하이드로사이클론 운영 분석을 위한 러프셋 이론 적용
** 본 논문은 하이드로사이클론 실험 데이터를 대상으로 자체 조직 지도(SOM)와 러프셋 이론(RST)을 결합한 SORST‑R 알고리즘을 제안한다. 먼저 SOM으로 데이터를 크리스프(명확)한 입자(granule)로 전처리하고, 그 결과를 기반으로 RST를 적용해 불확실성을 포함한 규칙을 추출한다. 추출된 규칙을 이용해 의사결정 속성을 근사적으로 예측하고, 기존의 SOM‑NFIS 기반 SONFIS와 비교하여 오류 감소와 규칙 간결성을 확인한다…
저자: H.Owladeghaffari, M.Ejtemaei, M.Irannajad
**
본 논문은 하이드로사이클론(Hydrocyclone)의 운전 성능을 데이터 기반으로 분석하기 위해 러프셋 이론(Rough Set Theory, RST)과 자기 조직 지도(Self‑Organizing Map, SOM)를 결합한 새로운 하이브리드 알고리즘을 제안한다. 연구 배경으로는 기존의 해석적·수치적·실험적 모델링이 복잡하고 비용이 많이 들며, 데이터의 불확실성(노이즈, 결측치 등)을 충분히 반영하지 못한다는 점을 들었다. 따라서 인공지능·데이터 마이닝 기법을 활용해 특징 선택과 불확실성 처리를 동시에 수행하는 방법이 필요하다고 주장한다.
논문은 먼저 정보 입자화(Granulation) 이론을 소개하고, 인간이 정보를 ‘입자’ 형태로 인지하는 심리적 메커니즘을 모방해 두 단계의 입자화를 설계한다. 첫 번째 단계는 ‘크리스프 입자’(Crisp Granules)를 생성하는 것으로, SOM을 이용해 연속형 입력 변수를 3~5개의 이산 레벨(예: low, medium, high)로 변환한다. 이 과정은 데이터의 차원을 축소하고, 동등 관계를 정의하기 위한 전처리 단계로서, 이후 러프셋 이론 적용에 필수적인 ‘동등 클래스’를 만든다.
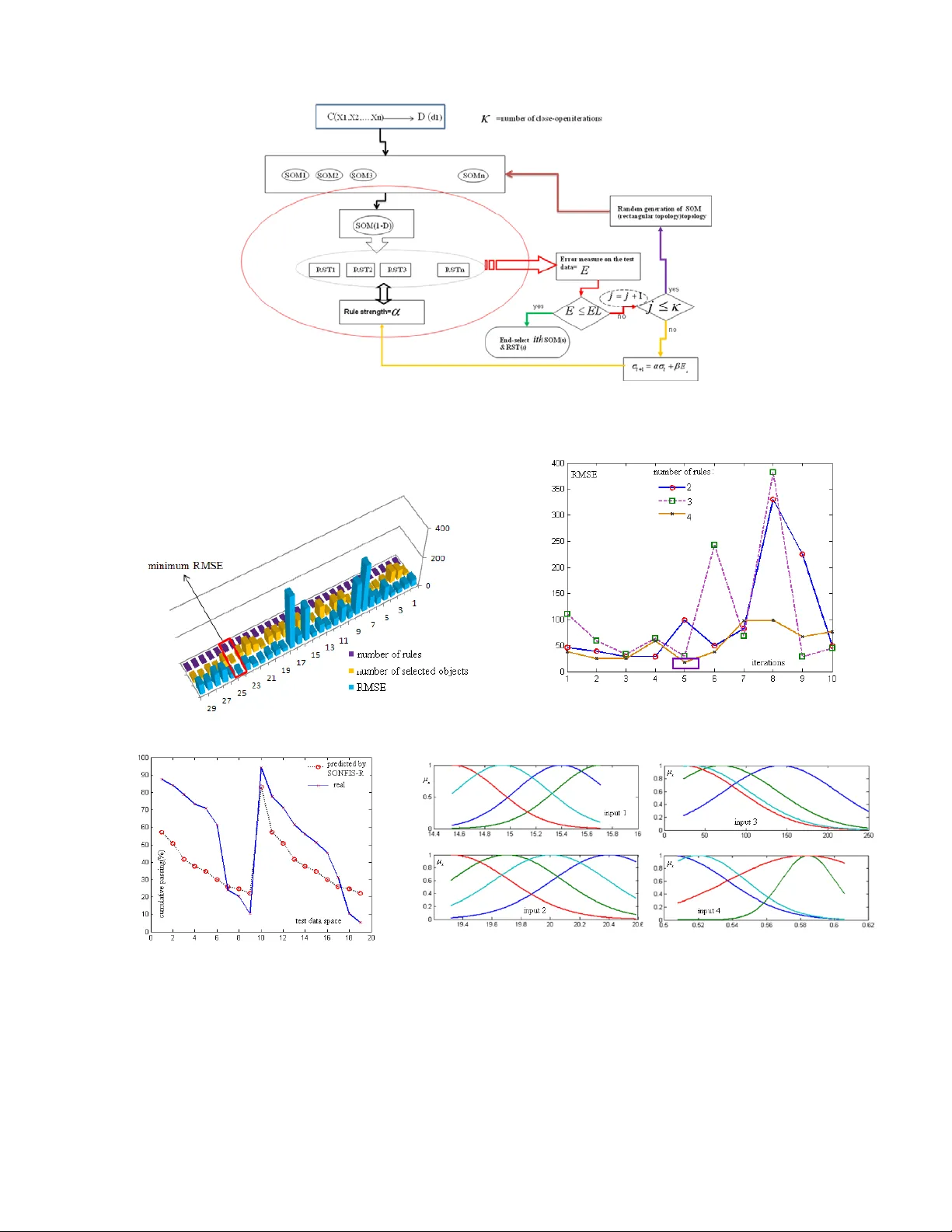
두 번째 단계에서는 전처리된 크리스프 입자를 바탕으로 러프셋 이론을 적용한다. RST는 하위 근사와 상위 근사를 통해 불확실성을 포괄적으로 모델링하며, ‘if‑then’ 규칙을 추출한다. 여기서 규칙은 단일 결정 클래스를 갖는 형태로 설계되어 해석이 직관적이다. 논문은 이 과정을 ‘SORST‑R’(Self‑Organizing Rough Set Theory‑Random)이라고 명명하고, SOM‑RST 결합 구조를 도식화하였다.
알고리즘 설계 시 ‘닫힌 세계 가정(CWA)’과 ‘열린 세계 가정(OWA)’를 교차 적용하는 ‘close‑open iteration’이 핵심이다. 초기 크리스프 입자는 CWA에 따라 완전 정보를 가정하고 생성하지만, 실제 데이터는 불완전하므로 OWA를 도입해 미인식 객체를 허용한다. 이 반복 과정에서 뉴런 수(NN)와 오류(E) 사이의 선형 관계식 NNₜ₊₁ = α·NNₜ + β·Eₜ + γ를 이용해 뉴런 성장과 오류 감소를 동시에 제어한다. 또한, 규칙 수, 오류 수준, 뉴런 성장 범위 등 세 가지 주요 파라미터를 조정해 최적 입자화 수준을 탐색한다.
실험에서는 하이드로사이클론 실험 데이터를 사용하였다. 학습 데이터는 150개, 테스트 데이터는 19개로 구성되었으며, 두 가지 알고리즘을 비교하였다. 첫 번째는 기존의 SOM‑NFIS 기반 SONFIS‑R(Regular)이며, 최대 10번의 close‑open 반복과 4개의 규칙을 제한하였다. 오류 평가지표는 RMSE이며, 최적 반복 시 RMSE가 0.03 수준으로 수렴하였다. 두 번째는 제안된 SORST‑R이며, 1‑D SOM(3 뉴런)으로 입력을 3단계 이산화하고, 7번의 무작위 SOM 구조 선택을 통해 평균 15개의 뉴런을 사용하였다. 오류 평가지표는 EM(정확도 기반)이며, 최저값은 4로 나타났다. 특히, 미인식 객체에 대해 고정값(4)을 부여함으로써 오류 변동성을 제어하고, 규칙이 단일 결정 클래스를 갖는 형태이므로 해석이 용이했다.
결과 분석에서는 SONFIS‑R이 규칙 수가 많아 복잡도가 증가하는 반면, SORST‑R은 규칙 수가 적고도 비슷하거나 더 낮은 오류를 보였음을 강조한다. 이는 SOM을 통한 효과적인 전처리와 RST의 불확실성 포괄 능력이 결합되어, 데이터의 핵심 패턴을 압축하면서도 중요한 정보를 손실하지 않기 때문이다. 또한, close‑open 반복을 통한 파라미터 자동 조정이 모델의 일반화 성능을 향상시켰다.
논문의 결론은 다음과 같다. (1) SOM 기반 전처리는 연속형 데이터를 효과적으로 이산화하여 러프셋 적용을 가능하게 한다. (2) RST를 이용한 규칙 추출은 불확실성을 명시적으로 다루면서도 해석 가능한 결과를 제공한다. (3) close‑open iteration은 CWA와 OWA를 균형 있게 적용해 모델 복잡도와 정확도 사이의 트레이드오프를 자동으로 최적화한다. 따라서 제안된 SORST‑R은 하이드로사이클론 운전 최적화뿐 아니라, 광산 처리 전반에 걸친 불확실성 높은 데이터 분석에 적용 가능한 실용적인 지식 발견 도구로 평가된다.
**
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기