객관적 인과 추론을 위한 설계 우선 원칙
이 논문은 인과 효과를 객관적으로 추정하기 위해서는 관찰 연구라도 무작위 실험을 모방하도록 설계해야 한다는 점을 강조한다. 설계 단계에서 최종 결과 데이터를 전혀 보지 않고, 잠재 결과와 할당 메커니즘을 명시하며, 적절한 공변량과 propensity score를 이용해 처리와 통제 집단의 균형을 확보해야 한다. 필요시 principal stratification을 도입해 실험 템플릿을 조정한다.
저자: Donald B. Rubin
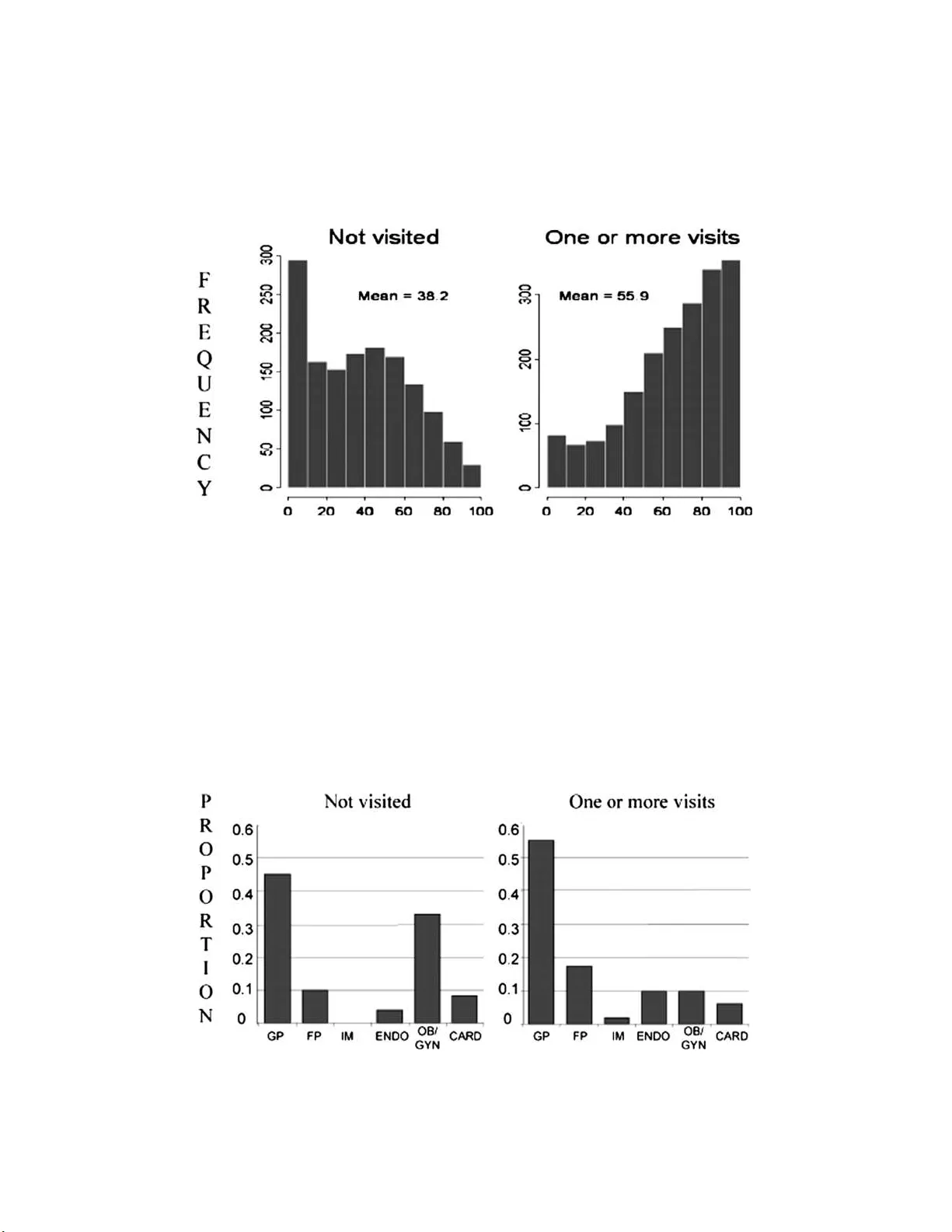
본 논문은 인과 효과를 객관적으로 추정하기 위해서는 무작위 실험이 가장 이상적인 방법이라는 전통적 견해를 인정하면서도, 실제 연구에서는 관찰 연구가 불가피하게 사용된다는 점을 출발점으로 삼는다. 저자는 관찰 연구도 무작위 실험을 모방하도록 설계한다면, 동일한 수준의 객관성을 확보할 수 있다고 주장한다. 이를 위해 Rubin Causal Model(RCM)의 두 핵심 요소인 ‘잠재 결과(potential outcomes)’와 ‘할당 메커니즘(assignment mechanism)’을 명확히 정의하고, 설계 단계에서 이 두 요소를 중심으로 연구를 진행한다.
첫 번째 부분에서는 RCM의 개념적 토대를 설명한다. 단위(unit)는 시간과 장소가 정해진 구체적 객체이며, 각 단위는 처리(treatment)와 통제(control) 두 조건에 대한 잠재 결과 Y(1)와 Y(0)를 가진다. 인과 효과는 이 두 잠재 결과의 차이 혹은 비율 등으로 정의된다. 그러나 실제로는 하나의 조건만이 관측되므로, 관찰된 결과(Y_obs)는 처리 지표 W와 결합된 형태가 된다. 이때 Y_obs를 그대로 사용하면 인과 구조와 관측 구조가 혼동되어 오류가 발생할 위험이 있다.
두 번째 부분에서는 할당 메커니즘을 확률적이고 무조건적인(unconfounded) 형태로 모델링한다. 무작위 실험에서는 Pr(W|X,Y(0),Y(1)) = Pr(W|X) 로 표현되며, 각 단위의 처리 확률인 propensity score e_i = Pr(W_i=1|X_i) 가 0과 1 사이에 존재한다. 이러한 확률적 할당은 관찰 연구에서도 동일하게 적용될 수 있다면, 관찰 데이터에서도 처리와 통제 집단 간의 균형을 propensity score를 통해 맞출 수 있다.
설계 단계에서는 먼저 연구 질문에 맞는 잠재 실험 템플릿을 정의한다. 이 템플릿이 요구하는 핵심 공변량이 데이터에 존재하는지, 그리고 처리와 통제 집단 사이에 공변량 분포가 겹치는(overlap)지를 확인한다. 겹침이 부족하거나 중요한 공변량이 누락된 경우, 해당 데이터셋은 사용을 포기하거나 추가 데이터를 수집해야 한다. 공변량이 충분히 확보되면, propensity score를 추정하고 이를 이용해 매칭, 서브클래스화, 가중치 부여 등 다양한 방법으로 처리군과 통제군을 균형 있게 만든다. 이때 사전 설계된 분석 계획을 고수하고, 최종 결과 데이터를 보지 않은 상태에서 설계가 완료되어야 한다.
논문은 구체적인 사례들을 통해 설계 절차를 시연한다. 첫 번째 예시는 Cochran(1968)의 단일 공변량 사례로, 하나의 배경 변수만을 이용해 propensity score를 계산하고 서브클래스를 만든다. 두 번째 예시는 유방암 치료 비교 연구로, 다중 공변량을 포함한 복잡한 설계를 보여준다. 여기서는 로지스틱 회귀를 통해 propensity score를 추정하고, 매칭과 가중치를 적용해 치료와 대조군 간의 균형을 확보한다. 세 번째 예시는 마케팅 데이터로, 대규모 관측치와 다변량 공변량을 활용해 실제 비즈니스 의사결정에 적용 가능한 설계 과정을 설명한다.
또한 Karolinska Institute 사례에서는 동일한 관찰 데이터가 두 개의 서로 다른 잠재 실험 템플릿을 지원할 수 있음을 보여준다. 하나는 보다 현실적인 비준위(비준위가 높은) 할당 메커니즘을 가정하고, 다른 하나는 이상적인 무작위 할당을 가정한다. 연구자는 두 템플릿을 사전 검토함으로써 어느 템플릿이 더 타당한지 판단하고, 그에 따라 설계와 분석을 진행한다.
마지막으로, 비순응(noncompliance)이나 중간 변수(intermediate variable) 문제를 다루기 위해 principal stratification을 도입한다. 이는 관찰 연구가 실제 실험과 동일한 인과 구조를 모방하도록 돕는 중요한 도구이며, 특히 치료에 대한 순응 여부에 따라 하위 집단을 구분해 각각의 인과 효과를 추정한다.
결론적으로, 저자는 “설계가 분석을 능가한다”는 원칙을 강조한다. 관찰 연구에서도 사전 설계 단계에서 잠재 실험을 재구성하고, propensity score 기반의 균형 확보와 principal stratification을 적절히 활용한다면, 무작위 실험과 동등한 수준의 객관적 인과 추론이 가능하다고 주장한다. 이는 통계학자와 실무 연구자 모두에게 설계 단계의 중요성을 재인식시키는 중요한 메시지를 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기