ScoutAttention: Efficient KV Cache Offloading via Layer-Ahead CPU Pre-computation for LLM Inference
Large language models encounter critical GPU memory capacity constraints during long-context inference, where KV cache memory consumption severely limits decode batch sizes. While existing research has explored offloading KV cache to DRAM, these appr…
Authors: Qiuyang Zhang, Kai Zhou, Ding Tang
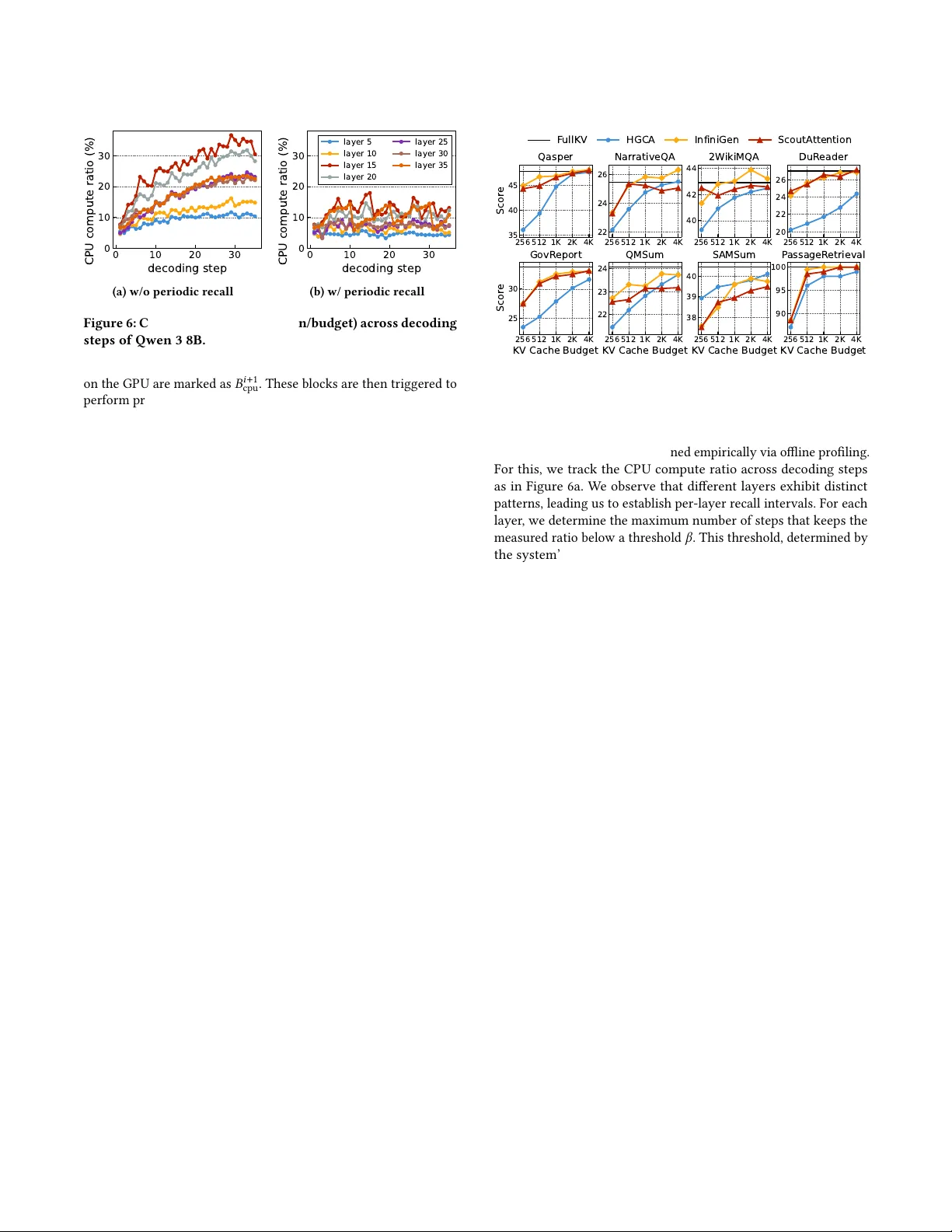
ScoutAention: Eicient K V Cache O loading via Layer- Ahead CP U Pre-computation for LLM Inference Qiuyang Zhang Huazhong University of Science and T echnology Wuhan, China qyzhang@hust.edu.cn Kai Zhou Huazhong University of Science and T echnology Wuhan, China kezzy@hust.edu.cn Ding T ang Huazhong University of Science and T echnology Wuhan, China dinger@hust.edu.cn Kai Lu ∗ Huazhong University of Science and T echnology Wuhan, China kailu@hust.edu.cn Cheng Li Huawei T echnologies Hefei, China licheng56@huawei.com Zhenyu Y ang Huawei T echnologies Hefei, China yangzhenyu33@huawei.com Peng Xu Research Center for High Eciency Computing Infrastructure Zhejiang Lab Hangzhou, China xup@zhejianglab.com Jiguang W an Huazhong University of Science and T echnology Wuhan, China jgwan@hust.edu.cn Abstract Large language models encounter critical GP U memory capacity constraints during long-context inference , where KV cache mem- ory consumption severely limits decode batch sizes. While exist- ing research has explored ooading K V cache to DRAM, these approaches either demand frequent GP U-CP U data transfers or impose e xtensive CP U computation requirements, resulting in poor GP U utilization as the system waits for I/O operations or CP U processing to complete. W e propose ScoutAttention, a novel KV cache ooading frame- work that accelerates LLM inference through collaborative GP U- CP U attention computation. T o prevent CP U computation from bottlenecking the system, ScoutAttention introduces GP U-CP U collaborative block-wise sparse attention that signicantly reduces CP U load. Unlike conventional parallel computing approaches, our framework features a novel layer-ahead CPU pre-computation al- gorithm, enabling the CP U to initiate attention computation one layer in advance, complemented by asynchr onous periodic recall mechanisms to maintain minimal CP U compute load. Experimental results demonstrate that ScoutAttention maintains accuracy within 2.4% of baseline while achieving 2.1x speedup compared to e xisting ooading methods. ∗ Kai Lu is the corresponding author This work is licensed under a Creative Commons Attribution-NonCommercial- NoDerivatives 4.0 International License. DA C ’26, Long Beach, CA, USA © 2026 Copyright held by the owner/author(s). ACM ISBN xxxxxxx xxxxxx xxxxxx xxxxxx https://doi.org/xxxx xxxxxx xxxxxx xxxxxx x A CM Reference Format: Qiuyang Zhang, Kai Zhou, Ding T ang, Kai Lu, Cheng Li, Zhenyu Y ang, Peng Xu, and Jiguang W an. 2026. ScoutAttention: Ecient KV Cache Of- oading via Layer- Ahead CP U Pre-computation for LLM Inference. In 63rd A CM/IEEE Design Automation Conference (DA C ’26), July 26–29, 2026, Long Beach, CA, USA. ACM, New Y ork, NY, USA, 7 pages. https://doi.org/ xxxx xxxxx xxxxx xxxxx xxxx 1 Introduction In recent years, Large Language Models (LLMs) have achieved un- precedented progress across a wide range of application domains [ 13 ]. Traditionally , these advances have been driven by increas- ing model size and training data—a paradigm known as train-time scaling [ 7 ]. However , with the diminishing returns of train-time scaling, the eld is gradually shifting toward inference-time scaling strategies [ 17 ]. Pioneered by models such as OpenAI’s o1 [ 6 ] and DeepSeek-R1 [ 4 ], inference-time scaling signicantly extends out- put length through a “think-before-answer” appr oach, employing chain-of-thought (Co T) r easoning that enables models to perform more extensive computation during infer ence. Concurrently , to fully harness the capabilities of LLMs, real- world applications increasingly dep end on sophisticated context en- gineering techniques [ 12 ]. Approaches such as Retrieval- A ugmented Generation (RA G) [ 9 ] and few-shot prompting inject contextual information into prompts, resulting in longer inputs that enable LLMs to better understand user queries and produce mor e accurate responses. While these two trends, extending input length through context engineering and extending output length through chain-of-thought reasoning, have signicantly improved LLM performance, their convergence places substantial pressure on the deco ding stage. Specically , the decoding is b ottlenecked by GP U memory capacity . Since decoding is memor y-bound, eective batching is crucial for DA C ’26, July 26–29, 2026, Long Beach, CA, USA Qiuyang Zhang et al. improving GP U utilization and throughput. However , GP U memory capacity constraints limit the maximum batch size, as longer se- quences consume substantially more memory . For example, given that a 32k-token Qwen3-32B request consumes 8GB for the KV cache, the total memory usage (including weights and activations) on an 80GB GP U limits the batch size to one, which greatly limits inference throughput. T o address the memor y bottleneck, existing work attempts to ooad part of the KV cache to DRAM during inference. For ex- ample, InniGen [ 8 ] ooads less important tokens to DRAM after the prell phase, retaining only a subset of tokens on the GP U to reduce memory usage. During the decode stage, it predicts the important tokens for the next layer one-layer-ahead and prefetches them back to the GP U. Although this approach mitigates the GP U memory capacity constraint, it introduces a new I/O b ottleneck. W e observe that in InniGen, even with prefetching, slow I/O causes the GP U to stall for 61% of the end-to-end execution time, leading to a substantial performance degradation. Beyond recall-base d K V cache ooading metho ds, there also exist co-attention approaches that compute attention directly on the CP U. For example , HGCA [ 3 ] avoids recalling KV tokens back to the GP U; instead, tokens ooaded to the CP U are processed concurrently on the CP U alongside GPU computation. Although this parallel attention strategy eliminates the I/O bottleneck in recall-based methods, it introduces a new compute bottleneck on the CP U. Giv en that GP U attention computation is approximately 20x faster than CP U, this parallel execution scheme still results in GP U idle time. Our experimental results reveal that with HGCA, the GP U remains idle for 57% of its e xecution time while waiting for CP U attention computation to complete. W e propose ScoutAttention , an ecient KV cache ooading framework for LLM inference . Since CP U-side attention computa- tion achieves higher eective thr oughput than PCIe data transfer , ScoutAttention adapts a co-attention strategy to eliminate slow recall I/O. T o prevent CP U computation from b ecoming the new performance bottleneck, ScoutAttention introduces a novel layer- ahead CP U pre-computation mechanism. Unlike conventional parallel execution, this approach initiates CP U computation one layer in advance, eectively hiding latency through pipelining. Building on this foundation, ScoutAttention implements GP U-CP U collaborative block-wise sparse attention , which strategically retains only the most critical K V cache blocks on the GP U while ooading the remainder to CP U memory . Our ke y observation is that the importance distribution of KV cache blocks exhibits strong temporal lo cality—adjacent decode tokens typically attend to highly overlapping sets of important blocks. By exploiting this property , ScoutAttention limits CP U computation to only a small subset of top-k blocks not present in the GP U cache , signicantly reducing computational overhead while preserving model accuracy . Moreover , to avoid increased CP U workload caused by temporal drift in the set of important blocks, we introduce asynchronous periodic K V cache recall , which periodically recalls imp ortant KV blo cks to the GP U to correct the drift. Unlike prior recall-based methods, periodic recall in ScoutAttention is issued only after a layer nishes. Compared with InniGen’s one-lay er-ahead recall, our asynchronous design stretches the I/O window from a single G PU at tn i m l p i at tn i +1 m l p i +1 la y er i l a y e r ( i + 1 ) G PU at tn i m l p i at tn i +1 m l p i +1 la y er i l a y e r ( i + 1 ) (a) Full Attention: high attention computation under long-context. G PU PC Ie at tn re c a ll i +1 at tn re c a ll i +2 a t tn re c a ll i a t tn i m l p i ml p i +1 to p k i +2 to p k i +1 bu bbl es la y er i la y er ( i + 1 ) 6 1 % a t tn i +1 G PU PC Ie at tn re c a ll i +1 at tn re c a ll i +2 a t tn re c a ll i a t tn i m l p i ml p i +1 to p k i +2 to p k i +1 bu bbl es la y er i la y er ( i + 1 ) 61 % a t tn i +1 (b) InniGen: pipeline bubbles due to slow KV cache recall. GPU CPU at tn i m l p i at tn i +1 m l p i +1 at tn cp u i +1 to pk i +1 .. . to p k i b u b b l e s l a y e r i l a y e r ( i + 1 ) 5 7 % a t tn cp u i GPU CPU at tn i m l p i at tn i +1 m l p i +1 at tn cp u i +1 to pk i +1 .. . to p k i b u b b l e s l a y e r i l a y e r ( i + 1 ) 5 7 % a t tn cp u i (c) HGCA: pipeline bubbles due to slow CP U-side computation. G PU CPU at tn i m l p i a t tn cp u i +1 to p k i +1 at tn i +1 m l p i +1 a t tn cp u i +2 to pk i +2 PCIe a syn c p e r io d ic reca ll i .. . cpu i l a y e r i l a y e r ( i + 1 ) .. . .. . G PU CPU at tn i m l p i a t tn cp u i +1 to p k i +1 at tn i +1 m l p i +1 a t tn cp u i +2 to pk i +2 PCIe a syn c p e r io d ic reca ll i .. . cpu i l a y e r i l a y e r ( i + 1 ) .. . .. . (d) ScoutAttention: ecient inference pip eline through layer-ahead CP U pre-computation. Figure 1: Inference pipeline of dierent KV cache o loading methods. layer to an entire decode step of one token, ensuring that the GP U never stalls waiting for I/O . W e implement ScoutAttention on SGLang [23] and evaluate its accuracy and performance across multiple datasets. The results show that the average accuracy degradation of ScoutAttention compared with full attention is less than 2.1%, while its decod- ing throughput reaches 5.1x that of full attention and 2.1x that of existing ooading methods. 2 Background and Motivation 2.1 LLM Inference and Prell-Decode Disaggregation Large language models (LLMs) implement autoregressive sequence modeling with a deep stack of Transformer blocks [ 16 ], each com- prising multi-head attention and a feed-for ward network (FFN) with residual connections. During inference, this architecture operates in two distinct phases. The prell phase processes the entire input prex in one pass, gen- erating and storing the 𝐾 and 𝑉 vectors in the K V cache . The decode phase then produces tokens autoregressiv ely , r eusing the cached K/V to compute each subsequent token. Prell is compute- bound due to its highly parallel workload, whereas decode is memory- bound as it repeatedly accesses the expanding K V cache. These contrasting resource demands lead to p erformance in- terference when both phases share the same hardware. Prell- Decode disaggregation addresses this by running the two phases on separate, specialized compute clusters, enabling b etter resource utilization, lower tail latency , and more reliable SLO compliance [24][14]. ScoutAention: Eicient K V Cache Oloading via Layer-Ahead CPU Pre-computation for LLM Inference DA C ’26, July 26–29, 2026, Long Beach, CA, USA 4 16 64 256 1024 4096 Size (KB) 0 5 10 15 20 Bandwidth (GB/s) Figure 2: I/O bandwidth be- tween GP U and CP U. 0 1 2 3 4 T ime (s) 0 20 40 GPU Utilization (%) HGCA InfiniGen Figure 3: Low GP U utilization of HGCA and InniGen. 2.2 Sparse Attention Attention exhibits inherent sparsity , with fewer than 20% of tokens accounting for more than 80% of the total attention weights. Build- ing on this observation, a growing body of work [ 22 ][ 15 ][ 18 ][ 10 ] propose sparse attention algorithms that reduce computation by se- lectively involving only the most inuential tokens in the attention computation. Among these sparse attention algorithms, block-wise sparsity has attracted considerable interest. It segments the KV cache into xed-size blo cks and summarizes each block with a block digest 𝐾 digest . During attention computation, the top-k important blocks are selected according to the dot product between 𝑄 and 𝐾 digest . Dierent block-wise sparse methods adopt dierent strategies for generating block digests. For e xample, Quest [ 15 ] constructs digests using channel-wise min/max pooling over 𝐾 , MoBA [ 11 ] uses mean pooling of 𝐾 , and NSA [ 21 ] incorporates a learnable Multi-Layer Perceptron (MLP) to generate digests from 𝐾 . 2.3 Related W ork and Motivation T o mitigate the large GP U memory footprint asso ciated with long- context processing, recent studies have investigated ooading the KV cache to DRAM. These approaches fall into two primar y strate- gies: recall-based method and co-attention approach. Figure 1 illus- trates the pipeline of dierent methods. Recall-based o loading. Recall-based approaches involve reload- ing the K V cache back to GP U memory when ne eded for computa- tion. For example, InniGen ooads most tokens to DRAM while keeping only critical tokens on the GP U. During attention com- putation, it introduces a predictive mechanism that identies the important tokens for the next layer and initiates the recall I/O one layer in advance, enabling ov erlap between I/O and computation. Howev er , interconnection bandwidth p oses a critical bottleneck for these methods. Figure 2 demonstrates the sev ere I/O bandwidth constraints between a 80GB HBM GP U and CP U, which communi- cate through a PCIe 4x16 interface. With a KV cache size of roughly 4 KB per token p er layer , the eective I/O bandwidth is only 800 MB/s. Even when transferring at a coarser granularity using a page size of 32 tokens (128 KB), the bandwidth increases to about 15 GB/s, which remains low compared with the 1.9 TB/s HBM band- width. Our evaluation r eveals that despite InniGen’s sophisticated one-layer-ahead pr efetching strategy , the GP U remains idle for 61% of execution time at a batch size of 40, r esulting in very low GP U utilization, as shown in Figure 3. Co-attention approach. For the co-attention approach, tokens ooaded to DRAM are computed directly on the CPU. For instance , G P U - CP U S p ar s e C o - att ent ion Inf erenc e K ernel Top - K K ernel Lay e r - a he a d CP U P r e - com pu t atio n As yn c P er io d ic KV Cac he Re ca l l GP U CPU HB M DRA M K V C a c h e B lo c k D i g e s t K V C ac he S Ms I/O wo r k e r s CPU wo r k ers CPU wo r k ers Co r e s § 3 .2 § 3 . 3 § 3 . 4 Figure 4: O verall architecture of ScoutAttention. HGCA [ 3 ] retains only a sliding window of 25% tokens on the GP U, ooading the remaining 75% tokens to the CP U. During computation, the GP U and CP U execute in parallel: the GP U-side performs full attention calculation, while the CP U-side employs sparse attention based on moving average attention weights. Although this co-attention approach eliminates the slow I/O bottleneck present in recall-based methods, it intr oduces a new bot- tleneck caused by the signicant computational disparity b etween the CPU and GP U. In decoding-phase attention, the GP U is roughly 20x faster than the CP U. Consequently , the parallel execution in HGCA results in about 57% GP U idle time under batch size of 40. 3 Design of ScoutAttention 3.1 Overview W e present ScoutAttention, a GP U-CP U collaborative sparse at- tention mechanism designed for ecient K V cache ooading. T o maximize performance, ScoutAttention is built on three key de- sign principles: 1) GP U-CP U co-attention , which mitigates PCIe bandwidth b ottlenecks; 2) CP U-side pre-computation , which hides CP U compute latency; and 3) integration with block-wise sparse attention , which reduces the CP U’s computational burden. Figure 4 illustrates the overall architecture of ScoutAttention. During the deco ding stage, ScoutAttention ooads most unim- portant KV blo cks to DRAM while retaining only block digests and a small set of important blocks on the GP U. During attention computation, we employ GP U-CP U cooperative sparse attention, where the top-k blocks are processed using a near-data computing approach (§3.2). T o prevent slow CP U-side attention computation from becoming the system bottleneck, we introduce a novel layer- ahead CP U pre-computation algorithm (§3.3). In addition, to correct importance drift as decoding progresses, we propose an asynchro- nous periodic recall me chanism that keeps the CP U’s computational load low (§3.4). 3.2 GP U-CP U Collaborative Block-wise Sparse Attention In modern AI servers, the CP U’s attention computation throughput (KV cache size divided by compute time) is signicantly higher DA C ’26, July 26–29, 2026, Long Beach, CA, USA Qiuyang Zhang et al. : [ 2 ,5 ,7 ] : [ 1 ,5 ,7 ] sco res b lo ck d ig e st kv b l o ck kv b l o ck GPU m e rge 0 1 2 3 4 5 6 7 0 1 2 3 4 5 6 7 to p - k to p - k \ \ CP U a t te n tio n flo w G P U a t te n tio n flo w a t te n tio n 𝑄 𝑖 𝑄 𝑖 𝑊 𝑄 𝑖 𝑋 𝑖 𝐵 𝑝 𝑟 𝑒 𝑑 𝐵 𝑔 𝑝 𝑢 𝐵 𝑝 𝑟 𝑒 𝑑 𝐵 𝑔 𝑝 𝑢 0 4 0 4 1 5 1 5 2 6 2 6 3 7 3 7 0 4 1 5 2 6 3 7 CPU 0 4 1 5 2 6 3 7 CPU × 𝑄 𝑝 𝑟 𝑒 𝑑 𝑖 × 𝑄 𝑝 𝑟 𝑒 𝑑 𝑖 × proje ct proje ct a t te n tio n 1 5 7 1 5 7 𝑋 𝑖 − 1 𝑊 𝑄 𝑖 Figure 5: W orkow of GP U-CP U collaborative block-wise sparse attention with layer-ahead CP U pre-computation. than the KV cache transfer throughput over PCIe. A 36-cor e CP U can achie ve an attention computation throughput of appr oximately 100 GB/s. Ho wever , as discussed in Sec. 2.3, the PCIe bandwidth for KV cache transfer reaches only about 15 GB/s. Motivated by this disparity , we adapt GP U–CP U co-attention rather than K V cache recall to enable ecient K V cache ooading. Unlike HGCA, which performs the entire sparse attention com- putation on the CP U, our design executes cooperative block-wise sparse attention across both CP U and GP U. As demonstrated in prior works (§ 2.2), block-wise sparse attention has been exten- sively validated for accuracy . In this paper , we employ Quest as our sparsication method; however , ScoutAttention is fully compatible with other sparsication algorithms such as DeepSeek NSA [21]. Building on block-wise sparse attention, ScoutAttention ooads less important KV cache blocks to DRAM while retaining only com- pact digests of each block and a xed subset of critical blocks in GP U memory . During attention computation, the GP U rst identies the top-k blocks by computing the dot product b etween the query and each block’s digest. It then processes the blocks that reside on the GP U, while the fraction of top-k blocks that are not r esident on the GP U are compute d on the CP U. Finally , the intermediate results from both devices are merged on the GP U using the FlashAttention algorithm [ 2 ][ 19 ] to produce the nal attention output. Figure 5 shows the overall w orkow of ScoutAttention. This partitioning strategy is highly eective because important blocks exhibit strong temporal locality across adjacent tokens. As shown in Figure 6a, on av erage less than 15% of important blocks change between consecutive tokens. Since the GP U retains the important blocks identie d in the pr eceding steps, the CP U needs to process only a small fraction of top-k blocks that not r esident on the GP U in ScoutAttention, substantially reducing its computational overhead. 3.3 Layer- Ahead CP U Pre-computation T o further prevent CP U computation from becoming a bottlene ck, we propose layer-ahead CP U pre-computation , a novel tech- nique that allows CP U-side attention computation to b egin one layer ahead of the GP U’s execution. Algorithm 1 Layer-ahead CPU Pre-computation 1: Input: layer i’s input 𝑋 𝑖 , query projection weight 𝑊 𝑄 , block digest 𝐾 digest . 2: Output: layer i’s attention output 𝐴 𝑖 . 3: ⊲ T rigger next layer’s CP U-side pre-computation ⊳ 4: 𝑄 𝑖 + 1 pred ← 𝑊 𝑖 + 1 𝑄 𝑋 𝑖 ⊲ Get predict query of next layer 5: 𝐵 𝑖 + 1 pred ← T opK ( 𝑄 𝑖 + 1 pred 𝐾 𝑖 + 1 digest ⊤ ) ⊲ Predict top-k blocks 6: 𝐵 𝑖 + 1 cpu ← 𝐵 𝑖 + 1 pred \ 𝐵 𝑖 + 1 gpu ⊲ Blocks reside in CP U 7: spawn CP U A ttn ( 𝐵 𝑖 + 1 cpu ) ⊲ Async CP U pre-computation 8: ⊲ Compute current layer’s attention ⊳ 9: 𝑄 𝑖 ← 𝑊 𝑖 𝑄 𝑋 𝑖 10: 𝐴 𝑖 gpu ← GP U A ttn ( 𝑄 𝑖 , 𝐵 𝑖 gpu ) 11: ⊲ Merge with 𝐴 𝑖 cpu triggered in pre vious layer ⊳ 12: 𝐴 𝑖 ← Merge ( 𝐴 𝑖 gpu , 𝐴 𝑖 cpu ) 13: return 𝐴 𝑖 T able 1: Cosine similarity between predict quer y and real query . Qwen 3 8B Gemma 3 12B Llama 3.1 8B Mistral 7B GLM 4 9B 0.94 0.93 0.96 0.97 0.94 As illustrated in Figure 1, ScoutAttention employs a pipelined execution strategy . While computing attention for layer i on the GP U, ScoutAttention rst identies the top-k important blocks for layer i+1. This enables proactiv e triggering of CP U-side attention computation for layer i+1, allowing it to run in parallel with the GP U’s processing of layer i. The GP U then computes the attention for layer i and merges it with the CP U-side attention r esults that were triggered during layer i-1. T o enable CP U-side pre-computation, the key challenge is deter- mining ho w to obtain layer i+1’s attention query at layer i. Inspired by InniGen, which observes that the inputs of conse cutive layers are highly similar due to r esidual connections, we hypothesize that it is p ossible to approximate 𝑄 𝑖 + 1 by applying the ne xt layer’s quer y projection matrix 𝑊 𝑖 + 1 𝑄 to the current layer’s input 𝑋 𝑖 , yielding a predicted query 𝑄 𝑖 + 1 pred . T o validate this hypothesis, we conducted experiments across various mo dels and observed that the cosine similarity b etween 𝑄 𝑖 + 1 pred and 𝑄 𝑖 + 1 remains consistently high, as shown in T able 1. This conrms that the pr edicted quer y pro vides a reliable approximation for CPU-side pre-computation. Building on this, we design a pre-computation algorithm as de- scribed in Algorithm 1 and illustrated in Figure 5. When the GP U is computing layer i, it rst predicts the next lay er’s query represen- tation 𝑄 𝑖 + 1 pred by applying the projection matrix 𝑊 𝑖 + 1 𝑄 to the current layer’s input 𝑋 𝑖 . Using 𝑄 𝑖 + 1 pred and the next layer’s digest key 𝐾 𝑖 + 1 digest , the model then identies the imp ortant blocks of the next layer by computing the dot product between them and selecting the top-k blocks, denoted as 𝐵 𝑖 + 1 pred . Next, we compare 𝐵 𝑖 + 1 pred with the blocks already resident in GP U memory 𝐵 𝑖 + 1 gpu . The blocks that are not yet ScoutAention: Eicient K V Cache Oloading via Layer-Ahead CPU Pre-computation for LLM Inference DA C ’26, July 26–29, 2026, Long Beach, CA, USA 0 10 20 30 decoding step 0 10 20 30 CPU compute ratio (%) (a) w/o periodic recall 0 10 20 30 decoding step 0 10 20 30 CPU compute ratio (%) layer 5 layer 10 layer 15 layer 20 layer 25 layer 30 layer 35 (b) w/ periodic recall Figure 6: CP U compute ratio (#token/budget) across deco ding steps of Qwen 3 8B. on the GP U are marked as 𝐵 𝑖 + 1 cpu . These blocks are then triggered to perform pre-computation on the CP U. After completing this setup of layer i+1’s CP U-side pr e-computation, the GP U proceeds with layer i’s attention computation. It rst performs the GP U-side atten- tion to produce 𝐴 𝑖 gpu , and then merges this result with the CP U-side output 𝐴 𝑖 cpu , which was pr e-computed during the pre vious layer , to obtain the nal attention output 𝐴 𝑖 . Instead of executing CP U operations concurrently with GP U computation, our pre-computation strategy leverages the entire transformer layer’s processing window for CP U-side attention computation. This extended window spans GP U-side attention, feed-for ward networks, and QKV projections. On an 80G HBM GP U running Qwen3-32B with a 4k sparsication budget, atten- tion computation alone requires 300us, while the complete trans- former layer consumes 900us during decoding. This layer-ahead pre-computation thus grants the CP U 3x more processing time com- pared to parallel computation approaches, eectively eliminating GP U idle periods. 3.4 Asynchronous Perio dic K V Cache Recall As decoding progresses, the set of important KV cache blocks grad- ually shifts. Because the CP U handles the KV blocks that are not resident on the GP U, whereas the GP U retains the important blo cks identied after the pr ell phase, this shift causes the CPU to process an increasingly large portion of tokens. Figure 6a illustrates the CP U compute ratio, dened as the numb er of tokens computed on the CP U relative to the sparse budget size at each decoding step. The ratio is low in the early decoding steps but shows a steady upward trend as generation proceeds, reecting the drift in block importance. T o mitigate p erformance degradation, we propose an asynchro- nous periodic K V cache recall mechanism. This process refreshes GP U-resident context by strategically recalling important blocks from DRAM at regular intervals. W e recognize that the PCIe inter- connection is a signicant b ottleneck for ne-graine d K V cache transfers. Therefore, our design is centered on two principles: min- imizing recall frequency and moving the data transfer operation o the critical inference path. Specically , if the system decides to trigger a recall at layer i of decoding step m, ScoutAttention initiates the I/O operation after the attention computation for layer i is complete. This asynchronous approach provides a sucient time window for the transfer , as the recalled blocks are not required 256 512 1K 2K 4K 35 40 45 Scor e Qasper 256 512 1K 2K 4K 22 24 26 Nar rativeQA 256 512 1K 2K 4K 40 42 44 2W ikiMQA 256 512 1K 2K 4K 20 22 24 26 DuR eader 256 512 1K 2K 4K KV Cache Budget 25 30 Scor e GovR eport 256 512 1K 2K 4K KV Cache Budget 22 23 24 QMSum 256 512 1K 2K 4K KV Cache Budget 38 39 40 S AMSum 256 512 1K 2K 4K KV Cache Budget 90 95 100 P assageR etrieval F ullKV HGCA InfiniGen ScoutA ttention Figure 7: Results on LongBench of dierent metho ds. by the GP U until layer i of the next decoding step m+1—typically oering a window exceeding 20ms. The recall interval is determined empirically via oine proling. For this, we track the CP U compute ratio across decoding steps as in Figure 6a. W e obser ve that dierent layers exhibit distinct patterns, leading us to establish p er-layer r ecall inter vals. For each layer , we determine the maximum number of steps that ke eps the measured ratio below a threshold 𝛽 . This threshold, determined by the system’s GP U/CP U computational power ratio and intercon- nection bandwidth, balances CP U computation overhead against I/O volume. Based on our empirical analysis, we set the default threshold at 12%. Figure 6b illustrates the impro ved CP U compute ratio achieved through our asynchronous periodic KV cache recall mechanism, where the average CP U compute ratio is 8.2% and the average recall interval across all layers is 8.7. 4 Implementation and Evaluation W e implement ScoutAttention on SGLang [ 23 ], one of the most widely used inference frameworks. T o eciently identify the top-k blocks, we implement a block-wise top-k selection CUD A kernel based on FlashInfer [ 20 ]. For CP U-side attention computation, we build an optimized CP U attention worker using IPEX (Intel Exten- sion for Py T orch) [ 5 ]. W e further partition CPU threads into gr oups, with each group handling one sequence in the batch, thereby im- proving ov erall attention computation throughput. 4.1 Baselines W e select three baselines: FullKV , which corresponds to a vanilla Transformer; InniGen, a recall-base d KV cache ooading method; and HGCA, a co-attention-based K V cache ooading approach. All baselines are implemented in SGLang to ensure a fair comparison. 4.2 Accuracy Benchmark W e use LongBench [ 1 ], a widely adopted long context understand- ing b enchmark for LLMs, to evaluate the accuracy of ScoutAttention. W e select eight datasets, including Qasper , NarrativeQA, 2WikiMQA, DuReader , GovReport, QMSum, SAMSum, and PassageRetrieval. These datasets cover a variety of tasks including single document Q A, multi do cument QA, summarization, and message retrieval. The context lengths reach up to 64k tokens. DA C ’26, July 26–29, 2026, Long Beach, CA, USA Qiuyang Zhang et al. 8192 16384 32768 65536 102400 Input L ength 0 250 500 750 1000 Thr oughput (tok/s) F ullKV HGCA InfiniGen ScoutA ttention Figure 8: Decode throughput of dierent methods under vary- ing input length. W e evaluate ScoutAttention and baselines across dierent budget sizes, with all experiments conducted using the Qwen 3 8B model. As shown in Figur e 7, ScoutAttention maintains robust accuracy across datasets. The slight accuracy drop relative to InniGen comes from using predicted queries for CP U side attention computation. Howev er , b ecause the cosine similarity b etween predicted and real queries is very high (see T able 1) and CP U-side computation ac- counts for only 8% of the total budget (§3.4), replacing real queries with predicted ones introduces minimal accuracy loss. Compared with full attention, ScoutAttention’s accuracy decreases by only 2.5% on average at a budget size of 1024 and 2.1% at a budget size of 2048. 4.3 Performance Evaluation In performance evaluations, we focus solely on the de code instances in Prell–Decode disaggregation architectures, evaluating only the decode phase while the prell phase is handled separately . For all baseline methods, the sparse budget is xe d at 2,048 tokens, and the block size in ScoutAttention is set to 32. All experiments in this section are conducted using the Qwen 3 14B model. Overall throughput. W e rst evaluate de coding throughput un- der varying input lengths. As shown in Figure 8, ScoutAttention con- sistently achieves the highest throughput across dierent sequence lengths. Moreover , as the input length increases, the spee dup ov er FullKV grows steadily due to FullK V’s severe memory-capacity bottleneck. At an input length of 64k, ScoutAttention attains a 5.1x speedup over FullK V . For HGCA and InniGen, the large GP U idle time caused by I/O bottlenecks and CP U compute bottlenecks (§2.3) results in throughput that is ev en lower than FullKV at an 8k input length. Although both methods ev entually surpass FullKV at larger input lengths, ScoutAttention still delivers up to a 2.1x sp eedup compared to them. Impact of batch size and block size. Figure 9 illustrates through- put scaling across batch sizes for a 32k input length. HGCA and InniGen exhibit sublinear scaling and achieve only 1.31x and 1.21x speedups when increasing the batch size from 16 to 32, as they are constrained by CP U compute and I/O bottlenecks. In contrast, ScoutAttention demonstrates better scalability , achie ving a 1.78x speedup from batch 16 to 32 and a 1.48x sp eedup from batch 32 to 64. Figure 10 illustrates the throughput of ScoutAttention on three dierent block sizes. As the block size increases, the total number of blocks decreases. This reduces the size of the digest cache used 16 32 64 Batch Size 0 250 500 750 Thr oughput (tok/s) HGCA InfiniGen ScoutA ttention Figure 9: Deco de throughput under dierent batch size. 16 32 64 Block Size 0 200 400 600 800 Thr oughput (tok/s) Figure 10: Deco de through- put under varying block size. F ullKV HGCA InfiniGen Ours 0 25 50 75 100 P er centage (%) A ttention FFN T opk Idle Figure 11: Latency Breakdo wn. w/o PC&PR w/o PR Ours 0 200 400 600 800 Thr oughput (tok/s) Figure 12: Ablation study . for block selection, freeing up memory to support larger batch sizes and enhancing decode throughput. Latency breakdown. Figure 11 presents the end-to-end latency breakdown, where idle represents GP U stalls due to CP U computa- tion dependencies or PCIe data transfers. HGCA experiences sev ere CP U compute bottlenecks, with idle time comprising 57% of total latency . InniGen performs even worse, with idle time rising to 61% due to signicant I/O bottlene cks. In contrast, ScoutAttention dramatically reduces idle time to merely 6% by minimizing CP U computation and employing CP U-side pre-computation. Ablation study . W e perform an ablation study on ScoutAttention to quantify the performance contribution of each optimization. As shown in Figure 12, “PC” refers to pre-computation and “PR” to pe- riodic recall. By hiding CP U compute latency through layer-ahead pre-computation, PC achiev es a 1.39x speedup. Meanwhile, asyn- chronous periodic KV -cache recall provides an additional 1.20x speedup by reducing the CP U compute load. 5 Conclusion W e propose ScoutAttention, an ecient GP U–CP U co-attention mechanism for KV cache ooading. T o enable high-performance CP U-side computation, we introduce a novel layer-ahead CP U pre-computation algorithm paired with an asynchronous periodic recall mechanism. Experimental results show that ScoutAttention achieves only a 2.1% accuracy drop while delivering up to a 5.1x speedup compared to full attention. Acknowledgments This work was sp onsored by the National Key Research and De- velopment Program of China under Grant No.2023YFB4502701, the National Natural Science Foundation of China under Grant No.62502170 and No.62302465, the China Postdo ctoral Science Foun- dation under Grant No.2024M751011, and the Postdoctor Project of Hubei Province under Grant No.2024HBBHCXA027. ScoutAention: Eicient K V Cache Oloading via Layer-Ahead CPU Pre-computation for LLM Inference DA C ’26, July 26–29, 2026, Long Beach, CA, USA References [1] Y ushi Bai, Xin Lv , Jiajie Zhang, Hongchang Lyu, Jiankai T ang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, Yuxiao Dong, Jie T ang, and Juanzi Li. 2024. LongBench: A Bilingual, Multitask Benchmark for Long Context Understanding. In Proceedings of the 62nd A nnual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers) . A ssociation for Computational Linguistics, Bangkok, Thailand, 3119–3137. doi:10.18653/v1/2024.acl- long.172 [2] Tri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. 2022. FLASHA T TENTION: fast and memor y-ecient exact attention with IO- awareness. In Proceedings of the 36th International Conference on Neural Informa- tion Processing Systems (New Orleans, LA, USA) (NIPS ’22) . Curran Associates Inc., Red Hook, N Y , USA, Article 1189, 16 pages. [3] W eishu Deng, Yujie Y ang, Peiran Du, Lingfeng Xiang, Zhen Lin, Chen Zhong, Song Jiang, Hui Lu, and Jia Rao. 2025. HGCA: Hybrid GP U-CPU Attention for Long Context LLM Inference. arXiv:2507.03153 [cs.LG] 2507.03153 [4] Daya Guo, Dejian Y ang, Haow ei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, and et al. 2025. DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. arXiv:2501.12948 [cs.CL] 12948 [5] Intel Corporation. 2024. Intel LLM Library for PyT orch (IPEX-LLM). https: //github.com/intel/ipex- llm. Accessed: 2024-11-18. [6] Aaron Jaech, Adam Kalai, Adam Lerer , Adam Richardson, Ahme d El-Kishky , Aiden Low , and et al. 2024. OpenAI o1 System Card. arXiv:2412.16720 [cs.AI] https://arxiv .org/abs/2412.16720 [7] Jared Kaplan, Sam McCandlish, T om Henighan, T om B. Bro wn, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jerey Wu, and Dario Amodei. 2020. Scaling Laws for Neural Language Models. arXiv:2001.08361 [cs.LG] https: //arxiv .org/abs/2001.08361 [8] W onb eom Lee, Jungi Lee, Junghwan Seo, and Jaewoong S im. 2024. InniGen: Ecient Generative Inference of Large Language Models with D ynamic KV Cache Management. In 18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24) . USENIX Association, Santa Clara, CA, 155–172. https://www.usenix.org/confer ence/osdi24/presentation/lee [9] Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir K arpukhin, Naman Goyal, Heinrich Küttler , Mike Lewis, W en-tau Yih, Tim Ro cktäschel, et al . 2020. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in neural information processing systems 33 (2020), 9459–9474. [10] Y uhong Li, Yingbing Huang, Bowen Yang, Bharat V enkitesh, Acyr Locatelli, Hanchen Y e , Tianle Cai, Patrick Lewis, and Deming Chen. 2024. SnapKV: LLM knows what you are lo oking for before generation. In Procee dings of the 38th International Conference on Neural Information Processing Systems (V ancouver , BC, Canada) (NIPS ’24) . Curran Associates Inc., Re d Hook, NY, USA, Article 722, 24 pages. [11] Enzhe Lu, Zhejun Jiang, Jingyuan Liu, Yulun Du, T ao Jiang, Chao Hong, Shaowei Liu, W eiran He, Enming Yuan, Y uzhi W ang, Zhiqi Huang, Huan Yuan, Suting Xu, Xinran Xu, Guokun Lai, Y anru Chen, Huabin Zheng, Junjie Y an, Jianlin Su, Yuxin W u, Neo Y. Zhang, Zhilin Y ang, Xinyu Zhou, Mingxing Zhang, and Jiezhong Qiu. 2025. MoBA: Mixture of Block Attention for Long-Context LLMs. arXiv:2502.13189 [cs.LG] [12] Lingrui Mei, Jiayu Y ao, Y uyao Ge, Yiwei W ang, Baolong Bi, Y ujun Cai, Jiazhi Liu, Mingyu Li, Zhong-Zhi Li, Duzhen Zhang, Chenlin Zhou, Jiayi Mao, Tianze Xia, Jiafeng Guo, and Shenghua Liu. 2025. A Survey of Context Engineering for Large Language Models. arXiv:2507.13334 [cs.CL] https://arxiv .org/abs/2507.13334 [13] Humza Naveed, Asad Ullah Khan, Shi Qiu, Muhammad Saqib, Saeed Anwar, Muhammad Usman, Naveed Akhtar , Nick Barnes, and Ajmal Mian. 2025. A Comprehensive Overview of Large Language Mo dels. ACM Trans. Intell. Syst. T echnol. 16, 5, Article 106 (Aug. 2025), 72 pages. doi:10.1145/3744746 [14] Pratyush Patel, Esha Choukse, Chaojie Zhang, Aashaka Shah, Íñigo Goiri, Saee d Maleki, and Ricardo Bianchini. 2025. Splitwise: Ecient Generative LLM In- ference Using Phase Splitting. In Proceedings of the 51st A nnual International Symposium on Computer A rchitecture (Buenos Aires, Argentina) (ISCA ’24) . IEEE Press, 118–132. doi:10.1109/ISCA59077.2024.00019 [15] Jiaming T ang, Yilong Zhao, Kan Zhu, Guangxuan Xiao, Baris K asikci, and Song Han. 2024. QUEST: quer y-aware sparsity for ecient long-context LLM inference. In Proceedings of the 41st International Conference on Machine Learning (Vienna, Austria) (ICML’24) . JMLR.org, Article 1955, 11 pages. [16] Ashish V aswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser , and Illia Polosukhin. 2017. Attention is all you need. Advances in neural information processing systems 30 (2017). [17] Y angzhen Wu, Zhiqing Sun, Shanda Li, Sean W elleck, and Yiming Yang. 2025. Inference Scaling Laws: An Empirical Analysis of Compute-Optimal Inference for LLM Problem-Solving. In The Thirteenth International Conference on Learning Representations . https://openreview .net/forum?id=VNckp7JEHn [18] Guangxuan Xiao, Y uandong Tian, Beidi Chen, Song Han, and Mike Lewis. 2024. Ecient Streaming Language Models with Attention Sinks. In The T welfth Inter- national Conference on Learning Representations . https://openreview .net/forum? id=NG7sS51zVF [19] Zihao Y e. 2023. From Online Softmax to FlashAttention. https://courses.cs. washington.edu/courses/cse599m/23sp/notes/ashattn.pdf UW CSE 599M Spring 2023: ML for ML Systems, https://courses.cs.washington.edu/courses/cse599m/ 23sp/notes/ashattn.pdf . [20] Zihao Y e , Lequn Chen, Ruihang Lai, Wuwei Lin, Yineng Zhang, Stephanie W ang, Tianqi Chen, Baris Kasikci, Vinod Grover , Arvind Krishnamurthy , and Luis Ceze. 2025. FlashInfer: Ecient and Customizable Attention Engine for LLM Inference Serving. arXiv:2501.01005 [cs.DC] https://ar xiv .org/abs/2501.01005 [21] Jingyang Yuan, Huazuo Gao, Damai Dai, Junyu Luo, Liang Zhao, Zhengyan Zhang, Zhenda Xie, Y. X. W ei, Lean W ang, Zhiping Xiao, Yuqing W ang, Chong Ruan, Ming Zhang, W enfeng Liang, and W angding Zeng. 2025. Native Sparse Attention: Hardware- Aligned and Nativ ely Trainable Sparse Attention. arXiv:2502.11089 [cs.CL] [22] Zhenyu Zhang, Ying Sheng, Tianyi Zhou, Tianlong Chen, Lianmin Zheng, Ruisi Cai, Zhao Song, Yuandong Tian, Christopher Ré, Clark Barrett, Zhangyang W ang, and Beidi Chen. 2023. H2O: heav y-hitter oracle for ecient generative inference of large language models. In Proceedings of the 37th International Conference on Neural Information Processing Systems (New Orleans, LA, USA) (NIPS ’23) . Curran Associates Inc., Red Hook, NY, USA, Article 1506, 50 pages. [23] Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Je Huang, Cody Hao Yu, Shiyi Cao, Christos K ozyrakis, Ion Stoica, Joseph E. Gonzalez, Clark Barrett, and Ying Sheng. 2024. SGLang: ecient execution of structured language model programs. In Procee dings of the 38th International Conference on Neural Information Processing Systems (V ancouver, BC, Canada) (NIPS ’24) . Curran Associates Inc., Red Hook, NY, USA, Article 2000, 27 pages. [24] Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yib o Zhu, Xuanzhe Liu, Xin Jin, and Hao Zhang. 2024. DistServe: disaggregating prell and decoding for goodput-optimized large language model ser ving. In Proceedings of the 18th USENIX Conference on Operating Systems Design and Implementation (Santa Clara, CA, USA) (OSDI’24) . USENIX Association, USA, Article 11, 18 pages.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment