MiroEval: Benchmarking Multimodal Deep Research Agents in Process and Outcome
Recent progress in deep research systems has been impressive, but evaluation still lags behind real user needs. Existing benchmarks predominantly assess final reports using fixed rubrics, failing to evaluate the underlying research process. Most also…
Authors: Fangda Ye, Yuxin Hu, Pengxiang Zhu
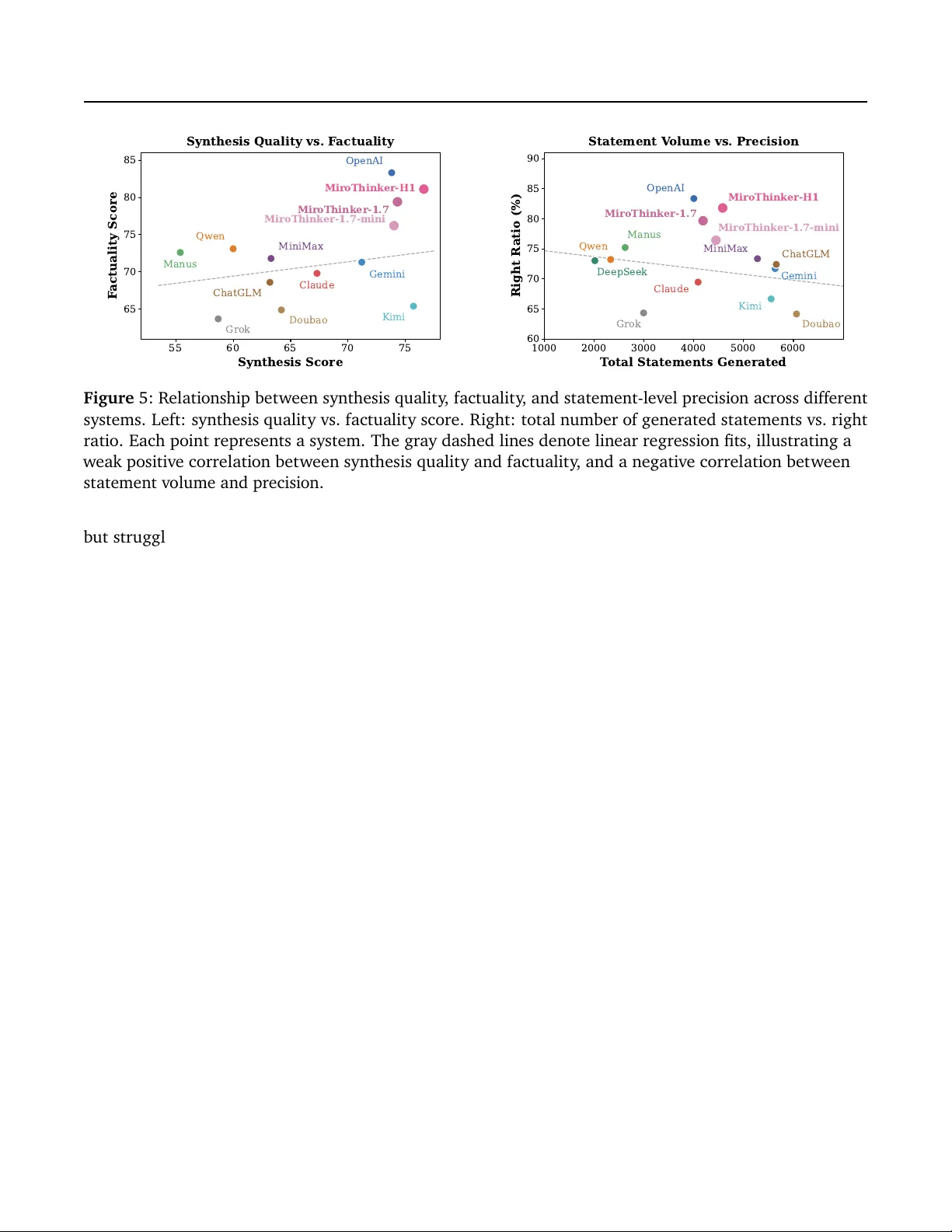
MiroE va l: Ben chmarking Multim oda l Deep R esearch Agents in Process and Outcome MiroMind T eam R ecent progress in deep research systems has been impressiv e, b ut evaluati on still lags behind real user needs. Existing benchmarks predominantly assess final reports using fixed rubrics, f ailing to evaluate the underlying research process. Most also off er limited multim oda l cov erage, rely on synthetic t as ks that do not reflect real- w orld query complexity , and cannot be refreshed as kno wledge ev olves. T o address these gaps, we introdu ce MiroEv al , a benchmark and evaluatio n framework for deep research systems. The benchmark comprises 100 tasks (70 text-only , 30 multim odal), all grounded in real user needs and constructed via a dual-path pipeline that supports periodi c updates, enab ling a live and evolving setting. The proposed eva luation suite assesses deep research systems along three complementary dimensio ns: adapti ve synthesis qu a lit y evaluati on with task-specifi c rubrics, a gentic factu a lit y verifi cation via activ e retriev al and reasoning o ver both w eb sources and m ultimoda l att achments, and process-centric evaluatio n audits ho w the system searches, reasons, and refines throughout its inv estigation. Eva luation across 13 systems yields three principal findings: the three evaluatio n dimensio ns capture complementary aspects of system capa bilit y , with each revealing distinct strengths and w eaknesses across systems; process qualit y serves as a reliab le predictor of ov era ll outcome while revea ling w eaknesses invisib le to output-lev el metrics; and multim odal t a sks pose substantially greater challenges, with m ost systems declining by 3 to 10 points. The MiroThinker series achiev es the mo st balanced performan ce, with MiroThinker-H1 ranking the highest o vera ll in both settings. Human verificati on by three expert annotators confirms benchmark qualit y at 92.0% precisio n. Extensiv e rob ustness experiments and a human ranking study (Kenda ll’s τ = 0.91) f urther confirm the reliabilit y of the evaluatio n framework. MiroE va l pro vides a holistic diagn osti c tool for the next generation of deep research agents. Blog Post : https://miroeval-ai.github.i o/bl og/ Project P age : https://miroeva l-ai.github.io/w ebsite/ GitHub : https://github.com/MiroMindAI/MiroEv al 50 60 70 80 Manus Gr ok Qwen ChatGLM MiniMax Doubao Claude Gemini OpenAI v1.7-mini v1.7 Kimi H1 55.4 58.7 60.0 63.2 63.3 64.2 67.3 71.2 73.8 74.0 74.3 75.7 76.7 (a) Synthesis Quality 55 65 75 85 Gr ok Doubao Kimi ChatGLM Claude Gemini MiniMax Manus Qwen v1.7-mini v1.7 H1 OpenAI 63.7 64.9 65.4 68.6 69.8 71.3 71.8 72.6 73.1 76.2 79.4 81.1 83.3 (b) Factual Accuracy 45 55 65 75 Doubao Gr ok Qwen Kimi Manus ChatGLM Claude Gemini MiniMax v1.7-mini v1.7 OpenAI H1 53.1 58.3 61.1 64.2 64.2 65.6 66.0 67.1 67.1 68.5 72.7 73.1 74.7 (c) Pr ocess Quality H1 = Mir oThinker -H1 v1.7 = Mir oThinker -1.7 v1.7-mini = Mir oThinker -1.7-mini Figure 1: Model performance comparison on 70 text-only deep research t as ks across three dimensions. MiroEva l: Benchmarking Multimoda l Deep Research Agents in Process and Outcome 1. Introd ucti on The rapid advancement o f L arge L angua ge Models (LLMs) has driven a pivotal transition from passi ve text generati on to agentic systems capa b le of auton om ous pl anning and execution [ 1 – 4 ]. Deep research, broad ly defined as the auton om ous, m ulti-step process of inv estigating complex inf ormation needs through iterativ e search, evidence gathering, verifi catio n, and synthesis [ 5 – 7 ], has become a prominent agenti c paradigm in this transition. Deep research systems [ 8 – 12 ] operationalize this paradigm by integrating planning, tool use, heterogeneou s source interaction, and long-f orm report generatio n into a unified workfl ow . As these systems are increa singly adopted in high-st akes domains such as fin ance, healthcare, and legal an a lysis, users demand more than a fluent final report: they need answers that are factu ally reli a bl e, grounded in thorough and traceab le investigati on, and capa b le of incorporating multim oda l materials (ima ges, PDF s, spreadsheets) that real-w orld research queries often inv olve. Meeting these demands requires continued improv ement of deep research systems, which in turn requires reliab le ways to measure whether a system truly condu cts thorough, f actually grounded inv estigatio n or merely prod uces a pl ausib le-l ooking report. Existing benchmarks hav e made va luab le progress in this directio n [ 13 – 15 ], but cov era ge in severa l area s remains limited. In particular , the majorit y of existing benchmarks eva luate only the final report, without assessing the underlying research process that produ ced it [ 14 , 16 , 17 ]. Multimoda l evaluati on is rarely supported beyond short-form Q A, despite the prevalen ce of m ultimoda l queri es in real-w orld usa ge [ 18 – 21 ]. T ask constructi on often relies on synthetic or academic queri es that do not f ully capture the complexit y o f authentic user needs [ 17 , 22 , 23 ], and st atic benchmarks risk becoming st a le as the informati on landscape evolv es [ 24 , 25 ]. T o address these chall enges, w e introdu ce MiroEva l , a benchmark and eva luation framework f or deep research systems. The benchmark comprises 100 t as ks (70 text-only , 30 multim oda l), all grounded in real user needs and constructed through t w o complementary paths (§ 2 ). The first path curates 65 queries (35 text-only and 30 multim odal) by rewriting authentic user patterns with privacy-preserving anonymization and difficult y stratificatio n. The second path generates 35 text-only queries via an automated pipeline grounded in real-time web trends and validated through a three-st a ge filtering process to ensure research necessit y . Since both paths are driven by analyzab le and refreshab le dat a sources, they can be periodica lly re-executed to keep the benchmark temporally relevant. The evaluati on suite assesses systems through three complementary l a yers. Comprehensiv e Adapti ve S ynthesis Q ualit y Eva luation (§ 3.1 ) dyn amica lly generates t ask-s pecific rubrics and import an ce weights to assess the final report, mo ving bey ond fixed criteria to capture domain-specifi c nuances. Agentic F actu ality Ev aluatio n (§ 3.2 ) decomposes reports into atomi c cl aims and employs an evaluatio n agent to v erif y them a gainst both liv e web sources and multim odal att achments, utili zing a four-wa y consistency assessment: RIGHT , WRONG , CONFLICT , or UNKNOWN . Process-Centric Ev aluatio n (§ 3.3 ) audits research trajectories across fiv e intrinsic dimensions—search breadth, analytica l depth, progressive refinement, critical thinking, and efficien cy—while measuring bidirectional alignment bet ween process findings and the fin al report (Process → R eport and R eport → Process) alo ngside contradi ctio n detectio n, to identif y traceabilit y gaps. All three l ayers nativ ely support m ultimoda l inputs, enab ling a holistic diagn osti c o f the next generati on of deep research agents. Ev aluatio n across 13 leading systems (§ 4 ) yields three principal findings. First, system rankings shift substanti a lly across synthesis qualit y , f actual precision, and research process rigor , demo nstrating that each dimension provides no n-redundant informati on. Second, process qualit y serves as a reliab le predictor o f ov era ll outcome while also revea ling wea knesses invisib le to output-lev el metrics, such as insufficient 2 MiroEva l: Benchmarking Multimoda l Deep Research Agents in Process and Outcome (a) User -Derive d Query Curation (b ) Automated Query Generation Real User Queries Text / Doc / PDF / Image Filter ed Queries Privac y Filtering Entity Replace ment Feature - Driven Cla ssificati on Information Densit y Comple xity Attac hment Type Goal Adhere nce Repeti tion Avoida nce Planning Quali ty Search Quali ty Synthesis Quali ty Error Correc tion Multimodal Unders tandin g Feature - Balanced Strate gy Route r Material - Based Hard Co nstrai nt Norma lized Featur e Matching Quota - Based Defic it Bonu s [Easy] Usage Decay Strategy A: Basic Retri eval Difficul ty - Strat ified Re writing Strategy B: Mul ti - Source Synthesis Strategy C: Contradicti on Detection Strategy D: Error - Prem ise Detecti on Strategy F: Attachment - Centri c Strategy E: Text - Only Researc h [Medium] [Hard] [Hard] [Mid – Hard] [Easy – Mid] Quali ty Verif icati on Reject if Ind isting uishabl e Ensures balanced 8 - feature coverage Factuali ty or 65 Rewri tten Queries ( 𝒬 !"# $% ) Seed Ex amples User Queri es 𝑄 !"#$ Regex Filter LLM Classi fy Sample 8 per topic Real - Ti me Web Tr ends via Serper API 12 Topics ✕ 3 subtopics LLM Gener ation 15 queries/topic 180 candidates 40 – 120 words 2 – 3 search rounds Diver se pers onas Search Valid ation Web Search Results ≥ 3 results from ≥ 2 source domains 180 → Search Validation ( 152 ) → DR Necessity ( 96 ) → Inverse Quality ( 50 ) → Manual Sele ction(35) Deep - Res earch Necess ity Fleiss’ κ ( validity) : 0.81 Three - St age Filte ring Inverse Quality Asses sment Step 1: Base line Answer Genera tion LLM answers with param etric k nowledge only Step 2:Ind ependent quali ty assessm ent Retain querie s with i nadequat e basel ine ( σ ≤ 0 .75) (c ) Benchmark Assembly and Verification 100 queries 65 𝒬 !"#$ % + 35 𝒬 &#' % 3 annotators Valid ity Non - triviality Fleiss’ κ ( non - triviality): 0.76 Overal l precision: 92.0% Requir es up - to - date, multi - source investigation LLM Eval T = 0.3, no retrieva l 2 Binary Crite ria Figure 2: Ov erview of query constructi on pipeline. analytica l depth and a significant traceabilit y gap bet ween reports and their underlying research procedures. Third, multim odal t asks pose subst antially greater challenges, with m ost systems declining by 3 to 10 points. Further an aly sis sho ws that user-derived queri es are consistently harder than auto-generated on es while system rankings remain st ab le across both sources (§ 4.5 ). Across all dimensions, the MiroThinker series dem onstrates the mo st balanced performance, with MiroThinker-H1 achieving the highest o vera ll scores in both text-only (77.5) and m ultimoda l (74.5) settings. Human verifi catio n by three expert annotators confirms benchmark qualit y at 92.0% precision (§ 2.4 ). Extensive robu stness experiments and a human ranking study (Kenda ll’s τ = 0.91) f urther confirm the reliabilit y o f the evaluati on framew ork (§ 4.5 ). 2. Query Collecti on and V erificatio n A reliab le benchmark for deep research systems must be grounded in real user needs while maint aining div ersit y and temporal relevan ce. W e constru ct a benchmark of 100 queries via t wo complementary paths (Figure 2 ): (1) curating 65 queries (35 text-only and 30 multim odal) inspired by real user query patterns obtained during a closed intern al testing phase, with privacy-preserving rewriting and difficult y stratificatio n (§ 2.2 ); and (2) generating 35 text-only queri es via an automated pipeline grounded in real-time web trends (§ 2.3 ). W e first present an o vervi ew of the resulting benchmark (§ 2.1 ), then describe each constructi on path, and fin a lly report qualit y verificati on results (§ 2.4 ). 2.1. Benchmark Overvi ew The fin a l benchmark comprises 100 queries: 70 text-only and 30 multim oda l (Figure 3 ). Domain Cov erage. Queries span 12 domains reflecting the breadth o f real-w orld deep research needs. T echnology (20) and Finance (17) are the mo st represented, follo w ed by Science (13). Eight mid-frequency 3 MiroEva l: Benchmarking Multimoda l Deep Research Agents in Process and Outcome 2 3 4 4 5 8 8 8 8 13 17 20 0 5 10 15 20 25 Education Lifestyle Cybersecurity Humanities Legal Policy Business Medical Engineering Science Finance T ech Document Editing 3 Code Generation 3 Data Analysis & Computation 5 Trend & Forecast 7 Survey & Synthesis 1 1 Causal Explanation 1 1 Policy & Regulation Analysis 12 Fact Enumeration & V erification 15 Comparative Analysis 16 Decision & Recommendation 17 0 5 10 15 20 25 EDT COD DA T TRD SUR CAU POL ENM CMP DEC N=100 70 T ext · 30 Multimodal T ech 20 Finance 17 Science 13 Engineering 8 Medical 8 Business 8 Policy 8 Legal 5 Humanities 4 Cybersecurity 4 Lifestyle 3 Education 2 CMP 7 ENM 3 COD 3 DEC 2 CAU 2 SUR 2 POL 1 DEC 3 ENM 3 TRD 3 EDT 3 CAU 2 DA T 2 SUR 1 CMP 4 CAU 4 SUR 3 ENM 1 DA T 1 DEC 2 CAU 2 CMP 1 ENM 1 SUR 1 TRD 1 SUR 3 DEC 2 CMP 1 ENM 1 DA T 1 DEC 3 ENM 3 POL 2 POL 4 DEC 2 CMP 1 TRD 1 POL 5 ENM 2 CAU 1 SUR 1 CMP 2 DEC 1 TRD 1 DEC 1 ENM 1 DA T 1 DEC 1 TRD 1 Query Distribution Overview Number of Queries Number of Queries (a) Domain × T ask (b) Domain Distribution (c) T ask Distribution Figure 3: Overvi ew of the query distrib utio n. ( a) Joint distributi on o f 12 domains and 10 t as k t ypes. ( b) Domain distributi on. ( c) T ask t ype distributi on. N = 100 (70 text-only , 30 multim oda l). domains (Engineering, Medica l, Business, Poli cy , L egal, Humanities, Cybersecurit y , and Edu catio n) each contrib ute 2 to 8 queries, ensuring that eva luation is not dominated by a n arro w set of topics. T a s k Distributi on. W e annotate each query with one o f 10 t a sk t ypes that characterize the reasoning pattern required. The three m ost comm on t ypes are Decision & R ecommendatio n (17), Comparativ e An aly sis (16), and F act Enumerati on & V erificatio n (15), which together account for nearly half the benchmark. Policy & R egulation Analysis (12), Causal Expl anation (11), and Survey & Synthesis (11) form a second tier . The remaining fo ur t ypes (T rend & F orecast, Data An a lysis & Comput atio n, Code Generation, and Document Editing) cov er specialized research patterns at lo w er frequency . Cross-Distrib utio n. Figure 3 ( a) show s the joint distributi on o f domains and t ask t ypes. T ask t ypes are spread across domains rather than concentrated within any single on e: for example, Comparativ e An a lysis queri es appear in Finance, S cien ce, Engineering, and Policy , while Decisio n & Reco mmendatio n queries span T ech, Medica l, Business, and L egal. This cross-co vera ge ensures that the benchmark eva luates domain kno wledge and reaso ning capabiliti es jointly rather than in isolation. 2.2. U ser-Deriv ed Query Curatio n The first path draws on query patterns observed during a closed intern al testing phase o f the MiroMind deep research system, cov ering both text-only and m ultimoda l interactions with att achments (ima ges, PDF s, spreadsheets, slides). Import antly , no original user query appears in the benchmark in any form. The pipeline analyzes the distributi on and structura l characteristics o f intern a l testing queries, then produ ces entirely new benchmark queries that preserve the topic distrib ution, complexit y profil e, and moda lit y cov era ge of the original population while containing no user-identifiab le content. 4 MiroEva l: Benchmarking Multimoda l Deep Research Agents in Process and Outcome Privacy-Preserving Processing. Throughout the entire pipeline, all dat a hand ling foll ow s strict confi- dentialit y protocols: raw queries are processed only on access-controlled internal infrastru cture, and all LLMs used for filtering, classifi cation, and rewriting are internally deployed inst ances that do not trans- mit dat a to any external service. At the entry point, an automated filter rem ov es all queri es cont aining privacy-sensitiv e content ( personal communi catio ns, confidentia l documents, and private fin an cial records) based on rule-based and model-a ssisted filtering. F or retained queries, all named entities ( institutio ns, organiz ati ons, and individ uals) are repl aced with realistic substitutes of the same t ype and scale through an automated anonymizatio n pipeline, ensuring that identifiab le entities are systematica lly repl aced before entering subsequent st a ges. Classificati on and R outing. An LLM classifies each anonymized query al ong sev en dimensions: att achment t ype, inf ormatio n densit y , domain, complexit y , attachment role, rewrite potential, and a set of target eva luation features drawn from a t axon omy of 8 capabiliti es ( Appendix B ): goal ad herence , repetitio n av o idance , pl anning , search , report generatio n , f actualit y , error correction , and m ultimoda l underst anding . Based on this cl assifi catio n, each query is routed to on e of 6 rewriting strategies spanning three difficult y tiers ( E as y , M e d i u m , and H a r d ; T ab le 9 ). R outing incorporates four f actors: (1) hard constraints that exclude strategies incompatib le with the query’s att achment t ype; (2) feature matching that scores how w ell each strategy’s target capa bilities align with those of the query; (3) quota bon uses that up-w eight strategies cov ering underrepresented evaluatio n features; and (4) usage decay that penalizes frequently selected strategies to maint ain div ersit y . Difficult y-Stratified R ewriting. Each routed query is rewritten into a benchmark-ready inst ance by an LLM foll o wing the selected strategy . E a sy queries require basi c retrieva l with att achment comprehensi on; Medium queri es inv olv e multi-step reasoning across heterogeneous sources; Hard queri es demand contradicti on identificati on or erroneou s-premise detection. The resulting set o f 65 queries co vers all 8 evaluati on features with balanced represent ati on across difficult y tiers. 2.3. A utomated Query Generati on The second path prod uces 35 text-only queries through a f ully auto mated pipeline that draws on recurring patterns from user query distributi ons and grounds generatio n in current web trends, en ab ling both temporal relevan ce and on-demand refresh. Trend-Grounded Generati on. W e organi ze generati on around 12 topics, each with 3 subtopics ( Ap- pendix C ). F or each topic, we retriev e recent head lines and snippets via the Serper API as trend context. An LLM then generates 15 candidate queri es per topic, conditi oned on the topic description, trend context, and anonymized seed exempl ars drawn from a broader pool of real user queries. Each query is designed to require inv estigatio n from multiple distinct angles, draw on diverse source t ypes, and adopt a specific persona ( e.g., an aly st, engineer , journalist, inv estor , or graduate student). This prod uces an initial pool of 180 candidates. Three-Stage Filtering. W e apply three filters to progressiv ely remo v e unsuit ab le candidates (T ab le 1 ). • Search validati on. Each candidate is submitted to a liv e web search. W e require ≥ 3 results from ≥ 2 distinct domains, rem oving queries that are too niche or ambiguo us. This ret ains 152 queries (84.4%). 5 MiroEva l: Benchmarking Multimoda l Deep Research Agents in Process and Outcome T abl e 1: Benchmark constructi on st atistics. User-deriv ed queri es are f ully rewritten from patterns ob- serv ed during intern al testing; auto-generated queri es are prod uced by trend-grounded generati on with three-stage filtering. Stage Count R etentio n U ser-Deriv ed P ath Internal testing patterns → rewritten queries 65 — A uto-Generated P ath T rend-grounded generati on 180 — + Search validati on 152 84.4% + Deep-research necessit y 96 63.2% + Inv erse qu ality assessment 50 52.1% + Manual selecti on 35 — Cum ulative from generatio n 19.4% Final benchmark 100 — • Deep-research necessit y . An LLM evaluates whether each query demands external sources and f urther inv estigati on bey ond parametric kno wledge. W e ret ain queries with necessit y confidence ≥ 0.7, yielding 96 queries (63.2%). • Inv erse qualit y assessment. The mo st discriminative filter t argets a key principle: effectiv e benchmark queri es should expose the limitations of parametric kno wledge. W e first elicit a baselin e answer without search access ( T = 0.3 ) using only parametric kno wledge, then assess this baseline in a separate call that pro- d uces three sign a ls: a continu ous qualit y score σ ∈ [ 0, 1 ] , a categorical label ℓ ∈ { low , medium , high } , and a bin ary requires_search flag. W e ret ain only queries where the baselin e is demonstra b ly in adequate: Q gen = { q | σ ( q ) ≤ 0.75 ∧ ℓ ( q ) = high ∧ requires_search ( q ) } . (1) The joint conditi on on all three signals provides robustn ess against boundary cases where any single indicator may be unreliab le. 35 queries are selected from the filtered pool as the fin a l auto-generated set. 2.4. Qualit y V erificatio n Assemb ly . The fin al benchmark combines 65 user-deriv ed and 35 auto-gen erated queries for a total of 100 (T ab le 1 ). Each query is annot ated with its source, a domain l abel from 12 categories ( Appendix C ), a t a sk t ype, and source-specifi c met adat a: feature vector and difficult y tier for user-derived queries; topic, necessit y confidence, and baseline qu a lit y for auto-gen erated queries. Human V erificatio n. W e validate the pipeline on a sample of queries from both sources. Three annotators with graduate-lev el research experience independently assess each query on t w o criteria: (1) va lidit y , i.e., whether the query constitutes a legitimate deep-research t ask, and (2) non-trivia lit y , i.e., whether it requires w eb search to answer adequ ately . As shown in T ab le 2 , both sources achieve subst antial inter-annotator a greement ( κ > 0.74 ) and precisio n abo v e 90%. T empora l R efres h. Both constru ction paths support periodic re-execution: the user-derived path can incorporate new rounds of user queri es as they become av ailabl e, while the auto-generated path can be refreshed at any time with the l atest web trends. This design prevents the benchmark from becoming st ale and redu ces the risk of ov erfitting to kno wn t asks. 6 MiroEva l: Benchmarking Multimoda l Deep Research Agents in Process and Outcome T ab le 2: Human verifi catio n results. Three annotators assess va lidit y and no n-trivialit y . Metric U ser-Derived A uto-Gen erated Fleiss’ κ (validity) 0.83 0.79 Fleiss’ κ (non-tri vialit y) 0.78 0.74 Majorit y-vote precision 94.0% 90.0% U nanimous agreement 86.0% 82.0% Aggregated Fleiss’ κ (validity) 0.81 Fleiss’ κ (non-tri vialit y) 0.76 Ov erall precision 92.0% 3. Ev aluati on Methodology T o pro vide a rigorous di a gno stic of deep research systems, the MiroEva l framework departs from traditio nal static benchmarks by est ab lishing a multi-layered, agentic evaluati on pipeline. Recognizing that a high-qu a lit y final report is only on e f acet of a successful inv estigatio n, our methodology decouples the research artif act from the underlying inv estigative procedure. W e introd uce an adaptiv e system that dyn amica lly constructs eva luation rubrics t ailored to the specific constraints and moda lities of each t as k. This approach allo ws for a holistic assessment across three critical dimensions: the synthesis qualit y of the fin al report, the factu a l grounding of cl aims against heterogeneo us evidence sources, and the structura l integrit y of the research trajectory itself . (a) Synthesis Quality Evaluat ion (b ) Agentic Factuality E valuation (c ) Process - Centric Evaluation Report Instruc tion Attach ment Text - only Queries Attachment - augmented Queries Key Facts Extract ion and Grounding Criteria LLM generate 1 – 3 expertise dimensions Groundin g Criteria Adapti ve Evalu ation Di mension S pace Coverage Insight Instructi on Following Clarity Task - Specif ic Expertise Precis e and A ttachmen t - specific Che ckpoints Dimensi on Weights Criterion W eights Information Acquisi tion Attach ment Key - Facts Verifiabl e Factua l Anchor s Groundin g Criteria Report Instructi on Attachment Statem ent 2 Statem ent 1 Statem ent 3 … Attachment Evidence Retrieval Native Mul timodal Processing …… Retrieval - Aug mented Processi ng Evidence Sear ching External Web Searc hing Task - Provide d Attachment s Evidence - ba sed Consist ency Asse ssment Wrong Correct Conflict Unverifiabl e Raw Proce ss Record Error Correction . Revision Planning Intermediate Synthesis Evidence Inspection Dependency Recover y Key Fin dings Discovery Critical Thinking Progre ssive Refineme nt Intrinsic Proc ess Quality Searc h Breadth Analyti cal Depth Efficiency Process Report Align ment Key Fin dings Coverage In Report Report Traceability t o Proce ss Contradiction Detection P→R R →P Specif icity Figure 4: Ov erview of the evaluati on pipeline. 3.1. Comprehensiv e Adapti ve Synthesis Qu a lit y Eva luation Deep research systems answ er complex research queries by performing multi-step retrieva l, reasoning, and synthesis to generate long-f orm, citation-backed reports. Since such t as ks vary subst antially in domain, 7 MiroEva l: Benchmarking Multimoda l Deep Research Agents in Process and Outcome objectiv es, and input m odalit y , fixed evaluati on dimensio n and criteri a cannot adequately capture synthesis qualit y . T o address this challenge, we propose a Comprehensiv e Adaptiv e Synthesis Qu ality Eva luation framew ork that dynamically tailors evaluatio n dimensions, criteria, and weights to each t as k. Queries may inv olv e heterogeneous inputs. In practice, they fall into t w o categories: (1) text-only queries , containing only n atural-langua ge instructio ns, and (2) attachment-augmented queries , where users additio nally pro vide multim oda l materials such as images, PD Fs, documents, or spreadsheets as supplementary context. The evaluatio n framework mu st theref ore hand le both categories and critica lly assess whether reports grounded in att achments faithf ully lev era ge the provided materi a ls. Adapti ve Eva luatio n Dimensio n Space. L et Q = ( I , A ) denote the input query , where I is the research instructi on and A is an optio nal set of att achments. F or each t a sk, the framework constructs a t ailored eva luation dimensio n space D = D fixed ∪ D dynamic ( Q ) . The fixed compon ent D fixed captures univ ersal as pects o f synthesis qualit y , such as Cov era ge, Insight, Instructio n-foll owing, and Clarit y . The dyn amic component D dynamic ( Q ) adapts to the specific characteristics of the query: • T ext-only queries ( A = ∅ ): the LLM generates 1–3 t a sk-specifi c expertise dimensions based solely on the instructi on I ( e.g., “Policy Pra gmatism” for a cross-national policy comparison). • Attachment-augmented queries ( A = ∅ ): the framework additio nally introdu ces a Grounding dimen- sio n, forming composite “Grounding & T as k-specific Expertise” dimensions. These dimensions require correct interpret ati on o f att achment content and meaningf ul analyti cal expansio n, while penalizing superficia l referencing or paraphrasing. Key F acts Extractio n and Grounding Criteria. F or att achment-augmented queries, an upstream mod ule extracts condensed key f acts from the raw att achments. This process distills heterogeneous materials ( e.g., tab les from spreadsheets, image capti ons, and structured text from PD Fs or documents) into a set o f verifia bl e factu a l anchors. These key f acts guide the generatio n of grounding criteria, transforming abstract eva luation requirements into precise and attachment-specific checkpoints. For example, given a t as k to “an alyze the globa l E V market” with an accompanying sal es spreadsheet, a context-free evaluator can only assess genera l criteria such as whether quantit ativ e an aly sis is used. Ho w ever , with extracted key f acts, the eva luator can generate concrete criteria su ch a s whether the report correctly identifies the inflecti on point where BYD surpassed T esla in 2023Q3. For text-only queries, evaluati on criteria are generated directly from the instructi on I . Dynamic W eighting and Scoring. Given the task-s pecific dimensio n space and criteria, the eva luator analyzes Q to derive dimension-l evel weights W d and criterion-l evel weights w d , c , subject to constraints d ∈ D W d = 1 and c w d , c = 1 , with explicit justificati on for each all ocatio n. The evaluator assesses the report R against each criterio n: s d , c = LLM θ ( R , d , c , Q ) , s d , c ∈ [ 0, 10 ] , (2) and the final qualit y score is computed as S qualit y = d ∈ D W d c w d , c s d , c . (3) 8 MiroEva l: Benchmarking Multimoda l Deep Research Agents in Process and Outcome 3.2. Agentic F actualit y Eva luation F actu ality evaluati on assesses whether claims in a generated report are supported by reliab le evidence. In deep research scen ario s, reports often contain numerous verifiab le st atements (such as qu antities, events, dates, locatio ns, or references to entities) that m ust be va lidated against av ail a bl e informati on sources. Unlike con venti ona l f act-checking settings that assume a single evidence source, real-w orld research t asks may inv olv e heterogeneo us evidence origin ating from both extern al web resources and t a sk-pro vided att achments. These sources may ev en provide conflicting con clusio ns, making traditional binary fact-checking insufficient. Drawing on DeepR esearchEv al [ 26 ], we design an agentic f actualit y eva luation framework based on MiroFlo w [ 27 ] that enab les an evaluati on agent to retriev e and reaso n o ver evidence from multipl e sources, foll o wing recent advances in long-f orm f actualit y verifi catio n with agenti c or multi-step reaso ning [ 28 – 30 ]. Given the query Q = ( I , A ) consisting of research instructio n I and att achments A and corresponding report R , the system first decomposes it into a set o f verifiab le st atements S ( Q , R ) = { s 1 , . . . , s n } . F or each st atement s ∈ S ( Q , R ) , the agent retriev es supporting or ref uting evidence from t w o complementary sources, forming an evidence set E ( s ) = E search ( s ) ∪ E attach ( s ) , where E search denotes evidence obtained from extern al search results and E attach denotes evidence retriev ed from task-pro vided att achments. Attachment Evidence R etrieva l. T o support f actual verifi catio n inv olving uploaded files, the eva luation framew ork provides a multim odal att achment querying tool that allo ws the eva luation agent to retrieve evidence from heterogeneo us file t ypes. The tool adopts a hybrid processing strategy to accomm odate the div erse formats encountered in realisti c research scen ari os. • Nativ e Multimoda l Processing. F or file formats that can be directly interpreted by multim odal language models ( e.g., images, PDF s, and pl ain-text documents), the att achment is passed to the model together with the query . The model can then reason directly ov er visu a l and structural informati on such as figures, t a bl es, and document l ay o uts without intermediate conv ersi on. • R etriev al-A ugmented Processing. F or formats that cannot be directly ingested by the extern al m odel ( e.g., spreadsheets, slides), the framew ork appli es a retrieva l-ba sed approach. The att achment is first con v erted into textual represent atio ns and segmented into smaller chunks. R elev ant segments are then retriev ed to answ er the query , en ab ling the agent to effici ently locate supporting evidence within l arge documents. T ogether , these mechanisms all ow the evaluati on agent to access and reaso n o ver informatio n contained in div erse att achments, en ab ling the benchmark to evaluate m ultimoda l f actual grounding in realisti c research scenarios where evidence may originate from both web sources and uploaded files. Eviden ce-based Consistency Assessment. The agent evaluates the consistency bet w een each st atement and its associated evidence set and assigns a f actualit y label y ( s ) ∈ { RIGHT , WRONG , CONFLICT , UNKNOWN } . The first three labels f ollo w st andard f act verifi catio n definitio ns. The additio nal label CONFLICT cap- tures cases where evidence from different sources leads to inconsistent conclu sions, explicitly representing disa greements bet ween heterogeneo us informati on sources rather than forcing them into bin ary judgments. 9 MiroEva l: Benchmarking Multimoda l Deep Research Agents in Process and Outcome 3.3. Process-Centric Eva luation While synthesis qualit y eva luation and factu a l verifi catio n a ssess the final research artif act, they do not directly eva luate the qualit y of the underlying research process. In deep research settings, how ev er , process qu a lit y is itself an import ant evaluatio n t arget. A system may produ ce a superficially strong report through redundant explorati on or brittle reaso ning, while another system may foll ow a m ore disciplined and inf ormativ e process whose intermediate results are only partially reflected in the final write-up. Motivated by this distinctio n, we introd uce a dedicated process-centric evaluatio n framew ork that focuses on how the system cond ucts the research procedure, rather than only on the final text it produ ces. Our framework is organiz ed into three compo nents: process representation, process qualit y eva luation, and alignment bet ween process-lev el key findings and report-lev el key findings. Process R epresent ati on. Giv en a raw process record P , w e first transform it into a structured process representation that supports downstream analysis. Since raw process logs are often no isy , verbo se, and heterogeneo us in form, direct evaluati on on the origin al text is unstab le and difficult to interpret. W e therefore decompo se the process into a sequence o f atomic units, where each unit correspo nds to one f uncti onally distinct step in the research proced ure, such as informati on acquisition, evidence inspection, intermediate synthesis, pl anning, revisio n, or error correctio n. Based on these units, we f urther recov er their loca l dependency structure and extract the key process findings that emerge during the research procedure. Importantly , this structured represent atio n is used only as an auxiliary analytica l interf ace: its purpose is to make the process more explicit and comparab le across tasks and systems, rather than to impose any strong assumpti on on the exact form of the process itself. Process Q ualit y Eva luation. Built on the structured represent ati on, we evaluate the intrinsic qualit y of the research process alo ng severa l complementary dimensions. • Search Breadth assesses whether the process explores a suffici ently wide range of sources, perspectiv es, and sub-topics relevant to the query . • Analytica l Depth measures whether the system goes beyond surf ace-lev el retrieva l to cond uct multi-step reaso ning, follo w-up inv estigati on, and in-depth analysis o f key findings. • Progressiv e Refin ement evaluates whether the system iteratively improv es its underst anding o ver the course o f the research, refining earlier conclusi ons as new evidence is gathered. • Critica l Thinking assesses the system’s abilit y to evaluate source reliabilit y , identif y limitations in retriev ed evidence, and respond appropriately to conflicting or wea k informati on. • Effici ency measures whether the research process av oids unnecessary redundan cy , including repeated queri es, circul ar exploratio n paths, and retrieved informatio n that is nev er utili zed. These dimensions are intended to characterize whether the system follo ws a produ ctiv e, no n-trivial, and self-correcti ve research process. U nlike report-lev el eva luation, this compon ent does not directly assess the fluen cy , st ylistic qualit y , or f actual correctness of the fin al report; instead, it focuses on whether the underlying process exhibits the procedura l properties expected from a well-co ndu cted deep research workflo w . Alignment Bet ween Process Findings and R eport Findings. Bey ond intrinsic process qualit y , w e f urther eva luate whether the final report f aithf ully reflects the subst antiv e findings developed during the research process. T o this end, we extract key findings from the process represent ati on and compare them against the key findings expressed in the final report. This alignment is examined in t w o directions and one cross-source consisten cy check. 10 MiroEva l: Benchmarking Multimoda l Deep Research Agents in Process and Outcome • Process → R eport ( P → R) checks whether the major findings estab lished d uring the process are adequately realized in the report. L o w P → R scores indicate that usef ul intermediate results are underutili zed or omitted d uring report synthesis. • R eport → Process ( R → P) checks whether the major conclusi ons st ated in the report can be linked back to sufficient support in the process. Low R → P scores indicate that the report ov erstates, introdu ces unsupported synthesis, or departs from the actu a l research procedure. • Contradicti on Detection ( C ontr) eva luates whether the system identifies and resolves conflicting evi- dence encountered across different sources during research, rather than silently ignoring or propagating inco nsistencies into the fin a l report. This compon ent is not intended to d uplicate f actual verifi cation; rather , it evaluates whether the report is proced urally grounded in the process that produ ced it, and whether the process itself hand les evidentiary confli cts responsib ly . Forma lly , given a process P and fin al report R , the ov erall process score is defined as S process = α S intrinsic ( P ) + ( 1 − α ) S align ( P , R ) , (4) where S intrinsic denotes the intrinsic process qu a lit y score and S align denotes the alignment score bet ween process findings and report findings. In this wa y , the proposed framework complements report-level qu ality and f actual evaluati on by explicitly measuring whether the system follo w ed a sound research procedure and whether the final deliv erab le remains f aithf ul to that proced ure. 4. Ev aluati on of Deep R esearch Sy stems 4.1. Experiment Setup W e cond uct eva luations on a range of mainstream commercial deep research systems, including OpenAI Deep R esearch [ 10 ], Gemini-3.1-Pro Deep Research [ 12 ], Grok Deep Research [ 31 ], Cl aude-Opus-4.6 Research [ 32 ], Manus-1.6-Max Wide Research [ 9 ], Doubao Deep Research [ 33 ], ChatGLM Agent [ 34 ], Kimi-K2.5 Deep R esearch [ 8 ], Qwen-3.5-Plu s Deep R esearch [ 35 ], and MiniMax-M2.5 R esearch [ 36 ]. W e f urther include three MiroThinker variants [ 37 ]: MiroThinker-1.7-mini, MiroThinker-1.7, and MiroThinker H1. F or Kimi-K2.5 Deep R esearch, Doubao Deep Research, and MiroThinker-1.7-mini, we report only text-only results, as these systems currently do not support m ultimoda l deep research. F or automatic evaluatio n, we use GPT -5.1 as the judge model for synthesis qu ality and GPT -5.2 for process evaluatio n, and GPT -5-mini for factu a lit y evaluati on. 4.2. Main R esults T ab le 3 presents the performance of all evaluated systems across Synthesis qu a lit y , F actu a lit y , and Process under both the T ext-O nly and MultiModal settings. Ov erall R esults. In the T ext-Only setting, systems separate into roughly three performan ce tiers. MiroThinker- H1, OpenAI Deep R esearch, and MiroThinker-1.7 f orm the top tier at 77.5, 76.7, and 75.5 respectively , with MiroThinker-1.7-mini close behind at 72.9. Gemini-3.1-Pro, Kimi-K2.5, MiniMax-M2.5, and ChatGLM Agent constitute a midd le tier , spanning approximately 66 to 70. A low er tier includes Manus-1.6-Max , Qw en-3.5-Plus, Claude-Opus-4.6, Doubao and Grok, all scoring below 65, with Grok trailing at 60.2. A broad ly similar grouping holds in the MultiModal setting, though ov era ll scores decrease by 3 to 10 points across systems and the inter-system gaps narrow . MiroThinker-H1 achiev es the highest MultiModal score at 74.5, follo w ed by MiroThinker-1.7 at 71.6 and OpenAI Deep R esearch at 70.2, indicating that these systems’ advantages generalize robustly bey ond text-only t a sks. 11 MiroEva l: Benchmarking Multimoda l Deep Research Agents in Process and Outcome T ab le 3: P erforman ce comparison of models with MiroEva l. Model T ext-Only MultiModal Overa ll Synthesis F actualit y Process Overa ll Synthesis F actualit y Process Overa ll Kimi-K2.5 Deep R esearch 75.7 65.4 64.2 68.4 – – – – – Doubao Deep Research 64.2 64.9 53.1 60.7 – – – – – Grok Deep R esearch 58.7 63.7 58.3 60.2 56.3 71.5 53.9 60.5 60.3 Qwen-3.5-P lus Deep R esearch 60.0 73.1 61.1 64.7 44.6 69.9 53.8 56.1 62.1 Manus-1.6-Max Wide R esearch 55.4 72.6 64.2 64.0 54.3 70.0 61.8 62.0 63.4 ChatGLM Agent 63.2 68.6 65.6 65.8 61.6 71.6 57.7 63.6 65.1 MiniMax-M2.5 Research 63.3 71.8 67.1 67.4 56.7 71.0 62.2 63.3 66.2 Claude-Opus-4.6 Research 67.3 69.8 66.0 67.7 62.5 70.7 65.9 66.4 67.3 Gemini-3.1-Pro Deep R esearch 71.2 71.3 67.1 69.9 66.4 73.7 64.1 68.1 69.3 OpenAI Deep R esearch 73.8 83.3 73.1 76.7 66.7 77.0 66.8 70.2 74.8 MiroThinker-1.7-mini 74.0 76.2 68.5 72.9 – – – – – MiroThinker-1.7 74.3 79.4 72.7 75.5 69.0 78.4 67.4 71.6 74.3 MiroThinker-H1 76.7 81.1 74.7 77.5 71.5 78.5 73.5 74.5 76.6 Key Findings. Beyo nd the ov erall ranking, three findings emerge from the dimension-lev el comparison. First, rankings s hift subst antially across evaluatio n dimensio ns across systems . Kimi-K2.5 achiev es the highest Synthesis score amo ng non-MiroThinker systems in the T ext-Only setting at 75.7, yet its F actu a lit y o f 65.4 ranks near the bottom, trailing OpenAI Deep R esearch by nearly 18 points on this axis. Conv ersely , Manu s-1.6-Max Wide R esearch obt ains the lo west Synthesis score at 55.4, yet its F actualit y of 72.6 surpasses sev eral systems with mu ch stronger reports, including Gemini-3.1-Pro and MiniMax-M2.5. These t wo cases, from opposite ends of the synthesis-qualit y spectrum, jointly illustrate that a polished report does not guarantee f actual grounding, nor does a factu a lly disciplined system necessarily prod uce w ell-structured output. W e inv estigate the sub-metric sources of this div ergence in § 4.3 . Second, process qualit y is broad ly predictiv e of outcome qu alit y . Across the T ext-Only setting, the top three systems on Process (MiroThinker- H1 at 74.7, OpenAI at 73.1, and MiroThinker-1.7 at 72.7) are also the top three on o vera ll outcome, and the wea kest process system, Doubao at 53.1, also produces a near-botto m outcome. While a small number o f systems devi ate from this trend, the ov era ll alignment suggests that process-level evaluati on captures a meaningf ul signal about final output qualit y . W e provide a det ailed an aly sis, including the rel ati onship bet ween process and individ ual outcome dimensio ns, in § 4.4 . Third, multim oda l t a s ks pose substanti ally greater challenges . Overa ll scores drop by 3 to 10 points for m ost systems when mo ving from the T ext-Only to the MultiModal setting, with the tier structure broad ly preserved b ut individ ual systems sho wing varying degrees of degradation. MiroThinker-H1 prov es the mo st resilient with a decline o f only 3.0 points, while Qw en-3.5-Plus suffers the largest drop at 8.6 points. A det ailed cross-setting comparison is provided in § 4.5 . Consistent Strength o f the MiroThinker Series. What distinguishes the MiroThinker series from other sys- tems is not dominance on any single dimensio n, but consistent competitiv eness across all three. MiroThinker- H1 achiev es the highest ov erall score in both the T ext-Only (77.5) and MultiModal (74.5) settings, ranking first or second on ev ery individua l dimension. MiroThinker-1.7 follo ws closely , ranking amo ng the top three on Synthesis, F actu a lit y , and Process with no significant wea kness on any axis. This balanced pro file contra sts with other top-performing systems that exhibit clear dimensio n-specific trade-o ffs: Kimi-K2.5 excels on Synthesis b ut l a gs on F actualit y , while OpenAI Deep R esearch leads on F actualit y but is surpassed on S ynthesis by m ultiple systems. Ev en MiroThinker-1.7-mini, a smaller variant, outperf orms the majorit y of 12 MiroEva l: Benchmarking Multimoda l Deep Research Agents in Process and Outcome T abl e 4: C ombin ed evaluati on on Synthesis qualit y and F actualit y . R eport is assessed across five dimen- sio ns ( Co vera ge, Insight, Instructi on-f ollo wing, Cl arit y , and Q uery Specificati on). F actu a lit y is measured by the av era ge right ratio (scaled to [ 0, 100 ] ). Overa ll is the av erage of Report A vg and F actu ality Ratio. T ext-Only comprises 70 t as ks and Multimoda l comprises 30 tasks. Model Synthesis F actualit y Overa ll Cov . Insight Instr . Cl arit y Spec. A vg Right Wro ng Conf . Unk. Ratio T ext-Only (70 T as ks) Grok Deep Research 67.3 56.3 74.9 64.7 51.1 58.7 1924 368 – 699 63.7 61.2 Manus-1.6-Max Wide R esearch 61.2 54.8 67.9 65.6 48.1 55.4 1972 191 – 459 72.6 64.0 Doubao Deep R esearch 72.9 62.7 74.6 67.2 58.2 64.2 3890 780 – 1393 64.9 64.6 ChatGLM Agent 69.9 62.8 74.5 67.5 57.1 63.2 4096 580 – 981 68.6 65.9 Qwen-3.5-P lus Deep R esearch 64.0 64.7 69.9 67.8 52.6 60.0 1706 244 – 380 73.1 66.5 MiniMax-M2.5 Research 69.8 62.7 74.2 70.6 56.7 63.3 3872 486 – 921 71.8 67.5 Claude-Opus-4.6 Research 73.3 72.0 73.5 71.2 61.1 67.3 2838 338 – 910 69.8 68.6 Kimi-K2.5 Deep Research 80.4 79.8 78.6 76.3 71.7 75.7 3702 595 – 1256 65.4 70.6 Gemini-3.1-Pro Deep Research 77.4 76.6 80.0 70.1 64.9 71.2 4039 526 – 1068 71.3 71.3 OpenAI Deep Research 78.2 74.3 81.6 77.1 69.1 73.8 3335 170 – 496 83.3 78.6 MiroThinker-1.7-mini 78.8 75.0 84.3 78.7 68.1 74.0 3397 246 – 802 76.2 75.1 MiroThinker-1.7 79.2 74.7 84.7 80.1 68.4 74.3 3334 181 – 670 79.4 76.9 MiroThinker-H1 80.6 80.3 84.7 81.0 70.0 76.7 3746 161 – 673 81.1 78.9 Multimoda l (30 T as ks) Qwen-3.5-P lus Deep R esearch 46.8 46.3 52.9 52.6 30.1 44.6 576 99 19 101 69.9 57.3 Manus-1.6-Max Wide R esearch 58.7 50.2 65.0 61.2 40.4 54.3 681 81 32 134 70.0 62.2 MiniMax-M2.5 Research 63.1 53.3 69.1 62.0 39.2 56.7 1255 184 59 255 71.0 63.8 Grok Deep Research 61.8 52.5 68.9 60.4 40.5 56.3 734 104 37 163 71.5 63.9 ChatGLM Agent 67.1 60.2 71.7 65.4 45.1 61.6 1038 144 46 215 71.6 66.6 Claude-Opus-4.6 Research 68.9 66.8 62.8 59.3 50.0 62.5 964 84 44 243 70.7 66.6 Gemini-3.1-Pro Deep Research 72.4 70.8 72.4 62.5 50.1 66.4 1502 158 94 302 73.7 70.0 OpenAI Deep Research 70.6 63.9 74.8 70.5 54.2 66.7 1062 100 36 157 77.0 71.8 MiroThinker-1.7 72.6 69.2 78.6 75.1 53.6 69.0 1306 103 63 235 78.4 73.7 MiroThinker-H1 72.7 76.0 78.6 78.3 59.5 71.5 1316 82 56 238 78.5 75.0 f ull-sca le systems ov era ll. In the follo wing sections, w e cond uct fine-grained an a lyses at the outcome level (§ 4.3 ) and the process lev el (§ 4.4 ) to inv estigate the sources o f these differences. 4.3. Outcome-Level An aly sis Having est ab lished that Synthesis qu a lit y and F actualit y are not interchangeab le (§ 4.2 ), we no w examine the sub-metric structure underlying each dimensio n to underst and where and why systems div erge. T ab le 4 presents the f ull breakdo wn. W e focu s primarily on the T ext-Only setting (70 t a sks) du e to its broader system co vera ge. S ynthesis Sub-Metrics: Specifi cit y is the Bottleneck, Insight is the Differentiator . Amo ng the fiv e S ynthesis sub-metrics, Specifi cit y emerges as the univ ersal bottleneck. It is the lo w est-scoring sub-metric for nearly ev ery system, trailing Cov era ge by 10 to 14 points: OpenAI Deep Research scores 78.2 on Cov era ge b ut only 69.1 on Specificit y , and Manus-1.6-Max Wide R esearch show s a simil ar gap o f 13.1 points. Ev en MiroThinker-H1, the strongest system on Synthesis at 76.7, still lags 10.6 points bet ween these t wo metrics. This consistent shortf a ll indicates that current systems can identif y relevant topics with reasonab l e breadth, 13 MiroEva l: Benchmarking Multimoda l Deep Research Agents in Process and Outcome 55 60 65 70 75 Synthesis Score 65 70 75 80 85 F actuality Score Synthesis Quality vs. F actuality Manus Grok Kimi Doubao Qwen Claude ChatGLM MiniMax Gemini OpenAI MiroThinker-1.7-mini MiroThinker-1.7 MiroThinker-H1 1000 2000 3000 4000 5000 6000 T otal Statements Generated 60 65 70 75 80 85 90 Right R atio (%) Statement V olume vs. Precision OpenAI MiroThinker-1.7 MiroThinker-1.7-mini Manus Claude Qwen DeepSeek MiniMax Gemini ChatGLM Kimi Doubao Grok MiroThinker-H1 Figure 5: Relati onship bet ween synthesis qualit y , f actualit y , and st atement-lev el precisio n across different systems. L eft: synthesis qualit y vs. f actualit y score. Right: total number of generated st atements vs. right ratio. Each point represents a system. The gray das hed lines denote linear regression fits, illustrating a w eak positiv e correl atio n bet ween synthesis qualit y and f actualit y , and a negativ e correlation bet ween statement volume and precisio n. b ut struggle to provide the granular , evidence-gro unded det ails that distinguish thorough research from surface-level summaries. Instructio n-follo wing, by contrast, is uniformly high among top systems and is no longer a meaningf ul differentiator . While Specificit y marks the shared wea kness, Insight is what mo st separates systems from one another . Scores range from 54.8 for Manus to 80.3 f or MiroThinker-H1, a 25-point spread that is substanti a lly wider than Cov era ge or Instructio n-foll o wing. This variance revea ls that the abilit y to synthesize non-obvi ous analytica l observatio ns, rather than merely aggregating retriev ed informati on, is the mo st discriminative report-writing capabilit y . Notab ly , severa l systems with moderate o vera ll performan ce, such as Gemini-3.1-Pro at 76.6 and Claude-Opus-4.6 at 72.0, score rel ativ ely well on Insight, suggesting analytica l strengths that are offset by w eaknesses in other dimensions. F actu al Cl aims: A Precisio n–V olume Trade-o ff . The F actualit y sub-metrics revea l a f undament a l tensio n bet ween how many cl aims a system generates and ho w often those claims are correct (Figure 5 ). At one extreme, ChatGLM Agent and Gemini-3.1-Pro produ ce ov er 4,000 correct claims each, b ut this high volume comes with 580 and 526 wrong cl aims respectiv ely , plus ov er 900 unv erifiab le ones, pulling their F actualit y Ratio s down to the lo w 70s. At the other extreme, OpenAI Deep R esearch generates few er correct cl aims at 3,335, but keeps wrong claims to just 170 and unv erifiab le claims to 496, achieving the highest per-t as k right Ratio of 83.3. These pro files reflect f undament a lly different generatio n strategies: broad claim co vera ge at the cost of precision versus selectiv e generatio n with strict f actual discipline. The MiroThinker series achiev es a distinctiv e balance bet ween these extremes. MiroThinker-H1 produ ces the highest claim v olume amo ng top-tier systems at 3,746 correct claims while maintaining only 161 wrong ones, the lo west absolute error count o f any system and a Ratio of 81.1. MiroThinker-1.7 follo ws a similar pattern with 3,334 correct and just 181 wrong claims, yielding a Ratio o f 79.4. Even MiroThinker-1.7-mini maint ains this discipline with 3,397 correct and 246 wrong claims. This consistency across model siz es suggests that the f actual discipline is architectural rather than solely a product of scal e. Connecting the T wo Dimensions: What Drives the Synthesis–F actualit y Misalignment? The sub-metric breakdo wns abo v e help expl ain the synthesis–f actualit y misalignment observed in § 4.2 . Kimi-K2.5, which achiev es the highest Synthesis Avg am ong no n-MiroThinker systems yet one o f the lo west F actu ality Ratios, 14 MiroEva l: Benchmarking Multimoda l Deep Research Agents in Process and Outcome T ab le 5: Process evaluati on results. Intrinsic metrics assess the qualit y of the research process itself across fiv e dimensions (Search Breadth, Analytica l Depth, Progressive Refin ement, Critical Thinking, and Effi- cien cy). Alignment metrics measure the consistency bet ween the research process and the fin a l report (Findings → R eport co vera ge, R eport → Process traceabilit y , and C ontradi ctio n detection). Overa ll is the w eighted av erage of Intrinsic A vg and Alignment A vg. Model Intrinsic Alignment Ov erall Brdth Depth R efin Critl Effi c Avg P → R R → P Contr A vg T ext-Only (70 T as ks) Doubao Deep R esearch 59.3 41.6 59.6 55.7 53.3 53.9 65.7 36.8 54.2 52.2 53.1 Grok Deep Research 50.9 49.4 61.0 54.6 64.7 56.1 74.6 42.2 64.6 60.4 58.3 Qw en-3.5-Plus Deep R esearch 74.4 64.1 75.0 74.1 63.2 70.2 59.6 39.7 56.9 52.1 61.1 Manus-1.6-Max Wide R esearch 62.8 58.4 60.6 53.5 68.8 60.8 75.1 51.3 76.3 67.6 64.2 Kimi-K2.5 Deep Research 77.5 59.4 71.0 67.6 53.5 65.8 70.7 46.8 70.4 62.6 64.2 ChatGLM Agent 76.2 59.4 67.1 59.3 59.0 64.2 77.1 51.4 72.3 67.0 65.6 Claude-Opus-4.6 R esearch 79.1 58.8 67.2 56.7 62.2 64.8 81.0 47.1 73.5 67.2 66.0 Gemini-3.1-Pro Deep Research 75.4 66.6 75.9 64.1 59.0 68.2 72.9 50.6 74.4 66.0 67.1 MiniMax-M2.5 R esearch 71.9 62.2 70.1 62.5 63.5 66.0 77.4 53.0 74.3 68.3 67.1 OpenAI Deep Research 77.4 67.3 76.7 74.7 63.7 72.0 83.6 59.0 79.9 74.1 73.1 MiroThinker-1.7-mini 75.5 56.3 71.3 70.9 59.0 66.6 79.7 56.3 75.2 70.4 68.5 MiroThinker-1.7 74.4 64.4 75.7 71.6 64.6 70.1 83.7 59.4 82.5 75.2 72.7 MiroThinker-H1 74.9 64.9 72.2 69.1 71.0 70.4 87.0 63.3 86.4 78.9 74.7 Multim odal (30 T as ks) Qw en-3.5-Plus Deep R esearch 57.0 51.3 58.7 57.7 51.3 55.2 61.7 39.3 56.3 52.4 53.8 Grok Deep Research 41.9 44.3 52.4 42.4 59.5 48.1 72.4 41.4 65.2 59.7 53.9 ChatGLM Agent 52.7 52.3 55.7 44.7 54.3 51.9 73.0 47.0 70.7 63.6 57.7 Manus-1.6-Max Wide R esearch 52.4 57.2 60.7 43.4 65.9 55.9 74.5 54.5 74.1 67.7 61.8 MiniMax-M2.5 R esearch 51.0 59.0 65.0 43.7 63.0 56.3 77.0 52.0 75.0 68.0 62.2 Gemini-3.1-Pro Deep Research 69.7 65.3 71.0 58.3 47.0 62.3 75.7 49.0 73.0 65.9 64.1 Claude-Opus-4.6 R esearch 75.2 60.7 69.6 59.3 60.0 65.0 78.9 49.3 72.6 66.9 65.9 OpenAI Deep Research 65.5 62.1 73.8 70.0 54.5 65.2 77.2 56.2 72.1 68.5 66.8 MiroThinker-1.7 65.0 57.0 72.0 63.0 57.7 62.9 80.7 58.7 76.0 71.8 67.4 MiroThinker-H1 68.6 63.1 73.4 71.0 64.1 68.1 86.6 63.4 86.9 79.0 73.5 turns out to combin e the leading Insight score o f 79.8 with a high wrong-claim count o f 595 and the second l argest pool o f unv erifiab le cl aims at 1,256. In other words, Kimi’s reports are an a lytically rich b ut insufficiently grounded: it generates insightf ul interpret ati ons that are not alwa ys backed by v erifiab le evidence. Manus-1.6-Max Wide R esearch presents the mirror image. Its Insight score of 54.8 is the lo w est am ong all systems, dra gging its Synthesis Avg down to 55.4, yet it produ ces only 191 wrong claims across nearly 2,000 correct on es, yielding a competitiv e F actu a lit y Ratio of 72.6. Man us appears to prioritize f actual cauti on ov er analytica l depth, a defensib le strategy for high-st akes t asks but one that limits report usabilit y . These contrasting pro files suggest that the synthesis–f actualit y gap is not random: it is systematica lly driven by how systems balance analyti cal ambitio n against f actual verificati on. T a keaw ay . The outcome-lev el analysis yields t wo actionab le insights. First, impro ving s pecificit y is the mo st impactf ul path to better synthesis qualit y , as cov era ge and instructi on-f ollo wing are approaching saturation am ong top systems. Second, the precisio n–v olume trade-off in factu a l claims is not inherent: the MiroThinker 15 MiroEva l: Benchmarking Multimoda l Deep Research Agents in Process and Outcome series demonstrates that high cl aim volume and low error rates can coexist, suggesting that appropriate research and v erificatio n strategies can resolve this tension without sacrificing either dimension. 4.4. Process-L ev el Analysis W e now turn to the process evaluatio n, which assesses how systems cond uct research rather than what they prod uce. T ab le 5 reports Intrinsic metrics (S earch Breadth, Analytica l Depth, Progressiv e Refin ement, Critica l Thinking, and Effici ency) and Alignment metrics (Findings → R eport cov era ge, R eport → Process traceabilit y , and Contradicti on detectio n). Intrinsic Qu a lit y: Sy stems Search Wide but F ail to Go Deep. The Intrinsic sub-metrics revea l a consistent structura l imbalance: m ost systems achiev e reaso nabl e Search Breadth but subst antially lo w er An a lytical Depth. In the T ext-Only setting, Breadth scores cluster bet ween 71 and 77 for most competitive systems, whereas Depth scores spread f ar more widely , from 41.6 for Doubao to 67.3 for OpenAI Deep R esearch. This makes Depth the single most discrimin ativ e Intrinsic metric, echoing the role that Specificit y plays amo ng R eport sub-metrics (§ 4.3 ): the abilit y to go beyo nd surf ace-lev el retrieval and condu ct deeper , m ulti-step analysis is what separates strong research processes from weak ones. Claude-Opus-4.6 off ers a particularly instructiv e case. Its Breadth of 79.1 is the highest among all the systems, but its Depth o f 58.8 trails behind by around 8 points, suggesting a search strategy that retriev es broad ly but rarely follo ws up with t argeted, iterativ e inv estigatio n. Bey ond Depth, Efficiency is a univ ersal wea kness: ev en the best system on this metric, MiroThinker-H1 at 68.1, scores well belo w its performan ce on other Intrinsic dimensions, and mo st systems fall in the 53 to 64 range. This indicates that current research processes contain subst antial redundan cy , including repeated queries, circul ar exploratio n paths, and retriev ed informati on that is nev er utilized, pointing to a clear av enu e for f uture optimi zation. Alignment: Findings R each the R eport, but R eports Outrun the Process. The Alignment metrics expose a revea ling asymmetry bet ween t wo directions of process-report consisten cy . Findings → R eport (F → R) scores are genera lly high: MiroThinker-H1 leads at 87.0, with OpenAI Deep R esearch and MiroThinker-1.7 both exceeding 83, and even mid-tier systems such as MiniMax-M2.5 and ChatGLM Agent remaining abo v e 70. This means that informatio n unco vered during the research process is, for the mo st part, successf ully incorporated into the final report. Report → Process (R → P) tells a different story . Scores are dramatically lo w er across the board: even the best system, MiroThinker-H1, achiev es only 63.3, and mo st others f all belo w 55, with Doubao at 36.8 and Qwen-3.5-P lus at 39.7. The gap bet ween F → R and R → P exceeds 23 points for MiroThinker-H1, 24 points for OpenAI, and approaches 30 points for Doubao, revea ling that a substanti a l portion of report content cannot be traced back to the research process . Sy stems routinely introd uce claims, interpretations, or synthesiz ed content that do n ot origin ate from their documented search and analysis steps. Whether this reflects implicit reaso ning, hallu cination, or unlogged intermediate steps, the practica l implicatio n is the same: current deep research systems exhibit a significant traceabilit y gap that undermines the audit a bilit y of their outputs. Contradicti on detection ( Contr) f urther differentiates systems on a complementary axis. MiroThinker-H1 leads decisively at 86.4, follo w ed by MiroThinker-1.7 at 82.5 and OpenAI at 79.9, while Doubao and Qwen-3.5-P lus score below 57, suggesting limited capacit y to hand le confli cting sources. This spread of o ver 30 points highlights contradicti on resolution as a critical and highly variab l e capabilit y for complex research t a sks where authorit ativ e sources frequently disagree. Process as a Predictor of Outcome Q ualit y . In § 4.2 we noted that process qu a lit y is broad ly aligned with outcome qualit y . Here w e deepen this observation by examining how Process rel ates to Synthesis and F actu alit y individ ually v ersus jointly . When correl ated with Synthesis al one, the rel atio nship is moderate: 16 MiroEva l: Benchmarking Multimoda l Deep Research Agents in Process and Outcome T ab le 6: P erforman ce comparison of models on user derived query and auto generati on query . Model U ser-Derived A uto-Generati on Overa ll Synthesis F actualit y Process Overa ll Synthesis F actualit y Process Overa ll Grok Deep R esearch 59.8 65.6 63.4 62.9 57.8 62.0 53.4 57.7 60.3 Doubao Deep Research 63.2 60.8 47.9 57.3 65.2 68.8 58.1 64.0 60.7 Manus-1.6-Max Wide R esearch 57.1 67.9 64.6 63.2 53.7 77.2 63.9 64.9 64.1 Qwen-3.5-P lus Deep R esearch 57.9 70.3 58.7 62.3 62.1 75.8 63.5 67.1 64.7 ChatGLM Agent 61.1 62.9 64.5 62.9 65.3 74.0 66.7 68.7 65.8 MiniMax-M2.5 Research 63.5 67.5 65.4 65.5 63.1 76.0 68.9 69.3 67.4 Claude-Opus-4.6 Research 65.9 70.1 66.3 67.4 68.7 69.6 65.7 68.0 67.7 Kimi-K2.5 Deep R esearch 74.9 63.5 64.1 67.5 76.5 67.5 64.3 69.5 68.5 Gemini-3.1-Pro Deep R esearch 70.1 69.5 65.8 68.5 72.3 73.0 68.4 71.2 69.9 OpenAI Deep R esearch 71.4 80.3 71.0 74.2 76.3 86.4 75.1 79.3 76.7 MiroThinker-1.7-mini 72.9 73.1 68.5 71.5 75.2 79.3 68.5 74.3 72.9 MiroThinker-1.7 73.6 78.5 71.2 74.4 75.0 80.5 74.3 76.6 75.5 MiroThinker-H1 75.2 78.4 74.3 76.0 78.2 83.7 75.1 79.0 77.5 Doubao achieves a Synthesis of 64.2 despite a Process score o f only 53.1, and Qwen-3.5-P lus attains a Process score of 61.1 that subst antially outranks its Synthesis of 60.0 rel ativ e to peers. The correl atio n with F actu ality alo ne is simil arly imperfect: Kimi-K2.5’s Process score of 64.2 would not predict its unusua lly low F actualit y Ratio of 65.4. H ow ev er , when S ynthesis and F actualit y are combined into an ov erall outcome measure, these individ ual irregul arities partially cancel out, and the alignment with Process becomes stronger . This is because a strong research process benefits both dimensio ns simultaneous ly , while the idio syncratic strategies that infl ate one dimensio n at the expense of the other are av eraged awa y . Empirically , w e compute the Pearso n correl ati on coefficient bet ween Process and the combined outcome score, obt aining a strong correlation of 0.88. This quantit ativ e result f urther substanti ates our an aly sis, confirming that process qualit y serv es as a reliab le predictor of o vera ll outcome qualit y . T a keawa y . The process-level an aly sis identifies t w o systemic wea knesses shared by current deep research systems. First, An alyti cal Depth and Efficien cy are the primary Intrinsic bottlenecks: systems retriev e broad ly b ut rarely inv estigate deeply , and mu ch of the retriev al effort is wasted. Second, the F → R versus R → P asymmetry revea ls a f undamental traceabilit y gap: reports consistently cont ain m ore than what the research process can account for . Despite these wea knesses, process qu a lit y remains a reliab le predictor of o vera ll outcome, validating process-centric eva luation as a meaningf ul complement to output-lev el assessment. 4.5. Further Analysis W e cond uct three supplement ary analyses to examine whether the findings from § 4.2 –§ 4.4 are robust across task sources, moda lit y settings, and evaluatio n configuratio ns. U ser-Deriv ed vs. A uto-Generated Queries. The 70 T ext-Only t a sks comprise t wo equ a lly si zed subsets: 35 user-derived queri es curated from real-w orld usa ge patterns through privacy-preserving rewriting (§2.2), and 35 auto-generated queri es produ ced by a trend-grounded pipeline (§2.3). T ab le 6 compares system performan ce across these t wo sources. A uto-generated queries are consistently easi er: nearly all systems with complete dat a score higher on the 17 MiroEva l: Benchmarking Multimoda l Deep Research Agents in Process and Outcome auto-gen erated subset, with o vera ll improv ements ranging from 0.6 points for Cl aude-Opus-4.6 to 6.7 points for Doubao Deep R esearch. This gap likely reflects the greater complexit y and ambiguit y inherent in queri es inspired by real user needs, which often inv olv e underspecified goals, domain-specific jargon, and multi-faceted informatio n requirements that are difficult to replicate through automated generati on. Despite this difficult y gap, the relative ranking of systems remains l argely stab le across the t wo subsets. OpenAI Deep R esearch and the MiroThinker series occupy the top positi ons in both cases, and the lo wer tier (Doubao, Qwen-3.5-P lus) is also consistent. F actualit y also show s a systematic source effect: the av era ge F actu ality score across systems is approximately 4 to 5 points higher on auto-generated queries, suggesting that trend-grounded queries, which are anchored in recent and well-documented web events, are easi er to v erif y than the more niche topics arising from real usa ge. These results carry t wo implicatio ns for benchmark design. First, the ranking st abilit y va lidates that auto- generated queries provide a reasonab l e proxy for real-w orld difficult y , supporting the scalability o f automated benchmark constru ctio n. Second, the consistent difficult y gap highlights that user-deriv ed queri es capture a dimensio n of complexit y that auto mated generatio n does not f ully reproduce, arguing for the inclusio n of both sources in a comprehensiv e benchmark. T ext-Only vs. MultiModal Comparison. In § 4.2 w e observed that multim odal t asks amplif y existing w eaknesses. Here we quantif y this effect more systematically . Across the eight systems with both T ext-Only and MultiModal o vera ll scores, the av era ge ov era ll score drops by 3.1 points. How ev er , the degradation is highly unev en across systems and dimensions. By dimension, Synthesis qualit y suffers the l argest av era ge decline at approximately 6 points, with Qwen- 3.5-Plus experiencing an extreme drop of 15.4 points ( from 60.0 to 44.6) and MiniMax-M2.5 declining by 6.6 points. Process scores decrease by an av era ge of roughly 4 points, with ChatGLM sho wing the sharpest decline of 7.9 points ( from 65.6 to 57.7). In contra st, F actualit y Ratios remain remarkab ly stab le, dropping by only 0.2 points on av era ge, suggesting that multim oda l t as ks do not systematica lly degrade f actual precisio n. This pattern reinforces a finding from § 4.3 : the multim odal bottleneck lies in report generatio n ( particularly specifi cit y and co vera ge of visual content) and research process qu a lit y ( particularly an alyti cal depth), not in factu a l v erificatio n. Systems that already struggle with these capa bilities in the T ext-O nly setting experien ce disproporti onate degradation when visual underst anding is required. Notab ly , MiroThinker-H1 show s the small est ov era ll decline at 3.0 points, suggesting stronger multim oda l integratio n in its research process, while the rel ativ e ranking bet w een systems remains broad ly consistent across both settings. Ev aluatio n R obu stness. T o verif y that our findings are not artifacts o f a particular evaluatio n configurati on, w e cond uct three rob ustness checks (detailed in Appendix D ). First, re-running the primary GPT judge three times on the MultiModal setting yields Overa ll st andard deviations o f only 0.3 to 0.6 across systems, with identical rankings in every run. Second, substituting Gemini as an alternative judge on the T ext-Only setting infl ates absolute scores by 13 to 17 points on Ov erall, yet the system ranking is perfectly preserv ed (Kenda ll’s τ = 1.0). Third, modif ying the judge prompt produ ces Overa ll shifts of less than 2 points with no rank changes. W e f urther va lidate against human judgment through a study with 5 expert annot ators ranking 10 systems on 5 sampled queries: the top three systems (MiroThinker-H1, OpenAI Deep R esearch, MiroThinker-1.7) match exactly , and the largest rank shift is only 2 positions. T ogether , these results confirm that the comparativ e conclu sions in § 4.2 –§ 4.4 are robu st across evaluatio n configuratio ns. 18 MiroEva l: Benchmarking Multimoda l Deep Research Agents in Process and Outcome 5. R elated W ork and Discussi on Deep Research S ystems. Deep research systems hav e emerged as a distinct paradigm in which langu a ge m odel agents auto nom ou sly pl an multi-step web inv estigati ons, synthesiz e evidence across heterogeneo us sources, and generate structured, citation-grounded reports [ 8 – 10 , 12 , 32 ]. Severa l benchmarks evaluate these capa bilities from a search or questio n-answering perspectiv e. General AgentBench [ 15 ] evaluates genera l-purpose a gents on multi-step reasoning and tool use; BrowseComp [ 38 ] measures persistent w eb navigati on; H LE [ 39 ] probes expert-level f actual knowl edge; and other efforts t arget search breadth [ 40 ] or grounded page interaction [ 41 ]. Ho w ever , these benchmarks assess retrieva l accuracy or short-answ er correctness, not the qualit y o f synthesi zed long-f orm outputs. R eport-Level Eva luation. Rea l-w orld deep research produ ces reports, not short answ ers—moti vating report- lev el evaluatio n. Most existing report benchmarks are text-only : DeepResearchBen ch [ 42 ] and DRBen ch [ 13 ] eva luate synthesis qu a lit y vi a human-annot ated rubrics; Liv eR esearchBench [ 23 ] introd uces temporal ground- ing; R eportBench [ 14 ] verifi es f actual grounding o f cited claims; and R esearcherBench [ 43 ] benchmarks m ulti-step research workfl ow s. R elated text-only efforts f urther enrich this landscape from complementary angles: DeepS cholar-Bench [ 17 ] studies generativ e research synthesis in a liv e setting, DEER [ 44 ] strengthens expert-lev el report assessment with broader document-lev el verificati on, Personalized Deep R esearch [ 45 ] incorporates authenti c user profil es and personalized informatio n needs, and I DRBen ch [ 46 ] begins to eva luate interactiv e deep research behavior beyo nd st atic final outputs. R ecent efforts extend to the multim oda l setting: MM-Brow seComp [ 47 ] extends Brow seComp to multim oda l retriev al but remains a short-form Q A t a sk; MMDeepResearch-Ben ch [ 19 ] eva luates multim odal reports b ut relies on fixed evaluatio n dimensions. Additiona l multim odal benchmarks explore adjacent as pects of research-oriented informatio n seeking: Visio n-DeepR esearch Benchmark [ 48 ] studies joint visual-textual search, MMSearch [ 20 ] benchmarks m ultimoda l search engines in m ore realistic web environments, and broader evaluati on frameworks such as DeepR esearchE val [ 26 ] and DeepF act [ 49 ] f urther reflect growing interest in long-f orm, grounded, and dyn amica lly maint ained research evaluati on. Across all o f these lines of work, severa l comm on limitations persist: evaluatio n criteri a tend to be fixed and task-a gno stic, f actual verifi cation is o ften restricted to cited statements or limited evidence scopes, assessment focu ses exclusiv ely on the final output without examining the underlying research process, multim oda l eva luation rarely goes beyo nd short-form Q A, and benchmark t as ks are rarely grounded in real user needs or designed for temporal refresh. MiroEva l addresses these limit ati ons al ong fo ur axes. F or evaluati on, it introd uces adaptiv e synthesis qualit y assessment with dynamically generated task-specifi c rubrics, agenti c factu a lit y verifi cation against both web and att achment evidence, and process-centric eva luation that audits ho w the system searches, reaso ns, and refines throughout its inv estigati on. All three l a yers n ativ ely support m ultimoda l inputs. For benchmark constru ctio n, it grounds a ll tasks in real user needs through a d ual- path pipeline that supports contin uous refresh, ensuring that evaluatio n remains aligned with the ev olving complexit y o f real-w orld deep research. 6. Conclu sio n W e introdu ced MiroEva l , a benchmark and evaluati on framew ork for deep research systems, comprising 100 t as ks (70 text-only and 30 multim oda l) assessed through three complementary layers: adaptiv e synthesis qualit y , a gentic f actualit y , and process-centric evaluati on. Our experiments across 13 leading systems sho w that the three dimensio ns capture complementary aspects of system capabilit y; that process qualit y reliab ly predicts ov era ll outcome while revea ling wea knesses invisib le to output-lev el metrics; and 19 MiroEva l: Benchmarking Multimoda l Deep Research Agents in Process and Outcome that multim oda l t a sks pose subst antially greater challenges. Human v erificati on confirms benchmark qu a lit y at 92.0% precision, and extensive robu stness experiments together with a human ranking study (Kenda ll’s τ = 0.91) validate the reliabilit y o f the evaluatio n framework. MiroEv al pro vides a holistic di a gno stic tool for the next generatio n of deep research a gents. Limitations and Future W ork. Our process eva luation relies on systems exposing their intermediate reaso ning traces, which limits applica bilit y to f ully closed-so urce systems that do not provide such access. Additio nally , the f actualit y evaluati on currently identifies cross-source confli cts ( e.g., bet ween web evidence and user-pro vided att achments) but does not yet resolve them: the CONFLICT label flags disagreements without determining which source is correct, an import ant direction for f uture work. L ooking ahead, we pl an to lev erage the refreshab l e dual-path constructi on pipeline to periodica lly update the benchmark with new queri es reflecting ev olving user needs and the l atest web trends, ensuring that MiroEva l remains temporally relevant as a live benchmark. 20 MiroEva l: Benchmarking Multimoda l Deep Research Agents in Process and Outcome R ef erences [1] L ei W ang, Chen Ma, Xueyang F eng, Zeyu Z hang, Hao Y ang, Jingsen Zhang, Z hiyuan Chen, Jiakai T ang, Xu Chen, Y ankai Lin, et al. A survey on l arge langu a ge model based auton om ous agents. Fronti ers of Computer Science , 18(6):186345, 2024. [2] Y ibo Li, Z ijie Lin, Ailin Deng, Xuan Zhang, Y ufei He, Shuo Ji, Tri Cao, and Bryan Hooi. Just-In- T ime R einf orcement Learning: Continua l L earning in LLM Agents Without Gradient Updates. arXiv preprint arXiv:2601.18510 , 2026. [3] Y uw en Du, R ui Y e, Shuo T ang, Xinyu Z hu, Yijun Lu, Yuzhu Cai, and Siheng Chen. OpenS eeker: Dem ocratizing Frontier Search Agents by Fully Open-Sourcing T raining Data, 2026. URL https: //arxiv.org/abs/2603.15594 . [4] Xuan-Phi N guyen, Shrey P andit, Rev anth Gangi Reddy , A ustin Xu, Silvio Savarese, Caiming Xio ng, and Shafi q Jot y . SF R-DeepR esearch: T o wards Effectiv e Reinf orcement L earning for Auto no mo usly R ea soning Single Agents, 2025. URL . [5] Y uxuan Huang, Yihang Chen, H aozheng Zhang, Kang Li, Huichi Zhou, Meng F ang, Linyi Y ang, Xi- aoguang Li, Lifeng Shang, S ongcen Xu, et al. Deep research agents: A systematic examin ati on and roadmap. arXiv preprint , 2025. [6] W enlin Z hang, Xiaopeng Li, Y ingyi Z hang, Pengyu e Ji a, Yi chao W ang, Huifeng Guo, Y ong Liu, and Xiangyu Z hao. Deep research: A surv ey of auto no mo us research agents. arXiv preprint , 2025. [7] Kui cai Dong, Shurui Hu ang, F angda Y e, W ei Han, Z hi Z hang, Dexun Li, W enjun Li, Q u Y ang, Gang W ang, Yi chao W ang, et al. Doc-researcher: A unified system for multim odal document parsing and deep research. arXiv preprint , 2025. [8] Kimi T eam. Kimi-Researcher: End-to-End RL T raining for Emerging Agentic Capabiliti es. https: //moonshotai.github.io/Kimi- Researcher/ , 2025. [9] Manu s AI. Introdu cing Wide R esearch. https://manus.im/blog/introducing- wide- research , 2025. [10] OpenAI . Introdu cing deep research. https://openai.com/index/ introducing- deep- research/ , 2025. [11] Jeremy Hadfield, Barry Zhang, Kenn eth Lien, Florian S cholz, Jeremy F ox, and Daniel F ord. Ho w W e Built Our Multi-Agent R esearch Sy stem. https://www.anthropic.com/engineering/ multi- agent- research- system , 2025. [12] Gemini. Gemini Deep R esearch. https://gemini.google/overview/deep- research/ , 2025. [13] Amirhossein Abaskohi, T ianyi Chen, Miguel Muñoz-Márm ol, Curtis F ox, Amrutha V arshini Ramesh, Étienn e Marcotte, Xing Han Lù, Nicolas Chapado s, Spandana Gella, Christopher P al, et al. DRBen ch: A realisti c benchmark for enterprise deep research. arXiv preprint , 2025. [14] Minghao Li, Ying Zeng, Z hihao Cheng, Cong Ma, and Kai Jia. R eportBench: Eva luating deep research a gents vi a academic survey t as ks. arXiv preprint , 2025. 21 MiroEva l: Benchmarking Multimoda l Deep Research Agents in Process and Outcome [15] Xiaochuan Li, R yan Ming, Pranav Setlur , Ab hijay Pa ladugu, Andy T ang, Hao Kang, S huai S hao, R ong Jin, and Chenyan Xiong. Benchmark T est- T ime Scaling o f General LLM Agents. arXiv preprint arXiv:2602.18998 , 2026. [16] João Coelho, Jing jie Ning, Jingyu an He, Kangrui Mao, Ab hijay P alad ugu, Pranav Setlur , Jiahe Jin, J amie Callan, João Ma galhães, Bruno Martins, et al. DeepR esearchGym: A free, transparent, and reprod ucib le eva luation sandbox for deep research. arXiv preprint , 2025. [17] Liana Patel, Negar Arabzadeh, Harshit Gupt a, Ankita Sundar , Ion Stoi ca, Matei Zaharia, and Carlos Guestrin. DeepSchol ar-Bench: A live benchmark and automated evaluatio n for generativ e research synthesis. arXiv preprint , 2025. [18] Jian Li, W eiheng Lu, H ao F ei, Meng Luo, Ming Dai, Min Xia, Yizhang Jin, Z henye Gan, Ding Qi, Chaoy ou Fu, et al. A surv ey on benchmarks o f m ultim odal large langu a ge models. arXiv preprint arXiv:2408.08632 , 2024. [19] P eizhou Huang, Zixuan Zhong, Z hongw ei W an, Donghao Z hou, Samiul Al am, Xin W ang, Zexin Li, Zhihao Dou, Li Zhu, Jing Xiong, et al. MMDeepR esearch-Bench: A Benchmark for Multimoda l Deep R esearch Agents. arXiv preprint , 2026. [20] Dongzhi Jiang, R enrui Z hang, Ziyu Guo, Y anmin Wu, Jiayi L ei, Pengshu o Q iu, P an Lu, Zehui Chen, Chaoy ou Fu, Guanglu Song, et al. MMsearch: Benchmarking the potential of l arge models as m ulti- m odal search engines. arXiv preprint , 2024. [21] Negar Foro ut an, Angelika R omano u, Matin Ansaripour , Julian Martin Eisenschlos, Karl Aberer , and Rémi L ebret. WikiMxQ A: a multim odal benchmark for questi on answering ov er t ab les and charts. In Findings of the Association for Comput atio nal Linguistics: A CL 2025 , pages 24941–24958, 2025. [22] Y utao Zhu, Xingshuo Zhang, Maosen Z hang, Jiajie Jin, Liancheng Z hang, Xi aos huai Song, Kangzhi Zhao, W encong Zeng, Ruiming T ang, H an Li, et al. GISA: A Benchmark for General Informati on-Seeking Assistant. arXiv preprint , 2026. [23] Jiayu W ang, Yif ei Ming, Riya Dulepet, Qinglin Chen, A ustin Xu, Zixuan Ke, Frederic Sala, Aw s Albargh- outhi, Caiming Xiong, and Shafiq Jot y . Liv eR esearchBen ch: A liv e benchmark for user-centric deep research in the wild. arXiv preprint , 2025. [24] Nathan Kuissi, Suraj Subrahmanyan, Nandan Thakur , and Jimmy Lin. Still Fresh? Eva luating T emporal Drift in R etriev al Benchmarks. arXiv preprint , 2026. [25] Nandan Thakur , Jimmy Lin, Sam Hav ens, Michael Carbin, Omar Khatt ab, and Andrew Drozdo v . Freshstack: Building realistic benchmarks for evaluating retrieval on technica l documents. arXiv preprint arXiv:2504.13128 , 2025. [26] Y ibo W ang, L ei W ang, Y ue Deng, Keming Wu, Y ao Xiao, Hu anjin Y ao, Liwei Kang, H ai Y e, Y ongcheng Jing, and Lidong Bing. DeepR esearchEv al: An A utomated Framework for Deep Research T ask C onstru ctio n and Agentic Eva luatio n. arXiv preprint , 2026. [27] Shi qian Su, S en Xing, Xuan Dong, Muyan Zhong, Bin W ang, Xizhou Z hu, Y unt ao Chen, W enhai W ang, Y ue Deng, Pengxiang Z hu, et al. MiroFlo w: T o wards High-Perf ormance and R obu st Open-Source Agent Framew ork for General Deep R esearch T asks. arXiv preprint , 2026. 22 MiroEva l: Benchmarking Multimoda l Deep Research Agents in Process and Outcome [28] Jerry W ei, Chengrun Y ang, Xinying S ong, Yif eng Lu, Nathan Hu, Jie Huang, Dustin T ran, Daiyi Peng, R uibo Liu, Da Huang, et al. L ong-f orm f actualit y in l arge l anguage models. Advances in Neural Informati on Processing Sy stems , 37:80756–80827, 2024. [29] Ho ngzhan Lin, Y ang Deng, Y uxuan Gu, W enxu an Zhang, Jing Ma, See Kio ng N g, and T at-Seng Chua. F act-audit: An adaptiv e multi-a gent framework for dynamic f act-checking evaluatio n of l arge l angua ge m odels. In Proceedings o f the 63rd Annual Meeting of the Association for C omputatio nal Linguistics , pages 360–381, 2025. [30] Xin Liu, L echen Z hang, Sheza Munir , Yiyang Gu, and Lu W ang. V erifact: Enhancing long-f orm f actualit y eva luation with refined f act extraction and reference f acts. In Proceedings o f the 2025 Conferen ce on Empirica l Methods in Natural L anguage Processing , pages 17919–17936, 2025. [31] xAI. Grok DeepS earch. https://x.ai/news/grok- 3 , 2025. [32] Anthropic. Introd ucing Cl aude S onn et 4.6, 2026. URL https://www.anthropic.com/news/ claude- sonnet- 4- 6 . [33] Doubao. Doubao Chat, 2026. URL https://www.doubao.com/chat/ . [34] Z hipu AI. ChatGLM, 2026. URL https://chatglm.cn . [35] Qw en T eam. Qwen3.5: T o wards Nativ e Multimoda l Agents, February 2026. URL https://qwen.ai/ blog?id=qwen3.5 . [36] MiniMax. MiniMax-M2.5, 2026. URL https://www.minimax.io/news/minimax- m25 . [37] MiroMind T eam, S . Bai, L. Bing, L. L ei, R. Li, X. Li, X. Lin, E. Min, L. Su, B. W ang, L. W ang, L. W ang, S . W ang, X. W ang, Y . Zhang, Z. Z hang, G. Chen, L. Chen, Z. Cheng, Y . Deng, Z. Hu ang, D. N g, J . Ni, Q . R en, X. T ang, B. L. W ang, H. W ang, N . W ang, C. W ei, Q . W u, J . Xi a, Y . Xiao, H. Xu, X. Xu, C. Xue, Z . Y ang, Z . Y ang, F . Y e, H. Y e, J . Y u, C. Z hang, W . Zhang, H. Zhao, and P . Z hu. MiroThinker-1.7 & H1: T o wards Hea vy-Dut y R esearch Agents vi a V erificatio n, 2026. URL . [38] J aso n W ei, Z hiqing Sun, Spencer Pa pay , Scott McKinney , Jeffrey H an, Isa Fulford, Hyung W on Chung, Alex T achard P a ssos, William F ed us, and Amelia Gl aese. BrowseCo mp: A simple yet challenging benchmark for browsing agents. arXiv preprint , 2025. [39] Long Phan, Alice Gatti, Ziwen Han, Nathani el Li, Josephina Hu, Hugh Zhang, Chen Bo Calvin Z hang, Mohamed Sha a ban, John Ling, Sean Shi, et al. Humanit y’s l ast exam. arXiv preprint , 2025. [40] R yan W o ng, Jiaw ei W ang, Junjie Zhao, Li Chen, Y an Gao, L ong Z hang, Xuan Z hou, Zuo W ang, Kai Xiang, Ge Zhang, et al. WideSearch: Ben chmarking agenti c broad info-seeking. arXiv preprint arXiv:2508.07999 , 2025. [41] Xiang Deng, Y u Gu, Boyuan Z heng, Shiji e Chen, Sam Stevens, Boshi W ang, Hu an Sun, and Yu Su. Mind2w eb: T owards a generalist a gent for the web. Advances in Neural Informatio n Processing Sy stems , 36:28091–28114, 2023. [42] Mingxuan Du, Benfeng Xu, Chiw ei Z hu, Xiaorui W ang, and Zhendong Mao. Deepresearch bench: A comprehensiv e benchmark for deep research agents. arXiv preprint , 2025. 23 MiroEva l: Benchmarking Multimoda l Deep Research Agents in Process and Outcome [43] T ianze Xu, Pengrui Lu, Lyumanshan Y e, Xiangkun Hu, and Pengf ei Liu. R esearcherBench: Eva luating deep AI research systems on the fronti ers of scientific inquiry . arXiv preprint , 2025. [44] J anghoon Han, Heegyu Kim, Changho L ee, Da hm L ee, Min Hyung Park, Hosung S ong, St anley Jungkyu Choi, Moont ae L ee, and Hongla k L ee. D EER: A Benchmark for Eva luating Deep R esearch Agents on Expert R eport Generatio n. arXiv preprint , 2025. [45] Y uan Liang, Jiaxian Li, Y uqing W ang, P iaohong W ang, Motong Tian, P ai Liu, Shu of ei Qiao, R unnan F ang, He Z hu, Ge Zhang, et al. T ow ards personalized deep research: Benchmarks and eva luations. arXiv preprint arXiv:2509.25106 , 2025. [46] Y ingchaojie F eng, Q iang Huang, Xiaoya Xie, Zhaorui Y ang, Jun Y u, W ei Chen, and Anthony KH Tung. I D RBench: Interactiv e Deep R esearch Benchmark. arXiv preprint , 2026. [47] Shil ong Li, Xingyu an Bu, W enji e W ang, Jiaheng Liu, Jun Dong, Haoyang He, Hao Lu, Haozhe Zhang, Chenchen Jing, Zhen Li, et al. Mm-BrowseCo mp: A comprehensiv e benchmark for multim odal bro wsing a gents. arXiv preprint , 2025. [48] Y u Zeng, W enxu an Huang, Z hen F ang, Shuang Chen, Y ufan Shen, Yis huo Cai, Xiaoman W ang, Zhenfei Y in, Lin Chen, Zehui Chen, et al. Visi on-deepresearch benchmark: Rethinking visual and textual search for multim odal l arge l angua ge models. arXiv preprint , 2026. [49] Y ukun Huang, L eonardo F R Ribeiro, Momchil Hardal ov , Bhuwan D hingra, Markus Dreyer , and V enkatesh Saligrama. DeepF act: Co-Ev olving Benchmarks and Agents for Deep Research F actual- it y . arXiv preprint , 2026. 24 MiroEva l: Benchmarking Multimoda l Deep Research Agents in Process and Outcome Contrib utors F angda Y e 1,2* , Y uxin Hu 1,2* , Pengxiang Zhu 1,2* , Yibo Li 1,2* , Ziqi Jin 1,3 † , Y ao Xiao 1 † , Yibo W ang 1 L ei W ang 1 ‡ , Zhen Zhang 1 † , Lu W ang 1 † , Y ue Deng 1 , Bin W ang 1 , Yifan Zhang 1 , Liangcai Su 1 , Xinyu W ang 1 , He Zhao 1 , Chen W ei 1 , Qi ang R en 1 Bryan Hooi 2 , An Bo 1,3 , Shuicheng Y an 2 , Lidong Bing 1 1 MiroMind AI 2 Nati onal Univ ersit y of Singapore 3 Nanyang T echnologi cal U niv ersit y ∗ Co-first author † Core contributi on ‡ Project L ead 25 MiroEva l: Benchmarking Multimoda l Deep Research Agents in Process and Outcome T ab le 7: A v erage report length across different systems. Sy stem T ext-Only Multimoda l Ov erall OpenAI Deep R esearch 17,669 12,751 16,194 MiroThinker-H1 20,442 11,802 17,850 MiroThinker-1.7 21,138 11,293 18,185 MiroThinker-1.7-mini 21,823 – – Qwen-3.5-P lus Deep R esearch 24,299 9,081 19,734 Manus-1.6-Max Wide R esearch 10,263 5,585 8,860 MiniMax-M2.5 Research 26,747 9,593 21,601 Gemini-3.1-Pro Deep R esearch 49,343 32,568 44,311 Claude-Opus-4.6 Research 23,624 20,129 22,576 ChatGLM Agent 24,386 10,313 20,164 Kimi-K2.5 Deep R esearch 61,739 – – Doubao Deep Research 43,160 – – Grok Deep R esearch 7,585 4,977 6,803 A. Data Collectio n and R eport Statistics T abl e 7 summariz es the report length st atistics of all eva luated deep research systems. All reports were collected in March 2026 within a controlled time window to ensure f air comparison across systems. Reports w ere generated and downl oaded from the offi cial interfaces of each system using automated tools. W e report the av erage length o f valid Deep Research outputs produ ced by each system across all eva luated tasks. F or systems that support both text-only and multim odal deep research, w e further report length statistics under both settings. A consistent pattern is that text-only reports are generally longer than their m ultimoda l counterparts. Severa l systems—including MiroThinker-1.7-mini, DeepSeek DeepThink, Kimi- K2.5 Deep R esearch, and Doubao Deep R esearch—do not support multim odal deep research. F or these systems, only text-only statistics are reported. B. Ev aluati on F eatures and R ewrite Strategies T ab le 8 defines the 8 evaluatio n features used to cl assif y and balance the benchmark queri es. Each feature correspo nds to a core capa bilit y of deep research systems. During query curatio n (§ 2.2 ), an LLM assigns a subset of these features to each query , and the routing mechanism ensures balanced co vera ge across the final benchmark. T abl e 9 describes the 6 rewrite strategies ( A through F) spanning three difficult y tiers. Each strategy transforms a raw user query into a benchmark-ready inst ance t argeting specific eva luation features. The routing mechanism selects the optimal strategy for each query ba sed on material constraints, feature matching, quota bonuses, and usa ge decay (§ 2.2 ). C. T opic T axon omy and Domain Labels T ab le 10 lists the 12 topics and 36 subtopics used for trend-grounded automated query generati on (§ 2.3 ). F or each topic, w eb searches are issued per subtopic to collect recent head lines and snippets as trend context for LLM-based query generati on. Each query in the benchmark is assigned a domain l abel from the 11 cano nical categories listed in T ab le 11 . 26 MiroEva l: Benchmarking Multimoda l Deep Research Agents in Process and Outcome T ab le 8: Definitio ns of the 8 eva luation features. F eature Definiti on Goal ad herence Whether the system maintains f ocus on all specified goals and co nstraints throughout a multi-step task without deviating from original objectives or silently dropping sub-t as ks. R epetitio n av oidance Whether the system av oids repeating the same informatio n or analysis across different sections of its output when the query contains multiple similar but distinct sub-tasks. Planning Whether the system can decompose a complex query into a coherent, logica lly ordered sequence of execution steps with clear dependencies bet ween st ages. Search Whether the system can form ulate effectiv e search queries and retrieve relevant external informati on, rather than relying solely on parametric kno wledge or the pro vided att achments. R eport generatio n Whether the system can organi ze retrieva l results into a well-structured, logica lly coherent report ( comparison t a bl es, analytica l summaries, or recommendati on lists) that synthesizes informati on from multipl e sources. F actualit y Whether factu al claims in the system’s output are accurate and v erifiab le a gainst authoritative sources, with proper citation where appropriate. Error correction Whether the system can detect errors, contradictio ns, or probl ematic premises in the query or att achments and proactively correct them, rather than blind ly foll owing fl aw ed instructi ons. Multim odal under- standing Whether the system can correctly parse, interpret, and utili ze non-textual in- formati on in att achments ( charts, tabl es, images, diagrams, structured data), extracting accurate valu es and underst anding spatial/visua l relations hips. This feature is only assigned to queries with att achments. A rule-based norma liz ati on f uncti on maps free-form domain strings to these l a bels using substring matching and keyword f allbacks, with tech as the def ault. 27 MiroEva l: Benchmarking Multimoda l Deep Research Agents in Process and Outcome T abl e 9: The 6 rewrite strategies used for user-derived query curation. “R equires att achments” indicates the strategy is excluded for text-only queries d uring routing. I D Difficulty T arget F eatures Descriptio n A Easy search, multim odal under- standing Extract 1–2 key points from the attachment, perform one round of retriev al for supplemen- tary context, and generate a concise response. R equires att achments. B Medium planning, search, report gen- eratio n, f actualit y , repetitio n av o idance Compare attachment data a gainst at least 2 ex- ternal publi c sources and produ ce a structured comparativ e analysis report. Requires attach- ments. C H ard factualit y , error correctio n, m ultimoda l underst anding Embed contradicti ons bet ween the query text and att achment content ( e.g., numeri cal dis- crepanci es, date misalignment). The system m ust discov er the inconsisten cy through read- ing the att achment and/or retrieva l. R equires high-densit y att achments. D Hard error correctio n, goa l ad her- ence Embed false premises or ambiguous expres- sio ns in the query . The system should identif y the erroneous premise, correct it, and still com- plete the core t a sk. E Medium / H ard planning, search, report gen- eratio n, goal adheren ce, repe- titio n av oidance Multi-step research query with no att achment dependency . Answers m ust be synthesi zed from multipl e public sources through iterative retrieva l. F Easy / Medium m ultimoda l underst anding, re- port generatio n Primary focus on att achment processing: struc- tured extraction, summari zation, format con- versi on, or cross-pa ge synthesis. Retri eva l is auxiliary only . Requires attachments. 28 MiroEva l: Benchmarking Multimoda l Deep Research Agents in Process and Outcome T ab le 10: T opi c t axon omy for automated query generatio n: 12 topics, each with 3 subtopics. # T opi c Subtopics 1 AI Policy & Regulati on EU AI Act implementation; US st ate AI laws; AI safet y frameworks 2 Cybersecurit y Zero-day exploits; Agentic SOC; AI-po wered social engineering 3 Finance & Macro Central bank policy; S o vereign debt; Infrastru cture investment 4 Crypto & Digit a l Assets Stab lecoin regul atio n; DeFi compliance; CBDC adoption 5 Healthcare & Pharma Gene therapy trials; GLP -1 market dyn amics; FDA regulatory shifts 6 International T rade Globa l supply chain restructuring; Free trade agreements impact; Cross-border regulatory harm onization 7 AI Engineering LLM benchmarking; Agentic coding tools; Model deployment ar- chitecture 8 Climate & Energy Data center sustainabilit y; Carbon pricing; Grid constraints 9 Edu catio n & W orkf orce AI in K -12 policy; W orkf orce reskilling; Immigration & t alent 10 L ega l & Compliance AI privilege doctrine; GD PR enforcement; Algorithmic discrimin a- tio n 11 Biotech & Science Computational biology; Quantum computing; Open access pub lish- ing 12 Supply Chain & Industrial Nearshoring trends; Auto nom ou s logistics; S emico ndu ctor supply T ab le 11: The 11 cano nica l domain labels. # L a bel Scope 1 finance Financial markets, investment analysis, banking, macroeconomi cs, corporate earnings, and economi c dat a. 2 policy Go vernment policy , regulatio n, go v ernance, and institutiona l rule- making at local, nationa l, and international lev els. 3 tech T echnology , soft ware engineering, AI/ML, hardware, and internet prod ucts. Also serves as the def ault fallback l abel. 4 cybersecurity Digital securit y threats, defenses, vulnera bilit y research, threat intelli- gence, and securit y operations. 5 health Hea lthcare, medicine, pharmaceuticals, clinical research, medical de- vices, and public health. 6 science Natura l sciences, academic research, engineering, mathematics, and research infrastructure. 7 education Ed ucatio n systems, learning, workf orce training, t al ent development, and prof essiona l reskilling. 8 legal Law , lega l practice, compliance, dat a protection enforcement, and algorithmi c account ability . 9 energy Energy systems, climate policy , carbon markets, sustainabilit y , and data center environmental impact. 10 trade Internationa l trade, supply chains, logistics, manufacturing, and cross- border commerce. 11 crypto Cryptocurrenci es, digital assets, decentra lized fin ance, blockchain technol ogy , and CBDCs. 29 MiroEva l: Benchmarking Multimoda l Deep Research Agents in Process and Outcome T abl e 12: Intra-judge st abilit y on MultiModal (30 tasks). Three independent runs with the same GPT judge configurati on. Each dimension reports scores from R un 1 / Run 2 / R un 3, follo w ed by the mean and st andard deviation. Model Synthesis F actualit y Process Ov erall A vg Std R1 R2 R3 R1 R2 R3 R1 R2 R3 R1 R2 R3 OpenAI Deep R esearch 66.7 66.5 66.7 77.0 75.0 76.9 66.8 65.0 66.2 70.2 68.8 69.9 69.6 0.6 Gemini-3.1-Pro 66.4 66.3 66.9 73.7 70.0 72.7 64.1 63.0 62.8 68.1 66.4 67.5 67.3 0.6 MiroThinker-1.7 69.0 68.7 68.6 78.5 80.9 79.6 67.4 67.7 67.4 71.6 72.4 71.9 72.0 0.3 MiroThinker-H1 71.5 72.0 70.8 78.4 76.2 77.4 73.5 73.6 73.3 74.5 73.9 73.8 74.1 0.3 D. E va luatio n R ob ustn ess and Human Study A key con cern for any LLM-ba sed evaluati on framew ork is whether the results are sensitiv e to random variatio n, the choi ce o f judge model, or minor prompt differences. W e address this through three controlled rob ustness experiments (§ D.1 –§ D .2 ), f ollo wed by a human study that va lidates consistency with expert judgments (§ D.3 ). D.1. Intra-Judge St a bilit y LLM-based evaluatio n can exhibit no n-trivial variance across runs due to sampling randomness. T o qu antif y this, we re-run the primary judge configuratio n ( GPT series) t w o additio nal times on the MultiModal setting (30 t as ks) f or fo ur systems: OpenAI Deep R esearch, Gemini-3.1-Pro, MiroThinker-H1, and MiroThinker-1.7. T ogether with the origin al run, this yields three independent eva luations per system. T ab le 12 reports the mean and standard deviation across runs. The standard deviatio ns on Ov erall are remarkab ly lo w , ranging from 0.3 (MiroThinker-H1 and MiroThinker- 1.7) to 0.6 ( OpenAI Deep R esearch and Gemini-3.1-Pro), and the system ranking is identica l across all three runs. At the sub-dimension level, Synthesis scores are the most st ab le with variatio ns under 1 point, while F actu alit y shows slightly larger fluctuatio ns of up to 3 points for individua l systems ( e.g., Gemini-3.1-Pro: 73.7 / 70.0 / 72.7), likely du e to the stochasti c nature of web search during claim verifi catio n. Despite these per-dimensio n fluctuations, the Overa ll ranking remains perfectly preserved, confirming that the eva luation results are stab le under repeated execution. D.2. Cro ss-Judge Consistency and Prompt Sensitivit y Bey ond run-lev el variance, we f urther examine whether system rankings are robu st to the choice of judge m odel and the form ulation o f judge prompts. T ab le 13 summariz es both experiments. Each cell reports scores in the format original / alternative / ∆ . Cross-Judge C onsisten cy . W e re-evaluate the T ext-Only setting (70 t a sks) using Gemini as an alternativ e judge f or all three dimensions, cov ering six systems ( Gemini-2.5-Pro f or synthesis and process evaluati on, and Gemini-3-Flash for f actualit y eva luation). The Gemini judge produ ces subst antially higher absolute scores across the board, with Overa ll delt a s ranging from +13.2 ( OpenAI Deep R esearch and MiroThinker-H1) to +16.9 ( ChatGLM Agent). This systematic infl atio n is mo st prono unced on Process (deltas of +16.6 to +21.3) and least on F actualit y (+6.0 to +11.7), suggesting that Gemini applies m ore lenient criteria for process eva luation than for factu a l verifi cation. Crucially , despite these l arge absolute shifts, the rel ativ e ranking of all six systems is perfectly preserved ( ∆ Rank = 0 for every system), yielding a Kenda ll’s τ o f 1.0 30 MiroEva l: Benchmarking Multimoda l Deep Research Agents in Process and Outcome T abl e 13: R obustn ess to judge model choi ce and prompt variation. Each cell reports origi- nal / alternativ e / ∆ . ∆ Rank: rank change based on Ov erall score. Upper : Cross-judge consistency on T ext-Only (70 t a sks), GPT vs. Gemini. L o wer : Prompt sensitivit y on MultiModal (30 t as ks), original vs. m odified prompt with the same GPT judge. Model Synthesis F actualit y Process Overa ll ∆ Rank Cross-Judge: T ext-Only (70 T as ks) — GPT S eries ( orig.) / Gemini Series ( alt.) / ∆ OpenAI Deep R esearch 73.8 / 90.2 / +16.4 83.3 / 89.3 / +6.0 73.1 / 90.2 / +17.1 76.7 / 89.9 / +13.2 0 Gemini-3.1-Pro 71.2 / 89.5 / +18.3 71.3 / 81.8 / +10.5 67.1 / 87.9 / +20.9 69.9 / 86.4 / +16.5 0 ChatGLM Agent 63.2 / 82.2 / +19.0 68.6 / 80.3 / +11.7 65.6 / 85.7 / +20.1 65.8 / 82.7 / +16.9 0 MiroThinker-1.7-mini 74.0 / 90.3 / +16.3 76.2 / 86.2 / +10.0 68.5 / 89.8 / +21.3 72.9 / 88.8 / +15.9 0 MiroThinker-1.7 74.3 / 90.8 / +16.5 79.4 / 87.6 / +8.2 72.7 / 91.0 / +18.3 75.5 / 89.8 / +14.3 0 MiroThinker-H1 76.7 / 92.1 / +15.4 81.1 / 88.6 / +7.5 74.7 / 91.3 / +16.6 77.5 / 90.7 / +13.2 0 Prompt Sensitivit y: MultiModal (30 T as ks) — Original / Modified / ∆ OpenAI Deep R esearch 66.7 / 66.3 / -0.4 77.0 / 74.6 / -2.4 66.8 / 65.0 / -1.8 70.2 / 68.6 / -1.6 0 Gemini-3.1-Pro 66.4 / 66.3 / -0.1 73.7 / 71.0 / -2.7 64.1 / 63.0 / -1.0 68.1 / 66.8 / -1.3 0 MiroThinker-1.7 69.0 / 68.8 / -0.2 78.4 / 76.3 / -2.1 67.4 / 67.5 / +0.2 71.6 / 70.9 / -0.7 0 MiroThinker-H1 71.5 / 71.7 / +0.2 78.5 / 77.9 / -0.6 73.5 / 72.5 / -1.0 74.5 / 74.0 / -0.5 0 on Ov erall. This dem onstrates that cross-judge differences are systematic rather than selectiv e, affecting all systems similarly and leaving comparativ e con clusio ns int act. Prompt S ensitivit y . W e re-eva luate four systems on the MultiModal setting (30 t asks) using the same GPT judge but with a modifi ed prompt that rephrases the scoring criteri a in a m ore concise format and adjusts the ordering of eva luation dimensio ns. In contrast to the cross-judge experiment, the prompt modifi catio n prod uces only minimal score changes: Overa ll delt as range from − 0.5 (MiroThinker-H1) to − 1.6 ( OpenAI Deep R esearch), with mo st per-dimension shifts below 1 point. The only dimension showing slightly l arger variatio n is F actu ality ( up to − 2.7 for Gemini-3.1-Pro), consistent with the higher sensitivit y of cl aim-lev el v erificatio n to prompt phrasing. As with the cross-judge experiment, system rankings are f ully preserved ( ∆ Rank = 0), confirming that the evaluati on outcomes are robu st to reaso nab le prompt reform ulations. D.3. Human Study T o va lidate that our automated eva luation aligns with expert human judgment, we condu ct a human study with 5 v olunteers. W e randomly sample 5 queri es from the benchmark and collect reports from all deep research systems that support multim oda l attachments. F or each case, annotators are provided with both the final report and the associated research process, and are as ked to rank the systems based on ov era ll qu a lit y , jointly considering the effectiv eness of the research process and the qu ality of the resulting report. T abl e 14 reports the av era ge human ranking al ongside the MiroEva l ranking for each system. The t wo rankings exhibit strong agreement, with Kenda ll’s τ = 0.91 and Spearman’s ρ = 0.95. The top three systems under human judgment (MiroThinker-H1, OpenAI Deep R esearch, MiroThinker-1.7) match the top three under MiroEva l exactly , and the largest rank shift across all systems is only 2 positi ons ( Qw en-3.5-Plu s). Summary . Across all four analyses, the rel ativ e ranking of systems is remarkab ly st ab le. Repeated runs prod uce Overa ll st andard deviations below 0.6; switching from GPT to Gemini as judge infl ates absolute 31 MiroEva l: Benchmarking Multimoda l Deep Research Agents in Process and Outcome T abl e 14: C ompariso n bet ween human rankings and MiroEva l rankings. Human rankings are av eraged across 5 annotators. ∆ Rank: positiv e va lues indicate higher human ranking than MiroEva l. Sy stem Human MiroE val ∆ Rank MiroThinker-H1 1.8 1 = OpenAI Deep R esearch 2.5 2 = MiroThinker-1.7 2.8 3 = Claude-Opus-4.6 Research 5.2 5 ↑ 1 Gemini-3.1-Pro Deep R esearch 5.3 4 ↓ 1 MiniMax-M2.5 Research 6.0 6 = Qwen-3.5-P lus Deep R esearch 6.8 9 ↑ 2 ChatGLM Agent 7.3 7 ↓ 1 Manus-1.6-Max Wide R esearch 8.0 8 ↓ 1 Grok Deep R esearch 9.5 10 = scores by 13 to 17 points but preserves the ranking perfectly; modif ying the judge prompt shifts scores by less than 2 points with no rank changes; and expert human annotators con verge on the same top-tier systems as MiroEva l with a maximum rank shift of 2 positio ns. These results confirm that the comparativ e con clusio ns drawn in the main text are robust to the evaluatio n configuratio n, and that absolute score differen ces bet w een judge m odels reflect systematic calibrati on o ffsets rather than meaningf ul disa greements abo ut rel ativ e system qu a lit y . 32 MiroEva l: Benchmarking Multimoda l Deep Research Agents in Process and Outcome E. Ca se Study E.1. S ynthesis Eva luatio n W e present t wo represent ativ e case studies to illustrate how the adaptiv e synthesis qu a lit y eva luation operates on concrete t as ks, including the generated dimensions, criteria, and scoring. Both cases are multim oda l t a sks with att achment-augmented queri es. Case 1: Analyzing the 50 F astest-Gro wing S o ft ware V endors T a s k. The user provides a screenshot of the BREX BENCHMARK “50 f astest-gro wing so ft ware vendors o f 2025” ranking ( an ima ge listing vendor n ames and ranks from #01 Cursor to #50 Wis pr) and asks the system to extract all company names, research each company’s produ ct, busin ess model, culture, and competitiv e advant a ges, and prod uce an integrated report. Extracted Key F acts. The framew ork extracts the foll o wing f actual anchors from the att achment: • T op-10 roster: 01 Cursor , 02 OpenRo uter , 03 Kling AI, 04 R etell AI , 05 Perpl exit y , 06 Windsurf , 07 FireCrawl, 08 Cl a y , 09 R eplit, 10 Exa. • The graphic cont ains only vendor names and ranks; no growth rates, categories, busin ess models, or financial metrics are sho wn. • Multiple vendors include “.ai” in their n ames, but this al one does not est a blis h AI-n ativ e st atus. Generated Eva luatio n Dimensio ns and W eights. Bey ond the fo ur fixed dimensio ns, three task-specifi c Grounding & Expertise dimensio ns are generated. The assigned w eights are: Dimensio n W eight Cov era ge 0.27 Insight 0.30 Instructi on-f ollo wing 0.14 Clarit y 0.09 Attachment-Grounded S cope & Methodology Integrit y 0.08 Eviden ce-Linked Business Model & AI-Nativ e Typology 0.07 Inv estment-Grade Pro fit ability & Go-to-Market Eva luatio n 0.05 The first grounding dimension checks whether the report uses the exact top-20 roster as its sampling frame and av oids inferring attributes from the graphic. The second checks whether b usiness-m odel labels are backed by extern al evidence rather than assumed. The third checks whether profitabilit y claims are sourced from credible references. Cross-S ystem Scoring. W e compare MiroThinker-H1 ( ov era ll: 8.5) a gainst ChatGLM Agent ( ov era ll: 4.5). Cov erage — “Complete per-company cl assifi catio ns for the top-20.” MiroThinker-H1 provides a per-company t ab le cl a ssif ying all 20 vendors by busin ess model, customer segment, and technology route. The eva luator notes: “ T he report pro vides a t a bl e that lists all top-20 compani es with columns for b usiness m odel, core customer group, and technology route, which it uses to indicate AI-native st atus. ” Score: 9.4 . ChatGLM Agent does not produ ce a per-company cl a ssificatio n t ab le. The evaluator notes: “ The report does not pro vide a per-co mpany matrix or t ab le that classifies each o f the top-20 by busin ess m odel, primary customer segment, and AI-n ativ e vs. traditional. It relies on anecdotes and pl aceholders. ” Score: 1.0 . Grounding: Eviden ce-Linked Business Model & Typology — “Correct top-20 sampling frame and co verage.” 33 MiroEva l: Benchmarking Multimoda l Deep Research Agents in Process and Outcome MiroThinker-H1 explicitly lists all 20 companies with correct names and ranks matching the att achment. The evaluator notes: “ T he report clearly works o ff the correct Brex ‘top 20’ roster . It explicitly lists all 20 compani es in T ab le 1 with correct n ames and ranks matching the key f acts. ” Score: 9.8 . ChatGLM Agent introdu ces companies outside the top-20 and conflates them into its analysis. The eva luator notes: “The report repeated ly goes beyo nd the top-20 scope, using ElevenLa bs—not in the roster—a s a core example for bu siness model and profitabilit y conclu sions.” Score: 2.5 . Grounding: Scope & Methodology Integrit y — “ Ackn owl edges graphic content limit ations and av o ids inferen ce.” ChatGLM Agent f abri cates gro wth rates from the graphic ( e.g., “Cursor 1000%, Kling AI 1900%”), when the att achment cont ains no gro wth data at all. The evaluator notes: “ The att achment s how s only n ames and ranks. The report neither ackno wledges this limit atio n nor av oids inferen ce; it asserts growth rates, pro fit a bilit y , and ARR figures not present in the graphi c. ” S core: 0.5 . T a keaw ay . The dyn amica lly generated grounding dimension catches a critical failure m ode—f abri cating gro wth rates and financials from a graphi c that contains only names and ranks—that a fixed rubric wo uld not detect. The key-facts extractio n step transforms the abstract instructi on into precise checkpoints ( e.g., “does the report use the exact top-20 roster?”), enab ling fine-grained discrimination. Case 2: V eterinary N utritio n Planning for a S eni or Cat T a s k. A user provides medica l records and 10 prod uct photographs ( canned wet foods from brands including Schesir After Dark, RA WZ, AIXIA, Uni charm, Zealandia, and Miaw Miaw) for a 12-year-old cat with chronic pancreatitis and mild CKD. The system m ust compare the nutriti onal profil es and produ ce a prioritized feeding recommendati on. Extracted Key F acts. The framework extracts produ ct-lev el f acts from each photograph. Crucially , mo st prod uct ima ges do not display nutriti onal analysis panels: • AIXIA Kenko-can 11+: phosphorus 0.08%, sodium 0.10% (visible on l abel); no f at content s ho wn . • Schesir After Dark Chicken 80 g: labeled “C ompl ete,” “Grain Free”; no fat or phos phorus visib le . • RA WZ Shredded Chicken & Pumpkin ∼ 3 oz: no nutrient panel visib le . • Uni charm Silver Spoo n 13+ (m ultiple tun a variants, 70 g each): no nutri ent valu es visibl e . Generated Eva luation Dimensio ns and W eights. Three t as k-specific dimensions are generated: Dimensio n W eight Cov era ge 0.28 Insight 0.26 Instructi on-f ollo wing 0.16 Clarit y 0.10 SK U- V erifi ed Nutrient Pro venance & R egio nal Fidelit y 0.07 Clinica lly-Norma liz ed Nutriti on Modeling & Suitabilit y Ranking 0.09 U ncertaint y-A ware Dat a Gap Go vernance 0.04 The first grounding dimensio n checks whether nutrient values are matched to the exact SK U and regio nal variant ( e.g., Ja pan-market vs. US-market form ulatio ns). The second checks whether nutri ents are con v erted to comparab le clinica l metrics for pancreatitis and CKD. The third checks whether the report explicitly ackno wledges missing dat a. Cross-S ystem S coring. W e compare Gemini-3.1-Pro ( ov erall: 7.6) against MiniMax-M2.5 ( o vera ll: 4.0). 34 MiroEva l: Benchmarking Multimoda l Deep Research Agents in Process and Outcome Insight — “T rade-o ff reasoning and decision logic.” Gemini-3.1-Pro constructs a t wo-dimensi onal f at–phosphoru s framework and proposes mixed-feeding strategies. The evaluator notes: “ Demo nstrates nuanced balancing with a 2D f at–phos phoru s framework and proposes t actica l mixed feeding to recon cile lo w -P vs lo w -fat trade-offs. It classifies produ cts by which axis they satisf y . ” Score: 8.9 . MiniMax-M2.5 assigns subjectiv e st ar ratings without explicit trade-o ff an aly sis. The evaluator notes: “ T rade-o ffs are only superficia lly addressed. T he report assigns st ar ratings but does not explicitly w eigh key compromises. ” Score: 4.6 . Grounding: Un certaint y-Aw are Data Gap Go vernance — “Explicitly ackno wledges missing f at and phos pho- rus for m ost SKU s and av oids inv enting values.” Gemini-3.1-Pro parti a lly ackno wledges missing panels and marks some valu es as unkno wn, b ut still uses ret ail aggregat or dat a without confirming regio nal SK U matches. Score: 3.2 . MiniMax-M2.5 asserts specific nutri ent valu es ( e.g., “Silver Spoon fat: 0.3%,” “RA WZ f at: 1.5%”) for prod ucts whose labels sho w no nutriti onal dat a at all , without citing any source. The evaluator notes: “ Attachments s ho w no f at/phos phorus panels for Schesir After Dark, RA WZ, Unicharm Silver Spoo n 13+, SEED S Golden Cat, Zealandia W allaby . T he report non etheless provides s pecific va lues without ackno wl edging data gaps or citing external sources. ” Score: 0.8 . Grounding: SK U- V erified Nutrient Pro venan ce — “ Authoritativ e, region-matched nutri ent sourcing.” Both systems struggle with regio nal fidelit y . Gemini-3.1-Pro sources from ret ail aggregators rather than manufacturer dat a sheets, and sometimes confl ates J apan-market and US-market variants. Score: 3.4 . MiniMax-M2.5 provides no manufacturer URLs or dat a sheets for any valu e. S core: 0.5 . T a keawa y . The Uncertaint y -A ware Data Gap Gov ernance dimension—gen erated because the key-f acts extractio n identified that m ost produ ct images l ack nutrient panels—catches a failure m ode where systems fabricate precise-looking numbers from no n-existent label dat a. A fixed rubric evaluating only “nutriti onal accuracy” w ould miss this distincti on, as it cannot kno w a priori which dat a points are av ailab le in the att achments. Ov erall observatio n. The t w o cases illustrate ho w adaptiv e evaluati on captures f ailure m odes invisib le to fixed rubrics. In Case 1, the key-f acts extraction revea ls that the att achment contains only n ames and ranks, prompting a grounding dimension that penalizes fabricated growth rates. In Case 2, the extractio n identifies perva siv e missing nutrient panels, prompting an uncert aint y-gov ernance dimensio n that penalizes inv ented va lues. In both cases, the dyn amica lly generated criteria provide task-specifi c discrimin atio n, while the shared fixed dimensio ns maint ain cross-t a sk comparabilit y . 35 MiroEva l: Benchmarking Multimoda l Deep Research Agents in Process and Outcome E.2. F actu ality Ev aluatio n W e present severa l represent ativ e case studies to illustrate t ypica l examples of v erif ying a statement using the proposed agenti c evaluati on framework. W e also include t wo cases where the judgments are incorrect; ho wev er , it should be noted that such cases only occur occasi onally . Correct Case 1 Extracted Statement In the second half of 2014, globa l ov ersupply driv en by U .S . shale produ ction growth and slo wing demand caused oil prices to plummet from approximately $110 to below $40 per barrel. Agentic V erificatio n: Wro ng. R ea soning: While the qu a lit ativ e expl anation—U .S . sha le-driv en ov ersupply combined with wea kening demand—is well supported by EIA and W orld Bank an a lyses, the specific numeri c cl aim that prices fell “belo w $40” during H2 2014 is incorrect. EIA monthly data sho w Brent crude av era ging approximately $106.77 in July 2014 and $62.34 in December 2014. W TI ended December 2014 at approximately $59.29. Prices did not fall belo w $40 per barrel until early 2016, more than a year after the period referen ced in the st atement. Eviden ce • EIA (Brent) : “EIA mo nthly t ab le for 2014: Brent July 2014 ≈ $106.77; Brent December 2014 ≈ $62.34.” • EIA ( WTI) : “W TI December 2014 ≈ $59.29 (not belo w $40 at year-end 2014).” Human Annotatio n Right Final Judge The model judgment is correct. Although the qualitative expl anation is accurate, the cl aim that prices fell “belo w $40” in H2 2014 is f a lse. EIA dat a sho w end-2014 prices near $62 (Brent) and $59 (W TI), with sub-$40 levels only reached in early 2016. This case illustrates a commo n hallucinati on pattern: correct directiona l reasoning b ut incorrect magnitude or timing. Correct Case 2 Statement In 2019, Hu a wei reported reven ue of CNY 858,833M, operating pro fit of CNY 77,835M, and an operating margin of 9.1%. Agentic V erificatio n: Right. R ea soning: The system extracted all three figures from the five-year fin ancia l highlights t ab le in the user-uploaded screenshot, and then independently retriev ed the same tab le from Huaw ei’s 2019 Annual R eport. All three valu es—reven ue, operating profit, and the stated margin—are consistent across both sources. An internal arithmetic cross-check f urther confirms the margin: 77,835 ÷ 858,833 ≈ 9.07% , which rounds to the reported 9.1% . Eviden ce • Uploaded screens hot (image) : “Rev en ue row: . . . 858,833 . . . ; Operating profit row: . . . 77,835 . . . ; Operating margin ro w: . . . 9.1% . . . ” • Huaw ei 2019 Annual R eport (PD F) : “Fiv e- Y ear Fin ancia l Highlights (2019 column): R ev enue ( CNY 36 MiroEva l: Benchmarking Multimoda l Deep Research Agents in Process and Outcome Millio n) 858,833; Operating profit 77,835; Operating margin 9.1%.” Human Annotatio n Right Final Judge Both the model and the human annotator correctly judge the statement a s accurate. The three figures are directly verifia bl e from Hu a wei’s publicly availab le 2019 Annual Report, and the margin is arithmetica lly consistent with the rev enu e and profit va lues: 77, 835 ÷ 858, 833 = 9.07% ≈ 9.1% . This case illustrates a distinctiv e m ultimoda l verifi catio n w orkflo w: the system first extracts numeric data from an embedded ima ge ( a screenshot of the fin ancia l highlights t ab le), then independently confirms the same figures via an authorit ativ e external document, and finally validates internal arithmetic consistency—a three-layer cross-check that is not possib le in text-only settings. Correct Case 3 Statement The LiuGong 856H E electri c wheel loader is equipped with a CA TL LFP battery rated at 350 kWh / 580 V , with a charging time of under 75 minutes. Agentic V erificatio n: C onfli ct. R ea soning: The att ached technical review explicitly reports a battery capacit y of 350 kWh and a rated v olt a ge of 580 V , with a charging time under 75 minutes . Ho w ever , LiuGong’s offi cial produ ct page lists the 856H E with an LFP battery rated at 432 kWh , resulting in an 82 kWh (23%) discrepancy . Since both sources are credib le yet inconsistent, and the difference cannot be explained by rounding, the claim cannot be definitively verifi ed without f urther clarificatio n ( e.g., model variants or specificatio n updates). Eviden ce • Attachment — technical review PD F ( Electric Wheel L oader Overvi ew .pdf , p. 8) : “the LiuGong 856H E E WL . . . ha s a rated energy capacit y of 350 kWh and a rated volta ge of 580 V , with a charging time o f under 75 min.” • W eb — LiuGong North America produ ct page (856H E) : “Battery Type: LFP . Rated Storage Energy: 432 kWh . Operating W eight: 46,297 lb (21,000 kg).” Human Annotatio n Conflict Final Judge The model judgment is correct. The discrepancy bet ween 350 kWh and 432 kWh indicates confli cting specifi cations across credible sources, likely due to different model variants or updates. This case high- lights a comm on m ultimoda l confli ct scen ari o: consistent evidence within each source but irreconcilab le differen ces across sources. Incorrect Case 1 Statement Star Raiders was relea sed in 1979. Agentic V erificatio n: Wro ng. 37 MiroEva l: Benchmarking Multimoda l Deep Research Agents in Process and Outcome R ea soning: The system retriev ed the Wikipedia articl e for St ar Raiders and identified the phra se “pub lished in 1980 by At ari, Inc.”, concluding that the correct relea se year is 1980 and that 1979 likely refers only to devel opment or internal demo nstratio ns. Eviden ce • Wikipedia — Star Raiders : “Star Raiders is a space combat simulator video game created by Doug Neuba uer and publis hed in 1980 by At ari, Inc. Originally released for the At ari 400/800 computers. . . ” [ excerpt truncated] Human Annotatio n Right Final Judge The agenti c verdict is incorrect. While the retriev ed evidence emphasizes the 1980 publi cation date, Star Raiders was already availa bl e in 1979 as a pack-in title for the At ari 400/800 l aun ch. Therefore, the st atement is f actually valid under a broader definition o f release. This case highlights a temporal ambiguit y: different sources refer to different relea se events, and the a gent f ails to reconcile these interpretations. Incorrect Case 2 Statement R ev enu e from produ cts built on generativ e AI models grew ov er 200% year-o ver-year . Agentic V erificatio n R esult: Right. R ea soning: The system retriev ed the CEO’s remarks from both the uploaded earnings document and the company’s o fficial b log, which report the figure as “nearly 400% year-ov er-year .” Since 400% exceeds 200%, the system interpreted the statement “ov er 200%” as a conservativ e but numerica lly va lid description and returned a Right verdi ct. Eviden ce • Attachment — Alphabet Q4 2025 E arnings R elea se (PD F , p. 1) : “In Q4, reven ue from produ cts built on our generativ e AI models grew nearly 400% year-ov er-year .” • W eb — Alphabet CEO Blog : “nearly 400% year-ov er-year .” ( https://blog.google/ company- news/inside- google/message- ceo/alphabet- earnings- q4- 2025/ ) Human Annotatio n W rong Final Judge The model judgment is incorrect. Although “nearly 400%” logica lly satisfies the lo w er-bound cl aim “o ver 200%,” the statement materially underst ates the reported magnitude and thus misrepresents the underlying f act. This case highlights a comm on failure m ode: treating logica l ent ailment as suffici ent for factu a l correctness, particularly for va gue low er-bound expressio ns ( e.g., “o ver X%”), leading to f alse positiv es. 38 MiroEva l: Benchmarking Multimoda l Deep Research Agents in Process and Outcome E.3. Process Ev aluatio n Process Case Studies. T o make the process evaluatio n more interpret a bl e, we present t wo representative case studies: w e first sho w ho w raw trajectories are abstracted into structured process represent atio ns, and then compare systems based on both intrinsic process qualit y and process–report alignment. The first case highlights an evidence-sparse text-only t as k, where strong performance depends on scope control and conserv ative synthesis. The second highlights a multim oda l t as k, where the key difference is whether the attachment is incorporated as an early grounding constraint that sha pes the subsequent inv estigatio n. Case Box 1: T ext-o nly t as k with fragmented and incompl ete evidence T a s k. The task asks the system to an alyze the employment destinations of graduates from Chin a’s 985 universiti es across 2023–2025, identif y the major recurring employers, compare hiring scal e and ind ustry absorptio n, distinguish undergraduate from postgrad uate outcomes, and exclude public-sect or placements. Structured process representation. After conv erting raw trajectories into atomic process units, the three systems exhibit marked ly different structures. MiroThinker-H1 foll ow s a compact trajectory of plan → search → read → search → read → analyze → v erif y → synthesize . Its process is anchored by an early scope decision: only enterprise employment is counted, while go vernment agenci es, publi c institutio ns, f urther study , and entrepreneurship are explicitly excluded. This decision determines all subsequent evidence collectio n. The extracted process findings sho w that H1 identifies three core constraints: (1) pub lic evidence is structura lly inco mplete and cannot support a f ully audit a bl e cross-985 ranking; (2) many univ ersit y reports mix enterprise and no n-enterprise destin ati ons, so employer rankings require unit-t ype cleaning; and (3) company-side recruiting pl ans can serve as auxiliary scale signals but are not equiva lent to realized grad uate placements. By contrast, MiroT hinker-v17 sho ws a mu ch longer but less consolidated structure. Although it retrieves m ore local evidence and successf ully gathers severa l usef ul universit y-lev el records, its trajectory is dominated by repeated search and scrape actions, with rel ativ ely wea k transition into explicit v erificati on and final synthesis. MiroT hinker is even more search-heavy: its process remains largely at the lev el o f searching for candidate sources and identif ying possib le clues, but nev er reaches a st ab le st age of cross-source consolidatio n. Cross-m odel comparison. This structural difference explains the process scores. H1 does not achiev e the widest search breadth, but it performs better on efficiency and alignment because it conv erts retrieved evidence into a bounded conclusi on. In particular , it explicitly st ates that the av ailab le evidence supports only a candidate set of major employers , not a reliab le T op-10 ranking. This yields the best alignment pro file in the case: the report remains l argely traceab le to the process, and unsupported extrapolatio ns are limited. In contra st, both v17 and MiroThinker introdu ce more con clusio ns that go beyo nd what wa s actu ally est ab lished in the trajectory . Their wea kness is therefore not simply insuffici ent search, but insuffici ently grounded synthesis. T akea wa y . This case illustrates a central failure mode in evidence-sparse research tasks: stronger processes are not necessarily those that collect more raw material, but those that define the scope early , verif y the comparabilit y of evidence, and stop at the evidence boundary instead of f abri cating a complete answer . 39 MiroEva l: Benchmarking Multimoda l Deep Research Agents in Process and Outcome Case Box 2: Multimoda l t a s k where att achment grounding changes the trajectory T a s k. The task as ks the system to assess the climate effects of a hypothetica l geographic interventi on in which the T arim Basin becomes an inl and sea connected to the Indi an Ocean, using both historica l analogu es and quantit ativ e climate evidence from att ached materials and extern a l sources. Structured process represent atio n. The multim oda l case rev eals a different kind of process differen ce. MiroThinker-H1 reads the att achment at the very beginning and extracts a key physica l constraint: the new waterwa y crosses the P amir/Karakoram region. This att achment-grounded constraint becomes the starting point for the l ater inv estigatio n. After structuring the trajectory , H1 foll ow s a l ayered process o f read att achment → retriev e analogues → read climate studies → analyze mechanisms → synthesize . Its extracted findings form an “evidence pyramid”: modern inland-sea an a logues, pal eocli- mate an a logies, reverse evidence from sea retreat and aridificati on, and circul atio n-lev el expl anations from climate-model studies. Its Search:R ead ratio is also highly distinctiv e, indicating that on ce the directio n is est ab lis hed, the model spends mo st of its budget digesting evidence rather than repeated ly re-searching. MiroThinker-v17 retrieves a l arger number o f quantit ativ e fragments and surf aces severa l usef ul nu- merica l observatio ns, but its trajectory is less tightly organiz ed around a single evidenti a l hierarchy . MiroThinker sho ws the w eakest structured process: it relies more heavily on broad an a logy search and limited reading, with severa l final numeri cal ranges f unctio ning as inferential placeholders rather than findings directly supported by the process. Cross-m odel comparison. These structura l differences are reflected most clearly in alignment. H1 achiev es the best process–report consistency because m ost major report cl aims can be linked back to process-lev el findings, and the report contains few subst antiv e contradi ctions. By contrast, v17 introd uces some unsupported extrapolations beyo nd the trace, while MiroThinker includes m ultiple quantit ativ e ranges that are not directly grounded in the retriev ed evidence. The core distinctio n is therefore not simply whether a model can retriev e climate an a logies, but whether it uses the att achment to define the scen ario constraints early and preserves that grounding throughout the report. T a keawa y . This case sho ws why multim oda l process evaluatio n cannot be redu ced to output inspection al one. A model may produ ce a plausib le report, yet still fail to ground its reaso ning in the attachment that defines the t ask. Stro ng multim odal research processes are characteri zed by early att achment integratio n, evidence digestion ov er repeated search, and tighter traceabilit y bet ween intermedi ate findings and final conclu sions. Ov erall observatio n. T ogether , these t wo cases illustrate the valu e of process-centric evaluati on beyo nd final-report scoring. In the text-only case, the decisiv e f actor is disciplined scope control under fra gmented evidence; in the m ultimoda l case, it is whether the att achment becomes a first-cl a ss constraint in the research trajectory . Across both settings, the strongest processes share the same procedura l pattern: early task reframing, selectiv e evidence digestio n, explicit hand ling of limitations or conflicts, and conservati ve synthesis that stays within the support of the documented trajectory . 40
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment