하드 네거티브 없이 개념 중심 학습으로 구성성 향상 및 제로샷 유지
본 논문은 긴 캡션과 전역 풀링이 구성성 학습을 방해한다는 두 근본 원인을 제시하고, 짧은 명사구 중심 캡션과 파라미터‑프리 교차‑모달 어텐션 풀링을 결합한 C²LIP 방법을 제안한다. 기존의 하드 네거티브 기반 접근법과 달리 실제 데이터의 명사구만을 활용해 보조 대조 손실을 추가함으로써, 복합성 벤치마크에서 SOTA 성능을 달성하면서도 제로샷 이미지 분류·검색 능력을 유지하거나 향상시킨다.
저자: Hai X. Pham, David T. Hoffmann, Ricardo Guerrero
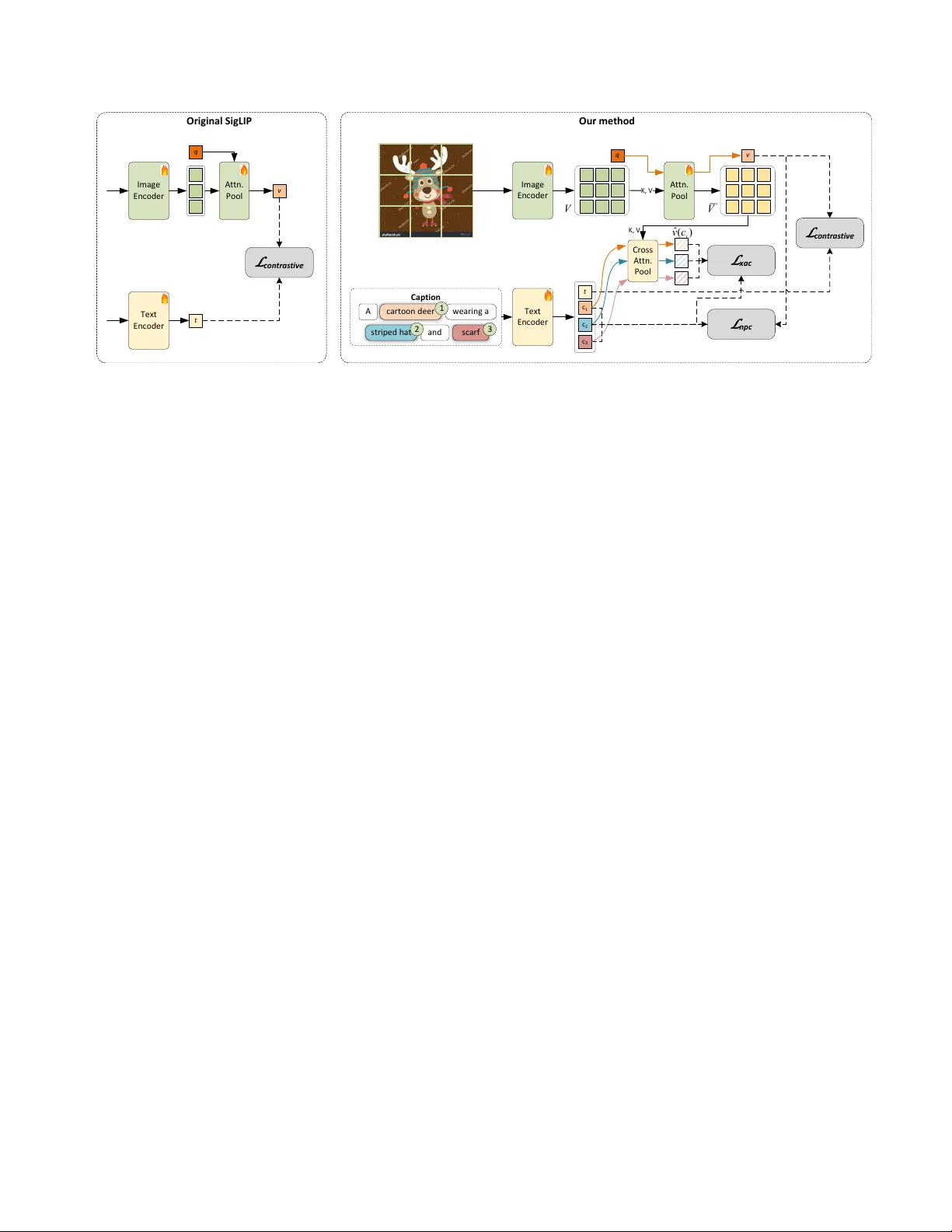
본 논문은 대조 학습 기반 비전‑언어 모델이 복합적인 의미 결합을 학습하는 데 겪는 근본적인 한계를 분석하고, 이를 해결하기 위한 새로운 학습 프레임워크인 C²LIP(Concept‑centric CLIP)를 제안한다. 기존 CLIP·SigLIP 등은 이미지와 긴 캡션을 쌍으로 학습하면서, 캡션 내의 명사와 속성(형용사, 관계 등)이 서로 결합된 구조적 정보를 별도로 학습하지 않아도 이미지‑텍스트 매칭이 가능하도록 만든다. 이는 모델이 단순히 단어들의 존재 여부만을 파악하는 Bag‑of‑Words(BOW) 표현에 머무르게 하며, ‘a red couch’와 같이 명사와 속성을 결합해야만 정확히 구분되는 상황에서 오류를 범한다.
논문은 이러한 현상의 두 가지 원인을 제시한다. 첫째, 훈련 시 사용되는 캡션이 길고 상세하기 때문에, 모델이 전체 캡션을 전역 풀링한 뒤에도 개별 개념을 구분할 필요가 없다는 점이다. 둘째, 이미지와 텍스트 인코더의 최종 전역 풀링 단계가 모든 토큰을 하나의 벡터로 압축하면서, 명사와 속성 사이의 바인딩 정보를 완전히 소실시킨다. 기존 연구들은 하드 네거티브(인위적으로 만든 어려운 부정 샘플)를 생성해 대조 손실에 추가함으로써 이 문제를 완화하려 했지만, 하드 네거티브는 특정 규칙에 의존해 일반화가 어렵고, 제로샷 분류·검색 같은 다른 다운스트림 작업에서 성능 저하를 일으킨다.
C²LIP은 하드 네거티브 없이도 실제 데이터만으로 구성성을 학습할 수 있는 두 가지 핵심 아이디어를 도입한다. 첫 번째는 캡션에서 명사구(‘concept’)만을 추출해 짧고 의미가 명확한 텍스트 단위로 변환하는 것이다. spaCy와 같은 오픈소스 NLP 툴을 이용해 ‘a red couch’, ‘the tall building’ 등 명사와 그 수식어가 결합된 구문을 자동으로 식별한다. 이러한 명사구는 BOW 방식으로는 구분이 어려워, 모델이 실제 의미적 바인딩을 학습하도록 강제한다. 두 번째는 파라미터‑프리 교차‑모달 어텐션 풀링(cross‑modal attention‑pooling)이다. 이미지 인코더의 마지막 레이어에서 얻은 토큰 집합 V에 대해, 각 명사구 텍스트 임베딩 c_k를 쿼리로 사용해 어텐션을 수행한다. 어텐션 가중치에 따라 이미지 토큰을 가중합해 명사구‑특화 시각 임베딩 ˆv(c_k)를 얻으며, 이는 명사구와 직접 매칭되는 시각 정보를 포함한다. 이 풀링 연산은 학습 단계에서만 적용되고, 파라미터가 없으며, 추론 시에는 기존 CLIP과 동일하게 전역 풀링된 이미지 벡터 v만 사용한다. 따라서 연산 비용이 전혀 증가하지 않는다.
학습 목표는 세 가지 손실을 결합한다. (1) 기존 전역 대조 손실 L_contrastive는 이미지와 전체 캡션을 매칭한다. (2) 명사구‑대 이미지 대조 손실 L_npc는 각 이미지와 그 이미지에 대응하는 모든 명사구를 동시에 매칭한다. 이는 다중‑양성(멀티‑포지티브) 형태의 대조 손실로, 각 명사구 c_j와 이미지 v_i 사이의 코사인 유사도를 최대화한다. (3) 교차‑모달 어텐션 풀링 손실 L_attn은 명사구 텍스트 임베딩 c_k와 해당 어텐션 풀링을 통해 얻은 시각 임베딩 ˆv(c_k) 사이의 정합성을 촉진한다. 세 손실은 모두 파라미터‑프리 어텐션 연산을 기반으로 하며, 기존 SigLIP 구조에 최소한의 변경만 가한다.
실험에서는 SigLIP‑ViT‑B/16을 베이스 모델로 사용해, SugarCrepe와 SugarCrepe++라는 두 개의 구성성 평가 벤치마크에서 기존 최첨단 방법들을 크게 앞섰다. 특히 하드 네거티브 기반 방법들이 특정 규칙에 맞춘 부정 샘플에만 강인함을 보이며, 새로운 구성성 테스트에서는 성능이 급격히 떨어지는 반면, C²LIP은 전반적인 구성성 점수에서 2~3%p 이상의 향상을 기록했다. 제로샷 이미지넷 분류에서는 사전 학습 대비 약 0.5%p 정도의 소폭 감소가 있었지만, 이는 파인튜닝 데이터가 사전 학습보다 다양성이 낮고, 장면 중심 표현이 이미지넷의 객체 중심 라벨과 다소 충돌하기 때문이라고 설명한다. 이미지‑텍스트 검색(Flickr30K, COCO)에서도 기존 CLIP 대비 1~2%p 정도의 mAP 향상을 보였으며, 전체 파라미터 수와 추론 시간은 변함이 없었다.
결론적으로 C²LIP은 (1) 하드 네거티브 없이 실제 캡션 데이터만으로 구성성을 학습한다는 점, (2) 파라미터‑프리 교차‑모달 어텐션 풀링을 통해 전역 풀링 이전에 명사와 속성 간 바인딩을 학습한다는 점, (3) 기존 CLIP/SigLIP 파이프라인과 완벽히 호환되어 추론 비용이 증가하지 않는다는 점에서 실용적이며, 향후 다양한 CLIP 변형이나 멀티모달 트랜스포머에 적용해 더 넓은 도메인으로 일반화할 가능성을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기