멀티모달 딥 리서치 에이전트 평가: 프로세스와 결과를 동시에 측정하는 MiroEval
MiroEval은 실제 사용자 요구에 기반한 100개의 텍스트·멀티모달 과제를 제공하고, 최종 보고서 품질, 사실 정확성, 연구 프로세스 세 가지 차원에서 딥 리서치 에이전트를 평가한다. 13개 시스템 실험을 통해 프로세스 품질이 결과 예측에 가장 큰 영향을 미치며, 멀티모달 과제가 기존 시스템에 큰 난이도를 부여한다는 점을 확인했다.
저자: Fangda Ye, Yuxin Hu, Pengxiang Zhu
**1. 서론**
대형 언어 모델(LLM)의 급격한 발전으로 단순 텍스트 생성에서 자율적인 계획·실행이 가능한 에이전트형 딥 리서치 시스템으로 전환하고 있다. 이러한 시스템은 복합적인 정보 탐색·증거 수집·사실 검증·보고서 작성 과정을 자동화하지만, 실제 고위험 분야(금융, 의료, 법률 등)에서는 최종 보고서의 정확성·투명성·멀티모달 지원이 필수적이다. 기존 벤치마크는 최종 보고서만을 고정 루브릭으로 평가하고, 멀티모달 지원이 제한적이며, 합성·정적 데이터에 의존해 실제 사용자 요구를 반영하지 못한다는 문제점을 지적한다.
**2. 벤치마크 설계**
MiroEval은 100개의 과제(텍스트 70개, 멀티모달 30개)를 두 경로로 구축한다.
- *사용자 파생 경로*: 내부 테스트 단계에서 수집된 실제 사용자 쿼리 패턴을 익명화·재작성하여 65개 과제를 만든다. 이 과정에서는 개인정보 제거, 엔터티 대체, 7가지 차원(첨부 유형, 정보 밀도, 도메인, 난이도 등)으로 분류하고, 난이도(Easy·Medium·Hard)와 기능 매칭을 고려한 6가지 재작성 전략을 적용한다.
- *자동 생성 경로*: 실시간 웹 트렌드(Serper API) 기반으로 12개 주제·3개 하위주제당 15개 후보를 생성, 3단계 필터링(검색 유효성, 딥리서치 필요성, 역품질 평가)과 수동 선별을 거쳐 35개 텍스트 과제를 확보한다.
각 과제는 도메인(기술·금융·과학·공학·의료·비즈니스·정책·법률·인문·사이버보안·생활·교육)과 작업 유형(결정·추천, 비교·분석, 사실 열거·검증, 정책·규제 분석, 인과 설명, 설문·종합, 트렌드·예측, 데이터·계산, 코드·생성, 문서·편집)에서 균형을 이루며, Fleiss’ κ가 0.81·0.76으로 높은 신뢰도를 보인다.
**3. 평가 프레임워크**
세 가지 상보적 차원을 제시한다.
- *적응형 합성 품질 평가*: 과제별 동적 루브릭을 자동 생성해 도메인·목표 가중치를 반영, 고정 기준의 한계를 극복한다.
- *에이전트 기반 사실성 검증*: 보고서를 원자적 주장으로 분해하고, 웹·멀티모달 소스에 대해 자동 검색·추론을 수행, RIGHT/WRONG/CONFLICT/UNKNOWN 네 가지 레이블을 부여한다.
- *프로세스 중심 평가*: 검색 폭, 분석 깊이, 단계적 정제, 비판적 사고, 효율성 등 5가지 내재 차원을 정량화하고, 프로세스→보고서·보고서→프로세스 정합성을 측정한다. 또한, 모순 탐지와 증거 추적 격차를 식별한다.
모든 차원은 멀티모달 입력을 자연스럽게 지원하도록 설계돼, 이미지·PDF·스프레드시트 등 다양한 첨부 파일을 포함한 과제에서도 동일한 평가 흐름을 유지한다.
**4. 실험 및 결과**
13개 최신 딥 리서치 시스템(Claude, Gemini, OpenAI, Qwen, MiniMax, Doubao, Kimi 등)을 MiroEval에 적용했다. 주요 발견은 다음과 같다.
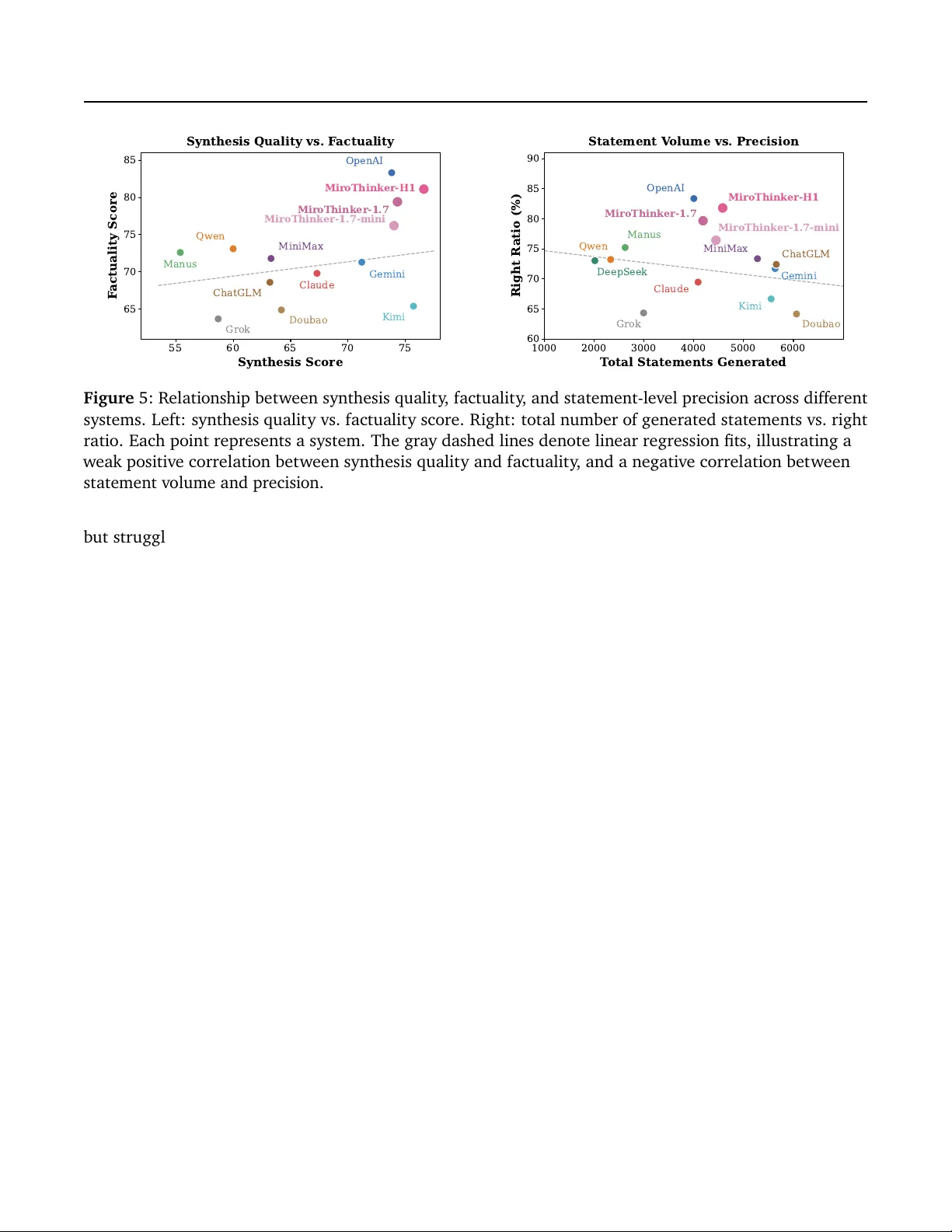
1) *차원 간 상보성*: 합성 품질, 사실 정확성, 프로세스 품질 순위가 크게 다르게 나타나며, 어느 하나만으로는 시스템 전반을 평가할 수 없음을 확인했다.
2) *프로세스 품질의 예측력*: 프로세스 점수가 전체 성과(합성+사실)와 가장 높은 상관관계를 보였으며, 검색 범위 부족·증거 연결 결함 등 출력‑레벨 메트릭에 숨겨진 약점을 드러냈다.
3) *멀티모달 난이도*: 멀티모달 과제에서는 대부분의 모델이 3~10점씩 성능이 감소했으며, 특히 이미지·PDF 해석·표 추출 능력이 낮은 것이 원인으로 분석됐다.
4) *시스템별 특성*: MiroThinker‑H1은 텍스트(77.5점)·멀티모달(74.5점) 모두에서 가장 균형 잡힌 성능을 보였으며, 다른 모델은 특정 차원에서 강점(예: Claude‑Fact)이나 약점(예: Qwen‑Process)으로 편중되는 경향을 보였다.
인간 전문가(3명) 검증을 통해 전체 벤치마크의 정밀도가 92%이며, 인간 순위와의 Kendall τ가 0.91로 높은 일치도를 나타냈다. 또한, 다양한 잡음(시드 변동, 검색 엔진 교체) 실험에서도 결과가 크게 변동하지 않아 평가 체계의 견고함을 입증했다.
**5. 논의 및 향후 과제**
MiroEval은 (1) 실시간 트렌드 기반 자동 쿼리 생성으로 시계열적 업데이트가 가능하고, (2) 다차원 평가를 통해 시스템 설계 시 프로세스 투명성·멀티모달 통합을 핵심 목표로 삼을 수 있게 한다는 점에서 기존 벤치마크와 차별화된다. 그러나 현재 멀티모달 첨부 파일의 복잡도(고해상도 이미지·다중 페이지 PDF)와 대규모 실시간 검색 비용이 제한 요소이며, 자동 사실성 검증의 ‘UNKNOWN’ 비율이 여전히 높아 추가적인 신뢰성 강화가 필요하다. 향후 연구에서는 (a) 멀티모달 인식·표 추출 모델과의 연동, (b) 사용자 피드백 기반 루프를 통한 동적 루브릭 조정, (c) 도메인 특화 프로세스 템플릿 제공 등을 통해 에이전트의 실제 활용성을 높일 수 있을 것이다.
**6. 결론**
MiroEval은 실제 사용자 요구에 기반한 다중 도메인·다중 작업 유형·멀티모달 과제를 제공하고, 최종 보고서 품질, 사실성, 연구 프로세스 세 축을 동시에 평가함으로써 딥 리서치 에이전트의 전반적인 역량을 종합적으로 진단한다. 실험 결과는 프로세스 품질이 전체 성과를 가장 잘 예측하고, 멀티모달 지원이 현재 시스템의 주요 약점임을 명확히 보여준다. 따라서 MiroEval은 차세대 딥 리서치 에이전트 개발과 평가에 있어 필수적인 진단 도구로 자리매김할 전망이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기