No Hard Negatives Required: Concept Centric Learning Leads to Compositionality without Degrading Zero-shot Capabilities of Contrastive Models
Contrastive vision-language (V&L) models remain a popular choice for various applications. However, several limitations have emerged, most notably the limited ability of V&L models to learn compositional representations. Prior methods often addressed…
Authors: Hai X. Pham, David T. Hoffmann, Ricardo Guerrero
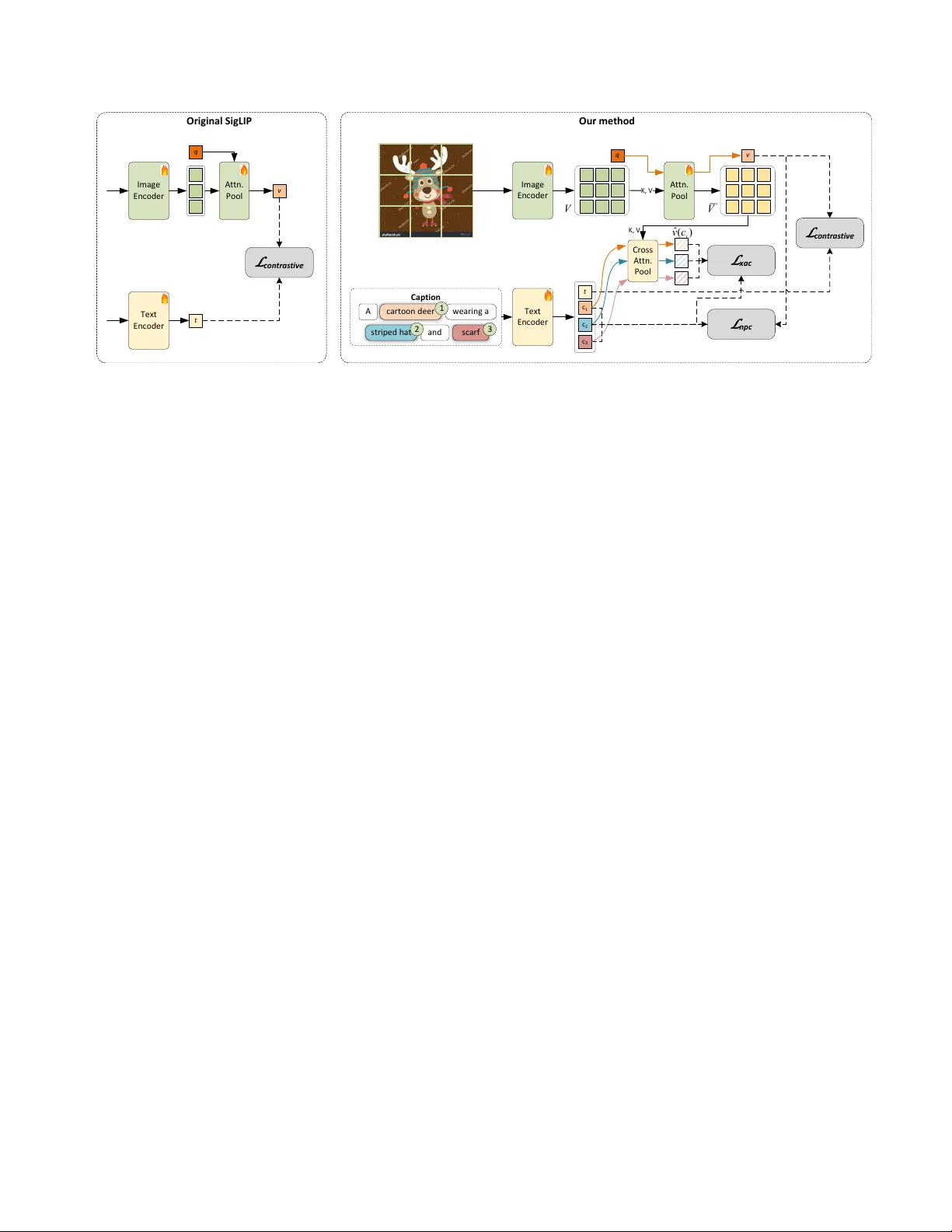
No Hard Negativ es Requir ed: Concept Centric Learning Leads to Compositionality without Degrading Zer o-shot Capabilities of Contrastiv e Models Hai X. Pham * David T . Hof fmann Ricardo Guerrero Brais Martinez Samsung AI Center Cambridge, UK Abstract Contrastive vision-language (V&L) models remain a pop- ular choice for various applications. However , sever al limitations have emer ged, most notably the limited abil- ity of V&L models to learn compositional repr esentations. Prior methods often addr essed this limitation by generat- ing custom training data to obtain hard ne gative samples. Har d ne gatives have been shown to impr ove performance on compositionality tasks, but ar e often specific to a sin- gle benchmark, do not generalize, and can cause substan- tial degr adation of basic V&L capabilities such as zer o- shot or retrie val performance, r endering them impr actical. In this work we follow a differ ent appr oach. W e identify two r oot causes that limit compositionality performance of V&Ls: 1) Long training captions do not r equir e a com- positional r epr esentation; and 2) The final global pooling in the text and image encoders lead to a complete loss of the necessary information to learn binding in the first place. As a r emedy , we pr opose two simple solutions: 1) W e obtain short concept centric caption parts using stan- dar d NLP software and align those with the image; and 2) W e intr oduce a parameter-fr ee cr oss-modal attention- pooling to obtain concept centric visual embeddings fr om the image encoder . W ith these two changes and simple auxiliary contrastive losses, we obtain SO T A performance on standar d compositionality benchmarks, while maintain- ing or impr oving str ong zer o-shot and r etrieval capabilities. This is achieved without increasing infer ence cost. W e r e- lease the code for this work at https://github.com/ SamsungLabs/concept_centric_clip . 1. Introduction Contrastiv e vision-language (V&L) models have been a cornerstone of computer vision and machine learning since the publication of CLIP [ 25 ]. While contrasti ve V&L models ha ve achiev ed remarkable performance on a large * Correspondence to: < pham.xuan.hai@outlook.com > variety of tasks and enabled deployment of vision mod- els to open world settings, various limitations have been found. Most notably , they struggle when learning com- positional representations, such as binding a noun to its attributes, understanding the relations between objects, or recognizing when one of multiple objects has been re- placed by another object [ 6 , 10 , 33 ]. Compositionality is a core capability of vision systems and results in vari- ous failure cases if not learned. Therefore, many works hav e focused on ways to improve compositionality post- hoc [ 1 , 4 – 6 , 8 , 10 , 15 , 23 , 28 , 29 , 33 , 35 ], most of which [ 4 , 5 , 23 , 28 , 35 ] rely on clev er ways of constructing hard negati ves for fine-tuning purposes. Previous works correctly identified one of the reasons why contrastiv e models do not learn compositional repre- sentations: A simple Bag-of-W ords (BoW) representation is completely sufficient to retrie ve the right image from a batch, as the caption is typically long and detailed. They hav e proposed solving this issue by training with hard neg- ativ es generated by follo wing simple rules. Models trained on these negativ es learn a compositional representation in the narro w domain defined by the set of rules used to gener - ate hard negati ves. T raining with hard negativ es has indeed been shown to yield in-distrib ution impro vements, b ut these gains often fail to generalize to hard negati ves that exhibit slightly dif ferent structures [ 10 , 15 ]. At the same time, the improv ements in compositionality achie ved via hard ne ga- tiv e training frequently come at the expense of generaliza- tion to other downstream tasks; precisely the property that originally made contrastiv e V&L models popular . Here, we follo w a dif ferent approach and focus on better exploiting existing pre-training data. In particular , we focus on noun-phrases, which are groups of words that function as a concept in a sentence, e.g. “a red couch” or “the tall building”, and define two auxiliary loss terms, a contrasti ve concept loss and a cross-attentiv e pooling loss, which com- bine to rectify the root causes of the contrastive learning behavior . Our contrasti ve concept loss focuses on contrast- ing noun-phrases and images. Noun-phrases are short and O r i g i n a l SigL I P Im a g e E n c o d e r T ext E n c od e r q t v L co ntr a s ti v e Attn . Po o l Attn . Po o l Im a g e E n c o d e r T ext E n c od e r q t v L co ntr a s ti v e Attn . Po o l O r i g i n a l SigL I P Im a g e E n c o d e r T ext E n c od e r q t v L co ntr a s ti v e Attn . Po o l O r i g i n a l SigL I P Im a g e E n c o d e r T ext E n c od e r q t v L co ntr a s ti v e Attn . Po o l O r i g i n a l SigL I P Im a g e E n c o d e r T ext E n c od e r q t v L co ntr a s ti v e Attn . Po o l Attn . Po o l Im a g e E n c o d e r T ext E n c od e r q t v L co ntr a s ti v e Attn . Po o l O r i g i n a l SigL I P Im a g e E n c o d e r T ext E n c od e r q t v L co ntr a s ti v e Attn . Po o l O r i g i n a l SigL I P Im a g e E n c o d e r T ext E n c od e r q t v L co ntr a s ti v e Attn . Po o l (a) Cap tion cart o o n d e e r s trip e d h at s ca rf A w e ar in g a an d Cap tion cart o o n d e e r s trip e d h at s ca rf A w e ar in g a an d Im a g e E n c o d e r T e xt E n c o d e r q 1 2 3 t c 1 c 2 c 3 t c 1 c 2 c 3 t c 1 c 2 c 3 Att n . Po o l K, V v C ros s Att n . Po o l K , V L co nt r a s ti v e L npc L xac O u r m e th od V ' V ˆ () i vc Cap tion cart o o n d e e r s trip e d h at s ca rf A w e ar in g a an d Im a g e E n c o d e r T e xt E n c o d e r q 1 2 3 t c 1 c 2 c 3 Att n . Po o l K, V v C ros s Att n . Po o l K , V L co nt r a s ti v e L npc L xac O u r m e th od V ' V ˆ () i vc Cap tion cart o o n d e e r s trip e d h at s ca rf A w e ar in g a an d Cap tion cart o o n d e e r s trip e d h at s ca rf A w e ar in g a an d Im a g e E n c o d e r T e xt E n c o d e r q 1 2 3 t c 1 c 2 c 3 t c 1 c 2 c 3 t c 1 c 2 c 3 Att n . Po o l K, V v C ros s Att n . Po o l K , V L co nt r a s ti v e L npc L xac O u r m e th od V ' V ˆ () i vc Cap tion cart o o n d e e r s trip e d h at s ca rf A w e ar in g a an d Im a g e E n c o d e r T e xt E n c o d e r q 1 2 3 t c 1 c 2 c 3 Att n . Po o l K, V v C ros s Att n . Po o l K , V L co nt r a s ti v e L npc L xac O u r m e th od V ' V ˆ () i vc (b) Figure 1. Method overview . (a) SigLIP uses a learnable query token in combination with an attention layer to pool the visual tokens into a single token. Aligning only global representations hampers the learning of a compositional representation. (b) Similar to SigLIP , our method aligns the global representations v and t . T o simplify learning of a compositional representation, our method extends SigLIP by first, pooling the text encoder output tokens into concept embeddings { c k } , which are used to attention-pool concept-specific information from the visual tokens ¯ V , resulting in ˆ v ( c ) . ˆ v ( c k ) and the corresponding c k are aligned using L xac . Furthermore, the global visual representation v is aligned with all c k via L npc , a multi-positi ve v ariant of SigLIP loss. Similarly , the global image and te xt representations v and t are aligned via L contrastiv e . thus are not solvable via a BoW representation. T o provide an example: For the noun-phrase “a red couch”, a BoW rep- resentation is likely insuf ficient, as the probability of an im- age containing a couch and anything colored in red is quite high. Thus, the model must learn a latent representation that is more discriminativ e. Since our method relies on real data positives instead of synthetically generated hard nega- tiv es, our method is less likely to learn shortcuts that do not generalize to broader domains. Despite the shortcuts when training with long captions, the overall architectural design of contrastive V&L mod- els also hinders the learning of a good compositional rep- resentation. V isual and textual representations are pooled into single-v ector embeddings, which mix nouns and adjec- tiv es from dif ferent regions of the image or different parts of the caption. This global pooling operation results in a complete loss of associations between attributes and nouns. Fine-tuning with post-pooling hard negativ e losses can yield improv ements by aligning the model to in-domain distribu- tions, ho we ver , this will not substantially change the under- lying behavior of the encoders. Instead of focusing on encouraging binding after the global pooling with hard negati ves, we focus on learning binding befor e global pooling. Once learned, the model only needs to preserve a representation of that binding through the pooling operation. T o encourage binding before the pooling operation, we introduce a cross-modal attention pooling function that extracts noun-phrase-specific infor- mation from the full visual representation, thereby produc- ing multi-word, concept-specific embeddings learned with an auxiliary contrastiv e loss. As the attention-pooling func- tion has no learnable parameters, this directly propagates the learning signal to the penultimate representation, i.e., it encourages a compositional representation before the global pooling operation. A schematic of our complete method can be seen in Fig. 1 . Our method, C 2 LIP (Concept-centric CLIP), is sim- ple to use, comes with no additional trainable parame- ters, and requires only fine-tuning for a few epochs with- out the incurred cost of complicated hard neg ativ e gen- eration pipelines. W e show quantitativ ely that this sim- ple method leads to improvements over its base model and reaches SO T A on the SugarCrepe [ 10 ] and SugarCrepe++ [ 6 ] benchmarks. At the same time, our method leads to im- prov ements on image caption retrie val datasets while incur - ring only modest drops in classification performance on Im- ageNet. Note that the drop in performance on ImageNet can be attributed to two factors: First, fine-tuning is performed on a less div erse dataset than the one used for pre-training. Second, the shift tow ard a more scene centric representa- tion (required for compositional reasoning) conflicts with ImageNet’ s objective of focusing on the most salient ob- ject. Overall, C 2 LIP demonstrates high performance across a v ariety of benchmarks and tasks. In contrast, the base- lines usually excel at a single task but perform considerably poorer on the others. In summary , our contributions are: 1) W e introduce a hard negati ve-free pipeline to fine-tune existing contrastiv e V&L models to improve compositionality . 2) W e show that training on short noun-phrases instead of long de- tailed captions leads to improvements on compositionality while maintaining zero-shot capabilities. 3) W e introduce a parameter-free cross-modal attention pooling mechanism that is used during training to encourage concept bind- ing before the global pooling operation. 4) The proposed method is simple to train, adds minimal training ov erhead, and retains unchanged inference. 5) W e sho w quantitati vely that our method C 2 LIP reaches SO T A on standard composi- tionality tasks, while at the same time maintaining high per - formance on standard retriev al and zero-shot benchmarks. It is particularly appealing that C 2 LIP is among the top per - formers on all benchmarks and metrics tested, instead of ex- celling on some at the cost of others, as frequently observed for other methods. 2. Related work Despite the great success of contrastiv e models for zero- shot class ification and retriev al, se veral issues emer ge when they are applied to more sophisticated tasks. For example, Y ¨ uksekg ¨ on ¨ ul et al. [ 33 ] showed that CLIP tends to learn BoW representations. Even more concerning, T ang et al. [ 29 ] found that CLIP matches an image of an eggplant and a lemon to the caption “a purple lemon” rather than the cor- rect “a yellow lemon”. V arious strategies hav e been tested to prev ent contrastiv e models from learning BoW representations [ 4 , 5 , 23 , 24 , 28 , 35 ]. Many of these follow Y ¨ uksekg ¨ on ¨ ul et al. [ 33 ] and use spaCy [ 9 ] to swap words in the captions, thereby creating hard negativ es [ 4 , 5 , 24 , 35 ] for the contrasti ve loss. Oth- ers achiev e the same goal by employing a BER T model to replace words [ 4 , 35 ]. More sophisticated methods gener- ate hard negati ves with an LLM, for instance via in-context learning [ 23 ], ho wev er , this approach incurs the risk of fail- ures during hard negati ve creation as well as a significant computational cost. Howe ver , Hsieh et al. [ 10 ], Le wis et al. [ 15 ] sho wed that designing a caption augmentation pipeline that generalizes to unseen cases is difficult, and many ap- proaches merely exploit biases in the test datasets. This questions whether the reliance on hand-crafted hard neg- ativ es is a promising direction in the first place. In par- allel with hard negati ve captions, se veral works explore hard negati ve images generated by text-to-image models [ 16 , 23 ]. These approaches typically generate hard negati ve captions and use these as input to a text-to-image model to obtain a hard negativ e image. Producing a large number of hard-neg ati ve images is very costly , as it requires both the creation of hard-negati ve texts and the execution of the text-to-image model, and thus inflates the dataset size, lead- ing to substantially higher computational demands. Many of the methods described abov e rely on custom contrastiv e losses, such as an extension of the MIL-NCE loss [ 5 ], an adaptiv e margin loss [ 16 ], or a dynamic thresh- old loss [ 35 ]. These losses are necessary to mitigate the negati ve impact of noisy or potentially erroneous synthetic samples, but each introduces its own set of challenges. Other works [ 5 , 8 , 21 , 37 ] argue that the problem lies in cap- tion quality and therefore obtain dense captions [ 5 , 21 , 37 ] for the images. Unfortunately , generating such dense cap- tions is expensiv e, and additional tricks [ 21 , 37 ] are required to make use of long captions in contrasti ve learning. Another line of work attrib utes the problem to the model architecture, in particular the late interaction be- tween modalities [ 1 , 31 ]. Inspired by object-centric learn- ing, Assouel et al. [ 1 ] use cross-attention to obtain caption- conditioned visual representations during both training and inference. Ho wever , their method requires an LLM to de- compose a caption into a scene graph, effecti vely outsourc- ing most of the binding problem to the LLM, and requires an independent forw ard pass for each sub-caption both dur- ing training and inference, increasing the cost of training and inference drastically . Our approach also uses attention to produce text-conditioned visual representations, but it is considerably simpler and does neither rely on an LLM, nor a complicated binding module, nor multiple forw ard passes. Instead, we only need to detect noun-phrases in re gular cap- tions (e.g., using spaCy [ 9 ]) to use in our two auxiliary training objectiv es. The inference pipeline is identical to the vanilla CLIP/SigLIP pipeline. 3. Concept-centric contrastive lear ning 3.1. Preliminaries: SigLIP model In this work, we utilize SigLIP [ 34 ] as base model, as it al- ready pro vides higher initial performance than CLIP . In this section we provide the necessary background on SigLIP by briefly describing the model architecture, especially its at- tention pooling layer and the loss function, which we ex- ploit in our concept-aware objectiv es. Howe ver , our method does not require any component specific to SigLIP . Thus, it is in principle applicable to an y CLIP-like model. W e leave such explorations for future work. The SigLIP model [ 34 ] follows the con ventional con- trastiv e learning frame work with two neural networks: the vision encoder f img and text encoder f txt that project the input image-caption ( I , T ) pair separately into two em- bedding vectors, ( v , t ) , in the joint subspace ∈ R D , where D is the dimensionality of this subspace. The encoders are jointly trained by maximizing the cosine similarity of the positiv e pairs s pos = v pos · t pos , while at the same time minimizing the similarity scores s neg of negati ve pairs within a training batch. Particularly , the SigLIP model deviates from the preceding CLIP model [ 25 ] at two important points: visual attention pooling and sigmoid loss. V isual attention pooling . The CLIP vision encoder [ 25 ] adopted the standard vision transformer (V iT) [ 13 ], where a learnable [CLS] token is appended to the input tokens and used to pool features via self-attention through all transformer layers. Whereas in SigLIP , a separate learnable token q ∈ R D is employed to pool features after the last transformer layer using an additional attention layer, as demonstrated in Fig. 1a . Let V ∈ R M × D be the outputs of the V iT , in which M is the number of image patches. The visual embedding v is calculated as follows: ¯ q = f q uer y ( q ) , ¯ K = f key ( V ) , ¯ V = f v al ue ( V ) , (1) ˜ q = ¯ V T · attn ( ¯ q , ¯ K ) , (2) v = f M LP ( ˜ q ) , (3) where f q uer y , f key , f v al ue and f M LP are neural functions. Contrastive sigmoid loss . W e consider a minibatch B comprising paired embeddings { ( v i , t i ) | | B | i =1 } , which we can org anize into | B | positiv e and | B | × ( | B | − 1) negati ve pairs in total. W e define an indicator function z ij with value 1 if i = j and − 1 otherwise, reflecting the assumption of pairwise matches between images and captions. The contrastiv e sigmoid loss is given by L contrastiv e = − 1 | B | | B | X i =1 | B | X j =1 log σ ( z ij ( τ v i · t j + b )) , (4) where σ denotes the sigmoid function, τ and b are learnable scalars corresponding to scale and bias terms. The sigmoid loss improves computational efficiency when compared to the more costly batch-wise softmax calculation required by CLIP . Howe ver , training only with this objective yields a BoW representation. In the next section we introduce ad- ditional concept-aware contrasti ve losses and explain how these losses are combined with our noun-phrase captions and cross-attention pooling function to promote learning a compositional representation. Note that these modifications do not require any changes to the original model architec- ture and do not alter the inference procedure. 3.2. Concept-aware contrasti ve training W e emphasize the binding of the elements in noun-phrase concepts , and aligning such concepts to the corresponding images. W e start by identifying a set of noun-phrases from each input caption, which can be done offline using standard NLP tools, e.g. spaCy [ 9 ]. Concept-aware contrastive loss. The objectiv e of this loss is to explicitly encourage the encoders to bind elements of a noun-phrase together . More specifically , each caption T i contains K i concepts (noun-phrases), with latent representations { c k i | K i k =1 } . These representations are computed by pooling the representations of the text tokens corresponding to the respecti ve noun-phrase, as depicted in Fig. 1b . W e then devise an image-text contrastiv e loss similar to Eq. ( 4 ). Howe ver , different from Eq. ( 4 ), we match each image to all of its corresponding sub-captions (i.e. noun-phrase concepts) simultaneously . This enforces that the model represents all concepts in the global image representation. Our loss extends the standard SigLIP loss to a version that accepts multiple positi ves per sample, thus the indicator function z ′ ij must be prepared accordingly . The n oun- p hrase c oncept (npc) loss is giv en by L npc = − 1 K | B | X i =1 K X j =1 log σ z ′ ij ( τ v i · c j + b ) , (5) where K = P | B | i =1 K i . Cross-attended concept-aware loss. In addition to SigLIPs attention-pooling in the vision tower , we apply cross-modal attention-pooling to extract information from the visual tokens using the concept embeddings c as queries, as shown in Fig. 1b . W e reuse the projected value ¯ V in Eq. ( 1 ) and the M LP in Eq. ( 3 ) to project the visual tokens to ¯ V ′ = f M LP ( ¯ V ) in the joint subspace, which are used as key and v alue in the cross-attention function: ˆ v ( c ) = ¯ V ′ T · attn ( c, ¯ V ′ ) . (6) Note that this attention-pooling does not add any additional parameters, and it is only utilized during training. The cross - a ttended c oncept-aware ( xac ) loss is defined similarly to L npc in Eq. ( 5 ), but replacing the unimodal vi- sual latent representation v with the cross-modal concept- attended variant ˆ v ( c ) , as follows: L xac = − 1 K | B | X i =1 K X j =1 log σ z ′ ij ( τ ˆ v i ( c j ) · c j + b ) . (7) T otal training loss. Finally , the model is fine-tuned with the combined loss giv en by L total = L contrastiv e + λ npc L npc + λ xac L xac , (8) where λ npc and λ xac are trade-off h yper-parameters. 4. Experimental results W e detail our experimental settings, baselines, datasets and the e valuation protocols in Sec. 4.1 . W e present and discuss our quantitative results in Sec. 4.2 , provide qualitativ e re- sults in Sec. 4.3 and ablate the components of our method in Sec. 4.4 . 4.1. Experimental setting W e fine-tune the pretrained SigLIP on CC3M [ 26 ] using our proposed method. Particularly , we use the new short cap- tions of CC3M introduced in DreamLIP [ 37 ], which contain richer descriptions of objects and attribute bindings. W e fine-tune the model for fiv e epochs using Adam optimizer with base learning rate of 1e-5, on eight A40 GPUs with effecti ve batch size of 768. The hyper-parameters λ npc and λ xac in Eq. ( 8 ) are empirically chosen as 1 and 0.01, respec- tiv ely . Our implementation extends from OpenCLIP [ 11 ]. Data pre-processing . First, we use spaCy for dependency parsing of the original captions, and traverse the depen- dency trees to e xtract the noun-phrase concepts. Baselines. W e use a V iT -B/16 in all our experiments. Ac- cordingly , we compare with baselines utilizing the same model, or models with similar parameter count. W e select checkpoints of corresponding models trained/fine-tuned on CC3M whenever av ailable, and use any provided check- points otherwise. Refer to T ab . 1 for details on the training setup of our baselines. Our main baseline is the SigLIP model pretrained on W e- bLI and fine-tuned on the DreamLIP variant of CC3M. This results in a fair baseline that has been trained with exactly the same data, exactly the same training setup and allo ws a comparison without confounding factors like the effect of a narrower domain of CC3M in comparison to W ebLI. Despite that, we also compare performance of our model to that of larger models using a V iT -L encoder, as well as models trained with multi-task objectiv es. Evaluation protocol. T o ensure fair , consistent perfor- mance comparisons and facilitate reproducibility , we ev al- uate all methods with the CLIP Benchmark tool [ 3 ] in the same en vironment, and report the resulting metrics on a va- riety of benchmarks: • Compositionality : SugarCrepe and SugarCrepe++ • Zer o-shot classification : ImageNet1K • Zer o-shot r etrieval : Flickr30K and MSCOCO • F ine-grained retrie val : DOCCI [ 22 ] and ImageInW ords (IIW) [ 7 ]. Follo wing the experiments of Xiao et al. [ 31 ], we split the long captions into single sentences and ev al- uate retriev al performance on them. Evaluation metrics. For ev aluation of compositionality , we follow the standard e v aluation protocol of SugarCrepe and SugarCrepe++ and report accuracy . These benchmarks consider a sample as correct, if the true caption is assigned a higher similarity to the image than the hard negati ve cap- tion. The datasets allo w to e valuate for dif ferent word types separately , namely for objects , attributes and relations of concepts . Accuracy is always reported for a set of subtasks, differing in how the false samples are created: “ Add” cre- ates the false caption by adding an unrelated word of a gi ven word type, “Swap” swaps a giv en word type with the same word type within the caption and “Replace” replaces a word with a new word of the same type. All ev aluations on Sug- arCrepe are image-to-text (I2T). SugarCrepe++ extends the protocol of SugarCrepe by using two positive captions and requiring both of them to be higher ranked than the negati ve, to be considered cor- rect. Furthermore, SugarCrepe++ adds the te xt-to-text tasks (TO T), which probes the text encoders in isolation for com- positionality , following the same e v aluation pattern. For the remaining tasks we follo w the default ev aluation settings of CLIP Benchmark [ 3 ]: For ImageNet we report accuracy . For Flickr30k, MSCOCO, DOCCI and IIW we report Recall@5. T able 1. T raining data of baselines. Summary of baseline meth- ods and their corresponding training datasets, excluding the orig- inal CLIP and SigLIP models. The last column indicates whether the provided checkpoints were trained from scratch ( ✓ ). Model T raining data T rain from scratch Composition-aware CE-CLIP [ 35 ] MSCOCO NegCLIP [ 33 ] MSCOCO CLIC [ 24 ] LAION-1.5B D A C [ 5 ] CC3M SL VC [ 4 ] CoN-CLIP [ 28 ] T ripletCLIP [ 23 ] ✓ Codebook-based Codebook-CLIP [ 2 ] ✓ IL-CLIP [ 36 ] ✓ F ine-grained training DreamLIP-3m [ 37 ] ✓ FLAIR-3m [ 31 ] ✓ FG-CLIP [ 32 ] LAION-2B + FineHARD ✓ FineCLIP [ 12 ] MSCOCO LLIP [ 14 ] Common Crawl 12.8B ✓ Large-sized models CLIP-A (V iT -L/14) [ 18 ] LAION-400M ✓ CLIPS (V iT -L/14) [ 21 ] Recap-DataComp-1B ✓ Multi-task training BLIP-B [ 17 ] 14M samples - FLA V A [ 27 ] PMD-80M - SigLIP-2 [ 30 ] W ebLI - 4.2. Quantitative e valuation Comparison with V iT -B baselines . Our main results are shown in T ab . 2 . The last two rows show the most impor- tant results as they sho w the most comparable models, both trained by us under the exact same setting on the Dream- LIP variant of CC3M with either the standard SigLIP ob- jectiv e or our objectiv es. It can be seen that fine-tuning on DreamLIP-CC3M alone leads only to marginal improve- ments with respect to the original SigLIP checkpoint. How- ev er, when using our method we observe considerable im- prov ements on all compositionality benchmarks and tasks. Additionally , our model impro ves on Flickr30k, MSCOCO, and IIW . Thus, it improv es both long and short caption re- triev al. Only on ImageNet does the performance drop. This T able 2. Performance comparison of V iT -B-based models . C 2 LIP achieves consistently high performance on SugarCrepe and Sugar- Crepe++ compared to the composition-aware models, despite only relying on regular captions during training. Additionally , our model is able to maintain and improv e the retriev al and zero-shot capabilities of the original SigLIP , achieving the best o verall score. Models SugarCrepe SugarCrepe++ ImNet1K Flickr30k MSCOCO DOCCI IIW A verage Add Replace Swap Replace Swap I2T TOT I2T TOT SigLIP V iT -B/16 86.5 84.1 65.8 73.8 62.8 48.0 34.7 76.1 95.2 78.9 58.9 75.3 70.0 CLIP (OpenAI) V iT -B/32 73.0 80.0 62.7 69.5 60.5 45.7 27.4 63.3 89.0 65.4 47.1 69.5 62.8 CLIP (OpenAI) V iT -B/16 72.7 80.4 62.5 70.1 60.2 43.8 23.9 68.4 90.9 67.6 50.4 71.3 63.5 F ine-grained models FG-CLIP 84.7 85.1 69.9 75.8 67.5 51.5 38.2 69.0 95.8 78.4 56.7 75.6 70.7 FineCLIP 85.4 85.3 66.8 72.8 68.7 43.9 26.8 55.8 93.5 79.0 44.9 67.1 65.8 DreamLIP-3m 72.9 77.5 64.2 61.2 51.5 44.4 30.1 31.6 83.1 61.2 58.8 77.9 59.5 FLAIR-3m 80.6 81.4 70.9 66.3 57.5 49.5 35.2 33.7 90.4 71.5 47.2 72.8 63.1 LLIP 71.4 78.9 57.8 67.3 56.8 40.8 27.3 60.8 90.2 67.5 46.9 70.7 61.4 Codebook-based models Codebook-CLIP 50.6 54.5 47.5 34.3 13.8 28.3 10.1 0.0 0.6 0.1 0.1 0.7 20.0 IL-CLIP 51.8 52.8 55.2 34.4 31.8 36.9 14.7 0.0 0.4 0.1 0.1 0.7 23.2 Composition-aware models CE-CLIP 92.9 87.0 74.9 56.5 67.0 34.3 32.5 40.4 87.4 71.9 30.8 50.1 60.5 NegCLIP 85.8 85.0 75.3 69.1 70.9 53.4 39.1 55.7 92.4 73.9 45.2 66.4 67.7 CLIC 89.8 85.8 72.5 76.6 58.1 59.0 27.0 66.6 91.1 67.4 51.3 73.4 68.2 D A C-SAM 91.6 87.0 73.5 52.4 60.2 30.6 18.4 52.3 84.0 58.8 31.2 50.6 57.5 D A C-LLM 93.7 89.5 74.6 53.7 59.6 32.2 18.1 51.1 83.7 59.0 27.1 43.9 57.2 SL VC-R 85.4 78.9 68.8 64.0 68.2 51.3 28.4 58.5 90.1 66.9 42.1 66.1 64.1 SL VC-RL 78.5 75.9 65.5 61.9 70.0 46.0 26.3 59.7 90.0 67.0 41.8 67.3 62.5 CoN-CLIP 82.4 77.4 62.4 68.1 70.1 45.2 28.0 63.7 86.0 61.2 46.0 67.1 63.1 T ripletCLIP 88.3 87.0 69.9 69.9 69.4 41.4 28.5 45.9 81.7 54.4 39.8 62.5 61.6 Models fine-tuned by us SigLIP V iT -B/16 (ft. CC3M) 87.9 85.6 69.7 73.5 67.9 49.8 36.6 75.9 95.6 80.3 59.8 75.5 71.5 C 2 LIP 94.2 88.3 73.1 79.7 75.3 55.2 44.2 73.5 97.0 82.7 60.0 76.4 75.0 phenomenon is observ ed for most composition-a ware mod- els. Compared to these methods, the drop on ImageNet for C 2 LIP is very small. W e attribute the drop in perfor- mance to the more scene centric representation encouraged by our training method, which can lead to poorer results on tasks like ImageNet classification, an extremely object centric task, for which it is beneficial to ignore everything except for the most salient and central object. Compared to previous methods that aimed at improv- ing compositionality (composition-aware models in T ab. 2 ), C 2 LIP sho ws consistently high performance on all bench- marks, making it the new SO T A method among models with similar backbone capacity . While C 2 LIP is outperformed on some metrics by either NegCLIP or D A C-LLM on the SugarCrepe benchmark (which is kno wn to be hackable), it outperforms both methods on the more trustworthy Sug- arCrepe++ benchmark. Similarly , CLIC surpasses C 2 LIP on SugarCrepe++ Swap-I2T task, but a closer look at text- only tasks (TO T) reveals that CLIC performs poorly , ex- posing major limitations in the compositional representa- tion learned by the CLIC text encoder . In summary , C 2 LIP demonstrates ov erall SO T A perfor- mance, achieving the best or second best results on most benchmarks and metrics while remaining among the top models on the remaining ones. C 2 LIP stands out par- ticularly for its consistently high performance across all benchmarks, whereas other models tend to excel on a sin- gle benchmark but perform considerably poorer on others. W ith this reliable performance, C 2 LIP is an excellent post- training method to improve compositional comprehension in foundation models, without sacrificing performance on other tasks. Comparison on attribute-binding performance. As shown in the previous section, C 2 LIP improves all com- positionality related tasks; howe ver , the main gain lies in strengthening attribute-object binding. Therefore, we ex- amine the results on attrib ute–object binding in more detail. As can be seen in T ab. 3 , on av erage, C 2 LIP outperforms all prior composition-aware methods for attribute related tasks. C 2 LIP achiev es the best results on almost ev ery met- ric, being surpassed only by DA C-LLM on the SugarCrepe “Replace” task by 0 . 3 percentage points. Overall, C 2 LIP shows consistently high performance, while baselines per- form poorly on at least one of the tasks. T able 3. Attribute-binding performance comparison. W e compare the accuracy of C 2 LIP with composition-aw are baselines on attrib ute replacement and swapping experiments of SugarCrepe and Sug arCrepe++. Our model consistently outperforms the competing baselines on most tasks and attains the best ov erall score. Moreover , previous methods rely on hard ne gati ves to induce a compositional representation, which often harms generalization to natural data and leads to a considerable performance drop on SugarCrepe++. In contrast, C 2 LIP maintains high performance on all metrics, further highlighting the strength of our proposed approach. Model SugarCrepe SugarCrepe++ A verage Replace Swap Replace-I2T Replace-TO T Swap-I2T Swap-T OT SigLIP V iT -B/16 86.7 71.5 75.5 64.2 56.3 46.4 66.8 CE-CLIP 88.8 77.0 52.0 64.2 32.3 36.3 58.4 NegCLIP 85.9 75.4 67.1 70.7 55.0 50.3 67.4 CLIC 86.6 74.0 75.9 52.4 62.2 31.2 63.7 D AC-SAM 85.9 75.1 44.3 56.0 33.5 25.4 53.3 D AC-LLM 89.5 74.2 47.7 59.5 32.9 24.8 54.8 SL VC-R 81.4 69.1 61.6 67.4 53.2 36.3 61.5 SL VC-RL 76.8 66.5 57.1 67.0 48.8 34.3 58.4 CoN CLIP 79.7 66.1 68.1 64.7 50.3 37.2 61.0 T ripletCLIP 85.7 69.7 66.0 71.1 44.4 38.1 62.5 C 2 LIP 89.2 78.8 79.8 80.2 66.2 59.8 75.7 T able 4. Comparison with SO T A foundation models. W e compare performance of C 2 LIP with larger contrastive models (V iT -L), and SO T A models trained with multimodal/multi-task objectives (BLIP , FLA V A, SigLIP-2). Despite the substantial disadvantages in model size and training, C 2 LIP has the best performance on “ Add” and “Replace” tasks of SugarCrepe, and maintains close performance on other benchmarks. On av erage our model is only 1 . 7 percentage points below the best model, CLIPS, which has 5x more parameters. Models SugarCrepe SugarCrepe++ ImNet1K Flickr30k MSCOCO DOCCI IIW A verage Add Replace Swap Replace Swap I2T TO T I2T TO T Multi-task SO TA BLIP-B 92.2 84.1 73.6 76.7 86.0 52.1 41.3 49.2 97.2 79.1 51.6 72.4 71.3 FLA V A 79.6 84.9 73.8 74.3 75.0 56.6 51.0 56.9 91.8 73.9 48.3 72.9 69.9 SigLIP2-V iT -B/16 89.0 86.0 71.9 77.7 69.7 57.9 42.0 78.5 96.5 82.8 62.2 78.1 74.4 Larger models CLIP-A (V iT -L/14) 85.8 82.9 63.8 74.7 74.8 45.8 30.8 79.6 95.2 78.1 59.4 75.4 70.5 CLIPS (V iT -L/14) 86.6 86.1 77.8 76.6 66.6 59.4 44.3 76.8 97.7 82.1 66.2 81.8 75.2 SigLIP V iT -L/16-res256 86.7 84.0 72.8 75.4 64.9 55.6 42.1 80.5 96.7 82.3 62.5 77.6 73.4 C 2 LIP 94.2 88.3 73.1 79.7 75.3 55.2 44.2 73.5 97.0 82.7 60.0 76.4 75.0 Comparison with models that use captioning and/or an LLM component. Contrastiv e learning offers clear ad- vantages ov er models trained with captioning losses, pri- marily due to its inexpensi ve zero-shot capabilities and the strictly separate image and text encoders; properties that, i.e., BLIP [ 17 ] does not possess. Ne vertheless, captioning based methods remain popular , and a comparison is instruc- tiv e. Similarly , LLM based approaches such as FLA V A [ 27 ] are rapidly gaining traction. W e compare C 2 LIP with mod- els that incorporate a captioning loss and with FLA V A in the top part of T ab. 4 . It can be seen that C 2 LIP is competitiv e ev en against these methods. Comparison with larger models. Next, we compare against contrastiv ely trained models that ha ve lar ger param- eter count. The results are shown in the middle part of T ab . 4 . Again, C 2 LIP performs competitiv ely on compo- sitionality tasks despite being considerably smaller . 4.3. Qualitative Results T o verify that our method behaves as intended and indeed yields better binding at the visual token lev el, we visual- ize the change in the attention map when training with our approach compared to SigLIP . Fig. 2 shows results for the caption “black sweater” and “green tablecloth” next to the corresponding images. For instance, it can be seen in Fig. 2a that the sign in the background receives considerably less attention from our C 2 LIP than from SigLIP . At the same time, attention increases or remains high for most patches that cover the sweater . This clearly illustrates that training T able 5. T raining objective ablation. Improvements in (green) with respect to the variant fine-tuned on CC3M. npc : noun-phrase loss, xac : cross-attended concept-aware loss. Both components lead to significant gains. T raining Configurations SugarCrepe Flickr8K Replace Swap Add A verage Object Attribute Relation Object Attribute Object Attribute Original SigLIP V iT -B/16 95.3 86.7 70.3 60.0 71.5 89.1 83.8 79.5 94.9 + fine-tuned on CC3M 95.8 87.4 73.5 65.3 74.2 88.9 87.0 81.7 95.2 + npc 96.7 (+0.9) 89.7 (+2.3) 78.5 (+5.0) 66.5 (+1.2) 78.5 (+4.3) 93.0 (+4.1) 93.9 (+6.9) 85.3 (+3.6) 96.3 (+1.1) + xac ( full ) 96.7 (+0.9) 89.2 (+1.8) 78.9 (+5.4) 67.3 (+2.0) 78.8 (+4.6) 93.5 (+4.6) 94.9 (+7.9) 85.6 (+3.9) 96.4 (+1.2) (a) Caption: “Black sweater” (b) Caption: “Green tablecloth” Figure 2. Change in attention when using C 2 LIP compared to SigLIP . W e visualize the differ ence in attention between C 2 LIP and SigLIP to the visual tokens giv en a caption and an image. Higher attention for C 2 LIP is sho wn as green . Lower attention for C 2 LIP indicated with violet . White means no change. (a) Black re- gions that are not a sweater get reduced attention, the sweater gets more or unchanged attention. (b) The background, the cups and beer cans get attended less after training with our method, while attention to the green tablecloth increases or stays the same. with our model improves binding at the patch lev el (i.e., before global pooling). Moreover , the quantitativ e results presented in Sec. 4.2 further demonstrate that binding im- prov es after global pooling. 4.4. Ablation studies W e perform an ablation study of the components of our pipeline and report the results in T ab . 5 . As can be seen, we observe large improvements across the benchmark when using the noun-phrase loss ( L npc ). Adding the cross-modal attention pooling loss ( L xac ) yields additional gains, par- ticularly for the “Swap” and “ Add” tasks. These results demonstrate that focusing on positiv e examples, i.e., us- ing concept-centric text tokens as extra positives, provides a substantial boost for compositionality . When a cross-modal attention pooling mechanism is also employed, the network can learn more easily , encouraging stronger binding before the global pooling stage. Consequently , performance im- prov es consistently on all benchmarks. 4.5. C 2 LIP impro ves visual instruction tuning In our compositionality experiments, C 2 LIP demonstrates consistent superior accuracies in comparison to similar- sized baselines. Ho wev er, these experiments are limited within the cross-modal retriev al task, and do not provide insights on whether these enhanced capabilities could influ- ence other downstream applications, such as using C 2 LIP as vision encoder for an LLM to train a vision-language model (VLM). Thus, we conduct experiments based on the LLaV a [ 20 ] instruction tuning frame work, where the frozen image encoder is combined with an LLM for image-to- text generation. In particular , we replace the CLIP V iT image encoder of LLaV a with SigLIP and C 2 LIP vision encoders, and train the adapter MLP and LLM following the 2-stage recipe of LLaV a on the same data, resulting in two VLMs, LLaV A-SigLIP and LLaV A-C 2 LIP , respec- tiv ely . The resulting models are ev aluated on SugarCrepe and SugarCrepe++, where the cosine similarity score is sub- stituted with the VQA image-text matching score (VQAS- core) [ 19 ]. The performance metrics are summarized in T ab . 6 . LLaV A-C 2 LIP outperforms LLaV A-SigLIP on both SugarCrepe and SugarCrepe++ by 0.4% and 1.6%, respec- tiv ely , sho wing that the enhanced compositionality compre- hension capabilities of C 2 LIP also transfers to the VLM that utilizes its vision encoder . 5. Conclusion W e propose a ne w method to improve the composition- ality of CLIP-like models. W e process the training cap- tions to extract noun-phrases, i.e., short segments that cor- respond to a single object and its attributes. Using the cap- tion decomposition we obtain a context embedding for each T able 6. Performance of VLM using C 2 LIP vision encoder . W e follow the LLaV a [ 20 ] recipe to train VLMs with frozen SigLIP and C 2 LIP image encoders, resulting in LLaV A-SigLIP and LLaV A-C 2 LIP , respectiv ely . LLaV A-C 2 LIP sho ws improv ements on composition- ality , demonstrating that the vision encoder trained with our proposed concept-centric approach also benefits the VLM that utilizes it. Model SugarCrepe SugarCrepe++ Replace Swap Add A verage Replace Swap A verage SigLIP-V iT -B-16 84.1 65.8 86.5 79.5 73.8 48.0 63.5 C 2 LIP 89.1 75.2 93.3 86.3 79.7 55.2 69.9 LLaV A-SigLIP 86.9 77.0 85.0 83.5 76.5 55.4 68.1 LLaV A-C 2 LIP 86.8 78.5 85.0 83.9 77.6 57.8 69.7 concept in the caption. By aligning each concept embed- ding with the global image embedding and subsequently using a parameter-free attention-pooling function to create visual-domain concept embeddings, we enforce alignment between visual and textual concept embeddings via a con- trastiv e loss. Notably , our method C 2 LIP does not rely on any hard negati ves, which often yield improvements that fail to generalize to slightly different compositionality tasks. Our approach is simple and incurs no additional computa- tional o verhead at inference time; in fact, inference remains identical to the original model. W e ev aluate C 2 LIP on stan- dard compositionality benchmarks as well as a variety of zero-shot and retriev al tasks. C 2 LIP achiev es consistent im- prov ements on all tested compositionality benchmarks and on most standard retriev al tasks. Owing to its consistently strong performance, C 2 LIP attains overall SO T A perfor- mance. Limitations and futur e work. While our approach leads to consistent improv ements without sacrificing gen- eral capabilities, we do observe a small drop in perfor- mance on ImageNet. Future work should explore whether it is possible to reduce this loss ev en further . Similarly , our approach clearly improv es the compositional represen- tation, but the final pooling layer remains suboptimal. Fu- ture work should explore pooling operations that naturally preserve compositionality , and the extensibility of our pro- posed method to other types of compositional reasoning be- yond object-attribute binding. References [1] Rim Assouel, Pietro Astolfi, Florian Bordes, Michal Drozdzal, and Adriana Romero-Soriano. Object-centric binding in contrastiv e language-image pretraining. arXiv pr eprint arXiv:2502.14113 , 2025. 1 , 3 [2] Y uxiao Chen, Jianbo Y uan, Y u Tian, Shijie Geng, Xinyu Li, Ding Zhou, Dimitris N Metaxas, and Hongxia Y ang. Revis- iting multimodal representation in contrastive learning: from patch and token embeddings to finite discrete tokens. In IEEE Conference on Computer V ision and P attern Recog- nition , 2023. 5 , 12 [3] Mehdi Cherti and Romain Beaumont. CLIP benchmark, 2025. 5 [4] Siv an Doveh, Assaf Arbelle, Siv an Harary , Rameswar Panda, Roei Herzig, Eli Schwartz, Donghyun Kim, Raja Giryes, Rogerio Feris, Shimon Ullman, and Leonid Karlin- sky . T eaching structured V ision&Language concepts to vi- sion&language models. In IEEE Conference on Computer V ision and P attern Recognition , 2022. 1 , 3 , 5 , 12 [5] Siv an Dov eh, Assaf Arbelle, Siv an Harary , Roei Herzig, Donghyun Kim, Paola Cascante-bonilla, Amit Alfassy , Rameswar Panda, Raja Giryes, Rogerio Feris, Shimon Ull- man, and Leonid Karlinsky . Dense and aligned captions (D AC) promote compositional reasoning in VL models. In Neural Information Pr ocessing Systems , 2023. 1 , 3 , 5 , 12 [6] Sri Harsha Dumpala, Aman Jaiswal, Chandramouli Sastry , Evangelos Milios, Sageev Oore, and Hassan Sajjad. SUG- ARCREPE++ dataset: vision-language model sensitivity to semantic and lexical alterations. In Neural Information Pr o- cessing Systems - Datasets and Benchmarks T rac k , 2024. 1 , 2 , 12 [7] Roopal Garg, Andrea Burns, Burcu Karagol A yan, Y onatan Bitton, Ceslee Montgomery , Y asumasa Onoe, Andrew Bun- ner , Ranjay Krishna, Jason Baldridge, and Radu Soricut. Im- ageinwords: Unlocking hyper-detailed image descriptions, 2024. 5 [8] B Gurung, David T Hoffmann, and Thomas Brox. Common data properties limit object-attribute binding in clip. In Ger- man Conference on P attern Recognition (GCPR) , 2025. 1 , 3 [9] Matthew Honnibal and Ines Montani. spaCy 2: Natural lan- guage understanding with Bloom embeddings, con volutional neural networks and incremental parsing. T o appear, 2017. 3 , 4 [10] Cheng-Y u Hsieh, Jieyu Zhang, Zixian Ma, Aniruddha Kem- bhavi, and Ranjay Krishna. SugarCrepe: Fixing hackable benchmarks for vision-language compositionality . In Neur al Information Pr ocessing Systems - Datasets and Benchmarks T rack , 2023. 1 , 2 , 3 [11] Gabriel Ilharco, Mitchell W ortsman, Ross Wightman, Cade Gordon, Nicholas Carlini, Rohan T aori, Achal Dav e, V aishaal Shankar, Hongseok Namkoong, John Miller , Han- naneh Hajishirzi, Ali Farhadi, and Ludwig Schmidt. Open- clip, 2021. If you use this software, please cite it as below . 5 [12] Dong Jing, Xiaolong He, Y utian Luo, Nanyi Fei, Guoxing Y ang, W ei W ei, Huiwen Zhao, and Zhiwu Lu. FineCLIP: Self-distilled region-based CLIP for better fine-grained un- derstanding. In Neural Information Processing Systems , 2024. 5 , 12 [13] Alexander Kolesniko v , Alex ey Dosovitskiy , Dirk W eis- senborn, Georg Heigold, Jakob Uszkoreit, Lucas Beyer , Matthias Minderer , Mostafa Dehghani, Neil Houlsby , Syl- vain Gelly , Thomas Unterthiner, and Xiaohua Zhai. An im- age is worth 16x16 words: Transformers for image recogni- tion at scale. In ICLR , 2021. 3 [14] Samuel Lav oie, Polina Kirichenko, Mark Ibrahim, Mido As- sran, Andrew Gordon Wilson, Aaron Courville, and Nico- las Ballas. Modeling caption diversity in contrastive vision- language pretraining. In International Confer ence on Ma- chine Learning , 2024. 5 , 12 [15] Martha Lewis, Nihal V Nayak, Peilin Y u, Qinan Y u, Jack Merullo, Stephen H Bach, and Ellie Pavlick. Does clip bind concepts? probing compositionality in large image models. arXiv pr eprint arXiv:2212.10537 , 2022. 1 , 3 [16] Haoxin Li and Boyang Li. Enhancing vision-language com- positional understanding with multimodal synthetic data. In IEEE Conference on Computer V ision and P attern Recogni- tion , 2025. 3 [17] Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. In Interna- tional Confer ence on Machine Learning , 2022. 5 , 7 [18] Xianhang Li, Zeyu W ang, and Cihang Xie. An inv erse scal- ing la w for CLIP training. In Neural Information Pr ocessing Systems , 2023. 5 [19] Zhiqiu Lin, Deepak Pathak, Baiqi Li, Jiayao Li, Xide Xia, Graham Neubig, Pengchuan Zhang, and De va Ramanan. Evaluating text-to-visual generation with image-to-text gen- eration. In Eur opean Conference on Computer V ision , 2024. 8 [20] Haotian Liu, Chunyuan Li, Y uheng Li, and Y ong Jae Lee. Improv ed baselines with visual instruction tuning. In IEEE Confer ence on Computer V ision and P attern Recognition , 2024. 8 , 9 [21] Y anqing Liu, Xianhang Li, Zeyu W ang, Bingchen Zhao, and Cihang Xie. CLIPS: An enhanced CLIP framework for learning with synthetic captions. arXiv [cs.CV] , 2024. 3 , 5 [22] Y asumasa Onoe, Sunayana Rane, Zachary Berger , Y onatan Bitton, Jaemin Cho, Roopal Garg, Alexander Ku, Zarana Parekh, Jordi Pont-T uset, Garrett T anzer, Su W ang, and Ja- son Baldridge. DOCCI: Descriptions of Connected and Con- trasting Images. In Eur opean Conference on Computer V i- sion , 2024. 5 [23] Maitreya Patel, Abhiram Kusumba, Sheng Cheng, Changhoon Kim, T ejas Gokhale, Chitta Baral, and Y ezhou Y ang. T ripletCLIP: Improving compositional reasoning of CLIP via synthetic vision-language negativ es. In Neural Information Pr ocessing Systems , 2024. 1 , 3 , 5 , 12 [24] Amit Peleg, Naman Deep Singh, and Matthias Hein. Ad- vancing compositional awareness in CLIP with efficient fine- tuning. In Neural Information Processing Systems , 2025. 3 , 5 , 12 [25] Alec Radford, Jong W ook Kim, Chris Hallacy , A. Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry , Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger , and Ilya Sutskever . Learning transferable visual models from nat- ural language supervision. In International Confer ence on Machine Learning , 2021. 1 , 3 [26] Piyush Sharma, Nan Ding, Sebastian Goodman, and Radu Soricut. Conceptual captions: A cleaned, hypernymed, im- age alt-text dataset for automatic image captioning. In Pr o- ceedings of the 56th Annual Meeting of the Association for Computational Linguistics (V olume 1: Long P apers) , pages 2556–2565, 2018. 4 [27] Amanpreet Singh, Ronghang Hu, V edanuj Goswami, Guil- laume Couairon, W ojciech Galuba, Marcus Rohrbach, and Douwe Kiela. FLA V A: A foundational language and vision alignment model. In IEEE Conference on Computer V ision and P attern Recognition , 2022. 5 , 7 [28] Jaisidh Singh, Ishaan Shriv astava, Mayank V atsa, Richa Singh, and Aparna Bharati. Learn “no” to say “yes” better: Improving vision-language models via negations. In W inter Confer ence on Applications of Computer V ision , 2025. 1 , 3 , 5 , 12 [29] Y ingtian T ang, Y utaro Y amada, Y oyo Zhang, and Ilker Y ildirim. When are lemons purple? the concept associa- tion bias of vision-language models. In Empirical Methods in Natural Languag e Processing , 2023. 1 , 3 [30] Michael Tschannen, Alex ey Gritsenk o, Xiao W ang, Muham- mad Ferjad Naeem, Ibrahim Alabdulmohsin, Nikhil Parthasarathy , T alfan Evans, Lucas Beyer , Y e Xia, Basil Mustafa, Olivier H ´ enaff, Jeremiah Harmsen, Andreas Steiner , and Xiaohua Zhai. Siglip 2: Multilingual vision- language encoders with improved semantic understand- ing, localization, and dense features. arXiv pr eprint arXiv:2502.14786 , 2025. 5 [31] Rui Xiao, Sanghwan Kim, Mariana-Iuliana Georgescu, Zeynep Akata, and Stephan Alaniz. FLAIR: Vlm with fine- grained language-informed image representations. In IEEE Confer ence on Computer V ision and P attern Recognition , 2025. 3 , 5 , 12 [32] Chunyu Xie, Bin W ang, Fanjing Kong, Jincheng Li, Dawei Liang, Gengshen Zhang, Dawei Leng, and Y uhui Y in. FG- CLIP: Fine-grained visual and textual alignment. In Interna- tional Confer ence on Machine Learning , 2025. 5 , 12 [33] Mert Y ¨ uksekg ¨ on ¨ ul, Federico Bianchi, Pratyusha Kalluri, Dan Jurafsky , and James Zou. When and why vision- language models behave like bags-of-words, and what to do about it? In International Confere nce on Learning Repr e- sentations , 2023. 1 , 3 , 5 , 12 [34] Xiaohua Zhai, Basil Mustafa, Alexander Kolesniko v , and Lucas Beyer . Sigmoid loss for language image pre-training. In IEEE International Confer ence on Computer V ision , 2023. 3 [35] Le Zhang, Rabiul A wal, and Aishwarya Agrawal. Con- trasting intra-modal and ranking cross-modal hard negati ves to enhance visio-linguistic compositional understanding. In IEEE Conference on Computer V ision and P attern Recogni- tion , 2024. 1 , 3 , 5 , 12 [36] Chenhao Zheng, Jieyu Zhang, Aniruddha Kembha vi, and Ranjay Krishna. Iterated learning improves compositional- ity in large vision-language models. In IEEE Confer ence on Computer V ision and P attern Recognition , 2024. 5 , 12 [37] Kecheng Zheng, Y ifei Zhang, W ei W u, Fan Lu, Shuailei Ma, Xin Jin, W ei Chen, and Y ujun Shen. Dreamlip: Language- image pre-training with long captions. In Eur opean Confer- ence on Computer V ision , 2024. 3 , 4 , 5 , 12 A. Additional experimental results W e provide additional results of our method, C 2 LIP , and the baseline contrastive models employing the same V iT -B backbone listed in T ab. A1 . Please refer to the main paper for details of the benchmarks and ev aluation protocol. This section is organized as follows. First, we show that our proposed loss function is not sensiti ve to scaling hyper - parameters in Sec. A.1 . Next, the ev aluation results on com- positionality benchmarks including SugarCrepe and Sugar- Crepe++ are described in Sec. A.2 . Furthermore, we dis- cuss zero-shot retriev al performance in Sec. A.3 . Finally , the zero-shot classification results are giv en in Sec. A.4 . T able A1. Baseline methods. Summary of baseline methods and their corresponding training datasets. The last column indicates whether the provided checkpoints were trained from scratch ( ✓ ). Model Training data T rain from scratch Composition-aware CE-CLIP [ 35 ] MSCOCO NegCLIP [ 33 ] MSCOCO CLIC [ 24 ] LAION-1.5B D A C [ 5 ] CC3M SL VC [ 4 ] CoN-CLIP [ 28 ] T ripletCLIP [ 23 ] ✓ Codebook-based Codebook-CLIP [ 2 ] ✓ IL-CLIP [ 36 ] ✓ F ine-grained training DreamLIP-3m [ 37 ] ✓ FLAIR-3m [ 31 ] ✓ FG-CLIP [ 32 ] LAION-2B + FineHARD ✓ FineCLIP [ 12 ] MSCOCO LLIP [ 14 ] Common Crawl 12.8B ✓ A.1. Sensitivity to hyperparameters in objective function T ab A2 shows the av erage accuracies on SugarCrepe of models trained with dif ferent values of λ hnc & λ xac . The variation in performance scores is marginal, showing that our proposed loss function function is robust to non-optimal values of of these hyperparameters. W e selected the combi- nation of (1 , 0 . 01) in all our e xperiments. A.2. Compositionality ev aluation In addition to the task-specific av erage scores shown in T ab . 2 of the main paper , we include all accuracy scores of all competing methods on all sub-tasks of SugarCrepe and SugarCrepe++ benchmarks in T ab . A3 and T ab. A4 , re- spectiv ely . SugarCrepe benchmark. As can be seen in T ab . A3 , our concept centric contrastive learning method improves the performance of the original base model, SigLIP , by 7 . 67% T able A2. Ablation of trade-off hyperparameters in the objec- tive function. W e experimented with different values of λ hnc & λ xac showing our proposed method incurs little sensitivity to these hyperparameters. λ hnc λ xac SugarCrepe A verage Accuracy 0.5 0.5 84.6 0.5 0.1 85.2 0.5 0.01 85.2 1 0.5 85.1 1 0.01 85.6 on average, surpassing most other composition-aware meth- ods as the second best performing model, only behind D A C- LLM [ 5 ] by 0.8 percentage points. Notably , these methods rely on training with hard-negati ves to induce the compo- sitionality representations. Instead our method emphasizes better exploiting regular data, with auxiliary concept cen- tric objectiv es, to improve compositional representations. In particular , C 2 LIP excels at recognizing incorrect objects in the image, evidenced by the highest scores on “Replace Object” and “ Add Object” sub-tasks. Moreov er , C 2 LIP ex- hibits strong attribute-binding capabilities, with the highest score on “Swap Attribute” and second best on “Replace At- tribute”. Our method, ho wev er , lags behind in “Replace Re- lation” and “Swap Object” sub-tasks. On the other hand, the substantial improvements on these two sub-tasks compared to the original SigLIP model demonstrate the effecti veness of our method. The results on SugarCrepe should be inter- preted carefully , as the benchmark is insuf ficient to e valuate lexical sensiti vity and semantic understanding [ 6 ]. SugarCrepe++ benchmark. SugarCrepe++ [ 6 ] resolves this problem by extending the protocol of SugarCrepe by using two positive captions and requiring both of them to be higher ranked than the negati ve, to be considered correct. By that, it aims to address the limitation of SugarCrepe, where the caption patterns can be, to some extent, imitated to create custom training data. Howe ver , the second pos- itiv e captions in SugarCrepe++ aim to e v aluate the gener- alization capabilities of contrastiv e models. Intuitiv ely , the concepts in the second caption remain the same as in the first, described differently , thus a model trained to fit the pattern in the first caption may no longer align to the second. As shown in T ab. A4 , the methods relying on custom hard- negati ve training data incur a substantial performance drop across SugarCrepe++ tasks. In contrast, our method per- forms consistently well across all tasks, sho wcasing both ef- fectiv e compositional representation as well as strong gen- eralization capabilities. On average C 2 LIP outperforms the baselines by a lar ge mar gin, made possible by our proposed concept centric learning framew ork. T able A3. SugarCrepe compositionality benchmark – all subtasks . The results in this table are summarized in T ab . 2 of the main paper . W e compare the accuracy of C 2 LIP with baseline methods on different tasks. On average, C 2 LIP is the second best method, only 0.8 percentage points below D A C-LLM, while being trained on much less data, without custom compositional captions. Models Replace Swap Add A verage Obj Attr Rel A vg Obj Attr A vg Obj Attr A vg SigLIP V iT -B/16 95.3 86.7 70.3 84.1 60.0 71.5 65.8 89.1 83.8 86.5 79.5 CLIP (OpenAI) V iT -B/32 90.9 80.0 69.2 80.0 61.2 64.1 62.7 77.2 68.8 73.0 73.1 CLIP (OpenAI) V iT -B/16 93.5 81.1 66.7 80.4 60.0 65.0 62.5 78.5 66.9 72.7 73.1 FG-CLIP 95.9 87.1 72.2 85.1 66.5 73.3 69.9 87.6 81.8 84.7 80.6 FineCLIP 95.6 85.2 75.0 85.3 63.3 70.3 66.8 90.0 80.8 85.4 80.0 DreamLIP-3m 87.2 77.3 68.1 77.5 56.3 72.1 64.2 74.3 71.5 72.9 72.4 FLAIR-3m 91.4 82.3 70.5 81.4 63.2 78.5 70.9 84.5 76.6 80.6 78.1 LLIP 89.6 79.4 67.6 78.9 55.9 59.6 57.8 79.1 63.7 71.4 70.7 Codebook-CLIP 53.5 51.4 58.7 54.5 45.7 49.2 47.5 57.3 43.8 50.6 51.4 IL-CLIP 53.1 54.1 51.1 52.8 57.6 52.7 55.2 54.9 48.6 51.8 53.2 CE-CLIP 93.1 88.8 79.0 87.0 72.8 77.0 74.9 92.4 93.4 92.9 85.2 NegCLIP 92.7 85.9 76.5 85.0 75.2 75.4 75.3 88.8 82.8 85.8 82.5 CLIC 95.6 86.6 75.3 85.8 71.0 74.0 72.5 88.4 91.2 89.8 83.1 D AC-SAM 91.2 85.9 83.9 87.0 71.8 75.1 73.5 87.5 95.7 91.6 84.4 D AC-LLM 94.5 89.5 84.4 89.5 75.1 74.2 74.6 89.7 97.7 93.7 86.4 SL VC-R 91.3 81.4 64.1 78.9 68.6 69.1 68.8 79.5 91.3 85.4 77.9 SL VC-RL 88.1 76.8 62.7 75.9 64.5 66.5 65.5 75.8 81.2 78.5 73.7 CoN-CLIP 92.5 79.7 60.1 77.4 58.8 66.1 62.4 86.7 78.2 82.4 74.6 T ripletCLIP 94.4 85.7 80.9 87.0 70.2 69.7 69.9 90.4 86.1 88.3 82.5 SigLIP V iT -B/16 (ft. CC3m) 95.8 87.4 73.5 85.6 65.3 74.2 69.7 88.9 87.0 87.9 81.7 C 2 LIP 96.7 89.2 78.9 88.3 67.3 78.8 73.1 93.5 94.9 94.2 85.6 A.3. Zero-shot r etrieval e valuation W e ev aluate our proposed method and the baselines on two regular retrie val benchmarks: MSCOCO and Flickr30k, and two fine-grained retriev al benchmarks: DOCCI and Image- in-words (IIW). W e report Recall@5 scores of image-to- text and text-to-image retriev al tasks, as summarized in T ab . A5 . As sho wn in this table, the composition-aware methods incur degraded retriev al performance compared to the base CLIP model. In contrast, C 2 LIP performs consis- tently well. It is the best performing model on most tasks, and on par with the top models for the remaining tasks. Our model enjoys 1.9 percentage point improvement over the original SigLIP on average. These results prov e that our training method not only effecti vely maintains, b ut can also improv e the generalization capability of the original model. A.4. Zero-shot classification e valuation Pretrained contrastiv e V&L models are increasingly em- ployed in a variety of do wnstream tasks in computer vision. One of them is zero-shot classification, which made this class of models popular in the first place. W e ev aluate our method and all baselines on 11 classification benchmarks, their accuracies are summarized in T ab. A6 . Among the composition-aware baselines, all methods significantly drop their performance on zero-shot classification. Only CLIC almost reaches the accuracy of the original CLIP model ( 68 . 1 and 69 , respectively), thanks to the generated train- ing data that helps improve generalization in addition to the hard-negati ves. Our model incurs a slight 2 . 9% per- formance drop compared to the original SigLIP , which is comparativ ely small in comparison to the other fine-tuned methods. The drop in performance is not surprising, as our model was fine-tuned with scene centric objectiv es and data, whereas the classification tas ks are object centric. De- spite the distributional shift, C 2 LIP can still retain most zero-shot performance. T able A4. SugarCrepe++ compositionality benchmark – all subtasks . The results in this table are summarized in T ab . 2 of the main paper . W e compare the accuracy of C 2 LIP with baseline methods on different compositionality tasks. SugarCrepe++ addresses the limi- tation of the SugarCrepe benchmark, where the positive and negati ve captions are “hackable” by using custom training data created using similar rules. Here we observe significant performance drops from the baseline methods, while our model, which maintains generalization capabilities, achiev es the best result overall. Models Replace - I2T Replace - TO T Swap - I2T Swap - TO T A verage Obj Attr Rel A vg Obj Attr Rel A vg Obj Attr A vg Obj Attr A vg SigLIP V iT -B/16 91.2 75.5 54.8 73.8 79.2 64.2 45.0 62.8 39.6 56.3 48.0 22.9 46.4 34.7 57.5 CLIP (OpenAI) V iT -B/32 86.7 65.6 56.3 69.5 83.7 59.3 38.6 60.5 46.1 45.2 45.7 19.1 35.6 27.4 53.6 CLIP (OpenAI) V iT -B/16 89.6 67.6 53.2 70.1 84.4 57.2 39.0 60.2 39.2 48.4 43.8 16.3 31.4 23.9 52.6 FG-CLIP 92.6 76.8 58.0 75.8 90.6 67.8 44.2 67.5 47.8 55.3 51.5 29.4 47.0 38.2 60.9 FineCLIP 90.8 70.7 57.0 72.8 91.3 67.9 47.0 68.7 39.6 48.2 43.9 20.8 32.7 26.8 56.6 DreamLIP-3m 75.8 60.8 46.9 61.2 71.4 50.8 32.4 51.5 34.3 54.4 44.4 20.0 40.1 30.1 48.7 FLAIR-3m 84.3 64.2 50.3 66.3 77.3 58.4 36.8 57.5 40.8 58.3 49.5 24.9 45.5 35.2 54.1 LLIP 84.1 66.0 51.9 67.3 71.2 54.8 44.5 56.8 36.7 44.9 40.8 24.5 30.2 27.3 50.9 Codebook-CLIP 32.3 32.6 37.8 34.3 18.2 9.8 13.5 13.8 28.2 28.5 28.3 8.6 11.6 10.1 22.1 IL-CLIP 38.0 32.9 32.4 34.4 55.8 18.5 21.3 31.8 39.2 34.7 36.9 9.4 20.0 14.7 30.2 CE-CLIP 71.9 52.0 45.5 56.5 86.3 64.2 50.5 67.0 36.3 32.3 34.3 28.6 36.3 32.5 50.4 NegCLIP 87.0 67.1 53.1 69.1 93.3 70.7 48.6 70.9 51.8 55.0 53.4 27.8 50.3 39.1 60.5 CLIC 91.6 75.9 62.3 76.6 84.7 52.4 37.3 58.1 55.9 62.2 59.0 22.9 31.2 27.0 57.6 D AC-SAM 64.3 44.3 48.7 52.4 75.9 56.0 48.7 60.2 27.8 33.5 30.6 11.4 25.4 18.4 43.6 D AC-LLM 65.7 47.7 47.6 53.7 76.8 59.5 42.3 59.6 31.4 32.9 32.2 11.4 24.8 18.1 44.0 SL VC-R 82.9 61.6 47.7 64.0 89.5 67.4 47.7 68.2 49.4 53.2 51.3 20.4 36.3 28.4 55.6 SL VC-RL 81.0 57.1 47.5 61.9 91.6 67.0 51.3 70.0 43.3 48.8 46.0 18.4 34.3 26.3 54.0 CoN CLIP 87.9 68.1 48.2 68.1 91.5 64.7 53.9 70.1 40.0 50.3 45.2 18.8 37.2 28.0 56.1 T ripletCLIP 84.9 66.0 58.7 69.9 89.0 71.1 48.1 69.4 38.4 4.4 21.4 18.8 38.1 28.5 51.7 SigLIP V iT -B/16 (ft. CC3m) 91.7 74.2 54.6 73.5 85.4 69.3 48.9 67.9 42.5 57.2 49.8 23.7 49.6 36.6 59.7 C 2 LIP 93.9 79.8 65.4 79.7 91.1 80.2 54.7 75.3 44.1 66.2 55.2 28.6 59.8 44.2 66.4 T able A5. Zero-shot retrie val benchmarks – all subtasks . The results in this table are summarized in T ab. 2 of the main paper . W e record Recall@5 metrics of all models on text-to=image (t2i) and image-to-text (i2t) tasks, across two standard retriev al benchmarks: MSCOCO and Flickr30K, and two fine-grained retriev al benchmarks: DOCCI and Image-in-w ords (IIW). It can be observed that C 2 LIP can maintain or improv e the performance of the original base model across all tasks, with the best av erage score. Models MSCOCO Flickr30k DOCCI IIW A verage t2i i2t t2i i2t t2i i2t t2i i2t SigLIP V iT -B/16 72.4 85.4 92.3 98.0 35.8 82.0 53.0 97.5 77.1 CLIP (OpenAI) V iT -B/32 56.0 74.9 83.4 94.6 27.1 67.1 44.7 94.3 67.8 CLIP (OpenAI) V iT -B/16 58.4 76.7 85.6 96.2 29.3 71.5 46.7 95.9 70.0 FG-CLIP 71.4 85.5 93.0 98.6 33.9 79.4 52.5 98.7 76.6 FineCLIP 73.7 84.2 90.2 96.7 27.9 61.9 44.6 89.5 71.1 DreamLIP-3m 55.2 67.2 76.6 89.6 39.3 78.2 58.5 97.4 70.2 FLAIR-3m 65.6 77.3 86.5 94.3 30.9 63.4 53.0 92.7 70.5 LLIP 62.3 72.8 87.3 93.1 28.6 65.2 48.3 93.1 68.8 Codebook-CLIP 0.1 0.1 0.5 0.6 0.1 0.1 0.8 0.5 0.3 IL-CLIP 0.1 0.1 0.3 0.5 0.1 0.1 0.7 0.7 0.3 CE-CLIP 69.5 74.3 86.4 88.4 19.1 42.4 31.4 68.8 60.0 NegCLIP 68.4 79.3 89.5 95.2 26.4 64.0 43.5 89.4 69.5 CLIC 62.9 71.9 88.2 94.0 33.1 69.4 52.2 94.6 70.8 D AC-SAM 59.7 57.9 85.5 82.5 26.9 35.5 45.5 55.7 56.2 D AC-LLM 63.5 54.5 87.8 79.6 24.8 29.4 40.9 46.9 53.4 SL VC-R 62.0 71.7 87.2 93.1 29.9 54.3 48.6 83.7 66.3 SL VC-RL 62.3 71.8 87.4 92.5 29.7 53.9 48.0 86.6 66.5 CoN-CLIP 54.6 67.9 84.2 87.9 27.2 64.9 42.6 91.5 65.1 T ripletCLIP 53.3 55.6 80.9 82.6 25.3 54.2 43.0 82.0 59.6 SigLIP V iT -B/16 (ft. CC3m) 73.7 87.0 92.8 98.4 36.2 83.3 53.0 97.9 77.8 C 2 LIP 77.9 87.5 95.2 98.8 38.0 81.9 56.1 96.7 79.0 T able A6. Zero-shot classification benchmarks . W e ev aluate classification accuracies of C 2 LIP and the baselines on 11 standard zero- shot classification benchmarks. W e observe significantly better performance of our model compared the composition-aware baselines in general, particularly on the challenging Cars and Air craft benchmarks where the classes are actually sub-classes of the same object category . Model ImageNet1K Food-101 CIF AR-10 CIF AR-100 SUN397 Cars Aircraft DTD Pets Caltech-101 Flowers A verage SigLIP V iT -B/16 76.1 91.6 92.3 72.2 69.9 90.9 43.8 64.7 94.1 88.0 86.0 79.0 CLIP (OpenAI) V iT -B/32 63.3 83.9 89.8 64.3 63.2 59.7 19.6 44.0 87.5 83.8 66.5 66.0 CLIP (OpenAI) V iT -B/16 68.4 88.8 90.8 67.0 65.5 64.7 24.5 45.2 89.2 84.0 71.5 69.0 FG-CLIP 69.0 85.2 93.9 76.4 71.2 84.2 24.4 57.2 90.5 86.2 70.1 73.5 FineCLIP 55.8 60.1 94.3 69.0 55.9 6.3 10.7 41.6 57.9 85.4 41.4 52.6 DreamLIP-3m 31.6 23.6 75.7 43.7 41.3 3.5 1.6 18.8 28.9 70.3 18.5 32.5 FLAIR-3m 33.7 24.8 81.9 51.6 47.0 4.0 2.0 24.3 35.8 72.4 20.4 36.2 LLIP 60.8 80.5 94.4 69.8 57.7 77.1 22.3 53.3 78.8 85.3 42.9 65.7 Codebook-CLIP 0.1 1.0 11.0 1.1 0.4 0.5 1.1 2.0 2.2 0.9 1.2 1.9 IL-CLIP 0.1 1.0 10.0 1.0 0.1 0.5 1.0 1.6 2.7 0.9 1.1 1.8 CE-CLIP 40.4 59.8 81.2 55.0 44.0 26.1 9.2 28.5 60.9 76.0 37.3 47.1 NegCLIP 55.7 74.1 85.9 60.9 55.9 46.0 11.8 39.1 82.3 82.5 58.0 59.3 CLIC 66.6 88.9 91.1 68.3 64.0 60.8 23.7 46.7 88.0 84.0 67.5 68.1 D AC-SAM 52.3 72.3 89.9 63.7 51.4 39.8 9.0 40.2 77.0 78.0 54.2 57.1 D AC-LLM 51.1 74.5 90.4 63.9 52.1 39.5 11.3 38.5 74.9 79.8 54.9 57.3 SL VC-R 58.5 81.3 92.3 66.0 62.6 49.6 14.9 39.4 85.8 81.9 59.7 62.9 SL VC-RL 59.8 81.7 92.0 66.7 63.7 50.6 14.5 39.8 85.0 82.7 61.3 63.4 CoN-CLIP 63.7 84.5 88.7 63.0 64.0 55.5 19.0 40.4 85.2 83.3 63.3 64.6 T ripletCLIP 45.9 58.7 86.9 56.6 53.6 11.7 7.9 33.1 55.2 78.3 45.2 48.5 SigLIP V iT -B/16 (ft. CC3m) 75.9 91.6 92.4 72.7 70.3 90.8 44.4 65.1 94.4 88.0 86.1 79.2 C 2 LIP 73.5 88.7 92.7 72.6 68.1 87.4 32.8 65.1 92.3 87.2 82.9 76.7
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment