anal. 29 274–291. MR1004339 [20] H sing, T., Kl ¨ upp elb erg, C. and Kuh n , G. (2004). Dep endence estimatio n and visualiza- tion in multiv ariate extremes with applications to financial data. Extr emes 7 99–121. MR2154362 [21] K esten, H . (1973). Rand om d ifference equations and renewal theory for pro ducts of random matrices. A cta Math. 131 207–248 . MR0440724 [22] Leadb etter, M.R., Lindgren, G. and Ro otz ´ en, H. (1983). Extr emes and R elate d Pr op erties of R andom Se quenc es and Pr o c esses . New Y ork: Springer. MR0691492 [23] Longin, F. and Solnik, B. (2001). Extreme correlation of internatio nal equity markets. Financ e 56 649–676. [24] Martins, A.P . and F erreira H. ( 20 05). The multiv ariate extremal index and the dep endence structure of a multiv ariate extreme val ue distribution. T est 14 433–448 . MR2211389 [25] Martins, A.P . and F erreira H. (2005). Measuring the extremal dep endence. Statist. Pr ob ab. L ett. 73 99–103. MR2159244 [26] Meyn , S.P . and Tweedie, R.L. (1993). Markov Chains and Sto chastic Stability . New Y ork: Springer. MR1287609 [27] N andagopala n, S. (1990 ). Multiv ariate ext remes an d estimation of the ex tremal index. Ph.D. d iss ertation, Dept . Statistics, Univ. North Carolina, Chap el Hill. [28] N andagopala n, S. (1994). On th e multiv ariate extremal index. J. R es. Nat. Inst. Stand. T e chnol. 99 543–550. [29] N euhaus, G. (1971). On w eak converg ence of stochastic pro cesses with multidimensional time parameter. Ann. Math. Statist. 42 1285–1295 . MR0293706 [30] N o v ak, S.Y . (2002). Multilevel clustering of extremes. Sto chastic Pr o c ess. Appl. 97 59–75. MR1870720 1064 C.Y. R ob ert [31] Parthasarath y , K.R. (1967). Pr ob abil ity Me asur es on Metric Sp ac es . New Y ork–London: Academic Press. MR0226684 [32] Perfekt, R . (1994). Extremal b ehaviour of stationary Marko v c hains with ap p lica tions. Ann. Appl. Pr ob ab. 4 529–548. MR1272738 [33] Perfekt, R. (1997). Extreme va lue th eory for a class of Marko v chai ns with va lues in R d . A dv. in Appl. Pr ob ab. 29 138–164. MR1432934 [34] Poon, S.H., Ro c kinger, M. and T awn, J. (2003). Modelling extreme-v alue dep endence in internatio nal sto c k markets. Statist. Si nic a 13 929–953. MR2026056 [35] R esnic k, S.I. (1987). Extr eme V alues, R e gular V ariation and Poi nt Pr o c esses . New Y ork: Springer. MR0900810 [36] R esnic k, S.I. an d Willek ens, E. (1991). Moving a verages with random co efficien ts and ran- dom co efficien t autoregressiv e models. Comm. Statist. Sto chastic Mo dels 7 511–525. MR1139067 [37] R obert, C.Y. (2008). Inference for the limiting cluster size distribution of extreme v alues. Ann . Statist. T o app ear. [38] R ootz´ en, H. (2008). W eak conv ergence of the tail empirical pro cess for d ependent sequences. Sto chastic Pr o c ess. Appl. D O I:10. 1016/j.spa.20 08.03.003. [39] S hao, Q.-M. and Y u, H. (1996). W eak conv ergence for weigh ted empirical processes of dep enden ts sequences. Ann. Pr ob ab. 24 2098–2127. MR1415243 [40] S mith, R.L. and W eissman, I. ( 19 94). Estimating the extremal in dex. J. R oy. Statist. So c. Ser. B 56 515–528. MR1278224 [41] S mith, R.L. and W eissman, I. (1996). Characterization and estimation of the multiv ariate extremal ind ex. T echnical Rep ort, Univ. North Carolina. [42] S tarica , C. (1999). Multiv ariate ex tremes for mo dels with constant conditional correlations. J. Empiric al Financ e 6 515–553. [43] V aart, A.W. v an der and W ellner, J. (1996). W e ak Conver genc e and Empiric al Pr o c esses . New Y ork: Springer. MR1385671 [44] V erv aat, W. (1972). F u nctional central limit theorems for pro cesses with p osi tive d rift and their inverses . Z. W ahrs ch. V erw. Gebiete 23 245–253. MR0321164 [45] W eissman, I. and N ov ak, S.Y. (1998). On blocks and runs estimators of the extremal index . J. Statist. Plann. I nfer enc e 66 281–288. MR1614480 [46] Zh ang, Z. and Smith, R.L. (2007). On t he estimation and application of max-stable pro- cesses. Su bmitted. R e c eive d F ebruary 2007 and r evise d May 2008
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment