Application of Rough Set Theory to Analysis of Hydrocyclone Operation
This paper describes application of rough set theory, on the analysis of hydrocyclone operation. In this manner, using Self Organizing Map (SOM) as preprocessing step, best crisp granules of data are obtained. Then, using a combining of SOM and rough…
Authors: H.Owladeghaffari, M.Ejtemaei, M.Irannajad
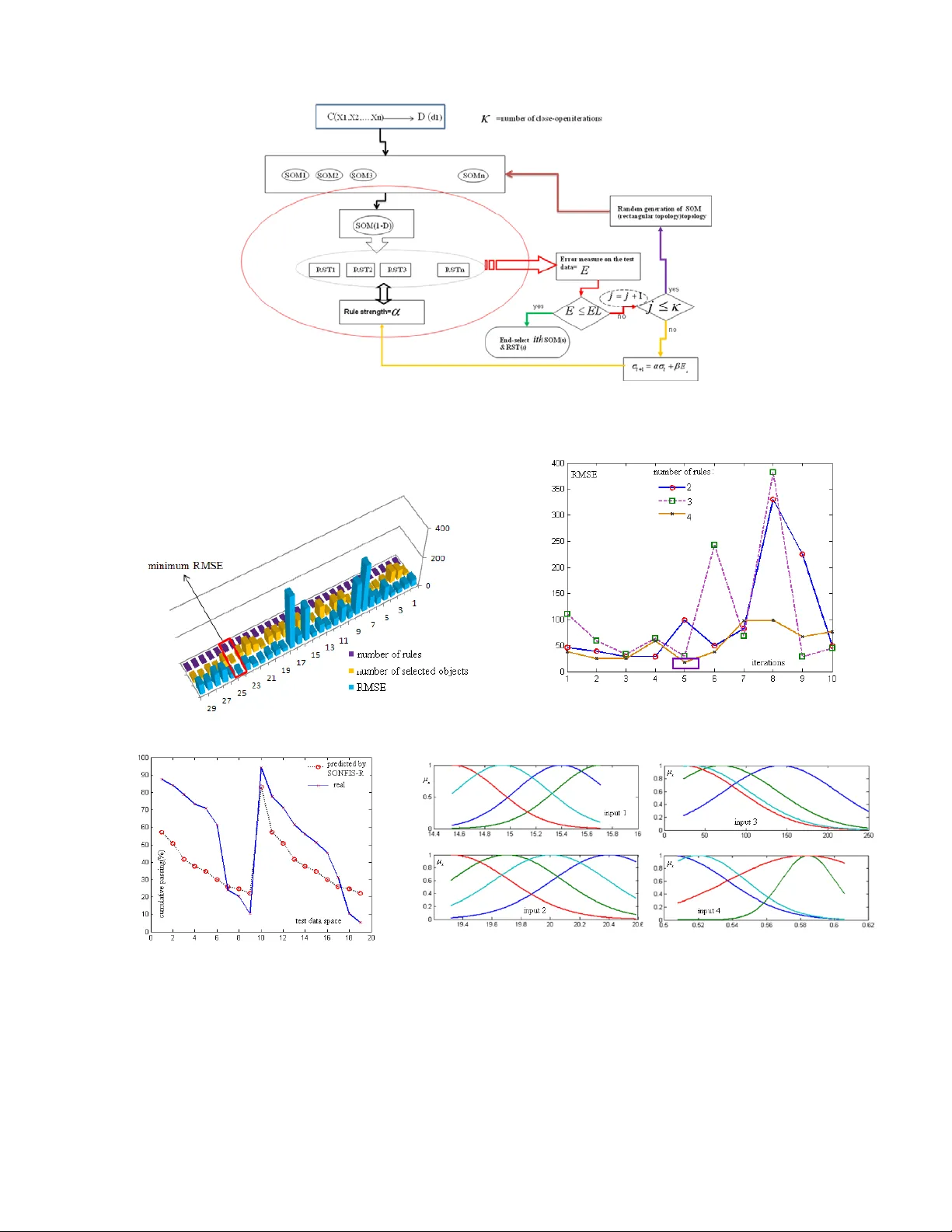
Application of Rough Set Th eory to Analysis of Hy drocyclone Operation H.Owladeghaffari, M.Ejte maei&M.Irannajad Department of Minin g&Metulrgica l Engineering, Amirk abir University of Tec hnology, Tehran, Iran Outline : This paper describes application of rough set theory, on the analy sis of hydrocyclone operation. In this manner, using Self Orga nizing Map (SOM) as preprocessing step, best crisp granules of data are obtained. Then, using a combining of SO M and rough set theory (RST)-called SORST-, the dominant rules on th e informati on table, obtained from laboratory tests, are extracted. Based on these rules, an approxi mate estimation on decision attribute is fulfilled. Finally, a brief comparison of th is method with the SOM-NFIS system (briefly SONFIS) is highlighted. A brief introuduction: In the design of m ineral processing cycle, one of the m ost im portant issues is the selection of hydrocyclone in different parts of the site. However, prediction of hydrocyclone performance using direct or indirect m odeling faces wi th some difficulties. Apart from analytical, numerica l, or experim ental m odeling, m odeling based on i ntelligent systems c an be supposed as an excellent situation, which is ensued by data engineering, machine learning, and stochastic learning theorem s. With advancing and extensi on of intelligent knowledge discovery (Data mining), in different applied sciences, selec tion of best features, acc ounting of the uncetainty in the m onitored data, are the main challenges of the most sciences. Because of being the uncertainty feature of the monitored data, acc ounting of uncertainty approaches such probability, fuzzy set and rough set theories to knowledge acquisition, extraction of rules and prediction of unknown case s, have been distinguishe d, more than the past. The granulation of information theory [1] covers the m entioned approaches in two formats: cri sp inform ation granulation and fuzzy i nformation granulat ion. There are two reasons why we propose this concept to tackle uncertainty in the monitored mineral processing data. The first one is hum an instinct. As hum an beings, we have developed a granular view of the world. When describing a problem, we tend to shy away from num bers and use aggregates to ponder the quest ion inst ead. This is especially true when a problem involves incom plete, unce rtain, or vague inform ation. It m ay be som etim es difficult to differentiate distinct elements, and so one is force consider “informa tion granules (IG) which one collection of entiti es arranged t ogether due to their similarit y, functional adjacency, and indistinguishability. In this study, using three computational intelligence (CI) theories, neural networks, fuzzy inference system and rough set based on inform ation granulation theory, two algorithms to analyses of hydrocy clone data will be presented. In our m odels, self-organizing feature m ap, Neuro-Fuzzy Inference Sy stem and rough set are utilized to construct IGs. Details of our instruments can be fo llowed in [2], [3], [4]. Proposed algorithms: In the whole of our algorithms, we use four basic axio ms upon the balancing of the successive granul es: Step (1): dividing the monitored data into groups of training and testing data Step (2): first granulation (crisp) by SOM or other crisp granulation methods Step (2-1): selecting the level of granularity randomly or depend on the obtain ed error from the NFIS or RST (regular neuron gr owth) Step (2-2): construction of the granules (crisp). Step (3): second granulation (fuzzy or rough IGs) by NFIS or RST Step (3-1): crisp granules as a n ew data. Step (3-2): selecting the level of granularity; (Error level, number of rules, strength threshold...) Step (3-3): checking the suitability. (C lose-open iteration: referri ng to the real data and reinspect closed world) Step (3-4): construction of fuzzy/rough granules. Step (4): extraction of knowledge rules Selection of initial crisp granules ca n be supposed as “Close Worl d Assumption (CWA)” .But in many applications, the assump tion of complete information is not feasible, and only cannot be used. In such cases, an “Open World Assumption (OWA)’, where information not known by an agent is assumed to be unknown, is often accepted [5]. Balancing assumption is sat isfied by the close-open iteration s: this process is a guide line to balancing of crisp and sub fuzzy/rough granules by some ra ndom/regular selection of initial granules or other optimal structures and in crement of supporting rules (fuzzy partitions or increasing of lower /upper approximations ), gradually. The overall schematic of Self Organizing Neuro-Fuzzy Inference System -Rando m and Regular neuron growth-: SONFIS-R, SONFIS-AR; has been shown in figure1. In first regular granulation, we use a linear relation is given by: 1 ; tt t t t NN E α βγ + =+ ∆ ∆ = + Where 12 1 2 ;. t Nn n n n M i n =× − = is number of neurons in SOM; t E is the obtained error (measured error) from second granulation on the te st data and coefficients must be determined, depend on the used data set. Obviously, one can employ like manipulation in the rule (second granulation) generation part, i.e., number of rules. Determination of granulation level is controlled with three main parameters: range of neuron growth, number of rules and error level. Th e main benefit of this algo rithm is to looking for best structure and rules for two know n intelligent sy stem, while in independent situations each of them has some appropriate problems such: finding of sp urious patterns for the large da ta sets, extra-time training of NFIS or SOM. In second algorithm, apart from em ploying hard computing methods (hard granules), RST instead of NFIS has been propos ed (figure 2). Applying of SOM as a preprocessing step and discretization tool is second process. Cate gorization of attributes (inputs/outputs) is transferring of the attribute space to the symbolic appropriate attributes. In fact for continuous valued attributes, the feature space needs to be discretized for defining indiscernibilty relations and equivalence classe s. We discretize each featur e in to some levels by SOM, for example “low, medium, and high” for attribute “a”. Finer discretization may lead to better accuracy to recognizing of te st da ta but im poses the hi gher cost of a comp utatio nal load. Because of the generated rules by a rough s et are coarse and therefore need to be fine-tun ed, here, we have used the preprocessing step on data set to crisp granu lation by SOM (close world assumption). In fact, with referring to the instinct of the human, we understand that human being want to states the events in the best sim ple words, sentences, rules, functions and so forth. Undoubtedly, such granules while satisfies the mentio ned axiom that describ e the distinguished initial structure(s) of events or immature data sets. Second SOM, as well as close world assumption, gets such dominant structures on the r eal data. In other word, condensation of real world and co ncentration on this space is asso ciated with approxi mate analysis, such rough or fuzzy facets. Results : Analysis of first situ ation is started off by setting num ber of cl ose-op en ite ration a nd maximum number of rules e qual to 10 and 4 in SONFIS-R, respec tively. The error m easure criteria in SO NFIS are Root Mean S quare Error (RMSE), given as below: *2 1 () m ii i tt RMSE m = − = ∑ ; Where i t is output of SONFIS and * i t is real answer ; m is the nu mber of test data (test ob jects). In the rest of paper, let m=19 and number of training data set =150. F igures 3 indicate the results of the aforesaid system. The indicated position in figure 3a, b states minimum RMSE over the iterations. It is worth noting that upon this balancing criterion, we may loose the general do minant distribution on the data space. The performance of the obtined fyzzy rules on the test data has been portrayed in figure 4(a). So, the membership functions of each input can be compared by thr real training distribution (figure 4b). In employing of second algorithm (figure2), we use- -for in this case- only exact rules i.e., one decision class in right hand of an if-then rule . Figure 14 and 15 depict the scaling process by 1-D SOM (3 neurons) and the performance of SORST-R o ver 7 random selection of SOM structure, respectively . The applied Error measure is : 2 1 () m r ea l cla ssif i ed ii i dd EM m = − = ∑ ; It must be noticed that for unrecognizable objects in test data (elicited by rules) a fix value such 4 is ascribed. So for measure part when any object is not identified, 1 is attributed. This is main reason of such swing o f EM in reduced data set 6 (figure 5-b). Clearly, in data set 5 SORST gains a lowest error (15 neurons in SOM). Figure 1. Se lf Organizing N euro-Fuzzy Inference System (SONFIS ) Figure 2. Self Organizing Rough S et Theory-Random neuron growth & adapt ive strength factor (SORS T-R) Figure3. obta nined results by SONF IS-R and the m inimum RMSE in 30 iteration -10 for each rule Figure4.a)the re al and predic ted decision on the test ing data set with sub-fuzz y granulati on; b) fuzzy gra nulation of inputs ;verti cal axises are meme bership degree( x µ )of any input. (a) (b ) (a) (a) (b) Figure 5. SO RST-R results on the Hydroc yclon data se t: a) strength fact or convergence (approximately); b) error measure variations along stren gth factor updati ng and c) 3-D column perspective of error measure- size of red uced ob jects Reference [ 1] L. A.Zadeh, “ Toward a theory o f fuzzy inform ation gran ulation an d its central ity in human Reasoning and fuzzy logic .Fuzzy sets an d systems 90”, P p:111-127,(199 7). [2] T.Kohonen, “ Self-organiz ation an d associate me mory ”, 2nd ed n. Springer – V erlag, Berlin,1987. [3] J.Jang and S . R., Sun, C. T and E.Mizutani, “ Neuro-fuzzy and soft c omputin g ”, Newjersy, Pr entice Hall, 1997. [4] P.Doherty and J.Kachn iarz and A.Szatas, “ Using contextually c losed queries for l ocal close d-world reasoning in roug h knowledge data base ” , In rou gh-neural com puting tec hniques for comparing with words, eds. Pal, S. K., Polkowski, L., Skowron, A., Pp. 219-250, (2004). [5] Pawlak, Z.1991. Rough S ets: Theoretica l Aspects Reas oning abou t Data . Kluwer academic, Boston. (a) (b) (c)
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment