프리트레인 과학을 연다: daVinci‑LLM의 완전 공개 연구
daVinci‑LLM은 3B 파라미터 모델을 8조 토큰에 걸쳐 두 단계 커리큘럼으로 학습하고, 데이터 다윈주의(L0‑L9) 체계를 적용해 200여 개 실험을 공개한다. 데이터 처리 깊이, 도메인 비율, 혼합 설계, 평가 프로토콜 등 네 가지 핵심 질문에 대한 체계적 탐구 결과를 제공함으로써 프리트레인 단계의 과학적 이해를 크게 진전시킨다.
저자: Yiwei Qin, Yixiu Liu, Tiantian Mi
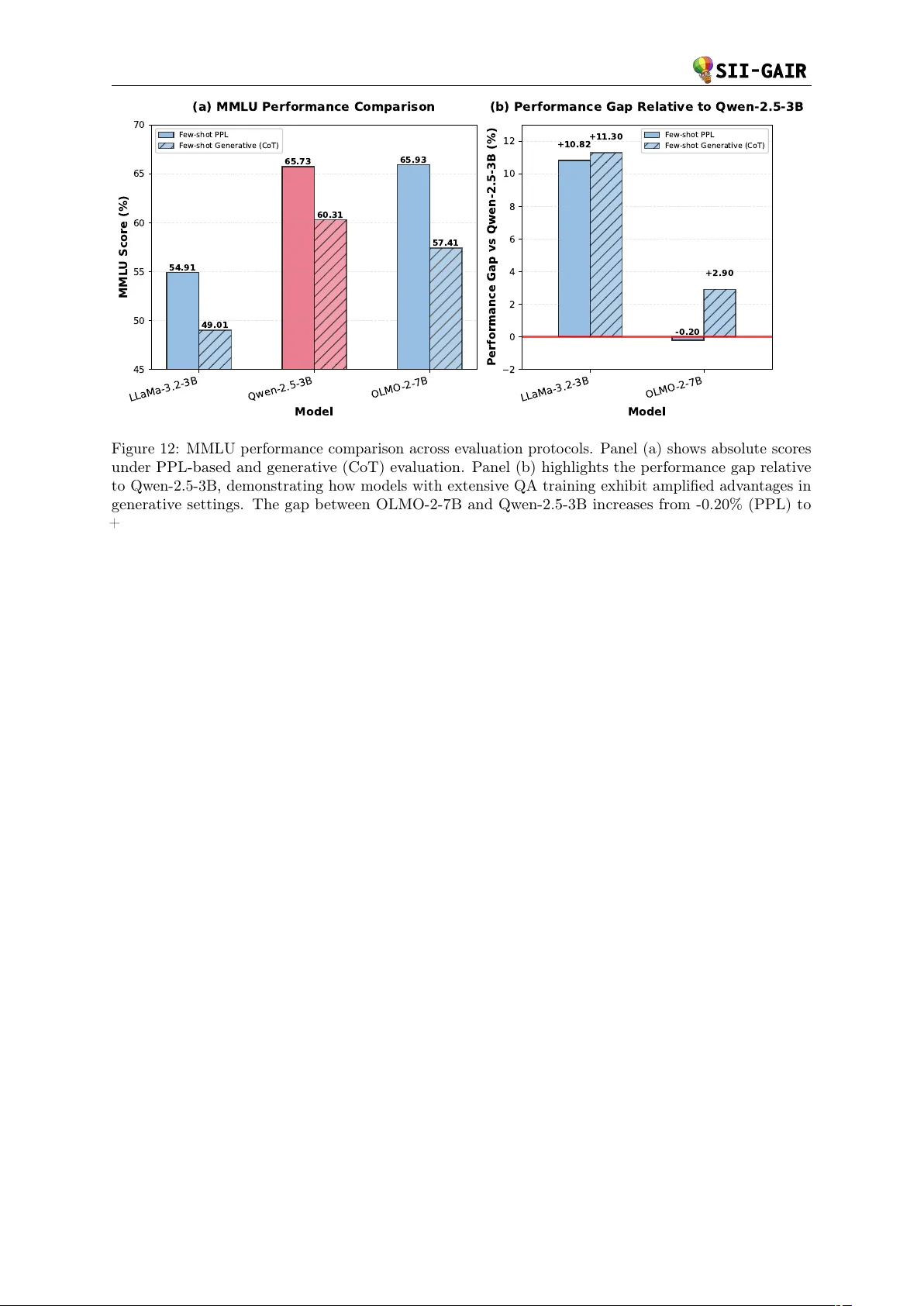
본 연구는 대규모 사전학습(프리트레인) 단계가 언어 모델의 최종 성능을 결정한다는 사실을 강조하면서, 현재 산업과 학계 사이에 존재하는 “자원‑자유도” 패러독스를 해결하고자 한다. 저자들은 대규모 컴퓨팅 인프라를 보유한 기업과 학술적 자유를 갖춘 연구팀이 협업하여, 3 B 파라미터 규모의 LLM을 8 T 토큰에 걸쳐 학습하고, 그 전 과정을 완전 공개한다.
1. **데이터 다윈주의 프레임워크**
- L0부터 L9까지 10단계의 데이터 처리 체계를 정의하고, 각 단계별 목표와 적용 기술을 상세히 기술한다.
- L0(데이터 수집)와 L1(포맷 정규화)에서는 웹 크롤링, PDF OCR, HTML 파싱 등을 통해 원시 데이터를 통합한다.
- L2(규칙 기반 필터링)에서는 중복 제거, 언어 식별, 길이 제한 등 전통적인 규칙을 적용한다.
- L3‑L5에서는 경량 모델 기반 품질 예측, 생성적 정제, 합성 QA 생성 등 점진적인 품질 향상을 위한 모델 기반 방법을 도입한다.
- L6‑L9는 아직 연구 단계이지만, 향후 대규모 LLM을 활용한 자동 요약·재작성·지식 합성까지 확장 가능성을 제시한다.
2. **데이터 풀 구성**
- 일반 웹 텍스트, 코드, 과학 논문, QA 네 개 도메인으로 구분하고, 각 도메인마다 L0‑L9 수준을 명시한다.
- 특히 코드와 과학 도메인은 L4 수준의 생성적 정제를 통해 오류를 교정하고, 도메인 특화 용어와 논리 구조를 강화한다.
3. **학습 레시피**
- **Stage 1 (6 T 토큰)**: 다양한 도메인 비율을 동적으로 조정하면서 기본 언어 능력을 구축한다. 데이터 비율 조정은 “Domain Proportion Adjustment” 전략으로, 초기에는 일반 텍스트 비중을 높이고, 점진적으로 코드·과학 비중을 늘린다.
- **Stage 2 (2 T 토큰)**: 대규모 구조화 QA 데이터와 강화된 코드·과학 데이터를 투입해 추론 능력을 집중 강화한다. 이 단계에서는 “Progressive Intensification”을 적용해 QA 데이터 비중을 단계적으로 증가시킨다.
- 두 단계 모두 학습률 스케줄링, 토큰 마스킹 비율, 혼합 샘플링 비율 등을 세밀히 기록하고, 5 k 스텝마다 체크포인트를 저장한다.
4. **실험 설계와 200+ Ablation**
- **데이터 처리 깊이**: L2 vs L4 vs L5 수준의 데이터가 동일 학습량에서 모델 성능에 미치는 영향을 비교한다. 결과는 처리 깊이가 증가할수록 특히 코드·과학 벤치마크에서 평균 3‑5% 성능 향상을 보였다.
- **도메인 포화 현상**: 각 도메인별 학습 곡선을 분석해 포화 시점을 파악하고, 포화 도메인 비중을 감소시키는 전략이 전체 성능 유지에 도움이 됨을 확인했다.
- **컴포지셔널 밸런스**: 도메인 비율을 급격히 변화시켰을 때 발생하는 성능 붕괴 현상을 방지하기 위한 “Balance‑Intensify” 조합을 검증했다.
- **평가 프로토콜**: 퍼플렉시티(PPL)와 생성 기반(예: MMLU, GSM‑8K) 평가를 동시에 사용해, 각각이 모델의 어느 단계 능력을 반영하는지 메타 분석을 수행했다.
5. **결과**
- 최종 daVinci‑LLM‑3B는 기존 3 B 모델 대비 일반 지식·코드·수학·추론 영역에서 평균 4‑6% 향상을 기록했으며, 7 B 규모 모델인 OLMo‑7B와 비슷한 종합 점수를 달성했다.
- 데이터 처리 깊이가 모델 능력 상한을 확장하는 핵심 차원임을 실증했으며, 도메인별 포화 동역학을 고려한 적응형 커리큘럼이 성능 저하 없이 특정 능력을 집중 강화할 수 있음을 보여준다.
6. **공개 자료**
- 원시 데이터 수집 스크립트, 전처리 파이프라인, L0‑L9 라벨링 파일, 학습 로그, 중간 체크포인트, 전체 평가 스위트, 부정 실험 결과 등을 모두 GitHub와 HuggingFace에 공개한다. 이는 향후 연구자들이 동일 조건을 재현하거나 새로운 변수를 추가해 비교 연구를 수행할 수 있는 기반을 제공한다.
7. **의의와 향후 과제**
- 프리트레인 단계에 대한 과학적 탐구가 가능하도록 “오픈니스 자체를 연구 방법론”으로 설정한 점이 가장 큰 기여이다.
- 아직 L6‑L9 단계의 자동 합성·지식 재구성 기술은 초기 단계이며, 향후 대규모 LLM을 활용한 데이터 생성·정제 파이프라인을 확장하는 연구가 필요하다.
- 또한, 평가 프로토콜의 다양화와 표준화가 모델 능력의 진정한 측정을 위해 지속적으로 논의되어야 한다.
요약하면, daVinci‑LLM은 데이터 처리 깊이, 도메인 비율, 혼합 설계, 평가 프로토콜이라는 네 축을 체계적으로 탐구하고, 그 전 과정을 완전 공개함으로써 프리트레인 과학을 한 단계 끌어올린 선구적 연구라 할 수 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기