예시 기반 모델링과 과신 측정으로 스프레드시트 위험 감소
본 논문은 전통적인 수식 작성 방식과 예시 기반 모델링(EDM)을 비교 실험을 통해 오류율과 과신 정도를 측정한다. 57명의 대학생을 대상으로 5단계 과제 수행 후 실제 정확도와 자기 평가를 비교하고, Halstead 복잡도와 새로운 ‘과신 비율’ 지표를 적용한다. 결과는 EDM이 복잡도가 증가할수록 오류가 현저히 감소하고, 과신 수준도 낮아진다는 점을 보여준다.
저자: Simon Thorne, David Ball, Zoe Lawson
본 논문은 스프레드시트 모델링에서 발생하는 오류가 조직의 전략적 의사결정에 미치는 위험성을 인간 인지 요인과 연결시켜 새로운 해결책을 모색한다. 기존 연구는 주로 오류 탐지 도구나 사후 검증에 초점을 맞추었지만, 저자들은 ‘예시 기반 모델링(Example‑Driven Modelling, EDM)’이라는 전혀 다른 접근법을 제안한다. EDM은 사용자가 직접 복잡한 수식을 작성하는 대신, 문제 상황에 맞는 예시 데이터를 제공하도록 요구한다. 이는 인간이 예시와 패턴 매칭에 뛰어나며, 수학적 연산보다는 사례 기반 학습에 더 적합하다는 인지심리학적 근거에 기반한다.
연구는 57명의 대학생(학부·석사)들을 대상으로 두 가지 모델링 방식을 비교 실험했다. 실험은 Campbell‑Stanley(1963)의 quasi‑experimental 설계를 차용했으며, 참가자를 무작위로 전통적 수식 작성 그룹과 EDM 그룹에 배정하였다. 각 참가자는 5개의 과제를 순차적으로 수행했으며, 과제 난이도는 점진적으로 상승했다. 첫 번째 과제는 ‘합격/불합격’ 판정 수식 작성, 마지막 과제는 4단계 등급(Fail, Pass, Merit, Distinction)까지 구분하는 복합 수식 작성이었다.
전통적 그룹은 주어진 문제에 대해 직접 Excel 수식을 작성했고, EDM 그룹은 동일한 문제에 대해 각 등급에 해당하는 예시 데이터를 제공했다. 과제 수행 후에는 ‘자기 평가 정확도’와 ‘자신감·난이도 인식’ 설문을 통해 과신(over‑confidence)을 측정하였다.
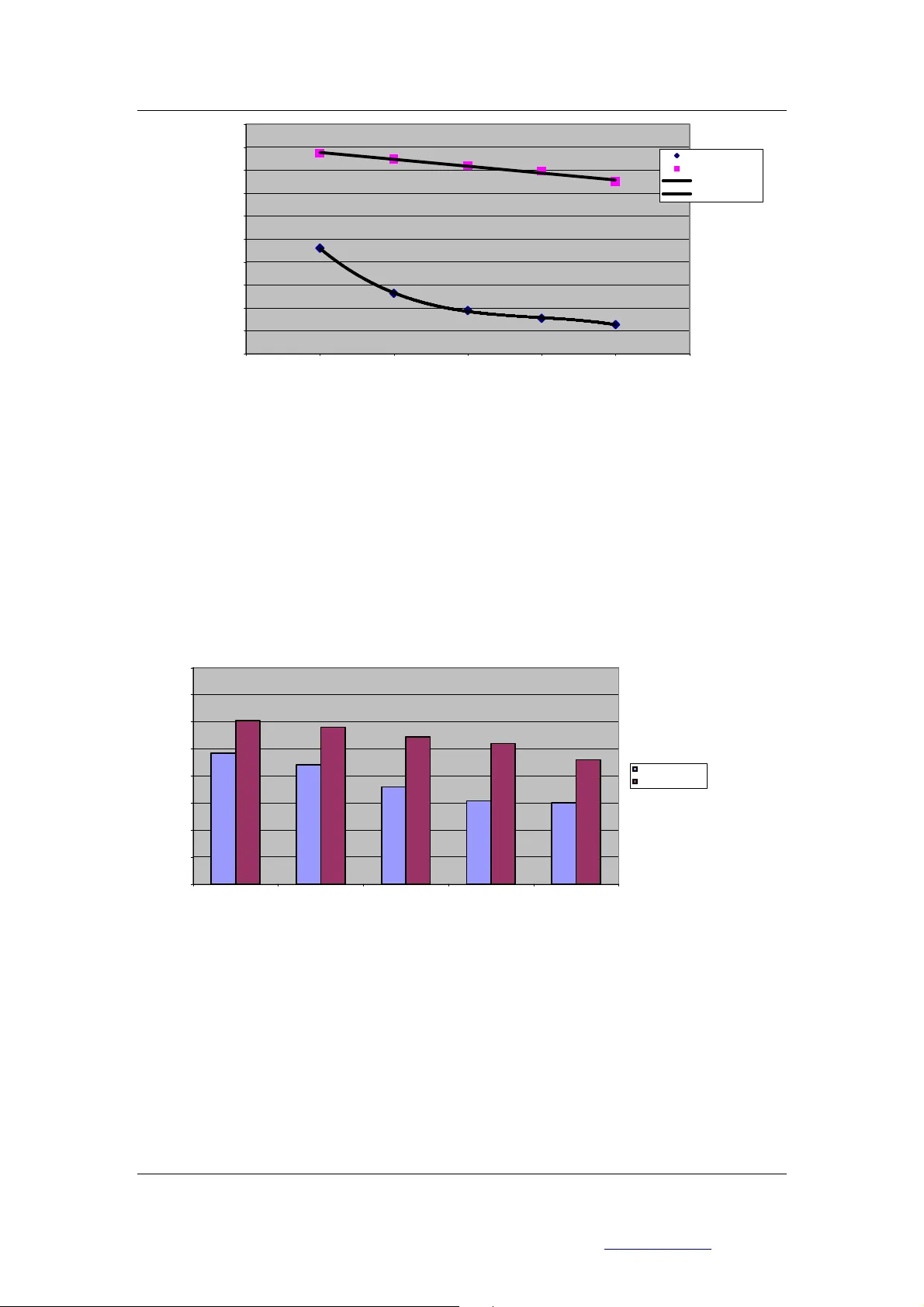
오류 측정은 두 가지 기준으로 이루어졌다. 전통적 수식 작성에서는 생성된 수식이 구문적으로 올바르고 셀 참조가 정확한지를 검증했으며, 필요 시 실제 데이터가 입력된 워크시트에 삽입해 결과를 확인하였다. EDM에서는 제공된 예시 데이터가 사전에 정의된 모델에 삽입될 때 정상적으로 동작하는지를 확인하였다. 오류 비율은 Panko(1998)의 ‘모델당 오류 비율(percentage of models with errors)’을 차용했으며, 복잡도 평가는 Halstead 복잡도 공식을 적용해 연산자·피연산자 수를 기반으로 산출하였다. Halstead 복잡도는 0에 가까울수록 복잡하고, 2에 가까울수록 단순하다고 정의하였다.
과신 측정은 기존에 확립된 통계적 지표가 없다는 점을 감안해 새롭게 ‘과신 비율(overconfidence ratio)’을 정의했다. 설문에서 얻은 자신감 점수(1‑5)와 난이도 인식 점수(1‑5)를 각각 0.5의 가중치로 합산해 ‘결합 과신(combined overconfidence)’을 구하고, 실제 오류 수 X에 따라 점수 F(X)를 매핑하였다(F(0)=5, F(1)=4, F(2)=3, F(3)=2, F(≥4)=1, 미응답은 0). 최종 비율은 (결합 과신 ÷ F(X)) 로 계산되며, 1에 가까울수록 자기 평가와 실제 성과가 일치함을 의미한다.
실험 결과는 두 모델링 방식 사이에 명확한 차이를 보여준다. 전통적 수식 작성 그룹에서는 과제 난이도가 상승함에 따라 오류 비율이 급격히 증가했으며, 과제 5에서는 약 45%의 모델이 오류를 포함했다. 과신 비율 역시 1.3‑1.8 사이로, 참가자들이 자신의 정확도를 과대평가하는 경향이 뚜렷했다. 반면 EDM 그룹은 복잡도 증가에도 불구하고 오류 비율이 10% 이하로 유지됐으며, 과신 비율은 0.8‑1.1 사이에 머물렀다. 이는 EDM이 인지 부하를 감소시키고, 사용자가 자신의 능력을 보다 현실적으로 인식하도록 돕는 효과가 있음을 시사한다.
논문은 또한 Halstead 복잡도와 오류율, 과신 비율 간의 상관관계를 분석했다. 전통적 그룹에서는 복잡도와 오류율 사이에 강한 양의 상관관계(r≈0.78)가 나타났으며, 과신 비율 역시 복잡도와 양의 상관관계를 보였다. EDM 그룹에서는 이러한 상관관계가 현저히 약해(r≈0.22) 실제 복잡도가 높아도 오류 발생이 크게 증가하지 않음을 확인했다.
연구의 제한점으로는 첫째, 실험 대상이 대학생에 국한되어 있어 산업 현장의 전문가에게 일반화하기 어려울 수 있다. 둘째, 과제 수가 5개에 불과해 장기적인 학습 효과나 피로도 영향을 충분히 배제하지 못했다. 셋째, Halstead 복잡도는 전통적인 프로그래밍 코드에 최적화된 지표이므로, 스프레드시트 특유의 비정형 구조를 완전히 포착하지 못할 가능성이 있다.
향후 연구 방향으로는 다양한 직군·경험 수준을 포함한 대규모 현장 실험, 스프레드시트 특화 복잡도 메트릭 개발, 그리고 EDM을 실제 업무 프로세스에 통합한 장기 효과 분석이 제시된다.
결론적으로, 본 논문은 ‘예시 기반 모델링’이라는 새로운 인간‑컴퓨터 상호작용 방식을 제시하고, 과신을 정량화하는 새로운 메트릭을 도입함으로써 스프레드시트 오류 감소와 의사결정 품질 향상에 기여할 수 있음을 실증적으로 보여준다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기