Temporal Difference Updating without a Learning Rate
We derive an equation for temporal difference learning from statistical principles. Specifically, we start with the variational principle and then bootstrap to produce an updating rule for discounted state value estimates. The resulting equation is s…
Authors: Marcus Hutter, Shane Legg
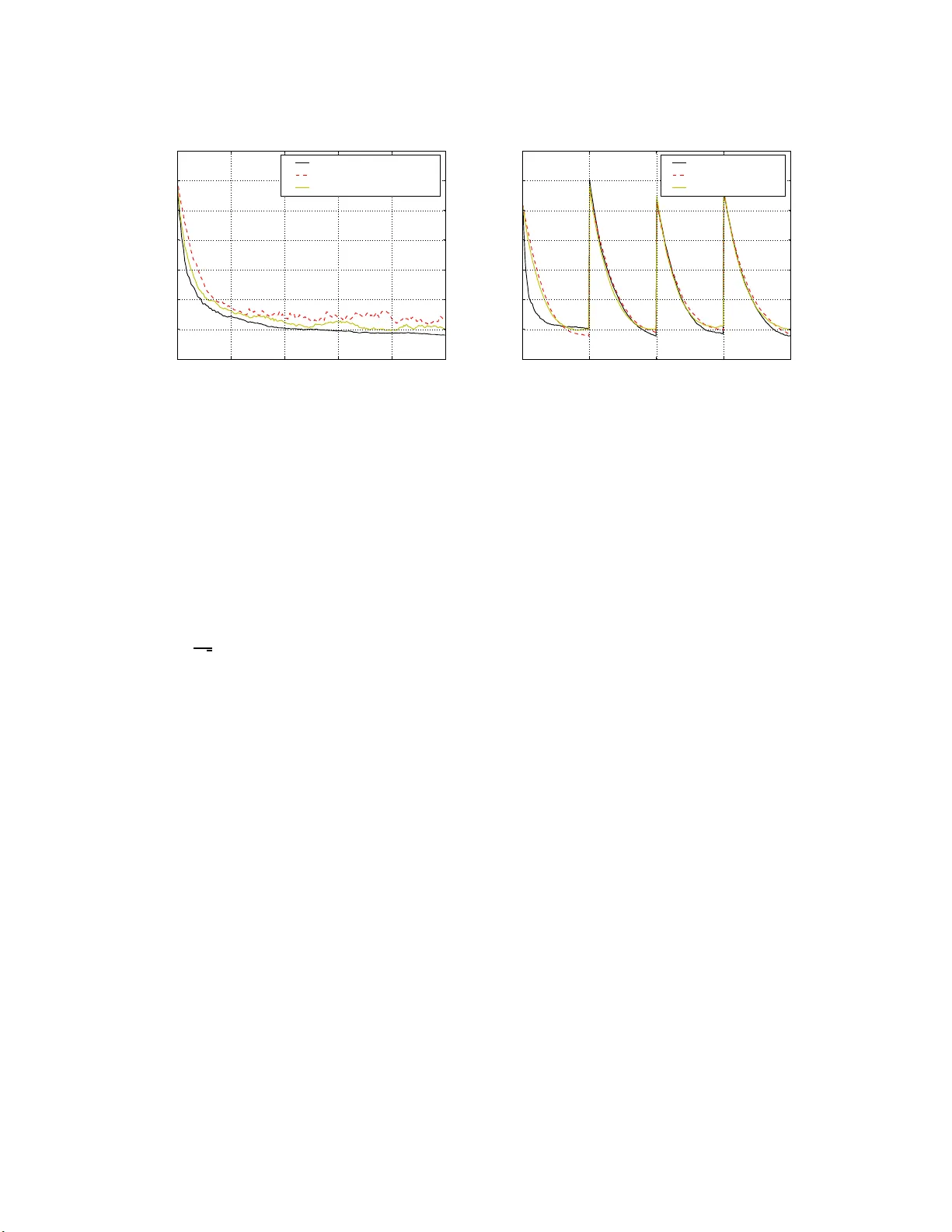
T emp oral Difference Up dating withou t a Learning Ra te Marcus Hutter RSISE @ ANU and SML @ NICT A, Canberra, A CT, 0200, Australia marcus@hutt er1.net www.hutter1 .net Shane Legg IDSIA, Galleria 2, Manno-Lugano CH-6928 , Switzerland shane@vetta .org www.vetta .org/shane 31 Octob er 2008 Abstract W e deriv e an equation for temp oral difference lea rning from statistical principles. Sp ecifically , w e start w ith the v ariat ional principle and then b o o t- strap to pr o duce an up dating rule f or d iscoun ted state v alue estimates. The resulting equation is similar to th e standard equation for temp oral difference learning with eligibilit y traces, so called TD( λ ), how ev er it lac ks the param- eter α that sp ecifies the learnin g rate. In the place of this free parameter there is now an equation for the learning r ate that is sp ecific to eac h state transition. W e exp erim entally test this new learning rule against TD( λ ) an d find that it offers sup erior p er f ormance in v arious settings. Finally , w e m ake some preliminary inv estigatio ns into how to extend our n ew temp oral differ- ence algorithm to reinforcement learning. T o do this w e com b ine our up date equation with b oth W atkins’ Q( λ ) and Sars a( λ ) and find th at it again offers sup er ior p erformance without a learning r ate parameter. Keyw ords reinforcemen t learnin g; temp oral difference; eligibilit y trace; v ariational prin- ciple; learning rate. 1 1 In tro du c tion In the field of reinforcemen t learning, p erhaps the most p o pular w ay to estimate the fut ure discoun ted rew ard of states is the metho d of temp or al differ enc e le arning . It is unclear who exactly intro duced this first, how ever the first explicit v ersion of temp oral difference as a learning rule app ears to b e Witten [Wit77]. The idea is as follo ws: The exp e cte d futur e d isc ounte d r ewar d of a state s is, V s := E n r k + γ r k +1 + γ 2 r k +2 + · · · | s k = s o , where the rew ards r k , r k +1 , . . . are geometrically discoun ted into the future b y γ < 1. F rom this definition it follows that, V s = E n r k + γ V s k +1 | s k = s o . (1) Our task, at time t , is to compute an estimate V t s of V s for eac h stat e s . The only information we hav e to base this estimate on is the curren t history of state transitions, s 1 , s 2 , . . . , s t , and the curren t history of observ ed rew a rds, r 1 , r 2 , . . . , r t . Equation (1) suggests that at time t + 1 the v alue of r t + γ V s t +1 pro vides us with information on what V t s should b e: If it is higher than V t s t then p erhaps this es timate should b e increased, and vice v ersa. This in tuition giv es us the follo wing estimation heuristic for state s t , V t +1 s t := V t s t + α r t + γ V t s t +1 − V t s t , where α is a pa r ameter that controls t he rate of learning. This ty p e of temp oral difference learning is known a s TD(0). One shortcoming of this metho d is that at each time step the v alue of only the last state s t is up dated. Stat es b efore the last state are also affected by c ha ng es in the last state’s v alue and th us these could b e up dated to o. This is what happ ens with so called temp or al differ enc e le arning w i th eligibility tr ac es , where a history , o r trace, is k ept o f whic h states hav e b een recen t ly visited. Under this metho d, when w e up date the v alue of a state w e also go back through the trace up dating the earlier states as w ell. F ormally , for any state s its eligibility trace is computed b y , E t s := ( γ λE t − 1 s if s 6 = s t , γ λE t − 1 s + 1 if s = s t , where λ is used to con tro l the rate at whic h the eligibilit y t race is discounte d. The temp oral difference up date is then, f o r all states s , V t +1 s := V t s + αE t s r + γ V t s t +1 − V t s t . (2) This more p ow erful v ersion of temp oral different learning is known as TD ( λ ) [Sut88 ]. The main idea of this pa p er is t o deriv e a temp oral difference rule from statistical principles and compare it to the standard heuristic describ ed ab o v e. Superficially , 2 our w o rk has some similarities to LSTD( λ ) ([LP03] and references therein). How ev er LSTD is concerned with finding a least- squares linear function approximation, it ha s not yet b een dev elop ed f or general γ and λ , and has up date time quadratic in the n umber of features/states. On the other hand, our alg o rithm “exactly” coincides with TD/Q/Sa r sa( λ ) f o r finite state spaces, but with a nov el learning rate deriv ed from statistical principles. W e therefore fo cus our comparison on TD/ Q /Sarsa. F or a recen t surv ey of metho ds to set the learning rate see [GP06]. In Se ction 2 we deriv e a least squares estimate for the v alue function. By ex- pressing the estimate as an incremen tal up dat e rule w e obtain a new form of TD( λ ), whic h we call HL( λ ). In Se ction 3 w e compare HL( λ ) to TD( λ ) o n a simple Mark ov c hain. W e then test it on a random Mark ov c hain in Se ction 4 and a non-stationary en vironmen t in Se ction 5 . In Se ction 6 we deriv e t w o new metho ds for p olicy learn- ing based on HL( λ ), and compare them to Sarsa( λ ) and W atkins’ Q( λ ) on a simple reinforcemen t learning problem. Se ction 7 ends the pap er with a summary and some though t s on future researc h directions. 2 Deriv ation The empiric al futur e disc ounte d r ewar d o f a state s k is the sum of actual r ewar ds follo wing from state s k in time steps k , k + 1 , . . . , where the rew ards are discoun ted as they go in to the future. F ormally , the empirical v alue o f state s k at time k for k = 1 , ..., t is, v k := ∞ X u = k γ u − k r u , (3) where the future rew ards r u are geometrically discoun ted by γ < 1. In practice the exact v alue o f v k is alw ays unkno wn to us as it dep ends not only o n rew ar ds that hav e b een already o bserv ed, but also on unkno wn future rew ards. Note that if s m = s n for m 6 = n , that is, w e ha ve visited the same state twic e at differen t times m and n , t his do es not imply that v n = v m as the observ ed rew a rds fo llo wing the state visit may b e differen t eac h time. Our go al is tha t for each stat e s the estimate V t s should b e as close as p ossible to the true exp ected future discoun ted rew a rd V s . Th us, for each state s w e w ould lik e V s to b e close to v k for all k suc h t hat s = s k . F urthermore, in non- stat io nary en vironmen t s we w ould like to discount old evidence b y some parameter λ ∈ (0 , 1]. F ormally , w e wan t to minimise the loss function, L := 1 2 t X k =1 λ t − k ( v k − V t s k ) 2 . (4) F or stationary en vironmen ts w e may simply set λ = 1 a priori. As w e wish to minimise this lo ss, w e take the partial deriv ativ e with resp ect to 3 the v alue estimate of each state and set to zero, ∂ L ∂ V t s = − t X k =1 λ t − k ( v k − V t s k ) δ s k s = V t s t X k =1 λ t − k δ s k s − t X k =1 λ t − k δ s k s v k = 0 , where w e could change V t s k in to V t s due to the presence of the Kronec k er δ s k s , defined δ xy := 1 if x = y , and 0 otherwise. By defining a discoun ted state visit counter N t s := P t k =1 λ t − k δ s k s w e get V t s N t s = t X k =1 λ t − k δ s k s v k . (5) Since v k dep ends o n future rew ards r k , Equation (5) can not b e used in its current form. Next w e note that v k has a self-consistency prop ert y with resp ect to the rew ards. Sp ecifically , t he tail of the future discoun ted rew ard sum for eac h state dep ends on the empirical v alue at time t in the follo wing w ay , v k = t − 1 X u = k γ u − k r u + γ t − k v t . Substituting this into Equation (5) and exc hanging the order of the do uble sum, V t s N t s = t − 1 X u =1 u X k =1 λ t − k δ s k s γ u − k r u + t X k =1 λ t − k δ s k s γ t − k v t = t − 1 X u =1 λ t − u u X k =1 ( λγ ) u − k δ s k s r u + t X k =1 ( λγ ) t − k δ s k s v t = R t s + E t s v t , where E t s := P t k =1 ( λγ ) t − k δ s k s is the eligibility trace of state s , and R t s := P t − 1 u =1 λ t − u E u s r u is the discoun ted reward with eligibilit y . E t s and R t s dep end only on quan tities kno wn at time t . The only unkno wn quan tity is v t , whic h we ha v e to replace with our curren t estimate of this v alue a t time t , whic h is V t s t . In o t her w ords, w e b o o tstrap our estimates. This g iv es us, V t s N t s = R t s + E t s V t s t . (6) F or state s = s t , this simplifies to V t s t = R t s t / ( N t s t − E t s t ). Substituting this bac k in to Equation (6) we obtain, V t s N t s = R t s + E t s R t s t N t s t − E t s t . (7) This giv es us an explicit expression for our V estimates. Ho wev er, from an algorith- mic p ersp ectiv e an incremen tal up date rule is more con v enien t. T o deriv e this w e mak e use of the relations, N t +1 s = λN t s + δ s t +1 s , E t +1 s = λγ E t s + δ s t +1 s , R t +1 s = λR t s + λE t s r t , 4 with N 0 s = E 0 s = R 0 s = 0. Inserting these into Equation (7) with t replaced b y t + 1, V t +1 s N t +1 s = R t +1 s + E t +1 s R t +1 s t +1 N t +1 s t +1 − E t +1 s t +1 = λR t s + λE t s r t + E t +1 s R t s t +1 + E t s t +1 r t N t s t +1 − γ E t s t +1 . By solving Equation (6) for R t s and substituting ba ck in, V t +1 s N t +1 s = λ ( V t s N t s − E t s V t s t ) + λE t s r t + E t +1 s N t s t +1 V t s t +1 − E t s t +1 V t s t + E t s t +1 r t N t s t +1 − γ E t s t +1 = ( λN t s + δ s t +1 s ) V t s − δ s t +1 s V t s − λE t s V t s t + λE t s r t + E t +1 s N t s t +1 V t s t +1 − E t s t +1 V t s t + E t s t +1 r t N t s t +1 − γ E t s t +1 . Dividing through b y N t +1 s (= λN t s + δ s t +1 s ), V t +1 s = V t s + − δ s t +1 s V t s − λE t s V t s t + λE t s r t λN t s + δ s t +1 s + ( λγ E t s + δ s t +1 s )( N t s t +1 V t s t +1 − E t s t +1 V t s t + E t s t +1 r t ) ( N t s t +1 − γ E t s t +1 )( λN t s + δ s t +1 s ) . Making the first denominator the same as the second, then expanding the nu- merator, V t +1 s = V t s + λE t s r t N t s t +1 − λE t s V t s t N t s t +1 − δ s t +1 s V t s N t s t +1 − λγ E t s t +1 E t s r t ( N t s t +1 − γ E t s t +1 )( λN t s + δ s t +1 s ) + λγ E t s t +1 E t s V t s t + γ E t s t +1 V t s δ s t +1 s + λγ E t s N t s t +1 V t s t +1 − λγ E t s E t s t +1 V t s t ( N t s t +1 − γ E t s t +1 )( λN t s + δ s t +1 s ) + λγ E t s E t s t +1 r t + δ s t +1 s N t s t +1 V t s t +1 − δ s t +1 s E t s t +1 V t s t + δ s t +1 s E t s t +1 r t ( N t s t +1 − γ E t s t +1 )( λN t s + δ s t +1 s ) . After cancelling equal terms (k eeping in mind that in ev ery t erm with a Kronec ker δ xy factor we ma y assume that x = y as the term is alw ays zero otherwise), a nd factoring out E t s w e obtain, V t +1 s = V t s + E t s ( λr t N t s t +1 − λV t s t N t s t +1 + γ V t s δ s t +1 s + λγ N t s t +1 V t s t +1 − δ s t +1 s V t s t + δ s t +1 s r t ) ( N t s t +1 − γ E t s t +1 )( λN t s + δ s t +1 s ) Finally , b y factoring out λN t s t +1 + δ s t +1 s w e obtain our up date rule, V t +1 s = V t s + E t s β t ( s, s t +1 ) ( r t + γ V t s t +1 − V t s t ) , (8) 5 where the learning r ate is giv en b y , β t ( s, s t +1 ) := 1 N t s t +1 − γ E t s t +1 N t s t +1 N t s . (9) Examining Equation (8 ), w e find the usual up date equation for temp oral difference learning with eligibilit y traces (see Equation (2)), how ev er the learning rate α has no w b een replaced b y β t ( s, s t +1 ). This learning rate w as deriv ed fr o m statistical principles by minimising the squared loss b et wee n the estimated a nd true state v alue. In the deriv ation w e ha ve exploited the fact that the latter mus t b e self-consisten t and then b o otstrapp ed to get Equation (6). This giv es us an equation for the learning rat e for eac h state transition at time t , as opp osed to the standard temp o ral difference learning where the learning rate α is either a fixed free para meter for all transitions, or is decreas ed o ver time b y some monotonically decreasing function. In either case, the learning rate is not automatic a nd m ust b e experimen tally tuned for go o d p erformance. The ab o v e deriv ation app ears to theoretically solv e this problem. The first term in β t seems to prov ide some t yp e of normalisatio n to the learning rate, though the intuition b ehind this is no t clear to us. The meaning of second term ho wev er can b e understo o d as follow s: N t s measures ho w often w e hav e visited state s in the recen t past. Therefore, if N t s ≪ N t s t +1 then state s has a v alue estimate based on relat ively few samples, while state s t +1 has a v alue estimate based on relativ ely man y samples. In suc h a situation, the sec ond term in β t b o osts the learning rate so that V t +1 s mo ves more a ggressiv ely to w ards the presumably more accurate r t + γ V t s t +1 . In the opp osite situation when s t +1 is a less visited state, w e see that the rev erse o ccurs and the learning rate is reduced in order to main tain the existing v alue of V s . 3 A s imple Mark ov pro ce s s F or our first test we consider a simple Mark ov pro cess with 51 states. In eac h step the state n um b er is either incremen ted or decremen ted b y one with equal proba bilit y , unless the system is in state 0 or 50 in which case it a lwa ys transitions to state 25 in the follo wing step. When the state transitions from 0 to 25 a reward of 1.0 is generated, and for a tra nsition from 5 0 to 25 a reward o f -1.0 is generated. All other transitions hav e a rew ard of 0. W e set t he discoun t v alue γ = 0 . 99 and then computed the true discoun ted v a lue of each state b y running a brute force Mon te Carlo sim ula t ion. W e ran our alg orithm 10 times on the ab ov e Mark ov chain and computed the ro ot mean squared error in the v alue estimate across the states a t eac h t ime step a veraged across eac h run. The optimal v alue of λ for HL( λ ) was 1.0, which was to b e exp ected giv en that the en vironmen t is stationary and th us discoun ting old exp erience is not helpful. F or TD( λ ) w e tried v arious different learning rates and v alues o f λ . W e could find no settings where TD( λ ) w as comp etitiv e with HL( λ ). If the learning ra te α 6 0.0 0.5 1.0 1.5 2.0 Time x1e+4 0.05 0.10 0.15 0.20 0.25 0.30 0.35 0.40 RMSE HL(1.0) TD(0.9) a = 0.1 TD(0.9) a = 0.2 Figure 1: 51 stat e Mark ov pro cess av er- aged o v er 10 runs. The para meter a is the learning rate α . 0.0 0.5 1.0 1.5 2.0 Time x1e+4 0.05 0.10 0.15 0.20 0.25 0.30 0.35 0.40 RMSE HL(1.0) TD(0.9) a = 8.0/sqrt(t) TD(0.9) a = 2.0/cbrt(t) Figure 2: 51 stat e Mark ov pro cess a v er- aged o ver 300 runs. w as set to o high the system w ould learn as fast as HL( λ ) briefly b efore b ecoming stuc k. With a lo wer learning rate the final p erformance w as impro ved, how ev er the initial p erformance w as no w muc h w orse than HL( λ ). The results of these tests app ear in Figure 1. Similar tests w ere p erformed with larger and smaller Mar ko v c hains, and with differen t v alues of γ . HL( λ ) was consisten tly sup erior to TD ( λ ) across these tests. One wonders whether this may b e due to the fact tha t the implicit learning rate that HL( λ ) uses is not fixed. T o test this w e explored t he p erfo rmance of a num b er of different learning rat e functions on the 51 state Mark ov chain describ ed a b o v e. W e found that functions o f the form κ t alw ays p erfor med p o orly , ho w ev er go o d p erformance w as p ossible by setting κ correctly for functions of the fo rm κ √ t and κ 3 √ t . As the results w ere m uch closer, we a veraged ov er 300 runs. T hese results app ear in Figure 2. With a v ariable lear ning rate TD( λ ) is p erfo r ming m uch b etter, ho w ev er w e w ere still unable to find an equation that reduced the learning rate in suc h a w ay that TD( λ ) w ould outp erform HL( λ ). This is evidence that HL ( λ ) is adapting the learning rate o ptimally without the need for man ual equation tuning. 4 Random Mark ov pro cess T o test on a Mark ov pro cess with a more complex tra nsition structure, w e created a random 50 state Marko v pro cess. W e did this by creating a 50 b y 50 tra nsition matrix where eac h elemen t w as set to 0 with probability 0.9, and a uniformly random n umber in the interv al [0 , 1] o t herwise. W e then scaled eac h ro w to sum to 1. Then to transition b etw een states w e in terpreted the i th ro w a s a probabilit y distribution o ver whic h state follow s state i . T o compute the rew ar d asso ciated with eac h transition 7 0 1000 2000 3000 4000 5000 Time 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 RMSE HL(1.0) TD(0.9) a = 0.2 TD(0.9) a = 1.5/cbrt(t) Figure 3 : Random 5 0 state Marko v pro- cess. The parameter a is the learning rate α . 0.0 0.5 1.0 1.5 2.0 Time x1e+4 0.00 0.05 0.10 0.15 0.20 0.25 0.30 0.35 RMSE HL(0.9995) TD(0.8) a = 0.05 TD(0.9) a = 0.05 Figure 4: 21 state non-statio nary Marko v pro cess. w e created a random matrix as ab o v e, but without normalising. W e set γ = 0 . 9 and then ran a brute force Mon te Carlo sim ulation to compute the t r ue discoun ted v alue o f eac h state. The λ pa rameter for HL( λ ) w as simply set to 1.0 as the en vironmen t is station- ary . F or TD we experimented with a range of pa rameter settings and learning r ate decrease functions. W e fo und that a fixed learning rate of α = 0 . 2, and a decreasin g rate of 1 . 5 3 √ t p erformed reasonable w ell, but nev er as w ell as HL( λ ). The results w ere generated by av eraging ov er 10 runs, and are sho wn in Figure 3. Although the structure of t his Marko v pro cess is quite different to that used in the previous exp erimen t, the results are again similar: HL( λ ) preforms as w ell or b etter than TD( λ ) from the b eginning to the end of the r un. F urthermore, stabilit y in the error tow ards the end of t he run is b etter with HL( λ ) a nd no man ual learning tuning w a s required for these p erformance gains. 5 Non-statio n ary Mark o v pro cess The λ parameter in HL( λ ) , introduced in Equation (4), reduces the imp orta nce of old observ ations when computing the state v alue estimates. When the en vironmen t is stationary this is not useful and so w e can set λ = 1 . 0 , ho wev er in a non-stat io nary en vironmen t we need to reduce this v alue so tha t the state v alues a da pt prop erly to c hanges in the env ironmen t. The more rapidly the en vironment is c hanging, the lo wer w e need to mak e λ in order to more rapidly forg et o ld observ ations. T o test HL( λ ) in suc h a setting, we used the Marko v ch ain from Section 3, but reduced its size to 21 states to sp eed up con vergenc e. W e used this Mark ov chain f or the first 5,00 0 time steps. At that p oin t, w e c ha nged the rew ard when transitioning from the last state to middle state to from -1.0 to b e 0.5. At time 10 ,0 00 w e then 8 switc hed back to the original Marko v c hain, and so o n alternating b et wee n the mo dels of the en vironmen t ev ery 5 ,000 steps. A t each switc h, we also c ha ng ed the target state v alues that the algorithm was trying to estimate to matc h the curren t configuration of the en vironmen t. F or this exp eriment w e set γ = 0 . 9. As exp ected, the optimal v alue of λ f or HL( λ ) fell fro m 1 do wn to ab out 0 .9995. This is ab out what w e w ould exp ect g iv en that eac h phase is 5,000 steps lo ng. F or TD( λ ) the optimal v alue of λ was around 0.8 and the o ptimum learning r a te w as around 0 . 05. As we w o uld exp ect, for b oth algo rithms when w e pushed λ a b o v e its optimal v alue t his caused p o or p erformance in the p erio ds follo wing eac h switc h in the en vironmen t (these bad parameter settings are not sho wn in the results). On the other hand, setting λ to o lo w pr o duced initially fast adaption to eac h env ironmen t switc h, but p o or p erformance after that until the next en vironment c hange. T o g et accurate statistics we a veraged ov er 20 0 runs. The results of these tests a pp ear in Figure 4. F or some reason HL(0 . 9995) learns faster tha n TD( 0 . 8) in the fir st half o f the first cycle, but only equally fast at the start of eac h follo wing cycle. W e a r e not sure wh y this is ha pp ening. W e could improv e the initial sp eed at which HL( λ ) learnt in the last three cycles b y reducing λ , how ev er tha t comes at a p erformance cost in terms of the lo w est mean squared error attained at the end o f eac h cycle. In any case, in this non- stationary situation HL( λ ) again p erformed well. 6 Windy Gr i dw orl d Reinforcemen t learning algo rithms suc h as W atkins’ Q ( λ ) [W at89] and Sarsa( λ ) [RN94, Rum95] are based o n temp oral difference up dates. This suggests that new reinforcemen t learning algor ithms based on HL( λ ) should b e p o ssible. F or our first exp erimen t w e to o k the standar d Sarsa( λ ) alg orithm and mo dified it in the ob vious wa y to use an HL temp oral difference up date. In the presen tation of this algorithm w e hav e ch anged notation sligh tly t o make things more consis- ten t with that t ypical in reinforcemen t learning. Sp ecifically , w e hav e dropp ed the t sup er script as this is implicit in the algorithm sp ecification, and hav e defined Q ( s, a ) := V ( s,a ) , E ( s, a ) := E ( s,a ) and N ( s, a ) := N ( s,a ) . Our new reinforcemen t learning algorithm, whic h w e call HLS( λ ) is given in Algor it hm 1 . Essen tially the only c hanges to the standard Sarsa( λ ) algor ithm hav e b een to add co de to compute the visit counter N ( s, a ), add a lo op to compute the β v alues, and replace α with β in the temp ora l difference up date. T o test HLS( λ ) against standard Sarsa( λ ) w e used the Windy Gridworld en vi- ronmen t describ ed on page 146 of [SB98]. This world is a grid of 7 b y 10 squares that the agen t can mo v e through b y going either up, do wn, left of rig ht. If the ag ent attempts to mov e off the grid it simply stays where it is. The agent start s in the 4 th ro w of the 1 st column and receiv es a r eward of 1 when it finds its w ay to the 4 th ro w of the 8 th column. T o make thing s more difficult, there is a “wind” blo wing the 9 Algorithm 1 HLS( λ ) Initialise Q ( s, a ) = 0, N ( s, a ) = 1 and E ( s, a ) = 0 for all s , a Initialise s and a rep eat T ak e a ction a , observ ed r , s ′ Cho ose a ′ b y using ǫ -greedy selection on Q ( s ′ , · ) ∆ ← r + γ Q ( s ′ , a ′ ) − Q ( s, a ) E ( s, a ) ← E ( s, a ) + 1 N ( s, a ) ← N ( s, a ) + 1 for all s, a do β (( s, a ) , ( s ′ , a ′ )) ← 1 N ( s ′ ,a ′ ) − γ E ( s ′ ,a ′ ) N ( s ′ ,a ′ ) N ( s,a ) end for for all s, a do Q ( s, a ) ← Q ( s, a ) + β (( s, a ) , ( s ′ , a ′ )) E ( s, a )∆ E ( s, a ) ← γ λE ( s, a ) N ( s, a ) ← λN ( s, a ) end for s ← s ′ ; a ← a ′ un til end of run agen t up 1 row in columns 4, 5, 6, and 9 , and a strong wind of 2 in columns 7 and 8. This is illustrat ed in Figure 5. Unlik e in the or ig inal v ersion, w e hav e set up t his problem to b e a contin uing discoun ted task with a n automatic transition from the goal state back to the start state. W e set γ = 0 . 99 and in eac h run computed the empirical future discounted rew ard a t eac h p oin t in t ime. As this v alue oscillated we also ra n a mov ing a verage through t hese v alues with a windo w length of 50. Eac h run lasted for 50,000 t ime steps as t his a llow ed us to see a t what leve l eac h learning algorithm topp ed out. These results app ear in Figure 6 and we re av eraged ov er 500 runs to get accurate statistics. Despite putting considerable effort into tuning the para meters o f Sarsa( λ ), we w ere unable to achiev e a final future discoun ted rew a rd ab ov e 5 .0 . The settings sho wn on the graph represen t the b est final v alue w e could ac hiev e. In comparison HLS( λ ) easily b eat t his result at t he end of the run, while b eing sligh tly slow er than Sarsa( λ ) at the start. By setting λ = 0 . 99 w e w ere able to ac hiev e the same p erformance as Sarsa( λ ) at the start o f the run, how ev er the p erformance at the end of the run w as then only sligh tly b etter than Sa rsa( λ ). This com bination of sup erior p erformance and few er pa r a meters to tune suggest that the b enefits of HL( λ ) carry o ver in to the reinforcemen t learning setting. Another p opular reinforcemen t learning a lgorithm is W atkins’ Q( λ ). Similar to Sarsa( λ ) a b ov e, w e simply inserted t he HL( λ ) temp oral difference up da te into the usual Q( λ ) algorithm in the ob vious w ay . W e call this new alg orithm HLQ( λ )(not 10 Figure 5: [Windy Gridw o rld] S mar ks the start state and G the goal state, a t whic h the ag en t jumps back to S with a r eward of 1. 0 1 2 3 4 5 Time x1e+4 0 1 2 3 4 5 6 Future Discounted Reward HLS(0.995) e = 0.003 Sarsa(0.5) a = 0.4 e = 0.005 Figure 6: Sarsa( λ ) v s. HLS( λ ) in the Windy Gridworld. P erforma nce av eraged o ver 500 runs. On the gr a ph, e represen ts the exploratio n parameter ǫ , and a the learning rate α . sho wn). The test env ironmen t w as exactly the same as w e used with Sarsa( λ ) ab ov e. The results this time w ere more comp etitive (these results are not sho wn). Nev er- theless, despite sp ending a considerable amount of time fine tuning the parameters of Q( λ ), w e we re unable to b eat HLQ( λ ). As the p erfor mance adv antage w as relativ ely mo dest, the ma in b enefit of HLQ( λ ) was t hat it achiev ed this lev el of p erformance without ha ving to t une a learning rate. 7 Conclus ions W e hav e deriv ed a new equation fo r setting the learning rate in temp oral difference learning with eligibilit y traces. The equation r eplaces the free learning rat e parame- ter α , whic h is normally exp erimen tally tuned by hand. In ev ery setting tested, b e it stationary Mark o v c hains, non-stationary Mark o v c hains or reinforcemen t learning, our new metho d pro duced sup erior results. T o further our theoretical understanding, the next step w ould b e to try to pro ve that the metho d con ve rges to correct estimates. This can b e done for TD( λ ) under certain a ssumptions on how the learning rate decreases o ver time. Hop efully , some- thing similar can b e pro ven fo r our new metho d. In terms of exp erimental results, it w ould b e interesting to try differen t ty p es of reinforcemen t learning problems and to more clearly iden tify where the ability to set the learning rate differen tly fo r dif- feren t state transition pairs helps p erformance. It would a lso b e go o d to generalise the result to episo dic tasks. Finally , just as w e ha v e succes sfully merged HL( λ ) with Sarsa( λ ) and W atkins’ Q( λ ), w e would also lik e t o see if the same can b e done with P eng’s Q( λ ) [PW96], and p erhaps other reinforcemen t lear ning algorithms. 11 Ac kno wledgemen t s. This researc h w a s funded b y the Swiss NSF grant 2 00020- 107616. References [GP06] A. P . George and W. B. P o well . Adaptiv e stepsizes f or recursive estimation with app licatio ns in appro ximate dy n amic programming. Journa l of Machine L e arning , 65(1):16 7–198 , 2006. [LP03] M. G. Lagoudakis and R. P arr. Least-squares p olicy iteration. Journal of Ma- chine L e arning R ese ar ch , 4:1107–114 9, 2003. [PW96] J. Peng and R. J. Williams. I ncreamen tal multi-ste p Q-learning. Machine L e arn- ing , 22:283–2 90, 1996. [RN94] G . A. Rummery and M. Niranjan. On-line Q-learning using connectionist sys- tems. T ec h nial Rep ort CUED/F-INFENG/TR 166, En gineering Department, Cam b ridge Universit y , 1994. [Rum95] G. A. Rum mery . Pr oblem solving with r einfor c ement le arning . PhD thesis, Cam b ridge Universit y , 1995. [SB98] R. S utton and A. Barto. R einfor c ement le arning: A n intr o duction . C am br idge, MA, MIT Pr ess, 1998. [Sut88] R. S . S utton. Learning to p redict by the metho ds of temp oral differences. Ma- chine L e arning , 3:9–44, 1988. [W at8 9] C .J.C.H W atkins. L e arning fr om De laye d R ewar ds . PhD thesis, K ing’s College, Oxford, 1989. [Wit77] I. H. Witten. An adaptive optimal cont roller for discrete-time mark o v environ- men ts. Information and Contr ol , 34:286–29 5, 1977. 12
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment