A Comparative Study in Surgical AI: Datasets, Foundation Models, and Barriers to Med-AGI
Recent Artificial Intelligence (AI) models have matched or exceeded human experts in several benchmarks of biomedical task performance, but have lagged behind on surgical image-analysis benchmarks. Since surgery requires integrating disparate tasks -…
Authors: Kirill Skobelev, Eric Fithian, Yegor Baranovski
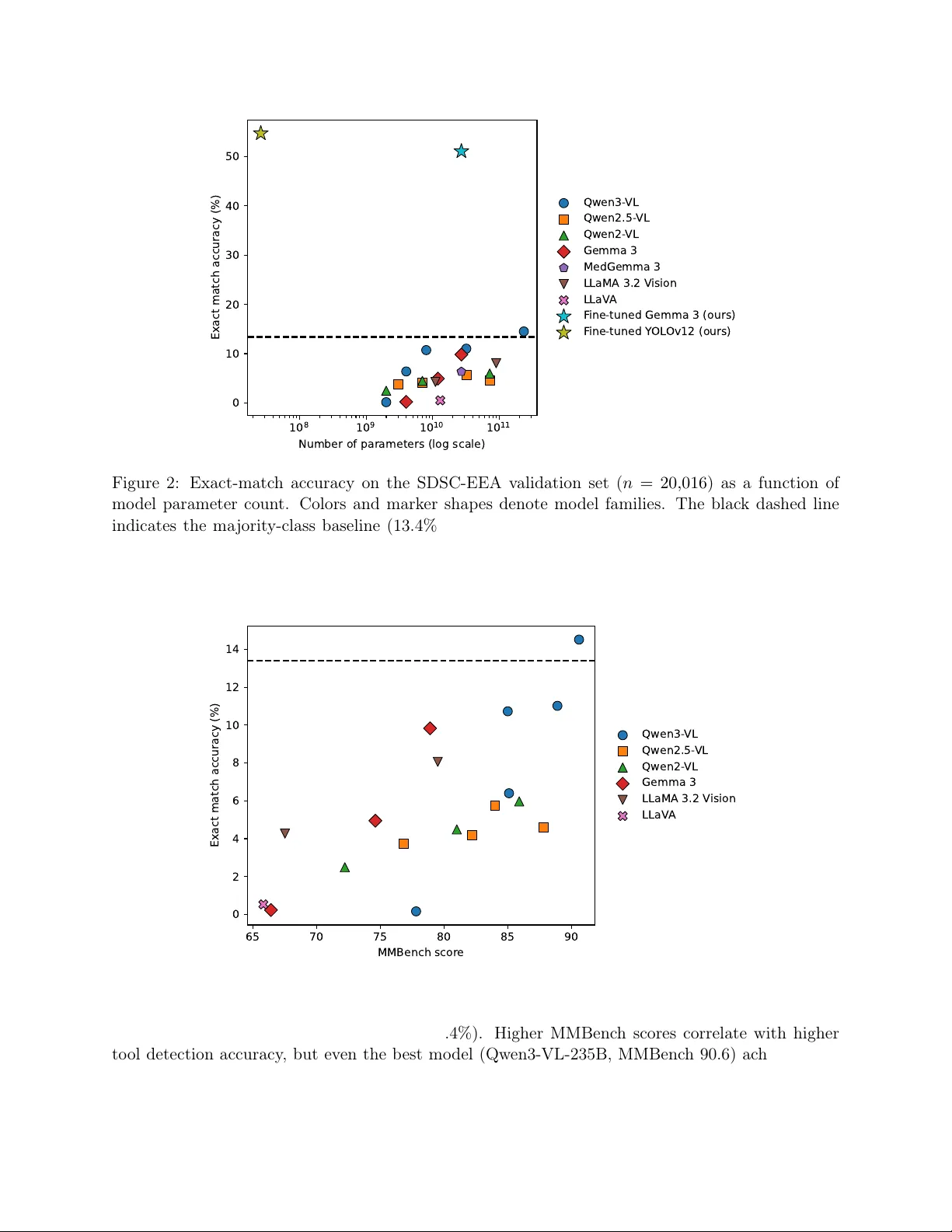
A Comparativ e Study in Surgical AI: Datasets, F oundation Mo dels, and Barriers to Med-A GI Kirill Sk ob elev 1 ∗ Eric Fithian 1 Y egor Barano vski 1 Jac k Co ok 2 Sandeep Angara 2 Shauna Otto 2 Zh uang-F ang Yi 2 John Zh u 2 Daniel A. Donoho 2,3 † X.Y. Han 1,4 † Neera j Maink ar 2 † Margaux Masson-F orsythe 2 † 1 Cen ter for Applied AI, Chicago Bo oth, Chicago, IL, USA 2 Surgical Data Science Collectiv e, W ashington D.C., USA 3 Children’s National Hospital, W ashington D.C., USA 4 Op erations Managemen t & T olan Cen ter for Healthcare, Chicago Bo oth, Chicago, IL, USA Marc h 31, 2026 Abstract Recen t Artificial In telligence (AI) mo dels ha ve matched or exceeded human exp erts in sev eral b enc hmarks of biomedical task p erformance, but ha ve lagged behind on surgical image-analysis b enc hmarks. Since surgery requires in tegrating disparate tasks—including multimodal data in tegration, human interaction, and ph ysical effects—generally-capable AI models could b e par- ticularly attractive as a collab orativ e to ol if p erformance could b e improv ed. On the one hand, the canonical approach of scaling architecture size and training data is attractive, esp ecially since there are millions of hours of surgical video data generated per y ear. On the other hand, prepar- ing surgical data for AI training requires significantly higher lev els of professional expertise, and training on that data requires exp ensiv e computational resources. These trade-offs pain t an uncertain picture of whether and to-what-extent mo dern AI could aid surgical practice. In this pap er, w e explore this question through a case study of surgical to ol detection using state-of- the-art AI metho ds av ailable in 2026. W e demonstrate that even with multi-billion parameter mo dels and extensiv e training, current Vision Language Models fall short in the seemingly sim- ple task of tool detection in neurosurgery . A dditionally , w e sho w scaling exp erimen ts indicating that increasing mo del size and training time only leads to diminishing improv emen ts in rele- v an t p erformance metrics. Th us, our exp erimen ts suggest that current mo dels could still face significan t obstacles in surgical use cases. Moreo ver, some obstacles cannot b e simply “scaled a wa y” with additional compute and p ersist across diverse model architectures, raising the ques- tion of whether data and lab el av ailability are the only limiting factors. W e discuss the main con tributors to these constraints and adv ance p oten tial solutions. Results Summary . W e present findings from six experiments. (1) W e ev aluate zero-shot surgical tool detection p erformance across 19 op en-w eight Vision Language Mo dels (VLMs) from 2023 to early-2026 on SDSC-EEA, a large video dataset consisting of endoscopic endonasal approach (EEA) neurosurgical pro ce- dures. Despite dramatic increases in mo del scale and b enc hmark scores, only one mo del marginally exceeds ∗ Lead Author: Kirill.Skobelev@chicagobooth.edu † Corresp on ding Authors: {dan,neeraj.mainkar,margaux}@surgicalvideo.io , XY.Han@chicagobooth.edu 1 the 13.4% ma jorit y class baseline on the v alidation set. (2) W e fine-tune Gemma 3 27B with LoRA adapters to generate structured JSON predictions. The mo del achiev es 47.63% exact match accuracy , surpassing the v alidation set baseline of 13.41%. (3) W e replace off-the-shelf JSON generation with a sp ecialized classifica- tion head. This approach achiev es 51.08% exact match accuracy . (4) T o assess the p oten tial of increasing computational resources, we gradually increase trainable parameters (b y increasing LoRA rank) by nearly three orders of magnitude. While training accuracy reaches 98.6%, v alidation accuracy remains b elow 40%, sho wing that scaling alone cannot ov ercome distribution shift. (5) W e compare zero-shot and fine-tuned VLM performance against YOLOv12-m, a sp ecialized 26M-parameter ob ject detection model. YOLOv12-m ac hieves 54.73% exact match accuracy , outperforming all VLM-based metho ds while using 1,000 × few er parameters. (6) W e demonstrate these findings generalize to CholecT50, an indep enden t and public dataset of laparoscopic cholecystectom y pro cedures, with additional comparisons to five proprietary frontier VLMs. The fine-tuned op en-w eight model and YOLOv12-m outp erform all zero-shot VLM metho ds including zero- shot metho ds using proprietary frontier VLMs. 1 In tro duction The scaling hypothesis has b ecome the dominant paradigm in AI researc h. Kaplan et al. [ 2020 ] do cumen ted that cross-entrop y loss scales with mo del size, data, and compute as a p o wer law. W ei et al. [ 2022 ] argued that certain capabilities emerge b ey ond critical mo del scales, while Chowdhery et al. [ 2022 ] demonstrated broad few-shot p erformance gains and emergent abilities in a 540B- parameter language mo del. These observ ations ha ve led to increasingly b old claims: Bub eck et al. [ 2023 ] interpret GPT-4’s behavior as indicativ e of emerging AGI, and Aschen brenner [ 2024 ] explicitly argues that contin ued scaling alone is sufficient to reac h AGI. In medicine, similar optimism has taken hold. Saab et al. [ 2024 ] present Med-Gemini, a family of mo dels achieving 91.1% on MedQA and large gains o ver GPT-4V on multimodal b enchmarks, as evidence that large m ultimo dal foundation mo dels can deliver strong generalist capabilities across medical sp ecialties. Suc h b enchmark results ha ve fueled sp eculation about the feasibilit y of a “Med- ical Artificial General In telligence” (Med-AGI) through scaling. Y et, when tested in realistic clinical settings, the pictures is less optimistic. F or example, Hager et al. [ 2024 ] find that state-of-the- art LLMs p erform significan tly w orse than physicians across pathologies, often failing to follow instructions. W u et al. [ 2025 ] further demonstrate that “generalist” radiology capability dep ends on large-scale in-domain pretraining and radiology-sp ecific instruction tuning, suggesting progress to ward Med-AGI ma y b e b ottlenec k ed by domain data cov erage as muc h as b y parameter count. In surgery sp ecifically , recen tly work has b egun to apply vision–language mo dels to surgical data across a range of tasks. Surgical-V QA Seeniv asan et al. [ 2022 ] introduces visual question answ ering ov er laparoscopic scenes, while GP-VLS Schmidgall et al. [ 2024 ] demonstrates that large foundation mo dels can be adapted to m ultiple surgical tasks, including instrumen t recognition, through extensive in-domain sup ervision. Related efforts fine-tune vision–language mo dels for to ol- related tasks suc h as k eyp oin t estimation using low-rank adaptation, often relying on syn thetic datasets to augmen t limited real annotations Duangprom et al. [ 2025 ]. This literature establishes VLMs as a viable mo deling paradigm for surgical understanding and motiv ates their ev aluation on fine-grained surgical p erception tasks using real op erativ e video. Despite progress on visual tasks suc h as surgery , whether these mo dels would lead to Med- A GI is an op en question. The definition of A GI remains debated, but, in order to function in the op erativ e setting, lo cating and classifying surgical instrumen ts is the earliest (necessary , not sufficien t) relev ant task. Non-exp ert h umans excel at this task: annotators in our study learned to lab el these tools with near-p erfect accuracy after minimal training. In this pap er, we ev aluate 2 state-of-the-art AI mo dels for to ol detection on SDSC-EEA, a unique dataset of 67,634 annotated frames from neurosurgical videos from the Surgical Data Science Collective (SDSC) [ 2026 ]. The pap er is organized as follows: • Section 2 describ es the dataset, mo dels, and exp erimental metho dology for five ev aluations spanning zero-shot inference, fine-tuning, parameter scaling, sp ecialized vision mo dels, and cross-dataset v alidation. • Section 3 presents fiv e findings: – Zero-shot VLMs do not surpass a trivial baseline (Section 3.1 ). A cross 19 mo dels span- ning 2B–235B parameters and t wo years of developmen t, v alidation accuracy remains at or near the ma jority class baseline of 13.4%. – Fine-tuning helps but do es not close the gap (Sections 3.2 – 3.3 ). LoRA fine-tuning of Gemma 3 27B raises v alidation exact matc h accuracy from 9.8% to 51.1%, but general- ization to held-out pro cedures remains limited. – Scaling adapter capacity do es not resolve generalization (Section 3.4 ). Increasing train- able parameters by nearly three orders of magnitude drives training accuracy to 98.6% while v alidation accuracy stays b elo w 40%. – A small sp ecialized mo del outp erforms all VLMs (Section 3.5 ). YOLOv12-m (26M pa- rameters) achiev es 54.7% exact matc h accuracy with 1,000 × few er parameters than the b est VLM. – These patterns replicate on a public, independent dataset (Section 3.6 ): CholecT50, a laparoscopic c holecystectomy b enchmark. Results, whic h include comparisons with proprietary frontier VLMs, confirm the broad pattern across surgical domains. • Section 4 argues that the b ottlenec k to surgical AI is sp ecialized data, not mo del scale, and prop oses hierarc hical architectures where generalist VLMs delegate to sp ecialized p erception mo dules. • Section 6 discusses limitations. • Section 7 concludes the pap er. 2 Metho ds This section describ es the dataset and exp erimenta l metho dology . Section 2.1 introduces the SDSC- EEA dataset. Section 2.2 describ es zero-shot VLM ev aluation. Section 2.3 describ es LoRA fine- tuning of a VLM. Section 2.4 describ es a sp ecialized ob ject baseline. Section 2.5 describ es an v alidation on the external CholecT50 dataset. Section 2.6 defines the ev aluation metrics used throughout. Corresp onding results for each exp erimen t are rep orted in Section 3 . 2.1 SDSC-EEA Dataset W e ev aluate surgical to ol detection using a dataset of endoscopic endonasal approac h (EEA) neu- rosurgical pro cedures. EEA is a minimally inv asive tec hnique used to access and treat lesions at the skull base through the nasal passages. The dataset is provided by the Surgical Data Science Collectiv e (SDSC) and comprises of 67,634 annotated frames extracted from 66 unique surgical 3 pro cedures. Figure 1 exhibits frames from some videos sampled from this dataset. W e will refer to it as SDSC-EEA in this pap er. The dataset w as constructed from video recordings of surgical pro cedures donated to the SDSC b y 10 surgeons across 7 institutions in the United States, F rance, and Spain. No exclusion criteria w ere applied. Ground truth annotations were pro duced by three annotators from a con tracted lab el- ing compan y , none of whom had clinical exp erience; annotators were provided with to ol descriptions and representativ e example images prior to lab eling. Labels w ere first review ed b y a senior anno- tator at the contracting compan y and subsequen tly by members of the SDSC. F ewer than 10% of frames required correction. Eac h frame is annotated with multi-label ground truth indicating the presence or absence of 31 distinct surgical instrument classes. Annotations are pro vided in YOLO format with b ounding b o x co ordinates. The av erage num b er of to ols p er frame is 1.72 (median: 2), with the distribution sho wing 7.6% of frames containing no to ols, 34.4% containing one to ol, 38.2% containing t wo to ols, and 19.8% containing three or more to ols. The to ol class distribution exhibits significant imbalance. Suction is the most prev alent instru- men t, app earing in 63.3% of all frames. Cotton Patt y (16.1%), Grasp er (10.6%), Curette (8.6%), and Rhoton Dissector (8.0%) follow in frequency . F or all fine-tuning exp erimen ts (Section 2.3 ), we split the data b y surgical pro cedure instances to preven t data leak age. F rames from the same surgical pro cedure app ear exclusively in either the training or v alidation set, nev er b oth. This yields 47,618 training frames from 53 pro cedures and 20,016 v alidation frames from 13 pro cedures. 2.2 Zero-Shot Ev aluation of Vision-Language Mo dels Correct Detections Incorrect Detections Figure 1: Example frames from SDSC-EEA with zero-shot predictions from Gemma 3 27B. T op ro w: correct detections (left to right: Drill + Suction; Suction; Drill + Suction; no to ols; no to ols). Bottom row: incorrect detections, left to right: y = Drill, Suction; ˆ y = Curette, Grasper, Irriga- tion, Monopolar Electro cautery , Suction; y = Cotton Patt y , Rhoton Dissector, Suction; ˆ y = Grasp er, Monop olar Electro cautery , Suction; y = Bip olar F orceps, Suction; ˆ y = Curette, Drill, Suction, Tis- sue sha ver; y = Suction; ˆ y = Grasp er, Monop olar Electro cautery , Suction; y = Rhoton Dissector; ˆ y = Monop olar Electro cautery , Suction. W e ev aluate zero-shot to ol detection p erformance across 19 op en-w eight vision-language mo dels spanning tw o years of dev elopment (Septem b er 2023–Septem b er 2025). The complete list of mo dels is shown in T able 1 . 4 T able 1: Vision-language mo dels ev aluated for zero-shot surgical to ol detection. Mo del P arams (B) Release MMBenc h Qw en3-VL-235B-A22B-Thinking [ Bai et al. , 2025a ] 235 Sep 2025 90.6 Qw en3-VL-32B-Instruct 32 Sep 2025 88.9 Qw en3-VL-8B-Instruct 8 Sep 2025 85.0 Qw en3-VL-4B-Instruct 4 Sep 2025 85.1 Qw en3-VL-2B-Instruct 2 Sep 2025 77.8 Qw en2.5-VL-72B-Instruct [ Bai et al. , 2025b ] 72 Mar 2025 87.8 Qw en2.5-VL-32B-Instruct 32 Mar 2025 84.0 Qw en2.5-VL-7B-Instruct 7 Mar 2025 82.2 Qw en2.5-VL-3B-Instruct 3 Mar 2025 76.8 Qw en2-VL-72B-Instruct [ W ang et al. , 2024 ] 72 Sep 2024 85.9 Qw en2-VL-7B-Instruct 7 Sep 2024 81.0 Qw en2-VL-2B-Instruct 2 Sep 2024 72.2 Gemma 3 27B-it [ Gemma-T eam et al. , 2025 ] 27 Mar 2025 78.9 Gemma 3 12B-it 12 Mar 2025 74.6 Gemma 3 4B-it 4 Mar 2025 66.4 MedGemma 3 27B-it [ Sellergren et al. , 2025 ] 27 July 2025 - Llama-3.2-90B-Vision [ Meta , 2024 ] 90 Sep 2024 79.5 Llama-3.2-11B-Vision 11 Sep 2024 67.5 LLaV A-1.5-13B [ Liu et al. , 2024a ] 13 Sep 2023 65.8 Mo dels span fiv e families: Qwen (12 mo dels across three generations), Gemma 3 (3 mo dels), MedGemma 3 (1 mo del), Llama 3.2 Vision (2 mo dels), and LLaV A 1.5 (1 mo del). Mo del sizes range from 2B to 235B parameters. MMBenc h [ Liu et al. , 2024b ], a holistic b enc hmark ev aluating m ultimo dal mo dels across p erception, reasoning, and knowledge, scores range from 65.8 (LLaV A 1.5) to 90.6 (Qwen3-VL-235B). F or each mo del, we prompt the mo del to identify all visible surgical to ols from a list of 31 v alid to ol names and return predictions as a JSON ob ject. The complete prompt template is provided in App endix B . Mo del outputs are v alidated against a strict sc hema; outputs that fail v alidation (malformed JSON, sc hema violations, or hallucinated tool names not in the ontology) are treated as empt y predictions rather than silen tly excluded. The full output v alidation metho dology is describ ed in App endix C . T able 2 rep orts exact match accuracy separately on the training set ( n = 47 , 618 frames from 53 pro cedures), v alidation set ( n = 20 , 016 frames from 13 pro cedures), and the full dataset. Figure 1 sho ws representativ e examples from our dataset, illustrating b oth successful and unsuccessful to ol detection cases. F or the zero-shot results rep orted in T able 2 , Figure 2 , and Figure 3 , we use exact matc h accuracy and Jaccard similarity as primary metrics, with p er-to ol precision, recall, and F 1 reported in App endix L . All ev aluation metrics are defined in Section 2.6 . These results are analyzed in Section 3.1 . 2.3 LoRA Fine-T uning W e fine-tune Gemma 3 27B using Low-Rank Adaptation (LoRA) [ Hu et al. , 2021 ] with adapters applied to atten tion pro jection matrices in b oth the language model and vision encoder. W e ev aluate 5 three configurations: JSON generation (Figure 4 , Section 3.2 ): The model learns to produce structured JSON outputs in the format {"detected_tools": ["Tool1", "Tool2"]} via sup ervised fine-tuning. Classification head (Figure 5 , Section 3.3 ): W e replace JSON generation with a single-lay er linear classification head that maps mean-p ooled hidden states to 31 output logits, trained with binary cross-en tropy loss. At inference, predictions are obtained b y thresholding sigmoid outputs at 0.5. This approac h enables con tinuous prediction scores for ROC-A UC and A UPRC metrics and requires only a single forward pass rather than autoregressive generation. Rank sweep (Figure 6 , T able 3 , Section 3.4 ): T o inv estigate whether increasing mo del capacity impro ves generalization, w e sw eep LoRA rank from r = 2 to r = 1024 , v arying trainable parameters b y nearly three orders of magnitude (4.7M to 2.4B parameters). All three configurations use the same pro cedure-lev el train/v alidation split describ ed in Sec- tion 2.1 . F ull configuration details (ranks, learning rates, batch sizes, and compute requirements) are provided in App endix D . 2.4 Sp ecialized Sup ervised Mo del As a sup ervised baseline, w e train YOLOv12-m [ Tian et al. , 2025 ], a state-of-the-art ob ject detection mo del with 26M parameters. Unlik e VLMs, which p erform set-based m ulti-lab el classification, YOLO directly predicts bounding b o xes with asso ciated class lab els and confidence scores. W e train using default YOLO hyperparameters; the full configuration is provided in App endix H . T o enable direct comparison with VLMs, we con vert YOLO’s p er-frame b ounding b o x predictions in to to ol sets: for each frame, we collect the unique set of to ol classes with confidence ≥ 0 . 25 and compare against the ground truth to ol set. This allows us to compute exact matc h accuracy , Jaccard similarity , top-1 accuracy , and p er-to ol precision/recall/F1 on the same basis as VLM- based classifiers. Results, including a p er-to ol comparison with Gemma (T able 4 ), are rep orted in Section 3.5 . 2.5 External Dataset: CholecT50 T o ev aluate generalization to an indep enden t surgical domain, we use CholecT50 [ Nwo ye et al. , 2022 ], a publicly a v ailable dataset of laparoscopic c holecystectomy pro cedures. CholecT50 comprises 50 videos with frame-level annotations for 6 surgical instruments (grasper, bip olar, ho ok, scissors, clipp er, irrigator), 10 surgical v erbs, 15 anatomical targets, and 100 instrument-v erb-target triplets. W e fo cus exclusiv ely on instrument detection to maintain consistency with our primary ev aluation. The dataset contains 100,863 annotated frames. W e p erform an 80/20 train/v alidation split at the video level to prev ent data leak age, yielding 80,940 training frames (40 videos) and 19,923 v alidation frames (10 videos). The ma jority class baseline—predicting the most common to ol set (grasp er, ho ok) for every frame—achiev es 34.76% exact match accuracy on the v alidation set. W e ev aluate zero-shot p erformance using Gemma 3 27B, fine-tune with LoRA and a clas- sification head using the same configuration as Section 2.3 , conduct a LoRA rank sw eep ( r ∈ { 2 , 4 , 8 , 16 , 32 , 64 , 128 , 256 , 512 , 1024 } ) using the same proto col as Section 2.3 , and train YOLOv12- m using the same setup as Section 2.4 . Results, including T able 6 and Figure 7 , are rep orted in Section 3.6 . 2.6 Ev aluation Metrics W e rep ort the follo wing metrics throughout. Exact match accuracy is the p ercen tage of frames where the predicted tool set exactly matc hes the ground truth; this is a strict metric that p enalizes an y 6 false positive or false negative. Jaccard similarit y is computed for each frame as J = | P ∩ G | / | P ∪ G | where P is the predicted set and G is the ground truth set, and w e report the mean across all frames. W e also compute p er-to ol precision, recall, and F1 scores as standard binary classification metrics indep enden tly for eac h to ol class. F or mo dels with con tinuous prediction scores (classification head), we additionally rep ort ROC-A UC (area under the receiv er op erating characteristic curve) and AUPR C (area under the precision-recall curv e) p er to ol class, as well as macro-av eraged v alues across to ols present in the v alidation set. Per-class accuracy for zero-prev alence classes is meaningless (a mo del predicting all negatives achiev es 100% accuracy) and is excluded from macro-a veraged metrics. T o enable direct comparison b et ween YOLO and VLM-based classifiers, we additionally rep ort top-1 accuracy: the fraction o f frames where the tool with the highest predicted probabilit y is presen t in the ground truth set. Both YOLO (via class confidence scores) and the Gemma classifier (via sigmoid outputs) pro duce explicit p er-tool probabilities, making this metric computable for b oth. How ev er, top-1 accuracy cannot b e computed for generative VLM outputs, which pro duce unordered to ol lists without p er-tool probability scores. This metric isolates the mo del’s ability to iden tify the single most salient to ol in each frame, a prerequisite for reliable surgical assistance. F or 95% confidence interv als on exact match accuracy , we use b o otstrap resampling with B = 1 , 000 iterations. F or a dataset of N frames, we resample N observ ations with replacemen t from the binary correct/incorrect results and compute the mean for eac h of the B b o otstrap samples; the 2.5th and 97.5th p ercentiles form the confidence in terv al. 3 Results W e presen t results in fiv e parts. Section 3.1 establishes the baseline: zero-shot VLMs fail to exceed a trivial ma jorit y class baseline despite tw o y ears of scaling. Given this failure, the next three sections ask whether adaptation can close the gap. Sections 3.2 and 3.3 explore t wo parallel fine-tuning strategies—JSON generation and a classification head—that b oth improv e substan tially ov er zero- shot but plateau w ell below human-lev el accuracy . Section 3.4 then tests whether this plateau is due to insufficien t capacit y b y scaling LoRA rank b y nearly three orders of magnitude; training accuracy saturates near 99% while v alidation accuracy remains b elow 40%, indicating that the b ottlenec k is not mo del capacity . Section 3.5 compares against YOLOv12-m, a sp ecialized 26M-parameter ob ject detection mo del that outp erforms all VLM-based approac hes with 1,000 × fewer parameters. Section 3.6 replicates the k ey exp eriments on CholecT50, a laparoscopic cholecystectom y dataset, and finds the same broad patterns across b oth surgical domains. 3.1 Zero-shot accuracy of op en-w eigh t mo dels do es not surpass the ma jority class baseline T ak ea wa ys Ev en for larger VLMs, in the zero-shot setting, performance sta ys at or near the ma jority-class baseline. Progress on general multimodal b enc hmarks and parameter scale do es not transfer reliably to this surgical p erception task. Detailed Results. W e ev aluate zero-shot to ol detection p erformance across 19 op en-w eigh t vision- language models (Section 2.2 ) released b et ween Septem b er 2023 and Septem b er 2025. Despite dramatic increases in mo del scale, from LLaV A 1.5 13B (2023) to Qwen3-VL-235B (2025), and sub- stan tial improv emen ts on general vision b enc hmarks, no mo del meaningfully surpasses the ma jority class baseline on the v alidation set. 7 1 0 8 1 0 9 1 0 1 0 1 0 1 1 Number of parameters (log scale) 0 10 20 30 40 50 Exact match accuracy (%) Qwen3- VL Qwen2.5- VL Qwen2- VL Gemma 3 MedGemma 3 LLaMA 3.2 V ision LLaV A F ine-tuned Gemma 3 (ours) F ine-tuned Y OL Ov12 (ours) Figure 2: Exact-match accuracy on the SDSC-EEA v alidation set ( n = 20 , 016 ) as a function of mo del parameter coun t. Colors and marker shap es denote mo del families. The blac k dashed line indicates the ma jorit y-class baseline (13.4%). A ccuracy exhibits a p ositiv e but strongly sublinear relationship with parameter count; the relationship is family-dep enden t, with Qwen mo dels consis- ten tly outp erforming similarly-sized Gemma and Llama mo dels. 65 70 75 80 85 90 MMBench scor e 0 2 4 6 8 10 12 14 Exact match accuracy (%) Qwen3- VL Qwen2.5- VL Qwen2- VL Gemma 3 LLaMA 3.2 V ision LLaV A Figure 3: Zero-shot exact-matc h accuracy on the SDSC-EEA v alidation set ( n = 20 , 016 ) plotted against MMBenc h score. Colors and mark er shap es denote model families. The blac k dashed line indicates the ma jority-class baseline (13.4%). Higher MMBench scores correlate with higher to ol detection accuracy , but even the b est mo del (Qwen3-VL-235B, MMBench 90.6) achiev es only 14.52%—far b elow fine-tuned mo dels (51.08%, Section 3.3 ). 8 T able 2 reports exact match accuracy for all models; no model meaningfully surpasses the ma jority class baseline. As sho wn in Figure 3 , higher MMBenc h scores are correlated with higher p erformance on the to ol detection b enc hmark in our dataset, and the relationship app ears to b e linear. Ho wev er, even the b est p erforming mo del, Qw en3-VL-235B, whic h ac hieves a 90.6 out of 100 score on MMBench, significantly underp erforms the fine-tuned Gemma 3 27B in Section 3.3 (14.52% vs 51.08% v alidation exact match accuracy). This suggests that there are surgical visual capabilities that go b eyond what can b e measured by multi-purpose b enc hmarks like MMBenc h. Notably , MedGemma 3 27B-it, which is describ ed as a mo del optimized for medicine, underp er- forms Gemma 3 27B-it—a sibling that MedGemma is based on—on the v alidation set (6.36% vs. 9.83%). P er-to ol classification metrics (precision, recall, F1) for all 19 ev aluated zero-shot mo dels are provided in App endix L . App endix G shows represen tative failed outputs, which are dominated b y hallucinated to ol names rather than formatting errors. 3.2 LoRA fine-tuning impro ves to ol detection mo destly but remains b elo w h uman-lev el T ak ea wa ys T ask-sp ecific fine-tuning impro ves p erformance relative to zero-shot ev aluation, but it do es not close the generalization gap on held-out pro cedures. Detailed Results Giv en that zero-shot mo dels fail at surgical to ol detection regardless of scale, w e next ask whether task-sp ecific fine-tuning can bridge the gap. W e fine-tune Gemma 3 27B with LoRA adapters to generate structured JSON predictions (Section 2.3 ). Figure 4 shows training and v alidation loss curves ov er 10 ep o c hs. 0 1000 2000 3000 4000 5000 6000 7000 Step 1 0 0 L oss T raining L oss T rain L oss 0 1000 2000 3000 4000 5000 6000 7000 Step 0 20 40 60 80 100 Exact Match A ccuracy (%) Exact Match A ccuracy T rain V al 0 1000 2000 3000 4000 5000 6000 7000 Step 0 20 40 60 80 100 Jaccar d Similarity (%) Jaccar d Similarity T rain V al Figure 4: T raining dynamics for LoRA fine-tuning with JSON output on SDSC-EEA ( r = 1024 ). Left: T raining loss (log scale) decreases steadily , confirming the mo del learns the structured output format. Center: Exact match accuracy . Right: Jaccard similarity . Both accuracy and Jaccard sho w a p ersisten t gap b et w een training and v alidation p erformance, indicating limited generalization to held-out pro cedures. Metrics are computed on fixed random subsets of 100 frames from each set, ev aluated 100 times throughout training. After 10 ep ochs, the fine-tuned mo del ac hieves 47.63% exact match accuracy (95% CI: 46.97%– 48.34%) and 57.34% Jaccard similarity on the v alidation set ( n = 20 , 016 ). This represents a sub- stan tial impro vemen t ov er b oth the ma jority class baseline (13.41% exact match, 31.91% Jaccard) and the pre-training baseline (9.83% exact match, 25.98% Jaccard). 9 T able 2: Zero-shot to ol detection exact match accuracy (%) on SDSC-EEA for all ev aluated VLMs with 95% b ootstrap confidence interv als. T rain ( n = 47 , 618 frames, 53 pro cedures), v alidation ( n = 20 , 016 frames, 13 pro cedures), and full dataset. Output v alidation failures are counted as incorrect predictions. The ma jorit y class baseline, which predicts the most common to ol set for every frame, achiev es 13.41% exact match accuracy on the v alidation set. The pre-training baseline (Gemma 3 27B) achiev es 9.83% v alidation exact match accuracy (95% CI: 9.43%–10.21%). V alidation accuracy ranges from 0.11% (Qw en3-VL-2B) to 14.52% (Qwen3-VL-235B-A22B-Thinking); only Qwen3-VL-235B marginally surpasses the ma jority class baseline. Output v alidation failure rates range from 0.8% (Gemma 3 27B, Qw en3-VL-8B) to 41.7% (Qwen2-VL-2B). P arams T rain V alidation F ull Mo del (B) EM % 95% CI EM % 95% CI EM % 95% CI Qw en3-VL-235B-A22B-Thinking 235 17.04 16.69–17.39 14.52 14.06–15.02 16.28 16.01–16.55 Qw en3-VL-32B-Instruct 32 16.02 15.70–16.34 11.04 10.57–11.45 14.58 14.32–14.84 Qw en3-VL-8B-Instruct 8 12.08 11.80–12.38 10.73 10.32–11.13 11.68 11.46–11.92 Qw en3-VL-4B-Instruct 4 11.10 10.82–11.38 6.37 6.04–6.70 9.72 9.51–9.94 Qw en3-VL-2B-Instruct 2 0.29 0.24–0.34 0.11 0.07–0.16 0.24 0.20–0.27 Qw en2.5-VL-72B-Instruct 72 10.27 10.01–10.54 4.56 4.27–4.87 8.59 8.40–8.79 Qw en2.5-VL-32B-Instruct 32 10.08 9.83–10.36 5.43 5.13–5.74 8.72 8.52–8.93 Qw en2.5-VL-7B-Instruct 7 6.54 6.33–6.75 3.48 3.25–3.75 5.64 5.49–5.82 Qw en2.5-VL-3B-Instruct 3 5.43 5.23–5.64 2.90 2.68–3.14 4.69 4.53–4.86 Qw en2-VL-72B-Instruct 72 8.70 8.46–8.95 5.70 5.39–6.00 7.82 7.64–8.01 Qw en2-VL-7B-Instruct 7 5.13 4.93–5.32 3.35 3.09–3.60 4.61 4.46–4.76 Qw en2-VL-2B-Instruct 2 2.29 2.15–2.42 1.48 1.31–1.64 2.05 1.94–2.15 Gemma 3 27B-it 27 5.61 5.40–5.81 9.83 9.43–10.21 6.85 6.66–7.02 Gemma 3 12B-it 12 5.20 5.01–5.39 4.95 4.65–5.25 5.13 4.97–5.29 Gemma 3 4B-it 4 0.56 0.50–0.63 0.23 0.16–0.30 0.46 0.42–0.51 MedGemma 3 27B-it 27 5.41 5.20–5.60 6.36 6.02–6.70 5.68 5.51–5.86 Llama-3.2-90B-Vision 90 10.62 10.33–10.91 8.06 7.68–8.45 9.85 9.62–10.09 Llama-3.2-11B-Vision 11 0.33 0.28–0.38 0.19 0.13–0.25 0.29 0.25–0.33 LLaV A-1.5-13B 13 1.66 1.55–1.77 0.53 0.44–0.64 1.33 1.23–1.41 Ma jority class baseline – 11.49 – 13.41 – 12.06 – 10 T able 8 in App endix E shows p er-to ol precision and recall. The mo del learns to detect sev eral to ols with high F1 scores (Suction Coagulator: 0.989, Drill: 0.876, Suction: 0.809) but completely fails on others (Suction micro debrider: 0% recall despite 497 ground truth instances in v alidation). This discrepancy arises from the pro cedure-based train/v alidation split: to ols that app ear predom- inan tly in v alidation pro cedures were rarely seen during training (T able 7 ). F or example, Suction micro debrider has only 94 training instances versus 497 in v alidation, and Aspirating dissector has 88 training instances versus 2,319 in v alidation. Qualitativ e analysis rev eals that fine-tuned mo dels pro duce syn tactically correct JSON outputs with v alid to ol names (eliminating output v alidation failures common in zero-shot outputs), but generalization to unseen to ol distributions remains p oor. 3.3 LoRA with classification head learns in-sample but fails to generalize out- of-sample T ak ea wa ys Dedicated classification ob jectives are more effective than autoregressiv e JSON gen- eration for surgical to ol detection, yielding the strongest VLM-based p erformance in our study . The train-v alidation gap remains. Detailed Results Ha ving established that LoRA fine-tuning with JSON generation impro ves o ver zero-shot baselines, w e test whether a dedicated classification ob jective can do b etter. W e replace JSON generation with a linear classification head trained with binary cross-entrop y loss (Section 2.3 ). The classification head produces p er-tool probability scores, enabling threshold- indep enden t metrics such as ROC-A UC and AUPR C that are not av ailable from discrete JSON outputs. Figure 5 sho ws training dynamics. 0 5000 10000 15000 20000 25000 30000 Step 1 0 8 1 0 6 1 0 4 1 0 2 1 0 0 L oss T raining L oss T rain L oss 0 5000 10000 15000 20000 25000 30000 Step 0 20 40 60 80 100 Exact Match A ccuracy (%) Exact Match A ccuracy T rain V al 0 5000 10000 15000 20000 25000 30000 Step 0 20 40 60 80 100 Jaccar d Similarity (%) Jaccar d Similarity T rain V al Figure 5: T raining dynamics for LoRA fine-tuning with classification head on SDSC-EEA ( r = 1024 ). Left: T raining loss (log scale). Center: Exact match accuracy . Right: Jaccard similarit y . The classification head achiev es the highest v alidation accuracy among all VLM-based metho ds (51.08%), outp erforming JSON generation at the same LoRA rank (47.63%, Figure 4 ). The p ersisten t train– v alidation gap reflects limited generalization to held-out pro cedures. Metrics are computed on fixed random subsets of 100 frames from each set, approximately 100 times throughout training. After 10 ep ochs, the fine-tuned mo del ac hieves 51.08% exact match accuracy (95% CI: 50.39%– 51.81%) and 61.33% Jaccard similarit y on the v alidation set ( n = 20 , 016 ), substan tially outperform- ing b oth the ma jority class baseline (13.41%) and the pre-training baseline (9.83%). The mo del also achiev es 80.5% macro-av eraged ROC-A UC and 37.6% macro-a veraged A UPRC across the 23 to ol classes presen t in the v alidation set. T able 10 in App endix F shows p er-tool ROC-A UC and A UPRC. 11 This approach ac hieves the highest v alidation accuracy among all VLM-based metho ds, outp er- forming JSON generation with the same LoRA rank (Section 3.2 , 47.63% exact matc h), suggesting that explicit multi-label classification ob jectiv es are more effective than autoregressiv e generation for this task. 3.4 Scaling LoRA adapter rank do es not meaningfully impro ve out-of-sample accuracy T ak ea wa ys Increasing LoRA rank improv es training accuracy but pro duces only limited gains on held-out pro cedures. This suggests that the main b ottleneck is not insufficient adapter capacit y or compute, but failure to generalize under distribution shift. Detailed Results The exp erimen ts in Sections 3.2 - 3.3 use a single, large LoRA rank ( r = 1024 ). A natural question is whether the v alidation accuracy gap reflects insufficient mo del capacity . W e sw eep LoRA rank from 2 to 1,024, increasing trainable parameters b y nearly three orders of mag- nitude (T able 3 ; metho dology in Section 2.3 ). Figure 6 shows accuracy as a function of rank. 2 4 8 16 32 64 128 256 512 1024 L oR A R ank 0 20 40 60 80 100 A ccuracy (%) Majority Class Baseline (V alidation) T rain V alidation Figure 6: Exact match accuracy vs. LoRA rank on SDSC-EEA. Gemma 3 27B with LoRA adapters and a linear classification head, trained for 3 ep ochs at each rank ( r ∈ { 2 , 4 , . . . , 1024 } ). T raining accuracy (dark blue) increases monotonically from 35.9% to 98.6%, while v alidation accuracy (light blue) remains b elo w 40% across all ranks. The widening gap demonstrates that scaling adapter capacit y alone cannot o vercome the pro cedure-lev el distribution shift. Error bars: 95% b o otstrap CIs ( B = 1 , 000 ). 12 T able 3: LoRA rank sweep on SDSC-EEA: configurations with trainable parameter counts for eac h rank. Rank P arams (M) 2 4.7 4 9.4 8 18.8 16 37.5 32 75.0 64 150.0 128 300.0 256 600.0 512 1200.1 1024 2400.2 T raining accuracy increases monotonically with rank, from 35.9% (95% CI: 35.5%–36.3%) at r = 2 to 98.6% (95% CI: 98.5%–98.7%) at r = 1024 . V alidation accuracy p eaks at r = 1024 with 39.6% (95% CI: 39.0%–40.3%), though the relationship is non-monotonic. 3.5 Sp ecialized sup ervised mo del T ak ea wa ys F or this narro w p erceptual task, a small sp ecialized vision mo del outp erforms all VLM-based approaches while using orders of magnitude few er parameters. This suggests the surgical AI p erformance is currently limited less by larger generalist mo dels than b y the av ailabilit y of task- sp ecific data. Detailed Results The VLM-based approac hes ab o ve require a 27B-parameter model, with corre- sp onding training time and inference cost. A natural question is whether a small, sp ecialized mo del can match that p erformance at a fraction of the cost. YOLOv12-m (Section 2.4 ), with only 26M parameters—o ver 1,000 × fewer—ac hieves 54.73% exact match accuracy (95% CI: 54.03%–55.44%) and 64.00% Jaccard similarit y (95% CI: 63.37%–64.58%) on the v alidation set ( n = 20 , 016 ), with 70.06% top-1 accuracy (95% CI: 69.43%–70.70%), outp erforming the b est VLM (Gemma 3 27B with classification head, r = 1024 ; 51.08% exact matc h, 61.33% Jaccard). W e select YOLO as a natural baseline for this task given its established success in ob ject detection. Ho wev er, YOLO is trained with b ounding b o x sup ervision, while VLMs receive only set-level lab els. T o verify that YOLO’s adv antage is not solely due to this richer sup ervisory signal, we train a ResNet-50 (23.6M parameters) using the same set-level labels as VLMs—without any bounding b ox information. This CNN achiev es 39.6% exact match accuracy (95% CI: 38.9%–40.3%), outp erforming all zero-shot VLMs (App endix J ). T able 4 compares p er-to ol metrics b et ween the t wo models. R OC-AUC is computed from Gemma’s sigmoid outputs and YOLO’s maximum detection confidence p er class. 13 T able 4: Per-tool comparison: YOLOv12-m vs. Gemma 3 27B (classification head) on the SDSC- EEA v alidation set ( n = 20 , 016 ). YOLO achiev es higher F1 and recall on all 15 to ols, while Gemma ac hieves higher precision on 4 to ols. F or R OC-AUC, the tw o mo dels are complementary: YOLO leads on 7 to ols, Gemma on 8. Sorted by ground truth coun t ( N ). Best p er row in b old. Precision Recall F1 R OC-AUC T o ol N YOLO Gemma YOLO Gemma YOLO Gemma YOLO Gemma Suction 10685 .732 .673 .963 .885 .832 .764 .875 .819 Rongeur 2790 .948 .960 .716 .222 .816 .361 .866 .920 Cotton P atty 2143 .877 .576 .819 .706 .847 .635 .981 .929 Drill 2116 .943 .945 .959 .790 .951 .861 .984 .983 Rhoton Dissector 1462 .554 .540 .882 .590 .680 .564 .945 .920 Surgical Knife 1422 .9 47 .920 .904 .049 .925 .092 .953 .939 Suction Coagulator 1188 .982 1.00 .995 .622 .988 .767 .998 1.00 Bac kbiting rongeur 1041 .852 .741 .243 .019 .378 .038 .641 .918 Scissor 996 .458 .622 .673 .136 .545 .223 .840 .766 Surgicel 739 1.00 .971 .635 .628 .776 .763 .825 .908 Curette 708 .842 .949 .468 .239 .601 .382 .744 .940 Grasp er 509 .289 .032 .686 .020 .406 .024 .840 .708 Bip olar F orceps 263 .752 .000 .346 .000 .474 .000 .675 .723 Straigh t F orceps 173 .454 .642 .775 .249 .573 .358 .908 .943 Irrigation 112 .809 1.00 .339 .018 .478 .035 .701 .776 3.6 Robustness: P erformance on CholecT50 T ak ea wa ys The results on SDSC-EEA reproduce on CholecT50: the broad pattern that zero-shot p erformance is p o or, that fine-tuning is necessary , and that smaller mo dels outp erform VLMs at a fraction of the size. Additionally , frontier proprietary models from the GPT, Gemini, and Claude families underp erform a fine-tuned op en-w eight LLM and a sp ecialised computer vision mo del. Detailed Results T o assess whether our findings generalize b eyond neurosurgery , we ev aluate on CholecT50, an indep enden t laparoscopic c holecystectomy dataset with 6 instrumen t classes (Sec- tion 2.5 ). Zero-shot Gemma 3 27B achiev es 6.87% exact match accuracy (95% CI: 6.55%–7.22%), whic h is b elo w the ma jorit y class baseline (34.76%). Fine-tuning Gemma 3 27B with LoRA ( r = 128 ) and a classification head reaches 83.02% exact matc h accuracy (95% CI: 82.52%–83.56%) and 88.79% Jaccard similarit y (95% CI: 88.43%–89.18%). YOLOv12-m achiev es 81.37% exact matc h accuracy (95% CI: 80.87%–81.92%) and 88.00% Jaccard similarit y (95% CI: 87.62%–88.34%), with 93.80% top-1 accuracy (95% CI: 93.45%–94.12%). T able 6 compares p er-to ol metrics b et ween the tw o fine-tuned mo dels. P er-to ol metrics for the zero-shot setting are in App endix I : grasp er ac hieves the highest F1 (0.627), while bip olar has 12,096 false p ositiv es vs. 838 true p ositiv es. A dditionally , since CholecT50 is a public dataset, we can also ev aluate the p erformance of five closed-w eight fron tier VLMs from the GPT 5.4 [ Op enAI , 2026 ], Gemini 3 [ Gemini T eam , 2026 ], and Claude 4.6 [ Anthropic , 2026 ] families 1 using the same prompt template and v alidation frames. T able 5 compares all mo dels ev aluated on CholecT50. 1 W e cannot ev aluate SDSC-EEA on proprietary frontier mo dels b ecause w e cannot send priv ate SDSC-EEA data to third-part y APIs. All ev aluations on SDSC-EEA were conducted locally on op en-source VLMs. 14 T able 5: T o ol detection exact match accuracy (%) on the CholecT50 v alidation set ( n = 19 , 923 frames, 6 instrumen t classes) with 95% b o otstrap confidence interv als ( B = 1 , 000 ). Mo dels are sorted by exact match accuracy . The ma jority class baseline predicts the most common to ol set for ev ery frame. Output v alidation failures are counted as incorrect predictions. Mo del P arams (B) EM % 95% CI Gemma 3 27B + LoRA cls. head 27 83.02 82.52–83.56 YOLOv12-m 0.026 81.37 80.87–81.92 Gemini 3 Flash Preview — 69.15 68.49–69.73 Gemini 3.1 Pro Preview — 66.21 65.58–66.88 Claude Opus 4.6 — 52.37 51.67–53.03 GPT-5.4 — 32.09 31.40–32.72 Claude Sonnet 4.6 — 30.73 30.07–31.37 Gemma 3 27B-it 27 6.87 6.55–7.22 Ma jority class baseline — 34.76 — T wo closed-weigh t fron tier mo dels—Gemini 3 Flash Preview and Gemini 3.1 Pro Preview— ac hieve 69.15% and 66.21% zero-shot exact matc h accuracy resp ectiv ely , far surpassing the op en- w eight Gemma 3 27B (6.87%) and approaching the fine-tuned mo dels. Second, p erformance v aries dramatically across mo del families: b oth Go ogle mo dels exceed 66%, Claude Opus reaches 52%, while GPT-5.4 and Claude Sonnet fall b elo w the ma jority class baseline. Third, the fine-tuned mo dels (83% and 81%) still outp erform even the best zero-shot API mo del b y 14 p ercentage points, confirming that task-sp ecific training remains v aluable even as frontier mo dels improv e. T able 6: Per-tool comparison: YOLOv12-m vs. Gemma 3 27B (classification head) on CholecT50 v alidation set ( n = 19 , 923 ). Unlike SDSC-EEA (T able 4 ), results are mixed: Gemma achiev es higher F1 on 4 of 6 to ols; YOLO leads on irrigator and bip olar. Gemma has higher precision on all 6 to ols; YOLO has higher recall on 5 of 6. Sorted by Gemma F1. Best p er row in b old. Precision Recall F1 R OC-AUC T o ol YOLO Gemma YOLO Gemma YOLO Gemma YOLO Gemma ho ok .953 .972 .986 .977 .969 .974 .992 .989 clipp er .902 .936 .910 .895 .906 .915 .967 .989 grasp er .860 .899 .953 .927 .904 .913 .958 .941 irrigator .910 .929 .819 .703 .862 .800 .955 .969 bip olar .920 .944 .776 .743 .842 .831 .920 .959 scissors .884 .888 .578 .599 .699 .715 .825 .947 W e additionally sweep LoRA rank from 2 to 1,024 on CholecT50 using the same proto col as Section 3.4 . Figure 7 sho ws accuracy as a function of rank. T raining accuracy increases from 67.1% (95% CI: 66.8%–67.5%) at r = 2 to 95.9% (95% CI: 95.8%–96.1%) at r = 1024 . V alidation accuracy increases from 64.7% (95% CI: 64.0%–65.4%) at r = 2 to 85.1% (95% CI: 84.5%–85.6%) at r = 1024 . Unlik e SDSC-EEA, where v alidation accuracy exhibits a non-monotonic relationship with rank and remains below 40% ev en at r = 1024 , CholecT50 v alidation accuracy increases monotonically across all tested ranks and reaches 85.1% at r = 1024 . 15 2 4 8 16 32 64 128 256 512 1024 L oR A R ank (r) 0 20 40 60 80 100 Exact Match A ccuracy (%) Majority Class Baseline (V alidation) T rain V alidation Figure 7: Exact matc h accuracy vs. LoRA rank on CholecT50. Unlike SDSC-EEA (Figure 6 ), v alidation accuracy increases monotonically across all ranks, reac hing 85.1% at r = 1024 , with a m uch smaller train–v alidation gap. The lo wer to ol diversit y (6 vs. 31 classes) and more uniform video-lev el distribution mak e CholecT50 more amenable to LoRA fine-tuning. Dashed line: ma jority class baseline (34.76%). Error bars: 95% b o otstrap CIs ( B = 1 , 000 ). 4 Discussion Despite the gro wing en thusiasm for some form of Med-A GI, our results on surgical to ol detection demonstrate that significant obstacles still exist when training generally-capable AI architectures to p erform sp ecialized medical tasks. As shown in Section 3.1 (T able 2 , Figures 2 – 3 ), 19 op en- w eight VLMs spanning 2B–235B parameters fail to surpass a trivial ma jority class baseline on surgical to ol detection, despite steady gains on general b enc hmarks. Fine-tuning closes part of the gap—Section 3.3 ac hieves 51.08% exact matc h accuracy with a classification head—but a p ersisten t train–v alidation gap (Figure 5 ) and the rank sw eep in Section 3.4 (Figure 6 ) confirm that scaling adapter capacity alone do es not resolv e the generalization b ottlenec k. Thus, our results suggest adv ancing surgical AI may require more task-sp ecialized approaches and—contrary to con ven tional wisdom—ma y not b e directly solv able by the “scaling law” approach of increasing computation or arc hitecture size [ Hestness et al. , 2017 , Kaplan et al. , 2020 , Ho et al. , 2025 ]. Mean while, Section 3.5 sho ws that YOLOv12-m, a 26M-parameter mo del, outperforms all VLM- based approaches (T ables 4 ), and Section 3.6 repro duces the same pattern (including on proprietary fron tier VLMs) on CholecT50 (T ables 5 - 6 , Figure 7 ), a dataset that is a v ailable in the public domain and ma y hav e b een included in the training of the underlying VLM. T aken together, these results sho w that sp ecialized computer vision mo dels match or outp erform VLMs at one thousandth of the cost measured in the n umber of parameters, whic h is directly prop ortional to compute and latency . The efficiency and sup eriorit y of these sp ecialized mo dels indicate that the next critical 16 adv ances in Surgical AI will most likely arise from a fo cused large-scale communit y effort to de- fragmen t data, achiev e consensus and lab eling at scale, and mak e data and lab els av ailable in an administrativ e/op erational context that would facilitate b etter training of such sp ecialized mo dels. Our results also suggest that one wa y to reconcile generality with p erformance is to treat the VLM as an orchestrator that can fit or select sp ecialized p erception mo dules on demand. The complemen tary strengths visible in T able 4 —where YOLO leads on recall and F1 across all to ols while Gemma leads on ROC-A UC for 8 of 15 to ols—suggest that h ybrid systems combining b oth mo del types could outp erform either alone. A promising direction for future researc h is exploring the b est approac hes for build and improving suc h hierarc hical systems, with the generalist mo del delegating to sp ecialized mo dels for high-precision subtasks. Need for Comm unit y-Driven Progress: P ersp ectiv es from the SDSC. Some authors of this pap er are members of the Surgical Data Science Collective (SDSC) , a nonprofit dedicated to adv ancing op en, collaborative, and clinically-grounded approac hes to surgical AI. Our experiences in dev eloping collab orativ e AI to ols for surgeons suggest that assem bling large-scale data, ontologies, and lab els is a critical prerequisite step for building useful clinical to ols. This inv olv es building curated datasets, domain sp ecific innov ations, and efficient annotation framewor ks. Moreov er, suc h an effort m ust b e supp orted by a communit y- and consensus-fo cused effort, led b y coalitions of aligned organizations. By fostering m ulti-institutional collaboration, standardizing data-sharing proto cols, and developing op en access to ols, SDSC and similar organizations seeks to rapidly adv ance surgical AI to achiev e clinical relev ance, equitable access, and real world impact. The SDSC b eliev es that surgical AI is constrained less b y mo del scale than by the av ailabilit y of clinically relev ant data. Despite adv ances in foundation mo dels, b oth the SDSC’s practical ex- p erience and the results in this pap er indicate that p erformance on basic p erceptual tasks remains limited under realistic distribution shift—as evidenced by the widening train–v alidation gap across LoRA ranks (Section 3.4 , Figure 6 ) and the unev en p er-to ol recall driven by pro cedure-lev el to ol im balance (Section 3.2 , T able 7 ). This indicates that significan t gaps remain in domain-sp ecific data co verage and suggests that improv ements will dep end on the developmen t of large-scale, standard- ized surgical datasets that capture v ariabilit y across pro cedures, institutions, and patient p opula- tions. In this setting, the SDSC and similar organizations can pla y an imp ortan t role in enabling cross-institutional data aggregation and establishing shared standards. In addition to the need for sp ecialized data, this pap er’s findings indicate that the most promis- ing path forw ard may not b e pushing tow ards more p ow erful end-to-end AI mo dels, but rather dev eloping h ybrid systems in whic h generalist mo dels are complemen ted b y specialized comp o- nen ts, consisten t with the strong p erformance of smaller task-sp ecific models (Sections 3.5 and 3.6 ). A ccordingly , the research and dev elopment of suc h hybrid models has b een a key focus at the SDSC [ Masson-F orsythe et al. , 2024 , Co ok et al. , 2025a , b ]. 5 Exploratory Next Steps: Natural Language vs. Op erating Ro om As an exploratory next step, in App endix N , we conduct a preliminary exp erimen t where LLMs app ear to give almost entirely correct resp onses to questions relating to pituitary tumor surgery . Ho wev er, as we ha ve demonstrated earlier, the same mo dels fail at a simple task of to ol detection. This result is not surprising: consider that neurosurgeons train primarily through practice. The A ccreditation Council for Graduate Medical Education (A CGME) requires 7 years of residency , t ypically completed after 2 years of rotations in medical school, compared to only 2 y ears of classro om and anatomy lab education ACGME [ 2025 ]. The idea that tacit knowledge in such jobs is more 17 imp ortan t than what can be written down is not new. In the con text of job market automation, this is often referred to as Polan yi’s paradox Autor [ 2014 ]. The challenge with medical AI is that the data for pretraining foundation mo dels lacks information from the op erating ro om. So, while it is conceiv able that scaling foundation mo dels could solve Med-A GI without domain-specific data, the evidence so far do es not supp ort this idea. 6 Limitations This study has several limitations. First, our ev aluation is restricted to surgical to ol detection: T o ol detection is a prerequisite for any system aspiring to general surgical intelligence, but we do not ev aluate higher-order capabilities such as phase recognition, decision supp ort, or anomaly detection. It is p ossible that VLMs offer greater adv an tages on these more abstract tasks, where language- mediated reasoning plays a larger role. Second, our VLM ev aluation fo cuses on op en-w eight models with a specific prompting and deco ding setup. Stronger closed-source models, alternativ e prompting strategies, or more extensive instruction tuning could yield different results. Third, the degree to whic h our conclusions generalize to other surgical sp ecialties, institutions, and recording conditions remains an op en question, although the consistency of the tak eaw a ys on CholecT50 with those that w e found on our own data suggests the broad pattern holds across at least t wo distinct surgical domains. Finally , while w e did our b est to conduct scaling exp eriments within our computational means, it remains p ossible that future mo dels ma y show non-linear “emergen t” jumps in p erformance if mo del size and training duration scale past a yet-to-be-discov ered threshold [ W ei et al. , 2022 ]. 7 Conclusion In this pap er, we ev aluate how m uch recent progress in large vision-language mo dels and scaling can bring us closer to the p opular notion of Med-AGI b y using surgical to ol detection in endoscopic endonasal neurosurgery as a case study . Section 3.1 shows that across 19 op en-w eight VL Ms span- ning 2B to 235B parameters, zero-shot p erformance on held-out pro cedures remains at or near a trivial ma jority class baseline, despite large gains on general benchmarks lik e MMBenc h. Section 3.3 demonstrates that LoRA fine-tuning with a classification head improv es p erformance substan tially , reac hing 51.08% exact match accuracy , but a p ersisten t train–v alidation gap reflects limited gener- alization under pro cedure-lev el distribution shift. Section 3.4 rules out insufficient capacity as the cause: scaling LoRA rank by nearly three orders of magnitude saturates training accuracy near 99% while v alidation accuracy remains b elo w 40%. Section 3.5 sho ws that YOLOv12-m, a 26M- parameter ob ject detection mo del—o ver 1,000 × smaller than the VLM—outp erforms all VLM-based approac hes at a fraction of the training time and inference cost. Section 3.6 replicates these find- ings (including comparisons with proprietary fron tier VLMs) on CholecT50, a public laparoscopic c holecystectomy dataset, confirming that the same patterns hold across surgical domains. Our findings suggest that progress to ward reliable surgical AI is lik ely more constrained by limited amounts of sp ecialized data than by the scale of p oten tial AI architectures and training resources. Small sp ecialized mo dels can outp erform large foundation mo dels on narrow surgical tasks while b eing orders of magnitude more efficien t. Thus, future efforts to p o ol and lab el surgical data across institutions will b e crucial to improving Surgical AI capabilities. 18 F unding and Supp ort. This pro ject is jointly funded by the Bo oth School of Business at UChicago, the Center for Applied AI at Chicago Bo oth, and the Surgical Data Science Collec- tiv e (SDSC). Collab orativ e data sharing b et ween Chicago Bo oth and the SDSC w as facilitated b y the T olan Center for Healthcare at Chicago Booth and the SDSC Engineering T eam. Computational exp erimen ts were conducted on the Pythia Sup ercomputer Cluster at Chicago Bo oth. References A CGME. Acgme program requirements for graduate medical education in neurological surgery , 2025. URL https://www.acgme.org/globalassets/pfassets/programrequirements/ 2025- reformatted- requirements/160_neurologicalsurgery_2025_reformatted.pdf . An thropic. Introducing Claude Opus 4.6, F ebruary 2026. URL https://www.anthropic.com/news/claude- opus- 4- 6 . Leop old Aschen brenner. Situational aw areness: The decade ahead, 2024. URL https://situational- awareness.ai . Da vid Autor. Polan yi’s paradox and the shap e of emplo yment growth. W orking Paper 20485, National Bureau of Economic Research, September 2014. URL http://www.nber.org/papers/w20485 . Sh uai Bai, Y uxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, W ei Ding, Chang Gao, Chunjiang Ge, W enbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, F ei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Jun yang Lin, Xuejing Liu, Jiaw ei Liu, Chenglong Liu, Y ang Liu, Dayiheng Liu, Shixuan Liu, Dunjie Lu, Ruilin Luo, Chenxu Lv, Rui Men, Lingchen Meng, Xuancheng Ren, Xingzhang Ren, Sib o Song, Y uchong Sun, Jun T ang, Jianhong T u, Jianqiang W an, P eng W ang, Pengfei W ang, Qiuyue W ang, Y uxuan W ang, Tianbao Xie, Yiheng Xu, Haiyang Xu, Jin Xu, Zhib o Y ang, Mingkun Y ang, Jianxin Y ang, An Y ang, Bow en Y u, F ei Zhang, Hang Zhang, Xi Zhang, Bo Zheng, Humen Zhong, Jingren Zhou, F an Zhou, Jing Zhou, Y uanzhi Zhu, and Ke Zh u. Qw en3-vl technical rep ort, 2025a. URL . Sh uai Bai, Keqin Chen, Xuejing Liu, Jialin W ang, W en bin Ge, Sib o Song, Kai Dang, Peng W ang, Shijie W ang, Jun T ang, Humen Zhong, Y uanzhi Zhu, Mingkun Y ang, Zhaohai Li, Jianqiang W an, Pengfei W ang, W ei Ding, Zheren F u, Yiheng Xu, Jiab o Y e, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhib o Y ang, Haiyang Xu, and Juny ang Lin. Qwen2.5-vl technical rep ort, 2025b. URL . Sébastien Bub eck, V arun Chandrasek aran, Ronen Eldan, Johannes Gehrke, Eric Horvitz, Ece Kamar, Peter Lee, Yin T at Lee, Y uanzhi Li, Scott Lundb erg, Harsha Nori, Hamid Palangi, Marco T ulio Rib eiro, and Yi Zhang. Sparks of artificial general intelligence: Early exp erimen ts with gpt-4, 2023. UR L . Aak anksha Chowdhery , Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Rob erts, Paul Barham, Hyung W on Chung, Charles Sutton, Sebastian Gehrmann, P arker Sc huh, Kensen Shi, Sasha T svyashc henk o, Joshua Maynez, Abhishek Rao, P arker Barnes, Yi T ay , Noam Shazeer, Vino dkumar Prabhak aran, Emily Reif, Nan Du, Ben Hutchinson, Reiner P op e, James Bradbury , Jacob Austin, Mic hael Isard, Guy Gur-Ari, Pengc heng Yin, T o ju Duke, Anselm Levsk ay a, Sanjay Ghemaw at, Sunipa Dev, Henryk Michalewski, Xavier Garcia, V edant 19 Misra, Kevin Robinson, Liam F edus, Denn y Zhou, Daphne Ipp olito, Da vid Luan, Hyeon taek Lim, B arret Zoph, Alexander Spiridono v, Ryan Sepassi, David Dohan, Shiv ani Agraw al, Mark Omernic k, Andrew M. Dai, Thanumala yan Sank aranara yana Pillai, Marie Pellat, Aitor Lewk owycz, Erica Moreira, Rewon Child, Oleksandr P olozov, Katherine Lee, Zongwei Zhou, Xuezhi W ang, Brennan Saeta, Mark Diaz, Orhan Firat, Mic hele Catasta, Jason W ei, Kathy Meier-Hellstern, Douglas Eck, Jeff Dean, Slav Petro v, and Noah Fiedel. Palm: Scaling language mo deling with pathw ays, 2022. URL . Jac k Co ok, Jonathan Chainey , Ruth Lau, Margaux Masson-F orsythe, A yesha Syeda, Kaan Duman, Daniel Donoho, Dhira j A Pangal, and Juan Viv anco Suarez. Enhancing surgical video phase recognition with adv anced ai mo dels for endoscopic pituitary tumor surgery . Journal of Neur olo gic al Sur gery Part B: Skul l Base , 86(S 01):S335, 2025a. Jac k Co ok, A yesha Sy eda, Margaux Masson-F orsythe, Dhira j Pangal, and Daniel Donoho. 1255 enhancing surgical computer vision: A real-time monitoring system for mo del p erformance and data quality . Neur osur gery , 71(Supplement_1):202, 2025b. Krit Duangprom, T ryphon Lambro u, and Bino d Bhattarai. Estimating 2d k eyp oin ts of surgical to ols using vision-language mo dels with low-rank adaptation, 2025. URL https://arxiv.org/abs/2508.20830 . Gemini T eam. Gemini 3.1 pro: A smarter mo del for your most complex tasks, F ebruary 2026. URL https://blog.google/innovation- and- ai/models- and- research/gemini- models/ gemini- 3- 1- pro/ . Gemma-T eam, Aishw arya Kamath, Johan F erret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, T atiana Matejo vicov a, Alexandre Ramé, Morgane Rivière, Louis Rouillard, Thomas Mesnard, Geoffrey Cideron, Jean bastien Grill, Sab ela Ramos, Edouard Y vinec, Mic helle Casb on, Etienne Pot, Ivo Penc hev, Gaël Liu, F rancesco Visin, Kathleen Kenealy , Lucas Bey er, Xiaohai Zhai, Anton T sitsulin, Rob ert Busa-F ekete, Alex F eng, Nov een Sachdev a, Benjamin Coleman, Yi Gao, Basil Mustafa, Iain Barr, Emilio Parisotto, David Tian, Matan Ey al, Colin Cherry , Jan-Thorsten Peter, Danila Sinopalniko v, Surya Bhupatira ju, Rishabh Agarw al, Mehran Kazemi, Dan Malkin, Ravin Kumar, David Vilar, Idan Brusilo vsky , Jiaming Luo, Andreas Steiner, Ab e F riesen, Abhanshu Sharma, Abheesht Sharma, A di Mayra v Gilady , A drian Go edec kemey er, Alaa Saade, Alex F eng, Alexander K olesniko v, Alexei Bendebury , Alvin Ab dagic, Amit V adi, András György , André Susano Pinto, Anil Das, Ankur Bapna, Antoine Miec h, Antoine Y ang, Antonia Paterson, Ashish Sheno y , A yan Chakrabarti, Bilal Piot, Bo W u, Bobak Shahriari, Bryce Petrini, Charlie Chen, Charline Le Lan, Christopher A. Cho quette-Choo, CJ Carey , Cormac Brick, Daniel Deutsch, Danielle Eisenbud, Dee Cattle, Derek Cheng, Dimitris Paparas, Divyashree Shiv akumar Sreepathihalli, Doug Reid, Dustin T ran, Dustin Zelle, Eric Noland, Erwin Huizenga, Eugene Kharitono v, F rederic k Liu, Gagik Amirkhan yan, Glenn Cameron, Hadi Hashemi, Hanna Klimczak-Plucińsk a, Harman Singh, Harsh Mehta, Harshal T ushar Lehri, Hussein Hazimeh, Ian Ballant yne, Idan Szp ektor, Iv an Nardini, Jean Pouget-Abadie, Jetha Chan, Jo e Stan ton, John Wieting, Jonathan Lai, Jordi Orba y , Joseph F ernandez, Josh Newlan, Ju y eong Ji, Jyotinder Singh, Kat Black, Kath y Y u, Kevin Hui, Kiran V o drahalli, Klaus Greff, Linhai Qiu, Marcella V alentine, Marina Co elho, Marvin Ritter, Matt Hoffman, Matthew W atson, Ma yank Chaturvedi, Michael Mo ynihan, Min Ma, Nabila Babar, Natasha Noy , Nathan Byrd, Nick Roy , Nikola Momchev, Nilay Chauhan, No veen Sachdev a, Osk ar Bun yan, Pankil Botarda, P aul Caron, Paul Kishan Rub enstein, Phil Culliton, Philipp Schmid, Pier Giusepp e Sessa, Pingmei Xu, Piotr Stanczyk, P ouya T afti, 20 Rak esh Shiv anna, Renjie W u, Renk e Pan, Reza Rokni, Rob Willoughb y , Rohith V allu, Ryan Mullins, Sammy Jerome, Sara Smo ot, Sertan Girgin, Shariq Iqbal, Shashir R eddy , Shruti Sheth, Siim Põder, Sijal Bhatnagar, Sindhu Raghuram Pan yam, Siv an Eiger, Susan Zhang, Tianqi Liu, T revor Y acov one, Tyler Liech ty , Uday Kalra, Utku Evci, V edant Misra, Vincent Roseb erry , Vlad F einberg, Vlad Kolesnik ov, W o oh yun Han, W o osuk Kw on, Xi Chen, Yinlam Chow, Y uvein Zhu, Zic huan W ei, Zoltan Egyed, Victor Cotruta, Minh Giang, Pho ebe Kirk, Anand Rao, Kat Black, Nabila Babar, Jessica Lo, Erica Moreira, Luiz Gustav o Martins, Omar Sanseviero, Lucas Gonzalez, Zach Gleicher, T ris W ark entin, V ahab Mirrokni, Ev an Sen ter, Eli Collins, Jo elle Barral, Zoubin Ghahramani, Raia Hadsell, Y ossi Matias, D. Sculley , Slav P etrov, Noah Fiedel, Noam Shazeer, Oriol Vin yals, Jeff Dean, Demis Hassabis, Kora y Ka vukcuoglu, Clemen t F arab et, Elena Buchatsk ay a, Jean-Baptiste Alayrac, Rohan Anil, Dmitry , Lepikhin, Sebastian Borgeaud, Olivier Bachem, Armand Joulin, Alek Andreev, Cassidy Hardin, Rob ert Dadashi, and Léonard Hussenot. Gemma 3 tec hnical rep ort, 2025. URL . P aul Hager, F riederike Jungmann, Robbie Holland, Kunal Bhagat, Inga Hubrech t, Manuel Knauer, Jakob Vielhauer, Marcus Mako wski, Ric kmer Braren, Georgios Kaissis, and Daniel Ruec kert. Ev aluation and mitigation of the limitations of large language mo dels in clinical decision-making. Natur e Me dicine , 30(9):2613–2622, 2024. doi: 10.1038/s41591- 024- 03097- 1. URL https://doi.org/10.1038/s41591- 024- 03097- 1 . Kaiming He, Xiangyu Zhang, Shao qing Ren, and Jian Sun. Deep residual learning for image recognition, 2015. URL . Jo el Hestness, Sharan Narang, Newsha Ardalani, Gregory Diamos, Heewoo Jun, Hassan Kianinejad, Md Mostofa Ali Pat wary , Y ang Y ang, and Y anqi Zhou. Deep learning scaling is predictable, empirically . arXiv pr eprint arXiv:1712.00409 , 2017. Anson Ho, Jean-Stanislas Denain, David Atanaso v, Sam uel Albanie, and Rohin Shah. A rosetta stone for ai b enchmarks. arXiv pr eprint arXiv:2512.00193 , 2025. Edw ard J. Hu, Y elong Shen, Phillip W allis, Zeyuan Allen-Zh u, Y uanzhi Li, Shean W ang, Lu W ang, and W eizhu Chen. Lora: Low-rank adaptation of large language mo dels, 2021. URL https://arxiv.org/abs/2106.09685 . Jared Kaplan, Sam McCandlish, T om Henighan, T om B. Brown, Benjamin Chess, Rew on Child, Scott Gray , Alec Radford, Jeffrey W u, and Dario Amo dei. Scaling laws for neural language mo dels, 2020. URL . Shen Li, Y anli Zhao, Rohan V arma, Omk ar Salp ek ar, Pieter No ordh uis, T eng Li, Adam Paszk e, Jeff Smith, Brian V aughan, Pritam Damania, and Soumith Chin tala. Pytorch distributed: Exp eriences on accelerating data parallel training, 2020. URL https://arxiv.org/abs/2006.15704 . Haotian Liu, Chun yuan Li, Y uheng Li, and Y ong Jae Lee. Improv ed baselines with visual instruction tuning, 2024a. URL . Y uan Liu, Hao dong Duan, Y uanhan Zhang, Bo Li, Songyang Zhang, W angb o Zhao, Yike Y uan, Jiaqi W ang, Conghui He, Ziwei Liu, Kai Chen, and Dahua Lin. Mmbench: Is your multi-modal mo del an all-around play er?, 2024b. URL . 21 Margaux Masson-F orsythe, Juan Viv anco Suarez, Muhammad Ammar Haider, James K Liu, and Daniel A Donoho. Ai-based surgical to ols detection from endoscopic endonasal pituitary videos. Journal of Neur olo gic al Sur gery Part B: Skul l Base , 85(S 01):S224, 2024. Meta. Llama 3.2: Rev olutionizing edge ai and vision with op en, customizable mo dels. https://ai.meta.com/blog/llama- 3- 2- connect- 2024- vision- edge- mobile- devices/ , Septem b er 2024. A ccessed: 2025-12-30. Chinedu Inno cent Nw oy e, T ong Y u, Cristians Gonzalez, Barbara Seeliger, Pietro Mascagni, Didier Mutter, Jacques Marescaux, and Nicolas Pado y . Rendezvous: Atten tion mec hanisms for the recognition of surgical action triplets in endoscopic videos. Me dic al Image Analysis , 78:102433, 2022. Op enAI. Introducing GPT-5.4, March 2026. URL https://openai.com/index/introducing- gpt- 5- 4/ . Khaled Saab, T ao T u, W ei-Hung W eng, Ryutaro T anno, David Stutz, Ellery W ulczyn, F an Zhang, Tim Strother, Chunjong Park, Elahe V edadi, Juanma Zambrano Chav es, Szu-Y eu Hu, Mik e Sc haekermann, Aishw arya Kamath, Y ong Cheng, David G. T. Barrett, Cathy Cheung, Basil Mustafa, Anil Palepu, Daniel McDuff, Le Hou, T omer Golany , Luy ang Liu, Jean baptiste Ala yrac, Neil Houlsby , Nenad T omasev, Jan F reyb erg, Charles Lau, Jonas Kemp, Jeremy Lai, Shek o ofeh Azizi, Kimberly Kanada, SiW ai Man, Ka vita Kulk arni, Ruo xi Sun, Siamak Shakeri, Luheng He, Ben Caine, Alb ert W ebson, Natasha Latyshev a, Melvin Johnson, Philip Mansfield, Jian L u, Eh ud Rivlin, Jesp er Anderson, Bradley Green, Renee W ong, Jonathan Krause, Jonathon Shlens, Ewa Dominowsk a, S. M. Ali Eslami, Katherine Chou, Claire Cui, Oriol Vin yals, Kora y Kavuk cuoglu, James Man yik a, Jeff Dean, Demis Hassabis, Y ossi Matias, Dale W ebster, Jo elle Barral, Greg Corrado, Christopher Semturs, S. Sara Mahdavi, Jura j Gottw eis, Alan Karthikesalingam, and Vivek Natara jan. Capabilities of gemini mo dels in medicine, 2024. URL . Sam uel Schmidgall, Joseph Cho, Cyril Zakk a, and William Hiesinger. Gp-vls: A general-purp ose vision language mo del for surgery , 2024. URL . Lalithkumar Seeniv asan, Mobarakol Islam, A dithy a K Krishna, and Hongliang Ren. Surgical-vqa: Visual question answering in surgical scenes using transformer, 2022. URL https://arxiv.org/abs/2206.11053 . Andrew Sellergren, Sahar Kazemzadeh, Tiam Jaro ensri, Atilla Kiraly , Madeleine T rav erse, Timo K ohlb erger, Shawn Xu, F ay az Jamil, Cían Hughes, Charles Lau, Justin Chen, F ereshteh Mahv ar, Liron Y atziv, Tiffany Chen, Bram Sterling, Stefanie Anna Baby , Susanna Maria Baby , Jeremy Lai, Samuel Schmidgall, Lu Y ang, Kejia Chen, Per Bjornsson, Shashir Reddy , Ryan Brush, Kenneth Philbrick, Mercy Asiedu, Ines Mezerreg, How ard Hu, Ho ward Y ang, Richa Tiwari, Sunn y Jansen, Preeti Singh, Y un Liu, Shekoofeh Azizi, Aishw ary a Kamath, Johan F erret, Shrey a Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, T atiana Matejovico v a, Alexandre Ramé, Morgane Riviere, Louis Rouillard, Thomas Mesnard, Geoffrey Cideron, Jean bastien Grill, Sab ela Ramos, Edouard Y vinec, Michelle Casb on, Elena Buchatsk a ya, Jean-Baptiste Ala yrac, Dmitry Lepikhin, Vlad F einberg, Sebastian Borgeaud, Alek Andreev, Cassidy Hardin, Rob ert Dadashi, Léonard Hussenot, Armand Joulin, Olivier Bachem, Y ossi Matias, Katherine Chou, A vinatan Hassidim, Kavi Go el, Clement F arab et, Jo elle Barral, T ris W arken tin, Jonathon Shlens, David Fleet, Victor Cotruta, Omar Sanseviero, Gus Martins, Pho eb e Kirk, Anand Rao, 22 Shra vya Shetty , David F. Steiner, Can Kirmizibayrak, Rory Pilgrim, Daniel Golden, and Lin Y ang. Medgemma technical rep ort, 2025. URL . Surgical Data Science Collective (SDSC). Surgical data science collective: F rom surgical data to clinical discov ery , 2026. URL https://www.surgicalvideo.io . Accessed: 2026-03-05. Y unjie Tian, Qixiang Y e, and David Do ermann. Y olo v12: Atten tion-cen tric real-time ob ject detectors, 2025. URL . P eng W ang, Shuai Bai, Sinan T an, Shijie W ang, Zhihao F an, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin W ang, W enbin Ge, Y ang F an, Kai Dang, Mengfei Du, Xuancheng Ren, Rui Men, Da yiheng Liu, Chang Zhou, Jingren Zhou, and Juny ang Lin. Qwen2-vl: Enhancing vision-language mo del’s p erception of the world at any resolution, 2024. URL https://arxiv.org/abs/2409.12191 . Jason W ei, Yi T ay , Rishi Bommasani, Colin Raffel, Barret Zoph, Sebastian Borgeaud, Dani Y ogatama, Maarten Bosma, Denny Zhou, Donald Metzler, Ed H. Chi, T atsunori Hashimoto, Oriol Viny als, Percy Liang, Jeff Dean, and William F edus. Emergent abilities of large language mo dels, 2022. URL . Chao yi W u, Xiaoman Zhang, Y a Zhang, Hui Hui, Y anfeng W ang, and W eidi Xie. T o wards generalist foundation mo del for radiology by lev eraging web-scale 2d&3d medical data. Natur e Communic ations , 16(1):7866, 2025. doi: 10.1038/s41467- 025- 62385- 7. URL https://doi.org/10.1038/s41467- 025- 62385- 7 . 23 A T o ol Distribution A cross T rain/V alidation Splits T able 7 shows the num b er of frames containing each to ol in the training set ( n = 47 , 618 frames, 53 pro cedures) and v alidation set ( n = 20 , 016 frames, 13 pro cedures). Because the split is p erformed at the pro cedure level, the p er-tool distribution across splits is highly uneven. Sev eral to ols app ear almost exclusively in one split: for example, Aspirating dissector has 88 training instances v ersus 2,319 v alidation instances, and Sonop et pineapple tip has 1,991 training instances v ersus zero in v alidation. T able 7: Number of frames con taining each to ol in the training ( n = 47 , 618 ) and v alidation ( n = 20 , 016 ) splits, with p ercentage of frames in eac h split. Sorted by total count in descending order. T rain V alidation T o ol N % N % T otal Suction 29,692 62.4 10,685 53.4 40,377 Cotton P atty 8,822 18.5 2,143 10.7 10,965 Grasp er 6,812 14.3 509 2.5 7,321 Rhoton Dissector 4,249 8.9 1,462 7.3 5,711 Curette 4,829 10.1 708 3.5 5,537 Rongeur 1,730 3.6 2,790 13.9 4,520 Scissor 2,928 6.1 996 5.0 3,924 Drill 1,639 3.4 2,116 10.6 3,755 Surgicel 2,847 6.0 739 3.7 3,586 Surgical Knife 1,364 2.9 1,422 7.1 2,786 Suction Coagulator 1,400 2.9 1,188 5.9 2,588 Aspirating dissector 88 0.2 2,319 11.6 2,407 Bip olar F orceps 1,934 4.1 263 1.3 2,197 Sonop et pineapple tip 1,991 4.2 0 0.0 1,991 Straigh t F orceps 1,602 3.4 173 0.9 1,775 Doppler 1,592 3.3 0 0.0 1,592 unkno wn 1,172 2.5 23 0.1 1,195 Bac kbiting rongeur 144 0.3 1,041 5.2 1,185 Tissue sha ver 934 2.0 57 0.3 991 Cottle Elev ator 855 1.8 0 0.0 855 Through cutting forceps 255 0.5 542 2.7 797 Suction microdebrider 94 0.2 497 2.5 591 Floseal Gel 502 1.1 40 0.2 542 Collagen Matrix 280 0.6 0 0.0 280 Floseal Applicator 199 0.4 40 0.2 239 Monop olar Electrocautery 190 0.4 0 0.0 190 Lo cal Anesthesia Needle 139 0.3 0 0.0 139 Straigh t Curette 102 0.2 16 0.1 118 Needle 31 0.1 0 0.0 31 Tisseel Applicator 23 0.0 0 0.0 23 B Zero-Shot Ev aluation Prompt T emplate The following prompt template is used for zero-shot tool detection ev aluation across all vision- language mo dels. 24 Prompt T emplate Identify all surgical tools visible in this surgical video frame. Valid tool names: - Aspirating dissector - Backbiting rongeur - Bipolar Forceps - Collagen Matrix - Cotton Patty - Cottle Elevator - Curette - Doppler - Drill - Floseal Applicator - Floseal Gel - Grasper - Irrigation - Local Anesthesia Needle - Monopolar Electrocautery - Needle - Rhoton Dissector - Rongeur - Scissor - Sonopet- pineapple tip - Straight Curette - Straight Forceps - Suction - Suction Coagulator - Suction microdebrider - Surgicel - Surgical Knife - Tisseel Applicator - Tissue shaver - Through cutting forceps - unknown Return your answer as a JSON object with this exact format: {"detected_tools": ["Tool Name 1", "Tool Name 2"]} Use ONLY the exact tool names from the list above. If a tool appears multiple times, list it only once. If no tools are visible, return: {"detected_tools": []} Return ONLY valid JSON, nothing else. C Output V alidation Metho dology Mo del outputs are parsed b y extracting the first v alid JSON ob ject from the resp onse text using regex matching. An output is classified as an output v alidation failure if it meets an y of the follo wing conditions: (1) the resp onse do es not con tain v alid JSON or is missing the detected_tools key (JSON failure), (2) the detected_tools v alue is not an arra y of strings (schema failure), or (3) 25 the array contains to ol names that do not exactly matc h any entry in the provided ontology of 31 v alid to ol names (ontology failure, e.g., missp ellings, capitalization mismatc hes, or hallucinated tool names). All output v alidation failures are treated as empt y predictions ( detected_tools: [] ). This ensures that a mo del’s inabilit y to follow the output format or correctly name to ols is penalized rather than silently excluded. Representativ e failure examples are sho wn in App endix G . D LoRA Fine-T uning Configuration All fine-tuning exp eriments use a fixed random seed of 42 for repro ducibility . LoRA adapters [ Hu et al. , 2021 ] are applied to the query , k ey , v alue, and output pro jection matrices in both the language mo del and vision enco der attention lay ers ( q_proj , k_proj , v_proj , o_proj , out_proj ). JSON Generation (Section 3.2 ). LoRA rank r = 1024 , scaling factor α = 2048 , drop out 0.05. T raining: 10 ep ochs, learning rate 2 × 10 − 5 , effectiv e batch size 64 (p er-GPU batc h size 1 × 8 gradien t accumulation steps × 8 H200 GPUs), bfloat16 precision. Gradient c heckpointing is used to reduce memory consumption. T raining is distributed using PyT orch DDP [ Li et al. , 2020 ]. T raining and ev aluation required 80 wall-clock hours (640 GPU-hours on H200 GPUs). During training, exact match accuracy and Jaccard similarit y are p erio dically ev aluated on fixed random subsets of 100 training and 100 v alidation frames. Classification Head (Section 3.3 ). The base mo del pro cesses the image and prompt, and we apply mean po oling o ver the final hidden states (excluding padding tok ens) to obtain a fixed- dimensional representation. A single linear lay er (no hidden lay ers) maps this representation to 31 output logits (one p er to ol class), trained with binary cross-en tropy loss a veraged across all to ol classes. A t inference, w e apply a sigmoid activ ation and threshold at 0.5 to obtain binary predictions. LoRA rank r = 1024 , α = 2048 , drop out 0.05. T raining: 10 ep o c hs, learning rate 5 × 10 − 6 , effectiv e batch size 32 (p er-GPU batc h size 1 × 4 gradien t accumulation steps × 8 H200 GPUs). Rank Sw eep (Section 3.4 ). W e sw eep LoRA ranks r ∈ { 2 , 4 , 8 , 16 , 32 , 64 , 128 , 256 , 512 , 1024 } , setting α = 2 r for each. T raining: 3 ep ochs p er configuration, effective batch size 32, with other settings matc hing the classification head configuration ab o ve. The full sw eep required approximately 62 wall-clock hours (492 GPU-hours on H200 GPUs). T rainable parameters scale linearly with rank, from 4.7M at r = 2 to 2.4B at r = 1024 . F or eac h configuration, w e rep ort training and v alidation exact match accuracy with 95% confidence interv als. E P er-T o ol Metrics for LoRA Fine-T uning with JSON Output T able 8 shows p er-tool classification metrics on the v alidation set ( n = 20 , 016 frames) for Gemma 3 27B fine-tuned with LoRA to pro duce JSON outputs. 26 T able 8: Per-tool classification metrics for Gemma 3 27B with LoRA fine-tuning (JSON output). TP = true p ositives, FP = false p ositiv es, FN = false negativ es, TN = true negatives. T o ol TP FP FN TN Accuracy Precision Recall F1 Aspirating dissector 0 0 2319 17697 0.884 0.000 0.000 0.000 Bac kbiting rongeur 141 44 900 18931 0.953 0.762 0.135 0.230 Bip olar F orceps 0 103 263 19650 0.982 0.000 0.000 0.000 Cottle Elev ator 0 271 0 19745 0.987 0.000 0.000 0.000 Cotton Patt y 1729 639 414 17234 0.947 0.730 0.807 0.767 Curette 103 3 605 19305 0.970 0.972 0.145 0.253 Doppler 0 31 0 19985 0.999 0.000 0.000 0.000 Drill 1637 109 479 17791 0.971 0.938 0.774 0.848 Floseal Applicator 0 17 40 19959 0.997 0.000 0.000 0.000 Floseal Gel 2 90 38 19886 0.994 0.022 0.050 0.030 Grasp er 60 666 449 18841 0.944 0.083 0.118 0.097 Irrigation 9 104 103 19800 0.990 0.080 0.080 0.080 Monop olar Electro cautery 0 831 0 19185 0.959 0.000 0.000 0.000 Rhoton Dissector 799 3086 663 15468 0.813 0.206 0.546 0.299 Rongeur 522 1509 2268 15717 0.811 0.257 0.187 0.217 Scissor 530 703 466 18317 0.942 0.430 0.532 0.475 Sonop et- pineapple tip 0 1 0 20015 1.000 0.000 0.000 0.000 Straigh t F orceps 44 406 129 19437 0.973 0.098 0.254 0.141 Suction 9411 4289 1274 5042 0.722 0.687 0.881 0.772 Surgicel 347 36 392 19241 0.979 0.906 0.470 0.619 Through cutting forceps 1 11 541 19463 0.972 0.083 0.002 0.004 Tissue shav er 0 0 57 19959 0.997 0.000 0.000 0.000 unkno wn 2 1223 21 18770 0.938 0.002 0.087 0.003 F P er-T o ol Metrics for LoRA Fine-T uning with Classification Head T able 9 shows p er-tool classification metrics on the v alidation set ( n = 20 , 016 frames) for Gemma 3 27B fine-tuned with LoRA and a linear classification head. 27 T able 9: P er-to ol classification metrics for Gemma 3 27B with LoRA fine-tuning and classification head. TP = true p ositiv es, FP = false p ositives, FN = false negativ es, TN = true negatives. T o ol TP FP FN TN Accuracy Precision Recall F1 Aspirating dissector 0 0 2319 17697 0.884 0.000 0.000 0.000 Bac kbiting rongeur 20 7 1021 18968 0.949 0.741 0.019 0.038 Bip olar F orceps 0 10 263 19743 0.986 0.000 0.000 0.000 Collagen Matrix 0 0 0 20016 1.000 0.000 0.000 0.000 Cottle Elev ator 0 3 0 20013 1.000 0.000 0.000 0.000 Cotton Patt y 1513 1112 630 16761 0.913 0.576 0.706 0.635 Curette 169 9 539 19299 0.973 0.949 0.239 0.382 Doppler 0 1 0 20015 1.000 0.000 0.000 0.000 Drill 1672 98 444 17802 0.973 0.945 0.790 0.861 Floseal Applicator 0 0 40 19976 0.998 0.000 0.000 0.000 Floseal Gel 2 1 38 19975 0.998 0.667 0.050 0.093 Grasp er 10 307 499 19200 0.960 0.032 0.020 0.024 Irrigation 2 0 110 19904 0.995 1.000 0.018 0.035 Lo cal Anesthesia Needle 0 1 0 20015 1.000 0.000 0.000 0.000 Monop olar Electro cautery 0 0 0 20016 1.000 0.000 0.000 0.000 Needle 0 0 0 20016 1.000 0.000 0.000 0.000 Rhoton Dissector 863 735 599 17819 0.933 0.540 0.590 0.564 Rongeur 620 26 2170 17200 0.890 0.960 0.222 0.361 Scissor 135 82 861 18938 0.953 0.622 0.136 0.223 Sonop et- pineapple tip 0 0 0 20016 1.000 0.000 0.000 0.000 Straigh t Curette 0 0 16 20000 0.999 0.000 0.000 0.000 Straigh t F orceps 43 24 130 19819 0.992 0.642 0.249 0.358 Suction 9452 4604 1233 4727 0.708 0.673 0.885 0.764 Suction Coagulator 739 0 449 18828 0.978 1.000 0.622 0.767 Suction micro debrider 0 0 497 19519 0.975 0.000 0.000 0.000 Surgical Knife 69 6 1353 18588 0.932 0.920 0.049 0.092 Surgicel 464 14 275 19263 0.986 0.971 0.628 0.763 Through cutting forceps 0 1 542 19473 0.973 0.000 0.000 0.000 Tisseel Applicator 0 0 0 20016 1.000 0.000 0.000 0.000 Tissue shav er 2 4 55 19955 0.997 0.333 0.035 0.064 unkno wn 0 26 23 19967 0.998 0.000 0.000 0.000 T able 10 shows p er-tool ROC-A UC and A UPRC. 28 T able 10: P er-to ol ROC-A UC and A UPRC for Gemma 3 27B with LoRA fine-tuning and classifi- cation head. T o ol ROC-A UC AUPR C Suction Coagulator 1.000 0.995 Drill 0.983 0.935 Straigh t F orceps 0.943 0.351 Curette 0.940 0.600 Surgical Knife 0.939 0.578 Cotton Patt y 0.929 0.699 Rongeur 0.920 0.729 Rhoton Dissector 0.920 0.540 Bac kbiting rongeur 0.918 0.482 Surgicel 0.908 0.701 Floseal Gel 0.878 0.351 Straigh t Curette 0.841 0.008 Suction 0.819 0.847 Through cutting forceps 0.797 0.092 Irrigation 0.776 0.117 Scissor 0.766 0.259 Tissue shav er 0.737 0.099 Bip olar F orceps 0.723 0.043 Grasp er 0.708 0.047 Aspirating dissector 0.655 0.158 unkno wn 0.618 0.001 Floseal Applicator 0.494 0.002 Suction micro debrider 0.298 0.016 Macro A verage 0.805 0.376 The mo del achiev es high ROC-A UC ( > 0 . 9 ) for to ols well-represen ted in training (Suction Co- agulator, Drill, Straigh t F orceps, Curette, Surgical Knife, Cotton P atty , Rongeur, Rhoton Dissector, Bac kbiting rongeur, Surgicel), but low er v alues for to ols with limited training data or those app ear- ing predominantly in v alidation pro cedures. Our p er-to ol ev aluation metrics (ROC-A UC and A UPRC) are rep orted for the 23 surgical in- strumen ts that app ear in the v alidation set. G Zero-Shot Output V alidation F ailure Examples Output v alidation failures in zero-shot ev aluation are not merely JSON formatting issues. T able 11 sho ws represent ative failed outputs from Qw en2-VL-2B-Instruct, the mo del with the highest output v alidation failure rate (41.7%). In most cases, the mo del pro duces syntactically v alid JSON but hallucinates to ol names that do not exist in the provided list, such as “Stirrup Curtain,” “Parallel Shears,” “Microlaryngeal electro des,” and “Semitendinosus skin dissection.” These hallucinated names are not surgical instruments and indicate a fundamental failure in visual recognition, not a formatting limitation. 29 T able 11: Representativ e output v alidation failure examples from Qwen2-VL-2B-Instruct zero-shot ev aluation. Each row sho ws the mo del’s raw output and the failure category . Outputs are from randomly sampled frames (seed=42). Mo del Output F ailure Category {“detected_tools”: [“SCissor”]} Ontology: missp elled tool name (“SCissor” vs. “Scissor”) [“Curette”, “Floseal Gel”, “Straight Curette”, “Scissors”, “Single- Precision Scissors”, “Suction microdebrider”] JSON + Ontology: missing JSON wrapp er; “Scissors” and “Single- Pre- cision Scissors” not in v alid list {“detected_tools”: [“Backbiting Rongeur”, “Rhoton Dissector”]} On tology: capitalization mismatch (“Rongeur” vs. “rongeur”) {“detected_tools”: [“Collagen Matrix”, “Curette”, “Tourniquet”]} On tology: hallucinated to ol (“T ourniquet”) {“detected_tools”: [“Local Anesthesia Needle”]] JSON: malformed JSON (extra clos- ing brack et) {“detected_tools”: [“Aspirating dissector”, “Froseal Applicator”, “Froseal Gel”, “Grasper”, “Intraoperative Hemostat”, “Rhoton Dissector”]} On tology: missp elled tools (“F roseal”) and hallucinated to ol (“In traop erativ e Hemostat”) {“detected_tools”: [“Curette”, “Rhoton Dissector”, “Stirrup Curtain”, “Parallel Shears”]} On tology: hallucinated to ols (“Stir- rup Curtain,” “Parallel Shears”) {“detected_tools”: [“Microlaryngeal electrodes”, “Laryngeal transducers”, “Semitendinosus skin dissection”, “Subglottic surgery”, “Endoscopic cautery”, “Suture”, “Hydrofracture”]} On tology: all 7 predicted to ols are hallucinated; none are surgical in- strumen ts H YOLOv12-m T raining Configuration T able 12 sho ws the training configuration for YOLOv12-m used in Section 3.5 . All h yp erparameters use YOLO default v alues; no hyperparameter search w as p erformed. 30 T able 12: YOLOv12-m training configuration (300-ep o c h run with b est exact match set accuracy). P arameter V alue Mo del YOLOv12-m (26M parameters) Pretrained weigh ts yolo12m.pt (COCO) Ep ochs 300 Batc h size 32 total (4/GPU × 8 GPUs) Image size 1280 × 1280 Hardw are 8 × L40S GPUs T raining time 11.3 wall-clock hours (90.6 GPU-hours) Learning rate schedule Cosine Mixed precision AMP (automatic) Early stopping patience 20 ep o c hs Mosaic close ep o c h 10 Data caching Disabled (disk-based) Confidence threshold (ev al) 0.25 Random seed 42 I P er-T o ol Metrics for CholecT50 Ev aluation T ables 13 – 17 sho w per-to ol classification metrics on the CholecT50 v alidation set ( n = 19 , 923 frames) for zero-shot Gemma 3 27B, fine-tuned Gemma 3 27B, and YOLOv12-m. T able 13: P er-to ol classification metrics for Gemma 3 27B zero-shot on CholecT50. TP = true p ositiv es, FP = false p ositives, FN = false negativ es, TN = true negatives. T o ol TP FP FN TN A ccuracy Precision Recall F1 grasp er 6978 2740 5552 4653 0.584 0.718 0.557 0.627 ho ok 2092 883 8651 8297 0.522 0.703 0.195 0.305 bip olar 838 12096 246 6743 0.381 0.065 0.773 0.120 irrigator 247 4355 696 14625 0.747 0.054 0.262 0.089 clipp er 59 686 627 18551 0.934 0.079 0.086 0.083 scissors 163 3993 313 15454 0.784 0.039 0.342 0.070 In the zero-shot setting, bip olar has 12,096 false p ositiv es, irrigator has 4,355, and scissors has 3,993. Ho ok has a recall of 0.195. Grasp er achiev es the highest F1 (0.627). T able 14: Per-tool classification metrics for Gemma 3 27B fine-tuned (LoRA + classification head) on CholecT50. TP = true p ositiv es, FP = false p ositiv es, FN = false negatives, TN = true negativ es. T o ol TP FP FN TN Accuracy Precision Recall F1 grasp er 11614 1307 916 6086 0.888 0.899 0.927 0.913 ho ok 10491 306 252 8874 0.972 0.972 0.977 0.974 bip olar 805 48 279 18791 0.984 0.944 0.743 0.831 irrigator 663 51 280 18929 0.983 0.929 0.703 0.800 clipp er 614 42 72 19195 0.994 0.936 0.895 0.915 scissors 285 36 191 19411 0.989 0.888 0.599 0.715 After fine-tuning, the mo del achiev es a macro ROC-A UC of 0.966 and macro A UPRC of 0.883. 31 T able 15 shows p er-tool ROC-A UC and A UPRC. T able 15: Per-tool ROC-A UC and AUPR C for Gemma 3 27B fine-tuned on CholecT50. Sorted by R OC-AUC in descending order. T o ol R OC-AUC A UPRC ho ok 0.989 0.985 clipp er 0.989 0.909 irrigator 0.969 0.836 grasp er 0.941 0.960 bip olar 0.959 0.856 scissors 0.947 0.753 Macro A verage 0.966 0.883 After fine-tuning, ho ok achiev es the highest F1 (0.974), and all to ols ac hieve F1 > 0.7. The largest change from zero-shot to fine-tuned is for bip olar (F1: 0.120 → 0.831) and irrigator (F1: 0.089 → 0.800). T able 16: Per-tool classification metrics for YOLOv12-m on CholecT50. T o ol TP FP FN TN Accuracy Precision Recall F1 grasp er 11938 1945 592 5448 0.873 0.860 0.953 0.904 ho ok 10590 517 153 8663 0.966 0.953 0.986 0.969 bip olar 841 73 243 18766 0.984 0.920 0.776 0.842 irrigator 772 76 171 18904 0.988 0.910 0.819 0.862 clipp er 624 68 62 19169 0.993 0.902 0.910 0.906 scissors 275 36 201 19411 0.988 0.884 0.578 0.699 F or YOLOv12-m, scissors has the lo west recall and F1 among all tools (476 v alidation instances). YOLOv12-m ac hieves higher F1 than Gemma on irrigator (0.862 vs. 0.800), while Gemma ac hieves higher F1 on grasp er (0.913 vs. 0.904). T able 17: Per-tool ROC-A UC for YOLOv12-m on CholecT50 (using maxim um detection confidence p er class as the contin uous score). T o ol R OC-AUC ho ok 0.992 clipp er 0.967 grasp er 0.958 irrigator 0.955 bip olar 0.920 scissors 0.825 Macro A verage 0.936 J Robustness Chec k: CNN without Bounding Bo x Sup ervision Our comparison b et w een YOLOv12-m and VLM-based classifiers ev aluates tool presence only: b oth mo dels are scored on whether the predicted to ol set matches the ground truth set, ignoring spatial 32 lo calization. Ho wev er, the t wo approac hes differ in their training signal. YOLO is trained with b ounding b o x sup ervision, while VLMs receiv e only set-lev el lab els during fine-tuning. YOLO’s lo calization ob jective may confer an indirect adv an tage for presence detection by forcing the mo del to ground eac h prediction spatially , reducing hallucinated detections. Con versely , VLMs must learn to ol presence from a weak er sup ervisory signal. This asymmetry could mean that YOLO’s adv antage partly reflects the richer information con tent of b ounding b o x annotations rather than a fundamen tal architectural sup eriorit y for the presence detection task. T o test this, w e train a ResNet-50 (23.6M parameters; He et al. 2015 ) for m ulti-lab el tool classification using only set-level lab els—the same sup ervisory signal a v ailable to VLMs—with no b ounding b o x information. The mo del uses ImageNet-pretrained w eights, a drop out la yer ( p = 0 . 5 ) follo wed by a 31-class linear head, and is trained with binary cross-entrop y loss (lab el smo othing ϵ = 0 . 1 ). W e use differen tial learning rates (bac kb one: 10 − 4 , head: 10 − 3 ), A dam W optimizer (w eight decay 10 − 2 ), cosine annealing sc hedule, and aggressive data augmen tation (random resized crops, color jitter, random erasing, rotation). T raining uses 8 × L40S GPUs for 50 ep o c hs with a total batch size of 512. Figure 8 sho ws training dynamics. The mo del ac hiev es 39.6% exact matc h accuracy (95% CI: 38.9%–40.3%) on the v alidation set ( n = 20 , 016 ), with 52.6% Jaccard similarit y , 70.3% top-1 accuracy , and 0.673 micro F1. 0 10 20 30 40 50 Epoch 0.20 0.22 0.24 0.26 0.28 B CE L oss T raining L oss 0 10 20 30 40 50 Epoch 0 10 20 30 40 50 Exact Match A ccuracy (%) Exact Match A ccuracy (V al) Majority baseline (13.4%) Figure 8: T raining dynamics for ResNet-50 multi-label classification without b ounding b o x sup ervi- sion. Left: T raining loss (binary cross-en tropy with lab el smoothing). Right: Exact match accuracy on the v alidation set ev aluated at each ep och. The dashed line indicates the ma jority class baseline (13.4%). This result exceeds all zero-shot VLMs and matches the 3-epo c h LoRA rank sw eep at r = 1024 (39.6%, Section 3.4 ), but falls b elo w the b est fine-tuned VLM (Gemma 3 27B with LoRA classification head trained for 10 ep o c hs: 51.08%, Section 3.3 ), despite using roughly 1,000 × fewer parameters and receiving the same set-level sup ervision. The ResNet-50’s p erformance also falls b elo w YOLOv12-m (54.7%), suggesting that b ounding b o x sup ervision do es confer some adv an tage for presence detection. The fact that a 23.6M-parameter CNN trained with set-level lab els alone outp erforms all zero-shot VLMs—including mo dels with up to 235B parameters—underscores the difficult y of surgical to ol detection as a zero-shot task. 33 K Effect of Sampling T emp erature on Zero-Shot A ccuracy T o in vestigate whether sampling temp erature affects zero-shot to ol detection p erformance, w e sw eep the generation temp erature of Gemma 3 27B-it from 0 (greedy decoding) to 2.0 in incremen ts of 0.1, ev aluating exact match accuracy on the full v alidation set ( n = 20 , 016 ) at eac h setting. Figure 9 sho ws the results with 95% Wilson binomial confidence interv als. 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 1.6 1.8 2.0 T emperatur e 8.75 9.00 9.25 9.50 9.75 10.00 10.25 10.50 Exact match accuracy (%) Figure 9: Zero-shot exact match accuracy of Gemma 3 27B-it on the SDSC-EEA v alidation set ( n = 20 , 016 ) as a function of sampling temp erature. Shaded region: 95% Wilson binomial CI. A ccuracy is largely insensitive to temp erature in the 0–0.7 range ( ∼ 10% ), with a gradual decline at higher temperatures. At T ≥ 1 . 5 , output v alidation failures b egin to app ear (up to 38 at T = 2 . 0 ), indicating that high temp eratures degrade the mo del’s ability to pro duce v alid JSON. All CIs o verlap, confirming that temp erature has no statistically significan t effect on zero-shot p erformance. L P er-T o ol Metrics for Zero-Shot VLM Ev aluation The following tables present p er-tool classification metrics for eac h zero-shot vision-language mo del ev aluated on the full dataset ( n ≈ 67 , 634 frames). Output v alidation failures are treated as empt y predictions ( detected_tools: [] ) for the purp ose of computing p er-tool precision, recall, and F1. Only to ols with at least one true p ositiv e, false p ositiv e, or false negative are shown. T o ols are sorted by F1 score in descending order. 34 T able 18: Per-tool metrics for Qwen3-VL-235B-A22B-Thinking (235B) zero-shot ev aluation. P = precision, R = recall. T ool TP FP FN P R F1 Suction 28745 12845 10868 0.691 0.726 0.708 Cotton Patt y 2329 387 8498 0.858 0.215 0.344 Sonopet pineapple tip 367 356 1624 0.508 0.184 0.270 Grasper 2216 8314 5106 0.210 0.303 0.248 Drill 467 260 2930 0.642 0.137 0.226 Rongeur 593 4131 3577 0.126 0.142 0.133 Straight F orceps 292 3286 1403 0.082 0.172 0.111 Bipolar F orceps 110 848 2087 0.115 0.050 0.070 Rhoton Dissector 193 883 5520 0.179 0.034 0.057 Suction Coagulator 88 1003 2298 0.081 0.037 0.051 Floseal Gel 13 115 514 0.102 0.025 0.040 Surgicel 36 512 3551 0.066 0.010 0.017 Backbiting rongeur 11 256 1174 0.041 0.009 0.015 Scissor 30 225 3895 0.118 0.008 0.014 Floseal Applicator 2 115 214 0.017 0.009 0.012 Suction micro debrider 16 2728 575 0.006 0.027 0.010 Aspirating dissector 12 407 2369 0.029 0.005 0.009 Irrigation 2 175 384 0.011 0.005 0.007 Cottle Elev ator 3 158 852 0.019 0.004 0.006 Surgical Knife 7 17 2780 0.292 0.003 0.005 Through cutting forceps 1 108 796 0.009 0.001 0.002 Curette 1 4 5538 0.200 0.000 0.000 Collagen Matrix 0 206 280 0.000 0.000 0.000 Doppler 0 32 1482 0.000 0.000 0.000 Local Anesthesia Needle 0 22 139 0.000 0.000 0.000 Monopolar Electrocautery 0 18 190 0.000 0.000 0.000 Needle 0 117 31 0.000 0.000 0.000 Straight Curette 0 2 102 0.000 0.000 0.000 Tisseel Applicator 0 8 23 0.000 0.000 0.000 Tissue shav er 0 9 991 0.000 0.000 0.000 unknown 0 0 1195 0.000 0.000 0.000 35 T able 19: Per-tool metrics for Qwen3-VL-32B-Instruct (32B) zero-shot ev aluation. P = precision, R = recall. T ool TP FP FN P R F1 Suction 33716 12951 7507 0.722 0.818 0.767 Grasper 1441 2642 6187 0.353 0.189 0.246 Cotton Patt y 1089 146 10088 0.882 0.097 0.175 Rhoton Dissector 1324 9249 4489 0.125 0.228 0.162 Bipolar F orceps 395 2933 1861 0.119 0.175 0.141 Rongeur 519 2156 4577 0.194 0.102 0.134 Floseal Gel 85 1148 460 0.069 0.156 0.096 Curette 352 1985 5226 0.151 0.063 0.089 Surgical Knife 242 3498 2561 0.065 0.086 0.074 Backbiting rongeur 63 634 1125 0.090 0.053 0.067 Surgicel 143 1415 3516 0.092 0.039 0.055 Aspirating dissector 146 3783 2263 0.037 0.061 0.046 Sonopet pineapple tip 44 37 1948 0.543 0.022 0.042 Floseal Applicator 14 701 234 0.020 0.056 0.029 Scissor 61 268 3871 0.185 0.016 0.029 Suction Coagulator 94 4420 2511 0.021 0.036 0.026 Drill 38 190 3729 0.167 0.010 0.019 Straight F orceps 18 568 1761 0.031 0.010 0.015 Monopolar Electrocautery 5 1182 185 0.004 0.026 0.007 Through cutting forceps 2 32 796 0.059 0.003 0.005 Irrigation 1 126 394 0.008 0.003 0.004 Collagen Matrix 0 905 280 0.000 0.000 0.000 Cottle Elev ator 0 0 866 0.000 0.000 0.000 Doppler 0 0 1601 0.000 0.000 0.000 Local Anesthesia Needle 0 5 139 0.000 0.000 0.000 Needle 0 108 31 0.000 0.000 0.000 Straight Curette 0 326 118 0.000 0.000 0.000 Suction micro debrider 0 1368 592 0.000 0.000 0.000 Tisseel Applicator 0 210 23 0.000 0.000 0.000 Tissue shav er 0 24 993 0.000 0.000 0.000 unknown 0 0 1249 0.000 0.000 0.000 36 T able 20: P er-to ol metrics for Qwen3-VL-8B-Instruct (8B) zero-shot ev aluation. P = precision, R = recall. T ool TP FP FN P R F1 Suction 15594 4603 24890 0.772 0.385 0.514 Grasper 1587 3204 5735 0.331 0.217 0.262 Surgical Knife 228 886 2559 0.205 0.082 0.117 Cotton Patt y 649 35 10320 0.949 0.059 0.111 Rhoton Dissector 522 4399 5191 0.106 0.091 0.098 Aspirating dissector 842 19376 1565 0.042 0.350 0.074 Drill 116 115 3639 0.502 0.031 0.058 Rongeur 135 1045 4851 0.114 0.027 0.044 Floseal Applicator 7 263 232 0.026 0.029 0.028 Irrigation 14 660 372 0.021 0.036 0.026 Scissor 46 241 3879 0.160 0.012 0.022 Surgicel 34 335 3553 0.092 0.009 0.017 Floseal Gel 5 68 537 0.068 0.009 0.016 Suction Coagulator 22 1047 2566 0.021 0.009 0.012 Bipolar F orceps 10 171 2187 0.055 0.005 0.008 Tissue shav er 5 340 986 0.014 0.005 0.007 Curette 21 132 5518 0.137 0.004 0.007 Monopolar Electrocautery 1 361 189 0.003 0.005 0.004 Straight F orceps 3 12 1772 0.200 0.002 0.003 Backbiting rongeur 1 1 1184 0.500 0.001 0.002 Suction micro debrider 5 7259 586 0.001 0.008 0.001 Collagen Matrix 0 54 280 0.000 0.000 0.000 Cottle Elev ator 0 23 855 0.000 0.000 0.000 Doppler 0 0 1592 0.000 0.000 0.000 Local Anesthesia Needle 0 7 139 0.000 0.000 0.000 Needle 0 21 31 0.000 0.000 0.000 Sonopet pineapple tip 0 20 1991 0.000 0.000 0.000 Straight Curette 0 34 118 0.000 0.000 0.000 Through cutting forceps 0 3 797 0.000 0.000 0.000 Tisseel Applicator 0 6 23 0.000 0.000 0.000 unknown 0 2 1195 0.000 0.000 0.000 37 T able 21: P er-to ol metrics for Qwen3-VL-4B-Instruct (4B) zero-shot ev aluation. P = precision, R = recall. T ool TP FP FN P R F1 Suction 26189 10548 14295 0.713 0.647 0.678 Drill 1126 402 2629 0.737 0.300 0.426 Grasper 4922 24241 2400 0.169 0.672 0.270 Cotton Patt y 1297 120 9672 0.915 0.118 0.209 Scissor 2016 18097 1909 0.100 0.514 0.168 Surgical Knife 251 3478 2536 0.067 0.090 0.077 Curette 290 3419 5249 0.078 0.052 0.063 Aspirating dissector 90 566 2317 0.137 0.037 0.059 Suction Coagulator 271 9345 2317 0.028 0.105 0.044 Irrigation 7 368 379 0.019 0.018 0.018 Local Anesthesia Needle 1 52 138 0.019 0.007 0.010 Through cutting forceps 5 167 792 0.029 0.006 0.010 Straight Curette 1 127 117 0.008 0.008 0.008 Surgicel 14 172 3573 0.075 0.004 0.007 Floseal Gel 2 57 540 0.034 0.004 0.007 Monopolar Electrocautery 1 110 189 0.009 0.005 0.007 Floseal Applicator 1 68 238 0.014 0.004 0.006 unknown 5 355 1190 0.014 0.004 0.006 Backbiting rongeur 2 30 1183 0.062 0.002 0.003 Straight F orceps 3 132 1772 0.022 0.002 0.003 Rongeur 8 230 4978 0.034 0.002 0.003 Rhoton Dissector 3 24 5710 0.111 0.001 0.001 Sonopet pineapple tip 1 23 1990 0.042 0.001 0.001 Bipolar F orceps 0 25 2197 0.000 0.000 0.000 Collagen Matrix 0 172 280 0.000 0.000 0.000 Cottle Elev ator 0 84 855 0.000 0.000 0.000 Doppler 0 32 1592 0.000 0.000 0.000 Needle 0 59 31 0.000 0.000 0.000 Suction micro debrider 0 214 591 0.000 0.000 0.000 Tisseel Applicator 0 71 23 0.000 0.000 0.000 Tissue shav er 0 224 991 0.000 0.000 0.000 38 T able 22: P er-to ol metrics for Qwen3-VL-2B-Instruct (2B) zero-shot ev aluation. P = precision, R = recall. T ool TP FP FN P R F1 Suction 24482 14568 16002 0.627 0.605 0.616 Grasper 4424 30813 2898 0.126 0.604 0.208 Drill 581 2309 3174 0.201 0.155 0.175 Rongeur 1472 19535 3514 0.070 0.295 0.113 Scissor 1236 18066 2689 0.064 0.315 0.106 Curette 710 9347 4829 0.071 0.128 0.091 Surgical Knife 2110 43265 677 0.047 0.757 0.088 Cotton Patt y 603 2503 10366 0.194 0.055 0.086 Rhoton Dissector 481 5552 5232 0.080 0.084 0.082 Suction Coagulator 732 18203 1856 0.039 0.283 0.068 Straight F orceps 476 16156 1299 0.029 0.268 0.052 Bipolar F orceps 100 2770 2097 0.035 0.046 0.039 Aspirating dissector 79 1986 2328 0.038 0.033 0.035 Tissue shav er 269 15834 722 0.017 0.271 0.031 Doppler 47 1623 1545 0.028 0.030 0.029 Cottle Elev ator 240 19232 615 0.012 0.281 0.024 Through cutting forceps 156 13162 641 0.012 0.196 0.022 unknown 16 690 1179 0.023 0.013 0.017 Sonopet pineapple tip 19 351 1972 0.051 0.010 0.016 Backbiting rongeur 19 1345 1166 0.014 0.016 0.015 Floseal Gel 58 7239 484 0.008 0.107 0.015 Suction micro debrider 214 29996 377 0.007 0.362 0.014 Surgicel 28 464 3559 0.057 0.008 0.014 Irrigation 35 5748 351 0.006 0.091 0.011 Monopolar Electrocautery 29 8210 161 0.004 0.153 0.007 Collagen Matrix 5 1746 275 0.003 0.018 0.005 Floseal Applicator 18 7161 221 0.003 0.075 0.005 Local Anesthesia Needle 14 6382 125 0.002 0.101 0.004 Straight Curette 8 5957 110 0.001 0.068 0.003 Needle 2 1901 29 0.001 0.065 0.002 Tisseel Applicator 1 14970 22 0.000 0.043 0.000 39 T able 23: P er-to ol metrics for Qwen2.5-VL-72B-Instruct (72B) zero-shot ev aluation. P = precision, R = recall. T ool TP FP FN P R F1 Suction 10304 3016 30180 0.774 0.255 0.383 Sonopet pineapple tip 174 272 1817 0.390 0.087 0.143 Grasper 472 1330 6850 0.262 0.064 0.103 Cotton Patt y 391 285 10578 0.578 0.036 0.067 Rongeur 156 1070 4830 0.127 0.031 0.050 Scissor 107 585 3818 0.155 0.027 0.046 Curette 118 902 5421 0.116 0.021 0.036 unknown 92 3878 1103 0.023 0.077 0.036 Surgical Knife 61 622 2726 0.089 0.022 0.035 Surgicel 68 529 3519 0.114 0.019 0.033 Rhoton Dissector 106 1226 5607 0.080 0.019 0.030 Straight F orceps 36 1250 1739 0.028 0.020 0.024 Backbiting rongeur 14 275 1171 0.048 0.012 0.019 Drill 36 93 3719 0.279 0.010 0.019 Bipolar F orceps 20 329 2177 0.057 0.009 0.016 Irrigation 4 406 382 0.010 0.010 0.010 Aspirating dissector 8 419 2399 0.019 0.003 0.006 Cottle Elev ator 2 254 853 0.008 0.002 0.004 Floseal Gel 1 63 541 0.016 0.002 0.003 Through cutting forceps 1 66 796 0.015 0.001 0.002 Collagen Matrix 1 658 279 0.002 0.004 0.002 Monopolar Electrocautery 1 1189 189 0.001 0.005 0.001 Suction Coagulator 1 94 2587 0.011 0.000 0.001 Doppler 0 17 1592 0.000 0.000 0.000 Floseal Applicator 0 142 239 0.000 0.000 0.000 Local Anesthesia Needle 0 7 139 0.000 0.000 0.000 Needle 0 6 31 0.000 0.000 0.000 Straight Curette 0 229 118 0.000 0.000 0.000 Suction micro debrider 0 64 591 0.000 0.000 0.000 Tisseel Applicator 0 38 23 0.000 0.000 0.000 Tissue shav er 0 139 991 0.000 0.000 0.000 40 T able 24: P er-to ol metrics for Qwen2.5-VL-32B-Instruct (32B) zero-shot ev aluation. P = precision, R = recall. T ool TP FP FN P R F1 Suction 10990 4861 29494 0.693 0.271 0.390 Cotton Patt y 929 518 10040 0.642 0.085 0.150 Scissor 269 2041 3656 0.116 0.069 0.086 Bipolar F orceps 236 3079 1961 0.071 0.107 0.086 Sonopet pineapple tip 77 50 1914 0.606 0.039 0.073 Curette 352 3950 5187 0.082 0.064 0.072 Surgical Knife 157 1770 2630 0.081 0.056 0.067 Rhoton Dissector 260 2364 5453 0.099 0.046 0.062 Rongeur 208 1972 4778 0.095 0.042 0.058 Grasper 230 948 7092 0.195 0.031 0.054 Drill 56 102 3699 0.354 0.015 0.029 Straight F orceps 29 864 1746 0.032 0.016 0.022 Through cutting forceps 10 307 787 0.032 0.013 0.018 Aspirating dissector 24 1249 2383 0.019 0.010 0.013 Floseal Gel 4 76 538 0.050 0.007 0.013 Irrigation 24 3707 362 0.006 0.062 0.012 Backbiting rongeur 6 115 1179 0.050 0.005 0.009 Floseal Applicator 2 230 237 0.009 0.008 0.008 Monopolar Electrocautery 9 3185 181 0.003 0.047 0.005 Local Anesthesia Needle 1 294 138 0.003 0.007 0.005 Suction Coagulator 5 223 2583 0.022 0.002 0.004 Tissue shav er 2 257 989 0.008 0.002 0.003 unknown 2 92 1193 0.021 0.002 0.003 Doppler 1 73 1591 0.014 0.001 0.001 Surgicel 2 22 3585 0.083 0.001 0.001 Collagen Matrix 0 166 280 0.000 0.000 0.000 Cottle Elev ator 0 89 855 0.000 0.000 0.000 Needle 0 307 31 0.000 0.000 0.000 Straight Curette 0 607 118 0.000 0.000 0.000 Suction micro debrider 0 55 591 0.000 0.000 0.000 Tisseel Applicator 0 55 23 0.000 0.000 0.000 41 T able 25: P er-to ol metrics for Qw en2.5-VL-7B-Instruct (7B) zero-shot ev aluation. P = precision, R = recall. T ool TP FP FN P R F1 Surgical Knife 799 11805 1988 0.063 0.287 0.104 Grasper 480 1506 6842 0.242 0.066 0.103 Suction 2207 1031 38277 0.682 0.055 0.101 Curette 399 2817 5140 0.124 0.072 0.091 Scissor 185 1476 3740 0.111 0.047 0.066 Rhoton Dissector 192 1678 5521 0.103 0.034 0.051 Suction Coagulator 113 1792 2475 0.059 0.044 0.050 Backbiting rongeur 43 632 1142 0.064 0.036 0.046 Rongeur 112 890 4874 0.112 0.022 0.037 Bipolar F orceps 59 998 2138 0.056 0.027 0.036 Drill 56 334 3699 0.144 0.015 0.027 Aspirating dissector 55 2346 2352 0.023 0.023 0.023 unknown 19 462 1176 0.040 0.016 0.023 Straight F orceps 26 789 1749 0.032 0.015 0.020 Doppler 15 399 1577 0.036 0.009 0.015 Tissue shav er 11 1071 980 0.010 0.011 0.011 Cottle Elev ator 10 1200 845 0.008 0.012 0.010 Cotton Patt y 40 60 10929 0.400 0.004 0.007 Sonopet pineapple tip 8 251 1983 0.031 0.004 0.007 Local Anesthesia Needle 1 156 138 0.006 0.007 0.007 Floseal Applicator 3 652 236 0.005 0.013 0.007 Floseal Gel 2 110 540 0.018 0.004 0.006 Through cutting forceps 3 220 794 0.013 0.004 0.006 Monopolar Electrocautery 4 1302 186 0.003 0.021 0.005 Surgicel 9 211 3578 0.041 0.003 0.005 Irrigation 1 271 385 0.004 0.003 0.003 Collagen Matrix 0 110 280 0.000 0.000 0.000 Needle 0 743 31 0.000 0.000 0.000 Straight Curette 0 762 118 0.000 0.000 0.000 Suction micro debrider 0 109 591 0.000 0.000 0.000 Tisseel Applicator 0 99 23 0.000 0.000 0.000 42 T able 26: P er-to ol metrics for Qw en2.5-VL-3B-Instruct (3B) zero-shot ev aluation. P = precision, R = recall. T ool TP FP FN P R F1 Drill 573 1106 3182 0.341 0.153 0.211 Surgical Knife 434 5197 2353 0.077 0.156 0.103 Curette 498 4650 5041 0.097 0.090 0.093 Suction 1650 660 38834 0.714 0.041 0.077 Rongeur 276 2926 4710 0.086 0.055 0.067 Straight F orceps 175 4054 1600 0.041 0.099 0.058 Grasper 157 783 7165 0.167 0.021 0.038 Bipolar F orceps 55 686 2142 0.074 0.025 0.037 Local Anesthesia Needle 3 86 136 0.034 0.022 0.026 Through cutting forceps 29 2458 768 0.012 0.036 0.018 Rhoton Dissector 51 421 5662 0.108 0.009 0.016 Scissor 30 239 3895 0.112 0.008 0.014 Aspirating dissector 23 877 2384 0.026 0.010 0.014 Cotton Patt y 62 139 10907 0.308 0.006 0.011 Collagen Matrix 3 308 277 0.010 0.011 0.010 Surgicel 19 214 3568 0.082 0.005 0.010 Irrigation 4 466 382 0.009 0.010 0.009 Floseal Gel 3 179 539 0.016 0.006 0.008 Sonopet pineapple tip 6 167 1985 0.035 0.003 0.006 Monopolar Electrocautery 3 1070 187 0.003 0.016 0.005 Backbiting rongeur 4 544 1181 0.007 0.003 0.005 Suction Coagulator 6 162 2582 0.036 0.002 0.004 Tissue shav er 3 429 988 0.007 0.003 0.004 Straight Curette 7 3403 111 0.002 0.059 0.004 Cottle Elev ator 2 216 853 0.009 0.002 0.004 Floseal Applicator 1 541 238 0.002 0.004 0.003 Doppler 2 236 1590 0.008 0.001 0.002 Suction micro debrider 1 498 590 0.002 0.002 0.002 Needle 0 42 31 0.000 0.000 0.000 Tisseel Applicator 0 22 23 0.000 0.000 0.000 unknown 0 67 1195 0.000 0.000 0.000 43 T able 27: Per-tool metrics for Qwen2-VL-72B-Instruct (72B) zero-shot ev aluation. P = precision, R = recall. T ool TP FP FN P R F1 Suction 9085 4437 31399 0.672 0.224 0.336 Drill 458 907 3297 0.336 0.122 0.179 Grasper 1069 4589 6253 0.189 0.146 0.165 Curette 401 3817 5138 0.095 0.072 0.082 Bipolar F orceps 191 2473 2006 0.072 0.087 0.079 Scissor 219 1650 3706 0.117 0.056 0.076 Rhoton Dissector 327 3356 5386 0.089 0.057 0.070 Sonopet pineapple tip 107 1039 1884 0.093 0.054 0.068 Rongeur 208 2034 4778 0.093 0.042 0.058 Surgical Knife 91 1493 2696 0.057 0.033 0.042 Straight F orceps 64 1818 1711 0.034 0.036 0.035 Backbiting rongeur 52 2098 1133 0.024 0.044 0.031 Surgicel 59 334 3528 0.150 0.016 0.030 unknown 35 1182 1160 0.029 0.029 0.029 Aspirating dissector 75 2785 2332 0.026 0.031 0.028 Cotton Patt y 146 70 10823 0.676 0.013 0.026 Suction Coagulator 52 1361 2536 0.037 0.020 0.026 Floseal Gel 10 509 532 0.019 0.018 0.019 Irrigation 19 2964 367 0.006 0.049 0.011 Local Anesthesia Needle 1 74 138 0.013 0.007 0.009 Doppler 6 135 1586 0.043 0.004 0.007 Tissue shav er 5 719 986 0.007 0.005 0.006 Cottle Elev ator 3 281 852 0.011 0.004 0.005 Suction micro debrider 7 2096 584 0.003 0.012 0.005 Through cutting forceps 3 369 794 0.008 0.004 0.005 Collagen Matrix 3 979 277 0.003 0.011 0.005 Monopolar Electrocautery 7 2923 183 0.002 0.037 0.004 Straight Curette 3 1897 115 0.002 0.025 0.003 Floseal Applicator 1 436 238 0.002 0.004 0.003 Needle 0 9 31 0.000 0.000 0.000 Tisseel Applicator 0 83 23 0.000 0.000 0.000 44 T able 28: P er-to ol metrics for Qwen2-VL-7B-Instruct (7B) zero-shot ev aluation. P = precision, R = recall. T ool TP FP FN P R F1 Suction 14191 7274 26293 0.661 0.351 0.458 Drill 1691 5743 2064 0.227 0.450 0.302 Curette 948 8601 4591 0.099 0.171 0.126 Grasper 680 4174 6642 0.140 0.093 0.112 Scissor 537 5600 3388 0.088 0.137 0.107 Surgical Knife 449 5921 2338 0.070 0.161 0.098 Suction Coagulator 338 7800 2250 0.042 0.131 0.063 Rongeur 219 2482 4767 0.081 0.044 0.057 Straight F orceps 226 5955 1549 0.037 0.127 0.057 Cotton Patt y 276 513 10693 0.350 0.025 0.047 Bipolar F orceps 48 1001 2149 0.046 0.022 0.030 Aspirating dissector 61 1912 2346 0.031 0.025 0.028 Doppler 39 1172 1553 0.032 0.024 0.028 Tissue shav er 38 2435 953 0.015 0.038 0.022 Backbiting rongeur 21 876 1164 0.023 0.018 0.020 Rhoton Dissector 61 544 5652 0.101 0.011 0.019 Through cutting forceps 29 2265 768 0.013 0.036 0.019 Cottle Elev ator 55 5065 800 0.011 0.064 0.018 Irrigation 93 12128 293 0.008 0.241 0.015 Floseal Gel 10 870 532 0.011 0.018 0.014 Surgicel 22 290 3565 0.071 0.006 0.011 Sonopet pineapple tip 12 288 1979 0.040 0.006 0.010 Suction micro debrider 19 3950 572 0.005 0.032 0.008 Monopolar Electrocautery 18 4194 172 0.004 0.095 0.008 Floseal Applicator 7 1680 232 0.004 0.029 0.007 Local Anesthesia Needle 4 1353 135 0.003 0.029 0.005 Straight Curette 6 3032 112 0.002 0.051 0.004 Collagen Matrix 0 91 280 0.000 0.000 0.000 Needle 0 837 31 0.000 0.000 0.000 Tisseel Applicator 0 700 23 0.000 0.000 0.000 unknown 0 134 1195 0.000 0.000 0.000 45 T able 29: P er-to ol metrics for Qwen2-VL-2B-Instruct (2B) zero-shot ev aluation. P = precision, R = recall. T ool TP FP FN P R F1 Curette 1110 11909 4429 0.085 0.200 0.120 Grasper 748 5279 6574 0.124 0.102 0.112 Rhoton Dissector 593 6046 5120 0.089 0.104 0.096 Drill 238 1733 3517 0.121 0.063 0.083 Aspirating dissector 283 5676 2124 0.047 0.118 0.068 Surgical Knife 343 7496 2444 0.044 0.123 0.065 Surgicel 139 2026 3448 0.064 0.039 0.048 Bipolar F orceps 114 2978 2083 0.037 0.052 0.043 Doppler 133 4515 1459 0.029 0.084 0.043 Rongeur 126 1728 4860 0.068 0.025 0.037 Suction 633 414 39851 0.605 0.016 0.030 Backbiting rongeur 28 1005 1157 0.027 0.024 0.025 Scissor 49 715 3876 0.064 0.012 0.021 Tissue shav er 25 1485 966 0.017 0.025 0.020 Cottle Elev ator 28 1921 827 0.014 0.033 0.020 Straight F orceps 21 519 1754 0.039 0.012 0.018 Sonopet pineapple tip 22 468 1969 0.045 0.011 0.018 Suction Coagulator 27 507 2561 0.051 0.010 0.017 Floseal Gel 25 2934 517 0.008 0.046 0.014 Collagen Matrix 31 4494 249 0.007 0.111 0.013 Irrigation 14 1991 372 0.007 0.036 0.012 Through cutting forceps 12 1274 785 0.009 0.015 0.012 Suction micro debrider 8 878 583 0.009 0.014 0.011 Floseal Applicator 20 4768 219 0.004 0.084 0.008 Straight Curette 5 1170 113 0.004 0.042 0.008 Monopolar Electrocautery 5 1324 185 0.004 0.026 0.007 Cotton Patt y 16 71 10953 0.184 0.001 0.003 Tisseel Applicator 1 732 22 0.001 0.043 0.003 Local Anesthesia Needle 1 790 138 0.001 0.007 0.002 Needle 0 371 31 0.000 0.000 0.000 unknown 0 33 1195 0.000 0.000 0.000 46 T able 30: Per-tool metrics for Gemma 3 27B-it (27B) zero-shot ev aluation. P = precision, R = recall. T ool TP FP FN P R F1 Suction 39555 26381 929 0.600 0.977 0.743 Rongeur 1424 14204 3562 0.091 0.286 0.138 Drill 154 32 3601 0.828 0.041 0.078 Bipolar F orceps 277 5299 1920 0.050 0.126 0.071 Grasper 329 1596 6993 0.171 0.045 0.071 Cotton Patt y 232 69 10737 0.771 0.021 0.041 Through cutting forceps 216 14551 581 0.015 0.271 0.028 Straight F orceps 25 666 1750 0.036 0.014 0.020 Scissor 42 177 3883 0.192 0.011 0.020 Surgical Knife 24 182 2763 0.117 0.009 0.016 Sonopet pineapple tip 21 816 1970 0.025 0.011 0.015 Surgicel 25 169 3562 0.129 0.007 0.013 Curette 35 129 5504 0.213 0.006 0.012 Irrigation 49 8101 337 0.006 0.127 0.011 Monopolar Electrocautery 23 5683 167 0.004 0.121 0.008 Suction micro debrider 3 461 588 0.006 0.005 0.006 Cottle Elev ator 1 60 854 0.016 0.001 0.002 Straight Curette 1 962 117 0.001 0.008 0.002 Rhoton Dissector 5 27 5708 0.156 0.001 0.002 Aspirating dissector 0 10 2407 0.000 0.000 0.000 Backbiting rongeur 0 0 1185 0.000 0.000 0.000 Collagen Matrix 0 538 280 0.000 0.000 0.000 Doppler 0 0 1592 0.000 0.000 0.000 Floseal Applicator 0 4 239 0.000 0.000 0.000 Floseal Gel 0 12 542 0.000 0.000 0.000 Local Anesthesia Needle 0 5 139 0.000 0.000 0.000 Needle 0 257 31 0.000 0.000 0.000 Suction Coagulator 0 54 2588 0.000 0.000 0.000 Tisseel Applicator 0 0 23 0.000 0.000 0.000 Tissue shav er 0 47 991 0.000 0.000 0.000 unknown 0 2 1195 0.000 0.000 0.000 47 T able 31: Per-tool metrics for Gemma 3 12B-it (12B) zero-shot ev aluation. P = precision, R = recall. T ool TP FP FN P R F1 Suction 26679 15734 13805 0.629 0.659 0.644 Grasper 4431 23958 2891 0.156 0.605 0.248 Suction Coagulator 1180 15044 1408 0.073 0.456 0.125 Rhoton Dissector 825 6977 4888 0.106 0.144 0.122 Scissor 327 2297 3598 0.125 0.083 0.100 Sonopet pineapple tip 101 611 1890 0.142 0.051 0.075 Local Anesthesia Needle 9 236 130 0.037 0.065 0.047 Drill 85 27 3670 0.759 0.023 0.044 Rongeur 158 2530 4828 0.059 0.032 0.041 Bipolar F orceps 65 1562 2132 0.040 0.030 0.034 Cotton Patt y 181 250 10788 0.420 0.017 0.032 Surgical Knife 71 2207 2716 0.031 0.025 0.028 Surgicel 38 119 3549 0.242 0.011 0.020 Monopolar Electrocautery 5 311 185 0.016 0.026 0.020 Irrigation 149 24718 237 0.006 0.386 0.012 Straight F orceps 10 552 1765 0.018 0.006 0.009 Suction micro debrider 3 366 588 0.008 0.005 0.006 Through cutting forceps 2 47 795 0.041 0.003 0.005 Tissue shav er 3 282 988 0.011 0.003 0.005 Aspirating dissector 7 667 2400 0.010 0.003 0.005 Curette 9 32 5530 0.220 0.002 0.003 Backbiting rongeur 0 0 1185 0.000 0.000 0.000 Collagen Matrix 0 954 280 0.000 0.000 0.000 Cottle Elev ator 0 76 855 0.000 0.000 0.000 Doppler 0 26 1592 0.000 0.000 0.000 Floseal Applicator 0 133 239 0.000 0.000 0.000 Floseal Gel 0 43 542 0.000 0.000 0.000 Needle 0 582 31 0.000 0.000 0.000 Straight Curette 0 1 118 0.000 0.000 0.000 Tisseel Applicator 0 0 23 0.000 0.000 0.000 unknown 0 3 1195 0.000 0.000 0.000 48 T able 32: Per-tool metrics for Gemma 3 4B-it (4B) zero-shot ev aluation. P = precision, R = recall. T ool TP FP FN P R F1 Suction 39017 26280 1467 0.598 0.964 0.738 Grasper 3699 24871 3623 0.129 0.505 0.206 Rongeur 1714 23095 3272 0.069 0.344 0.115 Surgical Knife 2314 43203 473 0.051 0.830 0.096 Bipolar F orceps 597 13902 1600 0.041 0.272 0.072 Suction Coagulator 136 1328 2452 0.093 0.053 0.067 Straight F orceps 1299 46446 476 0.027 0.732 0.052 Surgicel 96 489 3491 0.164 0.027 0.046 Monopolar Electrocautery 5 131 185 0.037 0.026 0.031 Curette 102 1512 5437 0.063 0.018 0.029 Cottle Elev ator 200 15114 655 0.013 0.234 0.025 Aspirating dissector 90 5718 2317 0.015 0.037 0.022 Local Anesthesia Needle 1 5 138 0.167 0.007 0.014 Irrigation 100 15849 286 0.006 0.259 0.012 Drill 21 7 3734 0.750 0.006 0.011 Rhoton Dissector 32 415 5681 0.072 0.006 0.010 Scissor 14 123 3911 0.102 0.004 0.007 Doppler 6 448 1586 0.013 0.004 0.006 Cotton Patt y 27 8 10942 0.771 0.002 0.005 Straight Curette 4 2463 114 0.002 0.034 0.003 Backbiting rongeur 1 28 1184 0.034 0.001 0.002 Needle 7 9710 24 0.001 0.226 0.001 Collagen Matrix 0 3 280 0.000 0.000 0.000 Floseal Applicator 0 0 239 0.000 0.000 0.000 Floseal Gel 0 0 542 0.000 0.000 0.000 Sonopet pineapple tip 0 0 1991 0.000 0.000 0.000 Suction micro debrider 0 38 591 0.000 0.000 0.000 Through cutting forceps 0 32 797 0.000 0.000 0.000 Tisseel Applicator 0 0 23 0.000 0.000 0.000 Tissue shav er 0 108 991 0.000 0.000 0.000 unknown 0 0 1195 0.000 0.000 0.000 49 T able 33: Per-tool metrics for MedGemma 3 27B-it (27B) zero-shot ev aluation. P = precision, R = recall. T ool TP FP FN P R F1 Suction 38413 24419 1970 0.611 0.951 0.744 Rongeur 2042 13802 2478 0.129 0.452 0.201 Surgical Knife 851 9387 1936 0.083 0.305 0.131 Curette 286 2206 5253 0.115 0.052 0.071 Sonopet pineapple tip 72 110 1919 0.396 0.036 0.066 Cotton Patt y 344 29 10625 0.922 0.031 0.061 Grasper 190 295 7132 0.392 0.026 0.049 Suction Coagulator 218 12464 2370 0.017 0.084 0.029 Straight F orceps 36 870 1739 0.040 0.020 0.027 unknown 147 10757 1048 0.013 0.123 0.024 Monopolar Electrocautery 13 1375 177 0.009 0.068 0.016 Irrigation 52 9955 334 0.005 0.135 0.010 Suction micro debrider 33 6177 558 0.005 0.056 0.010 Scissor 15 44 3910 0.254 0.004 0.008 Straight Curette 4 3246 114 0.001 0.034 0.002 Tissue shav er 1 30 990 0.032 0.001 0.002 Doppler 1 14 1591 0.067 0.001 0.001 Bipolar F orceps 1 23 2196 0.042 0.000 0.001 Aspirating dissector 1 26 2406 0.037 0.000 0.001 Rhoton Dissector 2 19 5711 0.095 0.000 0.001 Surgicel 1 28 3586 0.034 0.000 0.001 Backbiting rongeur 0 10 1185 0.000 0.000 0.000 Collagen Matrix 0 636 280 0.000 0.000 0.000 Cottle Elev ator 0 12 855 0.000 0.000 0.000 Drill 0 16 3755 0.000 0.000 0.000 Floseal Applicator 0 15 239 0.000 0.000 0.000 Floseal Gel 0 15 542 0.000 0.000 0.000 Local Anesthesia Needle 0 16 139 0.000 0.000 0.000 Needle 0 17 31 0.000 0.000 0.000 Through cutting forceps 0 44 797 0.000 0.000 0.000 Tisseel Applicator 0 15 23 0.000 0.000 0.000 50 T able 34: P er-to ol metrics for Llama-3.2-90B-Vision (90B) zero-shot ev aluation. P = precision, R = recall. T ool TP FP FN P R F1 Suction 24755 6689 15626 0.787 0.613 0.689 Drill 1264 1005 2489 0.557 0.337 0.420 Cotton Patt y 2569 2671 8400 0.490 0.234 0.317 Rongeur 1062 5120 3458 0.172 0.235 0.198 Curette 657 2324 4882 0.220 0.119 0.154 Grasper 669 1046 6653 0.390 0.091 0.148 Rhoton Dissector 705 7066 5008 0.091 0.123 0.105 Surgical Knife 167 1094 2620 0.132 0.060 0.083 Bipolar F orceps 153 2900 2044 0.050 0.070 0.058 Surgicel 97 1064 3490 0.084 0.027 0.041 Backbiting rongeur 53 1699 1132 0.030 0.045 0.036 Floseal Gel 24 927 517 0.025 0.044 0.032 Doppler 27 225 1565 0.107 0.017 0.029 Scissor 64 396 3861 0.139 0.016 0.029 Irrigation 12 588 374 0.020 0.031 0.024 Monopolar Electrocautery 67 5254 123 0.013 0.353 0.024 Through cutting forceps 18 846 779 0.021 0.023 0.022 Straight F orceps 27 1143 1748 0.023 0.015 0.018 Floseal Applicator 6 932 233 0.006 0.025 0.010 Sonopet pineapple tip 10 207 1981 0.046 0.005 0.009 Suction Coagulator 39 6827 2550 0.006 0.015 0.008 Collagen Matrix 3 553 277 0.005 0.011 0.007 unknown 45 11803 1150 0.004 0.038 0.007 Cottle Elev ator 2 225 853 0.009 0.002 0.004 Suction micro debrider 7 5387 584 0.001 0.012 0.002 Tissue shav er 1 594 990 0.002 0.001 0.001 Aspirating dissector 0 478 2407 0.000 0.000 0.000 Local Anesthesia Needle 0 295 138 0.000 0.000 0.000 Needle 0 291 31 0.000 0.000 0.000 Straight Curette 0 467 118 0.000 0.000 0.000 Tisseel Applicator 0 789 23 0.000 0.000 0.000 51 T able 35: P er-to ol metrics for Llama-3.2-11B-Vision (11B) zero-shot ev aluation. P = precision, R = recall. T ool TP FP FN P R F1 Suction 505 392 39979 0.563 0.012 0.024 Tissue shav er 10 467 981 0.021 0.010 0.014 Aspirating dissector 13 364 2394 0.034 0.005 0.009 Curette 23 190 5516 0.108 0.004 0.008 Bipolar F orceps 8 132 2189 0.057 0.004 0.007 Rongeur 15 163 4971 0.084 0.003 0.006 Suction micro debrider 2 168 589 0.012 0.003 0.005 Surgical Knife 8 309 2779 0.025 0.003 0.005 Scissor 8 87 3917 0.084 0.002 0.004 Grasper 13 115 7309 0.102 0.002 0.003 Drill 5 9 3750 0.357 0.001 0.003 Rhoton Dissector 5 19 5708 0.208 0.001 0.002 Suction Coagulator 1 53 2587 0.019 0.000 0.001 Cotton Patt y 1 4 10968 0.200 0.000 0.000 Backbiting rongeur 0 20 1185 0.000 0.000 0.000 Collagen Matrix 0 3 280 0.000 0.000 0.000 Cottle Elev ator 0 16 855 0.000 0.000 0.000 Doppler 0 19 1592 0.000 0.000 0.000 Floseal Applicator 0 2 239 0.000 0.000 0.000 Floseal Gel 0 0 542 0.000 0.000 0.000 Irrigation 0 99 386 0.000 0.000 0.000 Local Anesthesia Needle 0 26 139 0.000 0.000 0.000 Monopolar Electrocautery 0 38 190 0.000 0.000 0.000 Needle 0 11 31 0.000 0.000 0.000 Sonopet pineapple tip 0 0 1991 0.000 0.000 0.000 Straight Curette 0 13 118 0.000 0.000 0.000 Straight F orceps 0 17 1775 0.000 0.000 0.000 Surgicel 0 85 3587 0.000 0.000 0.000 Through cutting forceps 0 24 797 0.000 0.000 0.000 Tisseel Applicator 0 78 23 0.000 0.000 0.000 unknown 0 2 1195 0.000 0.000 0.000 52 T able 36: Per-tool metrics for LLaV A-1.5-13B (13B) zero-shot ev aluation. P = precision, R = recall. T ool TP FP FN P R F1 Suction 22423 14880 17960 0.601 0.555 0.577 Cotton Patt y 6339 27699 4630 0.186 0.578 0.282 Grasper 6850 54394 472 0.112 0.936 0.200 Rhoton Dissector 5405 58418 308 0.085 0.946 0.155 Curette 5429 59769 110 0.083 0.980 0.153 Rongeur 3798 53913 722 0.066 0.840 0.122 Scissor 3876 61604 49 0.059 0.988 0.112 Surgicel 2338 39493 1249 0.056 0.652 0.103 Drill 1661 27772 2094 0.056 0.442 0.100 Suction Coagulator 1309 29208 1279 0.043 0.506 0.079 Surgical Knife 2406 56776 381 0.041 0.863 0.078 Aspirating dissector 2353 62594 54 0.036 0.978 0.070 Bipolar F orceps 2150 62184 47 0.033 0.979 0.065 Sonopet pineapple tip 905 28587 1086 0.031 0.455 0.057 Backbiting rongeur 110 2896 1075 0.037 0.093 0.052 Straight F orceps 821 28844 954 0.028 0.463 0.052 Doppler 1010 49108 582 0.020 0.634 0.039 unknown 163 7614 1032 0.021 0.136 0.036 Tissue shav er 924 61184 67 0.015 0.932 0.029 Cottle Elev ator 355 29201 500 0.012 0.415 0.023 Floseal Gel 261 28761 281 0.009 0.482 0.018 Suction micro debrider 252 29226 339 0.009 0.426 0.017 Irrigation 374 63968 12 0.006 0.969 0.012 Floseal Applicator 91 28909 148 0.003 0.381 0.006 Monopolar Electrocautery 185 64062 5 0.003 0.974 0.006 Collagen Matrix 73 25090 207 0.003 0.261 0.006 Local Anesthesia Needle 123 49177 16 0.002 0.885 0.005 Straight Curette 53 29563 65 0.002 0.449 0.004 Needle 18 32276 13 0.001 0.581 0.001 Tisseel Applicator 17 46181 6 0.000 0.739 0.001 Through cutting forceps 0 137 797 0.000 0.000 0.000 M Qw en3-VL-235B-A22B-Thinking’s thinking Qw en3-VL-235B-A22B-Thinking Resp onse So, let’s look at the surgical video frame. There are two tools visible. Let’s check the list. The tools here seem to be a suction and maybe a grasper or something else. Wait, the left tool might be suction, and the right one... Let’s see. The valid names: Suction is one. Then, the other tool--- maybe Grasper? Wait, in the image, the two instruments. Let’s check each. First, Suction: yes, one of the tools is likely suction. Then, the other tool--- Grasper? Let’s confirm. The list has Grasper. So detected tools would be Suction and Grasper. Wait, let’s make sure. The image shows two surgical instruments. Let’s check the options. Suction is a valid name. Grasper is also there. So the detected tools are Suction and Grasper. {"detected_tools": ["Suction", "Grasper"]} 53 Qw en3-VL-235B-A22B-Thinking Resp onse So, let’s look at the image. First, identify the tools. There’s a white gauze-like material, which might be a Cotton Patty. Then there are two instruments: one looks like a suction tool (Suction), and another might be a Grasper. Wait, let’s check the list. Cotton Patty is in the list. Then, the metallic instrument with a tube--- Suction. Also, the other instrument that’s holding or manipulating--- Grasper. Let’s confirm. In the image, the white pad is Cotton Patty. The tube-like instrument is Suction. The other tool with the jaws is Grasper. Are there any others? Let’s check the valid names. So detected tools: Cotton Patty, Suction, Grasper. {"detected_tools": ["Cotton Patty", "Suction", "Grasper"]} Qw en3-VL-235B-A22B-Thinking Resp onse So, let’s look at the surgical video frame. There are two tools visible. First, the one on the left---what is that? Wait, the options include Suction, maybe? Wait, no. Wait, the tool on the left might be a Suction Coagulator? Or maybe Suction. Wait, let’s check the list. The tools present: the left tool looks like a suction device, maybe Suction. The right tool---wait, the right one has a metallic tip, maybe a Suction Coagulator? Wait, no. Wait, let’s think. The options include Suction. Let’s see. In the image, there are two instruments. Let’s check each. First, the left instrument: it’s a metallic tube, possibly a Suction tool. The right instrument: maybe a Suction Coagulator? Wait, no. Wait, the valid tools: Suction is a valid name. Let’s check. The list has "Suction" as a tool. So if there’s a suction device, that’s one. Are there others? Wait, the image shows two surgical instruments. Let’s identify each. The left one: maybe Suction. The right one: maybe Suction Coagulator? Wait, no. Wait, the Suction Coagulator is a specific tool. Alternatively, maybe the right one is a Suction microdebrider? No, the microdebrider is different. Wait, let’s check the options again. Wait, the tools in the list: Suction is a valid entry. So if there’s a suction device, that’s one. Are there any other tools? Let’s see. The image has two instruments. Let’s check each. First instrument (left): looks like a suction tube. So "Suction". Second instrument (right): the tip is rounded, maybe a Suction Coagulator? Wait, Suction Coagulator is a tool that combines suction and coagulation. But maybe 54 in this case, the right tool is a Suction Coagulator. Wait, but let’s check the options. The valid names include "Suction Coagulator" and "Suction". Wait, but maybe both are suction-related. Wait, no. Let’s think again. The left tool: maybe it’s a Suction. The right tool: perhaps a Suction Coagulator. But I need to be precise. Alternatively, maybe the right tool is a Suction microdebrider? No, the microdebrider has a different tip. Wait, the image shows two instruments. Let’s check the list again. Wait, the correct approach is to match the visible tools to the exact names. Let’s see: - Suction: yes, if there’s a suction device. Looking at the image, there are two instruments. Let’s check each. First, the left instrument: it’s a metallic tube, likely a suction device. So "Suction". Second, the right instrument: the tip is a rounded metallic part, maybe a Suction Coagulator. Wait, but Suction Coagulator is a specific tool. Alternatively, maybe it’s a different type. Wait, the list includes "Suction" as a separate entry. So if both are suction-related, but the exact names. Wait, the problem says to list each tool only once even if multiple. But in this case, are there two different tools or same? Wait, maybe the left is Suction and the right is Suction Coagulator. Let’s check. Suction Coagulator: a tool that suctions and coagulates. The right tool might be that. The left one is just Suction. So detected tools would be ["Suction", "Suction Coagulator"]. Wait, but let’s confirm. Let’s look at the image again. The left instrument is a larger tube, maybe a suction, and the right one is a different type. Alternatively, maybe both are suction, but the list has "Suction" as a single entry. Wait, no---if they are different tools, but the names must be exact. Wait, the valid tool names include "Suction" and "Suction Coagulator". So if one is Suction and the other is Suction Coagulator, then both are listed. Alternatively, maybe the right tool is a Suction microdebrider? No, the microdebrider has a rotating tip, which isn’t visible here. Wait, another approach: check common endoscopic tools. In sinus surgery, for example, suction and coagulator are common. The image shows two instruments. Let’s assume left is Suction, right is Suction Coagulator. So the detected tools would be Suction and Suction Coagulator. 55 {"detected_tools": ["Suction", "Suction Coagulator"]} M.1 Mo del Resp onses to Questions ab out Neurosurgery Question 1 What roles do suction, cotton patties, and hemostatic agents play during pituitary tumor resection? Gemma 3 27B Resp onse Okay, let’s break down the roles of suction, cotton patties, and hemostatic agents during pituitary tumor resection. These are *critical* components of the surgical toolkit, and understanding their interplay is key to a successful and safe operation. I’ll cover each, then discuss how they work together. This is a complex surgery, so I’ll aim for a detailed but understandable explanation. **Please remember I am an AI and this is for informational purposes only. It is not medical advice. Consult with a qualified healthcare professional for any health concerns or before making any decisions related to your health or treatment.** **1. Suction** * **Primary Role: Maintaining a Clear Operative Field & Removing Fluid/Debris.** This is arguably the *most* important element throughout the entire procedure. The surgeon needs to *see* what they’re doing, and the surgical space within the sella (the bony cavity where the pituitary gland sits) is incredibly small and prone to bleeding. * **Types of Suction Used:** * **Irrigation Suction:** This is the workhorse. It simultaneously delivers irrigating fluid (usually normal saline) to wash away blood, debris, and tumor fragments *while* simultaneously suctioning it all away. The fluid keeps the field clean and allows the surgeon to visualize the delicate structures. Different tip sizes and shapes are used depending on the specific area being worked on. Gentle irrigation is crucial to avoid damaging brain tissue. * **Ultrasonic Aspirator (CUSA):** Often used for softer tumors (like pituitary adenomas). CUSA uses high-frequency vibrations to break up the tumor tissue into small fragments, which are then suctioned away. It’s more selective than traditional suction, helping to preserve normal pituitary tissue and surrounding structures. It’s particularly useful for tumors that are adherent to critical structures. * **Bipolar Suction:** Some suction devices combine suction with bipolar electrocautery. This allows for simultaneous coagulation of small bleeding vessels while suctioning away the blood. * **Why it’s crucial in pituitary surgery:** * **Limited Space:** The sella is tiny. Blood quickly obscures the view. * **Proximity to Critical Structures:** The pituitary gland is nestled near the optic nerves, the cavernous sinus (a major venous structure), and the brainstem. Clear visualization is essential to avoid damage. 56 * **Fragile Tissue:** The pituitary gland and surrounding tissues are delicate. **2. Cottonoid Patties (Cotton Patties/Neuro-Patties)** * **Primary Role: Hemostasis (Stopping Bleeding) & Tissue Protection.** These aren’t your typical cotton balls. Neuro-Patties are specifically designed for neurosurgery. They are made of highly absorbent, tightly woven cotton. * **How they work:** * **Direct Pressure:** The primary mechanism. Gently packing the patties into the surgical bed applies direct pressure to bleeding points, helping to stop the hemorrhage. * **Absorption:** They soak up blood, further contributing to a dry field. * **Temporary Space Filling:** They can temporarily fill small defects in the bone or dura (the membrane covering the brain) created during tumor removal. * **Tissue Protection:** They can act as a barrier to protect delicate structures from inadvertent injury during manipulation. * **Specific Use in Pituitary Surgery:** * **Sella Floor Repair:** After the tumor is removed, there’s often a defect in the sella floor. A patty soaked in hemostatic agent (see below) is often placed here to promote healing and prevent cerebrospinal fluid (CSF) leak. * **Packing Around Vessels:** Used to gently pack around the cavernous sinus or other vessels to control bleeding. * **Dural Closure Assistance:** Can help to support the dural repair. * **Important Considerations:** * **Careful Removal:** Patties *must* be carefully removed after the surgery to avoid leaving any remnants behind, which could cause infection or inflammation. They are often marked with radiopaque threads to aid in identification on post-operative imaging. * **Not a Long-Term Solution:** Patties are for temporary hemostasis and space filling. They don’t promote permanent tissue repair on their own. **3. Hemostatic Agents** * **Primary Role: Enhancing Hemostasis (Stopping Bleeding).** These are substances applied to bleeding surfaces to accelerate clot formation. They are often used *in conjunction* with suction and cotton patties. * **Types of Hemostatic Agents Commonly Used in Pituitary Surgery:** * **Gelatin-Based (e.g., Gelfoam):** A porous sponge that provides a matrix for clot formation. It’s relatively inexpensive and effective for controlling minor bleeding. * **Oxidized Regenerated Cellulose (e.g., Surgicel):** Another absorbent material that promotes clotting. It has some antibacterial properties. * **Thrombin:** A potent clotting factor. Often used in combination with collagen or other carriers. Can be very effective for controlling more significant bleeding. (There are bovine and human forms; human thrombin is preferred to minimize immune reactions). 57 * **Fibrin Sealants:** Contain fibrinogen and thrombin, mimicking the natural clotting cascade. They create a strong, adhesive clot. Often used for dural closure. * **Polysaccharide-Based (e.g., Arista AH):** Derived from plant sources, these agents promote rapid clot formation and are biocompatible. * **How they’re used in pituitary surgery:** * **Soaking Cotton Patties:** Patties are frequently soaked in a hemostatic agent before being placed in the surgical bed. This provides both direct pressure and a boost to clotting. * **Direct Application:** Hemostatic agents can be applied directly to bleeding vessels or surfaces. * **Dural Sealants:** Fibrin sealants are often used to reinforce the dural closure, reducing the risk of CSF leak. * **Important Considerations:** * **Appropriate Agent Selection:** The choice of hemostatic agent depends on the type and severity of bleeding, the location, and the surgeon’s preference. * **Potential Complications:** While generally safe, some hemostatic agents can cause inflammation or allergic reactions. **How They Work Together: A Surgical Scenario** Imagine the surgeon is removing a pituitary adenoma: 1. **Initial Exposure:** The surgeon gains access to the sella through the nose (transsphenoidal approach). 2. **Tumor Dissection:** Using microsurgical instruments, the surgeon carefully dissects the tumor from surrounding structures. **Continuous irrigation suction** is used to keep the field clear of blood and debris. 3. **Bleeding Control:** As vessels are encountered, the surgeon may use **bipolar cautery** for small vessels. For larger bleeding points, they might apply a **hemostatic agent** (like thrombin) directly or pack the area with a **cotton patty soaked in hemostatic agent**. 4. **Tumor Removal (CUSA):** If the tumor is soft, a **CUSA** might be used to debulk it, with simultaneous suction to remove the fragmented tissue. 5. **Sella Floor Repair:** Once the tumor is removed, any defects in the sella floor are addressed. A **cotton patty saturated with a hemostatic agent and potentially a dural sealant** is carefully placed to promote healing and prevent CSF leak. 6. **Dural Closure:** The dura is closed, often with sutures and reinforced with a **fibrin sealant**. 7. **Final Inspection:** The surgeon meticulously inspects the field with **suction** to ensure complete hemostasis and remove any remaining debris or packing material. **In conclusion:** Suction, cotton patties, and hemostatic agents are not independent tools but rather a coordinated system used to achieve a safe and effective pituitary tumor resection. They work synergistically to provide 58 visualization, control bleeding, and promote healing in this delicate and challenging surgery. **Disclaimer:** This information is for general knowledge and informational purposes only, and does not constitute medical advice. It is essential to consult with a qualified healthcare professional for any health concerns or before making any decisions related to your health or treatment. N Gemma 3 27B Resp onses to Neurosurgery Questions This app endix presen ts the complete resp onses from Gemma 3 27B to five neurosurgery questions. The mo del was prompted with eac h question and generated the resp onses sho wn b elo w. N.1 Mo del Configuration P arameter V alue Mo del Gemma 3 27B Instruct Mo del ID google/gemma-3-27b-it Precision bfloat16 Max New T okens 8,192 T emp erature 0.0 T able 37: Gemma 3 27B generation configuration. Question 2 Describ e the standard steps of an endoscopic endonasal transsphenoidal approach to a pitu- itary adenoma. Gemma 3 27B Resp onse ## Endoscopic Endonasal Transsphenoidal Approach to Pituitary Adenoma: A Step-by-Step Description The endoscopic endonasal transsphenoidal approach (EETS) is now the gold standard for removing most pituitary adenomas. Here’s a detailed breakdown of the standard steps involved. It’s a complex procedure, and this is a general overview; specifics can vary based on tumor size, location, and surgeon preference. **I. Preoperative Preparation:** * **Imaging:** High-resolution MRI with and without contrast is *essential* for planning. CT scans may be used to assess sphenoid sinus anatomy. Angiography 59 may be considered for very large or invasive tumors to assess relationship to major vessels. * **Hormonal Evaluation:** Complete endocrine workup to assess pituitary function and identify hormone excess. * **Visual Field Testing:** To document pre-operative visual function, especially if the tumor is compressing the optic chiasm. * **Patient Counseling:** Detailed discussion of risks, benefits, alternatives, and expected recovery. * **Medical Optimization:** Management of any co-morbidities and potential cessation of blood thinners. **II. Intraoperative Steps:** **1. Anesthesia & Positioning:** * **General Anesthesia:** The patient is placed under general anesthesia. * **Positioning:** Typically a supine position with the head slightly elevated and fixed in a three-point head holder. This allows for optimal visualization and access. Sometimes a slight reverse Trendelenburg position is used. **2. Nasal Preparation & Endoscopic Access:** * **Nasal Decongestion:** Topical decongestants (like oxymetazoline) are used to shrink nasal mucosa. * **Endoscopic Setup:** A rigid endoscope (typically 0- or 30-degree) is inserted through one nostril. The surgeon operates by looking at a monitor displaying the endoscopic view. * **Septal Mucosa Incision:** A small incision is made in the nasal septum (the cartilage dividing the nostrils). This is often unilateral (one side) but can be bilateral if needed for wider access. * **Sphenoid Sinus Entry:** The posterior nasal septum is removed to expose the sphenoid sinus. The sphenoid sinus is then widely opened. This often involves removing any septations or disease within the sinus. Image guidance (see below) is crucial here. **3. Sellar Floor Exposure & Opening:** * **Sellar Floor Identification:** The surgeon identifies the bony sphenoid planum (sellar floor), which is the bone separating the sphenoid sinus from the sella turcica (the bony cavity housing the pituitary gland). * **Sellar Floor Removal:** Using a combination of micro-instruments (drills, curettes, and endoscopes), the surgeon carefully removes the bony sphenoid planum to create an opening into the sella turcica. This is done under constant endoscopic visualization and often with the assistance of image guidance. The dura (the membrane covering the brain) is usually visualized at this point. * **Dural Opening:** A small incision is made in the dura mater to access the sella. The size of the dural opening is tailored to the size of the tumor. **4. Tumor Resection:** 60 * **Tumor Debulking:** The surgeon begins to remove the tumor. For softer tumors, this can be done with suction and micro-instruments. For harder or fibrous tumors, a combination of techniques is used. * **Internal Decompression:** The tumor is often debulked from within, starting with the central portion. * **Capsule Dissection:** The tumor capsule is carefully dissected from the surrounding structures the pituitary gland, optic chiasm, cavernous sinuses, and sphenoid sinus walls. This is the most critical and delicate part of the surgery. * **Complete Resection (Goal):** The goal is to achieve gross total resection (GTR) of the tumor, meaning all visible tumor is removed. However, this isn’t always possible or safe, especially for invasive tumors. * **Suction Irrigation:** Continuous irrigation and suction are used throughout the resection to maintain a clear surgical field. **5. Reconstruction & Closure:** * **Dural Repair:** The dural opening is meticulously repaired. This is often done with a combination of: * **Fat Graft:** Fat harvested from the abdomen is used to provide a watertight seal. * **Dural Substitutes:** Collagen matrices or other synthetic materials may be used in conjunction with fat. * **Fibrin Glue:** Fibrin glue is often applied to reinforce the dural repair. * **Sphenoid Sinus Reconstruction (Optional):** In some cases, the sphenoid sinus is partially reconstructed with a flap or graft to prevent cerebrospinal fluid (CSF) leaks. * **Nasal Packing:** Nasal packing (e.g., with absorbable material or silicone splints) is placed to support the nasal mucosa and promote healing. **III. Important Adjuncts:** * **Image Guidance (Neuronavigation):** This is *crucial*. It uses pre-operative MRI or CT scans to create a 3D map of the patient’s anatomy, allowing the surgeon to precisely locate the tumor and surrounding structures during surgery. * **Intraoperative Neuromonitoring (IONM):** This may be used for larger or more complex tumors, especially those near the optic nerves. It involves monitoring the function of the optic nerves and brainstem during surgery to detect any potential injury. * **Fluorescence-Guided Surgery:** Some surgeons use fluorescent dyes (like 5-ALA) to help differentiate tumor tissue from normal pituitary tissue, improving the extent of resection. **IV. Postoperative Care:** 61 * **ICU Monitoring:** Patients are typically monitored in the intensive care unit (ICU) for 1-2 days. * **Hormone Replacement:** Postoperative hormone deficiencies are common and require hormone replacement therapy (e.g., cortisol, thyroid hormone, growth hormone). * **CSF Leak Monitoring:** Close monitoring for CSF leaks is essential. * **Follow-up MRI:** A follow-up MRI is performed within a few weeks to assess the extent of resection and rule out any complications. * **Endocrine Follow-up:** Regular endocrine follow-up is necessary to monitor hormone levels and adjust hormone replacement therapy as needed. **Disclaimer:** This is a general overview and should not be considered medical advice. The specific steps and techniques used in an EETS procedure can vary depending on the individual patient and the surgeon’s experience. Always consult with a qualified neurosurgeon for any medical concerns. Question 3 Compare microscopic versus endoscopic approaches for pituitary surgery . Gemma 3 27B Resp onse ## Microscopic vs. Endoscopic Pituitary Surgery: A Detailed Comparison Pituitary surgery aims to remove pituitary tumors (adenomas) that cause hormonal imbalances or compress surrounding structures like the optic nerves. Both microscopic and endoscopic approaches are common, but they differ significantly in technique, advantages, and disadvantages. Here’s a detailed comparison: **1. Surgical Approach & Technique:** * **Microscopic Surgery (Transsphenoidal):** * **Access:** Traditionally, this involves a surgical incision inside the nose (transsphenoidal approach) to reach the sphenoid sinus, a cavity behind the nose. A speculum is used to retract tissues, and a high-powered surgical microscope is essential for visualization. * **Visualization:** Relies heavily on the surgeon’s skill and the magnification provided by the microscope. The surgeon directly views the pituitary gland and tumor through the microscope. * **Instrumentation:** Uses specialized micro-instruments manipulated directly by the surgeon under microscopic guidance. * **Sinus Involvement:** Often requires significant opening of the sphenoid sinus to gain adequate access. * **Endoscopic Surgery (Transsphenoidal):** * **Access:** Also uses a transsphenoidal approach, but instead of a microscope and speculum, a thin, flexible endoscope (a tube with a camera and light 62 source) is inserted through the nostrils. * **Visualization:** Provides a wide-angle, high-definition view on a monitor. The surgeon views the surgical field on the monitor, manipulating instruments through channels in the endoscope. * **Instrumentation:** Uses specialized endoscopic instruments that are smaller and more maneuverable than microscopic instruments. * **Sinus Involvement:** Generally requires less sphenoid sinus opening than microscopic surgery, potentially minimizing nasal complications. **2. Advantages & Disadvantages:** | Feature | Microscopic Surgery | Endoscopic Surgery | |---|---|---| | **Visualization** | Excellent depth perception, tactile feedback. Surgeon directly views the field. | Wide-angle view, high definition. Can visualize around corners. Less depth perception. | | **Surgical Precision** | Highly precise, especially for complex tumors. Surgeon has direct control and feel. | Precision improving rapidly with advancements in endoscope technology and surgeon experience. | | **Tumor Size** | Well-suited for a wide range of tumor sizes, including larger and more complex tumors. | Historically better for smaller, less complex tumors. Increasingly used for larger tumors with experienced surgeons. | | **Sinus Complications** | Higher risk of nasal congestion, sinusitis, cerebrospinal fluid (CSF) leak, and septal perforation due to wider sphenoid sinus opening. | Lower risk of these complications due to less sinus disruption. | | **Nasal Morbidity** | More significant nasal packing often required post-operatively, leading to discomfort. | Less or no nasal packing often needed, leading to faster recovery and less discomfort. | | **Recovery Time** | Generally longer recovery due to more extensive sinus manipulation and nasal packing. | Generally faster recovery with less pain and quicker return to normal activities. | | **Learning Curve** | Steeper learning curve for surgeons initially, but well-established technique. | Steeper learning curve for surgeons transitioning from microscopic to endoscopic techniques. Requires specialized training. | | **Cost** | Can be slightly less expensive initially (equipment costs are established). | Can be more expensive due to the cost of endoscopes and specialized instruments. | | **Surgeon Experience** | Widely available with many experienced surgeons. | Availability of highly experienced endoscopic pituitary surgeons is growing but may be limited in some areas. | | **Anterior Pituitary Preservation** | Generally good, but can be challenging with larger tumors. | Potentially better preservation of normal anterior pituitary function due to less manipulation. | **3. Specific Tumor Types & Considerations:** 63 * **Microadenomas (<10mm):** Both approaches are effective. Endoscopic is often preferred due to faster recovery and lower morbidity. * **Macroadenomas (>10mm):** Microscopic surgery has traditionally been the gold standard, especially for complex macroadenomas with significant extension. However, experienced endoscopic surgeons are increasingly successful with these tumors. * **Aggressive Tumors (e.g., invasive adenomas):** Microscopic surgery may be favored for more extensive resection and better control. * **Recurrent Tumors:** Endoscopic approach can be useful for accessing residual tumor tissue after previous microscopic surgery. * **Craniopharyngiomas:** Both approaches can be used, but endoscopic may be preferred for smaller lesions and to minimize brain retraction. * **Cholesterol Granulomas:** Endoscopic approach is often preferred for these cysts due to its ability to effectively decompress the cyst and preserve pituitary function. **4. Current Trends & Future Directions:** * **Increasing adoption of endoscopic surgery:** Endoscopic techniques are becoming increasingly popular and are now considered the preferred approach by many surgeons, particularly for smaller and less complex tumors. * **Hybrid approaches:** Some surgeons utilize a combination of microscopic and endoscopic techniques to leverage the advantages of both. * **Robotic assistance:** Robotic-assisted endoscopic pituitary surgery is emerging as a potential future direction, offering even greater precision and dexterity. * **Improved endoscope technology:** Advancements in endoscope resolution, illumination, and instrument design are continually improving the capabilities of endoscopic surgery. **In conclusion:** Both microscopic and endoscopic approaches are viable options for pituitary surgery. The best approach depends on several factors, including the **size and type of tumor, the surgeon’s experience, and the patient’s overall health.** **It’s crucial to discuss the risks and benefits of each approach with a neurosurgeon specializing in pituitary surgery to determine the most appropriate treatment plan.** **Disclaimer:** I am an AI chatbot and cannot provide medical advice. This information is for general knowledge and informational purposes only, and does not constitute medical advice. It is essential to consult with a qualified 64 healthcare professional for any health concerns or before making any decisions related to your health or treatment. Question 4 Compare the use of a Rhoton dissector with suction or curettes during pituitary adenoma resection. When is eac h preferred? Gemma 3 27B Resp onse ## Rhoton Dissector vs. Suction/Curettes in Pituitary Adenoma Resection: A Comparison Both the Rhoton dissector and suction/curettes are crucial tools in transsphenoidal pituitary adenoma resection, but they serve different purposes and are used in different phases of the surgery. Here’s a detailed comparison, including when each is preferred: **1. Rhoton Dissector** * **What it is:** A thin, blunt instrument with a rounded tip, typically made of titanium or a similar material. It comes in various sizes and angles. It’s designed for *dissection*---gently separating the tumor from surrounding structures. * **Mechanism of Action:** Works by creating a plane between the tumor and the pituitary gland, cavernous sinus, optic chiasm, and dura. It relies on blunt dissection, minimizing trauma. * **Advantages:** * **Precise Dissection:** Excellent for delicate dissection around critical neurovascular structures (optic chiasm, internal carotid artery). * **Minimizes Trauma:** Blunt dissection reduces the risk of bleeding and damage to surrounding tissues compared to sharp instruments or aggressive curettage. * **Visualization:** Helps to define the tumor capsule and identify the optimal plane for removal. * **Soft/Cystic Tumors:** Particularly useful for softer, cystic adenomas where suction alone may not be effective. * **Capsule Dissection:** Essential for debulking and defining the tumor capsule, especially for larger or invasive adenomas. * **Disadvantages:** * **Time-Consuming:** Blunt dissection is slower than curettage. * **Requires Skill:** Effective use requires significant surgical experience and a thorough understanding of anatomy. * **Limited for Hard Tumors:** Less effective for very firm, fibrous adenomas. * **Can’t Remove Fluid/Debris:** Doesn’t actively remove tumor material; it *exposes* it for removal by other means. **2. Suction & Curettes** * **What they are:** 65 * **Suction:** A device that uses negative pressure to remove fluid, blood, and soft tissue fragments. Often uses a Frazier tip or similar. * **Curettes:** Loop-shaped instruments (various sizes and shapes - e.g., Ball, Luer, Janzen) used to scrape and remove soft tissue. Can be rigid or flexible. * **Mechanism of Action:** * **Suction:** Removes fluid and soft debris, improving visualization. * **Curettes:** Mechanically remove tumor tissue by scraping. * **Advantages:** * **Efficient Removal:** Rapidly removes large volumes of soft tumor tissue. * **Good for Soft/Friable Tumors:** Effective for adenomas that are easily fragmented. * **Hemostasis:** Suction can help control bleeding by removing blood from the surgical field. * **Debulking:** Quickly reduces tumor size, facilitating further dissection. * **Disadvantages:** * **Risk of Trauma:** Aggressive curettage can damage the pituitary gland, optic chiasm, or cavernous sinus. * **Poor Visualization:** Can create a bloody field, obscuring visualization. * **Not Ideal for Encapsulated Tumors:** May not effectively remove tumors with a well-defined capsule without first being dissected. * **Risk of CSF Leak:** Aggressive curettage of the sella can increase the risk of cerebrospinal fluid leak. **When is each preferred? A Phased Approach & Specific Scenarios** The use of these tools is often *sequential* and *complementary* during a pituitary adenoma resection. Here’s a breakdown: **Phase 1: Initial Entry & Tumor Exposure** * **Rhoton Dissector:** Primarily used for the initial entry into the sella, opening the sphenoid sinus, and identifying the dura. It’s also used to initially define the tumor margins and begin dissecting the tumor from the pituitary gland. * **Suction:** Used to remove any blood or debris encountered during the initial entry and to maintain a clear surgical field. **Phase 2: Tumor Debulking & Dissection** * **Rhoton Dissector:** Crucial for dissecting the tumor from the optic chiasm, cavernous sinus, and pituitary gland. This is especially important for: * **Optically Important Tumors:** Tumors that are close to or compressing the optic chiasm. Gentle dissection with the Rhoton is paramount. * **Invasive Adenomas:** Tumors that extend beyond the sella. * **Larger Adenomas:** To define the tumor capsule and create a plane for removal. * **Suction & Curettes:** Used *after* initial dissection with the Rhoton. * **Soft, Friable Tumors:** Curettes are used to remove the bulk of the tumor tissue that has been exposed by the Rhoton dissector. Suction simultaneously removes debris and maintains visualization. * **Cystic Components:** Suction is excellent for removing cystic fluid. 66 **Phase 3: Final Removal & Pituitary Reconstruction** * **Rhoton Dissector:** Used for meticulous removal of any remaining tumor fragments, especially in areas near critical structures. * **Suction & Curettes:** Used to remove any residual tumor tissue and to carefully curette the sella floor to ensure complete removal. However, curettage is used more cautiously in this phase to minimize the risk of pituitary damage or CSF leak. **Specific Scenarios & Preferences:** | Scenario | Preferred Tool(s) | Rationale | |---|---|---| | **Small, Soft Prolactinoma** | Suction & Curettes (primarily) | Often easily fragmented and removed with minimal dissection. | | **Large, Invasive Prolactinoma** | Rhoton Dissector + Suction/Curettes | Requires careful dissection from surrounding structures before debulking. | | **Non-Functioning Adenoma with Chiasm Compression** | Rhoton Dissector (primary) + Suction/Curettes | Optic chiasm preservation is paramount; gentle dissection is essential. | | **Firm, Fibrous Adenoma** | Rhoton Dissector + Micro-instruments | Requires more meticulous dissection; curettage may be less effective. | | **Recurrent Adenoma** | Rhoton Dissector + Suction/Curettes | Often involves scar tissue, requiring careful dissection. | | **Cystic Adenoma** | Suction (primary) + Rhoton Dissector | Suction effectively removes the cyst fluid, and the Rhoton helps define the capsule. | **Important Considerations:** * **Endoscopic vs. Microscopic Approach:** The specific techniques and tool preferences can vary slightly depending on whether the surgery is performed using an endoscope or a microscope. Endoscopes often allow for more angled visualization and may favor certain Rhoton dissector shapes. * **Surgeon’s Experience:** The surgeon’s skill and preference play a significant role in the choice of instruments and techniques. * **Intraoperative Monitoring:** Neurophysiological monitoring (e.g., visual evoked potentials) can guide the surgeon’s dissection and minimize the risk of damage to critical structures. **Disclaimer:** I am an AI chatbot and cannot provide medical advice. This information is for general knowledge and informational purposes only, and does not constitute medical advice. It is essential to consult with a qualified healthcare professional for any health concerns or before making any decisions related to your health or treatment. 67 Question 5 What anatomical landmarks are used to iden tify the sella turcica during transsphenoidal pituitary surgery , and wh y are they critical for av oiding complications? Gemma 3 27B Resp onse ## Anatomical Landmarks for Sella Turcica Identification in Transsphenoidal Pituitary Surgery & Why They Matter Transsphenoidal pituitary surgery is a delicate procedure requiring precise anatomical knowledge. Identifying the sella turcica (Turkish saddle) and its surrounding structures is *critical* for successful surgery and minimizing complications. Here’s a breakdown of the key landmarks and their importance: **I. External Landmarks (Pre-operative Imaging & Intraoperative Guidance)** These are identified primarily through pre-operative imaging (CT and MRI) and then confirmed intraoperatively using fluoroscopy, neuronavigation, and direct visualization. * **Dorsum Sellae:** This is the posterior wall of the sella, formed by the posterior clinoid processes. It’s the "back" of the saddle. *Importance:* Defining the dorsum sellae helps establish the posterior limit of the surgical field. Overly aggressive removal of the dorsum can lead to cerebrospinal fluid (CSF) leak and damage to the pituitary stalk. * **Tuberculum Sellae:** The anterior projection of the sella, formed by the anterior clinoid processes. It’s the "front" of the saddle. *Importance:* Helps define the anterior boundary. Fracturing the tuberculum sellae can cause bleeding and potentially damage the optic nerves/chiasm. * **Clivus:** The bony base of the skull anterior to the pons. The sella sits *on* the clivus. *Importance:* The clivus provides a key reference point for the overall orientation and depth of the surgical approach. Understanding its contours is vital to avoid injury to the brainstem. * **Sphenoid Sinus:** The air-filled cavity *below* the sella. The surgeon accesses the sella by opening the sphenoid sinus. *Importance:* The size and pneumatization (air-filling) of the sphenoid sinus vary significantly between individuals. Knowing its anatomy is crucial for safe and effective sinus entry. Variations like concha (bony shelves) within the sinus need to be identified to avoid damage. * **Carotid Groove:** Located laterally and inferior to the sella, housing the internal carotid arteries. *Importance:* This is arguably the *most critical* landmark. The internal carotid arteries are immediately adjacent to the sella and are at high risk of injury during surgery. Identifying the carotid groove and its relationship to the sella is paramount. * **Optic Canal & Optic Strut:** The bony canal through which the optic nerves pass, located superolaterally to the sella. The optic strut is the bony support between the optic canal and the sella. *Importance:* The optic nerves and chiasm lie *above* the sella and are vulnerable to compression or injury. The optic canals and strut define the superior limits of the surgical field and help protect the visual pathways. 68 * **Superior Sella Rim:** The bony edge of the sella superiorly. *Importance:* Helps define the superior limit of the sella and the proximity of the optic structures. * **Foramen Ovale:** Located posterolaterally, containing the accessory meningeal artery. *Importance:* While not directly within the sella, it’s a nearby structure that can be encountered during surgery and a potential source of bleeding. **II. Intraoperative Landmarks (Once the Sphenoid Sinus is Entered)** Once the surgeon has entered the sphenoid sinus, these landmarks become visible: * **Sellar Floor:** The bony floor of the sella, which the surgeon must remove to access the pituitary gland. *Importance:* Careful removal of the floor is essential to avoid dural tears and CSF leaks. * **Dural Ring:** The circular opening in the dura mater covering the sella. *Importance:* The dural ring is incised to gain access to the subarachnoid space and the pituitary gland. The incision must be carefully planned to minimize tension and prevent CSF leaks. * **Pituitary Gland:** The target of the surgery, usually appearing as a soft, pinkish-gray mass within the sella. *Importance:* Visualizing the gland and any associated tumor is crucial for accurate resection. * **Pituitary Stalk:** The connection between the pituitary gland and the hypothalamus. *Importance:* Preserving the pituitary stalk is often desirable to maintain residual pituitary function. * **Cavernous Sinus:** Located laterally to the sella, containing the internal carotid artery, abducens nerve (CN VI), and oculomotor nerve (CN III). *Importance:* The cavernous sinus is a critical landmark for avoiding injury to the internal carotid artery and cranial nerves. **Why are these landmarks critical for avoiding complications?** Complications in transsphenoidal pituitary surgery can be devastating. Precise anatomical knowledge and identification of these landmarks are essential to prevent: * **Cerebrospinal Fluid (CSF) Leak:** Damage to the dura mater or inadequate dural repair can lead to CSF leakage, potentially causing meningitis. * **Internal Carotid Artery Injury:** The internal carotid artery is in close proximity to the sella. Injury can cause stroke or massive hemorrhage. * **Optic Nerve/Chiasm Damage:** Compression or injury to the optic nerves/chiasm can result in vision loss (blindness). * **Hypopituitarism:** Damage to the pituitary gland or pituitary stalk can lead to hormone deficiencies. * **Cranial Nerve Palsies:** Injury to cranial nerves within the cavernous sinus (CN III, CN VI) can cause double vision or other neurological deficits. * **Bleeding:** Damage to blood vessels during surgery can lead to significant bleeding. 69 **Tools to Aid Landmark Identification:** * **Preoperative Imaging (CT & MRI):** Provides a detailed roadmap of the sella and surrounding structures. * **Fluoroscopy:** Real-time X-ray imaging used intraoperatively to confirm the position of instruments and identify bony landmarks. * **Neuronavigation:** A computer-assisted surgical planning and guidance system that uses pre-operative imaging to create a 3D map of the surgical field. This allows the surgeon to precisely locate anatomical structures during surgery. * **Endoscopic Visualization:** Provides a magnified view of the surgical field, allowing for better identification of anatomical landmarks. In conclusion, successful and safe transsphenoidal pituitary surgery relies heavily on a thorough understanding of the sella turcica’s anatomy and meticulous identification of its surrounding landmarks. The use of advanced imaging and surgical guidance technologies further enhances the surgeon’s ability to navigate this complex anatomical region and minimize the risk of complications. 70
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment