Diagnosing Non-Markovian Observations in Reinforcement Learning via Prediction-Based Violation Scoring
Reinforcement learning algorithms assume that observations satisfy the Markov property, yet real-world sensors frequently violate this assumption through correlated noise, latency, or partial observability. Standard performance metrics conflate Marko…
Authors: Naveen Mysore
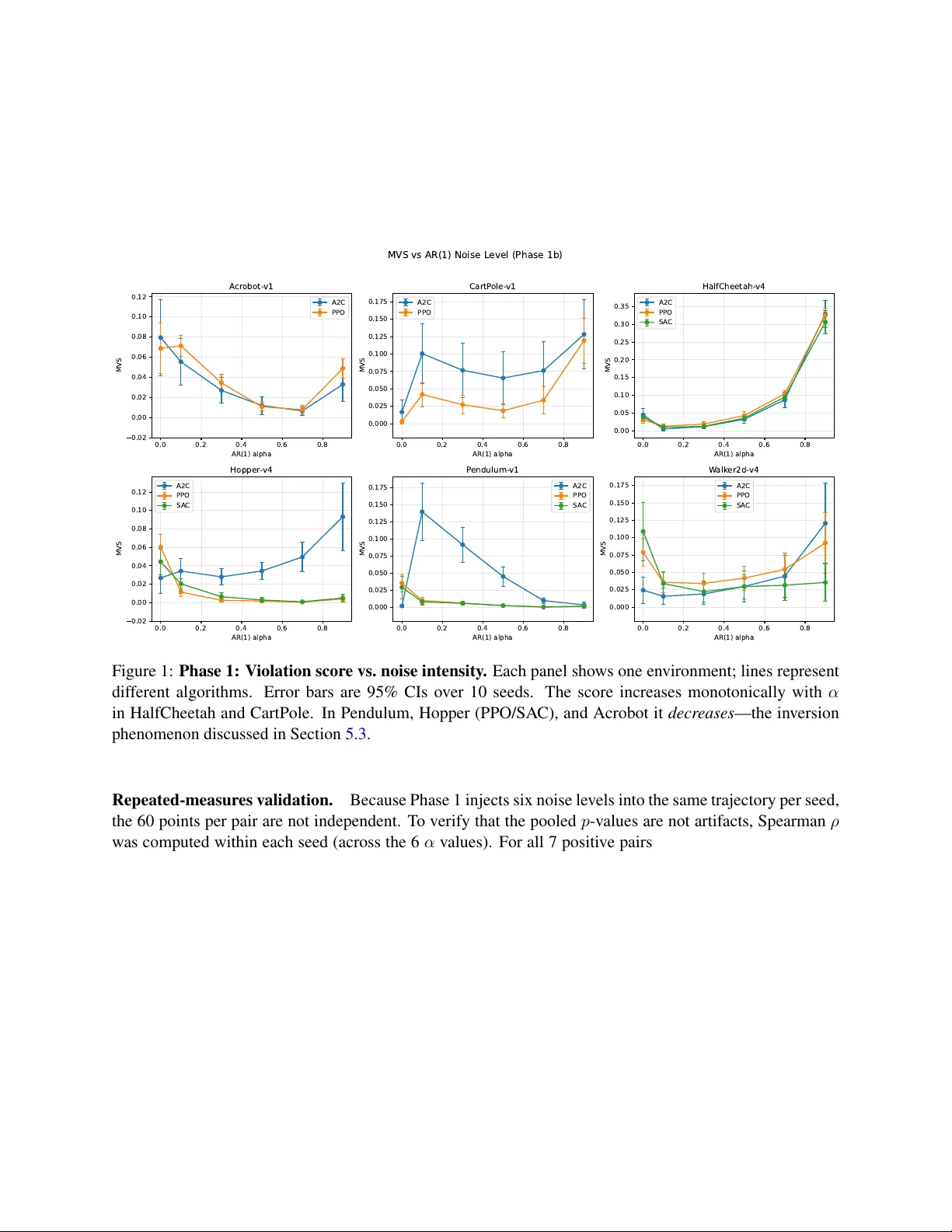
Diagnosing Non-Marko vian Observ ations in Reinforcement Learning via Prediction-Based V iolation Scoring Nav een Mysore 1,2 nmysore@ucsb.edu 1 Department of Electrical and Computer Engineering, Uni versity of California, Santa Barbara, USA 2 Dyssonance.ai Abstract Reinforcement learning algorithms assume that observations satisfy the Mark ov property , yet real- world sensors frequently violate this assumption through correlated noise, latency , or partial observabil- ity . Standard performance metrics conflate Markov breakdo wns with other sources of suboptimality , leaving practitioners without diagnostic tools for such violations. This paper introduces a prediction- based scoring method that quantifies non-Markovian structure in observ ation trajectories. A random forest first removes nonlinear Markov-compliant dynamics; ridge regression then tests whether histori- cal observ ations reduce prediction error on the residuals beyond what the current observation provides. The resulting score is bounded in [0 , 1] and requires no causal graph construction. Evaluation spans six en vironments (CartPole, Pendulum, Acrobot, HalfCheetah, Hopper, W alker2d), three algorithms (PPO, A2C, SAC), controlled AR(1) noise at six intensity lev els, and 10 seeds per condition. In post-hoc detection, 7 of 16 environment–algorithm pairs—primarily high-dimensional locomotion tasks—sho w significant positiv e monotonicity between noise intensity and the violation score (Spearman ρ up to 0 . 78 , confirmed under repeated-measures analysis); under training-time noise, 13 of 16 pairs exhibit sta- tistically significant rew ard degradation. An inv ersion phenomenon is documented in lo w-dimensional en vironments where the random forest absorbs the noise signal, causing the score to decrease as true violations grow—a failure mode analyzed in detail. A practical utility experiment demonstrates that the proposed score correctly identifies partial observability and guides architecture selection, fully recover - ing performance lost to non-Mark ovian observ ations. Source code to reproduce all results is provided at https://github.com/NAVEENMN/Markovianes . 1 Intr oduction Reinforcement learning (RL) algorithms ov erwhelmingly assume that observ ations satisfy the Marko v prop- erty: the current observation, together with the current action, is suf ficient to predict the distrib ution ov er next observations and re wards ( Sutton and Barto , 1998 ). This assumption underpins conv ergence guaran- tees, the policy gradient theorem, and the design of virtually all model-free and model-based methods. In practice, though, real-world observations are routinely corrupted by sensor noise, communication delays, and partial observ ability ( W isniewski et al. , 2024 ), an y of which can introduce temporal correlations that break the Marko v property . When that happens, value functions conditioned on the current state alone become systematically bi- ased, and policy gradients may point in wrong directions. The trouble is that standard ev aluation metrics— episodic return, sample efficienc y , con ver gence rate—cannot tell a practitioner why an agent is underper - forming. An agent struggling because its observ ations are non-Marko vian looks identical, by these metrics, 1 to one struggling with reward sparsity or function approximation error . Despite the practical importance of this failure mode, the RL community lacks standard diagnostic tools for detecting Mark ov violations in observ ation trajectories. This paper proposes a pr ediction-based violation scoring frame work to address this gap. The core idea is straightforward: first, a random forest captures whate ver structure is predictable from the current state– action pair alone; then, ridge regression checks whether lagged observations carry additional predictive signal about the residuals. If the y do, history matters and the Markov property is violated. The resulting score lies in [0 , 1] and requires no causal graph construction. Three main contributions are made. First, the two-stage scoring pipeline is dev eloped and ev aluated across six Gymnasium en vironments (CartPole, Pendulum, Acrobot, HalfCheetah, Hopper , W alker2d), three algorithms (PPO, A2C, SA C), six AR(1) noise intensities, and 10 seeds per condition—960 runs in total (Sections 4 and 5 ). Second, in the 7 en vironment–algorithm pairs where the score correctly tracks violations (Spearman ρ up to 0 . 78 ), higher scores correspond to worse policy performance, and 13 of 16 pairs show statistically significant re ward degradation under noise. Howe ver , an in version phenomenon is also observed in lo w-dimensional en vironments where the random forest absorbs the noise signal rather than leaving it for the second stage (Section 5.3 ). This in version was initially surprising, and its root cause is analyzed in detail, since understanding when the method fails is as important as demonstrating when it works. Third, the score is sho wn to be actionable: in a controlled partial-observability experiment on CartPole, a score- guided strategy that switches to a history-augmented policy when violations are detected fully recovers the lost performance (Section 5.6 ). The primary focus is diagnosis —gi ving practitioners a tool to answer “are my observ ations non-Markovian?”— rather than a complete remedy . That said, the utility experiment demonstrates that ev en a simple threshold on the violation score can dri ve architecture decisions with substantial impact on re ward. Paper organization. Section 2 surve ys related work. Section 3 introduces the Markov property and its connection to conditional independence. Section 4 defines the prediction-based scoring method. Section 5 presents experiments, including the utility demonstration. Section 6 discusses limitations, and Section 7 concludes. 2 Related W orks Robust RL and observ ation noise. Real-world RL deplo yments frequently encounter noisy or corrupted observ ations. The robust RL literature addresses this through adversarial training ( Pinto et al. , 2017 ), model- based methods for incomplete or noisy observations ( W ang et al. , 2019 ), and distributionally robust formu- lations ( Panaganti et al. , 2022 ; Liu et al. , 2022b ). Separately , the effect of correlated action noise on explo- ration and performance has been studied in continuous control ( Hollenstein et al. , 2024 ; 2022 ), and selecti ve noise injection has been proposed as a re gularizer to impro ve generalization ( Igl et al. , 2019 ). These lines of work all e valuate robustness or exploration quality through do wnstream task performance; none of them tell a practitioner whether or how sever ely the Markov property has been violated. Partial observability and POMDPs. When the full state is not directly observ able, the problem becomes a POMDP ( Lauri et al. , 2023 ). Solutions range from belief-state methods to identifying tractable POMDP subclasses with prov able sample efficiency ( Liu et al. , 2022a ). These methods can mitigate non-Markovian structure by maintaining history or exploiting structural assumptions, but they do not quantify how much history dependence is present in the first place. The present work is complementary: the proposed score diagnoses the violation; POMDP methods address it. 2 Conditional independence testing and Granger causality . The statistics literature provides many tools for testing conditional independence, from kernel-based tests ( Zhang et al. , 2011 ) to classifier-based ap- proaches. Granger causality ( Granger , 1969 ) asks whether past v alues of one series improve prediction of another—closely related to the approach taken here. Nonlinear extensions via neural networks ( T ank et al. , 2022 ) or random forests handle richer dynamics than linear methods. Our approach b uilds on this tradition but targets the RL setting specifically , where the question reduces to whether any historical observation helps predict the next state be yond what the current state already provides. Marko v property testing in RL. Directly testing the Markov property in RL trajectories has receiv ed limited attention. Shi et al. ( 2020 ) proposed a Forward-Backw ard Learning procedure that tests the Marko v assumption in sequential decision making without parametric assumptions on the joint distribution, with theoretical v alidity guarantees. Ho wev er , that test is designed for binary hypothesis testing (Markov or not) and does not produce a graded sev erity score. Constraint-based causal discov ery methods such as PCMCI ( Runge , 2022 ) can detect multi-lag dependencies; the framew ork supports both linear and nonlinear conditional independence tests, though the default partial-correlation test assumes linearity . Mysore ( 2025 ) applied PCMCI with partial correlation to quantify first-order Marko v violations in noisy RL, demonstrating that such diagnostics are useful but inheriting the linearity constraints of that specific test. The prediction- based approach proposed here sidesteps these issues: the random forest first stage is nonparametric, and history dependence is tested directly through prediction error comparison rather than graph construction. Positioning . Rob ust RL assumes violations exist and builds defenses; causal discovery infers graphical structure. The proposed method sits between the two, pro viding a single scalar answer to a more focused question: does the current observation suffice, or does history help? For an RL practitioner, that question is often more actionable than a full causal graph, and the prediction-based formulation handles nonlinear dynamics naturally . 3 Backgr ound 3.1 Marko v Property and Mark ov Decision Processes A discrete-time stochastic process { X t } ∞ t =0 satisfies the Markov pr operty if the future state X t +1 is condi- tionally independent of all prior states gi ven the current state: P X t +1 | X t , X t − 1 , . . . , X 0 = P X t +1 | X t . In RL, this applies to the state v ariable S t . When the en vironment is Markov , P S t +1 = s ′ , R t +1 = r | S t = s, A t = a, . . . , S 0 , A 0 = P S t +1 = s ′ , R t +1 = r | S t = s, A t = a , so only the current state S t and action A t determine what happens next. When noise or partial observ ability corrupts S t , the observed signal O t may no longer carry enough information, and higher-order dependencies can emer ge in the observ ation stream—ev en though the un- derlying state dynamics remain Markov . Detecting such observation-le vel dependencies is the central goal of this work. Throughout, “Markov violation” refers to non-Markovian structure in observ ations, not a breakdo wn of the latent state dynamics. 3 3.2 Conditional Independence as a T est f or Markov Structur e T wo random v ariables X and Y are conditionally independent gi ven Z if P ( X | Y , Z ) = P ( X | Z ) . The Marko v property is e xactly such a statement: S t +1 ⊥ ⊥ { S 0 , . . . , S t − 1 } | S t . Whenev er knowledge of past states improves prediction of the next state beyond what the current state provides, this independence is violated. This observ ation suggests a practical detection strate gy . Rather than constructing a causal graph or com- puting partial correlations, one can directly test whether historical observ ations carry predicti ve information that the current observ ation misses. The next section formalizes this idea. 4 Pr ediction-Based Markov V iolation Scoring This section describes the proposed violation score, a scalar that quantifies ho w much an observ ation trajec- tory departs from Markov . The method has two stages: first strip out whatever the current state can predict, then check whether past observ ations help explain what remains. 4.1 Stage 1: Nonlinear Markov Remo val Gi ven a trajectory of observati ons { o 1 , o 2 , . . . , o T } and actions { a 1 , a 2 , . . . , a T } , two sets of features are constructed. The Markov featur es x ( M ) t = [ o t , a t ] contain only the information that would suf fice if the process were Marko v . The history features x ( H ) t = [ o t , a t , o t − 1 , a t − 1 , . . . , o t − k +1 , a t − k +1 ] additionally include k − 1 lagged observation–action pairs. The target is always the ne xt observation y t = o t +1 . In Stage 1, a random forest regressor predicts y t from the Marko v features alone: ˆ y RF t = f RF x ( M ) t . The forest uses 200 trees with max depth 10 and a minimum of 5 samples per leaf. T o a void information leakage, residuals are computed using out-of-bag (OOB) predictions: r t = y t − ˆ y OOB t . After this stage, the residuals { r t } have been stripped of e verything predictable from the current observa- tion and action. Whatev er predictable structure remains must come from history—e xactly the signal that indicates a Marko v violation. 4.2 Stage 2: Ridge Comparison The residuals are split into training (first 70%) and test (last 30%) sets chronologically , and two ridge re- gressions are fit: Marko v ridge model. g M predicts residuals from Marko v features: ˆ r ( M ) t = g M x ( M ) t . This baseline picks up any linear Mark ov structure that the random forest may hav e missed. 4 History ridge model. g H predicts residuals from history features: ˆ r ( H ) t = g H x ( H ) t . If the process is truly Marko v , g H should do no better than g M . Both models use RidgeCV with 20 regularization v alues α ∈ { 10 − 2 , 10 − 1 . 6 , . . . , 10 5 } selected via leav e-one-out cross-v alidation (LOO). LOO on sequential data can leak temporal information through shared lagged features; block ed or rolling cross-v alidation would pro vide a stricter guard against this, at the cost of less ef ficient use of the training set. T est-set errors are: MSE M = 1 n test X t ∈T test r t − ˆ r ( M ) t 2 , MSE H = 1 n test X t ∈T test r t − ˆ r ( H ) t 2 . 4.3 Score Definition The Marko v V iolation Score (MVS) is the fractional reduction in prediction error from adding history: MVS = clip MSE M − MSE H MSE M , 0 , 1 . (1) A few properties are worth noting. The score is bounded in [0 , 1] by construction: negati ve v alues (where the history model performs worse, typically due to estimation noise in finite samples) are clipped to zero. When the process is Marko v , the history model g ains nothing and MVS ≈ 0 . Intuitiv ely , MVS measures the relati ve reduction in test-set prediction error from adding historical observations. The random forest first stage is important because it handles nonlinear-but-Mark ov dynamics (e.g., the trigonometric relationships in Pendulum) that would otherwise produce f alse positiv es. The ridge second stage, with cross-validated regularization, guards against o verfitting to spurious history correlations in finite samples. Design choices. A history depth of k = 3 (two additional lags beyond the current) is used, along with a 70/30 train–test split and per-dimension scoring av eraged across observation dimensions. AR(1) noise induces dependence at all lags (decaying as α ℓ ); k = 3 captures the strongest portion (lags 1–2) while keeping computation manageable. 4.4 AR(1) Noise as a Controlled Mark ov V iolation T o ev aluate the score under violations of known sev erity , autoregressiv e noise is injected into observ ations. At each time step, each dimension i is corrupted: ˜ o ( i ) t = o ( i ) t + z ( i ) t , z ( i ) t = α · z ( i ) t − 1 + ϵ ( i ) t , ϵ ( i ) t ∼ N (0 , 1) , where α ∈ [0 , 1) controls the autocorrelation. When α = 0 , the noise is i.i.d. and introduces no temporal correlation into the observation stream. (Strictly , ev en i.i.d. additiv e noise can make observ ations non- Marko v in the hidden-Marko v-model sense, since ˜ o t is a noisy function of the latent state; howe ver , no additional history dependence is created by the noise process itself, and the score is empirically near zero in this condition.) For α > 0 , the noise process z t carries information from previous time steps into ˜ o t , introducing temporal dependence that gro ws with α . An important distinction: the underlying en vironment dynamics remain Markov in the augmented state ( S t , z t ) . Howe ver , because the noise process z t is hidden from the agent, the observation stream { ˜ o t } is non-Marko v—the current corrupted observ ation alone does not determine the conditional distrib ution of the next. The proposed score targets exactly this observation-le vel non-Marko vity , which is what a practitioner encounters when working with sensor data. This setup gi ves two e xperimental phases: 5 1. Phase 1 (Post-hoc detection): Policies are trained on clean observ ations. AR(1) noise is injected into collected trajectories afterw ard, and the violation score is computed. This isolates detection capability from any polic y adaptation effects. 2. Phase 2 (T raining under noise): Policies are trained from scratch with AR(1) noise present through- out, measuring ho w Markov violations af fect learning. 5 Experiments and Results The proposed score is ev aluated across six RL en vironments, three algorithms, and six noise intensities. Phase 1 asks whether the score can detect controlled Markov violations in post-hoc trajectories; Phase 2 measures ho w those same violations affect polic y learning. 5.1 Experimental Setup En vironments. T able 1 summarizes the six environments, which span classic control and continuous lo- comotion from OpenAI Gymnasium ( T owers et al. , 2024 ). T able 1: En vironment summary . Observation dimensionality ranges from 3 (Pendulum) to 17 (HalfCheetah, W alker2d). SA C is used only for continuous-action en vironments. En vironment Obs. Dim Action Space Algorithms T raining Steps CartPole-v1 4 Discrete (2) PPO, A2C 50k Pendulum-v1 3 Continuous (1) PPO, A2C, SA C 450k Acrobot-v1 6 Discrete (3) PPO, A2C 50k HalfCheetah-v4 17 Continuous (6) PPO, A2C, SA C 1M Hopper-v4 11 Continuous (3) PPO, A2C, SA C 1M W alker2d-v4 17 Continuous (6) PPO, A2C, SA C 1M Algorithms. PPO ( Schulman et al. , 2017 ) and A2C are used across all six en vironments, with SA C ( Haarnoja et al. , 2018 ) additionally applied to the four continuous-action en vironments. SA C is e xcluded from Cart- Pole and Acrobot because the stable-baselines3 ( Raffin et al. , 2021 ) SA C implementation requires continuous action spaces. All agents use tw o-hidden-layer MLP policies, giving 16 en vironment–algorithm pairs in total. Noise protocol. AR(1) noise (Section 4.4 ) is applied to all observation dimensions at six autocorrelation le vels: α ∈ { 0 . 0 , 0 . 1 , 0 . 3 , 0 . 5 , 0 . 7 , 0 . 9 } . The α = 0 condition is the clean baseline. Seeds and e valuation. Every condition is run with 10 independent seeds. Means with 95% confidence interv als are reported, and significance is assessed via Spearman rank correlation (Phase 1) and W elch’ s t - test (Phase 2) at the p < 0 . 05 level. Because multiple en vironment–algorithm pairs are tested (16 in Phase 1, 15 in Phase 2), Benjamini–Hochber g f alse disco very rate (FDR) correction is applied; significance counts reported throughout refer to FDR-adjusted q -values. 6 5.2 Phase 1: Score Sensitivity to Noise Intensity Policies are first trained on clean observations. After training, trajectories are collected, AR(1) noise is injected post-hoc at each α le vel, and the violation score is computed. This design isolates detection from any confounding polic y adaptation. Figure 1 plots MVS against α for all 16 pairs. T able 2 giv es the Spearman correlations. 0.0 0.2 0.4 0.6 0.8 AR(1) alpha 0.02 0.00 0.02 0.04 0.06 0.08 0.10 0.12 MVS A cr obot- v1 A2C PPO 0.0 0.2 0.4 0.6 0.8 AR(1) alpha 0.000 0.025 0.050 0.075 0.100 0.125 0.150 0.175 MVS CartP ole- v1 A2C PPO 0.0 0.2 0.4 0.6 0.8 AR(1) alpha 0.00 0.05 0.10 0.15 0.20 0.25 0.30 0.35 MVS HalfCheetah- v4 A2C PPO S A C 0.0 0.2 0.4 0.6 0.8 AR(1) alpha 0.02 0.00 0.02 0.04 0.06 0.08 0.10 0.12 MVS Hopper - v4 A2C PPO S A C 0.0 0.2 0.4 0.6 0.8 AR(1) alpha 0.000 0.025 0.050 0.075 0.100 0.125 0.150 0.175 MVS P endulum- v1 A2C PPO S A C 0.0 0.2 0.4 0.6 0.8 AR(1) alpha 0.000 0.025 0.050 0.075 0.100 0.125 0.150 0.175 MVS W alk er2d- v4 A2C PPO S A C MVS vs AR(1) Noise L evel (Phase 1b) Figure 1: Phase 1: V iolation score vs. noise intensity . Each panel shows one en vironment; lines represent dif ferent algorithms. Error bars are 95% CIs over 10 seeds. The score increases monotonically with α in HalfCheetah and CartPole. In Pendulum, Hopper (PPO/SAC), and Acrobot it decreases —the inv ersion phenomenon discussed in Section 5.3 . Repeated-measures validation. Because Phase 1 injects six noise le vels into the same trajectory per seed, the 60 points per pair are not independent. T o verify that the pooled p -v alues are not artifacts, Spearman ρ was computed within each seed (across the 6 α values). For all 7 positive pairs, all 10 seeds show positiv e ρ (sign-test p = 0 . 002 ). Page’ s L trend test—which directly tests ordered alternatives under repeated measures—confirms significance for all 7 ( p < 10 − 4 ), with within-seed median ρ from 0 . 54 to 0 . 83 . Specificity check. The score was also computed on trajectories from random (untrained) policies under the same noise. Random-policy scores are near zero ev erywhere, confirming that the method does not fire on unstructured trajectories. The nonzero scores seen in trained-policy runs reflect a genuine interaction between the AR(1) noise and the structure that the learned policy imposes on trajectories. A stronger speci- ficity test—Marko v but nonlinear dynamics with i.i.d. noise under trained policies—is left to future work. 5.3 In verted Scores: When Detection F ails In eight of 16 pairs, the score moves in the wr ong direction: it decr eases as α increases (T able 2 ). This was initially surprising and prompted a detailed in vestigation. 7 T able 2: Phase 1 monotonicity . Spearman ρ between noise intensity α and violation score, pooled across seeds ( n = 60 per pair). Sev en pairs show the expected positiv e trend (HalfCheetah strongest at ρ = 0 . 78 ). Eight sho w significant inv ersion. See text for repeated-measures analysis that accounts for within-seed dependence. En vironment Algorithm Spearman ρ p -value Dir ection P ositive monotonicity (7 pairs): HalfCheetah-v4 PPO 0.776 < 10 − 12 ✓ HalfCheetah-v4 SA C 0.700 < 10 − 9 ✓ HalfCheetah-v4 A2C 0.664 < 10 − 8 ✓ CartPole-v1 PPO 0.554 < 10 − 5 ✓ Hopper-v4 A2C 0.520 < 10 − 4 ✓ W alker2d-v4 A2C 0.507 < 10 − 4 ✓ CartPole-v1 A2C 0.447 < 10 − 3 ✓ In verted (8 pairs): Pendulum-v1 PPO − 0 . 760 < 10 − 12 × Pendulum-v1 SA C − 0 . 756 < 10 − 12 × Hopper-v4 SA C − 0 . 724 < 10 − 10 × Hopper-v4 PPO − 0 . 643 < 10 − 7 × Acrobot-v1 PPO − 0 . 497 < 10 − 4 × Acrobot-v1 A2C − 0 . 466 < 10 − 3 × W alker2d-v4 SA C − 0 . 330 0 . 010 × Pendulum-v1 A2C − 0 . 280 0 . 030 × Not significant (1 pair): W alker2d-v4 PPO 0.070 0 . 596 — 8 Root cause. The problem lies in Stage 1. In lo w-dimensional en vironments with highly regular trained- policy trajectories, the random forest is flexible enough to fit not just the true Marko v dynamics but also the AR(1) noise pattern riding on top of them. Once the RF captures that noise structure, the residuals are scrubbed of the very signal Stage 2 needs. As α grows and the noise becomes a larger fraction of the total signal, the RF fits it more aggressi vely—hence the in verted relationship. When it happens. T wo factors predict inv ersion: (1) low observation dimensionality , which gives the RF fewer features and makes noise patterns easier to memorize, and (2) highly structured clean-policy trajectories, which provide a regular backdrop against which AR(1) noise stands out. HalfCheetah, with 17 dimensions and noisier dynamics, is largely immune. Implications. This is a fundamental limitation of any two-stage design where the first stage is flexible enough to absorb the violation signal. Potential mitigations—restricting RF capacity , using a linear first stage in lo w-dimensional settings, ensemble strategies—are discussed in Section 6 . 5.4 Phase 2: Impact of Markov V iolations on Reward Phase 2 asks whether the violations the proposed score is designed to detect actually matter for learning. Agents are trained from scratch with AR(1) noise present throughout. Clean ( α = 0 ) versus heavily noised ( α = 0 . 9 ) final reward is compared using W elch’ s t -test across 10 seeds. Figure 2 plots re ward against α ; T able 3 gives the statistical comparisons. 0.0 0.2 0.4 0.6 0.8 AR(1) alpha 400 350 300 250 200 150 100 50 R ewar d A cr obot- v1 A2C PPO 0.0 0.2 0.4 0.6 0.8 AR(1) alpha 100 200 300 400 500 R ewar d CartP ole- v1 A2C PPO 0.0 0.2 0.4 0.6 0.8 AR(1) alpha 0 2000 4000 6000 8000 10000 R ewar d HalfCheetah- v4 A2C PPO S A C 0.0 0.2 0.4 0.6 0.8 AR(1) alpha 0 500 1000 1500 2000 2500 3000 R ewar d Hopper - v4 A2C PPO S A C 0.0 0.2 0.4 0.6 0.8 AR(1) alpha 1400 1200 1000 800 600 400 200 R ewar d P endulum- v1 A2C PPO S A C 0.0 0.2 0.4 0.6 0.8 AR(1) alpha 0 1000 2000 3000 4000 R ewar d W alk er2d- v4 A2C PPO S A C R ewar d vs AR(1) Noise L evel (Phase 2) Figure 2: Phase 2: Reward vs. noise intensity . AR(1) noise during training degrades final performance across nearly all conditions. The worst collapses: HalfCheetah-SA C drops from 8920 to − 42 ; W alker2d- SA C from 4244 to 318; CartPole-PPO from 500 to 53. The damage is substantial. The worst-hit condition, HalfCheetah-SA C, collapses from 8920 to − 42 — essentially complete failure. W alker2d-SA C drops 93% (4244 to 318), CartPole-PPO 89% (500 to 53). The 9 T able 3: Phase 2: W elch’s t -test. Clean ( α = 0 ) vs. noised ( α = 0 . 9 ) re ward, 10 seeds. Thirteen of 16 pairs sho w significant degradation after Benjamini–Hochberg FDR correction ( q < 0 . 05 ). Re wards rounded to integers. En vironment Algorithm Clean Reward Noised Reward t -stat Significant CartPole-v1 PPO 500 53 94.3 Y es Pendulum-v1 PPO − 166 − 1191 57.4 Y es Pendulum-v1 SA C − 133 − 1134 48.2 Y es HalfCheetah-v4 SA C 8920 − 42 22.1 Y es W alker2d-v4 SA C 4244 318 21.3 Y es W alker2d-v4 PPO 2587 227 10.2 Y es HalfCheetah-v4 PPO 1654 336 9.25 Y es CartPole-v1 A2C 408 50 9.24 Y es Hopper-v4 SA C 2574 432 7.53 Y es Hopper-v4 PPO 2487 418 7.24 Y es Hopper-v4 A2C 169 67 5.22 Y es HalfCheetah-v4 A2C 893 193 4.70 Y es Pendulum-v1 A2C − 901 − 1292 3.41 Y es Acrobot-v1 PPO − 88 − 217 2.31 No ( q = 0 . 053 ) W alker2d-v4 A2C 186 112 1.95 No ( q = 0 . 08 ) Acrobot-v1 A2C − 286 − 150 − 2 . 09 No ( q = 0 . 07 ) three non-significant pairs after FDR correction are all borderline ( q < 0 . 08 ) and in volv e either A2C in en vironments where it already performs modestly , or Acrobot where the absolute re ward scale is small. A ca veat: AR(1) noise with larger α has higher marginal v ariance, so part of the degradation may reflect noise power rather than temporal correlation per se. Matching marginal v ariance across α while varying only autocorrelation would isolate the non-Markov contrib ution; this more controlled design is left to future work. 5.5 Combined Analysis Phase 1 and Phase 2 independently establish two facts: the score tracks violation se verity in high-dimensional en vironments (Spearman ρ up to 0 . 78 , 60 observations per pair), and those same violations degrade rew ard (13 of 16 pairs significant after FDR correction). Figure 3 puts the two together by plotting Phase 1 violation scores against Phase 2 re ward ratio for each condition. The scatter rev eals a clear pattern: in en vironments where the score w orks correctly—primarily high- dimensional ones like HalfCheetah—points fan out to the right with increasing noise, and higher scores correspond to worse re ward. In in verted en vironments, the score stays near zero reg ardless of noise level, so rew ard de grades without a corresponding signal. This is consistent with the in version mechanism from Section 5.3 . The qualitativ e takea way is that the proposed method is most informative in en vironments where the random forest cannot easily memorize the noise—precisely the higher-dimensional settings where diagnosis is most needed. 5.6 Practical Utility: Score-Guided Ar chitecture Selection The results so f ar show that the proposed score detects violations and that violations hurt re ward. But can a practitioner actually use the score? This is tested with a simple architecture-selection experiment: choose between a standard memoryless policy and one that recei ves a windo w of recent observ ations. 10 0.00 0.05 0.10 0.15 0.20 0.25 0.30 MVS (Phase 1b) 0 2 4 6 8 R ewar d R atio (vs clean baseline) MVS vs R ewar d Degradation Spear man r ho=-0.350, p=0.0015 A cr obot- v1 CartP ole- v1 HalfCheetah- v4 Hopper - v4 P endulum- v1 W alk er2d- v4 Figure 3: Combined: V iolation score vs. reward ratio. Each point is one en vironment–algorithm–noise- le vel condition. In en vironments where the score correctly tracks violations (e.g., HalfCheetah, CartPole), higher scores correspond to lo wer reward. In verted pairs cluster near score ≈ 0 regardless of re ward loss. Setup. CartPole-v1 is used under two observation conditions. In the full condition the agent sees all four state variables (position, velocity , angle, angular v elocity). In the masked condition the two velocities are zeroed out, leaving only positions—a clean partial-observability setting where the current observation alone cannot determine the next state. For each condition, both a standard MLP polic y and a history-augmented policy (current plus two prior observ ations concatenated) are trained. All runs use PPO, 100k steps, 5 seeds, 20 e valuation episodes. Detection results. T able 4 shows the violation score computed on trajectories from both random and trained policies. T able 4: Detection of partial observability . Masking velocities creates non-Markov observ ations. The score is near zero for full observ ations and rises to 0 . 42 under masking with a trained policy , correctly flagging the violation. Observation Random Policy Scor e T rained Policy Scor e Full (4D) 0.000 0.000 Masked (positions only) 0.002 0.421 The score correctly flags the masked condition ( 0 . 42 ) and confirms that full observations are Mark ov ( 0 . 00 ). Interestingly , the signal is much stronger under a trained policy than a random one ( 0 . 42 vs. 0 . 002 ), likely because a trained policy concentrates on a narro w re gion of state space where the missing v elocity information matters more. Architectur e selection. T able 5 shows what happens when the detection signal is acted upon. The takeaw ay is clear . When observ ations are Markov ( score = 0 ), a standard policy suffices and adding 11 T able 5: Architectur e selection results. Under full observations both policies hit 500. Under masking the standard policy collapses while the history-augmented policy fully recovers. PPO, 100k steps, 5 seeds, 20 e valuation episodes. Observation P olicy Mean Reward Std Full Standard 500.0 0.0 Full History-augmented 500.0 0.0 Masked Standard 43.1 1.2 Masked History-augmented 500.0 0.0 history b uys nothing. When observ ations are non-Markov ( score = 0 . 42 ), the standard policy collapses to re ward 43—a 91% drop—while the history-augmented polic y recov ers fully to 500. A simple rule—use the standard architecture when the score is near zero, switch to history augmentation otherwise—gets optimal performance in both cases without adding unnecessary complexity . 6 Limitations and Futur e Directions Score in version in low-dimensional en vironments. The most significant limitation is the in version phe- nomenon documented in Section 5.3 : in 8 of 16 en vironment–algorithm pairs, the violation score decr eases as the true violation gro ws stronger . Because the random forest in Stage 1 is flexible enough to absorb the noise signal itself, the residuals end up cleaner than the y should be—and Stage 2 finds nothing. This is not an implementation bug but a fundamental tension in any two-stage approach with a powerful first stage. Sev eral directions seem worth exploring: restricting forest capacity (fewer trees, shallower depth) so it cannot latch onto temporal noise patterns; falling back to a linear first stage in low-dimensional settings where Markov dynamics are roughly linear an yway; ensembling across Stage 1 models of v arying capac- ity; or collapsing to a single-stage direct comparison between Marko v and history models, accepting higher false-positi ve rates in nonlinear -but-Marko v systems. AR(1) noise as the sole violation type. The method has been tested exclusiv ely against AR(1) observation noise. AR(1) provides a clean, parameterized violation whose sev erity is controlled, b ut real-world non- Marko v structure comes from many sources: sensor latency , frame stacking artifacts, communication delays, and genuinely missing state dimensions. Whether the proposed approach generalizes to these settings is an open question. Frame stacking is especially interesting—it introduces a qualitati vely different kind of history dependence that may be easier or harder to detect than smooth autocorrelation. From diagnosis to remedy . Section 5.6 shows that the violation score can guide architecture selection in a controlled setting, b ut fully closing the loop remains open. The score could potentially run as an online diagnostic during training, triggering adaptiv e responses—switching to a history-augmented architecture when the score crosses a threshold, adjusting learning rates, or informing sensor suite design by comparing scores across observ ation configurations. That said, the in version problem must be resolved before the method can serve as a reliable online signal in all en vironments. Scalability . The pipeline requires collecting a trajectory , computing random forest predictions, and fitting ridge regressions. All steps scale linearly in trajectory length and polynomially in observ ation dimensional- ity . For the en vironments tested (up to 17 dimensions), computation is negligible next to RL training time. 12 Scaling to image observations would require a representation learning step before applying the scoring method, which introduces its o wn assumptions and potential failure modes. Algorithm coverage. PPO, A2C, and SA C—representativ e on-polic y and off-polic y methods—are ev alu- ated here. Ho w Mark ov violations interac t with model-based RL, offline RL, or multi-agent settings remains unexplored. Model-based methods are particularly interesting: their explicit dynamics models could either amplify non-Marko v noise or partially compensate for it. Cross-v alidation and noise design. Stage 2 selects ridge regularization via leav e-one-out cross-v alidation. Because adjacent time points share lagged features, LOO can leak temporal information; blocked or rolling CV w ould pro vide a stricter protocol. Additionally , AR(1) noise with larger α has higher mar ginal variance, so Phase 2 rew ard de gradation conflates temporal correlation with noise po wer . A design matching marginal v ariance across α while varying only autocorrelation woul d isolate the non-Markov contrib ution. Theoretical guarantees. The proposed score currently lacks formal statistical guarantees. The two-stage procedure creates dependencies between the residuals and the ridge models that complicate standard hypoth- esis testing. Establishing T ype I and T ype II error rates, or connecting the score to conditional independence tests with kno wn power properties, would put the method on firmer theoretical ground. 7 Conclusion A prediction-based scoring framework is introduced that quantifies non-Marko vian structure in RL obser- v ation trajectories. The two-stage approach—random forest residualization followed by ridge regression comparison—yields a bounded, interpretable scalar: zero when the process is Markov , increasing with the se verity of history dependence. Across six en vironments, three algorithms, and controlled AR(1) noise, the proposed method success- fully detects violations in 7 of 16 en vironment–algorithm pairs, with Spearman correlations up to ρ = 0 . 78 between noise intensity and the score. In these environments, higher scores correspond to worse policy performance. Phase 2 results confirm that these violations hav e real consequences: 13 of 16 pairs show statistically significant reward de gradation under noise. In a practical utility experiment, the score is shown to guide architecture selection—when partial observability renders observations non-Mark ovian, it flags the problem and a history-augmented policy chosen accordingly recovers the lost performance entirely . At the same time, an in version phenomenon in low-dimensional environments limits detection in nearly half the tested conditions, pointing to a fundamental tension between flexible first-stage modeling and preserving the signal that the second stage needs. The candid analysis of when the method works and when it does not is a contribution in its own right. Reliable detection of history dependence is a prerequisite for principled mitigation, and understanding why prediction-based approaches fail in certain regimes should inform the design of more robust diagnostics going forward. Refer ences C. W . J. Granger . In vestigating Causal Relations by Econometric Models and Cross-spectral Methods. Econometrica , 37(3):424–438, 1969. doi: 10.2307/1912791. 13 T uomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Le vine. Soft Actor-Critic: Of f-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor, August 2018. URL http://arxiv. org/abs/1801.01290 . arXiv:1801.01290 [cs]. Jakob Hollenstein, Sayantan Auddy , Matteo Sav eriano, Erwan Renaudo, and Justus Piater . Action Noise in Off-Polic y Deep Reinforcement Learning: Impact on Exploration and Performance. T ransactions on Machine Learning Resear ch , June 2022. doi: 10.48550/arXiv .2206.03787. URL https://arxiv. org/abs/2206.03787 . arXiv:2206.03787 [cs.LG]. Jakob Hollenstein, Georg Martius, and Justus Piater . Colored Noise in PPO: Improv ed Exploration and Performance through Correlated Action Sampling. Pr oceedings of the AAAI Confer ence on Artificial Intelligence , 38(11):12466–12472, March 2024. ISSN 2374-3468, 2159-5399. doi: 10.1609/aaai.v38i11. 29139. URL . arXiv:2312.11091 [cs]. Maximilian Igl, Kamil Ciosek, Y ingzhen Li, Sebastian Tschiatschek, Cheng Zhang, Sam Devlin, and Katja Hofmann. Generalization in Reinforcement Learning with Selectiv e Noise Injection and Information Bottleneck. In Advances in Neural Information Pr ocessing Systems , volume 32. Curran Associates, Inc., 2019. doi: 10.48550/arXiv .1910.12911. URL https://proceedings.neurips.cc/paper/ 2019/hash/e2ccf95a7f2e1878fcafc8376649b6e8- Abstract.html . arXi v:1910.12911 [cs.LG]. Mikko Lauri, Da vid Hsu, and Joni Pajarinen. Partially Observ able Marko v Decision Processes in Robotics: A Surve y . IEEE T ransactions on Robotics , 39(1):21–40, February 2023. ISSN 1552-3098, 1941- 0468. doi: 10.1109/TR O.2022.3200138. URL https://ieeexplore.ieee.org/document/ 9899480/ . Qinghua Liu, Alan Chung, Csaba Szepesvari, and Chi Jin. When Is Partially Observ able Reinforcement Learning Not Scary? In Pr oceedings of Thirty F ifth Conference on Learning Theory , pages 5175–5220. PMLR, June 2022a. URL https://proceedings.mlr.press/v178/liu22f.html . ISSN: 2640-3498. Zijian Liu, Qinxun Bai, Jose Blanchet, Perry Dong, W ei Xu, Zhengqing Zhou, and Zhengyuan Zhou. Dis- tributionally Robust $Q$-Learning. In Pr oceedings of the 39th International Confer ence on Machine Learning , pages 13623–13643. PMLR, June 2022b. URL https://proceedings.mlr.press/ v162/liu22a.html . ISSN: 2640-3498. Nav een Mysore. Quantifying first-order marko v violations in noisy reinforcement learning: A causal dis- cov ery approach. arXiv pr eprint , arXiv:2503.00206, February 2025. doi: 10.48550/arXi v .2503.00206. URL . Kishan Panaganti, Zaiyan Xu, Dileep Kalathil, and Mohammad Ghav amzadeh. Rob ust Reinforce- ment Learning using Of fline Data, October 2022. URL . arXi v:2208.05129 [cs]. Lerrel Pinto, James Da vidson, Rahul Sukthankar , and Abhina v Gupta. Robust Adversarial Reinforcement Learning. In Pr oceedings of the 34th International Conference on Machine Learning , pages 2817–2826. PMLR, July 2017. URL https://proceedings.mlr.press/v70/pinto17a.html . ISSN: 2640-3498. Antonin Raffin, Ashley Hill, Adam Gleav e, Anssi Kanervisto, Maximilian Ernestus, and Noah Dorber . Stable-Baselines3: Reliable reinforcement learning implementations. J ournal of Mac hine Learning Re- sear ch , 22(268):1–8, 2021. 14 Jakob Runge. Discovering contemporaneous and lagged causal relations in autocorrelated nonlinear time series datasets, January 2022. URL . [stat]. John Schulman, Filip W olski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov . Proximal Pol- icy Optimization Algorithms, August 2017. URL . arXi v:1707.06347 [cs]. Chengchun Shi, Runzhe W an, Rui Song, W enbin Lu, and Ling Leng. Does the Marko v Decision Process Fit the Data: T esting for the Markov Property in Sequential Decision Making. In Pr oceedings of the 37th International Conference on Mac hine Learning , pages 8807–8817. PMLR, November 2020. URL https://proceedings.mlr.press/v119/shi20c.html . ISSN: 2640-3498. Richard S Sutton and Andre w G Barto. Reinfor cement Learning: An Intr oduction . The MIT Press, Cam- bridge, MA, 1998. Alex T ank, Ian Covert, Nicholas Foti, Ali Shojaie, and Emily B. Fox. Neural Granger Causality. IEEE T ransactions on P attern Analysis and Machine Intelligence , 44(8):4267–4279, August 2022. doi: 10. 1109/TP AMI.2021.3065601. Epub 2022 Jul 1. PMID: 33705309; PMCID: PMC9739174. Mark T o wers, Ariel Kwiatk owski, Jordan T erry , John U. Balis, Gianluca De Cola, T ristan Deleu, Manuel Goulão, Andreas Kallinteris, Markus Krimmel, Arjun KG, Rodrigo Perez-V icente, Andrea Pierré, Sander Schulhoff, Jun Jet T ai, Hannah T an, and Omar G. Y ounis. Gymnasium: A Standard Inter- face for Reinforcement Learning En vironments. arXiv pr eprint arXiv:2407.17032 , July 2024. doi: 10.48550/arXi v .2407.17032. URL . [cs.LG]. Y uhui W ang, Hao He, and Xiaoyang T an. Robust Reinforcement Learning in POMDPs with Incom- plete and Noisy Observations, February 2019. URL . arXi v:1902.05795 [cs]. Mariusz W isniewski, Paraske vas Chatzithanos, W eisi Guo, and Antonios Tsourdos. Benchmarking Deep Reinforcement Learning for Navigation in Denied Sensor En vironments, October 2024. URL http: //arxiv.org/abs/2410.14616 . arXiv:2410.14616 [cs]. Kun Zhang, Jonas Peters, Dominik Janzing, and Bernhard Schölkopf. Kernel-based Conditional Indepen- dence T est and Application in Causal Discov ery . In Pr oceedings of the T wenty-Seventh Confer ence on Uncertainty in Artificial Intelligence , pages 804–813, February 2011. doi: 10.48550/arXiv .1202.3775. URL . arXiv:1202.3775 [cs.LG]. A Declaration of LLM Usage Large language models (GPT -4, Claude) were used during manuscript preparation for grammar correction and revising passiv e v oice constructions. All scientific content, experimental design, implementation, and analysis are the sole work of the author . 15 B Implementation and Repr oducibility Details All RL agents are trained using Stable-Baselines3 ( Raffin et al. , 2021 ) with def ault hyperparameters for each algorithm (PPO, A2C, SAC). The AR(1) noise wrapper , MVS computation pipeline, and analysis scripts are av ailable in the supplementary source code. Random seeds are fix ed for reproducibility; each condition is e valuated o ver 10 independent seeds. 16
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment