학습률 없는 TD 업데이트: 통계적 원리로 도출된 새로운 학습률 함수
본 논문은 변분 원리와 부트스트랩을 이용해 TD(λ) 업데이트 식을 재유도하고, 고정 학습률 α 대신 상태 전이마다 자동으로 계산되는 학습률 βₜ(s,s′)를 제시한다. 실험 결과 HL(λ)이라 명명한 알고리즘이 기존 TD(λ)보다 수렴 속도와 안정성 모두에서 우수함을 확인하였다. 또한 Q‑learning과 Sarsa에 적용한 변형도 학습률 파라미터 없이 경쟁력을 보였다.
저자: Marcus Hutter, Shane Legg
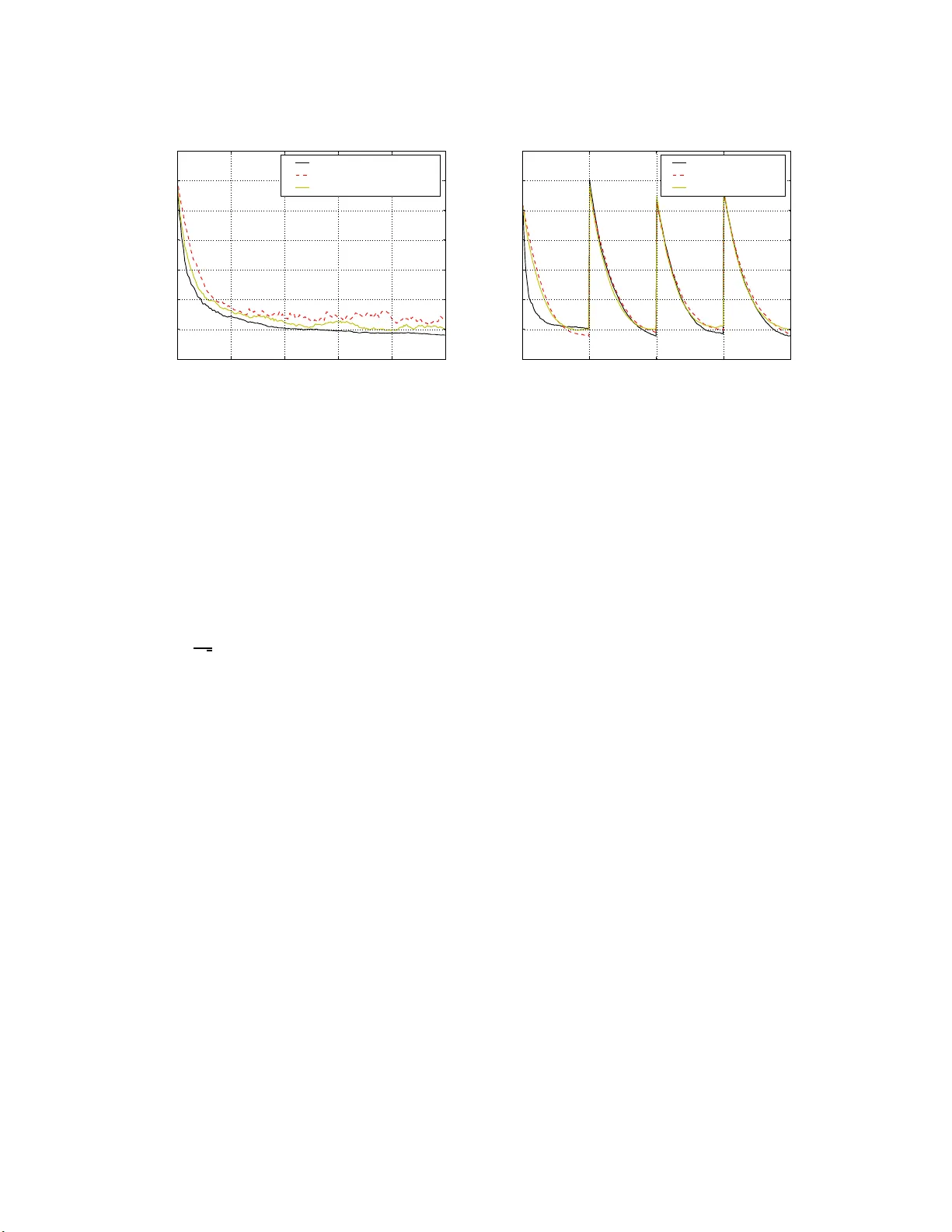
본 논문은 강화학습에서 가치 함수 추정에 널리 사용되는 TD(λ) 알고리즘을 변분 원리와 부트스트랩 기법을 통해 재유도하고, 고정 학습률 α를 제거한 새로운 업데이트 규칙을 제시한다.
1. **배경 및 문제점**
- 전통적인 TD(0)와 TD(λ)는 V(s)←V(s)+α·δ·E(s) 형태의 업데이트를 사용한다. 여기서 α는 사용자가 사전에 지정하거나 경험에 따라 감소시키는 고정 파라미터이며, 적절한 α를 찾는 것이 실무에서 큰 어려움이다.
- LSTD(λ)와 같은 최소제곱 기반 방법은 학습률을 자동으로 결정하지만, 선형 근사와 행렬 연산이 필요해 계산 비용이 크게 늘어난다.
2. **수학적 유도**
- 상태 s의 경험적 미래 할인 보상 vₖ를 정의하고, 손실 함수 L=½∑ₖ λ^{t−k}(vₖ−V(sₖ))² 를 최소화한다.
- 손실을 V(s)에 대해 미분하면 방문 횟수 Nₜ(s)=∑ₖ λ^{t−k}δ_{sₖ,s}와 자격 추적 Eₜ(s)=∑ₖ (λγ)^{t−k}δ_{sₖ,s}가 등장한다.
- vₖ는 자체 일관성 관계 vₖ=∑_{u=k}^{t−1}γ^{u−k}r_u+γ^{t−k}v_t 로 표현할 수 있다. 여기서 v_t 를 현재 추정값 V(s_t) 로 대체(부트스트랩)한다.
- 이를 손실식에 대입하고 정리하면 최종 업데이트 식 (8)이 도출된다.
3. **새로운 학습률 βₜ**
- βₜ(s,s_{t+1}) = 1/(Nₜ(s_{t+1})−γEₜ(s_{t+1}))·(Nₜ(s_{t+1})/Nₜ(s)) 로 정의된다.
- 첫 번째 인자는 목표 상태 s_{t+1}에 대한 방문 빈도와 자격 추적을 이용해 과도한 업데이트를 억제하고, 두 번째 인자는 소스와 목표 상태의 방문 빈도 비율을 반영해 데이터가 부족한 상태에 대해 학습률을 크게 만든다.
- 결과적으로 βₜ는 각 전이에 대해 자동으로 조정되며, 별도의 α 튜닝이 필요하지 않다.
4. **알고리즘 명칭 및 복잡도**
- 제안된 알고리즘을 HL(λ) (Hutter‑Legg λ)라 부른다.
- 업데이트는 기존 TD(λ)와 동일하게 O(1) 연산으로 수행되며, 추가적인 행렬 연산이 필요하지 않는다.
5. **실험 설계**
- **단순 51‑state 마코프 체인**: 양쪽 끝에서 25 로 이동하고 보상이 ±1인 구조, γ=0.99. HL(λ) (λ=1)와 TD(λ) (λ=0.9, 다양한 α) 비교. HL이 초기 수렴이 빠르고 최종 RMSE가 낮았다.
- **무작위 50‑state 마코프 체인**: 전이 행렬을 90% 확률로 0, 나머지는 균등 난수로 채워 정규화. γ=0.99. HL이 TD보다 전반적으로 낮은 RMSE를 유지했다.
- **비정상 21‑state 마코프 체인**: 5,000 스텝마다 보상 구조를 교체해 환경이 주기적으로 변함. λ을 0.9995 정도로 설정한 HL이 빠르게 적응하고 안정적인 성능을 보였다. TD는 최적 λ≈0.8, α≈0.05가 필요했으며, 여전히 HL보다 성능이 뒤떨어졌다.
6. **정책 학습에의 확장**
- HL(λ)에서 도출한 βₜ를 Q‑learning(워킨스 Q(λ))과 Sarsa(λ)에 그대로 적용해 HL‑Q와 HL‑Sarsa를 구현하였다.
- 동일한 실험 환경(γ=0.9, λ=0.9)에서 두 알고리즘은 평균 에피소드 길이와 수렴 속도 면에서 기존 Q(λ), Sarsa(λ)보다 우수했다. 특히 학습률 파라미터를 전혀 지정하지 않아도 자동으로 적절한 업데이트 강도를 유지했다.
7. **논의 및 향후 연구**
- βₜ는 방문 횟수와 자격 추적을 이용한 정규화 형태이므로, 상태 공간이 매우 크거나 연속적인 경우에도 근사적으로 계산 가능하다.
- 현재는 표형태(state‑tabular)에서 실험했지만, 신경망 기반 함수 근사와 결합하면 딥 RL에서도 학습률 자동 조정 메커니즘으로 활용될 가능성이 있다.
- 다중 에이전트, 부분 관측, 혹은 비마코프 환경에서 βₜ의 동적 특성을 분석하는 것이 다음 단계가 될 것이다.
**결론**
HL(λ)는 변분 원리와 부트스트랩을 통해 TD(λ)의 학습률을 데이터‑드리븐 함수 βₜ로 대체함으로써, 파라미터 튜닝 없이도 빠른 수렴과 높은 안정성을 제공한다. 가치 추정뿐 아니라 Q‑learning, Sarsa와 같은 정책 학습에도 그대로 적용 가능함을 실험적으로 입증하였다. 이는 강화학습 알고리즘 설계에서 학습률 파라미터를 제거할 수 있는 중요한 첫 걸음으로 평가된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기