daVinci-LLM:Towards the Science of Pretraining
The foundational pretraining phase determines a model's capability ceiling, as post-training struggles to overcome capability foundations established during pretraining, yet it remains critically under-explored. This stems from a structural paradox: …
Authors: Yiwei Qin, Yixiu Liu, Tiantian Mi
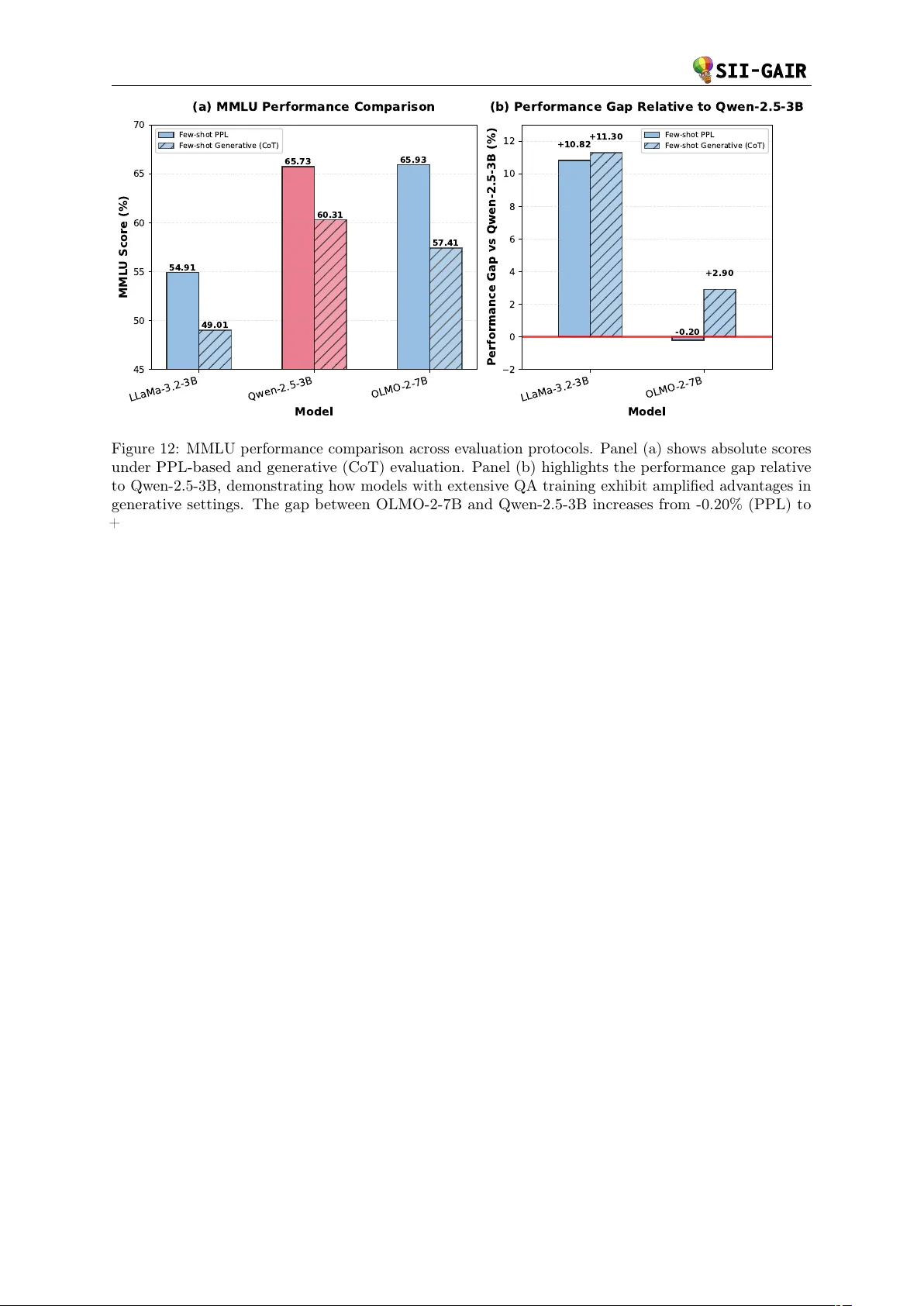
SII-GAIR d aVinci-LLM : T o w ards the Science of Pretraining Yiw ei Qin * 1,2,3 Yixiu Liu * 1,2,3 Tian tian Mi * 1,3 Muhang Xie * 1,3 Zhen Huang * 1,3 W eiy e Si 1,2,3 P engrui Lu 1,2,3 Siyuan F eng 1 Xia W u 1 Liming Liu 1 Y e Luo 1 Jinlong Hou 1 Qip eng Guo 1 Y u Qiao 1 P engfei Liu † 1,2,3 1 SI I 2 SJTU 3 GAIR § daVinci-LLM Gen er ati v e AI Re s e a r c h daVinci-LLM Mo del õ daVinci-LLM Data Abstract The foundational pretraining phase determines a mo del’s capability ceiling, as p ost-training struggles to ov ercome capability foundations established during pretraining, yet it remains criti- cally under-explored. This stems from a structural paradox: organizations with computational resources op erate under commercial pressures that inhibit transparen t disclosure, while aca- demic institutions p ossess researc h freedom but lack pretraining-scale computational resources. d aVinci-LLM o ccupies this unexplored intersection, combining industrial-scale resources with full researc h freedom to adv ance the science of pretraining. W e adopt a fully-op en paradigm that treats op enness as scien tific metho dology , releasing complete data pro cessing pip elines, full training pro cesses, and systematic exploration results. Recognizing that the field lacks systematic metho dology for data pro cessing, w e emplo y the Data Darwinism framew ork—a principled L0-L9 taxonomy from filtering to synthesis. W e train a 3B-parameter model from random initialization across 8T tokens using a tw o-stage adaptiv e curriculum that progres- siv ely shifts from foundational capabilities to reasoning-intensiv e enhancement. Through 200+ con trolled ablations, w e establish that: pro cessing depth systematically enhances capabilities, establishing it as a critical dimension alongside v olume scaling; differen t domains exhibit distinct saturation dynamics, necessitating adaptiv e strategies from prop ortion adjustments to format shifts; comp ositional balance enables targeted in tensification while prev enting p erformance collapse; ho w ev aluation proto col choices shap e our understanding of pretraining progress. By releasing the complete exploration pro cess, w e enable the communit y to build upon our findings and systematic metho dologies to form accumulativ e scientific knowledge in pretraining. Q w en2.5 - 3B LL aMa - 3 .2 - 3B O L MO - 3 - 7B da V inci - LLM - 3B O vera ll c o m p a ra b le t o 7B m o d e l Figure 1: P erformance comparison of daVinci-LLM-3B against baseline mo dels with score across three capabilit y domains, and o verall score comparable to OLMo-3-7B. * Equal contribution. † Corresp onding author. 1 Contents 1 Intro duction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3 2 Data: What W e Used and How We Pro cessed It . . . . . . . . . . . . . . . . . . . . . . . . . 5 2.1 Data Darwinism F ramew ork . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5 2.2 Data P o ol . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6 2.2.1 General . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7 2.2.2 Co de . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7 2.2.3 Science . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8 2.2.4 QA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10 3 T raining Recip e: How We T rained It . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12 3.1 Mo del Architecture . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12 3.2 Ev aluation Protocol . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12 3.3 T raining Metho dology . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13 3.3.1 Stage 1: General F oundation Pretraining . . . . . . . . . . . . . . . . . . . . . . . 14 3.3.2 Stage-2: Reasoning Capability Enhancement . . . . . . . . . . . . . . . . . . . . . 15 3.4 Final Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16 4 Explo ration: Why W e T rained It This Wa y . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17 4.1 Data Pro cessing Depth: F rom Filtering to Syn thesis . . . . . . . . . . . . . . . . . . . . . 18 4.1.1 Co de Data Filtering: L3 Model-Based Filtering . . . . . . . . . . . . . . . . . . . . 18 4.1.2 Math Data Qualit y: L4 Generative Refinement . . . . . . . . . . . . . . . . . . . . 19 4.1.3 L5 Syn thetic QA: Cognitiv e Completion . . . . . . . . . . . . . . . . . . . . . . . . 19 4.2 T raining Dynamics: Adaptiv e Data Strategies . . . . . . . . . . . . . . . . . . . . . . . . . 20 4.2.1 Domain Prop ortion Adjustmen t . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20 4.2.2 F rom Domain A djustment to QA In tro duction . . . . . . . . . . . . . . . . . . . . 21 4.3 Data Mixture Design: Balancing and Intensifying . . . . . . . . . . . . . . . . . . . . . . . 22 4.3.1 Domain Balance: Co de and Science Composition . . . . . . . . . . . . . . . . . . . 23 4.3.2 QA Concen tration: Progressive Intensification . . . . . . . . . . . . . . . . . . . . . 23 4.4 Ev aluation V alidit y: PPL-based vs. Generativ e-based . . . . . . . . . . . . . . . . . . . . 24 5 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25 A Evaluation Details . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31 A.1 Benc hmark Descriptions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31 A.1.1 General Knowledge and Reasoning Benchmarks . . . . . . . . . . . . . . . . . . . . 31 A.1.2 Co de Generation Benchmarks . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32 A.1.3 Mathematics and STEM Reasoning Benchmarks . . . . . . . . . . . . . . . . . . . 32 B T raining Implementation Decisions: LR Decay and QA Masking . . . . . . . . . . . . . . . . 33 C Prompts fo r Dataset Construction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34 2 1. In tro duction SII-GAIR F u n d a m e n t a l Q u es t i o n s D ec i s i o n Ra t i o n a l e A r t i f a c t s O n l y A P I O n l y T i m e l i n e I n c r e a s i n g R e s e a r c h D e p t h Pr e s s u r e f o r o p e n n e s s D e mo c r at i z at i o n of r e s e ar c h R e q u i r e s BO T H : R e so u r c e s + F r e e d o m C o mb i n i n g S c al e & R i g o r T h e U n e x p l o r e d I n t e r se c t i o n C o m m e r c i a l L a b s C h a t G PT , C l au d e , G e mi n i E v o l u t i o n o f P r e t r a i n i n g R e s e a r c h : T h e U n e x p l o r e d I n t e r s e c t i o n O p e n - w e i g h t Re l e a se s L l ama, Q w e n A c a d e m i c E f f o r t s O L M o : T r an s p ar e n c y b u t S c al e L i mi t s d a V i n c i - L L M S y s t e mat i c E x p l o r at i o n : 2 0 0 + a b l a t i o n s , L0 - L 9 m e t h o d o l o g y O p en n es s Figure 2: Evolution of pretraining researc h depth across institutional structures. The y-axis represents researc h depth from surface-lev el artifacts (API-only access) to fundamental scientific questions. The x- axis shows the temp oral progression from 2022 to 2026. Commercial entities (blue) p ossess computational resources but remain constrained to API-level access due to comp etitiv e pressures. Op en-w eight releases (green, e.g., Llama, Qwen) provide mo del artifacts but withhold design rationale and negative results. A cademic efforts (orange, e.g., OLMo) achiev e transparency and research freedom but face severe scale limitations—making systematic exploration with 200+ configurations structurally infeasible. The top tier remains largely unexplored, as it requires the rare alignment of large-scale computational resources with the research freedom to publish comprehensive findings. d aVinci-LLM (purple) o ccupies this in tersection, conducting the extensive ablations and systematic disclosures necessary to adv ance the science of pretraining. By releasing the complete decision-making logic alongside the model weigh ts, we bridge the structural gap betw een industrial scale and scientific transparency . 1 In tro duction The large language model ecosystem has evolv ed into a stratified landscap e c haracterized by v arying levels of transparency . At the most opaque tier lie closed-source commercial mo dels (GPT [ 1 , 2 ], Claude [ 3 ], Gemini [ 4 , 5 ]) accessible only through APIs. The in termediate tier comprises op en-w eight mo dels (LLaMA [ 6 ], Qw en [ 7 , 8 , 9 , 10 ], DeepSeek [ 11 ]) that release chec kp oin ts but withhold critical pretraining details—data compositions, mixture ratios, and training dynamics remain largely undisclosed. At the foundation are fully-op en efforts that release complete training sp ecifications. Despite this stratification, the field remains dominated by the first t wo paradigms. Y et as the A TOM (American T ruly Ope n Mo dels) Pro ject [ 12 ] emphasizes, open language mo dels are crucial for long-term comp etition by enabling the broader research communit y to pursue long-horizon transformativ e innov ations rather than only immediate deplo yment priorities. How ever, research atten tion has concentrated disprop ortionately on accessible post-training techniques [ 13 , 14 , 15 , 11 , 16 , 17 , 18 , 19 , 20 , 21 , 22 , 23 ], while the foundational pretraining phase, whic h determines a mo del’s capabilit y ceiling, remains critically under-explored. This im balance stems from structural constraints that create a fundamental parado x. Organizations with computational resources for large-scale pretraining op erate under commercial pressures that fav or rapid deplo ymen t ov er systematic exploration and inhibit transparent disclosure of training pro cesses. A cademic institutions p ossess researc h freedom but lack pretraining-scale infrastructure—ev en w ell-funded efforts like OLMo [ 24 , 25 ] face severe scale limitations that make large-scale systematic exploration structurally infeasible, while confronting p ersisten t challenges in sustaining b oth computational resources and k ey research p ersonnel. The consequence is stark: precisely when emerging evidence demonstrates that pretraining choices fundamentally shap e downstream capabilities [ 26 ], the communit y has limited abilit y to systematically inv estigate the principles gov erning how models acquire and organize knowledge during pretraining. Post-training techniques can refine and align model behavior, but struggle to fundamen tally ov ercome the capability foundations established during pretraining—research [ 27 , 28 ] sho ws that pretraining adv antages are amplified rather than comp ensated for in subsequent training 3 1. In tro duction SII-GAIR T able 1: T ransparency comparison across state-of-the-art LLMs. Unlike existing mo dels, daVinci pro vides the complete scien tific pro cess, enabling the systematic in vestigation of pretraining dynamics. Symbols: ✓ fully op en, ◎ patial disclosure or not released, p not disclosed. Dimension Llama 3 Qw en 3 Y uLan OLMo 3 daVinci Model Ar tif a cts Mo del W eigh ts ✓ ✓ ✓ ✓ ✓ T raining Co de p p ✓ ✓ ✓ T raining Logs p p p ✓ ✓ In termediate Checkpoints p p p ✓ ✓ D a t a Openness Data Comp osition ◎ ◎ ✓ ✓ ✓ Pro cessing Pipeline ◎ ◎ ✓ ✓ ✓ F ull T raining Data p p ◎ ✓ ✓ Pr o c essing Metho dolo gy p p p p ✓ (L0-9) Scientific Pr ocess Pretraining Ablations ✓ p ✓ ✓ ✓ Mixtur e R ationale p p p ◎ ✓ De cision T r ansp ar ency p p p ◎ ✓ Ne gative R esults p p p p ✓ phases. W e are p ositioned to address this gap by combining computational resources for billion-parameter training with the research freedom to inv estigate fundamental questions and publish comprehensive findings. T ow ards the science of pretraining, we adopt a fully-op en paradigm (as sho wn in T able 1 ) that treats op enness itself as scientific metho dology , releasing not only mo del weigh ts but complete training tra jectories, data sp ecifications, and ablation results do cumen ting b oth what w orks and what fails. Our w ork is structured around three pillars, eac h contributing to transparency and repro ducibilit y . Data (Section 2 ) Recognizing that data quality fundamen tally determines outcomes yet the field lac ks systematic metho dology for pro cessing decisions, we adopt the Data Darwinism framework [ 29 ], a principled L0-L9 taxonomy organizing op erations from basic filtering to con tent transformation to kno wledge synthesis. W e release our complete data pro cessing pip eline and the pro cessed datasets themselv es. Our data p ool spans general web text, co de, science, and QA domains, with each source explicitly annotated by its Darwin Level to systematically organize our pro cessing decisions and identify where further qualit y enhancement is feasible. T raining Recip e (Section 3 ) W e train a 3B-parameter mo del from random initialization across 8T tok ens using a tw o-stage curriculum: Stage 1 (6T tokens) establishes broad foundational capabilities through diverse web-scale corp ora with progressive data adjustment, while Stage 2 (2T tokens) shifts to w ard reasoning-intensiv e enhancement b y in tro ducing large-scale structured QA data alongside contin ued exp osure to co de and science domains. W e release all in termediate c hec kp oin ts at 5k-step in terv als, complete h yp erparameters, training logs, and the ev olution of data mixture comp ositions across stages, pro viding a complete dev elopmental tra jectory from initialization to final mode l. Exploration (Section 4 ) T ow ards the science of pretraining, we transform design decisions into system- atically v erifiable research questions. Through 200+ controlled ablations, we systematically inv estigate k ey questions spanning four thematic areas ab out pretraining: (1) Data Pro cessing Depth : How does hierarc hical data pro cessing systematically enhance mo del capabilities? (2) T raining Dynamics : How should data strategies and curriculum adapt during training? (3) Data Mixture Design : How to balance targeted enhancement with general capability preserv ation? (4) Ev aluation V alidit y : Which ev aluation proto cols reliably measure base mo del pretraining progress? Through these inv estigations, w e find that pro cessing depth systematically enhances capabilities, different domains exhibit distinct training dynamics requiring adaptive strategies, and mixture design critically determines the balance b et ween capabilit y enhancement and preserv ation. W e do cumen t b oth successful configurations and failed exp erimen ts, providing empirical evidence to inform each dimension of pretraining decisions. Our contributions span three dimensions: (1) Complete research materials : W e release mo del w eigh ts, intermediate c hec kp oin ts, and processed datasets, enabling researchers to analyze capability emergence, repro duce training pro cesses, and conduct extended inv estigations. (2) Question-driven pretraining science : By transforming key pretraining decisions into systematically verifiable research questions, we provide empirical understanding of data quality , training dynamics, and mixture strategies, offering reference p oin ts for researchers facing similar decisions. (3) T ransferable metho dological 4 2. Data: What W e Used and How W e Pro cessed It SII-GAIR Figure 3: Mapping of our pretraining data sources onto the Data Darwinism L0–L9 taxonomy across differen t training stage. foundations : The Data Darwinism framework, systematic exploration metho ds, and complete do cumen- tation of successes and failures constitute reusable research infrastructure, enabling the communit y to build upon do cumen ted b oundary conditions and form accum ulative scien tific knowledge in pretraining. T o facilitate repro ducibilit y and supp ort the research communit y , we publicly release all datasets pro duced through our own pro cessing and synthesis pipelines, together with the complete curation to olkit comprising all prompts and pro cessing co de. W e further release all in termediate and final mo del c hec kp oin ts sav ed throughout training, training logs, ablation results, and our full ev aluation suite. W e hop e these releases can help the communit y b etter understand, repro duce, and build up on our w ork. 2 Data: What W e Used and Ho w W e Pro cessed It Data transparency remains one of the most underserved dimensions of op en pretraining researc h. While op en-w eight releases hav e made mo del chec kp oin ts accessible, the data decisions underlying those models, including what sources were selected and how they were pro cessed, remain largely opaque. W e address this directly: b ey ond releasing our complete training corpus, we do cumen t the pro cessing depth of every data source through the Data Darwinism framework (L0–L9) [ 29 ], making our curation decisions explicit and traceable. Our pretraining corpus is organized into four categories of General, Co de, Science, and QA, dra wn from a combination of existing op en-source datasets and data collected directly from public rep ositories, with each source annotated by its corresponding Darwin Level and further pro cessed where meaningful qualit y gains can be achiev ed. 2.1 Data Darwinism F ramew ork The quality of pretraining data is fundamen tally shap ed by ho w it has b een collected, filtered, and pro cessed. Y et the field curren tly lacks a systematic framew ork for categorizing and comparing these op erations, making it difficult to reason ab out quality differences across heterogeneous data sources. Data Darwinism was prop osed precisely to address this gap, organizing data pro cessing op erations into a principled ten-level taxonomy (L0–L9). W e adopt this framework to assess the pro cessing depth of ev ery data source in our training corpus—not only to understand where eac h dataset currently stands in the hierarc h y , but also to identify whether further processing is feasible and whether the p oten tial quality gains justify the additional in vestmen t. Underlying this hierarch y is a coherent evolutionary logic: data pro cessing b egins with the selection and preserv ation of existing conten t, progressiv ely mo ves tow ard active rewriting and enrichmen t, and ultimately reac hes the capacity to synthesize entirely new con ten t from scratch. In parallel, the agents driving these operations shift from hand-crafted deterministic rules, to light weigh t classification mo dels, to frontier large language mo dels capable of reasoning and generation. W e now describe eac h lev el in turn: 5 2.2 Data Pool SII-GAIR L0: Data A c quisition. At this foundational stage, ra w data is gathered from diverse sources including w eb cra wls, PDF rep ositories, co de platforms, and curated databases. The collected data exists in highly v ariable formats such as HTML, PDF, and binary files, and t ypically contains significant noise and duplication. The primary challenges at this lev el lie in achieving broad cov erage, maintaining data pro v enance, and managing large-scale storage infrastructure. L1: F ormat Normalization. At this stage, heterogeneous ra w data is conv erted into unified, training- ready text represen tations. F or do cumen t-based sources, k ey op erations include OCR pro cessing of scanned PDF s and HTML parsing to extract clean conten t. No conten t is filtered here; the goal is uniform pro cessabilit y while preserving structural fidelit y across sources. L2: Rule-b ase d Filtering. This is the first stage of quality control, where deterministic pattern-based rules are applied to remov e ob jectively identifiable problematic con tent: near-duplicates detected via MinHash LSH, excessively short or malformed text, non-target languages, and garbled text from enco ding errors. The approach requires no learned mo dels, runs efficiently on CPU infrastructure, and achiev es substan tial v olume reduction while remaining fully in terpretable. L3: Lightweight Mo del Filtering. Unlike L2, whic h op erates on surface patterns, this stage introduces seman tic-lev el quality assessment using pretrained light weigh t classifiers. T asks such as educational v alue scoring, domain iden tification, and do cumen t type classification enable more nuanced filtering decisions than rules alone can supp ort. Imp ortan tly , this remains a pure selection stage: do cumen ts are retained or discarded based on predicted qualit y , but their conten t is never mo dified. L4: Gener ative R efinement. This stage marks a qualitativ e shift from selection to active, mo del-driv en transformation. Medium-to-large generative mo dels are deplo yed to purify conten t by remo ving structural noise such as navigation elements, reference lists, OCR artifacts, and formatting defects, as well as repairing fragmen ted text, while strictly adhering to the original con tent. A critical constrain t is that this stage must act as a faithful refiner: no external knowledge may b e in tro duced, and the output must remain seman tically equiv alen t to the input. L5: Co gnitive Completion. At this stage, frontier LLMs enrich data by making implicit reasoning explicit. Research and tec hnical do cumen ts are t ypically written for exp ert audiences, characterized b y compressed logical steps, assumed background knowledge, and implicit deriv ations that create a learnabilit y gap for language mo dels. This stage bridges that gap through reasoning reconstruction, terminological explication, and p edagogical bridging, pro ducing conten t that retains full scientific fidelit y while substan tially lo wering the cognitiv e barrier for mo del in ternalization. L6–L9: Higher-Or der Synthesis. The upp er levels of the hierarc hy address increasingly ambitious forms of data generation. Contextual Completion (L6) expands do cumen ts by integrating external references and background knowledge to create self-contained artifacts. Environmen t Synthesis (L7) constructs executable environmen ts in which data ob jects can b e v alidated through actual execution. Ecosystem Syn thesis (L8) builds dynamic multi-agen t systems where diverse intelligen t entities in teract and generate emergen t data through sustained collaboration. W orld Synthesis (L9) represents the theoretical ap ex of the framework, aspiring to construct comprehensive sim ulated worlds as a source of essentially unlimited syn thetic training data. It is worth noting that these levels are not mutually exclusiv e one-time passes: any op eration at a given lev el can be applied m ultiple times, with different mo dels, prompts, or parameters, eac h targeting differen t asp ects of qualit y to ac hieve progressively deeper processing. F urthermore, the ordering of op erations need not strictly follow the level hierarc hy—for instance, a dataset may undergo L4 Generative Refinement b efore b eing sub jected to L3 mo del-based filtering, if such an ordering b etter suits the c haracteristics of the source data. Throughout this w ork, we annotate each data source with its corresp onding Darwin Lev el to mak e our curation decisions explicit and transparen t. F or a subset of sources, we further apply higher-level pro cessing op erations to actively improv e their quality . This allows us to reason systematically ab out the depth of processing across our entire corpus, and to identify where additional effort is most likely to yield meaningful gains. 2.2 Data P o ol W e curate our pretraining corpus from five ma jor categories: CC, Co de, Math, Science, and QA. F or eac h data source, we annotate its corresp onding Darwin Lev el to mak e our curation decisions explicit and transparen t. T able 2 summarizes the comp osition and scale of the full data p ool across training stages, and Figure 3 pro vides an ov erview of the Darwin Level assigned to each data source. 6 2.2 Data Pool SII-GAIR T able 2: Data p ool comp osition and tok en allo cation across training stages. Shaded category rows show eac h category’s total p ool size and the tok ens allo cated p er stage; data source rows indicate whether the source is used ( ✓ ) or not used (–) in eac h stage. Data Source Pool Size Level Stage 1 Stage 2 Stage 1-1 Stage 1-2 Stage 2-1 Stage 2-2 General 4.28T 2.73T (68.2%) 1.11T (55.42%) 100B (10%) 188.4B (18.84%) Nemotron-CC-v1 4.28T L3 ✓ ✓ ✓ ✓ Code 598B 381B (9.53%) 233B (11.66%) 300 (30%) 26.1B (2.61%) Self-Crawled GitHub 187B L3 ✓ ✓ ✓ ✓ Nemotron-Pretraining-Code-v1-non-synthetic 220B L3 ✓ ✓ ✓ ✓ Nemotron-Pretraining-Code-v1-synthetic-code 171B L5 ✓ ✓ ✓ ✓ T xT360-Stack-Exc hange 20B L2 ✓ ✓ ✓ ✓ Science 1.94T 891B (22.27%) 658B (32.92%) 300B (30%) 85.5B (8.85%) MegaMath-W eb 231B L3 ✓ ✓ – – MegaMath-W eb-Pro 13B L4 ✓ ✓ ✓ ✓ MegaMath Refined 176B L4 – – ✓ ✓ MegaMath-Synth-Code 5B L5 ✓ ✓ ✓ ✓ Nemotron-CC-Math-v1-3 81B L4 ✓ ✓ – – Nemotron-CC-Math-v1-4+ 52B L4 ✓ ✓ – – Nemotron-CC-Math-v1-4+-MIND 74B L5 ✓ ✓ ✓ ✓ Nemotron-CC-Math-v1-3 Refined 68B L4 – – ✓ ✓ Nemotron-CC-Math-v1-4+ Refined 47B L4 – – ✓ ✓ Darwin-Science-Book 251B L4 ✓ ✓ ✓ ✓ Darwin-Science-Paper 215B L4 ✓ ✓ ✓ ✓ Darwin-Science-Paper-GPT 290B L5 ✓ ✓ – – Darwin-Science-Paper-Qwen 440B L5 – – ✓ ✓ QA 734B 0 (0%) 0 (0%) 300B (30%) 700B (70%) Nemotron-CC-v1 Synthetic QA 492B L5 – – – – Nemotron-Pretraining-SFT-v1-Code 21B L5 – – ✓ ✓ Nemotron-Pretraining-SFT-v1-Math 138B L5 – – ✓ ✓ Nemotron-Pretraining-SFT-v1-General 12B L5 – – ✓ ✓ Llama-Nemotron-Post-T raining-Dataset-Co de 5B L5 – – ✓ ✓ Llama-Nemotron-Post-T raining-Dataset-Math-RS 10B L5 – – ✓ ✓ Llama-Nemotron-Post-T raining-Dataset-Science-RS 0.4B L5 – – ✓ ✓ MegaMath-QA-RS 9B L5 – – ✓ ✓ MegaScience-RS 1B L5 – – ✓ ✓ Darwin-Science-Book QA 46B L5 – – ✓ ✓ T otal ∼ 7.58T 4T 2T 1T 1T 2.2.1 General General w eb text forms the bac kb one of our pretraining corpus, pro viding broad co v erage across topics, writing styles, and kno wledge domains. Our general corpus is primarily drawn from Common Crawl, with qualit y filtering applied to balance co verage and data quality . Nemotron-CC-v1. W e adopt the non-synthetic p ortion of Nemotr on-CC-v1 [ 30 ] as our web-scale general corpus. Nemotr on-CC-v1 is built from 99 snapshots of Common Crawl and undergo es text extraction, English language filtering, and global deduplication, follo wed by an ensemble of classifiers com bining educational v alue and informativ eness signals that scores eac h do cumen t and groups them in to fiv e quality tiers based on downstream task p erformance—enabling precise con trol ov er the quality– div ersit y trade-off across training stages. This complete pro cessing pip eline places Nemotr on-CC-v1 at Darwin Lev el L3, con tributing approximately 4.28T tok ens to our training corpus. 2.2.2 Co de Co de data equips the mo del with structured, executable knowledge and exposes it to formal reasoning patterns grounde d in programming languages. Our co de corpus is assem bled from a com bination of self-cra wled GitHub rep ositories and existing op en-source co de datasets, spanning b oth real-world source co de and synthetically generated co ding examples. Self-Cra wled GitHub. W e directly crawled public GitHub rep ositories and applied a minim um threshold of 10 stars p er rep ository as an initial rule-based quality gate, ensuring that only rep ositories 7 2.2 Data Pool SII-GAIR with demonstrated communit y adoption are retained. The collected source files were then organized and passed through Op enCo der’s filtering pip eline [ 31 ], whic h remov es low-qualit y or non-informative co de files through light weigh t mo del-based assessment, bringing the dataset to Darwin Lev el L3. This pro cess yields appro ximately 187B tok ens. Nemotron-Pretraining-Co de-v1. W e incorp orate t wo complemen tary subsets from Nemotr on- Pr etr aining-Co de-v1 [ 32 ], after cross-deduplication with our self-crawled GitHub collection. • Nemotr on-Pr etr aining-Co de-v1-non-synthetic. This subset consists of real-w orld source co de collected from GitHub. Rep ositories undergo license-based filtering to retain only p ermissiv ely licensed co de, follo w ed b y b oth exact and fuzzy deduplication to address the p erv asive cross-rep ository redundancy c haracteristic of op en-source ecosystems. The Op enCo der filtering pip eline is then applied to remo ve files that are lo w-quality or detrimental for L LM pretraining, bringing this subset to Darwin Lev el L3 and yielding appro ximately 220B tokens. • Nemotr on-Pr etr aining-Co de-v1-synthetic-c o de. This subset is generated by prompting an LLM to pro duce question-answer pairs grounded in short co de snippets, where the mo del is asked to b oth form ulate and solv e co ding questions across 11 programming languages. The resulting natural language–co de interlea ved pairs are filtered p ost-ho c through language-sp ecific heuristics such as Python AST parsing, reac hing Darwin Level L5 and yielding approximately 171B tok ens. T xT360-Stack-Exc hange. W e incorp orate txt360-stack-exchange [ 33 ] as a source of technical comm u- nit y discourse. This dataset is compiled from the Stack Exchange netw ork, cov ering 364 sub-communities spanning programming, mathematics, science, and numerous other tec hnical domains. Raw data is ex- tracted from archiv ed XML dumps, where p osts and comments are parsed to reconstruct the full threaded discussion hierarc hy , preserving the collab orativ e reasoning pro cess characteristic of comm unit y-driv en kno wledge building. Rule-based cleaning and format normalization are applied to ensure consisten t structure, placing the dataset at Darwin Lev el L2 and contributing approximately 20B tok ens. 2.2.3 Science Scien tific kno wledge forms an important part of a well-rounded pretraining corpus, enric hing the mo del with structured, knowledge-dense conten t spanning a broad range of disciplines. Our scientific corpus is assem bled from a combination of existing op en-source datasets and do cumen ts collected directly from public rep ositories, with additional pro cessing applied to improv e quality where appropriate. MegaMath. W e incorporate three subsets from Me gaMath [ 34 ] as part of our mathematical pretraining corpus. MegaMath is curated from diverse math-fo cused sources via a t w o-stage, coarse-to-fine web extraction pipeline ov er 99 Common Cra wl snapshots, combined with math-related co de recall from Stac k-V2 and LLM-based syn thetic data generation. • Me gaMath-W eb. This subset consists of mathematical conten t extracted from Common Cra wl using a t wo-stage pip eline: an initial fast extraction pass with Resiliparse follow ed by high-fidelity re-extraction with trafilatura on math-optimized HTML, with fastT ext-based math filtering and MinHash LSH deduplication applied throughout. The result is filtered through a fastT ext classifier trained on LLM-annotated math-relev ance labels, reaching Darwin Lev el L3 and con tributing appro ximately 231B tok ens. • Me gaMath-W eb-Pr o. This subset is a high-quality subset of MegaMath-W eb produced by first applying the FineMath classifier with a dynamic educational-v alue threshold (score ≥ 4 for older snapshots; score ≥ 3 for recent ones) to select high-qualit y do cumen ts, follow ed by LLM-driven refinemen t using Llama-3.3-70B-Instruct to remov e noise and reorganize conten t into a logically structured, information-dense form while preserving the original length. This reaches Darwin Level L4 and con tributes approximately 13B tok ens. • Me gaMath-Synth-Co de. This subset consists of LLM-generated natural language–co de interlea ved pairs targeting mathematical reasoning, pro duced b y prompting LLMs to generate structured blo c ks of mathematical text, symbolic expressions, and executable Python code grounded in MegaMath-W eb do cumen ts, with syntax and runtime verification via AST filtering and execution chec ks. It reac hes Darwin Lev el L5 and con tributes approximately 5B tok ens. 8 2.2 Data Pool SII-GAIR MegaMath Refined. W e apply L4 Generative Refinement to Me gaMath-W eb using Qwen3-235B- A22B-Instruct [ 9 ], following the same prompt design as MegaMath-W eb-Pro. The refinement strategy prompts the mo del to extract k ey facts and concepts, remov e noisy or irrelev ant conten t, and reorganize the material in to a logically structured, information-dense form while preserving the original length (see App endix C for the full prompt). The refined v ersion of MegaMath-W eb reaches Darwin Level L4 and con tributes appro ximately 176B tok ens. Nemotron-CC-Math-v1. W e incorp orate three subsets from Nemotr on-CC-Math-v1 [ 35 ], a high- qualit y mathematical corpus constructed from 98 Common Cra wl snapshots (2014–2024) spanning ov er 980,000 unique domains. Its pipeline identifies math-relev ant pages b y aggregating URL lists from existing op en math datasets, renders HTML via the Lynx text-based browser, applies a Phi-4-based clean up pass to remov e b oilerplate and normalize heterogeneous mathematical representations into unified L A T E X format, and then uses the FineMath classifierto score each do cumen t on a 1–5 scale for quality filtering, follo w ed b y fuzzy deduplication and benchmark decon tamination. • Nemotr on-CC-Math-v1-3. This subset retains do cumen ts with FineMath classifier scores of 3. The Phi-4-based cleanup pass applied during the original pip eline constitutes an L4 Generativ e Refinemen t op eration, bringing this subset to Darwin Level L4 and contributing approximately 81B tokens. • Nemotr on-CC-Math-v1-4+. This subset retains only the highest-quality do cumen ts with FineMath classifier scores of 4–5. As with Nemotron-CC-Math-v1-3, the Phi-4-based clean up pass places this subset at Darwin Lev el L4, contributing appro ximately 52B tokens. • Nemotr on-CC-Math-v1-4+-MIND. This subset is obtained by applying the MIND framew ork [ 36 ] to Nemotr on-CC-Math-v1-4+ , conv erting each mathematical do cumen t into structured multi-turn dia- logues via diverse conv ersational prompt templates (e.g., T eacher-Studen t, Problem-Solving, Debate) that reconstruct implicit reasoning steps and lo wer the cognitive barrier for mo del internalization, while strictly preserving the original conten t without introducing external knowledge. It reaches Darwin Lev el L5 and con tributes approximately 74B tok ens. Nemotron-CC-Math-v1 Refined. Building on the L4 Generative Refinement already applied during the original dataset construction, we apply a second round of L4 refinement to Nemotr on-CC-Math-v1-3 and Nemotr on-CC-Math-v1-4+ using the stronger Qwen3-235B-A22B-Instruct [ 9 ], with a more targeted prompt that instructs the mo del to extract key facts and concepts, remo v e noisy or irrelev ant conten t, and reorganize the material into a logically structured, information-dense form while preserving the original length (see Appendix C for the full prompt). This reflects our broader treatmen t of Darwin Level op erations as iterative rather than one-time passes. • Nemotr on-CC-Math-v1-3 R efine d. The refined version of Nemotron-CC-Math-v1-3, reac hing Darwin Lev el L4 and con tributing approximately 68B tok ens. • Nemotr on-CC-Math-v1-4+ R efine d. The refined version of Nemotron-CC-Math-v1-4+, reaching Darwin Lev el L4 and con tributing approximately 47B tok ens. Darwin-Science. W e construct Darwin-Scienc e as our primary scien tific corpus, built from raw PDF s of scien tific b ooks and academic pap ers sourced from publicly accessible online rep ositories and op en-source datasets including PubMed and arXiv. Both sources share a common L0–L3 pro cessing pip eline. Ra w PDF s are first conv erted in to machine-readable text using olmOCR-7B-0225-preview [ 37 ], a vision-language mo del optimized for do cumen t text extraction. The resulting text then undergoes deduplication via MinHash LSH, follow ed by rule-based filtering that discards files b elo w 8kb, do cumen ts with excessive garbled characters resulting from OCR errors, and non-English con ten t. All retained do cumen ts are subsequen tly annotated using EAI-Distill-0.5B [ 38 ], a light weigh t classifier that p erforms educational v alue scoring and field-of-discipline classification across nine ma jor domains; do cumen ts with no educational v alue are filtered out. Finally , all documents are classified in to bo ok and pap er categories—using metadata where a v ailable, and Qwen2.5-7B-Instruct [ 8 ] for ambiguous cases—as the tw o document types exhibit distinct learnabilit y c haracteristics that warran t different downstream processing. • Darwin-Scienc e-Bo ok . Scientific b ooks are pro cessed through L4 Generative Refinement using GPT-OSS-120B [ 39 ], which remov es structural noise suc h as table of conten ts entries, reference lists, headers and footers, and OCR artifacts, while repairing formatting defects such as fragmented text and damaged formulas without altering the underlying conten t. The detailed prompt is pro vided in App endix C . This pro cess yields approximately 251 tokens. 9 2.2 Data Pool SII-GAIR • Darwin-Scienc e-Pap er . The same L4 Generativ e Refinement pip eline is applied to academic pap ers using GPT-OSS-120B, yielding appro ximately 215 tokens. These L4-pro cessed pap ers serve as the foundation for further L5 processing. • Darwin-Scienc e-Pap er-GPT . Building on the L4-pro cessed pap ers, we apply L5 Cognitive Completion using GPT-OSS-120B to bridge the learnability gap inherent in expert-oriented scien tific writing. The augmen tation targets three dimensions: expanding implicit logical leaps in to explicit step-by-step deriv ations (Reasoning Reconstruction), contextualizing domain-sp ecific terminology within the narrativ e flow rather than assuming prior mastery (T erminological Explication), and grounding abstract concepts in concrete analogies and established knowledge (Pedagogical Bridging). The detailed prompt is pro vided in App endix C . This yields appro ximately 290B tokens. • Darwin-Scienc e-Pap er-Qwen . W e also apply L5 Cognitive Completion directly to the L4-pro cessed pap ers using Qwen3-235B-A22B-Instruct [ 9 ]. W e h yp othesize that a stronger mo del is b etter equipp ed to reconstruct implicit reasoning and pro duce richer p edagogical enric hment, potentially yielding greater learnabilit y gains. This yields approximately 440 tokens. 2.2.4 QA Question-answ er pairs serv e as a natural complement to ra w text pretraining data, and our QA data cov ers three broad domains: co de, general, and science. Sources are drawn from a mix of existing high-quality collections, rejection-sampled op en-source p ost-training datasets by Qwen3-32B in non-thinking mo de, and QA pairs syn thesized directly from scientifc documents. All subsets reach Darwin Level L5. T able 3: Domain cov erage of QA data sources. Each source is categorized into one of three domains: General, Co de, and Science (including Mathematics). Data Source General Co de Science Nemotron-CC-v1 Syn th etic QA (492B) ✓ Nemotron-Pretraining-SFT-v1-General (12B) ✓ Nemotron-Pretraining-SFT-v1-Co de (21B) ✓ Llama-Nemotron-P ost-T raining-Co de (5B) ✓ Nemotron-Pretraining-SFT-v1-Math (138B) ✓ Llama-Nemotron-P ost-T raining-Math-RS (10B) ✓ Llama-Nemotron-P ost-T raining-Science-RS (0.4B) ✓ MegaMath-QA-RS (9B) ✓ MegaScience-RS (1B) ✓ Darwin-Science-Bo ok QA (46B) ✓ Nemotron-Pretraining-SFT-v1. W e incorp orate Nemotr on-Pr etr aining-SFT-v1 [ 32 ]as a source of short-form sup ervised fine-tuning style pretraining data cov ering co de, math, and general knowledge domains. F or each subset, we retain only the short chain-of-though t p ortion of the data, discarding v erb ose reasoning traces. All subsets reac h Darwin Level L5. • Nemotr on-Pr etr aining-SFT-v1-Co de. This subset is syn thesized using the Genetic-Instruct frame- w ork [ 40 ], an evolutionary algorithm that b egins with a small set of seed co ding instructions and iterativ ely generates diverse, challenging instruction-co de pairs through tw o op erations: crosso ver, whic h prompts an LLM to pro duce new instructions from a set of seed examples, and m utation, whic h ev olves an existing instruction into a harder or more v aried one. A separate Co der-LLM generates corresp onding co de solutions, and a Judge-LLM filters outputs based on correctness and qualit y . This process yields a large-scale collection of co ding problem-solution pairs spanning multiple programming languages, reac hing Darwin Level L5 and con tributing approximately 21B tokens. • Nemotr on-Pr etr aining-SFT-v1-Math. This subset is synthesized follo wing Op enMathInstruct-2 [ 41 ], whic h uses a strong teacher mo del to generate multiple candidate solutions for a diverse set of seed math questions drawn from existing b enc hmarks suc h as GSM8K and MA TH. High-quality solutions are selected based on answer correctness, and question diversit y is explicitly optimized to maximize co verage across mathematical topics and difficulty levels. This reaches Darwin Level L5 and con tributes appro ximately 138B tokens. 10 2.2 Data Pool SII-GAIR • Nemotr on-Pr etr aining-SFT-v1-Gener al. This subset consists of MMLU-style question-answer pairs co v ering a broad range of kno wledge topics across different domains and difficulty levels, syn thesized b y prompting an LLM to generate both questions and answ ers grounded in curated source do cumen ts. This reac hes Darwin Lev el L5 and contributes appro ximately 12B tokens. Llama-Nemotron-P ost-T raining-Dataset. W e incorp orate m ultiple subsets of Llama-Nemotr on- Post-T r aining-Dataset [ 42 ], a large-scale p ost-training dataset in which prompts are sourced from public corp ora or synthetically generated, and resp onses are synthesized by a range of op en-source mo dels. W e use the co de subset directly without additional pro cessing, while for the science and math subsets we use the original prompts as input and apply rejection sampling using Qw en3-32B [ 9 ] in non-thinking mo de, retaining only resp onses that pass correctness verification against ground-truth answers. • Llama-Nemotr on-Post-T r aining-Dataset-Co de. This subset targets diverse programming tasks and problem-solving scenarios across multiple languages, w ith prompts sourced from public corpora or syn thetically generated, and resp onses filtered for qualit y and correctness during the original dataset construction. It reaches Darwin Level L5 and contributes appro ximately 5B tokens. • Llama-Nemotr on-Post-T r aining-Dataset-Scienc e-RS. This subset is obtained by applying rejection sampling to the science subset. The science subset comprises op en-ended and m ultiple-choice questions spanning academic scientific domains including physics, biology , and chemistry . The questions are drawn from t wo sources: question-answ er pairs extracted from StackOv erflow, and syn thetically generated MCQs conditioned on topic, subtopic, and difficulty level using Qwen2.5 mo dels following the Op enMathInstruct-2 augmentation pip eline. It reaches Darwin Level L5 and con tributes appro ximately 0.4B tok ens. • Llama-Nemotr on-Post-T r aining-Dataset-Math-RS. This subset is obtained by applying rejection sampling to the science subset. The subset comprises mathematical reasoning problems spanning comp etition-lev el and general math domains, with resp onses syn thesized by frontier op en-source mo dels. It reac hes Darwin Level L5 and contributes appro ximately 10B tokens. MegaMath-QA-RS. W e apply rejection sampling to Me gaMath-QA [ 34 ], the synthetic QA subset of MegaMath, in which question-answer pairs are extracted from mathematical web do cumen ts and refined to make intermediate reasoning steps explicit using an ELI5-st yle prompting strategy . R W e apply rejection sampling using Qwen3-32B [ 9 ] in non-thinking mo de, retaining only resp onses whose final answ ers are v erifiably correct against ground-truth answ ers, yielding approximately 9B tokens at Darwin Lev el L5. MegaScience-RS. W e apply rejection sampling to Me gaScienc e [ 43 ], a p ost-training dataset cov ering scien tific reasoning across multiple STEM disciplines, w ith questions drawn from textbo oks and curated scien tific sources. W e apply rejection sampling using Qwen3-32B [ 9 ] in non-thinking mo de, retaining resp onses that meet correctness criteria, yielding approximately 1B tokens at Darwin Level L5. Darwin-Science-Bo ok QA. W e generate knowledge-grounded QA pairs directly from Darwin-Scienc e Bo ok using Qw en3-235B-A22B-Instruct [ 9 ]. T o accoun t for the distinct knowledge structures and exp ository styles across scientific disciplines, w e design domain-sp ecific prompts for each of the b o ok domains cov ered in Darwin-Science, rather than applying a single universal prompt. The mo del is prompted to iden tify k ey kno wledge p oin ts from each source passage and formulate question-answer pairs that are strictly grounded in the original text, with the constraint that every answer must b e directly v erifiable against its source passage. T o further enhance learnabilit y , the mo del is also prompted to supply in termediate reasoning steps that bridge the question to the answer, making implicit deriv ations explicit. The full set of domain-sp ecific prompts is provided in The detailed prompt is pro vided in App endix C .. This dataset reac hes Darwin Level L5, con tributing approximately 46B tokens. Nemotron-CC-v1 Synthetic QA. W e incorp orate the Diverse QA subset of Nemotr on-CC-v1 , which is generated from high-quality do cumen ts selected from Common Crawl. In this pip eline, an LLM is prompted to generate question-answer pairs in m ultiple forms, including yes/no questions, op en-ended questions, and multiple-c hoice questions,that prob e factual information in the source text at different cognitiv e lev els. The model is required to pro vide clear and concise answ ers while preserving concrete details such as num b ers and sp ecific facts from the original do cumen t. This grounding in high-quality w eb text spanning div erse general-domain topics makes the subset a broad-cov erage complement to the domain-sp ecific QA sources describ ed ab o ve. This dataset reaches Darwin Level L5 and contributes appro ximately 492B tok ens. 11 3. T raining Recip e: How W e T rained It SII-GAIR T able 4: Architectural sp ecification of daVinci-LLM . P arameters ∼ 3.09B MLP in termediate size 11008 La y ers) 36 A ctiv ation function SwiGLU Hidden size 2048 P ositional enco ding RoPE (base θ = 10000 ) A tten tion heads 16 Max p osition em b eddings 4096 KV heads (GQA) 2 Normalization RMSNorm ( ϵ = 10 − 6 ) Head dimension 128 T okenizer Qw en2 tok enizer V o cab size 151936 Precision bfloat16 3 T raining Recip e: Ho w W e T rained It In this section, w e pro vide a comprehensive disclosure of the pretraining process for daVinci-LLM, focusing on the tec hnical execution and metho dological transparency that define our approac h. Mo ving beyond the industry standard of releasing only final chec kp oin ts, we adopt a fully-op en paradigm that do cuments the mo del’s complete developmen tal tra jectory from random initialization, ensuring that ev ery design choice is traceable and repro ducible. The follo wing subsections detail our ev aluation proto cols, the m ulti-stage adaptiv e curriculum, and the systematic data orchestration strategies that shap e the model’s capabilities. This documentation bridges the gap b et ween opaque commercial technical rep orts and scale-limited academic pap ers, providing a transparent framew ork for the communit y to replicate our results and adapt the underlying tec hnical workflo ws of pretraining. 3.1 Mo del Architecture W e adopt the Qwen2-based [ 7 ] transformer architecture for daVinci-LLM , training a 3B-parameter mo del from random initialization using a standard deco der-only causal language mo deling ob jectiv e. The arc hitecture emplo ys several mo dern design choices that balance computational efficiency with represen tational capacit y: Group ed-Query Atten tion (GQA) [ 44 ] with 2 key-v alue heads shared across 16 query heads to reduce memory bandwidth while preserving attention expressiv eness; SwiGLU [ 45 ] activ ation in the MLP la yers with an expansion ratio of ∼ 5.4 × (11008/2048) for enhanced nonlinearit y; RMSNorm [ 46 ] for efficient pre-normalization; and Rotary Position Embeddings (RoPE) [ 47 ] with base frequency 10000 for length generalization. W e train with a sequence length of 4096 tokens. The model utilizes a v o cabulary of 151936 tok ens from the Qw en2 tokenizer. T able 4 pro vides the complete architectural sp ecification. The configuration follows the Qwen2 design philosoph y of prioritizing depth (36 lay ers) with mo derate hidden dimensions (2048), a strategy that has pro v en effectiv e for balancing parameter count, training throughput, and downstream task p erformance in the 3B scale regime. 3.2 Ev aluation Proto col Ev aluation philosophy . T raditional pretraining ev aluations fo cus solely on final p erformance. W e adopt a more comprehensive approach aligned with our question-driv en metho dology: (1) T racking capabilit y emergence: W e ev aluate at 5k-step in terv als to understand when different dimensions saturate. (2) Benchmark stability analysis: W e systematically inv estigate whic h b enc hmarks remain stable indicators v ersus which collapse under certain training configurations (Section 4.4 ). (3) Multi-domain cov erage: Our 19 b enc hmarks span general kno wledge, co de, and science to capture synergy effects and trade-offs. W e conduct comprehensive ev aluation of our pretrained chec kp oin ts across diverse b enc hmarks to assess general knowledge, reasoning, code generation, and mathematical problem solving capabilities. This section describ es our ev aluation proto col, b enc hmark selection, and baseline comparisons. Benc hmarks and metrics. W e ev aluate on 19 tasks spanning three capability domains: General, Co de, and Science. The General cluster includes MMLU [ 48 ], MMLU-Pro [ 49 ], A GIEv al [ 50 ], HellaSw ag [ 51 ], T riviaQA [ 52 ], RA CE [ 53 ], WinoGrande [ 54 ], Op enBookQA [ 55 ], and PIQA [ 56 ]. The Co de cluster ev aluates Python co de synthesis through HumanEv al [ 57 ], Ev alPlus [ 58 ], and MBPP [ 59 ]. The Science cluster includes GSM8K [ 60 ], GSM-Plus [ 61 ], MA TH [ 62 ], GPQA [ 63 ], Sup erGPQA [ 64 ], MMLU-STEM, and MMLU-Pro-STEM. Detailed descriptions of all b enc hmarks are provided in App endix A . W e ev aluate using the lm-eval-harness framew ork (EleutherAI) [ 65 ]. Since the ev aluated mo dels are base c hec kp oin ts, we p erform inference under greedy deco ding to ensure consistency across exp erimen ts. W e adopt tw o complementary ev aluation strategies based on task c haracteristics. Perplexity-b ase d (PPL) ev aluation is applied to tasks fo cused on multiple-c hoice selection 12 3.3 T raining Metho dology SII-GAIR or likelihoo d estimation, where the model scores eac h candidate answer directly: PIQA (0-shot), MMLU (5-shot), OpenBo okQA (5-shot), GPQA-Main (5-shot), and MMLU-STEM (5-shot). Gener ative-b ase d ev aluation is applied to tasks requiring complex reasoning chains, co de generation, or Chain-of-Thought (CoT) outputs, where the mo del generates a free-form resp onse: MA TH (4-shot), MMLU-Pro (5-shot), Sup erGPQA (5-shot), MMLU-Pro-STEM (5-shot), GSM8K (8-shot), HumanEv al (0-shot), Ev alPlus (0-shot), MBPP (3-shot), AGIEv al (0-shot), HellaSwag (0-shot), T riviaQA (5-shot), RA CE (0-shot), WinoGrande (0-shot), and GSM-Plus (5-shot). Baselines. W e compare against six op en base mo dels spanning similar parameter scales: • OLMo-3 7B (7B) [ 25 ]: Our primary reference baseline, representativ e mo del trained b y academic institutions. • OLMo-2 7B (7B) [ 24 ]: Previous generation OLMo model. • Qwen-3.5-4B (4B) [ 10 ]: The latest mo del baseline from Alibaba’s Qwen family . • Qwen-3-4B (4B) [ 9 ]: Strong baseline from Alibaba’s Qw en family . • Qwen-2.5-3B (3B) [ 8 ]: Closest parameter-matched baseline (same architecture family as our mo del). • LLaMa-3.2-3B (3B) [ 6 ]: Meta’s LLaMa 3.2 series at matc hed scale. • Y ulan-Mini-2.4B (2.4B) [ 66 ]: Another mo del led b y academic institutions. These baselines pro vide b oth scale-matc hed comparisons (3–4B parameters) and capability-matc hed comparisons (7B models with stronger absolute p erformance). Our goal is to demonstrate that principled m ulti-stage pretraining can enable a 3B mo del to approach or exceed the performance of larger baselines through careful data mixture design and training stage orc hestration. T able 5: T raining hyperparameters of differen t training stages. Note that the Global Batch Size refers to the total num b er of sequences p er training step; the total num b er of tokens p er step is calculated as Global Batc h Size × Sequence Length. Stage 1 Stage 2 Stage 1-1 Stage 1-2 Stage 2-1 Stage 2-2 T raining T okens 4 T rillion 2 T rillion 1 T rillion 1 T rillion Global Batc h Size 1024 → 2048 → 4096 4096 4096 4096 Rotatory Base 10000 10000 10000 10000 Sequence Length 4096 4096 4096 4096 Precision bfloat16 bfloat16 bfloat16 bfloat16 W eight Decay 0.1 0.1 0.1 0.1 A dam W β 1 0.9 0.9 0.9 0.9 A dam W β 2 0.95 0.95 0.95 0.95 LR Strategy 2000 w armup + constan t (3e-4) cosine deca y (3e-4 → 3e-5) 2000 w armup + constan t (3e-5) constan t (3e-5) 3.3 T raining Metho dology Building upon the architectural sp ecifications and ev aluation framework previously defined, we present the systematic pretraining metho dology for daVinci-LLM . Moving b ey ond the view of pretraining as a monolithic sequence of token consumption, w e adopt a multi-stage, adaptiv e curriculum that ev olv es in tandem with the mo del’s maturing capabilities. Our training process is structured into tw o primary phases, shifting from expansiv e knowledge acquisition to reasoning-in tensive enhancement: • Stage 1 (General F oundation Pretraining) : Establishes broad foundational capabilities through 6T tok ens of div erse, w eb-scale corp ora. This phase is executed across t wo substages (Stage 1-1/1-2), utilizing progressive data adjustment to calibrate the mo del’s exposure to web text, co de, and scien tific con ten t. • Stage 2 (Reasoning Capability Enhancemen t) : Shifts the distribution tow ard reasoning-dense data through an additional 2T tok ens. By integrating structured QA, refined scientific conten t, and high-qualit y code, this stage amplifies reasoning capabilities, enabling our 3B-parameter mo del to matc h the 7B-scale OLMo-3. 13 3.3 T raining Metho dology SII-GAIR 0 1000 2000 3000 4000 5000 6000 Training T okens (B) 0 10 20 30 40 50 P erformance Score Stage 1-1 Stage 1-2 +34.73 +4.90 General Code Science Overall Figure 4: Progressive training results across Stage 1-1 and Stage 1-2, with chec kp oin ts ev aluated every 5000 steps. The vertical dashed line indicate the b oundary betw een tw o substages. The execution of these stages is not guided b y heuris tic con v en tions, but is principled and evidence- based, rooted in our extensive ablation studies (Section 4 ). Sp ecifically , our training recipe is informed b y three scientific pillars: (1) Data Pro cessing Depth (Section 4.1 ), utilizing the Data Darwinism taxonom y to systematically enhance data quality; (2) A daptive T raining Dynamics (Section 4.2 ), where stage transitions are informed by differential saturation rates across cognitive dimensions (general kno wledge plateaus early , while co de and science sustain growth); and (3) Mixture Optimization (Section 4.3 ), balancing concentration for targeted enhancemen t with div ersit y for capability preserv ation. 3.3.1 Stage 1: General F oundation Pretraining Stage 1 trains the mo del from random initialization across 6T tokens to establish broad foundational capabilities in natural language understanding, logical reasoning, and cross-domain kno wledge syn thesis. Multi-substage T raining Recip e. W e decomp ose Stage 1 into tw o consecutiv e sub-phases: Stage 1-1 and Stage 1-2, consuming appro ximately 6 trillion tokens in total. This phased approach enables efficien t scaling of batch size and fine-grained control ov er capability dev elopment through data mixture adjustmen ts. The detailed hyperparameters for each substage are provided in T able 5 and data mixtures are pro vided in T able 2 . • Stage 1-1 (F oundation Building, 4T tokens) : This stage prioritizes stability . W e employ a progressiv e global batch size (GBS) scaling strategy , starting at 1,024 for 70k steps, increasing to 2,048 for 40k steps, and finally reaching 4,096. The learning rate is held constant at 3e-4 after a 2,000-step linear w armup. The data mixture is dominated b y Common Cra wl (68.2%) to establish broad linguistic fluency . • Stage 1-2 (Reasoning Enhancemen t, 2T tokens) : Maintains GBS at 4,096 while transitioning to cosine learning rate decay (3e-4 → 3e-5). T o strengthen reasoning capabilities, we rebalance the mixture b y reducing Common Cra wl to 55.4% and increasing Co de (+2.1%) and Science (+10.6%) prop ortions, introducing denser logical and symbolic structures. T raining Stabilit y and Conv ergence. Figure 4 illustrates the training dynamics for a represen tative p ortion of Stage 1, highlighting the ov erall optimization stability . The training loss (Figure 5a ) demon- strates smo oth and consistent conv ergence, reflecting predictable resp onses to adjustments in batc h size and learning rate schedules. Notably , the gradient norm (Figure 5b ) remained stable throughout the illustrated steps, whic h is consisten t with the b eha vior observed throughout the en tire pretraining pro cess. No significan t gradient spikes or loss divergences w ere encountered during the run, enabling contin uous training without the need for man ual interv entions or restarts. T raining T ra jectories. Figure 4 trac ks capability evolution across Stage 1’s 6T-token training tra jec- tory , with chec kp oin ts ev aluated every 5k steps across all 19 b enc hmarks. General knowledge b enc hmarks plateau rapidly within the first 1T tokens, while co de and science b enc hmarks sustain consistent growth 14 3.3 T raining Metho dology SII-GAIR 0 50k 100k 150k 200k 250k 300k T raining Steps 2.0 2.2 2.4 2.6 2.8 3.0 L oss T raining Loss (a) 0 50k 100k 150k 200k 250k 300k T raining Steps 0 1 2 3 4 5 6 7 Gradient Nor m T raining Gradient Norm (b) Figure 5: Stage 1 T raining dynamics for the first 300k steps: (a) training loss curve demonstrating consisten t conv ergence, and (b) gradient norm curv e tracking optimization stability across the initial training phase. throughout training, with notable acceleration during Stage 1-2 follo wing the reasoning-heavy mixture adjustmen t. This differen tial saturation pattern,where general capabilities stabilize early while reasoning capabilities require extended training,motiv ated our multi-substage design with progressive data adjust- men t. Stage 1 concludes with an o v erall a verage of 39.58, establishing a solid foundation for Stage 2’s reasoning enhancemen t. 3.3.2 Stage-2: Reasoning Capability Enhancemen t Building up on the solid general language foundation established in Stage 1, Stage 2 is dedicated to transforming the mo del’s general capabilities into high-order reasoning proficiency . Informed by the domain prop ortion adjustment b oundary observed in Section 4.2 , we recognized that merely reallo cating ra w text prop ortions was no longer sufficient to sustain contin uous growth in reasoning capabilities. Consequen tly , Stage 2 shifts from broad linguistic modeling to structured logic acquisition by incorp orating large-scale, high-densit y QA data and adopting a progressive curriculum learning strategy consisting of t w o distinct substages totaling 2T tok ens. Multi-substage T raining Recip e. The training pro cess is gov erned by a strategy of consolidating the foundation through balance b efore targeted intensification, with detailed hyperparameters and data mixtures across substages pro vided in T able 5 and T able 2 . • Stage 2-1 : Balanced F oundation Building (1T tokens): T o prev ent o verfitting or domain collapse when in tro duced to high-intensit y reasoning data, w e designed a balanced mixture consisting of structured QA, co de data, and L4/L5-pro cessed scientific data (30% eac h). This allo cation, supplemented by 10% high-qualit y w eb text, ensures that each reasoning domain is sufficiently represented while preserving the mo del’s general knowledge comp etence. • Stage 2-2 : QA-Intensiv e Enhancement (1T tok ens): Building on the balanced representation established in Stage 2-1, we further increased the concen tration of QA data to 70% in the final 1T tokens. This in tensification strategy aims to leverage the stable representation base formed in the previous substage to amplify logical reasoning and scien tific problem-solving through high-density sup ervisory signals. T raining T ra jectories. Stage 2 tra jectories demonstrate highly efficient capability gains, particularly during the transition from general foundations to sp ecialized reasoning. As shown in Figure 6 , en tering the Stage 2-1 prop elled the ov erall a v erage from 39.58 at the Stage 1 endpoint to 48.60 within just 1T tokens. This efficiency stems from increased pro cessing depth under the Data Darwinism framework: by utilizing L4-lev el Generative Refinement and L5-level Cognitiv e Completion, the mo del internalizes structured 15 3.4 Final Results SII-GAIR 0 250 500 750 1000 1250 1500 1750 2000 Training T okens (B) 30 35 40 45 50 55 P erformance Score Stage 1 Baseline Stage 2-1 Stage 2-2 +8.97 +2.43 General Code Science Overall Figure 6: Progressive training results across Stage 2-1 and Stage 2-2, with chec kp oin ts ev aluated every 5000 steps. The vertical dashed line indicate the b oundary betw een tw o substages. logical chains instead of redundant narrativ es. Consequen tly , our 3B mo del achiev ed an outstanding 62.8 on the MA TH b enc hmark, drastically exceeding its Stage 1 p erformance of 22.0. These dynamics also highlight a clear stage dep endency in tok en efficiency . T ransitioning to 70% QA-in tensiv e training in Stage 2-2 did not trigger catastrophic forgetting of general capabilities. Instead, this delib erate data mixture adjustment enabled a second acceleration in scientific reasoning, culminating in a p eak ov erall score of 51.72. This tra jectory provides empirical evidence that in later pretraining phases, adv ancing data pro cessing depth serves as a more economical scaling mechanism than simply increasing ra w data volume. A more systematic in v estigation of these training dynamics, including domain-sp ecific saturation patterns, the transition from domain adjustment to structured QA, and the resulting adaptiv e strategies, is presen ted in Section 4.2 and Section 4.3 . 3.4 Final Results T able 6 presents the comprehensive ev aluation results of daVinci-3B compared to baseline mo dels across all 19 tasks. daVinci-3B achiev es 51.72 ov erall av erage, matching OLMo-3 7B despite having less than half the parameters (3B vs. 7B), and significantly outperforming parameter-matc hed baselines including LLaMa-3.2-3B and Y ulan-Mini-2.4B. P articularly notable is the mo del’s strong reasoning p erformance: MA TH exceeds the 7B-scale OLMo-3 b y ov er 23 points; code generation ac hieves 55.99 av erage (matching OLMo-3 7B’s 54.42); science reasoning reac hes 48.30 (exceeding OLMo-3 7B’s 45.98). Imp ortan tly , this reasoning capabilit y enhancement is ac hiev ed while main taining general kno wledge comp etence comparable to larger baselines, indicating no catastrophic forgetting during sp ecialized training. These results v alidate the effectiv eness of our systematic, evidence-based pretraining metho dology , informed b y three k ey findings: (1) Data pro cessing depth (Section 4.1 ) Adv ancing from L3 filtering to L4 refinemen t to L5 synthesis enables substan tial capability gains in reasoning-intensiv e domains, with qualit y enhancemen t out w eighing naiv e v olume scaling; (2) A daptive training dynamics (Section 4.2 ) Monitoring differen tial saturation rates across capabilities and progressiv ely adapting data comp osition (from domain adjustment to structured QA introduction) sustains growth b ey ond homogeneous data regime limits; (3) Data Mixture optimization (Section 4.3 ) Balancing aggressive reasoning-data concen tration with capability preserv ation through adaptiv e comp osition prev ents catastrophic forgetting while maximizing targeted enhancemen t. T ogether, these findings demonstrate that systematic, question-driven inv estigation of pretraining dynamics can substantially impro ve base mo del capabilities. Our work shows that careful examination of data quality hierarchies, capability-specific saturation patterns, and mixture trade-offs enables more effectiv e pretraining, suggesting significant headro om for base mo del improv ement through principled, scien tific exploration. 16 4. Exploration: Why W e T rained It This W ay SII-GAIR T able 6: Comprehensive ev aluation across diverse capabilit y b enc hmarks. d aVinci-LLM-3B is compared against state-of-the-art op en-w eigh t mo dels. F ul ly-op en Mo dels Op en-weight Mo dels Domain Benc hmark daVinci 3B OLMO-3 7B OLMO-2 7B Y ulan 2.4B LLaMa-3.2 3B Qw en-2.5 3B Qw en-3 4B Qw en-3.5 4B General MMLU 62.53 66.53 65.93 50.70 54.91 65.73 75.35 72.75 MMLU-Pro 43.50 35.70 28.40 23.90 24.50 39.00 54.10 53.50 A GIEv al 26.77 33.75 31.78 28.22 22.72 37.15 45.87 44.89 HellaSw ag 71.17 74.15 80.50 68.56 73.60 73.60 73.75 75.29 T riviaQA 49.90 55.45 68.01 27.64 55.22 51.20 47.44 49.80 RA CE 38.56 40.57 40.96 35.69 38.95 38.47 39.62 39.23 WinoGrande 66.77 69.61 74.59 66.69 69.22 68.59 70.17 71.19 Op enBookQA 40.20 41.80 47.60 43.00 43.00 43.80 43.20 46.60 PIQA 77.26 78.62 81.07 76.22 77.58 78.89 77.86 78.89 Avg Gener al 52.96 55.13 57.65 46.74 51.08 55.16 58.60 59.13 Co de HumanEv al 61.64 59.05 16.78 66.77 33.17 60.17 65.93 71.46 Ev alPlus 57.32 53.62 13.85 62.25 27.22 53.23 59.45 65.00 MBPP 49.00 50.60 23.20 52.00 36.80 55.00 67.80 51.40 Avg Co de 55.99 54.42 17.94 60.34 32.40 56.13 64.39 62.62 Science GSM8K 72.86 76.80 67.32 66.79 29.72 75.36 85.52 82.56 GSM-Plus 50.38 51.58 44.58 43.71 16.12 51.21 64.17 60.04 MA TH 62.80 39.60 17.80 29.40 9.00 37.20 50.40 48.00 GPQA-Main 32.37 37.05 30.80 29.91 29.46 31.47 38.17 41.07 Sup erGPQA 19.56 21.84 1.67 15.53 3.18 18.40 28.81 35.59 MMLU-STEM 53.41 60.20 53.63 44.12 47.64 61.91 75.36 72.09 MMLU-Pro-STEM 46.70 34.77 23.77 20.52 22.03 37.00 54.73 53.15 Avg Scienc e 48.30 45.98 34.22 35.71 22.45 44.65 56.74 56.07 Ov erall A verage 51.72 51.65 42.75 44.82 37.58 51.44 58.83 58.55 4 Exploration: Wh y W e T rained It This W a y While the prece ding sections detailed the final training recip e of daVinci-LLM , this section pro vides the systematic in v estigation b ehind those decisions. W e mov e b ey ond presenting a finalized configuration as a settled conv ention and instead adopt a question-driven approac h to do cumen t the mo del’s evolutionary path. By disclosing 200+ controlled ablations, we aim to elev ate pretraining from an intuition-led craft to an evidence-based discipline, providing a transparent record of not only what work ed, but how design c hoices were informed by rigorous empirical observ ation. This do cumen tation serves as an empirical substrate, offering a gran ular view in to the patterns of capabilit y developmen t and the strategic trade-offs encoun tered throughout the pretraining process. W e structure our exploration around three primary in vestigativ e themes: 1. Data Pro cessing Depth (Section 4.1 ): W e ev aluate ho w the hierarc hical progression of data pro cessing systematically enhances mo del capabilities, establishing pro cessing depth as a pivotal dimension for exploration alongside data v olume scaling. 2. T raining Dynamics and Adaptation (Section 4.2 ): W e analyze ho w distinct capability satura- tion patterns necessitate adaptive data strategies, examining the transition from domain-prop ortion adjustmen ts to structural format shifts as the effectiv eness of raw text diminishes. 3. In tensification and Preserv ation (Section 4.3 ): W e in vestigate the tension b et w een targeted capabilit y enhancemen t and the main tenance of general comp etence, identifying how comp ositional balance enables aggressiv e data intensification without triggering represen tational collapse. Our inv estigation concludes with an analysis of Ev aluation V alidit y (Section 4.4 ), demonstrating ho w ev aluation proto cols themselves can shap e our understanding of mo del quality . By providing this comprehensiv e disclosure, we offer the empirical evidence and decision-making logic b ehind our recip e, con tributing to a more evidence-based and systematic understanding of pretraining scienc e. 17 4.1 Data Pro cessing Depth: F rom Filtering to Synthesis SII-GAIR T able 7: Comparison of rule-based and mo del-based filtering approaches. Configuration HumanEv al Ev alPlus MBPP A vg Gen. A vg Co de A vg Sci. Ov erall Rule-Based Filtering (L2) 54.43 48.58 42.40 51.12 48.47 40.14 46.66 Mo del-Based Filtering (L3) 54.70 48.39 45.80 51.19 49.63 40.28 46.93 ∆ (L3 – L2) +0.27 -0.19 +3.40 +0.07 +1.16 +0.14 +0.27 4.1 Data Processing Depth: F rom Filtering to Syn thesis Section T akea w a y Hierarc hical data pro cessing, progressing from qualit y filtering to conten t refinemen t to cognitive syn thesis, enables systematic capability developmen t. Within the Darwin framew ork, L3 mo del-based filtering yields mo dest but consisten t gains, v alidating progression b ey ond rule-based approaches. L4 generativ e refinement delivers substantial improv ements for complex reasoning, demonstrating that conten t transformation outw eighs volume expansion. L5 cognitiv e completion enables targeted capabilit y steering through domain-aligned synthesis. These results establish pro cessing depth as a systematic optimization dimension, offering a principled alternative to naiv e scaling : hierarchical data pro cessing can substitute for m ulti-fold data v olume increases. While data quality’s imp ortance for reasoning capabilities is increasingly recognized, the field lac ks systematic understanding of how pr o c essing depth shap es effe ctiveness . Section 2.1 introduced the Data Darwinism L0-L9 taxonomy , c haracterizing op erations from basic filtering to active synthesis. Y et a critical question remains unansw ered: Do es data pr o c essing depth systematic al ly impr ove r e asoning c ap abilities, and what effe ctiveness p atterns vary acr oss the hier ar chy? Answ ering this determines when practitioners should inv est in adv anced pro cessing versus expanding data volume, and whether systematic qualit y enhancement can substitute for massive scale increases. W e conduct controlled ablations across three hierarchical levels, holding data volume and training compute constant to isolate pro cessing depth’s causal effect. L3 mo del-based filtering (Section 4.1.1 ) remo v es low-qualit y conten t via LLM-based classifiers, preserving existing material unchanged. L4 generativ e refinement (Section 4.1.2 ) employs frontier LLMs to transform con tent—extracting key concepts, remo ving noise, reorganizing structure—while maintaining semantic in tegrit y . L5 cognitive completion (Section 4.1.3 ) actively synthesizes new reasoning chains through domain-sp ecific QA generation, mo ving b ey ond refinement to targeted capability steering. Our experiments rev eal distinct effectiveness patterns: L3 provides consistent but mo dest impro v emen ts across tasks, with notable gains on foundational programming (+3.40 on MBPP); L4 delivers substantial gains on complex reasoning (+7.00 on MA TH), though effects remain task-specific; L5 enables domain-targeted steering, with synthetic QA exhibiting strong source-target alignmen t but limited cross-domain transfer. These findings establish a systematic path w a y from filtering to syn thesis for data-centric capabilit y improv ement. 4.1.1 Co de Data Filtering: L3 Mo del-Based Filtering T o ev aluate whether mo del-based filtering (L3) pro vides measurable improv ements o ver rule-based approac hes (L2), we compare their effectiveness on co de generation tasks. W e apply GPT-OSS-120B qualit y scoring following SeedCo der’s assessment framework, which iden tifies and remov es low-qualit y co de artifacts: configuration files with extensiv e hard-co ded data, data files dominated by constants, co de with minimal logic, and auto-generated conten t. W e train for 500B tok ens, comparing L3 mo del-based filtering against the L2 rule-based baseline. T able 7 sho ws that L3 mo del-based filtering provides consistent but mo dest improv ements across most metrics. The most notable gain appears on MBPP , while improv ements on HumanEv al and Ev alPlus remain minimal. This differential pattern, where foundational programming tasks b enefit more substan tially than adv anced algorithmic challenges, suggests that quality filtering’s impact dep ends on task complexity . One plausible in terpretation is that basic programming comp etence is more sensitiv e to training example clarity , as mo dels acquiring fundamental patterns b enefit from removing noisy artifacts lik e configuration b oilerplate. How ever, the mo dest o v erall magnitude indicates that adv ancing from L2 to L3 yields incremen tal rather than transformative gains. These results v alidate that model-based quality assessmen t (L3) provides measurable adv antages o ver pure rule-based approaches (L2), confirming the v alue of adv ancing pro cessing depth within the Darwin framew ork. How ever, the limited impro vemen ts, particularly on sophisticated co ding b enc hmarks, suggest 18 4.1 Data Pro cessing Depth: F rom Filtering to Synthesis SII-GAIR T able 8: Comparison of baseline and generative refinement approaches. Configuration GSM-8K GSM-Plus MA TH A vg Gen. A vg Co de A vg Sci. Overall Baseline 64.06 40.58 38.00 51.69 49.80 40.52 47.27 Generativ e Refined (L4) 65.43 42.38 45.00 51.40 50.15 42.25 47.83 ∆ (L4 – Baseline) +1.37 +1.80 +7.00 -0.29 +0.35 +1.73 +0.56 0 84 168 252 336 419 503 Training T okens (B) 40 45 50 55 CC-QA +5.06 0 84 168 252 336 419 503 Training T okens (B) 40 45 50 55 CodeQA +4.29 General Code Science Overall Figure 7: Effectiveness of CC-QA and Co deQA syn thetic data in Stage 2-2. that filtering alone may b e insufficient to unlo c k the full p oten tial of co de training data. More intensiv e pro cessing interv entions, such as generative refinement to improv e co de clarit y and do cumen tation, may b e necessary to achiev e breakthrough gains in co de capabilities. 4.1.2 Math Data Quality: L4 Generative Refinement Section 4.1.1 indicates that L3 filtering offers marginal returns, prompting an inv estigation into whether activ e conten t transformation (L4) can further enhance reasoni ng performance. T o test this, we compared L4-refined mathematical data against the original MegaMath and Nemotron-CC-Math baseline, holding data v olume constant at 500B tokens. W e utilize Qw en3-235B to perform generative refinement, which systematically prunes narrative noise, extracts core form ulas, and reorganizes fragmen ted steps in to logically structured pro ofs while strictly preserving semantic integrit y . As sho wn in T able 8 , L4 refinement yields substantial improv ements across all mathematical b enc hmarks, though the gains are markedly uneven. The MA TH b enc hmark ac hieved a significan t +7.00 increase, while the improv ement on GSM8K was relativ ely mo dest (+1.37). This divergence suggests that structural purification, sp ecifically the transition from messy exp osition to p edagogical logic, disprop ortionately b enefits complex, multi-step reasoning. While basic w ord problems in GSM8K follo w relativ ely simple and linear solution paths, the abstract problems in MA TH are highly sensitive to the clarit y of the underlying logical flo w. By stripping aw ay redundant exp osition and reinforcing the connection b et ween reasoning steps, L4 pro cessing effectively reduces the difficulty for mo dels to extract fundamen tal patterns from complex mathematical text, leading to a performance leap in adv anced reasoning tasks. 4.1.3 L5 Syn thetic QA: Cognitive Completion While L4 refinemen t reorganizes existing conten t, L5 cognitive completion in volv es the activ e synthesis of new reasoning c hains to bridge the gap betw een implicit information and explicit problem-solving steps. W e in vestigate L5 processing by incorporating syn thetic QA data from t wo domain-sp ecific sources: Co deQA, derived from curated rep ositories, and CC-QA, extracted from high-quality web text. Unlike previous levels that mo dify existing material, L5 synthesis allows generative mo dels to construct structured reasoning scaffolds that ma y b e absen t in ra w corp ora. The exp erimen tal results in Figure 7 reveal a strong pattern of domain-sp ecific steering: Co deQA substan tially enhances programming b enc hmarks, while CC-QA primarily strengthens science reasoning. This source-target alignment suggests that the impact of synthetic reasoning is largely go verned by its originating domain. F or instance, co de-domain QA syn thesizes algorithmic structures that directly b enefit programming but offer limited cross-domain transfer to unrelated areas like general knowledge or science. 19 4.2 T raining Dynamics: A daptiv e Data Strategies SII-GAIR 0 1000 2000 3000 4000 5000 6000 7000 Training T okens (B) 0 10 20 30 40 50 60 70 80 P erformance Score 49.8 Stg 1-1 Stg 1-2 Stg 1-3 General General A verage 0 1000 2000 3000 4000 5000 6000 7000 Training T okens (B) 0 5 10 15 20 25 30 35 40 34.6 Stg 1-1 Stg 1-2 Stg 1-3 Code Code A verage 0 1000 2000 3000 4000 5000 6000 7000 Training T okens (B) 0 10 20 30 40 50 29.4 Stg 1-1 Stg 1-2 Stg 1-3 Science Science A verage Figure 8: Stage 1 b enc hmark p erformance. Ligh t curves sho w individual benchmarks; dark curves sho w category a v erages for general kno wledge, co de, and science. T wo vertical dashed lines indicate the b oundaries b et ween substages 1-1, 1-2, and 1-3, resp ectiv ely . This limited generalization indicates that L5 synthesis acts as a high-precision to ol for capabilit y steering rather than a univ ersal p erformance b ooster. These findings establish that strategic syn thesis can b e as effective as massive data scaling. By generating data that mirrors specific reasoning structures, practitioners can delib erately guide mo del p erformance tow ard target domains. This p ositions L5 processing as a principled alternativ e to exhaustiv e data accum ulation, offering a more efficien t path to capability developmen t. 4.2 T raining Dynamics: A daptive Data Strategies Section T akea w a y Effectiv e pretraining requires stage-sp ecific data strategies guided by capabilit y dy- namics. Systematic con v ergence trac king rev eals that different capabilities exhibit v astly different saturation timescales, enabling adaptive in terven tions that reallo cate compute tow ard actively learning capabilities. How ev er, domain prop ortion adjustmen ts encoun ter fundamental limitations once standard corpus formats collectively approac h saturation, at which point, reallo cating among these data types no longer suffices. Stage 1’s diminishing returns from prop ortion adjustments motiv ated in tro ducing structured question-answ er data in Stage 2, which substan tially outp erforms con tin ued prop ortion optimization. These findings establish that no single data mixture or for- mat suffices across extended training : sustained capability developmen t demands monitoring con v ergence patterns and adapting b oth domain prop ortions and data formats accordingly . Section 4.1 established that adv ancing data pro cessing depth enables systematic qualit y improv ements. Ho w ev er, even with high-qualit y pro cessed data, ho w to comp ose them optimally remains a critical question. T raditional approaches apply uniform strategies with fixed data mixtures ov er predetermined tok en budgets, implicitly assuming all capability dimensions develop at similar timescales. Y et if general kno wledge saturates rapidly while reasoning capabilities require sustained training, maintaining static mixtures ma y w aste compute on conv erged dimensions while under-serving actively-learning ones. This motiv ates our central question: How should data c omp osition evolve as differ ent c ap abili- ties matur e at differ ent r ates? Sp ecifically , w e inv estigate tw o aspects: (1) Do different capability dimensions exhibit systematically different saturation patterns? W e in vestigate whether tracking domain- sp ecific conv ergence enables principled in terven tion timing and adaptive data comp osition adjustments. (2) What adaptation strategies work when capabilities div erge? W e examine whether domain prop ortion adjustmen t suffices, or whether fundamental data format shifts b ecome necessary as standard corpus formats collectiv ely approac h saturation. W e address these through systematic con vergence trac king across Stage 1 (6T tok ens) and Stage 2 (2T tok ens). Section 4.2.1 examines domain-sp ecific saturation dynamics within Stage 1, revealing differen tial con v ergence rates (general knowledge plateaus at 1T tokens; co de/science sustain growth through 4T tok ens) that motiv ate adaptive domain prop ortion adjustments and the b oundaries of such strategies. Section 4.2.2 inv estigates the transition from domain adjustment to structured QA introduction in Stage 2, establishing when prop ortion optimization suffices versus when data format shifts b ecome necessary . 4.2.1 Domain Proportion Adjustmen t Do different capability dimensions saturate at different rates, and can w e use this to guide adaptiv e training? W e in vestigate this through Stage 1’s training tra jectory (6T tokens), trac king capabilit y-sp ecific 20 4.2 T raining Dynamics: A daptiv e Data Strategies SII-GAIR 0 168 336 503 671 839 1007 Training T okens (B) 49.0 50.0 51.0 52.0 53.0 54.0 -0.15 +2.15 General Stage 1-3 Stage 2 0 168 336 503 671 839 1007 Training T okens (B) 30.0 35.0 40.0 45.0 50.0 55.0 +2.62 +20.34 Code 0 168 336 503 671 839 1007 Training T okens (B) 30.0 35.0 40.0 45.0 -0.24 +15.75 Science Figure 9: Performance comparison b et ween con tinued data domain adjustment (stage 1-3) and QA in tro duction (Stage 2). con v ergence patterns across general kno wledge, co de, and scien tific domains. W e examine whether domain prop ortion adjustmen ts, reallo cating compute from saturated to actively-learning capabilities, can sustain capabilit y gro wth, and where suc h strategies encounter fundamen tal limitations. Differen tial conv ergence motiv ates adaptive mixture adjustmen t. Figure 8 shows Stage 1’s 6T-tok en tra jectory , rev ealing distinct conv ergence patterns across data domains. General kno wledge b enc hmarks plateau rapidly within the first 1T tok ens, with minimal subsequen t impro vemen t. In con trast, reasoning-in tensiv e b enc hmarks, b oth co de and scientific domains, sustain consistent gro wth through the initial 4T tokens, though improv ement rates b egin to slow. Notably , b enc hmarks within each domain exhibit consisten t conv ergence b eha vior: all general knowledge tasks saturate early , while all reasoning tasks main tain growth tra jectories, confirming these patterns reflect domain-lev el characteristics rather than task-sp ecific idiosyncrasies. This differen tial saturation motiv ated Stage 1-2’s adaptive adjustment strategy at the 4T c heckpoint. With general knowledge approaching saturation while reasoning capabilities remained actively impro ving, w e reduced generic web data prop ortion and increased co de/science concentrations, complemented by transitioning to cosine learning rate decay . Figure 8 shows that this adjustmen t successfully amplified reasoning domain gains in Stage 1-2 (4-6T tokens): b oth co de and science b enc hmarks exhibit renew ed acceleration, while general knowledge maintains stable p erformance without degradation. These results v alidate adaptiv e mixture strategies that reallocate compute from saturated domains (general kno wledge) to w ard capabilities exhibiting sustained learning potential (code and science reasoning). Domain adjustment encoun ters saturation boundaries. Encouraged b y Stage 1-2’s success, we explored further domain prop ortion adjustments, referred to as Stage 1-3, in Stage 1’s later phase to sustain reasoning capability growth. As co de and science p erformance b egan to decelerate again near 6T tok ens, w e attempted additional increases in co de/science concentrations while further reducing generic w eb data. 1 Ho w ev er, figure 8 shows that these adjustmen ts yielded only marginal improv ements at Stage 1-3, with p erformance gains substan tially smaller than those achiev ed during Stage 1-2’s adjustment. This diminishing effectiveness reveals an inherent limitation: once standard pretraining corp ora (web, co de, science) collectively approaches saturation, reallo cating prop ortions among these textual formats cannot ov ercome the fundamental constraint. These observ ations suggest that sustaining growth requires in tro ducing new data formats, a transition we inv estigate in the following section. 4.2.2 F rom Domain A djustment to QA Introduction Section 4.2.1 demonstrated that domain prop ortion adjustments encounter diminishing returns as standard pretraining corpora approach saturation. T o ov ercome this limitation, we hypothesize that sustaining capabilit y growth requires shifting from ra w text to data with explicit reasoning structures. W e therefore in tro duce structured question-answer pairs in Stage 2. Unlike raw text, QA data pro vides inherent problem-solving scaffolds: questions define the reasoning target, while answers supply direct sup ervision signals for multi-step inference. This format is uniquely suited for reasoning-intensiv e domains, precisely the domains that Section 4.2.1 sho wed require extended training inv estment. Structured QA outp erforms domain adjustmen t alone. T o isolate the v alue of introducing QA data, we conducted a con trolled comparison. Starting from the Stage 1-2 chec kp oin t, we examined t w o con tinuation paths: (1) Stage 1-3, which further increases co de/science prop ortions without adding 1 Stage 1-3 configuration: CC 51.42%, Co de 13.64%, Math 13.58%, Science 21.36%, with constant learning rate 3e-5. 21 4.3 Data Mixture Design: Balancing and In tensifying SII-GAIR 0 200 400 600 800 1000 Training T okens (B) 30 40 50 60 70 80 P erformance Score 52.1 Stg 2-1 Stg 2-2 General General A verage 0 200 400 600 800 1000 Training T okens (B) 30 35 40 45 50 55 60 52.3 Stg 2-1 Stg 2-2 Code Code A verage 0 200 400 600 800 1000 Training T okens (B) 20 30 40 50 60 70 45.4 Stg 2-1 Stg 2-2 Science Science A verage Figure 10: Stage 2 b enc hmark p erformance. Light curves show individual b enc hmarks; dark curv es sho w category a verages for general knowledge, co de, and science. The vertical dashed lines indicate the b oundaries b et ween Substages 2-1, 2-2. QA (as describ ed in Section 4.2.1 ), v ersus (2) Stage 2, which introduces 30% QA. Figure 9 presents the p erformance tra jectories. Stage 2 substantially outp erforms Stage 1-3 across reasoning domains: co de and scientific b enc hmarks ac hieve significan tly higher p erformance with QA introduction compared to mere domain adjustment. While general kno wledge also exhibits a mo dest impro vemen t, the gains are disproportionately concentrated in reasoning-intensiv e capabilities. This v alidates that structured data formats, rather than simple prop ortion adjustments, are essential to o vercome the saturation of unstructured text regimes and unlock adv anced cognitive potential. A daptive Adjustmen t within Stage 2 sustains growth. Having established QA’s effectiveness, we examine Stage 2’s internal dynamics. Figure 10 reveals conv ergence patterns consistent with Stage 1’s hierarc h y: general knowledge benchmarks exhibit near-complete saturation throughout Stage 2, sho wing minimal v ariation. In contrast, the co de and scien tific reasoning domains ac hiev e substan tial p erformance gains during Stage 2. When improv ement rates for these domains b egin to decelerate tow ard the end of Stage 2-1, we implemen t further mixture adjustment in Stage 2-2, increasing QA concen tration to 70%. This successfully triggers renewed p erformance gro wth, demonstrating that adaptive mixture adjustment remains effectiv e across training stages, with detailed mixture design explored in Section 4.3 . Implemen tation details b ey ond mixture design. In addition to mixture adjustment, we examined t w o practical training decisions that could plausibly affect Stage 2 outcomes: the learning rate schedule in later substages and the masking policy for QA data. Empirically , cosine decay provides small but consisten t gains o ver a constant learning rate, whereas masking question tokens yields only marginal impro v emen ts when the QA data is already diverse and high qualit y . W e defer the full analysis to App endix B . 4.3 Data Mixture Design: Balancing and In tensifying Section T akea w a y Mixture optimization balances reasoning in tensification with global capability preser- v ation. Our results sho w that while high reasoning data concentrations are essential, in ternal balance b et ween domains is critical to preven t ov er-sp ecialization sacrificing broader comp etence. Similarly , structured QA intensification requires na vigating a stage-dep enden t tolerance: conserv a- tiv e ratios preserv e stability during foundational training, while progressive concentration can b e lev eraged once a balanced representational base is established. These findings demonstrate that concen tration and preserv ation are not mutually exclusive, as effectiv e mixture design ac hieves b oth through an adaptive comp osition that ev olves with training progress. Section 4.2 established that transitioning to structured reasoning formats is essential for surpassing the performance plateaus of unstructured text. How ever, the in tro duction of these data types raises a new c hallenge: the tension b et w een targeted intensification and capability preserv ation . While aggressiv e concentration of reasoning-intensiv e data is nece ssary to drive p erformance, it also risks triggering catastrophic trade-offs where gains in one domain come at the exp ense of others. This leads to a critical researc h question: How to manage the intensific ation of r e asoning data to maximize gains without c ompr omising the mo del’s over al l c ap ability br e adth? W e address this question through tw o ablation studies. Section 4.3.1 examines the internal composition of reasoning domains, documenting ho w an aggressive yet balanc ed allo cation b et ween co de and science 22 4.3 Data Mixture Design: Balancing and In tensifying SII-GAIR Eva lPl us Human Eva l GSM - 8K MMLU GPQA Mai n MA TH 55.50 C- 10 -S- 10 C- 10 -S- 30 C- 30 -S- 10 C- 30 -S - 30 C- 40 - S- 20 50.09 60.52 30.80 64.06 38.00 (a) 10% 30% 50% 70% 100% QA R atio (%) 25.0 30.0 35.0 40.0 45.0 50.0 55.0 P erformance Score 50.9 51.4 51.7 51.8 48.1 29.9 31.2 26.1 27.9 26.9 35.8 39.1 41.8 44.1 48.2 42.0 43.6 44.0 45.2 44.8 General Code Science Overall (b) Figure 11: Co de and science data ratio analysis. Notation: C-X-S-Y indicates X% code and Y% science. (a) Performance across co de and science prop ortions (QA fixed at 30%, remainder allo cated to CommonCra wl w eb data). (b) Data synergy effects across QA ratios in Stage 2-1. prev en ts o ver-specialization and yields more robust results than extreme domain-sp ecific concentrations. Section 4.3.2 inv estigates the progressiv e in tensification of structured QA data. W e demonstrate that the mo del’s tolerance for high-concentration sup ervision is stage-dep enden t: a conserv ative mixture is required to maintain stability during foundational training (Stage 2-1), whereas an intensified regime can b e successfully applied (Stage 2-2) once a balanced capability base has b een established. 4.3.1 Domain Balance: Co de and Science Comp osition Section 4.2.1 rev eals that different domains exhibit distinct conv ergence rates during pretraining. Building on this observ ation, we inv estigate the internal comp osition of reasoning-in tensiv e data (sp ecifically co de and science) when training join tly with QA. W e fix QA concentration at 30% and systematically v ary co de-science prop ortions: 10%-10%, 10%-30%, 30%-10%, 30%-30%, and 40%-20%, with the remainder allo cated to CommonCra wl web data. All configurations are trained for 500B tokens from the Stage 1 c hec kp oin t. W e ev aluate p erformance across general kno wledge, co de generation, and science reasoning, visualizing the results via radar plots (Figure 11a ). T w o critical patterns emerge from this ablation. First, reasoning-intensiv e intensification is essen tial for Stage 2 progress : configurations allo cating 60% to code and science (C-30-S-30 and C-40-S-20) substan tially outp erform low er concentrations. This v alidates that transitioning from Stage 1’s CC-dominated mixture to Stage 2’s reasoning-hea vy regime requires aggressive reallo cation tow ard sym b olic and logical domains. Second, within high-concen tration regimes, in ternal balance is critical for main taining ov erall capabilit y : C-30-S-30 ac hieves sup erior ov erall performance compared to the co de-hea vy C-40-S-20. This indicates that while intensification is necessary , extreme sp ecialization in a single domain can trigger trade-offs, whereas equal allocation b et ween co de and science maintains general comp etence while delivering comp etitiv e reasoning gains across all dimensions. These findings establish the design principle for Stage 2-1: aggressiv e reasoning-data concentration with in ternal balance preven ts under-resourcing of sp ecific reasoning domains while preserving general capabilities. The balanced configuration (30% QA, 30% co de, 30% science, 10% web text) forms the foundation for subsequen t QA intensification strategies examined in the next section. 4.3.2 QA Concen tration: Progressiv e Intensification Section 4.3.1 established balanced prop ortions within the reasoning domains. W e now in vestigate the concen tration of structured QA itself, revealing stage-dep enden t optimal ratios: conserv ativ e c hoices in Stage 2-1 prioritize stability , while higher concentrations in Stage 2-2 lev erage established foundations to safely amplify reasoning gains. Stage 2-1: Conserv ative QA c hoice prioritizes capability balance. W e conduct a systematic in v estigation in Stage 2-1, training configurations with 10% to 100% QA. As shown in Figure 11b , general kno wledge remains stable across mo derate concentrations but degrades sharply at 100% QA, indicating 23 4.4 Ev aluation V alidity: PPL-based vs. Generative-based SII-GAIR T able 9: Impact of QA data ratio on mo del p erformance in Stage 2-2. Configuration T raining T okens General Co de Science Ov erall QA-30% 84B 51.59 47.71 40.25 46.80 252B 51.66 46.79 40.03 46.61 419B 51.80 47.16 40.59 46.94 QA-50% 84B 51.72 49.86 41.60 47.70 252B 51.85 49.01 42.80 48.06 419B 51.83 49.89 43.42 48.43 QA-70% 84B 51.91 49.23 42.89 48.17 252B 51.69 50.99 45.04 49.13 419B 52.16 52.40 45.77 49.84 that exclusiv e structured exp osure cannot sustain broad linguistic comp etence. Notably , co de p erformance exhibits a non-monotonic b ehavior: impro ving initially but collapsing b ey ond the 30% threshold. In con trast, science reasoning impro ves monotonically . This divergence b et ween science and co de merits further inv estigation. W e hypothesize that this stems from the comp ositional imbalance of our QA corpus: our Stage 2-1 QA p ool is heavily weigh ted tow ard science (appro x. 80%) , while co de-related QA is relativ ely scarce (approx. 26B tok ens). At higher total QA concentrations, the insufficient div ersit y of co de samples may trigger premature ov er-fitting or representation collapse, whereas the abundant science data sustain growth. This suggests a critical requiremen t for scaling QA: p erformance is gov erned not just by the total ratio, but by the absolute div ersit y of the sup ervised signals in each domain. In our final Stage 2-1 recipe, w e select 30% QA to maintain balanced capabilities. Although 70% QA yields higher av erage p eak scores, the resulting co de degradation suggests that a conserv ative foundation-building phase is essen tial to preven t irreversible domain loss b efore further in tensification. Stage 2-2: F oundation enables aggressive QA intensification without collapse. Con tinuing from the Stage 2-1 chec kp oin t, we inv estigated higher QA concen trations in Stage 2-2 (30%, 50%, and 70%). In this phase, p erformance increases monotonically across all clusters, including co de. This con trasts sharply with Stage 2-1, where increasing QA b ey ond 30% triggered collapse. W e h yp othesize that Stage 2-1’s balanced training establishes a necessary foundation that enables the mo del to effectively in ternalize high-in tensit y sup ervision without capability loss. These findings v alidate a progressive mixture strategy: Stage 2-1 employs a conserv ative 30% QA ratio to build stability , while Stage 2-2 intensifies to 70% QA for targeted enhancement. This staged approach ac hiev es what static mixtures cannot by preserving broad competence while deliv ering significan t reasoning gains. The complete tra jectory demonstrates that no single mixture suffices: sustained developmen t requires adapting data comp osition across training stages. 4.4 Ev aluation V alidity: PPL-based vs. Generativ e-based T akea w a y Ev aluation design critically impacts conclusions drawn ab out base mo del pretraining: The choice b et ween PPL-based and generativ e ev aluation is not merely technical—these proto cols prob e different aspects of mo del capability , and mo dels with extensive QA pretraining can exhibit ranking reversals across them. Benchmark selection and ev aluation metho dology m ust therefore b e v alidated join tly against the intended use case. Previous sections focused on the tr aining side : ho w data mixture design, QA prop ortion, and data qualit y shape mo del b eha vior during contin ued pretraining. W e now turn to the evaluation side . Even when training settings are fixed, the conclusions we draw ab out mo del quality can v ary substantially dep ending on how the mo del is ev aluated. In particular, base mo dels are commonly assessed under tw o distinct proto cols: PPL-based ev aluation , which measures whether the mo del assigns higher lik eliho o d to the correct answer, and generative ev aluation , whic h requires the mo del to actively pro duce an answ er. These proto cols are often treated as interc hangeable, but they in fact prob e different asp ects of capability and can lead to different mo del rankings. Therefore, it is necessary to clarify what each ev aluation setting is actually measuring and whic h one b etter matc hes the intended use case. Figure 12 illustrates this difference on MMLU across three representativ e base mo dels. Under PPL-based ev aluation, OLMO-2-7B slightly outp erforms Qwen-2.5-3B; under generative ev aluation, the ranking 24 5. Conclusion SII-GAIR LLaMa-3.2-3B Qwen-2.5-3B OLMO -2-7B Model 45 50 55 60 65 70 MML U Score (%) 54.91 65.73 65.93 49.01 60.31 57.41 (a) MML U Performance Comparison F ew-shot PPL F ew-shot Generative (CoT) LLaMa-3.2-3B OLMO -2-7B Model 2 0 2 4 6 8 10 12 Performance Gap vs Qwen-2.5-3B (%) +10.82 -0.20 +11.30 +2.90 (b) Performance Gap Relative to Qwen-2.5-3B F ew-shot PPL F ew-shot Generative (CoT) Figure 12: MMLU p erformance comparison across ev aluation proto cols. P anel (a) sho ws absolute scores under PPL-based and generative (CoT) ev aluation. Panel (b) highligh ts the p erformance gap relative to Qw en-2.5-3B, demonstrating how models with extensive QA training exhibit amplified adv antages in generativ e settings. The gap b et ween OLMO-2-7B and Qw en-2.5-3B increases from -0.20% (PPL) to +2.90% (generativ e), a 3.10% swing that reverses the ranking. rev erses in Qw en-2.5-3B’s fa v or—a 3.10% swing. W e argue that this discrepancy arises b ecause the t w o proto cols place different demands on the mo del. PPL-based ev aluation is closer to latent kno wledge access : the mo del only needs to assign relatively higher probability to the correct candidate among presen ted options. By contrast, generative ev aluation requires the model to surface and organize kno wledge into an explicit answer , often under additional reasoning demands. In this sense, generativ e ev aluation is more sensitiv e not only to what the model knows, but also to whether it has learned to op erationalize that knowledge through answ er pro duction. This distinction helps explain why mo dels with heavier QA exp osure during pretraining tend to gain disprop ortionately under generative ev aluation. QA-style pretraining do es not merely inject factual con tent; it also trains the mo del in the b eha vioral format of mapping questions to explicit answ ers. As a result, tw o mo dels with similar underlying kno wledge ma y app ear muc h closer under PPL-based ev aluation, yet diverge substantially when ev aluated generativ ely . The ranking reversal b et w een OLMO-2-7B and Qw en-2.5-3B is a concrete example of this effect. F raming one protocol as inherently sup erior w ould therefore b e misleading. The appropriate choice dep ends on the deploymen t scenario. Applications requiring direct answer generation–such as chatbots or open-ended QA systems–are b etter matc hed by generative ev aluation, whereas applications that use language mo dels as scoring or ranking functions are better aligned with PPL-based ev aluation. More broadly , when comparing base mo dels, substan tial discrepancies across proto cols should not b e dismissed as noise: they often indicate meaningful differences in pretraining data comp osition, esp ecially QA exp osure, and should b e rep orted transparen tly . Ev aluating base mo dels under b oth protocols pro vides a more complete capabilit y profile and helps av oid proto col-induced ranking artifacts. 5 Conclusion W e ha v e presen ted daVinci-LLM , a systematic inv estigation of pretraining dynamics through controlled exp erimen tation and comprehensive transparency . Through the Data Darwinism framework and 200+ con trolled ablations, w e establish empirical understanding of data pro cessing depth, training dynamics, and mixture design, releasing complete pip elines and exploration results to the comm unit y . This work represen ts a step tow ard transparency , and transforming pretraining into rigorous scientific discipline requires comm unity-wide open collab oration. Only when systematic exploration b ecomes the norm and empirical kno wledge accumulates across organizations can pretraining adv ance from intuition-driv en practice to w ard gen uine scientific understanding. 25 References SII-GAIR References [1] Op enAI. Introducing gpt-5.2. https://openai.com/zh- Hans- CN/index/ introducing- gpt- 5- 2/ , Decem b er 2025. A ccessed: 2026-02-07. [2] Josh Ac hiam, Steven Adler, Sandhini Agarw al, Lama Ahmad, Ilge Akk ay a, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shy amal Anadk at, et al. Gpt-4 technical rep ort. arXiv pr eprint arXiv:2303.08774 , 2023. [3] An thropic. In tro ducing claude opus 4.6. https://www.anthropic.com/news/ claude- opus- 4- 6 , F ebruary 2026. Accessed: 2026-02-07. [4] Go ogle. A new era of intelligence with gemini 3. https://blog.google/ products- and- platforms/products/gemini/gemini- 3/ , Nov ember 2025. Accessed: 2026- 02-07. [5] Gheorghe Comanici, Eric Bieb er, Mik e Schaek ermann, Ice Pasupat, Nov een Sac hdev a, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Ev an Rosen, et al. Gemini 2.5: Pushing the frontier with adv anced reasoning, m ultimo dalit y , long con text, and next generation agentic capabilities. arXiv pr eprint arXiv:2507.06261 , 2025. [6] Abhiman yu Dub ey , Abhina v Jauhri, Abhina v Pandey , Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Math ur, Alan Schelten, Amy Y ang, Angela F an, et al. The llama 3 herd of mo dels. arXiv e-prints , pages arXiv–2407, 2024. [7] An Y ang, Baosong Y ang, Bin yuan Hui, Bo Zheng, Bo wen Y u, Chang Zhou, Chengpeng Li, Chengyuan Li, Da yiheng Liu, F ei Huang, Guan ting Dong, Haoran W ei, Huan Lin, Jialong T ang, Jialin W ang, Jian Y ang, Jianhong T u, Jianw ei Zhang, Jianxin Ma, Jin Xu, Jingren Zhou, Jinze Bai, Jinzheng He, Jun y ang Lin, Kai Dang, Keming Lu, Keqin Chen, Kexin Y ang, Mei Li, Mingfeng Xue, Na Ni, Pei Zhang, P eng W ang, Ru Peng, Rui Men, Ruize Gao, Runji Lin, Shijie W ang, Shuai Bai, Sinan T an, Tianhang Zhu, Tianhao Li, Tianyu Liu, W enbin Ge, Xiao dong Deng, Xiaohuan Zhou, Xingzhang Ren, Xinyu Zhang, Xipin W ei, Xuanc heng Ren, Y ang F an, Y ang Y ao, Yic hang Zhang, Y u W an, Y unfei Ch u, Y uqiong Liu, Zeyu Cui, Zhenru Zhang, and Zhihao F an. Qwen2 technical rep ort. arXiv pr eprint arXiv:2407.10671 , 2024. [8] An Y ang, Baosong Y ang, Beic hen Zhang, Bin yuan Hui, Bo Zheng, Bo wen Y u, Chengyuan Li, Da yiheng Liu, F ei Huang, Haoran W ei, Huan Lin, Jian Y ang, Jianhong T u, Jianw ei Zhang, Jianxin Y ang, Jiaxi Y ang, Jingren Zhou, Jun y ang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Y ang, Le Y u, Mei Li, Mingfeng Xue, P ei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li, Tingyu Xia, Xingzhang Ren, Xuancheng Ren, Y ang F an, Y ang Su, Yic hang Zhang, Y u W an, Y uqiong Liu, Zeyu Cui, Zhenru Zhang, and Zihan Qiu. Qwen2.5 technical rep ort. arXiv pr eprint arXiv:2412.15115 , 2024. [9] An Y ang, Anfeng Li, Baosong Y ang, Beic hen Zhang, Binyuan Hui, Bo Zheng, Bo wen Y u, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Li u, F an Zhou, F ei Huang, F eng Hu, Hao Ge, Haoran W ei, Huan Lin, Jialong T ang, Jian Y ang, Jianhong T u, Jianw ei Zhang, Jianxin Y ang, Jiaxi Y ang, Jing Zhou, Jingren Zhou, Jun y ang Lin, Kai Dang, Keqin Bao, Kexin Y ang, Le Y u, Lianghao Deng, Mei Li, Mingfeng Xue, Mingze Li, P ei Zhang, P eng W ang, Qin Zhu, Rui Men, Ruize Gao, Shixuan Liu, Sh uang Luo, Tianhao Li, Tian yi T ang, W enbiao Yin, Xingzhang Ren, Xinyu W ang, Xin yu Zhang, Xuancheng Ren, Y ang F an, Y ang Su, Yic hang Zhang, Yinger Zhang, Y u W an, Y uqiong Liu, Zekun W ang, Zeyu Cui, Zhenru Zhang, Zhip eng Zhou, and Zihan Qiu. Qwen3 technical report. arXiv pr eprint arXiv:2505.09388 , 2025. [10] Qw en T eam. Qw en3.5: T ow ards native multimodal agen ts, F ebruary 2026. URL https://qwen. ai/blog?id=qwen3.5 . [11] Da y a Guo, Dejian Y ang, Haow ei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi W ang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capabilit y in llms via reinforcemen t learning. arXiv pr eprint arXiv:2501.12948 , 2025. [12] Nathan Lam b ert. The atom pro ject, August 2025. URL https://atomproject.ai . [13] Baolin Peng, Chun yuan Li, Pengc heng He, Mic hel Galley , and Jianfeng Gao. Instruction tuning with gpt-4. arXiv pr eprint arXiv:2304.03277 , 2023. [14] Long Ouy ang, Jeffrey W u, Xu Jiang, Diogo Almeida, Carroll W ainwrigh t, P amela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray , et al. T raining language mo dels to follow instructions with human feedback. A dvanc es in neur al information pr o c essing systems , 35:27730– 27744, 2022. 26 References SII-GAIR [15] Aaron Jaech, A dam Kalai, A dam Lerer, Adam Ric hardson, Ahmed El-Kishky , Aiden Low, Alec Hely ar, Aleksander Madry , Alex Beutel, Alex Carney , et al. Op enai o1 system card. arXiv pr eprint arXiv:2412.16720 , 2024. [16] Yiw ei Qin, Xuefeng Li, Haoy ang Zou, Yixiu Liu, Shijie Xia, Zhen Huang, Yixin Y e, W eizhe Y uan, Hector Liu, Y uanzhi Li, et al. O1 replication journey: A strategic progress rep ort–part 1. arXiv pr eprint arXiv:2410.18982 , 2024. [17] Zhen Huang, Hao yang Zou, Xuefeng Li, Yixiu Liu, Y uxiang Zheng, Ethan Chern, Shijie Xia, Yiwei Qin, W eizhe Y uan, and Pengfei Liu. O1 replication journey–part 2: Surpassing o1-preview through simple distillation, big progress or bitter lesson? arXiv pr eprint arXiv:2411.16489 , 2024. [18] Yixin Y e, Zhen Huang, Y ang Xiao, Ethan Chern, Shijie Xia, and Pengfei Liu. Limo: Less is more for reasoning. arXiv pr eprint arXiv:2502.03387 , 2025. [19] Shijie Xia, Yiw ei Qin, Xuefeng Li, Y an Ma, Run-Ze F an, Steffi Chern, Haoy ang Zou, F an Zhou, Xiangkun Hu, Jiahe Jin, et al. Generativ e ai act ii: T est time scaling drives cognition engineering. arXiv pr eprint arXiv:2504.13828 , 2025. [20] Carlos E Jimenez, John Y ang, Alexander W ettig, Sh un yu Y ao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language mo dels resolv e real-world gith ub issues? arXiv pr eprint arXiv:2310.06770 , 2023. [21] Yixiu Liu, Y ang Nan, W eixian Xu, Xiangkun Hu, Lyumanshan Y e, Zhen Qin, and P engfei Liu. Alphago momen t for mo del architecture discov ery . arXiv pr eprint arXiv:2507.18074 , 2025. [22] P engfei Liu, W eizhe Y uan, Jinlan F u, Zhengbao Jiang, Hiroaki Hay ashi, and Graham Neubig. Pre-train, prompt, and predict: A systematic survey of prompting metho ds in natural language pro cessing. ACM c omputing surveys , 55(9):1–35, 2023. [23] Qish uo Hua, Lyumanshan Y e, Dayuan F u, Y ang Xiao, Xiao jie Cai, Y unze W u, Jifan Lin, Junfei W ang, and Pengfei Liu. Context engineering 2.0: The context of con text engineering. arXiv pr eprint arXiv:2510.26493 , 2025. [24] T eam OLMo, P ete W alsh, Luca Soldaini, Dirk Gro enev eld, Kyle Lo, Shane Arora, Akshita Bhagia, Y uling Gu, Shengyi Huang, Matt Jordan, et al. 2 olmo 2 furious. arXiv pr eprint arXiv:2501.00656 , 2024. [25] T eam Olmo, Allyson Ettinger, Amanda Bertsch, Bailey Kuehl, David Graham, Da vid Heineman, Dirk Groeneveld, F aeze Brahman, Finbarr Timbers, Hamish Ivison, et al. Olmo 3. arXiv pr eprint arXiv:2512.13961 , 2025. [26] Sy eda Nahida Akter, Shrimai Prabh umo y e, Eric Nyb erg, Mostofa Pat wary , Mohammad Shoeybi, Y ejin Choi, and Bryan Catanzaro. F ront-loading reasoning: The synergy b et ween pretraining and p ost-training data. arXiv pr eprint arXiv:2510.03264 , 2025. [27] Oded Ov adia, Menachem Brief, Moshik Mishaeli, and Oren Elisha. Fine-tuning or retriev al? comparing knowledge injection in llms. In Pr o c e e dings of the 2024 c onfer enc e on empiric al metho ds in natur al language pr o c essing , pages 237–250, 2024. [28] Sergey Pletenev, Maria Marina, Daniil Mosko vskiy , V asily Kono v alo v, P a v el Brasla vski, Alexander P anc henk o, and Mikhail Salniko v. How muc h knowledge can you pack into a lora adapter without harming llm? arXiv pr eprint arXiv:2502.14502 , 2025. [29] Yiw ei Qin, Zhen Huang, Tiantian Mi, W eiye Si, Cheny ang Zhou, Qip eng Guo, Siyuan F eng, and P engfei Liu. Data darwinism part i: Unlo c king the v alue of scientific data for pre-training. arXiv pr eprint arXiv:2602.07824 , 2026. [30] Dan Su, Kezhi Kong, Ying Lin, Joseph Jennings, Brandon Norick, Markus Kliegl, Mostofa Pat w ary , Mohammad Sho eybi, and Bryan Catanzaro. Nemotron-cc: T ransforming common crawl in to a refined long-horizon pretraining dataset. arXiv pr eprint arXiv:2412.02595 , 2024. [31] Siming Huang, Tianhao Cheng, J. K. Liu, Jiaran Hao, Liuyihan Song, Y ang Xu, J. Y ang, Jiaheng Liu, Chenchen Zhang, Linzheng Chai, Ruifeng Y uan, Zhaoxiang Zhang, Jie F u, Qian Liu, Ge Zhang, Zili W ang, Y uan Qi, Yinghui Xu, and W ei Ch u. Op encoder: The op en co okb ook for top-tier co de large language mo dels, 2025. URL . 27 References SII-GAIR [32] NVIDIA, :, Aarti Basant, Abhijit Khairnar, Abhijit Paithank ar, Abhinav Khattar, Adith ya Ren- duc hin tala, Adit ya Malte, Akhiad Berco vic h, Akshay Hazare, Alejandra Rico, Aleksander Ficek, Alex Kondratenk o, Alex Shap oshnik ov, Alexander Bukharin, Ali T aghibakhshi, Amelia Barton, Amey a Sunil Mahabaleshw ark ar, Amy Shen, Andrew T ao, Ann Guan, Anna Shors, Anubha v Man- darw al, Arham Mehta, Arun V enk atesan, Ash ton Sharabiani, Ashw ath Aithal, Ashwin Poo jary , A yush Dattagupta, Balaram Buddhara ju, Banghua Zhu, Barnab y Simkin, Bilal Kartal, Bita Darvish Rouhani, Bobby Chen, Boris Ginsburg, Brandon Norick, Brian Y u, Bryan Catanzaro, Charles W ang, Charlie T ruong, Chetan Mungek ar, Chintan Patel, Chris Alexiuk, Christian Munley , Christopher P arisien, Dan Su, Daniel Afrimi, Daniel K orzekwa, Daniel Rohrer, Daria Gitman, David Mosal- lanezhad, Deepak Naray anan, Dima Rek esh, Dina Y ared, Dmytro Pykhtar, Dong Ahn, Duncan Riach, Eileen Long, Elliott Ning, Eric Chung, Erick Galinkin, Ev elina Bakhturina, Gargi Prasad, Gerald Shen, Haifeng Qian, Haim Elisha, Harsh Sharma, Hayley Ross, Helen Ngo, Herman Sahota, Hexin W ang, Hoo Chang Shin, Hua Huang, Iain Cunningham, Igor Gitman, Iv an Moshk o v, Jaeh un Jung, Jan Kautz, Jane P olak Sco w croft, Jared Casp er, Jian Zhang, Jiaqi Zeng, Jimmy Zhang, Jinze Xue, Jo celyn Huang, Jo ey Conw ay , John Kamalu, Jonathan Cohen, Joseph Jennings, Julien V eron Vialard, Junk eun Yi, Jupinder Parmar, Kari Briski, Katherine Cheung, Katherine Luna, Keith W yss, Keshav San thanam, Kezhi Kong, Krzysztof P aw elec, Kumar Anik, Kunlun Li, Kushan Ahmadian, La wrence McAfee, La ya Sleiman, Leon Derczynski, Luis V ega, Maer Ro drigues de Melo, Mak esh Narsimhan Sreedhar, Marcin Cho c howski, Mark Cai, Markus Kliegl, Marta Stepniewsk a-Dziubinsk a, Matvei No vik ov, Mehrzad Samadi, Meredith Price, Meriem Boub dir, Mic hael Bo one, Michael Ev ans, Michal Bien, Michal Zaw alski, Miguel Martinez, Mike Chrzano wski, Mohammad Sho eybi, Mostofa Pat wary , Namit Dhameja, Nav e Assaf, Negar Habibi, Nidhi Bhatia, Nikki Pope, Nima T a jbakhsh, Nirmal Ku- mar Juluru, Oleg Rybako v, Oleksii Hrinch uk, Oleksii Kuchaiev, Oluw atobi Olabiyi, P ablo Ribalta, P adma v ath y Subramanian, Parth Chadha, Pa vlo Molchano v, P eter Dyk as, Peter Jin, Piotr Bialec ki, Piotr Januszewski, Pradeep Thalasta, Prashan t Gaikwad, Praso on V arshney , Pritam Gundec ha, Przemek T redak, Rab eeh Karimi Mahabadi, Ra jen Patel, Ran El-Y aniv, Ranjit Ra jan, Ria Cheruvu, Rima Shahbazy an, Ritik a Bork ar, Ritu Gala, Roger W aleffe, Ruoxi Zhang, Russell J. Hew ett, Ryan Prenger, Sahil Jain, Samuel Kriman, Sanjeev Satheesh, Saori Ka ji, Sarah Y urick, Saura v Muralidha- ran, Sean Narenthiran, Seonmy eong Bak, Sep ehr Sameni, Seung ju Han, Shanmugam Ramasam y , Shaona Ghosh, Sharath T uruv ek ere Sreeniv as, Shelb y Thomas, Shizhe Diao, Shrey a Gopal, Shrimai Prabh umo y e, Sh ubham T oshniwal, Shuo yang Ding, Siddharth Singh, Siddhartha Jain, Somshubra Ma jumdar, Soumy e Singhal, Stefania Alb orghetti, Syeda Nahida Akter, T erry Kong, Tim Moon, T omasz Hliwiak, T omer Asida, T ony W ang, T ugrul Kon uk, T winkle V ashishth, Tyler Poon, Udi Karpas, V ahid Noro ozi, V enk at Sriniv asan, Vijay Korthik anti, Vikram F ugro, Vineeth Kalluru, Vitaly Kurin, Vitaly Lavrukhin, W asi Uddin Ahmad, W ei Du, W onmin By eon, Ximing Lu, Xin Dong, Y ashaswi Karnati, Y ejin Choi, Yian Zhang, Ying Lin, Y onggan F u, Y oshi Suhara, Zhen Dong, Zhiyu Li, Zhongb o Zhu, and Zijia Chen. Nvidia nemotron nano 2: An accurate and efficient hybrid mam ba-transformer reasoning mo del, 2025. URL . [33] Liping T ang, Nikhil Ranjan, Omk ar Pangark ar, Xuezhi Liang, Zhen W ang, Li An, Bhask ar Rao, Linghao Jin, Huijuan W ang, Zhoujun Cheng, Suqi Sun, Cun Mu, Victor Miller, Xuezhe Ma, Y ue P eng, Zhengzhong Liu, and Eric P . Xing. T xt360: A top-quality llm pre-training dataset requires the p erfect blend, 2024. [34] F an Zhou, Zengzhi W ang, Nikhil Ranjan, Zhoujun Cheng, Liping T ang, Guow ei He, Zhengzhong Liu, and Eric P Xing. Megamath: Pushing the limits of op en math corpora. arXiv pr eprint arXiv:2504.02807 , 2025. [35] Rab eeh Karimi Mahabadi, Sanjeev Satheesh, Shrimai Prabhumo ye, Mostofa Pat wary , Mohammad Sho eybi, and Bry an Catanzaro. Nemotron-cc-math: A 133 billion-tok en-scale high quality math pretraining dataset. arXiv pr eprint arXiv:2508.15096 , 2025. [36] Sy eda Nahida Akter, Shrimai Prabh umoy e, John Kamalu, Sanjeev Satheesh, Eric Nyb erg, Mostofa P at wary , Mohammad Sho eybi, and Bryan Catanzaro. MIND: Math informed synthetic dialogues for pretraining LLMs. In The Thirte enth International Confer enc e on L e arning R epr esentations , 2025. URL https://openreview.net/forum?id=TuOTSAiHDn . [37] Jak e P oznanski, Luca Soldaini, and Kyle Lo. olmo cr 2: Unit test rewards for do cumen t o cr, 2025. URL . [38] Essen tial AI, :, Andrew Ho jel, Michael Pust, Tim Romanski, Y ash V anjani, Ritvik Kapila, Mohit P armar, A darsh Chaluv ara ju, Alok T ripathy , Anil Thomas, Ashish T anw er, Darsh J Shah, Ishaan Shah, Karl Stratos, Khoi Nguyen, Kurt Smith, Mic hael Callahan, Peter Rushton, Philip Monk, Platon Mazarakis, Saad Jamal, Saurabh Sriv astav a, Somanshu Singla, and Ashish V aswani. Essential-w eb v1.0: 24t tokens of organized web data, 2025. URL . 28 References SII-GAIR [39] Op enAI. gpt-oss-120b & gpt-oss-20b mo del card, 2025. URL 10925 . [40] Somsh ubra Ma jumdar, V ahid Noro ozi, Mehrzad Samadi, Sean Narenthiran, Aleksander Ficek, W asi Uddin Ahmad, Jocelyn Huang, Jagadeesh Balam, and Boris Ginsburg. Genetic instruct: Scaling up syn thetic generation of coding instructions for large language models, 2025. URL https://arxiv.org/abs/2407.21077 . [41] Sh ubham T oshniwal, W ei Du, Iv an Moshko v, Branislav Kisacanin, Alexan A yrap et yan, and Igor Gitman. Op enmathinstruct-2: Accelerating ai for math with massive op en-source instruction data, 2024. URL . [42] Akhiad Bercovic h, Itay Levy , Izik Golan, Mohammad Dabbah, Ran El-Y aniv, Omri Pun y , Ido Galil, Zach Moshe, T omer Ronen, Na jeeb Nabw ani, Ido Shahaf, Oren T ropp, Ehud Karpas, Ran Zilb erstein, Jiaqi Zeng, Soum ye Singhal, Alexander Bukharin, Yian Zhang, T ugrul Kon uk, Ger- ald Shen, Ameya Sunil Mahabaleshw ark ar, Bilal Kartal, Y oshi Suhara, Olivier Delalleau, Zijia Chen, Zhilin W ang, Da vid Mosallanezhad, A di Renduchin tala, Haifeng Qian, Dima Rekesh, F ei Jia, Somshubra Ma jumdar, V ahid Noro ozi, W asi Uddin Ahmad, Sean Narenthiran, Aleksander Ficek, Mehrzad Samadi, Jo celyn Huang, Siddhartha Jain, Igor Gitman, Iv an Moshk o v, W ei Du, Sh ubham T oshniw al, George Armstrong, Branisla v Kisacanin, Matv ei Novik ov, Daria Gitman, Ev elina Bakhturina, Jane P olak Scow croft, John Kamalu, Dan Su, Kezhi Kong, Markus Kliegl, Rab eeh Karimi, Ying Lin, Sanjeev Satheesh, Jupinder Parmar, Pritam Gundecha, Brandon Norick, Joseph Jennings, Shrimai Prabhumo ye, Syeda Nahida Akter, Mostofa Pat wary , Abhinav Khattar, Deepak Nara y anan, Roger W aleffe, Jimmy Zhang, Bor-Yiing Su, Guyue Huang, T erry Kong, P arth Chadha, Sahil Jain, Christine Harvey , Elad Segal, Jining Huang, Sergey Kashirsky , Rob ert McQueen, Izzy Putterman, George Lam, Arun V enk atesan, Sherry W u, Vinh Nguyen, Mano j Kilaru, Andrew W ang, Anna W arno, Abhilash Somasamudramath, Sandip Bhask ar, Mak a Dong, Na ve Assaf, Shahar Mor, Omer Ullman Argov, Scot Junkin, Oleksandr Romanenko, Pedro Larroy , Monik a Katariya, Marco Rovinelli, Viji Balas, Nic holas Edelman, Anahita Bhiwandiw alla, Muth u Subramaniam, Smita Ithap e, Karthik Ramamo orth y , Y uting W u, Suguna V arshini V elury , Omri Almog, Joyjit Da w, Den ys F ridman, Erick Galinkin, Mic hael Ev ans, Katherine Luna, Leon Derczynski, Nikki P op e, Eileen Long, Seth Schneider, Guillermo Siman, T omasz Grzegorzek, Pablo Ribalta, Monik a Katariya, Joey Con w a y , T risha Saar, Ann Guan, Krzysztof Pa welec, Sh y amala Pray aga, Oleksii Kuchaiev, Boris Ginsburg, Oluw atobi Olabiyi, Kari Briski, Jonathan Cohen, Bry an Catanzaro, Jonah Alb en, Y onatan Geifman, Eric Ch ung, and Chris Alexiuk. Llama-nemotron: Efficient reasoning mo dels, 2025. URL https://arxiv.org/abs/2505.00949 . [43] Run-Ze F an, Zengzhi W ang, and Pengfei Liu. Megascience: Pushing the frontiers of p ost-training datasets for science reasoning, 2025. URL . [44] Josh ua Ainslie, James Lee-Thorp, Mic hiel De Jong, Y ury Zemlyanskiy , F ederico Lebrón, and Sumit Sanghai. Gqa: T raining generalized multi-query transformer models from multi-head chec kp oin ts. arXiv pr eprint arXiv:2305.13245 , 2023. [45] Noam Shazeer. Glu v ariants improv e transformer. arXiv pr eprint arXiv:2002.05202 , 2020. [46] Biao Zhang and Rico Sennric h. Ro ot mean square la yer normalization. A dvanc es in neur al information pr o c essing systems , 32, 2019. [47] Jianlin Su, Murtadha Ahmed, Y u Lu, Shengfeng Pan, W en Bo, and Y unfeng Liu. Roformer: Enhanced transformer with rotary posi tion embedding. Neur o c omputing , 568:127063, 2024. [48] Dan Hendryc ks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeik a, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. Pr o c e e dings of the International Confer enc e on L e arning R epr esentations (ICLR) , 2021. [49] Y ub o W ang, Xueguang Ma, Ge Zhang, Y uansheng Ni, Abhranil Chandra, Shiguang Guo, W eiming Ren, Aaran Arulra j, Xuan He, Ziy an Jiang, et al. Mmlu-pro: A more robust and challenging m ulti-task language understanding b enc hmark. arXiv pr eprint arXiv:2406.01574 , 2024. [50] W anjun Zhong, Ruixiang Cui, Yiduo Guo, Y aob o Liang, Shuai Lu, Y anlin W ang, Amin Saied, W eizhu Chen, and Nan Duan. Agiev al: A human-cen tric b enc hmark for ev aluating foundation mo dels, 2023. [51] Ro w an Zellers, Ari Holtzman, Y onatan Bisk, Ali F arhadi, and Y ejin Choi. Hellaswag: Can a machine really finish y our sen tence? In Pr o c e e dings of the 57th Annual Me eting of the Asso ciation for Computational Linguistics , 2019. 29 References SII-GAIR [52] Mandar Joshi, Eunsol Choi, Daniel S W eld, and Luke Zettlemo yer. T riviaqa: A large scale distantly sup ervised challenge dataset for reading comprehension. arXiv pr eprint arXiv:1705.03551 , 2017. [53] Jiasheng Zheng, Boxi Cao, Zhengzhao Ma, Ruotong Pan, Hongyu Lin, Y ao jie Lu, Xianp ei Han, and Le Sun. Beyond correctness: Benchmarking multi-dimensional co de generation for large language mo dels, 2024. URL . [54] Keisuk e Sak aguchi, Ronan Le Bras, Chandra Bhaga v atula, and Y ejin Choi. Winogrande: An adv ersarial winograd sc hema challenge at scale. arXiv pr eprint arXiv:1907.10641 , 2019. [55] T o dor Mihaylo v, Peter Clark, T ushar Khot, and Ashish Sabharwal. Can a suit of armor conduct electricit y? a new dataset for op en b o ok question answering. In EMNLP , 2018. [56] Y onatan Bisk, Ro wan Zellers, Jianfeng Gao, Y ejin Choi, et al. Piqa: Reasoning ab out physical commonsense in natural language. In Pr o c e e dings of the AAAI c onfer enc e on artificial intel ligenc e , v olume 34.05, pages 7432–7439, 2020. [57] Mark Chen, Jerry T worek, Heewoo Jun, Qiming Y uan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edw ards, Y uri Burda, Nic holas Joseph, Greg Bro c kman, Alex Ray , Raul Puri, Gretc hen Krueger, Mic hael Petro v, Heidy Khlaaf, Girish Sastry , P amela Mishkin, Brooke Chan, Scott Gray , Nic k Ryder, Mikhail Pa vlov, Alethea Po wer, Luk asz Kaiser, Mohammad Bav arian, Clemens Winter, Philipp e Tillet, F elip e P etroski Suc h, Dav e Cummings, Matthias Plappert, F otios Chantzis, Elizabeth Barnes, Ariel Herb ert-V oss, William Hebgen Guss, Alex Nic hol, Alex Paino, Nik olas T ezak, Jie T ang, Igor Babuschkin, Suchir Bala ji, Shantan u Jain, William Saunders, Christopher Hesse, Andrew N. Carr, Jan Leike, Josh Ac hiam, V edant Misra, Ev an Morik aw a, Alec Radford, Matthew Knight, Miles Brundage, Mira Murati, Katie May er, Peter W elinder, Bob McGrew, Dario Amo dei, Sam McCandlish, Ily a Sutskev er, and W o jciech Zaremba. Ev aluating large language mo dels trained on co de, 2021. [58] Jia w ei Liu, Ch unqiu Stev en Xia, Y uyao W ang, and Lingming Zhang. Is your co de generated b y c hatGPT really correct? rigorous ev aluation of large language mo dels for co de generation. In Thirty-seventh Confer enc e on Neur al Information Pr o c essing Systems , 2023. URL https: //openreview.net/forum?id=1qvx610Cu7 . [59] Jacob Austin, Augustus Odena, Maxw ell Ny e, Maarten Bosma, Henryk Mic halewski, Da vid Dohan, Ellen Jiang, Carrie Cai, Michael T erry , Quo c Le, et al. Program syn thesis with large language mo dels. arXiv pr eprint arXiv:2108.07732 , 2021. [60] Karl Cobb e, Vineet Kosara ju, Mohammad Bav arian, Mark Chen, Heewoo Jun, Luk asz Kaiser, Matthias Plapp ert, Jerry T worek, Jacob Hilton, Reiichiro Nak ano, Christopher Hesse, and John Sc h ulman. T raining verifiers to solve math word problems. arXiv pr eprint arXiv:2110.14168 , 2021. [61] Qin tong Li, Ley ang Cui, Xueliang Zhao, Lingp eng Kong, and W ei Bi. Gsm-plus: A comprehensive b enc hmark for ev aluating the robustness of llms as mathematical problem solvers. arXiv pr eprint arXiv:2402.19255 , 2024. [62] Dan Hendrycks, Collin Burns, Saurav Kadav ath, Akul Arora, Steven Basart, Eric T ang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. arXiv pr eprint arXiv:2103.03874 , 2021. [63] Da vid Rein, Bett y Li Hou, Asa Co oper Stickland, Jackson Pett y , Richard Y uanzhe Pang, Julien Dirani, Julian Mic hael, and Sam uel R Bowman. Gp qa: A graduate-lev el google-pro of q&a b enc hmark. In First Confer enc e on L anguage Mo deling , 2024. [64] Xinrun Du, Yifan Y ao, Kaijing Ma, Bingli W ang, Tianyu Zheng, King Zh u, Minghao Liu, Yiming Liang, Xiaolong Jin, Zhenlin W ei, et al. Sup ergp qa: Scaling llm ev aluation across 285 graduate disciplines. arXiv pr eprint arXiv:2502.14739 , 2025. [65] Leo Gao, Jonathan T ow, Bab er Abbasi, Stella Biderman, Sid Black, Anthon y DiPofi, Charles F oster, Laurence Golding, Jeffrey Hsu, Alain Le Noac’h, Haonan Li, Kyle McDonell, Niklas Muennighoff, Chris Ociepa, Jason Phang, Laria Reynolds, Hailey Sc ho elk opf, A viy a Sko wron, Lintang Sutawik a, Eric T ang, Anish Thite, Ben W ang, Kevin W ang, and Andy Zou. The language mo del ev aluation harness, 07 2024. URL https://zenodo.org/records/12608602 . [66] Yiw en Hu, Huatong Song, Jia Deng, Jiap eng W ang, Jie Chen, Kun Zhou, Y utao Zhu, Jinhao Jiang, Zican Dong, W ayne Xin Zhao, et al. Y ulan-mini: An op en data-efficient language mo del. arXiv pr eprint arXiv:2412.17743 , 2024. 30 A. Ev aluation Details SII-GAIR A Ev aluation Details A.1 Benc hmark Descriptions This app endix provides detailed descriptions of all 19 benchmarks used in our ev aluation, organized by capabilit y domain. A.1.1 General Kno wledge and Reasoning Benchmarks MMLU (Massiv e Multitask Language Understanding). MMLU is a comprehensive m ultiple- c hoice b enc hmark cov ering 57 sub jects spanning STEM, humanities, so cial sciences, and other areas. The dataset tests a mo del’s broad knowledge across div erse domains including elemen tary mathematics, US history , computer science, law, and more. Questions range from elemen tary to professional level, pro viding a thorough assessmen t of general knowledge and reasoning capabilities. MMLU-Pro. MMLU-Pro is an enhanced v arian t of MMLU designed to address the plateau in mo del p erformance on the original benchmark. It extends MMLU b y: (1) in tegrating more challenging, reasoning-fo cused questions; (2) expanding the choice set from four to ten options; and (3) eliminating trivial and noisy questions. MMLU-Pro causes a significant 16-33% accuracy drop compared to MMLU while demonstrating greater stability under v arying prompts (2% sensitivity vs. 4-5% in MMLU). The b enc hmark sho ws that mo dels utilizing Chain of Thought (CoT) reasoning achiev e better p erformance compared to direct answ ering. A GIEv al (EN). AGIEv al is a h uman-cen tric b enc hmark sp ecifically designed to ev aluate foundation mo dels’ general abilities in tasks p ertinen t to h uman cognition and problem-solving. It is derived from 20 official, public, and high-standard admission and qualification exams, including Chinese College Entrance Exam (Gaok ao), American SA T, law school admission tests, math comp etitions, lawy er qualification tests, and national civil service exams. W e ev aluate on the English subset (A GIEv al-EN) whic h includes A QUA-RA T, Gaok ao English, LogiQA-EN, LSA T (Analytical Reasoning, Logical Reasoning, Reading Comprehension), SA T (English, Math), and MA TH problems. HellaSw ag. HellaSwag is a commonsense natural language inference dataset designed to b e trivial for h umans (>95% accuracy) but challenging for state-of-the-art models. Given an ev en t description (e.g., “A w oman sits at a piano”), the task is to select the most likely followup from multiple options. The dataset w as constructed via Adv ersarial Filtering (AF), where discriminators iteratively select adversarial mac hine-generated wrong answ ers. The key insight is scaling up the length and complexity of examples to a “Goldilo c ks” zone where generated text is ridiculous to humans yet often misclassified by models. T riviaQA. T riviaQA is a large-scale reading comprehension dataset containing ov er 650K question- answ er-evidence triples. It includes 95K question-answ er pairs authored b y trivia enth usiasts and indep enden tly gathered evidence do cumen ts (six p er question on av erage) that pro vide high-quality distan t sup ervision for answering the questions. The dataset tests b oth reading comprehension and the abilit y to lo cate relev ant information across multiple do cumen ts. RA CE (ReAding Comprehension from Examinations). RACE is a large-scale reading compre- hension dataset with more than 28,000 passages and nearly 100,000 questions. The dataset is collected from English examinations in China designed for middle sc ho ol and high school studen ts. Questions require understanding passage conten t and reasoning ab out implicit information, making it a challenging test of reading comprehension capabilities. WinoGrande. WinoGrande is a collection of 44K problems inspired by the Winograd Schema Challenge, designed to test commonsense reasoning. F ormulated as a fill-in-a-blank task with binary options, the goal is to choose the correct option for a giv en sen tence requiring commonsense reasoning. The dataset w as adjusted to impro ve scale and robustness against dataset-sp ecific bias. Op enBookQA. Op enBookQA is a question-answering dataset mo deled after op en b ook exams for assessing h uman understanding of science. It consists of 5,957 m ultiple-c hoice elemen tary-level science questions (4,957 train, 500 dev, 500 test) that prob e understanding of 1,326 core science facts and their application to nov el situations. Answ ering requires b oth the provided “b ook” of facts and additional broad common kno wledge not contained in the bo ok. PIQA (Physical Interaction: Question Answ ering). PIQA is a physical commonsense reasoning b enc hmark designed to in vestigate the ph ysical kno wledge of language models. The dataset tests reasoning ab out physical in teractions and commonsense understanding of how the ph ysical world works. Questions 31 A.1 Benchmark Descriptions SII-GAIR are designed to assess to what extent mo dels are actually learning ab out the ph ysical world versus merely pattern matc hing. A.1.2 Co de Generation Benc hmarks HumanEv al. HumanEv al is a co de generation b enc hmark introduced to measure functional correctness for syn thesizing Python programs from do cstrings. It con tains 164 handwritten programming problems with function signatures, do cstrings, reference implemen tations, and m ultiple unit tests. The b enc hmark ev aluates pass@k metrics, measuring the probabilit y that at least one of k generated samples passes all unit tests. HumanEv al has b ecome a standard benchmark for ev aluating co de generation capabilities of language mo dels. Ev alPlus. Ev alPlus extends HumanEv al with more comprehensiv e test suites, providing stricter ev aluation than the original b enc hmark. It augments HumanEv al problems with additional test cases that b etter co v er edge cases and corner conditions, making it more difficult to achiev e high scores through sup erficial pattern matching. MBPP (Mostly Basic Programming Problems). MBPP is a b enc hmark for program synthesis con taining 974 short Python programming tasks designed to be solv able b y entry-lev el programmers. Eac h problem consists of a natural language description, a reference solution, and three automated test cases. The dataset is designed to measure the ability of mo dels to synthesize short Python programs from natural language descriptions, testing basic programming competence. A.1.3 Mathematics and STEM Reasoning Benchmarks GSM8K (Grade School Math 8K). GSM8K is a dataset of 8.5K high-quality , linguistically div erse grade sc ho ol math w ord problems requiring m ulti-step mathematical reasoning. Despite the conceptual simplicit y of this problem distribution, even large transformer mo dels struggle to ac hieve high test p erformance. The dataset tests whether models can p erform the sequen tial reasoning steps needed to solv e elemen tary mathematics problems. Eac h question has a natural language solution that demonstrates the reasoning steps. GSM-Plus. GSM-Plus is a comprehensiv e benchmark for ev aluating the robustness of LLMs as mathematical problem solvers. It extends GSM8K with v arious mathematical p erturbations to test whether mo dels truly understand and apply mathematical knowledge or merely rely on shortcuts. When math questions are slightly c hanged (new statements added or question targets altered), LLMs can mak e mistak es even on problems they solv ed in the original GSM8K, rev ealing brittleness in their mathematical reasoning. MA TH. MA TH is a dataset of 12,500 challenging comp etition mathematics problems spanning algebra, coun ting and probability , geometry , intermediate algebra, num b er theory , prealgebra, and precalculus. Eac h problem has a full step-by-step solution demonstrating the deriv ation of the answ er. The comp etition- lev el difficult y makes MA TH one of the most challenging mathematical reas oning b enc hmarks, requiring sophisticated problem-solving strategies b ey ond pattern matc hing. GPQA (Graduate-Level Go ogle-Proof Q&A). GPQA is a challenging dataset of 448 multiple- c hoice questions written b y domain exp erts in biology , physics, and chemistry . The questions are designed to b e “Google-pro of ”: experts with PhDs reach 65% accuracy (74% when d iscoun ting clear mistakes), while highly skilled non-exp ert v alidators only reach 3 4% accuracy despite sp ending o ver 30 min utes with unrestricted web access. State-of-the-art AI systems also struggle, with GPT-4-based baselines achieving around 39% accuracy . GPQA-Main refers to the main v ariant of this b enc hmark. Sup erGPQA. Sup erGPQA is an extended v ariant of GPQA with additional challenging questions in biology , ph ysics, and chemistry . It maintains the graduate-level difficulty and Go ogle-proof prop ert y of the original GPQA while expanding co verage of adv anced scientific topics. MMLU-STEM. This is the STEM-fo cused subset of MMLU, including sub jects such as abstract algebra, astronomy , college biology , college chemistry , college computer science, college mathematics, college ph ysics, computer security , elementary mathematics, high school biology , high scho ol chemistry , high school computer science, high school mathematics, high school ph ysics, high school statistics, machine learning, and electrical engineering. MMLU-Pro-STEM. This is the STEM subset of MMLU-Pro, maintaining the increased difficulty and expanded c hoice set (10 options) of MMLU-Pro while fo cusing specifically on STEM disciplines. It pro vides an ev en more challenging test of scien tific and mathematical knowledge than MMLU-STEM. 32 B. T raining Implementation Decisions: LR Decay and QA Masking SII-GAIR T able 10: Impact of learning rate decay strategy on Stage 2-2 p erformance. Constant LR main tains 3e-5 throughout, while cosine deca y gradually reduces LR from 3e-5 to 3e-6. Configuration A vg General A vg Code A vg Science Overall A vg Constan t LR 52.06 52.32 45.44 49.66 Cosine decay 52.49 53.31 45.39 50.00 ∆ (decay - constan t) +0.43 +0.99 -0.05 +0.34 84 168 252 336 419 503 Training T okens (B) 51.00 51.25 51.50 51.75 52.00 52.25 52.50 General W/O Loss Mask W/ Loss Mask 84 168 252 336 419 503 Training T okens (B) 49.0 50.0 51.0 52.0 53.0 Code 84 168 252 336 419 503 Training T okens (B) 40.5 41.0 41.5 42.0 42.5 43.0 43.5 44.0 Science Figure 13: Impact of QA masking policy on three capability dimensions across training steps in Stage 2-2. The comparison b et ween masked and unmasked configurations shows marginal improv ements, with consisten t but mo dest gains across all capability clusters. B T raining Implementation Decisions: LR Deca y and QA Masking Bey ond data mixture design, tw o practical implemen tation choices can meaningfully influence training outcomes y et are rarely studied in pretraining contexts: learning rate deca y sc heduling and QA question masking p olicy . LR deca y schedules determine how aggressively the mo del consolidates kno wledge in later training steps, while masking p olicy gov erns whether the mo del is trained to predict question tok ens or only answer tokens. Although both choices may seem like minor engineering details, their interaction with the data format and training stage can lead to non-trivial p erformance differences. W e systematically in vestigate both decisions to provide principled guidance for Stage 2 configurations. Learning rate deca y . W e compare constan t LR against cosine decay (decreasing from 3e-5 to 3e-6) for the 70% QA Stage 2-2 configuration (T able 10 ). Cosine decay yields consistent improv ements in general kno wledge and co de generation, while science reasoning remains largely unc hanged. The b enefits align with a “capability building then refinement” pattern: aggressive learning in Stage 2-1 establishes broad capabilities, and a gradual LR reduction in Stage 2-2 consolidates and stabilizes them. The ov erall impro v emen t is modest but reliable, making cosine deca y a low-cost enhancement worth applying in m ulti-substage configurations. QA data masking p olicy . W e compare masking the question p ortion of QA pairs (only answer tok ens con tribute to loss, follo wing SFT conv ention) against treating QA as contin uous text (all tokens con tribute). Using the 70% QA Stage 2-2 configuration with high-quality , diverse question data, masking ac hiev es 49.14 ov erall at 30k steps v ersus 48.77 without masking (+0.37). This marginal gain is consistent across general (+0.38), co de (+0.35), and science (+0.35) domains, and training dynamics remain stable under b oth strategies. In contrast to SFT—where masking is essential to preven t shortcut learning— pretraining’s broader knowledge acquisition ob jectiv e means that mo dels b enefit from learning b oth question understanding and answ er generation when questions are sufficien tly diverse. Practically , masking incurs non-trivial engineering ov erhead (additional mask storage or runtime computation) for a mo dest return; the k ey tak ea w a y is that question quality and div ersity matter more than masking strategy . Figure 13 illustrates the comparison across training chec kp oin ts. 33 C. Prompts for Dataset Construction SII-GAIR C Prompts for Dataset Construction Rewriting Prompt for Constructing MegaMath-W eb-Pro Task: - Carefully analyze the provided text to extract key facts, concrete details, important numbers, and core concepts. - Remove any irrelevant or noisy information, and reorganize the content into a logically structured, information-dense, and concise version that is easy to learn from. Output only the refined text. - Strive to maintain the original length as much as possible (avoid excessive shortening). Text: Just output the refined text, no other text. Darwin-Science L4 Pro cessing Prompt You are an expert document cleaner specialized in identifying and removing unwanted content and correcting OCR errors from various document (mainly academic) chunks. ## Objective: Clean and standardize OCR text by identifying and removing redundant, erroneous, or unwanted content and correcting obvious OCR errors according to the rules below. Your task is to identify and delete unnecessary content completely, fix technical errors, while preserving all academic value. ## Deletion and Correction Rules: ### Document Structural Deletion * Remove ** table of contents and navigation structures ** : Multiple consecutive chapter/section titles listed together without accompanying text content - ** Preserve content section headings in main text ** : such as chapter headings, section titles followed by explanatory text or academic material * Remove ** reference lists completely ** : numbered entries with author names, publication titles, and years (e.g., "1. Smith, J. (2020). Title. Journal, 15(3), 123-145.") ** [Delete entire list regardless of format] ** * Remove ** front matter and back matter ** : such as prefaces, acknowledgments, copyright statements, indexes, and other standard book structural elements - ** Preserve sections with academic value ** : such as abstracts, introductions, conclusions that present research background or methodology * Remove ** publication and metadata information ** : such as ISBN, publisher information, revision history, version numbers, institutional affiliations, author affiliations, addresses, contact information * Remove ** page headers, page footers, and page numbers ** ### Academic Content Deletion * Remove ** pure indexing appendices ** : such as glossaries, symbol tables, abbreviation lists, indexes, notations and other purely referential lookup content (entries that only provide definitions without explanations, e.g., "a - alpha coefficient") - ** Preserve ** : appendices with learning value (e.g. mathematical derivations, proofs, technical explanations) - ** Preserve ** : explanatory content that directly supports main text elements (e.g. abbreviation/parameter explanations after tables/formulas/diagrams) * Remove ** image files and placeholders ** : such as ` ![]() ` tags, image file paths, image URLs, markdown syntax and image placeholders (e.g. ` [Image] ` , ` [Picture not available] ` ) - ** Preserve ** : figure/table titles, descriptive text (including content within markdown image formats:  → description) - ** Preserve ** : in-text references (e.g., "as shown in Figure 1") ### Invalid and Redundant Content Deletion 34 C. Prompts for Dataset Construction SII-GAIR * Remove ** OCR processing artifacts ** : such as garbled text, encoding artifacts, duplicate characters, malformed special characters, OCR messages ( ` [OCR error] ` ), file paths, timestamps, version numbers, revision history * Remove ** garbage content ** : such as junk information, advertising content, placeholders (e.g. [Insert citation here]) * Remove ** duplicate content ** : identical paragraphs or sections mainly caused by OCR errors - ** Exception ** : Carefully apply to technical formulas, equations, or specialized notation that may contain subtle but meaningful differences - ** Exception ** : Apply contextual analysis - preserve identical content that serves different semantic purposes or artistic purposes (e.g., poetic refrains, literary repetition) * Remove ** content and navigation markers ** : [content missing], [page break], (Continued), and similar placeholder markers * Remove ** URLs and links ** : all web addresses, hyperlinks, and link information ### OCR Error Correction * ** Fix text fragmentation ** : repair split words, broken sentences, erroneous line breaks and paragraph divisions, missing spaces and punctuation * ** Fix fragmented structured content ** : Repair OCR-damaged structured content (e.g. tables, diagrams, formulas) appearing as consecutive lines of isolated words, single characters, or short phrases - ** Pattern ** : Consecutive lines (5+) with 1-3 words/characters each - ** Action ** : Preserve content while indicating structural damage; delete if unrepairable * ** Standardize whitespace and formatting ** : clean excessive whitespace, compress blank lines, standardize spacing and indentation * ** Fix character and encoding errors ** : correct obvious character errors, spelling issues, and Unicode anomalies * ** Standardize punctuation ** : unify quotation marks, dashes, hyphens, and other punctuation * ** Complete truncated words ** : only fix obviously incomplete words from clear OCR errors, avoid modifying content at chunk edges * ** Standardize academic formatting ** : remove excessive LaTeX commands and unify notation format ## Content Protection Rules: ### Always Preserve Academic and Educational Content * Preserve ** Technical and specialized content ** : such as formulas, equations, proofs, symbols, chemical structures, biological sequences and their original format - ** Preserve exact content ** : do not alter variables, coefficients, structures, sequences, or any technical details * Preserve ** In-text references and citations ** : such as (Smith, 2020), [15], "see Chapter 2", equation (5), "Figure 2.5", (pp. 3-7) * Preserve ** Table structures ** : preserve academic table content, formatting and structural markers (e.g. "|", HTML tags) - ** Exception ** : Does not apply to navigation tables (table of contents, indexes, glossaries) which should be removed * Preserve ** Code blocks and programming examples ** : preserve code block markers ( ``` language, ``` , etc.) and internal code syntax and structure * Preserve ** Educational content ** : such as exercises, questions, answers, solutions, case studies, instructions, user guides * Preserve ** Explanatory content ** : such as NOTE boxes, WARNING boxes, tips, author comments, supplementary information, academic footnotes * Preserve ** Chunk boundary content ** : incomplete sentences and words at chunk edges due to text segmentation * Preserve ** Literary and humanities content ** : including poetry, fiction, drama, creative writing, literary analysis, philosophical texts, and other humanities scholarship with educational value ## Instructions: - Carefully identify all content matching the deletion rules - Remove completely any content that should be deleted - Preserve all valuable academic content by applying protection rules and retaining content that doesn't match deletion rules - Apply OCR error corrections to fix obvious technical problems 35 C. Prompts for Dataset Construction SII-GAIR - Ensure text flows naturally after corrections and deletions - If the entire chunk should be deleted, leave the output tags completely empty - ** Important ** : The content inside the
` tags, image file paths, image URLs, markdown syntax and image placeholders (e.g. ` [Image] ` , ` [Picture not available] ` ) - ** Preserve ** : figure/table titles, descriptive text (including content within markdown image formats:  → description) - ** Preserve ** : in-text references (e.g., "as shown in Figure 1") ### Invalid and Redundant Content Deletion 34 C. Prompts for Dataset Construction SII-GAIR * Remove ** OCR processing artifacts ** : such as garbled text, encoding artifacts, duplicate characters, malformed special characters, OCR messages ( ` [OCR error] ` ), file paths, timestamps, version numbers, revision history * Remove ** garbage content ** : such as junk information, advertising content, placeholders (e.g. [Insert citation here]) * Remove ** duplicate content ** : identical paragraphs or sections mainly caused by OCR errors - ** Exception ** : Carefully apply to technical formulas, equations, or specialized notation that may contain subtle but meaningful differences - ** Exception ** : Apply contextual analysis - preserve identical content that serves different semantic purposes or artistic purposes (e.g., poetic refrains, literary repetition) * Remove ** content and navigation markers ** : [content missing], [page break], (Continued), and similar placeholder markers * Remove ** URLs and links ** : all web addresses, hyperlinks, and link information ### OCR Error Correction * ** Fix text fragmentation ** : repair split words, broken sentences, erroneous line breaks and paragraph divisions, missing spaces and punctuation * ** Fix fragmented structured content ** : Repair OCR-damaged structured content (e.g. tables, diagrams, formulas) appearing as consecutive lines of isolated words, single characters, or short phrases - ** Pattern ** : Consecutive lines (5+) with 1-3 words/characters each - ** Action ** : Preserve content while indicating structural damage; delete if unrepairable * ** Standardize whitespace and formatting ** : clean excessive whitespace, compress blank lines, standardize spacing and indentation * ** Fix character and encoding errors ** : correct obvious character errors, spelling issues, and Unicode anomalies * ** Standardize punctuation ** : unify quotation marks, dashes, hyphens, and other punctuation * ** Complete truncated words ** : only fix obviously incomplete words from clear OCR errors, avoid modifying content at chunk edges * ** Standardize academic formatting ** : remove excessive LaTeX commands and unify notation format ## Content Protection Rules: ### Always Preserve Academic and Educational Content * Preserve ** Technical and specialized content ** : such as formulas, equations, proofs, symbols, chemical structures, biological sequences and their original format - ** Preserve exact content ** : do not alter variables, coefficients, structures, sequences, or any technical details * Preserve ** In-text references and citations ** : such as (Smith, 2020), [15], "see Chapter 2", equation (5), "Figure 2.5", (pp. 3-7) * Preserve ** Table structures ** : preserve academic table content, formatting and structural markers (e.g. "|", HTML tags) - ** Exception ** : Does not apply to navigation tables (table of contents, indexes, glossaries) which should be removed * Preserve ** Code blocks and programming examples ** : preserve code block markers ( ``` language, ``` , etc.) and internal code syntax and structure * Preserve ** Educational content ** : such as exercises, questions, answers, solutions, case studies, instructions, user guides * Preserve ** Explanatory content ** : such as NOTE boxes, WARNING boxes, tips, author comments, supplementary information, academic footnotes * Preserve ** Chunk boundary content ** : incomplete sentences and words at chunk edges due to text segmentation * Preserve ** Literary and humanities content ** : including poetry, fiction, drama, creative writing, literary analysis, philosophical texts, and other humanities scholarship with educational value ## Instructions: - Carefully identify all content matching the deletion rules - Remove completely any content that should be deleted - Preserve all valuable academic content by applying protection rules and retaining content that doesn't match deletion rules - Apply OCR error corrections to fix obvious technical problems 35 C. Prompts for Dataset Construction SII-GAIR - Ensure text flows naturally after corrections and deletions - If the entire chunk should be deleted, leave the output tags completely empty - ** Important ** : The content inside the tags must be exactly the text after deletion, with no explanations, comments, or additional text inside the tags ## Input: OCR document chunk: [CHUNK] ## Output Format: [Place the cleaned content here, or leave completely empty if everything should be deleted] Darwin-Science L5 Pro cessing Prompt You are a master science communicator and pedagogical expert. Your mission is to transform the following dense, expert-level text chunk into vibrant, crystal-clear educational material. Imagine you are creating a definitive learning resource for a bright but novice audience. Your goal is not merely to simplify, but to deeply elucidate, making the complex intuitive and the implicit explicit. Your transformation will be governed by two sets of principles: the Core Mandate (what you must actively do) and the Unbreakable Rules (what you must never violate). ### The Unbreakable Rules: Fidelity and Integrity This principle is of paramount importance and must be followed without exception to ensure the output is valid. * ** (a) Scientific and Factual Correctness: ** Maintain absolute rigor. All data, formulas, definitions, theories, experimental results, and logical arguments must be preserved without altering their meaning or context. Your additions must clarify, not contradict. * ** (b) Structural Integrity: ** Preserve the original structure flawlessly. Keep ALL section headers ( ` ## ` , ` ### ` ), figure/table labels, equation numbers, etc., exactly as they appear, especially at the beginning and end of the chunk. * ** (c) Contextual Limitation and Termination: ** You are processing a partial * chunk * of a document. You lack the full context. Therefore, you must work ** strictly ** within the provided text. Do not invent definitions or reference goals from outside the chunk. ** This strict adherence means your output must terminate exactly where the provided chunk terminates. ** If the chunk ends abruptly (e.g., at a new section header, in the middle of a sentence, or with a label), your output ** must be cut off at that exact same point. ** This is the single most critical rule for preventing hallucination and ensuring continuity. ### The Core Mandate: Deep Pedagogical Transformation This is your primary objective. Be bold and proactive in adding educational value. Your goal is to weave a rich tapestry of understanding. 36 C. Prompts for Dataset Construction SII-GAIR * ** (a) Deconstruct and Narrate the 'Why': ** This is your primary mode of explanation. Actively expand on logical leaps. When the text says "it follows that," "clearly," or "trivially," you must step in and meticulously detail the intermediate steps. More importantly, you must articulate the expert's internal monologue. When faced with an equation, a problem, or a logical step, explain the strategy. Ask and answer questions like: "Okay, what's our goal here?" "What's the first thing I should look for when I see an equation like this?" "We're going to use technique X, and here's why it's the right tool for this specific job." Your mission is to reveal the problem-solving journey, making every single connection transparent. * ** (b) From Jargon to Insight: ** When you encounter a crucial technical term, or a significant variable within a formula, you must deliberately pause the narrative to explain it. Don't just provide a dry definition. Elucidate its importance: What role does this term or variable play? Why does it matter? Crucially, you must then use simpler language, vivid analogies, or concrete examples to build a strong and intuitive mental model for the reader before you continue with the main explanation. This ensures no reader is left behind due to unfamiliar notation or terminology. * ** (c) Invent Vivid Analogies and Concrete Examples: ** Go beyond the text. Where a concept is abstract, create a simple, concrete example to illustrate it. Invent memorable analogies that connect the new information to a learner's existing knowledge (e.g., electron shells as floors in a hotel). * ** (d) Create Contextual Bridges: ** Weave a narrative thread by connecting the current idea to the broader field of knowledge. Hint at future applications or link back to more foundational concepts. For instance: "This principle of [X] is a cornerstone of the field and will be essential for understanding [Y] later on." * ** (e) Think Like a Learner: ** Proactively identify points of potential confusion. What questions would a curious student ask here? Answer them before they are asked. A great teacher warns students about common mistakes. Where applicable, insert brief, helpful asides that feel like a mentor's margin notes. * ** (f) Prioritize Narrative Flow and Clean Formatting: ** When you encounter messy or noisy original LaTeX formatting, convert it to a clean and pristine style (especially for formulas and tables). Above all, strive for a smooth, cohesive, and engaging narrative. Your writing should feel like a continuous, guided tour through the material, not a collection of disconnected facts and callouts. To that end, you must avoid the overuse of overly-structured, point-by-point expressions. Let the main text flow logically and tell a story, adopting the persona of an extremely patient and encouraging teacher. --- Summary of Principles Above: To sum it up, you must strictly respect the accuracy and structure of the original chunk while doing everything possible to make the rewritten text easier to learn and to lower the reader's cognitive load. Consequently, the rewritten text will typically be more detailed and thus longer than the original. --- ** Crucial Output Instructions: ** 1. ** Self-Contained Output: ** The refined text must stand on its own. Avoid any meta-commentary or phrases that refer to the original text, such as "the original paper," "the original context," "the original chunk", etc. The goal is to create a seamless, self-contained educational text, not a commentary on another document. 2. ** Strict Termination: ** You ** MUST ** terminate your output at the ** EXACT ** same point the provided chunk terminates. Do not write a single character past the end of the original chunk. In particular, if a chunk ends with the start of a new section, subsection, step (e.g., it starts with a heading) or cuts off in the middle of a proof/solution, you must NOT invent or continue writing ANY content that would follow. ** --- 37 C. Prompts for Dataset Construction SII-GAIR * You must output ONLY the refined chunk itself, without any introductory or concluding remarks. * ** Original text: ** {chunk} ** Refined text: ** QA Extraction Prompt for Darwin-Science-Bo ok-QA(Biology) Below is a document extract from biological sciences domain (biology, ecology, medicine, genetics, physiology, etc.). # Extraction Task Extract complete, independently solvable biology Q&A pairs following these strict guidelines: ## CRITICAL RULES (Must Follow): 1. ** Answer-First Principle ** : Only extract a question if its complete answer exists in the document 2. ** Zero References Requirement ** : - Questions: No references to "the document", "the text", "Figure 1", "Table 2", "above", "below", "the experiment above","as discussed in the extract"etc. - Answers: No references to "as in document", "as shown in text", "see the document", "Table 2", etc. - Replace ALL references with actual content from the document 3. ** Complete Independence ** : - Each question must be self-contained with ALL necessary information, as others will not have access to the original text. - If a question is incomplete, incorporate missing context to make it fully solvable - Multiple questions must be mutually independent (no "as in first Question", "using previous result") 4. ** Answer Must Exist ** : All answers must be directly found or clearly derivable from the given text - do not extract if uncertain 5. ** Value-Based Selection ** : Focus on extracting the MOST IMPORTANT and EDUCATIONAL content 6. ** No Data-Dependent Conclusions ** : Do NOT extract questions whose answers rely heavily on complex data tables or extensive numerical data that cannot be reasonably included in the Q&A format ## For Questions/Problems: - ** Extract explicit question-answer pairs ** if they exist (ensure they meet zero references and independence requirements) - ** For Mechanisms/Processes ** : Create questions about how biological processes work (e.g., "How does X process occur?", "Describe the mechanism of...") - ** For Structure-Function ** : Create questions linking structure to function (e.g., "What is the structure and function of X?") - ** For Phenomena and Causes ** : Create questions exploring why biological phenomena occur (e.g., "Why does X happen?", "What causes X?") - ** For Comparisons ** : Create questions comparing biological entities (e.g., "What are the differences between X and Y?", "How does X differ from Y?") - ** For Diseases ** : Create questions about etiology, symptoms, mechanisms, or treatments (when information is complete) - ** For Experiments ** : Extract questions about experimental design, findings, or significance (only if self-contained without heavy data table dependence) - ** For Evolution/Ecology ** : Create questions about evolutionary explanations, adaptations, or ecological relationships - ** For Concepts/Definitions ** : Ask about them flexibly, but focus on core concepts and ensure complete answers exist - ** Critical ** : Each question must be complete and self-contained, as others will not have access to the original text. - ** Do NOT extract ** : 38 C. Prompts for Dataset Construction SII-GAIR - Questions that require additional data to be provided in order to be answered - Questions whose answers are uncertain or incomplete - If no valid Q&A content can be extracted following above rules, return exactly: [NO QA] ## For Answers: - ** Process ** : First locate the complete answer in the document, then organize it clearly - If the answer has explanation, reorganize it into a clear, well-structured format - If the answer lacks explanation, add necessary biological reasoning or context - For final answers that need exact matching (multiple-choice, calculations, fill-in-the-blank, true/false), use $ boxedanswer$ notation ## Output Format (STRICT): Use this exact format for parsing: ---BEGIN QA--- Question: Answer: ---END QA--- ---BEGIN QA--- Question: Answer: ---END QA--- If no valid Q&A can be extracted, return exactly: [NO QA] --- Extract: chunk Now process the extract and return the result in the specified format. QA Extraction Prompt for Darwin-Science-Bo ok-QA(Chemistry) Below is a document extract from chemistry domain. # Extraction Task Extract complete, independently solvable chemistry Q&A pairs following these strict guidelines: ## CRITICAL RULES (Must Follow): 1. ** Answer-First Principle ** : Only extract a question if its complete answer exists in the document 2. ** Zero References Requirement ** : - Questions: No references to "the document", "the text", "Figure 1", "Scheme 45", "compound 201", "above", "below", etc. - Answers: No references to "as in document", "as shown in text", "see Scheme", "compound 201", etc. - Replace ALL references with actual content (e.g., replace "compound 201" with its chemical name) 3. ** Complete Independence ** : - Each question must be self-contained with ALL necessary information, as others will not have access to the original text. - If a question is incomplete, incorporate missing context to make it fully solvable - For multi-step reactions, include all necessary steps and conditions - Multiple questions must be mutually independent (no "as in first Question", "using previous result") 39 C. Prompts for Dataset Construction SII-GAIR 4. ** Answer Must Exist ** : All answers must be directly found or clearly derivable from the given text - do not extract if uncertain 5. ** No Scheme/Figure-Dependent Content ** : Do NOT extract questions whose answers rely heavily on reaction schemes, structural diagrams, or figures that cannot be described adequately in text ## For Questions/Problems: - Extract explicit chemistry questions ONLY if their complete answers are present - ** Prioritize substantive content ** over trivial details: focus on chemical properties, principles, mechanisms, experimental methods, calculations, and applications rather than isolated nomenclature or data-dependent conclusions - ** For Chemical Properties ** : Create questions about physical/chemical properties, reactivity, or characteristics when well-described - ** For Chemical Principles/Theories ** : ask to explain the principle or test understanding of key concepts (e.g., "Explain Le Chatelier's principle", "What happens to equilibrium when...") - ** For Chemical Equations ** : ask about equation balancing, reaction types, or explain the reaction principles (include complete conditions) - ** For Reaction Mechanisms ** : Create questions about how reactions proceed ONLY if describable in text without complex schemes - ** For Chemical Calculations ** : Extract calculation problems with ALL given values, units, and formulas only if the answer exits in the text - ** For Experiments ** : create questions about experimental methods, observations, or interpret/explain phenomena (include complete procedural steps) - ** Critical ** : Each question must be complete and self-contained - ** Do NOT extract ** : - Questions depending on reaction schemes or structural diagrams not describable in text - Questions requiring extensive analytical data tables or spectroscopic data - Questions that require additional data to be provided in order to be answered - Questions whose answers are uncertain or incomplete - Questions whose answers can't be found in the text - If no valid Q&A content can be extracted following above rules, return exactly: [NO QA] ## For Answers: - ** Process ** : First locate the complete answer in the document, then organize it clearly - For numerical answers: include units and appropriate significant figures - If the answer has explanation, reorganize it into a clear, well-structured format - If the answer lacks explanation, add necessary context or reasoning - For final answers that need exact matching (multiple-choice, calculations, fill-in-the-blank, true/false), use $ boxedanswer$ notation ## Output Format (STRICT): Use this exact format for parsing: ---BEGIN QA--- Question: Answer: ---END QA--- ---BEGIN QA--- Question: Answer: ---END QA--- If no valid Q&A can be extracted, return exactly: [NO QA] --- Extract: chunk 40 C. Prompts for Dataset Construction SII-GAIR Now process the extract and return the result in the specified format. QA Extraction Prompt for Darwin-Science-Bo ok-QA(Computer Science) Below is a document extract from computer science domain (programming, systems, algorithms, software engineering, etc.). # Extraction Task Extract complete, independently solvable CS Q&A pairs following these strict guidelines: ## CRITICAL RULES (Must Follow): 1. ** Answer-First Principle ** : Only extract a question if its complete answer exists in the document 2. ** Zero References Requirement ** : - Questions: No references to "the document", "the text", "Figure 1", "Section 2.1", "above", "below", "the code above","in Algorithm 4.2" etc. - Answers: No references to "as in document", "as shown in text", "see the document", "Section 2.1", etc. - Replace ALL references with actual content from the document 3. ** Complete Independence ** : - Each question must be self-contained with ALL necessary information, as others will not have access to the original text. - If a question is incomplete, incorporate missing context to make it fully solvable - For code-related questions, include necessary code context within the question - Multiple questions must be mutually independent (no "as in first Question", "using previous result") 4. ** Answer Must Exist ** : All answers must be directly found or clearly derivable from the given text - do not extract if uncertain 5. ** Value-Based Selection ** : Focus on extracting the MOST IMPORTANT and EDUCATIONAL content ## For Questions/Problems: - Extract explicit questions ONLY if their complete answers are present - ** For Step-by-Step Procedures ** : Extract as "How to..." questions ONLY if ALL steps are present and self-contained - ** For System Design/Architecture ** : Create questions about design decisions, trade-offs, or evolution (e.g., "Why did BGS migrate from Mimer to Oracle?") - ** For Algorithms/Code ** : Questions can focus on functionality, complexity, implementation details, or usage, if including code, ensure sufficient context is provided in the question - ** For Comparisons ** : Create questions like "What are the differences between X and Y?" or "When to use X vs Y?" - ** For Performance ** : Extract questions about optimization techniques, performance metrics, or bottlenecks - ** For Concepts/Definitions ** : Ask about them flexibly, but ensure complete answer exists and focus on core concepts - ** Formulate questions naturally and appropriately ** - use varied question formats based on content type, but make sure the answer can be found in the document - If no valid Q&A content can be extracted following above rules, return exactly: [NO QA] ## For Answers: - ** Process ** : First locate the complete answer in the document, then organize it clearly - If the answer has explanation, reorganize it into a clear, well-structured format - If the answer lacks explanation, add necessary context or reasoning - For final answers that need exact matching (multiple-choice, calculations, fill-in-the-blank, true/false), use $ boxedanswer$ notation 41 C. Prompts for Dataset Construction SII-GAIR ## Output Format (STRICT): Use this exact format for parsing: ---BEGIN QA--- Question: Answer: ---END QA--- ---BEGIN QA--- Question: Answer: ---END QA--- If no valid Q&A can be extracted, return exactly: [NO QA] --- Extract: chunk Now process the extract and return the result in the specified format. QA Extraction Prompt for Darwin-Science-Bo ok-QA(Engineer) Below is a book document extract. # Extraction Task Extract complete, independently solvable engineering questions and answers from the document while following these guidelines: ## For Questions: - Extract any explicit engineering questions with their associated answers - For implicit engineering principles, design methods, procedures, or technical specifications presented as statements, convert them to well-formed questions ONLY if they can stand alone - Ensure each extracted question contains ALL necessary information to be solved independently without requiring additional context - Include any relevant diagrams, circuit schematics, system designs, specifications, or technical data mentioned (describe them if not visible) - Extract multiple questions separately if they exist - ** If a question lacks necessary context (specifications, constraints, parameters, standards, initial conditions), incorporate the missing information from the document to make it self-contained ** - If no engineering content can be meaningfully extracted as a question, return ` [NO QA] ` ## For Answers: - Include the answer provided in the extract - Answers should capture the essential explanation of the engineering principle, design approach, or solution methodology - If the source material contains design procedures, calculation steps, or implementation methods, include these in the answer - For engineering problems, the answer should explain the approach, assumptions, calculations, and practical considerations as presented in the text - If the answer already has explanation, reorganize the solution into a clear and well-structured format for better readability and understanding - If the answer lacks explanation, add necessary intermediate steps, reasoning, and justifications as a teacher would - For final answers that need exact matching (calculations, design values, multiple-choice, true/false), use $ boxed$ notation - Include units, dimensions, and tolerances where applicable ## Requirements: - The question should include all necessary information (specifications, constraints, parameters, standards) 42 C. Prompts for Dataset Construction SII-GAIR - The answer should be practical, accurate, and well-explained - Both question and answer should stand alone (no references to documents or original materials) - Preserve technical terminology, symbols, and notation accurately - Maintain engineering rigor and attention to practical feasibility - Include safety considerations and industry standards where relevant ## Format: Format each question-answer pair as: Question: [Complete engineering question with all context needed to understand] Answer: [Corresponding answer from the text] The extract is as follows: chunk Now process the extract and return the result. QA Extraction Prompt for Darwin-Science-Bo ok-QA(Humanso cial) Below is a document extract from humanities and social sciences domain. # Extraction Task Extract complete, independently solvable humanities/social sciences Q&A pairs following these strict guidelines: ## CRITICAL RULES (Must Follow): 1. ** Answer-First Principle ** : Only extract a question if its complete answer exists in the document 2. ** Zero References Requirement ** : - Questions: No references to "the document", "the text", "the author", "Chapter 1", "above", "below", etc. - Answers: No references to "as in document", "as shown in text", "the author states", etc. - Replace ALL references with actual content from the document 3. ** Complete Independence ** : - Each question must be self-contained with ALL necessary information - If a question is incomplete, incorporate missing context to make it fully solvable - Multiple questions must be mutually independent (no "as in first Question", "using previous result") 4. ** Answer Must Exist ** : All answers must be directly found or clearly derivable from the given text - do not extract if uncertain 5. ** Value-Based Selection ** : Focus on extracting the MOST IMPORTANT and EDUCATIONAL content with analytical substance 6. ** Knowledge-Based Content Only ** : Only extract from texts that convey factual information, scholarly theories, analytical arguments, or objective descriptions. Do NOT extract from: - Narrative fiction, creative writing, or purely storytelling passages (novels, literary narratives) - Religious proselytizing, propaganda, or ideological indoctrination - Advertising, marketing, or promotional content - Pure emotional expressions, personal rants, or subjective opinions without analytical substance - Inflammatory or extremist rhetoric ## For Questions/Problems: - ** Extract explicit question-answer pairs ** if they exist (ensure zero references and independence requirements) - ** Create questions about ** : - Historical events: causes, consequences, significance, key figures - Theories and concepts: definitions, frameworks, applications, explanations - Arguments and viewpoints: main claims, evidence, reasoning, limitations - Comparisons: differences and similarities between theories/events/policies/concepts 43 C. Prompts for Dataset Construction SII-GAIR - Impacts and significance: effects, influence, historical/social importance - ** Formulate questions naturally ** - use varied formats based on content type - ** Critical ** : Each question must be self-contained with necessary context and clearly distinguish facts from interpretations - ** Do NOT extract ** : - Questions from narrative fiction, religious proselytizing, propaganda, advertising, or purely emotional content - Rhetorical questions without answers in the text - Open-ended questions without clear answers - Questions requiring extensive background not provided - Trivial details without analytical significance - If no valid Q&A content can be extracted following above rules, return exactly: [NO QA] ## For Answers: - ** Process ** : First locate the complete answer in the document, then organize it clearly - If the answer has explanation, reorganize it into a clear, well-structured format - If the answer lacks explanation, add necessary contextual reasoning while staying true to the text - For final answers that need exact matching (multiple-choice, calculations, fill-in-the-blank, true/false), use $ boxed$ notation ## Output Format (STRICT): Use this exact format for parsing: ---BEGIN QA--- Question: Answer: ---END QA--- ---BEGIN QA--- Question: Answer: ---END QA--- If no valid Q&A can be extracted, return exactly: [NO QA] --- Extract: chunk Now process the extract and return the result in the specified format. QA Extraction Prompt for Darwin-Science-Bo ok-QA(Math) # Extraction Task Extract complete, independently solvable mathematical Q&A pairs following these strict guidelines: ## CRITICAL RULES (Must Follow): 1. ** Answer-First Principle ** : Only extract a question if its complete answer exists in the document 2. ** Zero References Requirement ** : - Questions: No references to "the document", "the text", "Figure 1", "Theorem 1.1", "above", "below", etc. - Answers: No references to "as in document", "as shown in text", "see the document","by Theorem 1.1" etc. - Replace ALL references with actual content from the document 3. ** Complete Independence ** : - Each question must be self-contained with ALL necessary information - If a question is incomplete, incorporate missing context to make it fully solvable 44 C. Prompts for Dataset Construction SII-GAIR - Multiple questions must be mutually independent (no "as in first Question ", "using previous result") 4. ** Answer Must Exist ** : All answers must be directly found or clearly derivable from the given text - do not extract if uncertain ## For Questions/Problems: - Extract explicit mathematical questions ONLY if their complete answers are present - For ** Theorem/Proposition/Corollary + Proof/DEMONSTRATION ** pairs: Convert into "Prove that [full theorem statement]" format - For ** Standalone Theorems ** (without proof): Create questions about the theorem content (e.g., if theorem states "(x-y)(x+y)=x²-y²", ask "(x-y)(x+y)=?" or ask to state/explain the theorem) ONLY if the answer content is in the text - For ** Concepts/Definitions ** : You may ask about them, but ensure the complete answer can be found in the document - ** If you see only solution steps without a question, DO NOT create a question ** - If no valid Q&A content can be extracted following above rules, return exactly: [NO QA] ## For Answers: - ** Process ** : First locate the complete answer in the document, then enhance the reasoning steps - Include the provided solution, proof, or demonstration when available - ** Replace all references ** : Do NOT use "by Theorem 1.2", "using Lemma 3", "from Definition 2.1", etc. Instead, state the actual theorem/lemma/definition content or rephrase the reasoning without references - For theorems/propositions, the answer should contain the complete proof - If the answer has explanation, reorganize it into a clear, well-structured format - If the answer lacks explanation, add necessary intermediate reasoning as a teacher would - For final answers that need exact matching (multiple-choice, calculations, fill-in-the-blank, true/false), use $ boxedanswer$ notation ## Output Format (STRICT): Use this exact format for parsing: ---BEGIN QA--- Question: Answer: ---END QA--- ---BEGIN QA--- Question: Answer: ---END QA--- If no valid Q&A can be extracted, return exactly: [NO QA] Extract: chunk Now process the extract and return the result in the specified format. QA Extraction Prompt for Darwin-Science-Bo ok-QA(Medicine) Below is a document extract from medical sciences domain (clinical medicine, pharmacology, physiology, pathology, public health, etc.). # Extraction Task Extract complete, independently solvable medical Q&A pairs following these strict guidelines: 45 C. Prompts for Dataset Construction SII-GAIR ## CRITICAL RULES (Must Follow): 1. ** Answer-First Principle ** : Only extract a question if its complete answer exists in the document 2. ** Zero References Requirement ** : - Questions: No references to "the document", "according to the text", "Figure 1", "Table 3", "above", "below", "the study above", etc. - Answers: No references to "as in document", "as shown in text", "see Table", "Figure 1", etc. - Replace ALL references with actual content from the document 3. ** Complete Independence ** : - Each question must be self-contained with ALL necessary information - If a question is incomplete, incorporate missing context to make it fully solvable - Multiple questions must be mutually independent (no "as in first Question", "using previous result") 4. ** Answer Must Exist ** : All answers must be directly found or clearly derivable from the given text - do not extract if uncertain 5. ** Value-Based Selection ** : Focus on extracting the MOST IMPORTANT and EDUCATIONAL medical content 6. ** No Data-Dependent Conclusions ** : Do NOT extract questions whose answers rely heavily on complex data tables, diagnostic images, or clinical charts that cannot be adequately described in text ## For Questions/Problems: - ** Extract explicit question-answer pairs ** if they exist (ensure zero references and independence requirements) - ** Prioritize substantive clinical and medical content ** over trivial details or data-dependent conclusions - ** For Disease-related content ** : Create questions about definition, classification, pathophysiology, clinical manifestations, diagnosis, prevention, complications, or risk factors - ** For Drug/Treatment-related content ** : Create questions about drug composition, indications, mechanisms of action, dosage, side effects, or other treatment modalities - ** For Physiological mechanisms ** : Create questions about normal body functions, pathological processes, biochemical mechanisms, or metabolic pathways - ** For Concepts and comparisons ** : Create questions about medical definitions, comparisons between diseases/treatments/approaches, or differential diagnosis - ** Critical ** : Each question must be complete and self-contained, as others will not have access to the original text. - ** Do NOT extract ** : - Questions depending on diagnostic images, complex clinical charts, or detailed lab data tables - Questions requiring extensive clinical case details not fully provided - Questions whose answers are uncertain, speculative without clear indication, or incomplete - Medical advice for specific individual cases (focus on general medical knowledge) - If no valid Q&A content can be extracted following above rules, return exactly: [NO QA] ## For Answers: - ** Process ** : First locate the complete answer in the document, then organize it clearly - If the answer has explanation, reorganize it into a clear, well-structured format - If the answer lacks explanation, add necessary medical reasoning or context - For final answers that need exact matching (multiple-choice, calculations, fill-in-the-blank, true/false), use $ boxed$ notation ## Output Format (STRICT): Use this exact format for parsing: ---BEGIN QA--- Question: 46 C. Prompts for Dataset Construction SII-GAIR Answer: ---END QA--- ---BEGIN QA--- Question: Answer: ---END QA--- If no valid Q&A can be extracted, return exactly: [NO QA] --- Extract: chunk Now process the extract and return the result in the specified format. QA Extraction Prompt for Darwin-Science-Bo ok-QA(Ph ysics) Below is a book document extract. # Extraction Task Extract complete, independently solvable physics content following these guidelines: ## CRITICAL RULES (Must Follow): 1. ** Answer-First Principle ** : Only extract a question if its complete answer exists in the document 2. ** Zero References Requirement ** : - Questions: No references to "the document", "the text", "Figure 1", "Theorem 1.1", "above", "below", etc. - Answers: No references to "as in document", "as shown in text", "see the document","Theorem 1.1" etc. - Replace ALL references with actual content from the document 3. ** Complete Independence ** : - Each question must be self-contained with ALL necessary information - If a question is incomplete, incorporate missing context to make it fully solvable - Multiple questions must be mutually independent (no "as in first Question ", "using previous result") 4. ** Answer Must Exist ** : All answers must be directly found or clearly derivable from the given text - do not extract if uncertain ## For Questions/Problems: - Extract any explicit physics questions ONLY if their answers are present in the document - If you see only solution steps without a question, DO NOT create a question - ** For Laws/Principles with proofs/derivations ** : Create questions asking for the derivation or proof when available - ** For Standalone Laws/Principles ** (without derivation): Create questions about their content, applications, or physical meaning ONLY if the answer is in the text - ** For Formulas ** : Create questions flexibly (e.g., if text derives E=mc², could ask "Derive the mass-energy relation" or "What is the relationship between mass and energy?" or apply it in a scenario) ONLY if the answer content is in the text - ** For Concepts/Definitions ** : Ask about them flexibly, but ensure the complete answer can be found in the document - ** For Phenomena Explanations ** : Create questions naturally based on the content - Extract multiple questions separately if they exist, ensuring each is completely independent without relying on or referencing other questions - If no valid physics Q&A content can be extracted following above rules, return ` [NO QA] ` ## For Answers: - ** Process: First locate the answer in the document, then enhance the reasoning steps ** 47 C. Prompts for Dataset Construction SII-GAIR - Include the provided solution, derivation, or explanation when available - For derivations/proofs, the answer should contain the complete step-by-step process - If the answer already has explanation, reorganize it into a clear and well-structured format for better readability and understanding - If the answer lacks explanation, add necessary intermediate reasoning (physical reasoning, mathematical steps, unit analysis, physical interpretation) - For final answers that need exact matching (multiple-choice, calculations, fill-in-the-blank, true/false), use $ boxed$ notation ## Format: Use this exact format for parsing: ---BEGIN QA--- Question: Answer: ---END QA--- ---BEGIN QA--- Question: Answer: ---END QA--- The extract is as follows: chunk Now process the extract and return the result. QA Extraction Prompt for Darwin-Science-Bo ok-QA(stem-others) Below is a document extract from STEM fields (engineering, applied sciences, technology, interdisciplinary sciences, etc.). # Extraction Task Extract complete, independently solvable STEM Q&A pairs following these strict guidelines: ## CRITICAL RULES (Must Follow): 1. ** Answer-First Principle ** : Only extract a question if its complete answer exists in the document 2. ** Zero References Requirement ** : - Questions: No references to "the document", "the text", "Figure 1", "Table 2", "Equation 3", "above", "below", etc. - Answers: No references to "as in document", "as shown in text", "see Figure", "Equation 1", etc. - Replace ALL references with actual content from the document 3. ** Complete Independence ** : - Each question must be self-contained with ALL necessary information - If a question is incomplete, incorporate missing context to make it fully solvable - Multiple questions must be mutually independent (no "as in first Question", "using previous result") 4. ** Answer Must Exist ** : All answers must be directly found or clearly derivable from the given text - do not extract if uncertain 5. ** Value-Based Selection ** : Focus on extracting the MOST IMPORTANT and EDUCATIONAL content 7. ** No Figure/Table-Dependent Content ** : Do NOT extract questions whose answers rely heavily on complex diagrams, charts, or data tables that cannot be adequately described in text ## For Questions/Problems: - ** Extract explicit question-answer pairs ** if they exist (ensure zero references and independence requirements) 48 C. Prompts for Dataset Construction SII-GAIR - ** Prioritize substantive technical and scientific content ** over trivial details or data-dependent conclusions - ** Create questions about ** : - Principles and theories: fundamental concepts, laws, theoretical frameworks, underlying principles - Formulas and equations: mathematical expressions, relationships, derivations (when describable in text) - Mechanisms and processes: how systems work, operational principles, step-by-step processes - Concepts and definitions: technical terminology, key concepts, classifications - Properties and characteristics: material properties, system characteristics, performance parameters - Comparisons: differences between systems/methods/materials/approaches - ** Critical ** : Each question must be self-contained with all necessary technical context, definitions, conditions, and parameters - ** Do NOT extract ** : - Questions depending on complex diagrams, charts, or detailed data tables - Questions requiring extensive background knowledge not provided in the text - Trivial details without educational or technical significance - Questions whose answers are uncertain or incomplete - If no valid Q&A content can be extracted following above rules, return exactly: [NO QA] ## For Answers: - ** Process ** : First locate the complete answer in the document, then organize it clearly - If the answer has explanation, reorganize it into a clear, well-structured format - If the answer lacks explanation, add necessary technical reasoning or context - For final answers that need exact matching (multiple-choice, calculations, selections, specific values), use $\ boxed{answer}$ notation ## Output Format (STRICT): Use this exact format for parsing: ---BEGIN QA--- Question: Answer: ---END QA--- ---BEGIN QA--- Question: Answer: ---END QA--- If no valid Q&A can be extracted, return exactly: [NO QA] --- Extract: chunk Now process the extract and return the result in the specified format. 49
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment