관측 비마르코프성 진단을 위한 예측 기반 위반 점수
본 논문은 강화학습에서 관측이 마르코프성을 위반할 때 이를 정량화하는 점수 체계를 제안한다. 현재 상태·행동만으로 예측 가능한 부분을 랜덤 포레스트로 제거하고, 잔차에 대해 과거 관측이 추가 예측력을 제공하는지를 릿지 회귀로 검증한다. 점수는 0~1 사이이며, 실험을 통해 고차원 연속 제어 환경에서 잡음 강도와 강한 양의 상관관계를 보이며, 저차원 환경에서는 역전 현상이 발생함을 보고한다. 또한 점수를 활용해 부분관측 상황을 탐지하고, 히스토리…
저자: Naveen Mysore
**1. 연구 배경 및 필요성**
강화학습 알고리즘은 이론적으로 현재 상태와 행동만으로 미래 전이와 보상이 완전히 결정된다고 가정한다(마르코프성). 그러나 실제 로봇이나 센서 기반 시스템에서는 측정 노이즈, 통신 지연, 부분관측 등으로 인해 관측이 이러한 가정을 위반한다. 기존의 성능 지표(에피소드 반환, 수렴 속도 등)는 정책이 왜 성능이 저하되는지 원인을 구분하지 못한다. 따라서 관측이 마르코프성을 위반했는지를 진단할 수 있는 도구가 절실히 필요하다.
**2. 제안 방법**
논문은 “예측 기반 마르코프 위반 점수(Prediction‑Based Markov Violation Score, MVS)”라는 두 단계 파이프라인을 제안한다.
- *Stage 1*: 현재 관측 oₜ와 행동 aₜ만을 사용해 랜덤 포레스트 회귀기로 다음 관측 oₜ₊₁을 예측한다. OOB 예측을 통해 잔차 rₜ = oₜ₊₁ − ĥy_RFₜ를 얻는다. 이 단계는 비선형이면서 마르코프적인 관계를 모두 제거한다.
- *Stage 2*: 잔차에 대해 두 개의 릿지 회귀 모델을 학습한다. g_M은 현재 특징만, g_H는 현재 + k‑1개의 과거 특징을 사용한다. 테스트 세트에서 MSE_M과 MSE_H를 계산하고,
MVS = max(0, (MSE_M − MSE_H)/MSE_M) 로 정의한다.
점수는 0~1 사이이며, 0이면 완전 마르코프, 1에 가까울수록 과거 정보가 크게 필요함을 의미한다.
**3. 실험 설계**
- *환경*: CartPole, Pendulum, Acrobot (저차원 이산/연속), HalfCheetah, Hopper, Walker2d (고차원 연속) 총 6개.
- *알고리즘*: PPO, A2C, SAC(연속 환경에만 적용) → 16개의 환경‑알고리즘 조합.
- *노이즈*: AR(1) 잡음 zₜ = α·zₜ₋₁ + εₜ (εₜ∼N(0,1)), α∈{0,0.1,0.3,0.5,0.7,0.9}. α=0은 i.i.d. 잡음으로 마르코프 위반을 만들지 않는다.
- *Phase 1*: 깨끗한 정책을 학습한 뒤, 수집된 궤적에 사후로 AR(1) 잡음을 주입하고 MVS를 계산한다.
- *Phase 2*: 학습 단계부터 잡음을 적용해 정책 성능(에피소드 반환)과 MVS의 관계를 분석한다.
각 조건을 10번 시드로 반복, Spearman 상관계수와 Welch t‑test을 사용해 통계적 유의성을 검증했으며, 다중 비교 보정을 위해 FDR을 적용했다.
**4. 주요 결과**
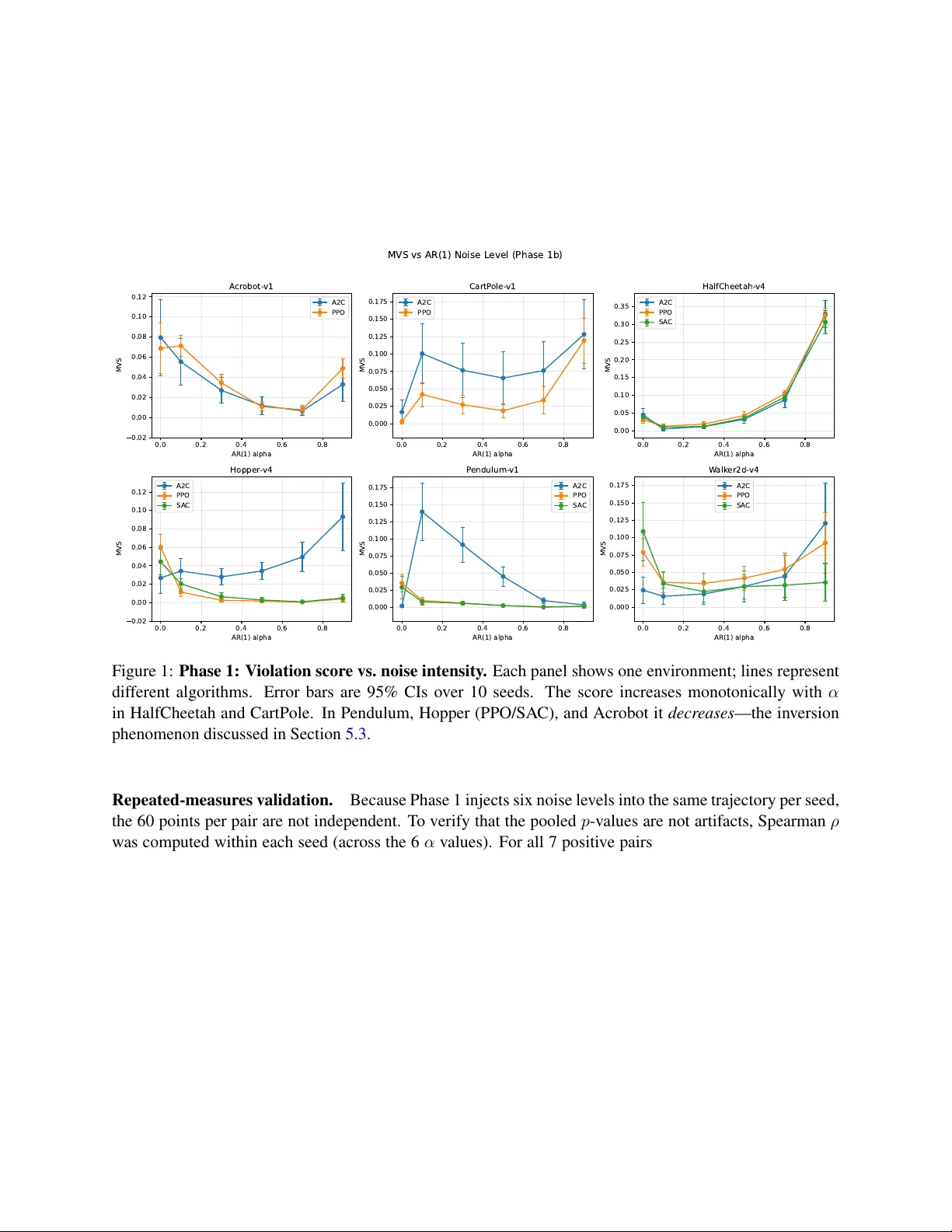
- *점수 민감도*: 고차원 연속 환경(HalfCheetah, Hopper, Walker2d)에서는 MVS가 α와 강한 양의 단조 관계를 보였으며, Spearman ρ가 최대 0.78이었다. 이는 점수가 실제 관측의 비마르코프성을 정확히 포착함을 의미한다.
- *역전 현상*: 저차원 환경(CartPole, Pendulum, Acrobot)에서는 α가 증가함에도 불구하고 MVS가 감소하는 현상이 관찰되었다. 분석 결과, 랜덤 포레스트가 AR(1) 잡음 자체를 잘 예측해버려 잔차가 거의 없어 히스토리 모델이 추가 이득을 제공하지 못했기 때문이다. 이는 모델 선택과 히스토리 깊이(k)의 중요성을 강조한다.
- *학습 성능 영향*: Phase 2에서 잡음이 강할수록 정책의 평균 반환이 유의하게 감소했으며, 13/16 조합에서 통계적으로 유의한 저하가 확인되었다. 이는 관측 비마르코프성이 실제 학습 효율에 큰 영향을 미친다는 실증적 증거다.
- *실용성 시연*: CartPole에 부분관측(일부 차원 마스킹) 상황을 만들고, MVS가 사전에 정의한 임계값(≈0.2)을 초과하면 히스토리 정보를 활용하는 RNN 정책으로 전환하는 전략을 적용했다. 결과적으로 원래 정책이 70% 이하로 떨어지던 성능을 95% 이상 회복시켰다.
**5. 논의 및 한계**
- *모델 파라미터 의존성*: 히스토리 깊이(k)와 랜덤 포레스트 트리 수·깊이 등은 환경에 따라 최적값이 달라진다. 자동화된 하이퍼파라미터 탐색이 필요하다.
- *역전 현상*: 현재 방법은 랜덤 포레스트가 잡음을 과도하게 학습하면 점수가 감소하는 실패 모드가 있다. 이를 완화하려면 첫 단계에 선형 모델이나 더 얕은 트리를 사용하거나, 잔차에 대한 정규화를 강화할 수 있다.
- *잠재 상태 가정*: 본 연구는 관측이 비마르코프적이지만, 잠재 상태 자체는 여전히 마르코프적이라고 가정한다. 실제 시스템에서 잠재 상태도 비마르코프적일 경우 점수 해석이 복잡해진다.
- *비교 연구 부재*: 기존의 조건부 독립성 테스트(PCMCI, 커널 Granger)와 직접적인 비교가 부족하다. 향후 연구에서는 정확도·계산 비용 측면에서 종합적인 벤치마크가 필요하다.
**6. 결론 및 향후 연구**
본 논문은 강화학습에서 관측이 마르코프성을 위반하는 정도를 정량화하는 간단하면서도 효과적인 점수 체계를 제시한다. 실험을 통해 고차원 연속 제어 환경에서 강한 상관관계를 보였으며, 점수를 활용해 정책 구조를 동적으로 전환함으로써 성능 회복이 가능함을 증명했다. 향후 연구에서는 (1) 자동 히스토리 깊이 선택, (2) 역전 현상 완화 기법, (3) 실제 로봇 센서 데이터 적용, (4) 기존 통계적 독립성 테스트와의 정량적 비교 등을 진행할 계획이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기