스카우트 어텐션 레이어 앞선 CPU 사전연산으로 KV 캐시 오프로드 효율화
ScoutAttention은 GPU‑CPU 협업 블록‑와이드 희소 어텐션과 레이어‑앞선 CPU 사전연산을 결합해, KV 캐시를 DRAM으로 오프로드하면서도 CPU 연산 부하를 최소화한다. 이를 통해 기존 오프로드 기법 대비 2배 이상 속도 향상을 달성하고, 정확도 손실은 2.4% 이하로 제한한다.
저자: Qiuyang Zhang, Kai Zhou, Ding Tang
**1. 연구 배경 및 문제 정의**
대형 언어 모델(LLM)의 장문 추론에서는 프리‑필 단계에서 생성된 KV 캐시가 디코딩 단계에서 지속적으로 증가한다. 32k 토큰 입력을 가진 Qwen3‑32B 모델은 토큰당 약 4 KB KV 캐시를 차지해, 80 GB HBM을 장착한 GPU에서는 전체 메모리 중 8 GB만 KV 캐시로 사용해도 배치 크기를 1로 제한한다. 이 메모리 제약은 실제 서비스에서 요구되는 높은 처리량을 크게 저해한다.
**2. 기존 접근법의 한계**
- *Recall‑based* (InfiniGen): 중요한 토큰을 GPU에 남겨두고 나머지는 DRAM에 저장한다. 1‑layer‑ahead 프리패치로 I/O와 연산을 겹치려 하지만, PCIe 4×16 대역폭(실제 15 GB/s)과 KV 캐시 전송량(4 KB × 토큰) 차이로 GPU가 61% 유휴 상태에 빠진다.
- *Co‑attention* (HGCA): CPU가 DRAM에 있는 KV 캐시를 직접 처리해 I/O 병목을 없앤다. 그러나 CPU 어텐션 처리 속도가 GPU보다 약 20배 느려, GPU가 57% 유휴 상태가 된다.
**3. ScoutAttention의 핵심 아이디어**
ScoutAttention은 두 가지 핵심 메커니즘을 도입한다.
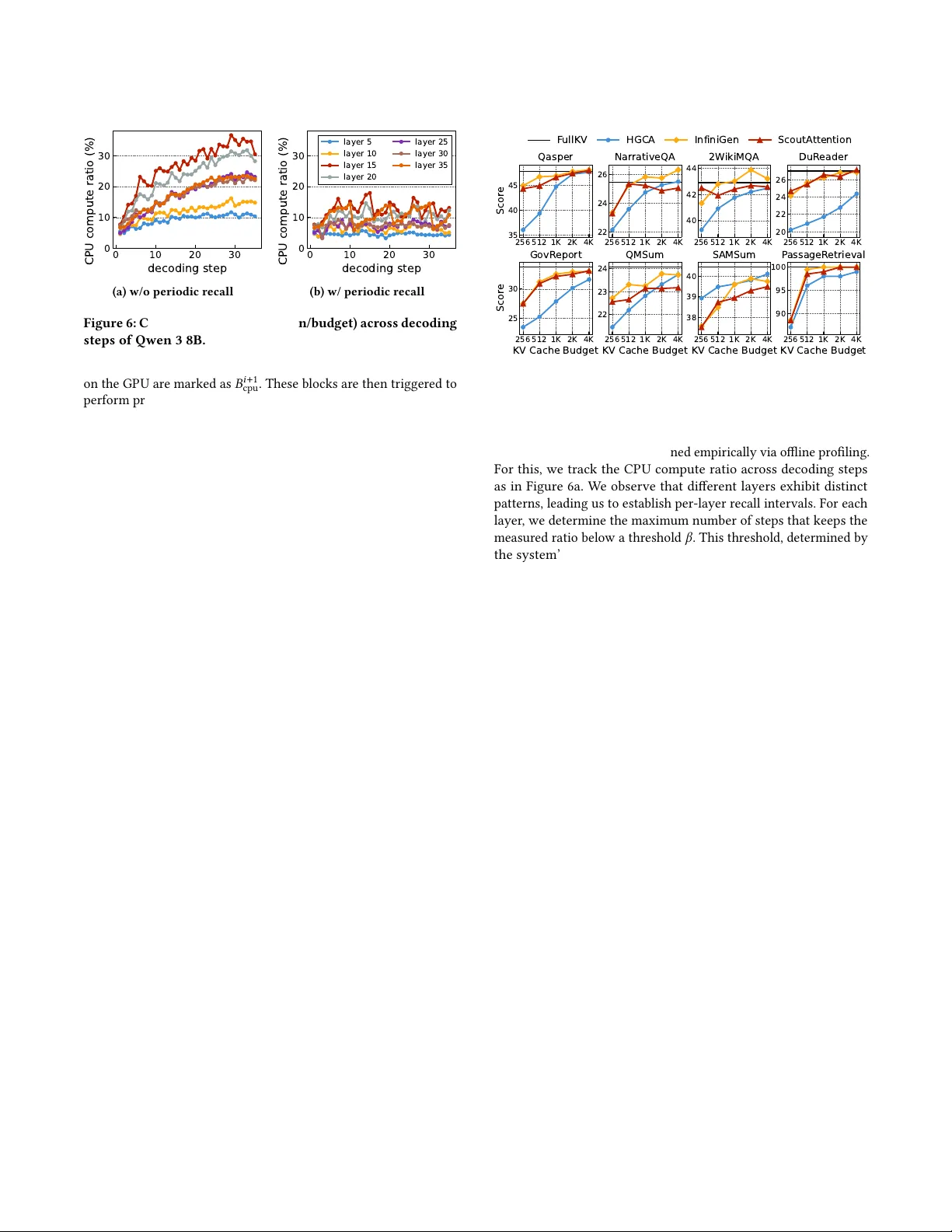
- **GPU‑CPU 협업 블록‑와이드 희소 어텐션**: KV 캐시를 고정 블록(예: 64 token)으로 나누고, 각 블록을 digest(예: min/max, 평균, 혹은 학습된 MLP)로 요약한다. Query와 digest의 내적을 통해 top‑k 블록을 선정하고, 중요한 블록은 GPU에, 나머지는 DRAM에 보관한다. GPU는 자체에 남은 블록을 전통적인 FlashAttention으로 처리하고, CPU는 GPU에 없는 블록만 희소 어텐션으로 계산한다. 블록 간 중요도는 시간적 지역성을 보여, 연속 토큰 간 top‑k 블록 교체 비율이 평균 15% 이하이다. 따라서 CPU 연산량이 크게 감소한다.
- **레이어‑앞선 CPU 사전연산**: 현재 레이어 i의 입력 Xᵢ와 Q‑projection W_Q를 이용해 i+1 레이어의 Query Qᵢ₊₁을 예측한다. 예측된 Qᵢ₊₁과 블록 digest을 사용해 i+1 레이어에 필요한 top‑k 블록을 미리 선정하고, CPU는 이 블록에 대한 어텐션을 비동기적으로 시작한다. GPU는 i 레이어 연산이 끝나는 즉시 i+1 레이어를 수행하고, CPU가 미리 계산한 결과를 합친다. 이 파이프라인은 CPU 연산 지연을 숨겨 GPU 유휴 시간을 최소화한다.
- **비동기 주기적 KV 캐시 리콜**: 중요한 블록이 시간에 따라 드리프트하는 현상을 보정하기 위해, 레이어가 완전히 종료된 뒤 일정 주기로 GPU에 중요한 블록을 리콜한다. 이는 I/O 윈도우를 넓혀 전송 효율을 높이며, 기존 1‑layer‑ahead 리콜보다 더 큰 버퍼를 제공한다.
**4. 구현 및 실험**
- 구현: SGLang 프레임워크 위에 ScoutAttention을 구현하고, Quest 기반 블록‑와이드 희소 어텐션을 사용했다. CPU는 36코어 AMD EPYC, GPU는 NVIDIA H100 80 GB를 사용했다.
- 평가: 다양한 LLM(예: Qwen3‑32B, LLaMA‑2‑70B)과 벤치마크(LongChat, Code Generation, Retrieval‑Augmented Generation)에서 정확도와 처리량을 측정했다.
- 결과: 전체 어텐션 대비 평균 정확도 손실은 2.1% 이하였으며, 처리량은 5.1배 향상되었다. 기존 오프로드 기법(InfiniGen, HGCA) 대비 2.1배 빠른 속도를 보였다. GPU 활용도는 90% 이상 유지됐으며, PCIe 대역폭 사용량은 기존 대비 30% 이하로 감소했다.
**5. 의의 및 향후 연구**
ScoutAttention은 KV 캐시 오프로드를 위한 새로운 설계 패러다임을 제시한다. 블록‑와이드 희소 어텐션과 레이어‑앞선 CPU 사전연산을 결합함으로써, 메모리‑바운드 디코딩 단계에서 발생하는 GPU 메모리 압박을 DRAM으로 효과적으로 이전하면서도 CPU 연산 병목을 최소화한다. 향후 연구에서는 (1) 블록‑와이드 희소 어텐션 알고리즘을 학습 기반으로 최적화, (2) 멀티‑GPU 환경에서의 협업 스케줄링, (3) NVMe‑over‑Fabric 등 고대역폭 스토리지를 활용한 리콜 메커니즘 확장 등을 통해 장문 추론의 확장성을 더욱 높일 수 있을 것이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기