Agent Factories for High Level Synthesis: How Far Can General-Purpose Coding Agents Go in Hardware Optimization?
We present an empirical study of how far general-purpose coding agents -- without hardware-specific training -- can optimize hardware designs from high-level algorithmic specifications. We introduce an agent factory, a two-stage pipeline that constru…
Authors: Abhishek Bh, waldar, Mihir Choudhury
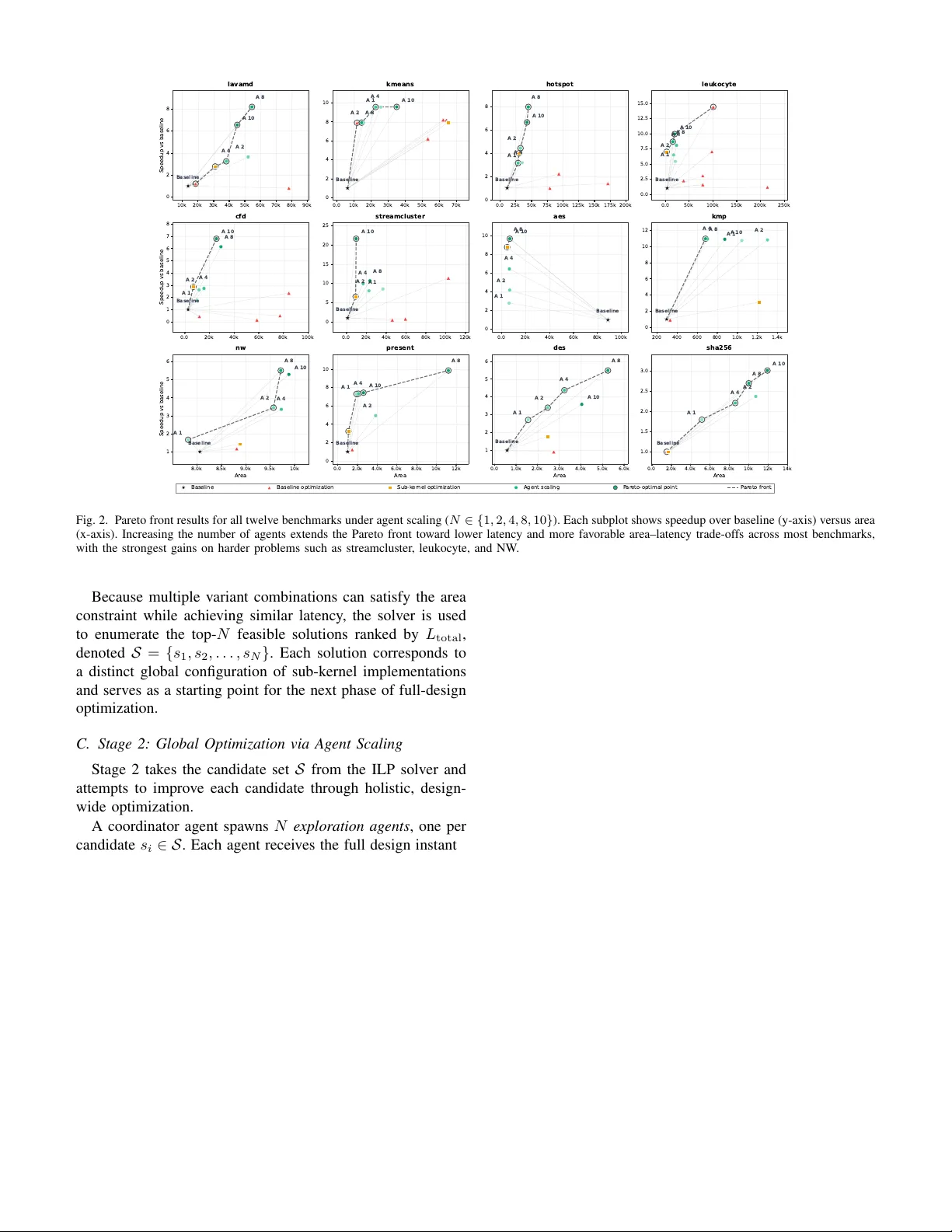
Agent F actories for High Le v el Synthesis: Ho w F ar Can General-Purpose Coding Agents Go in Hardware Optimization? Abhishek Bhandwaldar , Mihir Choudhury , Ruchir Puri, Akash Sri vasta v a IBM Corporation Abstract —W e present an empirical study of how far general- purpose coding agents—with no hardwar e-specific training— can go in optimizing hardwar e designs from high-lev el algo- rithmic specifications. Our method, an agent factory , is a two- stage pipeline that builds and coordinates multiple autonomous optimization agents. In Stage 1, the factory decomposes a design into sub-kernels, independently optimizes each through pragma and code-lev el transformations, and solves an Integer Linear Program to assemble globally promising configurations under area constraints. In Stage 2, it spawns N expert agents over the top ILP solutions, each exploring cross-function optimizations— pragma r ecombination, loop fusion, memory restructuring—that sub-kernel decomposition cannot reach. W e ev aluate the pipeline on twelve kernels from HLS-Eval and Rodinia-HLS using Claude Code (Opus 4.5/4.6) with AMD V i- tis HLS. Scaling from 1 to 10 agents yields a mean 8 . 27 × speedup over baseline, with gains concentrated on harder problems: streamcluster exceeds 20 × and kmeans reaches ∼ 10 × . Across benchmarks, agents consistently recover known hardware opti- mization patterns without domain-specific training, and winning designs frequently originate from non-top-ranked ILP variants, confirming that global optimization uncov ers impro vements in vis- ible to sub-kernel sear ch. These findings establish agent scaling as a practical axis for HLS optimization. W e pro vide an anonymized implementation here. Index T erms —Large Language Models (LLMs), Multi-Agent Systems, Agentic AI, Inference-Time Scaling, High-Level Synthe- sis (HLS), Design Space Exploration (DSE), Hardwar e Optimiza- tion I . I N T R O D U CT I O N High-Lev el Synthesis (HLS) striv es to raise the abstraction of hardware design from R TL to C/C++, with the goal of achieving high performance. Howe ver , with current state-of- the-art HLS tools, significant expert-dri ven pragma insertion and code restructuring remains necessary to achiev e desirable results [1]–[3]. Selecting the right combination of directiv es such as PIPELINE , UNROLL , ARRAY_PARTITION , and others requires deep hardware kno wledge, careful latency-area tradeoff reasoning, and extensi ve iteration with the synthesis toolchain [4]. As an example, Cong et al. report that more than 40% of lines of high-level code in a real-world genomics kernel were attrib utable to hardware-specific optimizations and pragmas alone [4], illustrating the manual effort that persists ev en with modern HLS tools. Existing automation approaches treat high-level code to R TL generation as a black-box optimization problem ov er a predefined parameter space. Bayesian optimization meth- Input design 𝒟 Stage 1: Sub-kernel Optimization + ILP Selection Coordinator Agent Extract call graph G(f₁, …, f ₖ ) Optimizer Agent f₁ M = 7 variants Optimizer Agent f₂ M = 7 variants ··· Optimizer Agent f ₖ M = 7 variants Evaluate V ariants Correctness check → HLS synthesis → (L, A) ILP Solver min L_total(x) s.t. A ≤ 𝒜 _budget T op-N solutions 𝒮 = {s₁, …, s ₙ } Stage 2: Global Optimization via Agent Scaling Exploration Agent 1 starting from s₁ Exploration Agent 2 starting from s₂ ··· Exploration Agent N starting from s ₙ Design-wide Exploration Paths ① Pragma composition ② Code restructure ③ Memory opt. ④ Compute opt. Iterate argmin L(d) s.t. A(d) ≤ 𝒜 _budget Optimized design 𝒟 * Fig. 1. T wo-stage agent-based pipeline for HLS design space exploration. Giv en an input design D , a coordinator agent extracts the function call graph G and spawns one optimizer agent per sub-function f 1 , . . . , f K . V ariants are ev aluated for correctness and synthesized to obtain (latency , area) pairs. An ILP solver then selects the top- N combinations S = { s 1 , . . . , s N } that minimize total latency subject to the area budget. In Stage 2, N exploration agents each start from a candidate solution and iterativ ely apply design-wide optimization paths, to produce the final optimized design D ∗ . ods [5]–[7] build surrogate models over pragma configu- rations; Integer Linear Programming (ILP) and non-linear programming formulations [8], [9] compose optimized con- figurations from pre-enumerated candidates. These approaches navigate large configuration spaces efficiently , but cannot restructure code, rewrite algorithms, or discover optimizations outside the predefined parameter space. Recent LLM-based methods [10]–[12] are a promising step, but most still operate within structured pragma selection rather than open-ended program transformation. This work explores how far g eneral-purpose coding agents—with no HLS-specific training—can go in optimizing har dwar e designs, given only sour ce code, synthesis tool ac- cess, and fr eedom to modify both code and pra gmas. The moti- vation is straightforward: recent agentic coding systems [13]– [16] hav e shown that LLM-based agents can iteratively refine code using tool feedback across a range of software engi- neering tasks, and similar agent-driven optimization efforts are emerging in adjacent domains [17]. The key question is whether this capability transfers to the hardware domain, where optimization requires reasoning about latency , area, memory bandwidth, and non-obvious pragma interactions. Un- like parameter-sweep methods, agents search ov er pr ograms : in principle, they can restructure loops, replace computations with closed-form expressions, or reorganize memory access. In practice, as our results show , agents most often discover effecti ve pragma strategies, but occasionally apply code-lev el transformations that go beyond what predefined parameter spaces can enumerate. Our frame work uses an ag ent factory that generates multiple autonomous optimization agents exploring different trajecto- ries through the design space. The framework operates in two stages: (1) sub-kernels are independently optimized and combined via ILP under area constraints; (2) N global agents explore full-design transformations ov er the top-ranked ILP solutions. By v arying N , we study whether agent scaling, allocating more inference-time compute, improv es solution quality . W e ev aluate the pipeline on 12 kernels: 6 from prior HLS benchmarks [12] and 6 from Rodinia-HLS [18], using Claude Code (Opus 4.5/4.6) and AMD V itis HLS. W e frame this as an empirical study : our benchmark set is small, sev eral kernels are well-studied, and results are specific to a single model family and toolchain. The contribution is a systematic characterization of what general-purpose agents can and cannot do in hardware optimization, with the goal of establishing a baseline that the community can build upon. Our findings: 1. Agent scaling improv es exploration. Increasing the number of agents from 1 to 10 yields a mean 8 . 27 × speedup ov er baseline, with the largest gains on complex workloads: str eamcluster exceeds 20 × , and kmeans reaches ∼ 10 × . Sim- pler or pipeline-dominated kernels show limited or saturating improv ements. 2. Agents go bey ond isolated pragma selection. The best final design does not always originate from the top-ranked ILP variant, indicating that global optimization across function boundaries can uncov er improvements not reachable by sub- kernel search alone. On lavamd , agents achiev e ∼ 8 × speedup at ∼ 40 – 60 K area, improving area–latency trade-offs compared to reference implementations. 3. Agents recover known hardware optimization pat- terns without training. Across kernels, agents consistently apply ARRAY_PARTITION to resolve memory bottlenecks and learn that PIPELINE is ineffecti ve unless loop-carried dependencies are first addressed, patterns that align with established HLS expertise. 4. Limitations are significant and inform future work. This is a preliminary study with inherent scope constraints. The benchmark set of twelve kernels does not capture the full complexity of real-world HLS workloads. All experiments use a single model family (Claude Opus 4.5/4.6), a single synthesis tool (V itis HLS), and a single target architecture (FPGA). Baselines, while systematic, are bounded exhausti ve searches ov er restricted directi ve sets rather than comparisons against state-of-the-art DSE frameworks such as AutoDSE. Gains are also uneven: simpler kernels saturate early , and under tight area budgets additional agents can increase area without proportional latency improvement. W e vie w this study as a starting point intended to bootstrap a line of in vestigation that can be extended, through broader benchmarks, stronger baselines, additional models, and div erse target architectures, via community contribution. I I . R E L A T E D W O R K a) Automated Design Space Exploration for HLS: Opti- mizing HLS designs requires tuning directiv es such as pipelin- ing, unrolling, and memory partitioning, motiv ating extensiv e work on automated DSE. Early approaches relied on heuris- tic and analytical strate gies [19], [20], follo wed by iterative synthesis-driv en frame works [1], lattice-based trav ersal [21], multi-lev el parallelism modeling [22], and multi-strategy au- totuning [2], [23], [24]. Learning-based methods accelerate DSE through surrogate models [1], [3], [25], [26], GNN- based program representations [27]–[29], and cross-modality learning [30]. These approaches largely treat optimization as search over a predefined parameter space, limiting their ability to perform open-ended program transformations or capture global interactions across sub-kernels. b) LLM-based Optimization for HLS: Recent work ap- plies LLMs to HLS optimization along three directions. First, directiv e generation systems such as HLSPilot, LIFT , LLM- DSE, and iDSE use LLMs to propose pragma configura- tions within synthesis-in-the-loop feedback [10], [11], [31], [32], but remain within predefined parameter spaces. Second, source-to-source transformation approaches iterativ ely con vert C/C++ into synthesizable HLS code, focusing primarily on correctness and synthesizability [33], [34]. Third, agentic pipelines integrate profiling, transformation, and DSE [11], [35], but typically follow a single optimization trajectory or fixed coordination strategy . c) Agentic LLM Systems and Scaling: LLM-based agents enable multi-step reasoning, tool use, and iterative code refine- ment across software engineering tasks [13]–[16]. Our work builds on this paradigm by treating the number of agents as inference-time compute, analogous to test-time scaling [36]. While prior agentic systems typically rely on a small number of coordinated agents, we study agent scaling as a first-class design dimension for HLS optimization. I I I . M E T H O D Giv en an input program written in a high-level language (e.g., C/C++) and a target implementation such as an FPGA platform or ASIC with resource limits, the goal of HLS design space exploration is to find an implementation that minimizes ex ecution latency (in clock cycles) while satisfying area con- straints, flip-flops, RAMs, and DSP blocks. The design space consists of all feasible combinations of HLS pragma assign- ments (e.g., PIPELINE , UNROLL , ARRAY_PARTITION ) and code-lev el transformations (e.g., loop restructuring, mem- ory reorganization) applied to the input program, where each configuration yields a distinct hardware implementation with different latency and resource utilization. This space is difficult to explore for three reasons: 1) First, the number of feasible configurations grows com- binatorially with the number of loops, arrays, and func- tions, and each configuration requires an HLS synthesis run that may take minutes, making exhausti ve search impractical. 2) Second, optimization decisions interact globally: aggres- siv ely optimizing one function may e xhaust the area bud- get and prev ent improvements elsewhere, so exploration must balance decisions across the full design. 3) Third, the effect of pragmas is non-linear and some- times counterintuitive – for example, in the Needleman– W unsch kernel, fully unrolling the reverse_string loop increased latency from 26 to 71 cycles due to mem- ory port contention, illustrating that more aggressive optimization does not always improve performance. These challenges motiv ate a two-stage pipeline that decom- poses the problem into independent sub-kernel optimization followed by global, design-wide exploration. A. Notation Let the input design D consist of a top-lev el function that inv okes a set of sub-functions F = { f 1 , f 2 , . . . , f K } . W e extract a function call graph G = ( F , E ) , where a directed edge ( f i , f j ) ∈ E indicates that f i in vokes f j . From G we compute the critical path and classify inter-function dependencies as sequential or parallel. For each sub-function f k , we define a variant set V k = { v 0 k , v 1 k , . . . , v M k } , where each variant v m k is a distinct opti- mization configuration (pragma assignment and/or code trans- formation). Each variant is characterized by its latency L m k and area A m k , obtained through HLS synthesis after passing a functional correctness check. A binary selection variable x m k ∈ { 0 , 1 } indicates whether v ariant m of sub-function k is selected. Let A budget denote the global area constraint imposed by the target FPGA platform, and let L baseline denote the latency of the unoptimized design. B. Stage 1: Sub-Kernel Optimization and ILP Selection Stage 1 proceeds in three phases: variant generation, ev al- uation, and ILP-based selection. T ABLE I V A R I AN T E X P LO R A T I ON S T RAT EG Y P E R S U B - F U N CT I O N . V ariant Strategy v 0 k Baseline: synthesize unmodified code v 1 k Conservati ve: minimal pragmas, low area v 2 , 3 k Pipeline: PIPELINE II ∈ { 1 , 2 , 4 } v 4 , 5 k Aggressiv e: pipeline + partial/full UNROLL v 6 k Alternate: ARRAY_PARTITION , INLINE , closed-form rewrites 1) Phase 1a — V ariant Generation: A coordinator agent analyzes the call graph G and spawns one optimizer agent per sub-function f k ∈ F . Each optimizer explores M = 7 variants following a structured strategy (T able I). 2) Phase 1b — Evaluation: Each v ariant v m k is ev aluated through a pipeline of (i) functional correctness testing against the original design, (ii) HLS synthesis on the target platform, and (iii) extraction of latency L m k and area A m k . V ariants that fail correctness are discarded. 3) Phase 1c — ILP F ormulation: Once all optimizer agents complete, the coordinator aggregates the survi ving variants for each sub-kernel. At this stage, each function f k has multiple candidate implementations with latency L m k and area A m k obtained from HLS synthesis. Selecting the best variant for each function independently is insufficient, because the latency of the overall design depends on how these functions compose in the program execution structure. In HLS designs, functions may execute sequentially , ov erlap through pipelining, or appear within loop iterations. As a result, the global latency cannot be e xpressed as a simple sum of individual function latencies. T o determine how candidate variants interact in the full design, the coordinator analyzes the program call graph G and deriv es a latency composition model that reflects the ex ecution structure of the program. For sub-functions on a sequential path, latencies accumulate; for sub-functions that e xecute in parallel regions, the dominant latency determines the stage duration. The resulting latency model is expressed as L total ( x ) = h { L m k · x m k } k,m , (1) where h ( · ) encodes the latency composition derived from the call graph (e.g., sums along sequential chains and maxima ov er parallel branches, with appropriate loop multipliers). The binary decision variable x m k indicates whether variant m of sub-function f k is selected. Using this deri ved latency model, the coordinator constructs an Integer Linear Programming (ILP) formulation that selects one variant per sub-kernel while respecting the global area constraint: min x L total ( x ) s.t. P m x m k = 1 ∀ f k ∈ F , P k,m A m k x m k ≤ A budget , x m k ∈ { 0 , 1 } . (2) 10k 20k 30k 40k 50k 60k 70k 80k 90k 0 2 4 6 8 Speedup vs baseline lavamd Baseline A 2 A 4 A 8 A 10 0.0 10k 20k 30k 40k 50k 60k 70k 0 2 4 6 8 10 kmeans Baseline A 1 A 2 A 4 A 8 A 10 0.0 25k 50k 75k 100k 125k 150k 175k 200k 0 2 4 6 8 hotspot Baseline A 1 A 2 A 4 A 8 A 10 0.0 50k 100k 150k 200k 250k 0.0 2.5 5.0 7.5 10.0 12.5 15.0 leuk ocyte Baseline A 1 A 2 A 4 A 8 A 10 0.0 20k 40k 60k 80k 100k 0 1 2 3 4 5 6 7 8 Speedup vs baseline cfd Baseline A 1 A 2 A 4 A 8 A 10 0.0 20k 40k 60k 80k 100k 120k 0 5 10 15 20 25 streamcluster Baseline A 1 A 2 A 4 A 8 A 10 0.0 20k 40k 60k 80k 100k 0 2 4 6 8 10 aes Baseline A 1 A 2 A 4 A 8 A 10 200 400 600 800 1.0k 1.2k 1.4k 0 2 4 6 8 10 12 kmp Baseline A 1 A 2 A 4 A 8 A 10 8.0k 8.5k 9.0k 9.5k 10k Ar ea 1 2 3 4 5 6 Speedup vs baseline nw Baseline A 1 A 2 A 4 A 8 A 10 0.0 2.0k 4.0k 6.0k 8.0k 10k 12k Ar ea 0 2 4 6 8 10 present Baseline A 1 A 2 A 4 A 8 A 10 0.0 1.0k 2.0k 3.0k 4.0k 5.0k 6.0k Ar ea 1 2 3 4 5 6 des Baseline A 1 A 2 A 4 A 8 A 10 0.0 2.0k 4.0k 6.0k 8.0k 10k 12k 14k Ar ea 1.0 1.5 2.0 2.5 3.0 sha256 Baseline A 1 A 2 A 4 A 8 A 10 Baseline Baseline optimization Sub-k er nel optimization Agent scaling P ar eto - optimal point P ar eto fr ont Fig. 2. Pareto front results for all twelve benchmarks under agent scaling ( N ∈ { 1 , 2 , 4 , 8 , 10 } ). Each subplot shows speedup ov er baseline (y-axis) versus area (x-axis). Increasing the number of agents extends the Pareto front toward lower latency and more favorable area–latency trade-offs across most benchmarks, with the strongest gains on harder problems such as streamcluster , leukocyte, and NW . Because multiple variant combinations can satisfy the area constraint while achie ving similar latency , the solver is used to enumerate the top- N feasible solutions ranked by L total , denoted S = { s 1 , s 2 , . . . , s N } . Each solution corresponds to a distinct global configuration of sub-kernel implementations and serves as a starting point for the next phase of full-design optimization. C. Stage 2: Global Optimization via Agent Scaling Stage 2 takes the candidate set S from the ILP solver and attempts to improve each candidate through holistic, design- wide optimization. A coordinator agent spawns N explor ation agents , one per candidate s i ∈ S . Each agent receives the full design instanti- ated with the sub-kernel variants specified by s i and explores optimization paths that operate across function boundaries. These paths are categorized as: 1. Pragma composition: new combinations of HLS prag- mas applied jointly across multiple functions, not explored during Stage 1. 2. Code restructuring: loop reordering, loop fusion, or function inlining at the global le vel. 3. Memory optimization: cross-function array partitioning and memory access restructuring. 4. Compute optimization: algebraic simplifications or closed-form transformations spanning multiple sub-kernels. Each agent iterativ ely generates modified designs, verifies correctness, synthesizes via HLS, and records (latency , area) pairs. Let R i denote the set of all valid designs explored by agent i . The final output of the pipeline is: D ∗ = arg min d ∈ S N i =1 R i L ( d ) s.t. A ( d ) ≤ A budget . (3) D. Algorithm Summary Algorithm 1 in the appendix summarizes the complete two-stage pipeline. By parameterizing Stage 2 with N , we study how increasing the number of parallel exploration agents af fects solution quality . Larger N e xpands the ex- plored region of the design space, increasing the probability of discovering lower -latency implementations. W e e valuate N ∈ { 1 , 2 , 4 , 8 , 10 } in Section IV. I V . R E S U LT S A. Experimental Setup W e ev aluate the two-stage pipeline on twelve HLS ker- nels: six HLS-Eval benchmarks from prior work [12] (AES, DES, KMP , NW , PRESENT , SHA256) and six from Rodinia- HLS [18] (lav amd, kmeans, hotspot, leukocyte ( lc_dilate ), cfd ( cfd_step_factor ), streamcluster). Results are av er- aged over 5 runs; when HLS reports latency as a range, we use the midpoint. All experiments use Claude Code (Opus 4.5/4.6) with AMD V itis HLS. a) Baselines: For HLS-Eval kernels, we use a bounded exhausti ve baseline that enumerates per-loop pragma config- urations for each sub-kernel. Each loop selects one of fiv e options: no directive, PIPELINE (II ∈ 1 , 2 ), or UNROLL T ABLE II M E AN S P EE D U P OV E R B A SE L I N E A S A G EN T S S C AL E 1 → 2 2 → 4 4 → 8 8 → 10 Speedup 5.26 × (+5.9%) 5.81 × (+13.5%) 7.66 × (+31.8%) 8.27 × (+7.9%) (factor ∈ 2 , 4 ), capturing common loop optimizations with a manageable branching factor . The search space grows as 5 n for n loops, so we cap variants per function to keep synthesis tractable. Each variant is synthesized to obtain latency and area, and an ILP selects one v ariant per sub-kernel to minimize latency under a global area constraint. W e design the baseline to operate at the pragma lev el, isolating directiv e search and enabling a controlled ev aluation of the additional benefits from higher-le vel transformations (e.g., code restructuring, memory layout, array partitioning) introduced by the LLM agent. This provides a strong pragma-only reference, though not globally optimal due to the bounded search. For Rodinia-HLS kernels, we compare against reference optimized implementations (e.g., tiling, pipelining, double- buf fering) and report the best feasible design. All designs must satisfy area and timing constraints. W e use a fixed clock of 10 ns (35 ns for streamcluster ); infeasi- ble baseline configurations are adjusted by reducing pragma factors, and designs violating area or timing are discarded. B. Results on FPGA using V itis HLS 1) Sub-Kernel Optimization: Across the twelve bench- marks, Stage 1 improves latency ov er the baseline while remaining within the area budget; SHA256 is the exception, where performance stays comparable to baseline (Fig. 2). T wo recurring patterns emerge without any HLS- specific training. First, agents consistently identify ARRAY_PARTITION as the highest-impact directiv e, yielding the largest gains in AES, DES, and PRESENT by resolving memory bottlenecks. Second, agents learn that PIPELINE applied in isolation is often ineffecti ve—or ev en harmful—unless memory bandwidth and loop-carried dependencies are addressed first. 2) ILP V ariant Selection: Follo wing sub-kernel optimiza- tion, a coordinator agent composes the surviving variants into a full design. It analyzes the function call graph, derives a latency composition model that accounts for sequential and parallel execution paths, and formulates the ILP objectiv e (Eq. 2) to minimize global latency under an area constraint. T able III validates the agent’ s inferred latency structure on two synthetic benchmarks (SYN5, SYN6) from [12] and two real kernels (NW , AES). The agent correctly captures parallel compositions—minimizing the maximum latency for concurrent modules (SYN5)—and mixed parallel-sequential structures (SYN6). Because this formulation estimates global latency from isolated sub-kernel synthesis, it cannot capture cross-function effects such as inter-kernel memory reuse or global pipeline T ABLE III T H E A G EN T A NA LY ZE S D A TA FL OW G R A P HS A ND AU TO M A T I C AL LY F O RM U L A T E S I L P C O NS T R A IN T S T O M IN I M I ZE L A T E N C Y U N D E R A N A R E A B UD G E T . D A TA FLO W G R AP H B O R ROW E D F RO M [ 1 2 ]. DFG Agent-formulated ILP & constraints min L iter · Loop count s.t. L iter ≥ L F + L O , L iter ≥ 2 L F , L iter ≥ L E + L F P v x v = 1 , P v A v x v ≤ A budget , x v ∈ { 0 , 1 } One variant per function; A v is vari- ant area. min 5( M F O + 2 L E ) s.t. M F O ≥ L F , M F O ≥ L O P v x v = 1 , P v A v x v ≤ A budget , x v ∈ { 0 , 1 } L F , L O denote latencies of F and O. min( L F M + L T B + L RS ) P v x v = 1 , P v A v x v ≤ A budget , x v ∈ { 0 , 1 } L F M , L T B , L RS denote module la- tencies. min 11 L ARK + 10 L S B + 10 L S R + 9 L M C + L K E + L I N I T P v x v = 1 , P v A v x v ≤ A budget , x v ∈ { 0 , 1 } L ∗ denotes module latency . scheduling. Exhausti ve enumeration w ould resolve this gap b ut is computationally prohibitive. The ILP stage therefore serves as an efficient filter that narrows the search space, producing a ranked set of N starting points for Stage 2. 3) Global Optimization: Figure 2 shows Pareto fronts across all twelve benchmarks, and T able II reports the mean best speedup over 5 runs as agents scale from N =1 to N =10 . W e organize the findings below by the character of the scaling behavior . a) Str ong scaling on complex workloads: The largest gains appear on benchmarks with rich optimization landscapes. Str eamcluster benefits most dramatically: speedup climbs from ∼ 6 × to ov er 20 × as agents scale, with each increment exposing new regions of the Pareto front. Cfd , hotspot , and kmeans follow a similar pattern, reaching 7 – 10 × speedup with progressiv ely better area–latency trade-offs. Among the larger Rodinia kernels, lavamd reaches ∼ 8 × speedup at moderate area. b) Intermediate and non-monotonic behavior: F or PRESENT , NW , and DES, scaling improves latency overall b ut the progression is not strictly monotonic: in several cases (e.g., PRESENT , DES), N =8 yields Pareto-optimal designs not dominated by N =10 , reflecting stochastic exploration effects. Leukocyte presents a distinct pattern: its top speedup ( ∼ 14 – 15 × ) originates from a baseline optimization that agents do not replicate, though they do improve designs in the ∼ 7 – 10 × Fig. 3. Latency improvement factor over baseline versus number of expert agents across six benchmarks. Improvements range from 1.4 × to 14.5 × and generally increase with agent count, typically plateauing after four agents. range. c) Saturation under simplicity or tight r esour ce budg ets: Simpler or resource-constrained kernels exhibit diminishing returns. KMP saturates early ( ∼ 10 – 12 × ), and AES shows similar performance for N =8 and N =10 . NW , which operates near its area limit ( ∼ 10 K), illustrates a related effect: N =8 slightly outperforms N =10 , suggesting that under tight area budgets additional agents may explore configurations that trade area for diminishing latency gains. d) Global optimization beyond sub-kernel decomposi- tion: Across benchmarks, the best final designs do not al- ways originate from the top-ranked ILP variant. This con- firms that Stage 2 optimization—through pragma recombina- tion and code-level transformations applied across function boundaries—can exploit cross-function interactions that the ILP model, which estimates global latency from isolated sub- kernel synthesis, cannot capture. C. Generalization to ASICs The approach presented in this paper uses HLS tools with FPGA as the target device to e valuate and guide the agent- based optimization flow . While the approach itself is tool- agnostic, and can use ASIC-targeted HLS and logic synthesis tools to e valuate and guide the flow , we sho w that both latency improv ements and area correlate well to an ASIC-mapped design as well. T o measure how well area reported by HLS tool correlates with ASIC-mapped area, we compute correlation between HLS-reported synthesis area and logic area obtained from the open-source logic synthesis tool ABC, across the six HLS-Ev al benchmarks. The strength of the correlation varies: SHA256 ( r =0 . 992 ), KMP ( r =0 . 964 ), and NW ( r =0 . 859 ) show strong near-linear relationships, indicating that HLS area estimates are generally reliable proxies for silicon cost on these kernels. AES ( r =0 . 757 ) shows moderate-to-strong correlation, while DES ( r =0 . 603 ) is moderate. PRESENT ( r =0 . 277 ) exhibits weak correlation, suggesting that HLS area estimates may be less reliable for this design. This variation is because HLS tool area estimates tend to be inaccurate for designs with more memory instances. Figure 3 shows the factor of improv ement in latency (com- pared to the baseline design) on the y-axis and number of agents on the x-axis. Latency is computed as the product of number of cycles obtained from the HLS timing report and an estimate for clock period obtained from ABC synthesis report. The latency value for different number of agents is then normalized by the latency of the baseline design (without agentic optimization) to get the latency reduction factor on the y-axis. Across the six benchmarks, latency can be improved by a factor ranging from 1.4X to 14.5X. For all benchmarks, latency improvements increase with increasing number of expert agents, typically plateauing after four expert agents. D. Discussion and Futur e W ork This work presents an initial exploration of agent scaling for HLS design space exploration. Our results demonstrate that Agent F actories , when applied to High Level Synthesis domain yield sev eral consistent trends: increasing the number of agents improve exploration and extend the Pareto frontier on se veral kernels. This suggests that agent scaling, analogous to inference-time scaling in LLMs can serve as a powerful mechanism for navigating large hardware designs spaces with- out explicit training or handcrafted heuristics. While these results are encouraging, the current study can be significantly expanded in scope. Our ev aluation spans twelve benchmarks and focuses on V itis HLS with logic-lev el validation through ABC, without yet incorporating broader benchmark suites (e.g., HLSyn) or comparisons to advanced automated DSE framew orks such as AutoDSE. Sev eral directions follow naturally from this observ ation: in- corporating learning (e.g., fine-tuning or reinforcement learn- ing) to improve generalization and efficienc y; expanding ev al- uation across broader benchmarks and toolchains, including downstream synthesis; and integrating adv anced agentic strate- gies (e.g., memory , replay , coordination) to improve search quality . In addition, we are working towards several baselines comparisons with traditional optimization methods as well for HLS design space exploration to determine the differentiation and tradeoffs inv olved with Agent Factoties. This research demonstrates a powerful result that taken together , the direction point tow ard a broader vision in which agent-based systems, combined with learning and deeper inte- gration into hardware toolchains, act as scalable optimizers for complex design spaces, reducing the need for manual expertise and enabling more automated hardware design. A P P E N D I X A A G E N T S C A L I N G T O K E N U S AG E T oken usage is reported as the total number of model tokens consumed by the agents during execution, with Claude Opus 4.5 and Claude Opus 4.6 used as the underlying models. Across all valid runs, the method consumed a median of 5.82M tokens and a mean of 7.67M tokens per run, indicating a right-ske wed distribution with a small number of substan- tially more expensiv e runs. The 25th and 90th percentiles were 3.09M and 13.39M tokens, respecti vely , while the observed range spanned from 1.14M to 45.33M tokens. These results indicate that token consumption is typically in the low-to- mid millions per run, with occasional substantially higher-cost outliers. The overall token summary is shown in Fig. 4. Fig. 4. A verage Inference cost of agent scaling. Each session is combination of Opus 4.5/4.6. A P P E N D I X B A L G O R I T H M Algorithm 1 summarizes the complete two-stage pipeline. By parameterizing Stage 2 with N , we study how increasing the number of parallel exploration agents affects solution quality . Larger N expands the explored region of the design space, increasing the probability of discov ering lower -latency implementations. W e ev aluate N ∈ { 1 , 2 , 4 , 8 , 10 } in Sec- tion IV. R E F E R E N C E S [1] A. Sohrabizadeh, C. H. Y u, M. Gao, and J. Cong, “ Autodse: Enabling software programmers to design efficient fpga accelerators, ” A CM T rans. Des. Autom. Electr on. Syst. , vol. 27, no. 4, Feb . 2022. [Online]. A vailable: https://doi.org/10.1145/3494534 [2] J. Ansel, S. Kamil, K. V eeramachaneni, J. Ragan-K elley , J. Bosboom, U.-M. O’Reilly , and S. Amarasinghe, “Opentuner: an extensible framew ork for program autotuning, ” in Pr oceedings of the 23rd International Confer ence on P arallel Ar chitectur es and Compilation , ser . P ACT ’14. New Y ork, NY , USA: Association for Computing Machinery , 2014, p. 303–316. [Online]. A vailable: https://doi.org/10. 1145/2628071.2628092 [3] J. Zhao, L. Feng, S. Sinha, W . Zhang, Y . Liang, and B. He, “Comba: a comprehensiv e model-based analysis framew ork for high lev el synthesis of real applications, ” in Proceedings of the 36th International Confer- ence on Computer-Aided Design , ser . ICCAD ’17. IEEE Press, 2017, p. 430–437. [4] J. Cong, J. Lau, G. Liu, S. Neuendorffer , P . Pan, K. V issers, and Z. Zhang, “Fpga hls today: Successes, challenges, and opportunities, ” ACM T rans. Reconfigurable T echnol. Syst. , vol. 15, no. 4, Aug. 2022. [Online]. A vailable: https://doi.org/10.1145/3530775 [5] M. R. Ahmed, T . Koike-Akino, K. Parsons, and Y . W ang, “ Autohls: Learning to accelerate design space exploration for hls designs, ” 2024. [Online]. A vailable: https://arxiv .org/abs/2403.10686 [6] H. Kuang, X. Cao, J. Li, and L. W ang, “Hgbo-dse: Hierarchical gnn and bayesian optimization based hls design space exploration, ” in 2023 International Conference on Field-Pr ogrammable T echnology (ICFPT) , 2023, pp. 106–114. [7] H. Kuang and L. W ang, “Compass: A collaborativ e hls design space exploration framework via graph representation learning and ensemble bayesian optimization, ” 2024 International Confer ence on F ield Pr ogrammable T echnology (ICFPT) , pp. 1–9, 2024. [Online]. A vailable: https://api.semanticscholar .org/CorpusID:280697200 Algorithm 1: T wo-Stage Multi-Agent Design Space Exploration for HLS Input: Design D , area budget A max , agents N Output: Optimized design D ∗ 1 Coordinator extracts call graph G = ( F , E ) from D ; 2 forall f k ∈ F in parallel do 3 launch optimizer agent a k ; 4 V k ← a k . S E A R C H A N D E V A L UA T E ( f k ) ; 5 end 6 ILP agent builds a global model from {V k } and G ; 7 S ← top- N feasible ILP solutions; 8 forall s i ∈ S in parallel do 9 launch exploration agent g i ; 10 R i ← g i . T A R G E T E D R E FI N E M E N T ( D , s i , A max ) ; 11 end 12 D ∗ ← arg min d ∈∪ i R i L ( d ) s.t. A ( d ) ≤ A max ; 13 return D ∗ ; 14 Function S E A R C H A N D E V A L UAT E ( f k ) : 15 generate candidate variants { v m k } M m =0 ; 16 V k ← { ( v m k , L m , A m ) | C O R R E C T N E S S ( v m k ) } ; 17 retur n verified variants in V k with HLS metrics ; 18 Function T A R G E T E D R E FI N E M E N T ( D , s, A max ) : 19 instantiate D s ← I N S TA N T I A T E ( D , s ) ; 20 generate refinement attempts { p j } ; 21 R ← { ( D j , L j , A j ) | D j = A P P L Y ( p j , D s ) , C O R R E C T N E S S ( D j ) , A j ≤ A max } ; 22 retur n R if non-empty , else { ( D s , L s , A s ) } ; [8] V . G. Castellana, A. T umeo, and F . Ferrandi, “High-lev el synthesis of parallel specifications coupling static and dynamic controllers, ” in 2021 IEEE International P arallel and Distributed Pr ocessing Symposium (IPDPS) , 2021, pp. 192–202. [9] S. Pouget, L.-N. Pouchet, and J. Cong, “ Automatic hardware pragma insertion in high-le vel synthesis: A non-linear programming approach, ” ACM Tr ans. Des. Autom. Electr on. Syst. , vol. 30, no. 2, Feb . 2025. [Online]. A vailable: https://doi.org/10.1145/3711847 [10] N. Prakriya, Z. Ding, Y . Sun, and J. Cong, “Lift: Llm-based pragma insertion for hls via gnn supervised fine-tuning, ” 2025. [Online]. A vailable: https://arxiv .org/abs/2504.21187 [11] C. Xiong, C. Liu, H. Li, and X. Li, “Hlspilot: Llm-based high-level synthesis, ” 2024. [Online]. A vailable: https://arxiv .org/abs/2408.06810 [12] L. Collini, A. Hennessee, R. Karri, and S. Garg, “Can reasoning models reason about hardware? an agentic hls perspectiv e, ” in 2025 IEEE International Confer ence on LLM-Aided Design (ICLAD) , 06 2025, pp. 188–194. [13] J. Y ang, C. E. Jimenez, A. W ettig, K. Lieret, S. Y ao, K. Narasimhan, and O. Press, “Swe-agent: Agent-computer interfaces enable automated software engineering, ” 2024. [Online]. A vailable: https://arxiv .org/abs/ 2405.15793 [14] S. Hong, M. Zhuge, J. Chen, X. Zheng, Y . Cheng, C. Zhang, J. W ang, Z. W ang, S. K. S. Y au, Z. Lin, L. Zhou, C. Ran, L. Xiao, C. Wu, and J. Schmidhuber , “Metagpt: Meta programming for a multi-agent collaborativ e framework, ” 2024. [Online]. A vailable: https://arxiv .org/abs/2308.00352 [15] C. Qian, W . Liu, H. Liu, N. Chen, Y . Dang, J. Li, C. Y ang, W . Chen, Y . Su, X. Cong, J. Xu, D. Li, Z. Liu, and M. Sun, “Chatdev: Communicativ e agents for software development, ” 2024. [Online]. A vailable: https://arxiv .org/abs/2307.07924 [16] S. W ong, Z. Qi, Z. W ang, N. Hu, S. Lin, J. Ge, E. Gao, W . Chen, Y . Du, M. Y u, and Y . Zhang, “Confucius code agent: Scalable agent scaffolding for real-world codebases, ” 2026. [Online]. A vailable: https://arxiv .org/abs/2512.10398 [17] A. Karpathy , “ Autoresearch: Autonomous machine learning research with ai agents, ” https://github .com/karpathy/autoresearch, 2026. [18] J. Cong, Z. Fang, M. Lo, H. W ang, J. Xu, and S. Zhang, “Understanding performance dif ferences of fpgas and gpus: (abtract only), ” in Pr oceedings of the 2018 ACM/SIGD A International Symposium on F ield-Pr ogrammable Gate Arrays , ser . FPGA ’18. New Y ork, NY , USA: Association for Computing Machinery , 2018, p. 288. [Online]. A vailable: https://doi.org/10.1145/3174243.3174970 [19] J. Cong, B. Liu, S. Neuendorffer , J. Noguera, K. V issers, and Z. Zhang, “High-lev el synthesis for fpgas: From prototyping to deployment, ” IEEE T ransactions on Computer-Aided Design , 2011. [20] J. Cong, P . W ang, and Y . Zhang, “ Automatic design space exploration for high-lev el synthesis, ” in Design Automation Confer ence (DA C) , 2012. [21] L. Ferretti, G. Ansaloni, and L. Pozzi, “Lattice-traversing design space exploration for high level synthesis, ” in 2018 IEEE 36th International Confer ence on Computer Design (ICCD) , 2018, pp. 210–217. [22] G. Zhong, A. Prakash, S. W ang, Y . Liang, T . Mitra, and S. Niar, “Design space exploration of fpga-based accelerators with multi-level parallelism, ” in Design, Automation & T est in Europe Conference & Exhibition (DA TE), 2017 , 2017, pp. 1141–1146. [23] C. Xu, G. Liu, R. Zhao, S. Y ang, G. Luo, and Z. Zhang, “ A parallel bandit-based approach for autotuning fpga compilation, ” in Pr oceedings of the 2017 ACM/SIGD A International Symposium on F ield-Pr ogrammable Gate Arrays , ser . FPGA ’17. Ne w Y ork, NY , USA: Association for Computing Machinery , 2017, p. 157–166. [Online]. A vailable: https://doi.org/10.1145/3020078.3021747 [24] Q. Gautier, A. Althoff, C. L. Crutchfield, and R. Kastner, “Sherlock: A multi-objectiv e design space exploration framework, ” ACM T rans. Des. Autom. Electron. Syst. , vol. 27, no. 4, Mar . 2022. [Online]. A vailable: https://doi.org/10.1145/3511472 [25] Y . Bai, A. Sohrabizadeh, Z. Qin, Z. Hu, Y . Sun, and J. Cong, “T owards a comprehensive benchmark for high-lev el synthesis targeted to fpgas, ” in Advances in Neural Information Processing Systems , 2023. [26] Y . Bai, A. Sohrabizadeh, Y . Sun, and J. Cong, “Improving gnn-based accelerator design automation with meta learning, ” in Proceedings of the 59th ACM/IEEE Design Automation Conference , ser . DA C ’22. New Y ork, NY , USA: Association for Computing Machinery , 2022, p. 1347–1350. [Online]. A vailable: https://doi.org/10.1145/3489517. 3530629 [27] A. Sohrabizadeh, Y . Bai, Y . Sun, and J. Cong, “ Automated accelerator optimization aided by graph neural networks, ” in Pr oceedings of the 59th ACM/IEEE Design Automation Confer ence , ser. D A C ’22. New Y ork, NY , USA: Association for Computing Machinery , 2022, p. 55–60. [Online]. A vailable: https://doi.org/10.1145/3489517.3530409 [28] ——, “Robust GNN-based representation learning for HLS, ” in Pr o- ceedings of the 42nd IEEE/ACM International Confer ence on Computer- Aided Design (ICCAD) , 2023. [29] N. Wu, Y . Xie, and C. Hao, “Ironman: Gnn-assisted design space exploration in high-level synthesis via reinforcement learning, ” in Pr oceedings of the 2021 Gr eat Lakes Symposium on VLSI , ser . GLSVLSI ’21. A CM, Jun. 2021, p. 39–44. [Online]. A vailable: http://dx.doi.org/10.1145/3453688.3461495 [30] Z. Qin, Y . Bai, A. Sohrabizadeh, Z. Ding, Z. Hu, Y . Sun, and J. Cong, “Cross-modality program representation learning for electronic design automation with high-level synthesis, ” 2024. [Online]. A vailable: https://arxiv .org/abs/2406.09606 [31] H. W ang, X. W u, Z. Ding, S. Zheng, C. W ang, N. Prakriya, T . Now atzki, Y . Sun, and J. Cong, “Llm-dse: Searching accelerator parameters with llm agents, ” 2025. [Online]. A vailable: https://arxi v .org/abs/2505.12188 [32] R. Li, J. Xiong, and X. W ang, “idse: Navigating design space exploration in high-level synthesis using llms, ” 2025. [Online]. A vailable: https://arxiv .org/abs/2505.22086 [33] L. Collini, S. Garg, and R. Karri, “C2hlsc: Lev eraging lar ge language models to bridge the software-to-hardware design gap, ” ACM T ransactions on Design Automation of Electr onic Systems , vol. 30, no. 6, p. 1–24, Oct. 2025. [Online]. A vailable: http: //dx.doi.org/10.1145/3734524 [34] K. Xu, G. L. Zhang, X. Y in, C. Zhuo, U. Schlichtmann, and B. Li, “ Automated c/c++ program repair for high-level synthesis via large language models, ” 2024. [Online]. A vailable: https://arxiv .org/abs/2407. 03889 [35] A. E. Oztas and M. Jelodari, “ Agentic-hls: An agentic reasoning based high-level synthesis system using large language models (ai for eda workshop 2024), ” 2024. [Online]. A vailable: https: //arxiv .org/abs/2412.01604 [36] I. Puri, S. Sudalairaj, G. Xu, K. Xu, and A. Srivasta va, “Rollout roulette: A probabilistic inference approach to inference-time scaling of llms using particle-based monte carlo methods, ” in Advances in Neural Information Processing Systems (NeurIPS) , 2025.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment