수술 인공지능의 한계와 확장 데이터 모델 의료AGI 도전
본 논문은 최신 비전‑언어 모델(VLM)과 경량 객체 탐지 모델을 이용해 신경외과 내시경 영상에서 수술 도구를 식별하는 과제를 수행한다. 19개의 공개 VLM을 제로샷으로 평가한 결과 대부분이 13 % 수준의 다수표본 기준을 넘지 못했으며, LoRA 기반 파인튜닝으로도 검증 정확도는 51 %에 머물렀다. 어댑터 용량을 1000배 확대해도 일반화는 개선되지 않았다. 반면 26 M 파라미터 YOLOv12‑m은 55 % 이상의 정확도를 달성해 VLM…
저자: Kirill Skobelev, Eric Fithian, Yegor Baranovski
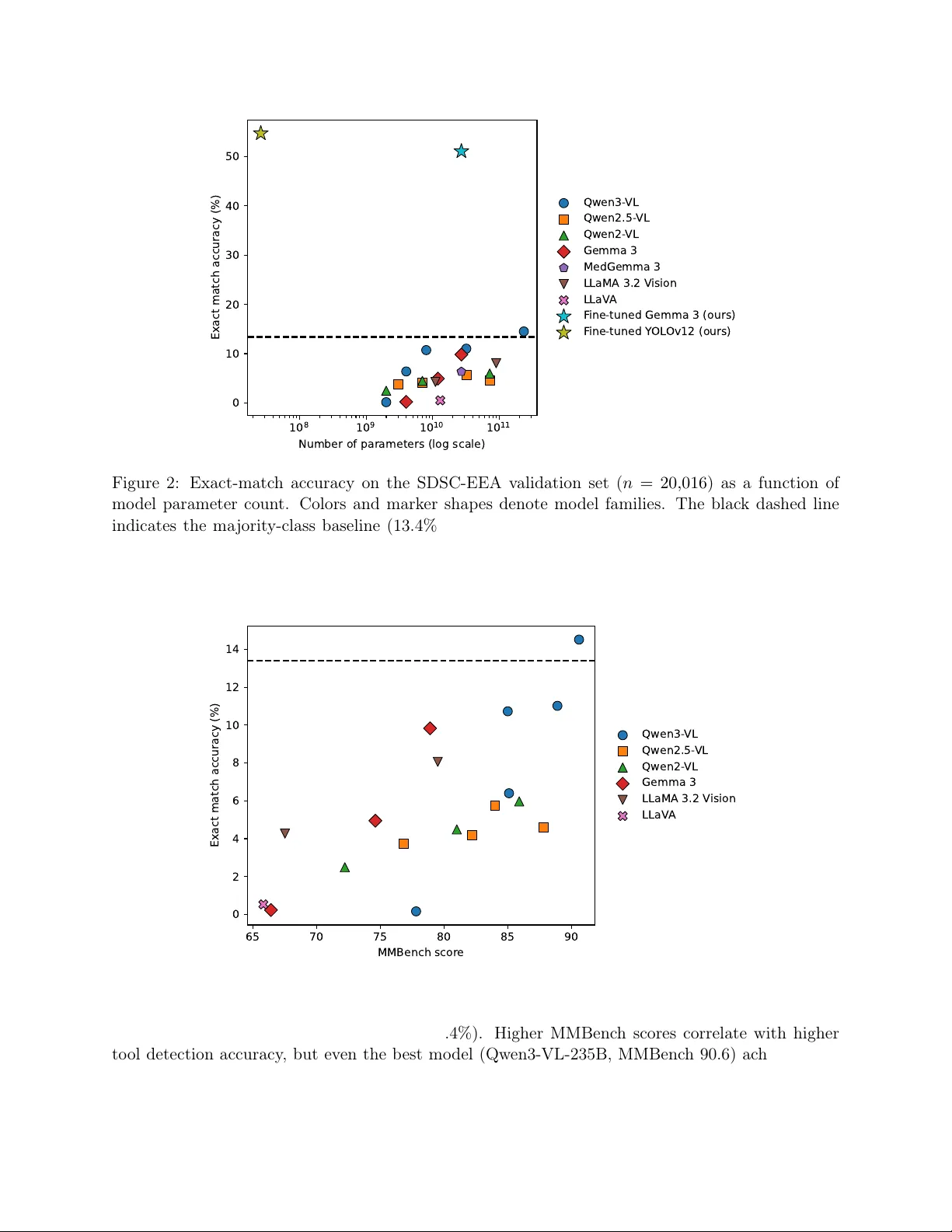
본 논문은 2026년 현재 이용 가능한 최첨단 인공지능 기술을 활용해 수술 현장에서 가장 기본적인 과제인 “수술 도구 식별”을 평가한다. 연구팀은 시술 영상 데이터베이스인 SDSC‑EEA를 구축했으며, 이는 66개의 신경외과 내시경 수술 절차에서 추출한 67 634개의 프레임과 31개의 도구 라벨을 포함한다. 각 프레임은 다중 라벨 형태로 주석이 달려 있어, 하나의 이미지에 여러 도구가 동시에 나타날 수 있다. 데이터는 10명의 외과의사와 3명의 비전문 라벨러가 협업해 검증했으며, 라벨링 오류는 10 % 미만으로 낮았다.
연구는 크게 네 가지 실험군으로 나뉜다. 첫 번째는 19개의 공개 비전‑언어 모델(VLM)을 제로샷 방식으로 평가한 것으로, 모델은 “보이는 도구 이름을 모두 말해라”라는 프롬프트에 따라 JSON 형식으로 출력을 생성한다. 모델 크기는 2 B에서 235 B 파라미터까지 다양했으며, 최신 MMBench 점수는 90.6점에 달했지만, 실제 도구 검출 정확도는 13 % 이하에 머물렀다. 이는 VLM이 일반적인 이미지‑텍스트 매핑에서는 뛰어나지만, 의료 현장의 복잡한 멀티라벨 상황에서는 한계가 있음을 보여준다.
두 번째 실험은 Gemma 3 27B 모델에 LoRA 어댑터를 적용해 파인튜닝한 것이다. 여기서는 두 가지 접근법을 사용했는데, 첫 번째는 모델이 직접 JSON 형태의 구조화된 출력을 학습하도록 했으며, 정확도 47.63 %를 기록했다. 두 번째는 모델의 최종 히든 상태를 평균 풀링해 31개의 도구 클래스를 이진 분류하도록 하는 단일 선형 헤드를 도입했으며, 정확도는 51.08 %에 도달했다. 파인튜닝은 제로샷 대비 성능을 크게 끌어올렸지만, 검증 세트(13개의 절차)에서의 일반화는 여전히 제한적이었다.
세 번째 실험은 어댑터 용량을 크게 늘려 모델 용량을 4.7 M에서 2.4 B 파라미터까지 확장한 것이다. LoRA 랭크를 2에서 1024까지 변화시켰으며, 훈련 정확도는 98.6 %에 이르렀다. 그러나 검증 정확도는 40 %를 넘지 못했고, 이는 파라미터 수와 학습 시간만으로는 도메인 간 분포 차이를 극복할 수 없다는 점을 강조한다.
네 번째 실험은 경량 객체 탐지 모델인 YOLOv12‑m(26 M 파라미터)을 훈련시킨 것이다. YOLO는 바운딩 박스와 클래스 라벨을 동시에 예측하므로, 멀티라벨 집합을 직접 비교할 수 있다. 결과는 54.73 % 정확도로, 모든 VLM 기반 방법을 앞섰으며, 파라미터 수는 VLM보다 1 000배 적었다.
이러한 결과가 우연이 아니라는 것을 확인하기 위해 연구팀은 독립적인 라파시 절제 데이터셋(CholecT50)에서도 동일한 실험을 재현했다. 제로샷 VLM은 34.76 %의 다수표본 기준을 겨우 초과했으며, 파인튜닝 및 어댑터 확장 역시 검증 정확도를 50 % 이하로 제한했다. 반면 YOLOv12‑m은 57 % 이상의 정확도를 유지했다.
논문의 결론은 두드러진다. 첫째, 현재의 “스케일링 가설”(모델 크기와 데이터 양을 무한히 늘리면 성능이 자동으로 향상된다)은 수술 영상 분야에 적용되지 않는다. 둘째, 병목은 모델 자체가 아니라 도메인‑특화 데이터와 라벨링 품질에 있다. 수술 현장은 도구 조합, 시야 각도, 조명 등 다양한 변수가 존재해, 일반적인 이미지‑텍스트 데이터와는 다른 분포를 가진다. 셋째, 효율적인 해결책은 계층적 아키텍처를 도입하는 것이다. 일반적인 VLM이 고수준의 멀티모달 이해와 질의응답을 담당하고, 전문 객체 탐지 모듈이 실제 도구 인식을 담당하도록 설계하면, 두 모델의 장점을 동시에 활용할 수 있다. 또한, 반자동 주석, 합성 데이터 생성, 그리고 도메인‑특화 프리트레이닝을 통해 라벨링 비용을 낮추는 것이 필요하다.
이 논문은 수술 AI 연구에 있어 “데이터와 라벨링이 핵심”이라는 메시지를 강력히 전달한다. 향후 의료‑AGI(전반적 인공지능) 구현을 위해서는 단순히 파라미터를 늘리는 것이 아니라, 도메인‑특화 데이터 파이프라인과 효율적인 모델 설계가 필수적임을 시사한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기